
低光照图像增强算法综述
2022-05-23 03:55马龙马腾宇刘日升
中国图象图形学报 2022年5期
马龙,马腾宇,刘日升
1.大连理工大学软件学院,大连 116024; 2.鹏程实验室,深圳 510852;3.大连理工大学—立命馆大学国际信息与软件学院,大连 116024
0 引 言
随着人工智能技术引起的全方位变革,真实场景下的感知需求日益迫切。图像作为感知世界的重要媒介,其质量往往决定了算法的性能。然而在图像捕获过程中,往往存在多种不可控的物理因素,导致图像质量受损,进而影响了高层视觉任务应用过程中信息的获取与利用,如人脸识别(叶学义 等,2019)、语义分割(翟鹏博 等,2020)等。在多种影响图像质量的因素当中,低光照因素较为常见且难以避免,例如阴天、夜晚等场景。
为了在低光照环境下获得肉眼可见且信息丰富的高质量图像,一种直接的方式是通过物理成像过程的参数设置来提高成像质量。延长成像设备的曝光时间是最常用的手段(Chen等,2018a),然而由于在成像过程中相机抖动或者物体移动等运动过程的存在,曝光时间的延长不可避免地会造成图像产生模糊。提高ISO(International Standardization Organization)是另一种常用手段,尽管图像亮度可以显著提升,但噪声也会随之出现。使用闪光灯或者外置灯光也是一种常用技巧,但是由于光的不均匀现象,会引起色彩不自然等问题。总体来说,单纯依赖物理成像过程的调整依然难以获得理想的图像。因此构建智能化算法以提升图像质量,已成为低光照图像增强领域的研究热点之一。
图1展示了不同场景下的低光照图像,从人眼的观测角度来看,几乎无法获取到有价值的信息,尤其是对于极具挑战的例子而言。事实上对于计算机而言,在这些肉眼不可见的矩阵数据中,其数值上存在的差异性是反映图像信息的关键。换言之,人眼不可见只是片面的感受,而计算机能够从图像的数值分布层面的差异和联系出发,对图像有更加清晰的认知。总之,如何利用机器学习算法实现肉眼可见的信息转换是现有低光照图像增强技术的基本目的。

图1 低光照图像示例
根据算法设计理念不同,现有的低光照图像增强算法可分为3类,即基于分布映射的方法,基于模型优化的方法和基于深度学习的方法。其中,基于分布映射的方法关注低光照观测的像素分布情况,致力于利用曲线变换、直方图均衡化等手段改善图像的像素分布,从而提高图像亮度与清晰度。此种类型技术与问题本身的成像过程无关,是人工智能技术发展早期解决一般图像处理问题的常用方式,如图像去雾等。由于缺乏对于低光照图像自身对于光照需求的建模以及忽略了分布内在的联系,以致于无法有效区分语义,进而导致该类技术生成的结果往往存在颜色失真以及细节异常等视觉不友好的现象。基于模型优化的方法隶属于经典的图像处理技术范畴,其核心在于以物理成像规律导出的数据项作为基本成分,以设计刻画目标变量的正则项作为关键,并进一步利用现有的优化技术进行求解获得基于迭代的算法流程。然而,限于设计的先验的刻画能力,这些传统算法往往会产生曝光不足、色彩不饱和以及伪影或噪声明显的问题。
为了克服上述传统方法的弊端,受大数据时代的影响,通过启发式设计网络结构建立低光照输入与增强输出之间的关系,已成为一种主流的低光照图像增强模式。对于网络结构而言,训练数据的获取至关重要,这也正是深度学习技术不断发展迭代更新的基石。对于多种常规的图像处理问题,利用物理退化模型合成数据是提供有效训练数据对的最常见方法。然而,在低光照图像增强任务中,光照是其核心降质因素,但其原理复杂,很难通过手工合成获得。通过调整曝光时间以在实际场景中获取低与高曝光图像对是一种获取数据的方式,通过邀请领域专家对捕获的低对比度、色彩不饱和的图像进行修饰,以获取高质量的高曝光图像是另外一种常用的数据集构造手段。研究者们还开发了一些仅有低光照图像的数据集用于支撑基于深度学习方法的发展。基于以上数据集,多种端到端的深度学习技术被设计来解决低光照图像增强任务。其中,引入特定任务的物理原理和先验正则项成为网络结构设计的主流思想。最具代表性的数据驱动型深度网络构建了“三阶段”架构。首先通过分解网络粗略估计了初始光照和反射,然后分别采用设计的架构进一步优化了这两个组件,但是,这种方式容易引起过度曝光现象,因此Retinex理论被进一步考虑以解决过曝问题。然而实际上,该过程严格执行基于模型优化的求解步骤,忽略了深度网络自身的强大推理能力。此外一些工作致力于构建低光照输入与清晰图像之间的显式连接,由于缺乏对于物理规律的利用,往往不可避免地产生其他衍生的影响视觉质量的因素。
总体而言,现有的低光照图像增强技术的发展过程有迹可循,百花齐放,但仍存在诸多问题尚待解决,因此有必要进行全面的综述以及讨论。本文系统地描述并分析了现有的低光照图像增强技术的研究进展和面临的技术挑战,希望能够对低光照图像增强技术的发展提供帮助,并期待启发相关领域研究人员诞生更多创新型的研究工作。
1 低光照图像增强数据集
现有的低光照图像增强数据集大致遵循数据规模从小到大、场景类型从单一到多样、数据难度从简单到复杂的规律,如表1所示。

表1 低光照图像增强数据集总结
