
双麦克风语音增强算法研究与实现
2022-05-24 11:44崔智恒焦继业祝禛天
电子设计工程 2022年10期
崔智恒,焦继业,祝禛天
(1.西安邮电大学计算机学院,陕西 西安 710121;2.西安邮电大学电子工程学院,陕西 西安 710121)
语音增强是语音识别的重要组成部分,目前已经被广泛应用于电话语音拨号、家电遥控、汽车设备的语音控制、智能玩具等领域。此外,随着IC技术和信号处理技术的不断发展,电子设备的体积变得越来越小,这就要求在拥有良好增强效果的前提下,减少麦克风的数量,压缩体积,才能满足设备的小型化需求[1]。语音增强主要分为单通道语音增强和多通道语音增强。单通道的算法中都有一个基本的假设,即噪声是平稳的[5],因此对非平稳噪声的抑制能力有限。为了解决单通道语音增强系统存在的不足,提出了多通道的语音增强算法[8]。对于小型化的嵌入式设备语音增强,如何在保证阵列体积不能过大及系统实时性的前提下,提升语音增强的性能成为需要解决的问题。
针对这一问题,文中提出一种结合一阶差分阵列与语音活动检测的双麦克风语音增强算法,并给出了硬件实现方案。
1 原理分析
1.1 双麦克风阵列模型
在不考虑声学反射的条件下,双麦克风阵列中每个麦克风所接收到的信号可以表示为:
式中,xi(t)(i=1,2)为两个麦克风接收到的带噪语音信号,s(t)为纯净语音信号,ni(t)(i=1,2)为两个麦克风接收到的噪声信号,Δt为声源到达两个麦克风之间的延迟时间。
对于远场语音信号,声音到达两个麦克风的传播模型[11]如图1所示,图中d为麦克风间距,由图1可知,声源到达两个麦克风之间的延迟时间Δt=(dcosθ)/c,c为声速。
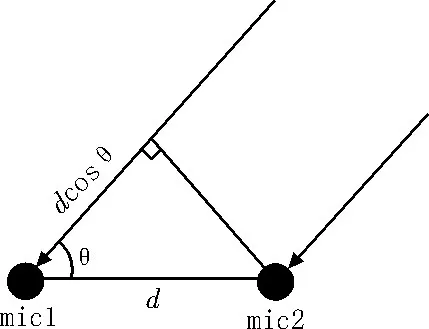
图1 双麦克风阵列传播模型
一阶差分阵列的延迟相减实现框图[12]如图2 所示,延迟单元T=c/d,∑表示求和运算。
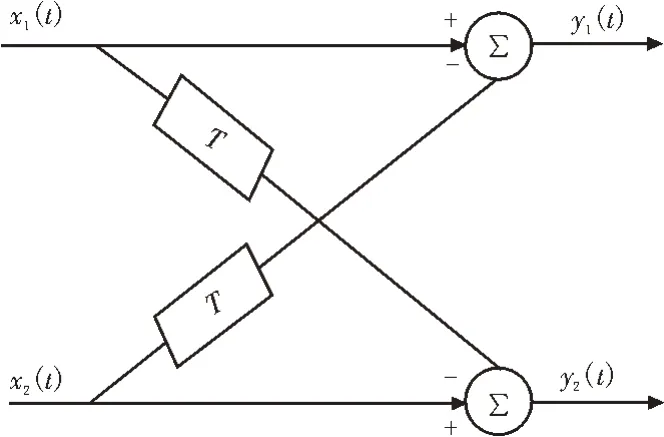
图2 延迟相减实现框图
由图2 可得,一阶差分阵列的输出信号为:
