
零参考样本下的逆光图像深度学习增强方法
2022-05-23 03:55王知音张二虎石争浩段敬红
中国图象图形学报 2022年5期
王知音,张二虎*,石争浩,段敬红
1.西安理工大学印刷包装与数字媒体学院,西安 710048;2.西安理工大学计算机科学与工程学院,西安 710048
0 引 言
随着数码相机和移动设备在消费者市场的流行,拍照已经成为人们记录生活的一种主流方式,而如何拍摄出高质量的照片依旧是个难以掌控的问题。影响拍照质量的一个重要环境因素就是光线,其中逆光图像就是由于拍摄光线位于拍摄目标的后面,使拍摄设备感受到的目标主体反射光很弱,而背景的反射光较强形成的。如图1是典型的逆光图像,其背景亮度远高于主体部分,以至于人们感兴趣部分的亮度、对比度和可视性质量都较低,极大地影响了对图像细节信息的获取,而且不利于图像的后期应用,如图像识别和目标跟踪等。

图1 逆光情况下拍摄的图像
采用传统的图像增强方法如对数变换、γ变换及直方图均衡化等直接处理逆光图像并不可行,因为逆光图像和常见的低照度图像不同,逆光图像同时存在欠曝光区域(图像中较暗的区域)和过曝光区域(图像中较亮的区域)。传统方法主要是提升图像整体亮度,极易导致逆光图像增强过度或者增强程度不够。另一种主流方法是基于Retinex理论,该方法的主要思想是将图像分解为反射分量和照射分量,而反射分量通常被认为是一致的,所以传统的Retinex算法一般在光照均匀的场景下才能有效地解决曝光不足的问题。如Wang等人(2013)利用光通滤波器将图像分解为反射图像和照射图像,并用双对数变换对照射图像进行调整,提出了保持自然特性的增强算法(naturalness preserved enhancement algorithm,NPEA)。虽然NPEA具有增强细节和保持图像自然特性的优点,但当图像前景与背景的亮度存在较大差异时(如逆光图像),会导致处理后的图像在明暗对比处产生明显的光晕效应。
为了解决传统方法受限于全局增强的缺点,很多基于分割的方法致力于将逆光图像的不同曝光区域分别增强。如Kim等人(2013)采用模糊C聚类算法将逆光图像分割成前景区域和背景区域,再用自适应加权中值滤波器进行矫正,由于该算法针对移动端所设计,主要追求的是处理速度,所以增强效果受分割算法的影响并不优异。另外,Im等人(2013)受到暗通道法的启发,采用该思想提取逆光图像的欠曝光区域,再用空间自适应对比度进行增强。而暗通道法最初是用于去除雾霾任务的(He等,2011),因此采用光线的透射率来区分逆光图像的前景与背景区域并不可靠。另一项工作(Li和Wu,2018)也将该问题的重点放在了分割上面,提出了一种两阶段逆光图像恢复技术,而效果也正如文中所描述的,图像的增强结果极大地依赖于分割的准确性。
一些学者采用基于融合的方法进行逆光图像增强。如Wang等人(2016)在HSV(hue, saturation, value)颜色空间的V分量上分别做对数变换、γ变换及GUM(generalized unsharp masking)处理后,再采用Mertens等人(2007)的算法进行融合。与此方法类似,Buades等人(2020)对输入图像的RGB通道分别进行对数变换和γ变换后再融合,结合后处理技术(即采用锐化手段做全局增强,再利用色彩校正方法恢复图像的色调)以达到图像增强的目的。虽然这些方法增强了图像细节,但也有一些局限性,如色彩不自然、颜色过饱和以及曝光过度等。
利用深度学习进行图像增强的任务越来越多,主要分为有监督和无监督两大类。监督网络如LLNet(low-light net)(Lore等,2017)是比较早的用深度学习方法进行低光照图像增强,该方法基于合成的成对数据训练堆叠稀疏去噪自编码器,对低光照图像进行增强和去噪。Wang等人(2019)提出了一种通过估计欠曝光图像的照度图进行增强的网络,该网络也是在成对数据上进行训练的。而应用深度学习方法进行逆光图像增强的最大问题是实际中无法收集成对的逆光图像及其对应的正常图像数据集,且目前也无合成的成对数据集。基于此,很多学者转向无监督方向的研究。如Guo等人(2020)利用一系列无需参考图像的损失函数估计出S型映射曲线来完成低照度图像的增强任务,但这种方法存在色彩偏差,且不能适应其他情况下的光照环境。Zhang等人(2019)受超分辨问题的启发(Shocher等,2018),开展了第1个采用无监督卷积网络进行逆光图像增强的工作,并设计了ExCNet(exposure correction network)网络估计出用于矫正逆光图像的两阶段S型曲线,但是它在损失函数的设定中受到灰度理论假设的限制,使得增强结果遭到光晕和灰色伪影的影响。
综上所述,无论是基于传统的方法还是基于深度学习的方法,现有的图像增强算法在解决伪影、光晕以及不同区域分别增强的问题上无法兼顾。受Guo等人(2020)提出的基于映射曲线低照度图像增强方法的启发,本文提出一种结合注意力的逆光图像深度增强方法,对以上两个方面进行改进。
1 映射曲线迭代的像素级增强方法
基于映射曲线的增强方法是利用所设计的深度学习网络学习映射曲线参数,然后利用映射学习对逆光图像进行增强,进一步对增强后的图像进行评价并利用评价结果指导网络训练。S型曲线是一种常见的映射曲线,可以调整图像中暗区域、中间调区域或是高亮区域的曝光度。Zhang等人(2019)虽然是第一个利用深度学习将S型曲线应用于逆光图像增强中的工作,但是其网络的输出只有两个优化参数(即欠曝光调节参数和过曝光调节参数),并借助该参数对将输入图像的所有像素均采用Yuan和Sun(2012)设计的映射方法得到最终的增强图像。此种方法其实还是一种全局上的映射,容易导致局部区域的增强过度或增强不够的问题。
参考Guo等人(2020)设计的映射曲线对图像进行增强,可以通过网络学习得到逆光图像中每个像素的映射参数。该映射曲线可以表达为
L(x)=I(x)+AI(x)(1-I(x))
(1)
式中,I是输入图像,I(x)表示输入图像中每个像素x处的值,并归一化到[0,1]范围,L表示增强后的图像。A是和I一样大小的映射参数图,对应输入图像中每个像素的映射系数α(α∈[-1,1])。如图2为不同映射系数下的曲线,横坐标表示原始图像的亮度值,纵坐标表示调节后图像的亮度值。当α<0时,通过调整曲线将逆光图像的过曝光区域变得更暗;当α>0时,将逆光图像的欠曝光区域变得更亮;若α=0,则表示逆光图像的亮度不发生改变,对应逆光图像中的正常曝光区域。
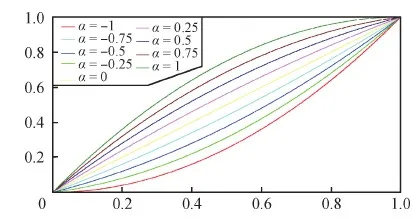
图2 不同调节参数下的映射曲线
通过迭代映射的方法可以促使曲线对各种光线情况下的逆光图像有更全面的调整能力。如图3是不同迭代次数下曲线的曲率变化。可以看出,迭代次数越高,曲线调整能力越强。此时,表达式为