发展早期,大部分低光照图像增强技术聚焦于研究一些小规模的数据集,如NASA(National Aeronautics and Space Administration),LIME(low-light image enhancement),NPE(naturalness preserved enhancement),MEF(multi-exposure image fusion),DICM(digital cameras),VV(Vasileios Vonikakis)等(部分示例见图2)。由于数据集规模比较小,同时缺乏对应的标签,因此早期在这些数据集上的研究普遍属于与数据无关的基于模型优化的方法。直至近几年,一些较大规模的低光成对数据的提出,开始推动深度学习的发展,其中代表性的工作当属2018年推出的SID-RAW(see-in-the-dark dataset)数据集(Chen等,2019),由于该数据集考虑的是RAW类型,即未经过ISP(image signal processing)处理的数据,为研究低光照图像增强技术提供了坚实的数据支撑,进而引起了工业界对于该问题的浓厚兴趣。此外,该数据集的构造过程也促使一些RGB域的成对数据产生,如LOL,LSRW等成对的数据集(部分示例见图3)。

图2 部分非成对低光数据集中的低光照图像示例

图3 部分成对低光数据集中的低光照图像示例
一个不可忽视的问题在于,现有成对数据的产生,不可避免地需要人工参与,所得到的标签往往不够理想,使得算法性能受限。具体来说,现有成对数据普遍通过手工控制曝光时间来得到低光照与正常光照数据,而时间变化,环境光照会随之产生变化,从而产生颜色偏差等问题。换句话说,现有成对数据集的参考图像往往难以精准表现低光照观测捕获时的场景信息。上述问题进而影响了采样成对数据进行训练的深度网络的表现性能。
总的来说,现有低光照数据集多数是在真实场景下采集的仅包含低光照观测的数据,而少数具有成对参考图像的数据集,其标签往往受到一些不可避免的物理因素影响,使得标签不精确。从数据集的发展情况来看,相比于其他图像处理问题(如图像去噪(Pang等,2021)、超分辨率(Brifman等,2019)和图像去雨(Huang等,2021)等),理想的成对低光照数据集由于物理建模过程复杂难以通过合成方式获取。而且由于数据是基于深度学习技术发展的关键,因此低光照图像增强的深度学习技术的发展相对滞后,如何充分挖掘真实数据本身的潜在特性以打破对于成对数据的依赖,是现有基于深度学习的低光照图像增强技术发展的关键。
2 低光照图像增强方法
如何增强低光照图像已引起了学术界和工业界的广泛关注。例如国内某厂商在2019年其旗舰手机的发布会上将夜间环境下的拍摄能力作为主打亮点,并随之引起多家厂商的争相效仿,一定程度上推动了低光照图像增强技术的发展。截止目前,现有的低光照图像增强技术可粗略分为基于分布的映射、基于模型优化和基于深度学习的3类方法。近几年得益于深度学习技术的井喷式发展,最后一种数据驱动的深度学习技术已成为当前解决低光照图像增强问题的主流。本文将进行细致而全面的研究现状及发展动态分析。
2.1 基于分布映射的方法
映射低光照输入的分布以放大较小的值(显示为暗)是解决低光照图像增强的一种最直观的思路。直方图均衡化和基于S型曲线的方法是此类方法的两种代表性工作。常规的直方图均衡化方法(Cheng和Shi,2004)生成结果往往会存在曝光不当、细节损失和颜色失真等问题。为此,设计了一系列基于直方图均衡化的改进版本以改善上述缺点。例如,Kim(1997)开发了双直方图均衡化方法,Wang等人(1999)设计了二元子图像直方图均衡化方法来实现曝光的自然化处理。为了处理细节损失,Pizer等人(1987)构造了自适应直方图均衡方法,Pisano等人(1998)设计了对比度自适应的直方图均衡化方法。然而,由于分布映射过程中缺乏对于语义信息的识别与利用,现有的基于分布映射的方法仍然存在颜色失真等影响增强结果观感的现象。
伽玛校正是最著名的基于S型曲线的图像亮度校正技术之一,它具有映射亮度水平以补偿显示设备的非线性亮度的功能。然而对于低光照图像增强而言,伽马校正的增强结果极其不自然且不真实,尤其是在曝光水平和细节表现上。为了克服这些问题,一系列改进版本相继提出。在Bennett和McMillan(2005)的方法中,使用双边滤波分解低光观测,随后采用不同参数设置的S型曲线方法处理分解层,并进行重新组合。Yuan和Sun(2012)提出试图对通过分割输入而生成的每个子区域执行S型曲线功能。总体而言,现有的基于S型曲线的方法,曝光不均匀现象仍然是存在的最大的问题。
2.2 基于模型优化的方法
Retinex理论(Land和McCann,1971)为增强弱光图像的过程提供了直观的物理描述。该理论假设可以通过去除低光输入的光照来获得期望的正常图像(即反射图)。Retinex理论表明低光照图像与正常图像存在点除关系,其中正常图像可通过低光照图像点除根据低光照图像生成的光照图像获得。