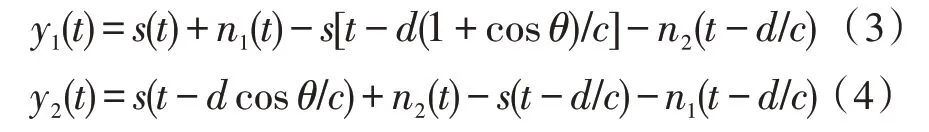
一阶差分阵列的期望声源一般在阵列的沿线方向,即θ≈0°,所以式(4)可以近似为:
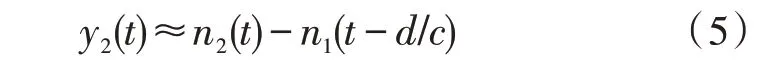
因此,y2(t)中只包括噪声项,y1(t)不仅包括空间波束所增强的语音,还包括部分残余噪声,通过y2(t)通道中的参考噪声来抵消y1(t)通道的残余噪声就可以进一步实现语音增强。
根据文献[13]给出的具体设计方法,定义先验信噪比:

1.2 语音活动检测
上述双麦克风阵列语音增强方法需要首先估计先验信噪比,而先验信噪比的计算又依赖于参数β,即静音段的比值,所以静音段的估计决定着语音增强性能的好坏。传统方法采用语音数据的前几帧作为对静音段的估计[14],这种方法易于实现,可以在一定程度上实现噪声的去除;但是对静音段的估计过于粗略,当估计不准确时会大大降低语音增强的性能。语音活动检测可以通过计算语音数据的特征参数实现有无声段的判定。因此引入语音活动检测来实现静音段的准确估计,由此可以进一步提升语音增强的性能。综合考虑小型化嵌入式设备对计算量和实时性的要求,文中设计选择基于短时幅度值和过零率的双门限语音活动检测方法[15]来实现对静音段的估计。
短时幅度值主要用来区分清音和浊音,因为清音的能量相对于浊音要小的多,因此可以用它作为有无声段的判定门限之一。其定义如式(8)所示:

式中,N为帧长,E为每一帧对应的短时幅度值。短时过零率指信号在一帧时间内通过零值的次数,其定义如式(9):
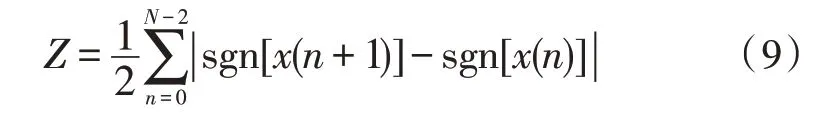
式中,Z为每一帧对应的过零率,sgn(x)是符号函数。
1.3 算法流程
图3 给出了改进前增强算法的实现流程,采用语音数据的前几帧作为静音段的估计。图4给出了引入语音活动检测后增强算法的实现流程,使用语音活动检测实现对静音段的估计,VAD表示语音活动检测。
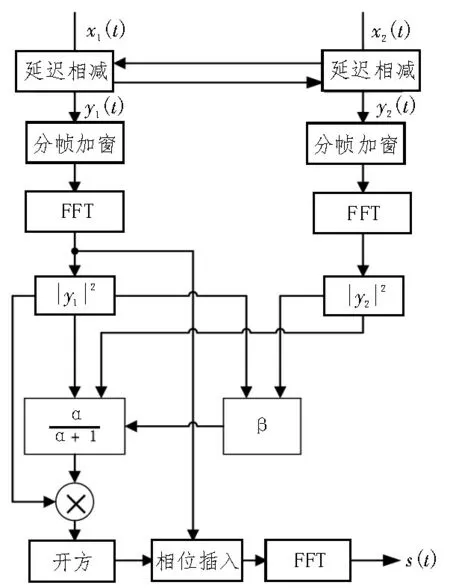
图3 改进前算法流程
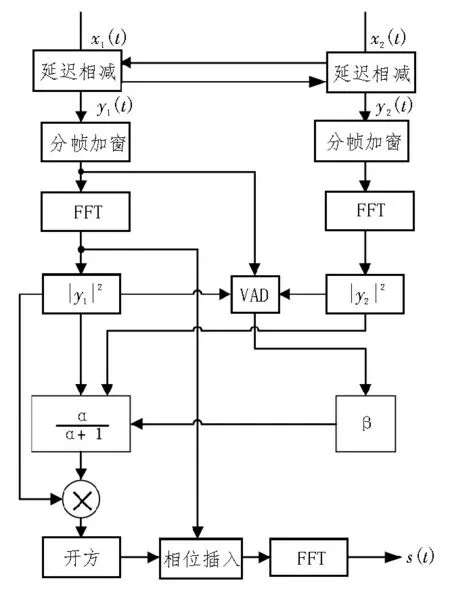