图3 α=0.5时,不同迭代次数下的调整曲线
Ln(I(x))=Ln-1(I(x))+
AnLn-1(I(x))(1-Ln-1(I(x)))
(2)
式中,n表示迭代次数,该表达式的意思是将上一次增强的图像Ln-1(I(x))作为输入,通过式(1)再做一次增强即得到该次的增强结果Ln(I(x))。
将一幅逆光图像通过这种像素级的映射进行增强,可以准确地将欠曝光区域、过曝光区域以及正常曝光区域控制在合理的亮度范围内,为了估计出该映射参数,本文设计了一个基于注意力的逆光图像增强网络(attention-based backlight image enhancement network,ABIEN)。
2 本文的逆光图像增强网络
本文通过基于注意力的逆光图像增强网络(ABIEN)估计出逆光图像的映射参数,之后采用迭代映射的方式进行图像增强。为了在增强欠曝光区域的同时还能抑制过曝光区域中增强过度的问题,文中借助注意力机制来辅助网络关注这两个不同区域的增强过程;另外,为了解决大多数图像恢复工作都会出现的伪影、光晕等问题,又采用原始分辨率保留模块(raw resolution retention module,RRRM),将主网络各个层次的深度特征提取出来,并保留其原始分辨率大小,避免了由于尺度变化而影响到增强图像的效果,图4是网络的整体结构图。
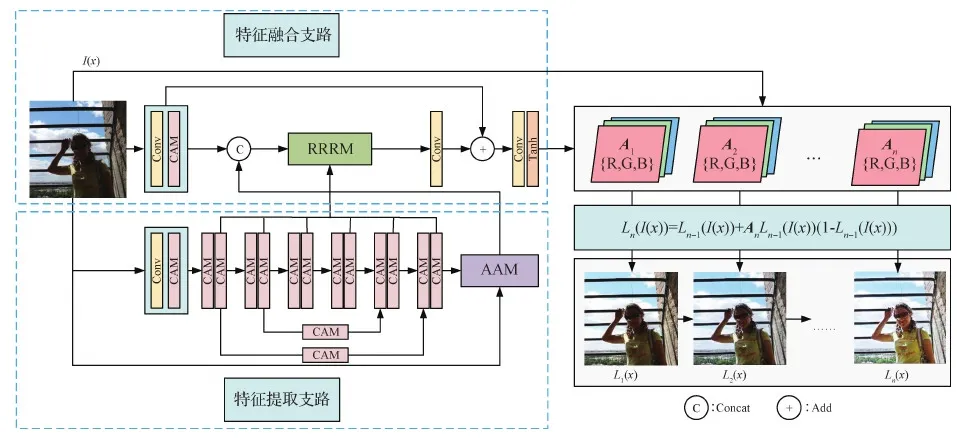
图4 基于注意力的逆光图像增强网络结构图
ABIEN网络主要分为两个支路:特征提取支路和特征融合支路。在特征提取支路中,主要采用堆叠通道注意力模块(channel attention module,CAM)的方式取代传统的卷积层,这样可以更好地帮助网络提取输入图像的特征信息。此外,由于多个CAM的堆叠,致使网络层数加深,本文通过在堆叠的CAM模块之间采用对称式的跳连接进行特征拼接,从而避免特征信息在网络深处消失的问题。之后利用辅助注意力模块(auxiliary attention module,AAM)将特征提取模块的末端输出和特征融合支路的初级特征做拼接,再与原始分辨率保留模块提取的各层特征进行融合。最后利用“卷积+Tanh激活”输出预定的映射特征图,这里的激活函数选用Tanh是因为映射参数值的范围为[-1,1]。考虑到图像的增强效果,以及对应的RGB三通道和迭代次数n=4的设置,网络的输出特征图数目为12。
2.1 注意力机制
视觉注意力机制能有效帮助定位图像中目标的位置,并且在特征图中捕获到感兴趣的区域,已广泛应用于目标识别和分类任务等多个领域之中。此外,注意力机制在图像恢复与增强领域中也有很广泛的应用,如图像去雨(Jiang 等,2021)、图像去模糊(Li 等,2020)和低照度图像增强(Shan 等,2019)等,并且都取得了很好的效果。逆光图像增强的目标就是在增强图像中欠曝光区域的同时也要防止过曝光区域过亮,因此期望通过注意力机制帮助网络在这两种区域上进行区分。
2.1.1 通道注意力模块
彩色图像本身就是多通道图像,图像的通道之间有着丰富的颜色信息,有利于图像增强任务中对图像色彩信息的恢复。因此,为了在复杂的逆光图像中捕获通道之间的关系,本文使用通道注意力机制来引导图像的增强过程。图5是ABIEN网络不同深度特征图的热力图表示。由图5可知,浅层网络的特征图在前景部分与背景部分的内容有相似的颜色,随着通道注意力模块的加深(即CAM模块),前景和背景的颜色区分愈加明显,因此,通道注意力模块可以有效帮助网络关注到逆光图像中感兴趣的特征信息。