Jobson等人(1997)基于Retinex理论进行了一些基本的尝试,通过引入滤波器进行光照的估计,但获得了不符合真实自然图像分布的结果,出现了未知的伪影以及色偏等现象。为提升增强性能,Wang等人(2013)提出了一种低光照图像增强算法并设计了一种全新的评估指标,然而该方法性能不稳定,时常会出现细节缺失和亮度不足现象。随着研究的深入,以Retinex模型为数据项,一系列的工作聚焦于设计针对Retinex模型中的变量的正则约束项来辅助估计精确的目标变量。早期,Fu等人(2015)建立了一个基于MAP(maximum a posteriori)的能量模型,该模型针对不同层定义了不同的先验约束。他们还提出了基于对数域的加权变分模型,用于同时估算光照和反射(Fu等,2016)。这些工作的主要问题在于,由于设计的先验过于简单,导致大量未知伪影的出现。Cai等人(2017)设计了一个联合内在和外在的先验模型用于优化光照和反射,但该方法倾向于产生亮度不足的结果。
考虑到在一些复杂场景下,噪声和伪影始终伴随着增强过程,因此Li等人(2018a)构建了一种基于Retinex的联合低光照增强和去噪的模型,并通过定义不同的先验约束来建立优化目标。然而,由于先验约束不强以及复杂的求解过程,这项工作时常会产生过度平滑和亮度不足的结果。为克服上述问题,一系列的联合亮度增强和噪声去除的工作相继提出。Ren等人(2020)设计了一种低秩正则化Retinex模型LR3M(low-rank regularized Retinex model),首次将低秩先验应用于Retinex分解过程以抑制噪声,通过时序间的低秩构造,该方法还成功地应用于低光照视频增强问题,并取得优异性能。进一步地,Kong等人(2021)提出了一种泊松噪声感知Retinex模型,首次考虑采用泊松分布来定义Retinex驱动的保真项,并构建泊松噪声分布先验来实现噪声抑制,成功实现了在去除噪声的同时图像结构信息的保留。Xu等人(2020a)构建了一种结构和纹理感知的Retinex模型,以明确区分光照与反射的梯度,并通过交替优化以及矢量化最小二乘技术导出关于两个目标变量的闭形式解。Hao等人(2020)提出了一种半解耦方式进行Retinex分解的高斯全变分模型,用于同时提高亮度和抑制噪声。Ren等人(2019a)通过结合相机响应模型与基于光照的曝光率估计,提出了一种利用相机响应特性的低光照图像增强框架。
随着研究的深入,研究者们发现采用Retinex模型来实现亮度提升的关键在于光照层估计,沿着该思路,一系列着重于设计光照正则项的工作相继提出。Guo等人(2017)构建了第1个只考虑对光照进行建模并求解的工作,所提出方法命名为LIME,通过使用保留边缘的平滑方法RTV(relative total variation)(Xu等,2012)优化了从输入得到的初始光照。不可否认的是,该项工作取得了显著的性能,亮度突出且结构明显。但是在大多数情况下会出现曝光过度的现象。为解决LIME存在的过曝现象,Zhang等人(2018,2020a)从不同角度引入了一系列的光照约束,成功地将过曝现象解决,但由于引入更多的正则项约束,导致算法求解过程复杂,其推理速度显著变慢。
总体而言,对于以上基于模型优化的方法,如何设计先验正则项是大部分工作的核心,其设计过程往往依赖于一系列对于现实环境的假设条件,先验表征能力有限。此外,已有工作始终需要针对实际情况进行手动调整诸多模型参数。因此这些基于模型的工作无法在某些具有挑战的场景中实现一致优异的性能。更重要的是,基于模型优化的方法往往使用迭代过程,因此相对耗时,不利于实际应用。
2.3 基于深度学习的方法
深度学习已被广泛证明其在许多低级视觉任务中的优势(Yasarla等,2021;Wu等,2021a)。与其他常规视觉任务不同,利用深度网络解决低光照图像增强问题仍然不够成熟。核心难点在于缺乏有效的训练数据对。直到研究人员开发了一系列具有弱光输入和正常曝光标签的成对数据集,进而推动了低光照图像增强深度网络技术的发展。基于深度学习的低光照图像增强方法起始于2017年,随后渐渐成为低光照图像增强的主流方法。总体而言,从实现目的来看,基于深度学习的低光照图像增强方法能够粗略地分为两类,用于亮度增强的方法以及联合亮度增强与噪声去除的方法。以下将从这两方面展开详细介绍。
1)用于亮度增强的方法。低光照图像增强的一个核心任务在于提升图像亮度以显示更多结构与细节,因此一系列专注于亮度增强的工作相继提出。早期的工作由于成对数据的匮乏,普遍采用合成数据的方式来进行深度网络的训练。Shen等人(2017)将卷积神经网络与Retinex理论相结合,将多尺度Retinex看做是具有跳跃链接或者是残差形式的级联高斯卷积,设计出一个多尺度的卷积神经网络MSR-net(multi-scale Retinex network),并基于Photoshop处理后的成对数据获得端对端低光照图像增强网络。网络中采用对数变换的方式将Retinex模型由相乘的形式转换为相加。由于对数变换会抑制亮区域梯度的变化,该方法容易引起细节丢失。Li等人(2018b)提出了一种用于低光照图像增强的卷积神经网络(LightenNet)。他们通过基于Retinex理论创建的训练对来训练设计的网络结构,但是该方法仍然难以获得令人满意的增强效果,尤其是在一些有挑战性的真实场景。Tao等人(2017)和Lyu等人(2020)尝试将图像融合应用于低光照图像增强方法中。