图4 改进后算法流程
2 FPGA实现
2.1 整体架构
增强算法最初是在可以进行高精度浮点运算的Matlab 平台开发的。在FPGA 实现时,需要考虑到数据精度的问题。全浮点运算无疑会占用较多的资源,不利于部署在资源有限的平台。全定点计算虽然降低了资源的占用,但是由于数据精度不足,会导致系统中增加量化噪声,影响语音增强的质量。文中设计为了平衡硬件资源和性能,制定了定点—浮点分块结构,分为定点计算部分和浮点计算部分,系统整体架构如图5 所示。
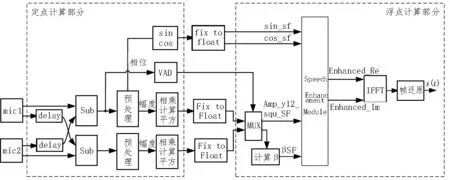
图5 硬件实现架构图
2.2 语音预处理模块
因为语音信号具有短时平稳性,所以需要对其进行分帧操作。为了保证语音信号的连续性和完整性,每帧数据之间都会有重叠,即帧移。为了便于FPGA 实现,设计中帧长选择为256,帧移为128。
加窗处理可以避免傅里叶变换时发生频谱泄漏。该设计中窗函数选择升余窗中的汉宁窗,窗长为256。
图6 所示是语音预处理模块的FPGA 实现框图,该模块主要包括分帧、加窗、FFT、CORDIC 及去除镜像缓存FIFO。为了实现更高效的开发,FIFO、FFT 和CORDIC 均采用Xilinx 现有的IP 核。通过两个FIFO作乒乓缓存实现分帧操作,这里参考时钟频率为50 MHz。分帧之后数据重叠一半,导致数据率增加一倍,而FFT 及CORDIC 模块占用资源较多,所以将这部分计算模块的时钟频率增加一倍来匹配数据率,参考时钟频率为100 MHz。数据分帧之后的加窗是利用LUT 查找表的方式提取汉宁窗函数,再通过乘法器实现的。经过FFT 处理后的数据有一半是镜像频率,只需要处理有效频率,所以数据率降低了1/2,此时,同步时钟频率降为50 MHz。
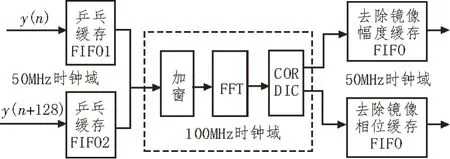
图6 语音预处理框图
2.3 语音活动检测模块