图5 通道注意力模块对网络的影响
因为在特征提取支路需要大量堆叠的通道注意力模块(CAM),为了保留网络深层信息的传递能力,该模块的整体设计是一个残差结构。其结构如图6所示。对输入特征Fin采用“卷积+PReLU激活+卷积”处理得到初级特征F′,然后类似SE(squeeze-and-excitation)模块(Hu 等,2020),进行式(3)的处理,即

图6 通道注意力模块
(3)

(4)
式中,⊕表示像素级的加法,⊗表示像素级的乘法。
2.1.2 辅助注意力模块
辅助注意力模块(auxiliary attention module,AAM)是借助注意力机制将特征提取层中有用的信息传播至特征融合阶段。该操作主要是考虑到网络中长距离的信息交流,通过将输入以此种方式渗透到网络中,以弥补深层网络中的细节信息的丢失。如图7所示,AAM将特征提取层得到的特征Fin∈RW×H×C,作为一路输入,经过1×1卷积调整其通道数后与另一路输入的逆光图像对应位相加得到维度为W×H×3的中间特征Fm。接着用1×1的卷积和sigmoid激活函数将Fm生成与Fin维度一致的注意力图Fatt∈RW×H×C。最后,通过该注意力图进一步精炼特征图Fin,得到注意力引导的特征图Fatt_guide∈RW×H×C,该特征图可以更准确地捕捉到输入特征图中相邻像素之间重要的信息,因此将其作为学习到的内容,通过残差的形式(加法的形式)补充到输入特征Fin中,从而得到最终的输出特征Fout∈RW×H×C。