在网络结构中,将多个尺度特征注入到多分支体系结构中,将多个阶段的特征进行融合,形成较好的增强效果,但该方法对于一些光照极其不足的场景性能较差。Cai等人(2018)致力于低光照图像对比度的调整,并构建了一个低对比度和高对比度的图像对训练数据集,使用卷积神经网络训练对比度增强网络。尽管该方法能够有效提升图像亮度,但是会出现一些未知的伪影以及过于细化的细节进而造成图像失真。Wang等人(2019a)在原始端对端网络估计的基础上,引入了中间光照估计,将输入与预期的增强结果相关联,从而增强了网络对复杂图像的调整能力。此外,采用了与MIT-Adobe FiveK(Bychkovsky等,2011)类似的策略来生成成对训练数据。事实上这项工作使用了HDRNet(high dynamic range network)(Hasinoff等,2016)中的部分体系结构,并定义了3种不同的损失函数来解决低光照图像增强。实际上基于MIT-Adobe FiveK,已经有一系列面向曝光控制的工作相继提出,如Hu等人(2018)通过结合强化学习与分辨率无关的滤波器提出WhiteBox,以解决自动照片的后期处理。Chen等人(2018b)首先构造了一个全局特征增强的U-Net架构,并采用Wasserstein GAN(generative adversarial network)训练机制,随后引入自适应加权机制确保了更快的收敛速度。Yu等人(2018b)将深度强化对抗学习引入到低光照图像增强任务中。根据低光照图像原始的低层次特征,将图像分割成能够反映曝光动态范围变化的子图像。在子图像上通过政策网络顺序自动学习每个子图像的局部曝光,以达到整体曝光的平衡。此外,一些工作关注于如何在确保算法计算效率的前提下增强图像亮度。Lyu等人(2020)侧重于方法效率的提升,提出了一种轻量化、速度快的低光照图像增强模型,该模型可以部署到移动端上。Li等人(2021c)为了简化模型复杂的网络结构和沉重的计算负担,提出了一种轻量级且高效的高亮度感知金字塔网络(luminance-aware pyramid network,LPNet),按照由粗到细的策略重建正常光照图像。Ma等人(2020)受传统的多尺度Retinex启发,构造了一种轻量化的残差网络学习多尺度Retinex用于低光照图像增强。
2)联合亮度增强与噪声去除的方法。以上提及的低光照图像增强算法着重于对于亮度的提升,忽略了对于一些恶劣场景下捕获图像存在的噪声问题。为提供更高的视觉质量,现有的主流工作将同时实现亮度增强与噪声去除作为低光照图像增强的核心。Lore等人(2017)设计了一种低光照网络(low-light net,LLNet)深度自动编码器,在提高低光照图像对比度的同时兼顾去噪。但由于合成数据的不真实性,导致这种方法增强后的图像会不符合实际,且存在曝光不足的问题。Chen等人(2018a)针对夜间成像问题,构建了一个不同程度曝光的数据集,其中包含对应的短(可能带噪声)/长曝光图像对。基于该数据集,训练了一个端到端的低光照图像增强卷积神经网络模型,且该方法直接对RAW数据进行操作,该数据集的开发显著推动了低光照图像增强在工业界的应用。
一系列工作基于传统模型中的Retinex关键理论设计网络结构,以赋予算法从模型中导出的泛化能力。Chen等人(2018c)开发了基于Retinex的低光照图像增强网络(RetinexNet)。网络由两部分组成,分别是光照估计和反射层估计模块,进而实现同时估算光照和反射。此外,为满足网络训练的需求,Chen等人(2018c)还建立了一个通过更改曝光时间获得的带合成噪声的全新数据集(即LOL(low-light paired dataset)数据集)。尽管该方法能够有效提升图像亮度,但是会出现一些未知的伪影以及过于细化的细节进而造成图像失真,其本质原因在于对于中间变量的约束不足。进一步地,Zhang等人(2019,2021)提出了一种简单有效的低光照图像增强网络(kindling the darkness: a practical low-light image enhancer,KinD)。该网络框架与RetinexNet架构类似,核心在于引入了更多的训练损失约束。Wang等人(2019b)基于Retinex的方法考虑解耦,提出了一种新的渐进式Retinex框架,使用相互增强的方式感知低光照图像的光照和噪声。在网络结构设计上,采用了两个卷积神经网络模拟环境光和图像噪声的统计规律,并以此作为约束来促进相互学习。不过该方法所考虑的场景不够恶劣,亮度情况不够差,因此限制了其应用空间。Zhang等人(2020c)提出了一种受Retinex原理启发的多聚合网络来同时实现光照增强和噪声去除。通过建立一个开创性的原理启发连接,将物理原理呈现在网络内部,以加强结构描绘。Wang等人(2020)将低光照图像增强问题看做是一个残差学习的问题,即估计低光照和正常光照之间的残差。为了估计出残差光照,在网络结构中通过光照反向映射(lightening back-projection,LBP)迭代地执行增亮和变暗过程。