语音活动检测主要涉及短时幅度值和过零率两个关键参数的计算。数据的绝对值可以通过判断最高位进行计算,将一帧数据的绝对值进行累加就可以输出这帧的短时幅度值,同时累加器清零开始下一帧的累加。在过零率的计算中,分帧后的数据被延迟一个时钟,然后在每个时钟周期中判断延迟前每一帧和延迟后每一帧的最高位。如果数据的最高位不同,则判别结果为1,否则判别结果为0。最后,在一帧数据范围内对判别结果进行累加得到过零率。
对静音段的估计采用有限状态机实现,门限阈值的设定基于背景噪声,取前6 帧数据的短时幅度值和过零率,分别求取平均值来计算短时幅度值和过零率的门限阈值,如式(10)、(11)所示。
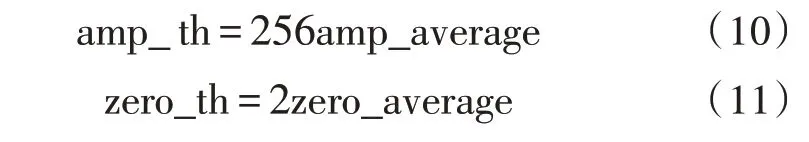
式中,amp_average、zero_average 分别为前6 帧数据短时幅度值和过零率均值,amp_th 为短时幅度值门限,zero_th 为过零率门限。状态转移如图7 所示,包括4 个状态:S0(初始态)、S1(静音态)、S2(过渡态)、S3(语音态)。frm_count表示帧计数,voice_count表示语音帧计数,voice_min 表示语音最小帧数。
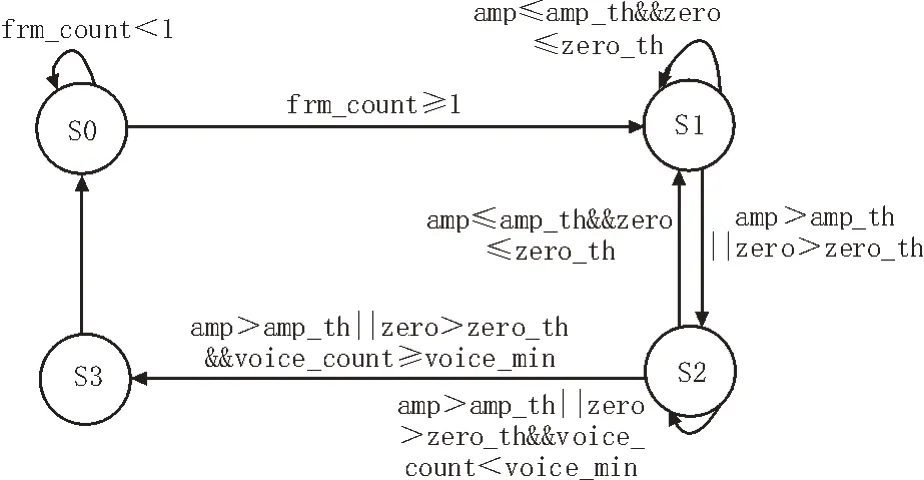
图7 静音段估计状态转移图
在初始态S0,复位voice_count,当帧计数大于或等于1 时跳转到静音态S1。在静音态S1,如果短时幅度值小于或等于amp_th 且过零率小于或等于zero_th,则继续停留在S1 态;如果短时幅度值大于amp_th 或过零率大于zero_th,则跳转到过渡态S2,同时voice_count 加1。在过渡态S2,如果短时幅度值大于amp_th 或过零率大于zero_th 且语音帧计数小于voice_min,继续停留在过渡态,同时voice_count加1,这是为了消除能量比较大的突发噪声所造成的影响。如果短时幅度值小于或等于amp_th 且过零率小于或等于zero_th,则跳转到静音态S1,同时voice_count 清零;如果短时幅度值大于amp_th 或过零率大于zero_th且语音帧计数大于或等于voice_min,则跳转到语音态S3,此时静音段的估计流程结束。
2.4 语音增强模块
经过化简,增强之后的语音功率可以表示为:

根据上述所设计的开方及相位插入模块如图8所示。
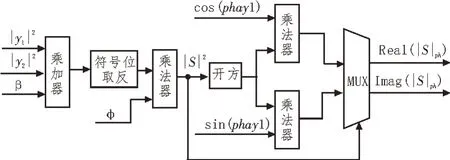
图8 开方及相位插入
得到增强语音的频域输出之后需要进行傅里叶逆变换,将频域信号还原为时域信号。由于前面去除了镜像频率数据,而IFFT 又做256 点,所以需要补零,这就导致数据率提高了一倍。为了节省资源,这里只使用一个IFFT IP,IFFT 处理时钟也提高一倍,利用FIFO 进行跨时钟域处理。IFFT 输出的数据实部是分帧之后的语音数据,需要通过重叠相加来进行帧还原,数据率降低1/2,与IFFT 之前输入数据的数据率相同,这里也使用FIFO 进行跨时钟域处理。IFFT 及帧还原如图9 所示。
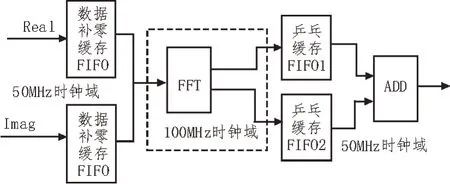
图9 IFFT及帧还原
3 实验与分析
3.1 实验结果
文中设计在FPGA平台Xilinx Artix-7(XC7A35TL1CSG324I)开发板进行验证,验证平台如图10所示。

图10 验证平台
测试语音数据来自中文语音数据库THCHS30,使用软件模拟双麦克风阵列模型得到两路语音数据,并将两路数据存储到FPGA 的ROM 中作为语音输入。为了数据的直观显示,通过逻辑分析仪ILA抓取硬件产生的输出,并导入到Matlab 中与软件端实现的结果进行比较,实验结果如图11 所示。
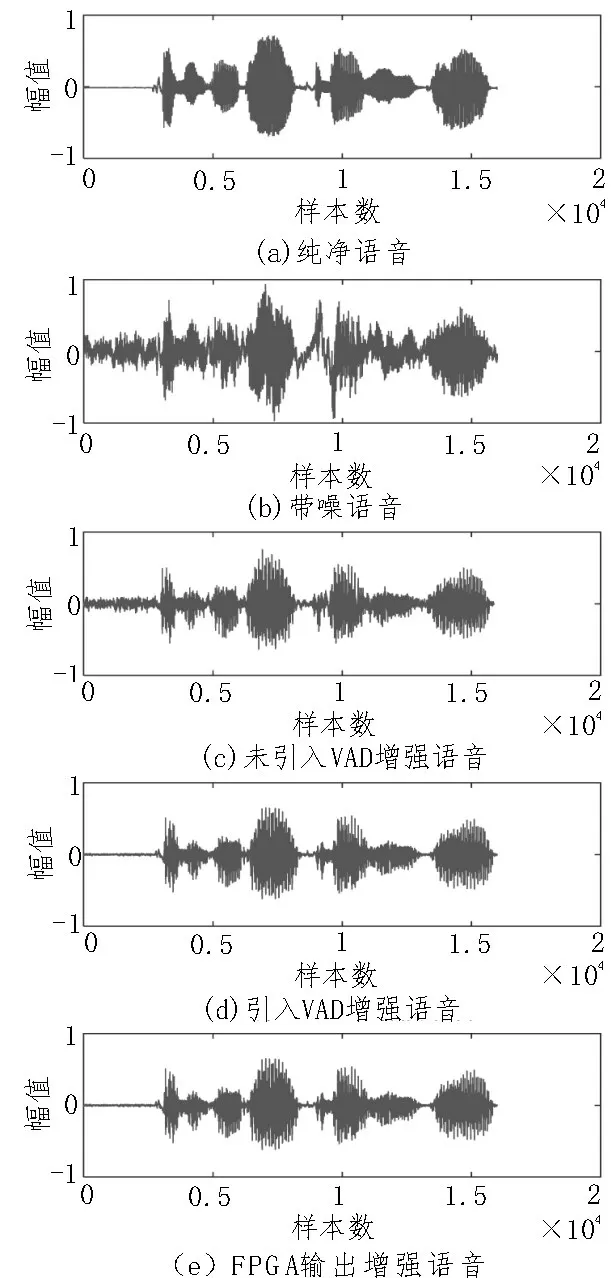
图11 语音波形图
通过对比波形可以看出,带噪语音经过处理后可以有效实现语音增强,引入语音活动检测可以大大提高语音增强的质量,并且FPGA 的实现也是有效的。
文中还使用多段语音进行客观语音质量评估(Perceptual Evaluation of Speech Quality),将PESQ 得分作为评价语音质量的指标,PESQ 得分对比如表1。
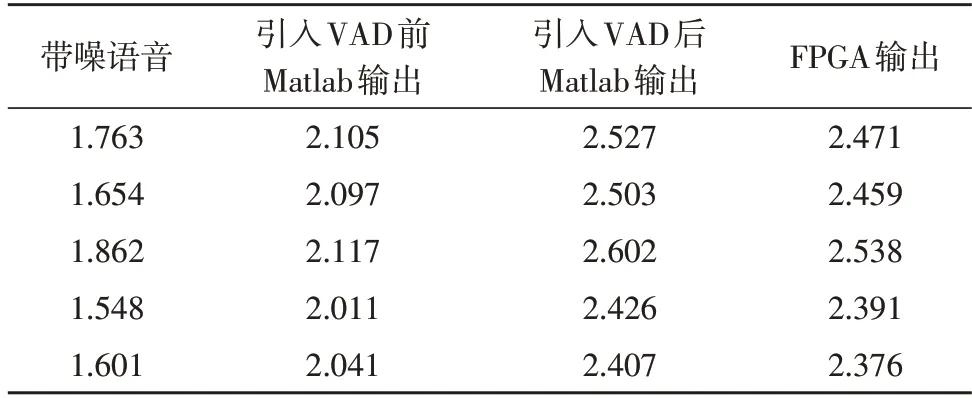
表1 PESQ得分对比