图7 辅助注意力模块
2.2 原始分辨率保留网络
传统的编码—解码网络逐步将输入的图像下采样到一定分辨率后再恢复到原始分辨率(Ronneberger等,2015)。虽然这种方法可以有效地获取多尺度信息,但由于重复使用降采样操作,容易牺牲空间特征上的细节,且这种缺点在图像恢复中的问题更为突出,经常以光晕、伪影等形式呈现(Zhang等,2021a)。因此,本文在网络设计中丢弃了传统的下采样和上采样操作,使特征图的分辨率大小保持不变。此外,为了避免这类单尺度的卷积操作造成的信息提取不充分,文中引入原始分辨率保留模块(RRRM)。该模块将特征提取层中不同深度的特征图提取出来,再利用多个CAM模块强化特征融合阶段,其结构如图8所示。考虑到训练的效率与整体增强效果,将原RRRM中CAM个数设为8。

图8 原始分辨率保留模块
2.3 损失函数
基于深度学习的逆光图像增强方法中,另一个重要的问题是没有成对的数据集对网络进行训练,因此需要一系列无需参考图像的损失函数监督ABIEN网络的训练过程。为了保证增强后的图像在曝光度、色彩以及平滑性等各方面的指标,参考Guo等人(2020)在低照度图像增强中采用的损失函数,各项损失函数如下所述。
1)曝光损失。为了约束欠曝光区域和过曝光区域的曝光程度,引入曝光损失Lexp,计算图像局部区域的平均亮度和曝光度E=0.5之间的距离,即
(5)
式中,M表示大小为16×16的非重叠局部区域个数,Yk是增强图像中局部区域的平均亮度。
2)空间一致性损失。通过计算输入图像与增强图像相邻域的差异而保持增强图像的空间一致性,即
(6)
式中,K表示局部区域的个数,局部区域的大小设置为4×4,Ω(i)表示中心像素i的四邻域。Y和I分别表示增强图像和输入图像局部区域的平均亮度值。
3)颜色恒定损失。依据灰度世界假设理论(Buchsbaum,1980),同时考虑到三通道彼此间的关系,设计颜色恒定损失来矫正增强图像中的色彩偏差,即
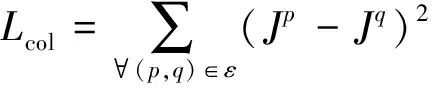
ε∈{(R,G),(R,B),(G,B)}
(7)
式中,Jp表示增强图像中通道p的平均亮度值,(p,q)表示任意一对通道。
4)光照平滑损失。为了保持相邻像素之间的单调性,在映射特征图A上引入了光照平滑损失,即

ξ∈{R,G,B}
(8)

总损失为
Ltotal=WexpLexp+WspaLspa+WcolLcol+WALA
(9)
式中,Wexp,Wspa,Wcol,WA均为损失函数的权重系数。
3 实验结果及分析
3.1 数据集
分别从CIE_XYZ(Afifi等,2020)、COCO(common objects in context)(Lin等,2014)、DICM(different images collected from multiple cameras)(Lee等,2012;Li等,2021)、ExDark(exclusively dark)(Loh和Chan,2019)、Fusion(fusion-based method)(Wang等,2016)、Li和Wu(2018)工作、LOL(low-light dataset)(Wei等,2018)、GLADNet(global illumination-aware and detail-preserving network)(Wang等,2018)、MEF(multi-exposure image fusion)(Ma等,2015)、VV(Vasileios Vonikakis)(Li等,2021)数据集中收集到符合逆光图像特点的数据集,为了尽可能接近现实中的逆光图像,该数据集中包含了各类曝光程度不一的逆光图像。最后以8∶2的比例划分为训练集和测试集。为了提高训练数据集中图像的多样性,对图像进行了随机翻转和随机亮度调整的数据增广操作,最终得到训练数据集的图像为7 125幅,测试集的图像为371幅。因为大部分的多曝光图像尺寸较大,所以将其统一裁剪为512×512像素的大小。
3.2 实验设置
实验所用的计算机设备GPU配置为NVIDIA GeForce GTX 1080,CPU配置为Intel Core i7-7700。训练所用的深度学习框架为Pytorch,batch size为8,epoch设为100,优化器选为ADAM,weight_decay设为0.000 1,学习率设为0.000 1。图9是ABIEN网络训练过程的损失值以及收敛情况。可以看出,网络大约在第5个epoch的时候损失已经降到0.85以下,有着较快的收敛速度;在第20个epoch之后,损失的波动较小,已经达到较为稳定的收敛状态。