除了关注于网络结构的启发式设计以外,一部分工作考虑引入额外信息来辅助实现低光照图像增强。Ren等人(2019b)设计了一个具有内容和边缘流的混合网络,以恢复更准确的场景内容,并在带噪声的合成数据训练,以实现亮度增强与噪声去除。然而由于合成数据的问题,该方法时常会产生模糊面纱的问题。Fan等人(2020)将额外的先验信息引入低光照图像增强任务中。该方法将语义分割网络与Retinex方法相结合,将语义分割的结果直接作用于反射层估计网络,间接作用于低光照图像增强。除了使用语义标签之外,Zhu等人(2020)将图像的边缘信息引入到低光照图像增强网络中,提出了一种边缘增强多重曝光融合网络。该方法采用两阶段方式,第1阶段对低光照图像进行初步增强,提高图像的对比度的同时解决了颜色偏差的问题;在第2阶段引入了一个边缘增强模块,在边缘信息的帮助下细化增强图像的质量。Zhu等人(2021)构建了一种高效的协同式反射与光照学习框架,通过在特征空间应用Retinex导出的反射与光照的物理关系,显著降低了网络参数,实现了高效的低光照图像增强。Zhao等人(2021)提出深度对称网络,通过采用可逆神经网络进行图像之间的双向特征学习,并引入循环残差注意力模块以校正颜色偏差。
此外也存在一些利用其他新颖技术来实现联合亮度增强与噪声去除的工作。Zhu等人(2020)提出了一种新颖的三分支卷积神经网络。与之前基于Retinex的方法略有不同,该网络将图像分解为3个分量,分别是光照、反射和噪声。在网络训练过程中,通过使用迭代最小化损失函数进行权重更新。Lim和Kim(2021)利用拉普拉斯金字塔在图像空间和特征空间中的有用性,提出了一种称为深度堆叠拉普拉斯恢复(deep stacked Laplacian restorer,DSLR)的方法。该方法能够同时生成用于亮度提升的光照信息和用于结构增强的细节信息,并在图像空间中逐步整合光照和细节信息。由于特征空间中定义的拉普拉斯金字塔基于多尺度结构中高阶残差的丰富连接,使得恢复过程更加高效。Xu等人(2020b)构建了具有真实噪声的低光照图像数据集以及对应的清晰图像。基于此数据集,提出了一种基于频率的分解和增强模型,以同时实现噪声抑制和细节增强。Jin等人(2021)提出了一种弥补低光场景之间的差距:快速适应的双层学习。该方法使用双层学习的方法,使得低光照图像增强模型在多个数据集上都具有较好的性能,提高了方法的鲁棒性。
实际上,以上网络属于传统的启发式设计思路,网络结构整体作为黑箱,缺乏对特征空间中信息的再利用过程。为此,Ma等人(2021)关注于特征空间中的上下文依赖性,提出了一种上下文敏感的分解网络。通过结合物理原理来桥接光照与反射在特征层面的估计过程,进一步构造空间变化的光照引导以实现光照组件的边缘感知平滑特性,最终实现了高质量的视觉增强效果。此外该工作还提供了两种显著优于现有工作的不同的加速版本以提高算法的实际应用价值。Zhang等人(2020c)构建了一种原理启发的多尺度聚合网络用于低光照图像增强,通过特征信息的充分利用同时实现了噪声去除和亮度增强。
考虑到现有成对数据训练机制产生的泛化性能不足,以及现有成对数据自身存在的不精确性,一系列减轻对于成对数据依赖的工作相继提出。生成对抗网络(generative adversarial network,GAN)(Liu等,2017)是一种代表性的非成对数据训练网络,且已在一系列图像到图像(如黑夜到白天)的转换中取得显著成功。因此一个直接的想法是,GAN可以用于解决低光照图像增强问题。Shi等人(2019)提出了一个生成器,并利用转换的SID数据集(Chen等,2018a)来实现成对数据训练。但是,由于训练过程中过于关注分布,经常导致增强的结果看起来是不自然的。为了使得恢复出的增强图像更加自然,Guo等人(2020)通过逐步推导构造出了一种像素级别的曲线估计卷积神经网络Zero-DCE(zero-reference deep curve estimation),并设计了一系列的零参考训练损失函数,以解决低光照图像增强问题。进一步地,Li等人(2021b)提供了加速的版本Zero-DCE++,显著提升运算效率,性能几乎保持不变。最近,在注意力机制的启发下,Jiang等人(2021)建立了一个具有自我注意力机制的生成对抗网络,并且以一种不成对的GAN的方式进行训练。尽管该方法的性能要远优于现有的一系列基于GAN的低光增强方法,但是由于忽略了物理原理的作用,该方法在增强过程中总是会产生一些未知的伪像。Zhang等人(2020b)通过设计多种与基于模型优化的方法相关的训练损失函数,并基于RetinexNet的体系结构进行重新设计与调整,进而建立了一个自监督学习的卷积神经网络,以同时输出光照和反射。
Yang等人(2020,2021)设计了一种用于低光照图像增强的半监督学习框架,其中设计了一种深度递归带来连接全监督框架和无监督框架,以整合全监督和无监督学习的优势。全监督框架能够获得较强的信号保真度约束以防止偏离目标,而无监督训练高质量的图像数据集,能够确保较强的视觉感知质量。然而,该方法设计的结构过于复杂,导致性能增益与资源消耗不成正比。Liu等人(2021b)设计了一种基于Retinex架构搜索展开技术RUAS。具体来说,基于Retinex理论,RUAS(Retinex-inspired unrolling with architecture search)首先建立模型来表征低光照图像的内在曝光不足结构,并展开优化过程以构建整体的传播结构。然后通过设计一种协作的无参考学习策略,从紧凑的搜索空间中查找低光先验架构,RUAS能够获得性能最佳的图像增强网络,该网络速度快且需要很少的计算资源。