由表1 可以看出,引入VAD 后,Matlab 输出增强语音PESQ 得分平均提高了20.18%;FPGA 输出的增强语音与Matlab 输出相比,得分平均下降了1.83%,与带噪语音相比,得分平均提高了45.61%,可见通过引入VAD 可以有效提高语音增强的性能,并且FPGA 的实现与Matlab 等效,证明了FPGA 实现的准确性。
另外,对该设计进行了实时性评估,以处理1 s的16 kHz 语音的时间为评价指标,该设计仅需要1.92 ms 便可完成语音增强,可以满足实时语音增强的需求。
3.2 资源利用率
表2 为该设计经过Vivado 综合布局布线之后的资源消耗情况。由表可知,该设计相对于文献[16-17]中单通道语音增强设计,资源消耗有所增加,但是却实现了双通道语音增强,克服了单通道语音增强对非平稳噪声抑制效果不佳的缺点,并且占用的硬件资源适中,适合应用于嵌入式设备[18]。
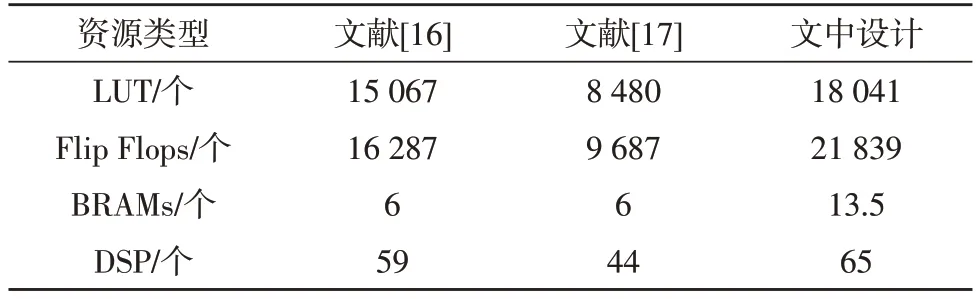
表2 资源利用对比
4 结论
文中面向小型化嵌入式设备提出一种基于一阶差分阵列的双麦克风语音增强方案,针对现有算法容易因静音段估计不准确造成语音增强性能下降这一问题,提出了通过语音活动检测对有无声段进行判别,实现对静音段准确估计的改进方案。实验结果表明,该方案相对于优化前设计,语音PESQ 得分平均提高20.18%,并且基于FPGA 的实现与纯浮点Matlab 平台等效,可实现实时语音增强,为小型化嵌入式设备语音增强提供了方法。后续工作中还需要深入研究,使用更高效的语音活动检测方法来提升语音增强的性能。
猜你喜欢
股市动态分析(2021年25期)2021-12-30
石油沥青(2021年3期)2021-08-05
电脑报(2020年50期)2020-03-10
宇航计测技术(2018年3期)2018-09-08
小学科学(2016年12期)2017-01-06
电脑爱好者(2016年24期)2017-01-05
发明与创新(2016年34期)2016-08-22
做人与处世(2015年19期)2015-09-10
股市动态分析(2014年27期)2014-07-29
南方周末(2014-01-02)2014-01-02