图9 ABIEN网络的训练损失
3.3 实验结果
由于图像增强类的问题本质就是一类病态问题,并没有一种既定的标准衡量其恢复的好与坏。因此需要将主观评价和客观评价结合起来分析。
3.3.1 主观分析
为了验证本文方法的有效性,文中选择了MSRCR(multi-scale retinex with color restoration)(Jobson等,1997)、Fusion-based(fusion-based method)(Wang等,2016)、Learning-based(learning-based restoration)(Li和Wu,2018)、ExCNet(exposure correction network)(Zhang等,2019)、NPEA(naturalness preserved enhancement algorithm)(Wang等,2013)、DSLR(deep stacked Laplacian restorer)(Lim和Kim,2020)以及KinD++(kindling the darkness)(Zhang等,2021b)等算法进行比较,其中包含了传统增强方法、基于融合的方法、基于机器学习的方法以及基于深度学习的方法。
各类对比算法的主要参数设置如下:MSRCR的多尺度高斯模糊值为[15,80,200],增益为5.0,偏差为25.0;用于控制网络ExCNet增量函数的k1、k2、k3分别设置为5、14、1.6,网络的其他参数按照原文设置;Learning-based采用原文中预训练好的分割模型进行测试;Fusion-based、NPEA、DSLR和KinD++均与原文的建议参数保持一致。
图10是4幅典型的逆光图像,图11—图18中的第1行分别为通过上述几种方法以及本文方法进行增强后的图像,每幅图像的下方是其中一个局部区域放大后的图像,以便更清楚地观察到细节内容。可以看出,MSRCR方法增强后的图像主要问题在于颜色失真,增强后的图像整体亮度过高,出现增强过度的问题。而Fusion-based方法的主要问题是欠曝光区域的增强程度不够,图12的第1列和第3列增强图像中的人物面部区域较暗,五官的细节信息不够清楚;而在第2列增强图像中,裤子的条纹细节和白色鞋子处的细节信息也没有得到很好恢复。此外,正如前面分析的那样,基于分割的方法很大程度上依赖于分割的精准度,当图像内容较简单的时候效果好,而当图像内容较为复杂的时候,该类方法便不再适用。Learning-based的方法就是一类基于分割而进行图像增强的方法。从图13的增强结果中可以很明显地观察到分割痕迹。图13第1列增强图像在人物的轮廓处有一圈灰色的分割界限,而且图像的色彩也发生了严重的失真。第2列增强图像中背景的森林与天空交界处有明显的分割界限。由于分割不当,第3列增强图像的黄色衣服肩膀处以及红色衣服的手部出现了黑色斑块,在第4列图像的标语牌中也出现了严重的色块斑驳。NPEA方法在一定程度上达到了图像增强的效果,能够恢复出欠曝光区域的细节信息,但是也存在颜色失真和噪声的问题。在图14的第1列和第3列增强图像中,仔细观察人物的面部区域,可以发现人物的皮肤颜色不自然,有偏红的趋势。而第2列增强图像中人物的衣服上出现多处噪声块。基于深度学习的ExCNet方法对逆光图像有一定的增强效果,但是也存在着增强程度不够的问题,而且不可避免地出现了颜色失真的问题,如图15中第3列图像中红色衣服的肩膀处出现的彩色斑块。而DSLR和KinD++两种基于深度学习的方法主要是针对低照度图像增强任务而设计的。从图16的增强效果来看,DSLR的方法没有考虑到逆光图像不同区域需要不同程度增强的问题,不仅对欠曝光区域没有得到充分的增强作用,而且在背景部分出现了很明显的曝光过度,如图像1—3的天空区域。KinD++虽然在图像的整体亮度上得到了不少的提升,但是增强图像出现了模糊和颜色不自然的问题,在图17的第1列和第3列增强结果中人物的面部轮廓呈现出虚化现象,且肤色不正常,同时第2列图像的衣服上也有颜色斑驳的问题。相较而言,本文方法在增强了欠曝光区域的前提下,过曝光区域也没有出现过度增强的问题。纵向对比第4列逆光图像通过各种方法得到的增强结果来看,本文方法增强后的标语牌白色背景很干净,文字信息也很清楚,所以本文方法在图像细节信息的恢复方面非常好。此外,经过各项对比发现,本文方法在颜色失真、噪声干扰以及光晕、伪影等方面也有很好的抑制作用。