2.4 相关领域发展现状
此外,随着低光照图像增强技术的发展,也有一些工作开始关注低光照视频增强。Chen等人(2019)致力于对极端条件下的原始视频进行深度处理,为了支持该项工作的开展,作者收集了一个全新的RAW域的低光照视频数据集。此外,Jiang 和Zheng(2019)通过光学系统捕获完全相同场景的明亮和黑暗视频,为真实低光照视频数据集生成成对的训练集。在网络操作中,使用具有3D和2D混杂操作的全卷积网络用于学习增强映射,并从原始相机传感器数据到明亮的RGB视频进行适当的时空转换。Triantafyllidou等人(2020)提出一种数据合成机制来解决低光照视频 RAW到RGB的数据收集的瓶颈,该机制可以生成丰富的动态视频训练对。该方法将现有的视频(例如互联网视频)映射到低光(短、长曝光)域。Zhang等人(2021c)构建了一种仅使用静态图像即可增强低光照视频,并确保时间稳定性的框架,同时该论文提出了一种全新的成对视频数据集。Wang等人(2021a)通过构建机电一体化系统来精确控制视频捕获过程,并通过识别系统的匀速运动阶段进一步在空间和时间上对齐视频对,进而获取一个全新的低光视频数据集SDSD(seeing dynamic scenes in the dark dataset),并提出了一个端到端的网络框架以及一种自监督策略以在提升亮度的同时减少噪声。
与其他经典图像处理类似,单纯依赖于视觉质量进行评判的低光照图像增强技术的发展已经遭遇瓶颈。一方面,由于低光照图像增强问题的特殊性,缺乏行之有效的能够准确反映增强图像质量的指标;另一方面,仅依靠部分志愿者对于视觉质量打分投票的过程,缺乏一般性,容易存在偏见引起非理性决断。因此,越来越多的人开始考虑采用一系列下游高层视觉任务来评判增强图像的质量。由国际顶级计算机视觉领域会议CVPR(IEEE Conference on Computer Vision and Pattern Recognition)主办的UG2+ Challenge(http://cvpr2021.ug2challenge.org/)比赛应运而生,该比赛包含低光人脸检测子课题,旨在探讨图像处理技术与高层视觉任务之间的联系,致力于推动恶劣场景下的高层视觉任务发展。截止目前,该比赛已成功举办4届,其中的冠军方案普遍采用增强加检测的策略。由此可见低光照增强技术对于下游任务的重要性。基于“增强+检测”思路,Liang等人(2021)通过建立能够输出多个不同曝光程度的中间结果的循环曝光生成模块,并将之与多曝光检测模块进行无缝耦合。最终实现检测不同光照情形下的人脸。Wang等人(2021b)通过双向的低层自适应和多任务的高层自适应,成功实现了在缺乏检测标签的情形下的低光人脸检测。此外,也有一些学者,如Dai和Van Gool(2018),Sakaridis等人(2019,2020,2021),Wu等人(2021b),Tan等人(2020)开始研究夜间情形下的语义分割问题。
2.5 小结
现有低光照图像增强技术在方法层面上已经完成从传统模型设计到数据驱动的深度学习的跨越。在学习机制方面,正在从全监督学习迈向半监督/无监督学习;在应用场景方面,从相对简单的场景逐步转向更加具有挑战的真实场景(如手机拍摄);从评估方式来看,现有技术正在渐渐地跳出基于视觉质量的感知评估体系,而愈发关心下游高层视觉任务的性能,逐步从只关注视觉质量转变为高层视觉任务性能优先。此外,随着视频在生活中越来越常见,现有的工作也在逐步从空间上的图像层面转变为时序上的图像层面,即视频处理。
总之,无论是服务于各类高层视觉任务的低光照图像增强,还是服务于时序层面的低光照视频增强,长远来看,低光照图像增强技术仍然大有可为。
3 低光照图像增强方法性能对比
3.1 实现细节
实验首先在4个成对数据集NASA、LIME、MEF、VV上进行,首先分析对比了SRIE(simultaneous reflectance and illumination estimation)、WVM(weighted variational model)、LIME、JIEP(joint intrinsic-extrinsic prior)、RRM(robust Retinex model)、LECARM(low-light enhancement using camera response model)、PSB(perceptually bidirectional similarity)、SDD(semi-decoupled decomposition)、STAR(structure and texture aware Retinex)共7种基于模型优化的方法和HDRNet、DPE(deep photo enhancer)、WhiteBox(photo post-processing framework)、RetinexNet(deep Retinex-net)、KinD、DeepUPE(underexposed photo enhancement using deep illumination estimation)、EnlightenGAN(deep light enhancement without paired supervision)、Zero-DCE、FIDE(frequency-based image decomposition-and-enhancement)共9种基于深度学习的低光照图像增强方法的性能。