图10 逆光图像

图11 MSRCR方法增强后的结果

图12 Fusion-based方法增强后的结果

图13 Learning-based方法增强后的结果

图14 NPEA方法增强后的结果

图15 ExCNet方法增强后的结果

图16 DSLR方法增强后的结果

图17 KinD++方法增强后的结果
3.3.2 客观分析
图像质量评价与人类视觉系统有关,目前还没有一种通用的方法来满足图像增强的主观效果,针对逆光图像增强任务,将几个评价指标结合起来进行分析。
由于增强图像中产生的光晕、伪影、轮廓线和振铃等问题容易引起图像亮度顺序统计量的改变,为此引入LOE(luminance ordinal distortion)(Wang等,2013)指标来评价,LOE值越小代表恢复效果越好。VLD(visibility level descriptor)(Hautière等,2008)通过计算图像恢复前后的可见边缘梯度比值,得到图像能见度指标,VLD值越高表明图像的整体视觉质量越高。CDIQA(contrast-distorted image quality assessment)(Liu和Li,2020)是一种无参考的图像质量度量标准,它反映了因为对比度失真影响到自然图像统计特性,进而影响图像感知质量的问题。CDIQA可以看做是评价图像内容丰富度的指标,越高的CDIQA值表示图像的质量越好。另外,处理时间也是一项重要指标,在很多现实场景应用中要求程序的运行速度足够快,以达到实时处理的需求。
鉴于DSLR(Lim和Kim,2020)和KinD++(Zhang等,2021b)是针对低照度图像增强任务所设计的网络,其增强图像中出现的问题在主观对比结果中显而易见,因此下面只针对逆光图像增强方法进行客观指标比较。表1给出了MSRCR(Jobson等,1997)、Fusion-based(Wang等,2016)、Learning-based(Li和Wu,2018)、NPEA(Wang等,2013)、ExCNet(Zhang等,2019)以及本文方法在处理371幅测试图像后,计算得到的LOE、VLD、CDIQA以及处理时间的平均值。可以看到,本文方法在LOE指标上取得最优,这和主观比较中得到的结果一致,即本文方法在抑制增强图像的伪影、光晕等问题上很有优势。而且本文方法在描述图像内容的能见度指标(VLD)中排名第2,表明本文方法在增强逆光图像的细节信息方面也有很好的效果。虽然Learning-based在VLD指标上排名第1,但是结合图13的主观图像效果对比,发现该方法的增强图像均产生了严重的分割界限和颜色失真的问题,因此在计算伪影的LOE指标中,该方法取得的效果很差。在对比度失真指标CDIQA中,本文方法仅次于Fusion-based,表明本文方法在增强逆光图像的同时,也保留了图像色彩的保真度,而Fusion-based的主要问题在于对欠曝光区域的增强程度不够,不能满足对逆光图像增强的要求。

表1 不同方法增强效果的客观比较
为了客观评价各方法的处理效果,实验中使用了各方法提供的处理代码,其编程语言及运行环境不同。其中,Fusion-based、Learning-based和NPEA使用MATLAB语言,在CPU上计算;MSRCR和ExCNet使用Python语言,运行于CPU上;本文方法使用Python语言,在GPU上计算得到。虽然由于编程语言与运行环境不同,导致无法准确客观地比较各方法的运行时间,但从表1可以看出,本文方法的处理速度非常快,具有一定的时间优势。
综合以上分析,可以看出本文方法在增强逆光图像的同时保证了尽量少的失真,该方法不仅可以恢复出图像的细节信息,还能有效抑制恢复任务中经常出现的伪影、偏色及光晕等问题。另外,本文方法的处理速度较快,有希望在实际场景中应用于实时图像增强任务。
4 结 论
针对逆光图像增强任务中出现的欠曝光区域和过曝光区域增强不合理以及增强图像易出现光晕、伪影及偏色等问题,本文结合注意力机制,提出了一种零参考图像下的逆光图像增强的深度学习网络。该方法通过注意力机制帮助网络关注逆光图像中欠曝光区域和过曝光区域的增强过程,同时采用原始分辨率保留网络消减图像增强时容易出现的光晕和伪影等问题,最后利用网络学习到的映射参数,对逆光图像进行迭代映射以达到增强效果。将本文方法与现有的一些图像增强方法进行对比,结果表明本文方法不仅有效地提高了逆光图像的视觉质量,而且还避免了颜色失真、光晕和伪影等现象的出现。在客观评价方面,与其他方法相比,本文方法在各类指标中都有相对较高的提升。但是在实验结果中发现,如果逆光图像中欠曝光区域的亮度过暗,恢复的效果还有待进一步改进。不过这个问题在现有的方法中普遍存在,因此在接下来的任务中将会针对这类有挑战的问题继续进行深入探究。
参考文献(References)
Afifi M, Abdelhamed A, Abuolaim A, Punnappurath A and Brown M S.2020.CIE XYZ net: unprocessing images for low-level computer vision tasks[EB/OL].[2021-06-23].https://arxiv.org/pdf/2006.12709.pdf
Buades A, Lisani J L, Petro A B and Sbert C.2020.Backlit images enhancement using global tone mappings and image fusion.IET Image Processing, 14(2): 211-219[DOI: 10.1049/iet-ipr.2019.0814]
Buchsbaum G.1980.A spatial processor model for object colour perception.Journal of the Franklin Institute, 310(1): 1-26[DOI: 10.1016/0016-0032(80)90058-7]
Guo C L, Li C Y, Guo J C, Loy C C, Hou J H, Kwong S and Cong R M.2020.Zero-reference deep curve estimation for low-light image enhancement//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Seattle, USA: IEEE: 1777-1786[DOI: 10.1109/CVPR42600.2020.00185]
Hautière N, Tarel J P, Aubert D and Dumont É.2008.Blind contrast enhancement assessment by gradient ratioing at visible edges.Image Analysis and Stereology, 27(2): 87-95[DOI: 10.5566/ias.v27.p87-95]
He K M, Sun J and Tang X O.2011.Single image haze removal using dark channel prior.IEEE Transactions on Pattern Analysis and Machine Intelligence, 33(12): 2341-2353[DOI: 10.1109/TPAMI.2010.168]
Hu J, Shen L, Albanie S, Sun G and Wu E H.2020.Squeeze-and-excitation networks.IEEE Transactions on Pattern Analysis and Machine Intelligence, 42(8): 2011-2023[DOI: 10.1109/TPAMI.2019.2913372]
Im J, Yoon I, Hayes M H and Paik J.2013.Dark channel prior-based spatially adaptive contrast enhancement for back lighting compensation//Proceedings of 2013 IEEE International Conference on Acoustics, Speech and Signal Processing.Vancouver, Canada: IEEE: 2464-2468[DOI: 10.1109/ICASSP.2013.6638098]
Jiang K, Wang Z Y, Yi P, Chen C, Han Z, Lu T, Huang B J and Jiang J J.2021.Decomposition makes better rain removal: an improved attention-guided deraining network.IEEE Transactions on Circuits and Systems for Video Technology, 31(10): 3981-3995[DOI: 10.1109/TCSVT.2020.3044887]
Jobson D J, Rahman Z and Woodell G A.1997.A multiscale retinex for bridging the gap between color images and the human observation of scenes.IEEE Transactions on Image Processing, 6(7): 965-976[DOI: 10.1109/83.597272]
Kim N, Lee S, Chon E, Hayes M H and Paik J.2013.Adaptively partitioned block-based backlit image enhancement for consumer mobile devices//Proceedings of 2013 IEEE International Conference on Consumer Electronics.Las Vegas, USA: IEEE: 393-394[DOI: 10.1109/ICCE.2013.6486944]
Lee C, Li C and Kim C S.2012.Contrast enhancement based on layered difference representation//Proceedings of the 19th IEEE International Conference on Image Processing.Orlando,USA: IEEE: 965-968[DOI: 10.1109/ICIP.2012.6467022]
Li C Y, Guo C L, Han L H, Jiang J, Cheng M M, Gu J W and Loy C C.2021.Low-light image and video enhancement using deep learning: a survey[EB/OL].[2021-11-05].https://arxiv.org/pdf/2104.10729.pdf
Li X G, Yang F F, Lam K M, Zhuo L and Li J F.2020.Blur-Attention: a boosting mechanism for non-uniform blurred image restoration[EB/OL].[2021-08-18].https://arxiv.org/pdf/2008.08526.pdf
Li Z H and Wu X L.2018.Learning-based restoration of backlit images.IEEE Transactions on Image Processing, 27(2): 976-986[DOI: 10.1109/TIP.2017.2771142]
Lim S and Kim W.2020.DSLR: deep stacked Laplacian restorer for low-light image enhancement.IEEE Transactions on Multimedia, 23: 4272-4284[DOI: 10.1109/TMM.2020.3039361]