选取NIQE(natural image quality evaluator)(通常大于0)(Mittal等,2013)为定量分析指标,随后在用于低光人脸检测的DARK FACE数据集上评估现有方法的人脸检测性能,对于该数据集,将检测精度mAP(mean average precision)作为评估指标。
本文实验对所有的比较方法重新测试,传统方法只使用低光照图像作为输入,深度学习方法需要加载原论文的预训练模型。
3.2 低光照图像增强性能对比
表2展示了基于模型优化的方法和基于深度学习的方法在4个基准数据库上的性能表现,可以看出基于模型优化的方法整体上优于基于深度学习的方法,而且在表现相对突出的基于深度学习方法(表现为前两名)当中,除FIDE外,均属于无监督方法。总的来说,从表2可以看出,一方面,现有的基于模型的优化方法相对于基于深度学习的方法具有更强的泛化性能,基于模型优化的方法不依赖于数据的影响,如何设计先验正则项是其核心部分,往往其设计过程依赖于一系列对于现实环境的假设条件,引入大量的先验知识,从而具有更好的泛化能力,基于模型优化的工作在某些具有挑战的场景中能够实现令人满意的性能。基于深度学习的方法依赖于大量的训练数据,数据是影响性能的重要因素,此外,当训练数据和测试数据分布差异较大时,基于深度学习的方法也无法取得令人满意的性能,换句话讲,基于深度学习的方法无法将已经训练好的模型快速地应用于另一种不同分布的数据上。

表2 不同类型方法在4个非成对真实数据集的定量(NIQE)结果对比
另一方面,基于无监督深度学习的方法要普遍优于全监督的深度学习方法,首先在真实场景中获取成对的低光照图像与正常光照图像极其困难,因此通过全监督学习方法泛化能力普遍弱于无监督学习方法;其次无监督学习通过设计精巧的网络结构以及精心设计损失函数从而引入更多反映环境特性的先验知识。
图4展示了部分方法的可视化结果。可以看出,在当前深度学习盛行的时代,基于模型优化的方法仍然具有令人满意的表现效果。传统方法通过对图像本身进行分析,不依赖于数据的影响,性能较为稳定。随着深度学习的发展,现在的研究方向更加倾向于通过设计精巧的网络结构实现图像增强。但是现有的大部分基于深度学习的方法严重依赖于训练数据,往往需要通过成对数据(即低光照图像输入与其对应的正常光照图像),因此这些方法无法具有良好的普适性。基于无监督学习的图像增强方法在逐渐发展占据深度学习的领导地位,然而此类方法往往需要精心设计在训练过程中的损失函数,训练严重依赖于损失函数的设计以及网络参数的调节。总之,各类方法存在的算法设计问题较为突出,而从性能表现可以看出,增强结果出现的曝光不均匀、颜色偏差和细节丢失等现象仍是亟需解决的核心难题。如何在深度学习跨越式发展时代构建稳定、鲁棒和高效的算法是低光照图像增强技术发展的关键。

图4 部分非成对低光数据集中的低光照图像增强结果对比
3.3 低光人脸检测性能对比
为了进一步探究现有低光照图像增强算法在下游高层视觉任务上的性能,本文还分析了一系列低光照图像增强算法在低光人脸检测上的性能。这里需要强调的是,正如2.3节所言,基于深度学习的方法已经成为主流技术,为此,本小节主要对一系列基于深度学习的低光照图像增强算法进行评估。另外,相对于传统的基于模型优化的方法,基于深度学习的方法能够更加容易与低光人脸检测相结合,构造完整的端到端训练过程,限于一些方法未公布训练代码,本文主要考虑两种情形。一种是在增强结果上直接利用现有正常图像的检测方法进行检测;另一种是在增强结果上重新训练检测网络再进行测试。采用一种成熟的人脸检测算法DSFD(dual shot face detector)(Li等,2019)来评估人脸检测性能。
表3展示了低光照图像增强在1 000个随机采样的DarkFace数据上的人脸检测结果,图5为视觉对比效果。其中直接检测是采用DSFD在WIDER FACE(Yang等,2016)数据集上预训练的模型直接测试,而重训练后检测是指在4 000个增强后的DarkFace数据上重新训练DSFD,并随后进行检测。可以看到,与输入相比,绝大多数的低光照图像增强方法可以有效提升低光人脸检测的精度,其中Zero-DCE和RUAS获得了前2名的性能,而巧合的是,这两种方案均属于无监督深度学习范畴。从这些结果可以得到两方面的认知,一方面,对于这种高层的视觉任务而言,成对数据训练的网络得到的结果缺乏一般性,难以刻画自然图像分布。而无监督方法能够通过反映自然图像分布的损失函数的设计,生成更满足自然图像分布的增强结果,进而显著提升了检测性能。另一方面,设计面向高层视觉任务的无监督的低光照图像增强技术也将是一个可行的研究方向。