Lin T Y, Maire M, Belongie S, Bourdev L, Girshick R, Hays J, Perona P, Ramanan D, Zitnick C L and Dollar P.2014.Microsoft COCO: common objects in context[EB/OL].[2021-06-21].https://arxiv.org/pdf/1405.0312.pdf
Liu Y T and Li X.2020.No-reference quality assessment for contrast-distorted images.IEEE Access, 8: 84105-84115[DOI: 10.1109/ACCESS.2020.2991842]
Loh Y P and Chan C S.2019.Getting to know low-light images with the exclusively dark dataset.Computer Vision and Image Understanding, 178: 30-42[DOI: 10.1016/j.cviu.2018.10.010]
Lore K G, Akintayo A and Sarkar S.2017.LLNet: a deep autoencoder approach to natural low-light image enhancement.Pattern Recognition, 61: 650-662[DOI: 10.1016/j.patcog.2016.06.008]
Ma K D, Zeng K and Wang Z.2015.Perceptual quality assessment for multi-exposure image fusion.IEEE Transactions on Image Processing, 24(11): 3345-3356[DOI: 10.1109/TIP.2015.2442920]
Mertens T, Kautz J and Van Reeth F.2007.Exposure fusion//Proceedings of the 15th Pacific Conference on Computer Graphics and Applications.Maui,USA: IEEE: 382-390[DOI: 10.1109/PG.2007.17]
Ronneberger O, Fische P and Brox T.2015.U-Net: convolutional networks for biomedical image segmentation//Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention.Munich, Germany: Springer: 234-241[DOI: 10.1007/978-3-319-24574-4_28]
Shan C W, Zhang Z Z and Chen Z B.2019.A coarse-to-fine framework for learned color enhancement with non-local attention//Proceedings of 2019 IEEE International Conference on Image Processing.Taipei, China: IEEE: 949-953[DOI: 10.1109/ICIP.2019.8803052]
Shocher A, Cohen N and Irani M.2018.Zero-shot super-resolution using deep internal learning//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City,USA: IEEE: 3118-3126[DOI: 10.1109/CVPR.2018.00329]
Wang Q H, Fu X Y, Zhang X P and Ding X H.2016.A fusion-based method for single backlit image enhancement//Proceedings of 2016 IEEE International Conference on Image Processing.Phoenix,USA: IEEE: 4077-4081[DOI: 10.1109/ICIP.2016.7533126]
Wang R X, Zhang Q, Fu C W, She X Y, Zheng W S and Jia J Y.2019.Underexposed photo enhancement using deep illumination estimation//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Long Beach, USA: IEEE: 6842-6850[DOI: 10.1109/CVPR.2019.00701]
Wang S H, Zheng J, Hu H M and Li B.2013.Naturalness preserved enhancement algorithm for non-uniform illumination images.IEEE Transactions on Image Processing, 22(9): 3538-3548[DOI: 10.1109/tip.2013.2261309]
Wang W J, Wei C, Yang W H and Liu J Y.2018.GLADNet: low-light enhancement network with global awareness//Proceedings of the 13th IEEE International Conference on Automatic Face and Gesture Recognition.Xi′an, China: IEEE: 751-755[DOI: 10.1109/FG.2018.00118]
Wei C, Wang W J, Yang W H and Liu J Y.2018.Deep retinex decomposition for low-light enhancement[EB/OL].[2021-08-14].https://arxiv.org/pdf/1808.04560.pdf
Yuan L and Sun J.2012.Automatic exposure correction of consumer photographs//Proceedings of the 12th European Conference on Computer Vision.Florence, Italy: Springer: 771-785[DOI: 10.1007/978-3-642-33765-9_55]
Zhang L, Zhang L J, Liu X, Shen Y, Zhang S M and Zhao S J.2019.Zero-shot restoration of back-lit images using deep internal learning//Proceedings of the 27th ACM International Conference on Multimedia.Nice, France: ACM: 1623-1631[DOI: 10.1145/3343031.3351069]
Zhang Y H, Guo X J, Ma J Y, Liu W and Zhang J W.2021b.Beyond brightening low-light images.International Journal of Computer Vision, 129(4): 1013-1037[DOI: 10.1007/s11263-020-01407-x]
Zhang Y L, Tian Y P, Kong Y, Zhong B N and Fu Y.2021a.Residual dense network for image restoration.IEEE Transactions on Pattern Analysis and Machine Intelligence, 43(7): 2480-2495[DOI: 10.1109/TPAMI.2020.2968521]
猜你喜欢
农业工程学报(2022年13期)2022-10-09
航天返回与遥感(2022年2期)2022-05-12
小雪花·成长指南(2022年1期)2022-04-09
照相机(2019年10期)2019-09-10
通信产业报(2017年38期)2017-11-07
计算机应用(2016年10期)2017-05-12
中华建设科技(2016年11期)2017-01-06
第二课堂(课外活动版)(2016年2期)2016-10-21
摄影世界(2014年4期)2014-07-04
旅游纵览(2014年7期)2014-01-19