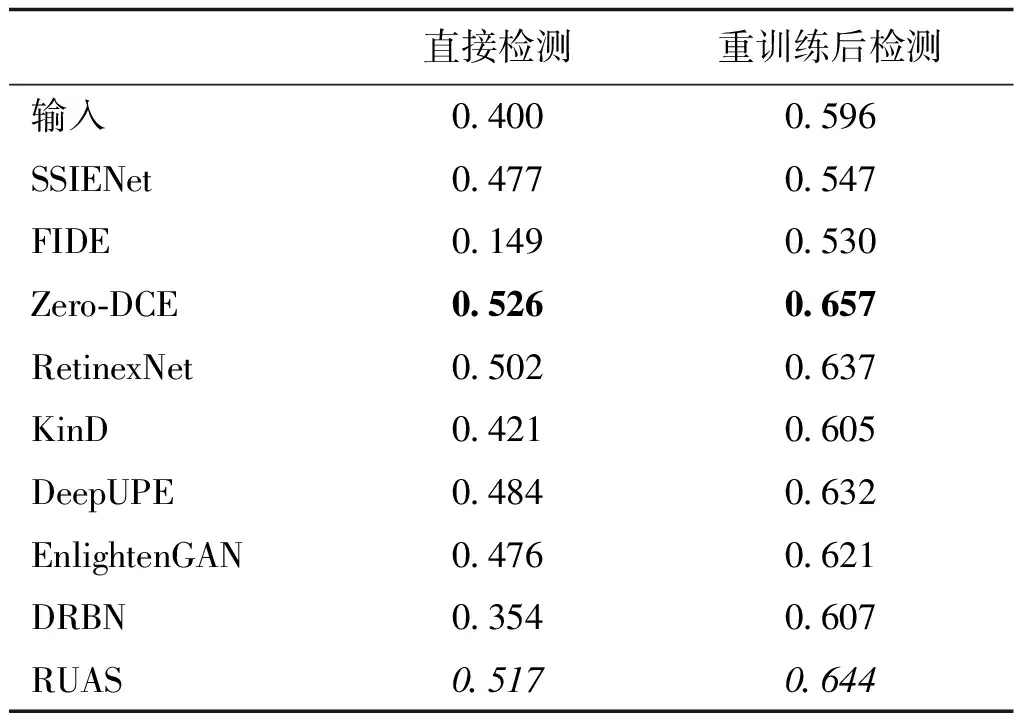
表3 低光人脸检测mAP数值结果对比

图5 低光人脸检测可视结果对比(“P”代表直接利用预训练好的模型测试,“F”代表在增强结果上Finetune预训练好的模型再进行测试)
图5为对应表3中两种情况的可视化结果对比,可以明显看出,经过重新训练后的检测精度和检测框的数量明显提升,反映了针对特定高层视觉任务重新训练的重要性。此外,从这些增强结果也可以看出,视觉效果好的未必检测精度高,这也间接印证了现有诸多工作中表述的视觉质量与高层视觉任务之间存在的差距,二者之间难以确保相辅相成的关系。
4 结 语
本文从低光照图像数据集的发展、低光照图像增强技术的发展以及实验评估3个层面对低光照图像增强领域进行了全面且系统的分析,总结如下:
1)现有低光照图像增强数据集呈现出:规模从小到大、场景由单一到多样以及数据难度从简单到复杂的趋势。其中大多数的数据集属于非成对数据,而由于低光照图像增强建模中的光照难以得到,无法有效合成理想的成对数据集,因此现有的成对低光照图像数据集中的标签主要依赖于手工参数的设置(调整曝光时间或专家修饰),存在多种物理因素变化带来的误差,使得标签不精确;此外,一些数据集的构造过程考虑了检测标签,即与高层视觉任务建立联系。
2)现有低光照图像增强技术的发展脉络为:由传统模型设计方法向数据驱动的深度学习技术转变;由全监督的学习机制向半监督/无监督学习机制迈进;网络结构从复杂逐步向轻量转变;评估手段不再取决于视觉感知质量的好坏,而是高层视觉任务的性能。在问题定义方面,不再仅仅是单图像的低光照增强任务,开始出现探究如何融入时序信息以实现稳定的低光照视频增强的工作。在实际应用层面,一系列具有真实应用场景的任务逐渐进入研究视野,如低光人脸检测、夜间语义分割等问题。
3)从一系列的增强实验结果可以看出,现有的基于模型优化的方法普遍具有优于基于深度学习的泛化能力;现有的无监督学习技术相对于全监督学习方法更加鲁棒和稳定。低光人脸检测的实验结果进一步反映了无监督学习机制面向高层视觉任务的友好性。从上述现象可以得出,如何构建具有普适性、场景无关的、对高层视觉任务有辅助支撑作用的无监督低光照图像增强方法是现阶段低光照图像领域发展亟待解决的问题。
通过以上总结,可以推测出如下未来可能的研究方向:
1)如何挖掘不同场景下的低光数据内在规律,打破对于成对数据的依赖,赋予算法场景无关的泛化能力;
2)如何构建适用于低光照图像增强任务的高效网络框架,以及如何设计更加有效的学习策略来实现框架的充分学习;
3)如何建立低光照图像增强与高层视觉任务(如检测)之间的联系,探究是否存在一种机制能够实现两种任务的相辅相成。
参考文献(References)
Bennett E P and McMillan L.2005.Video enhancement using per-pixel virtual exposures//Proceedings of ACM SIGGRAPH 2005 Papers.Los Angeles, California, USA: ACM: 845-852[DOI: 10.1145/1186822.1073272]
Brifman A, Romano Y and Elad M.2019.Unified single-image and video super-resolution via denoising algorithms.IEEE Transactions on Image Processing, 28(12): 6063-6076[DOI: 10.1109/TIP.2019.2924173]
Bychkovsky V, Paris S, Chan E and Durand F.2011.Learning photographic global tonal adjustment with a database of input/output image pairs//Proceedings of 2011 Conference on Computer Vision and Pattern Recognition.Colorado Springs, USA: IEEE: 97-104[DOI: 10.1109/CVPR.2011.5995332]
Cai B L, Xu X M, Guo K L, Jia K, Hu B and Tao A C.2017.A joint intrinsic-extrinsic prior model for retinex//Proceedings of 2017 IEEE International Conference on Computer Vision.Venice, Italy: IEEE: 4020-4029[DOI: 10.1109/ICCV.2017.431]
Cai J R, Gu S H and Zhang L.2018.Learning a deep single image contrast enhancer from multi-exposure images.IEEE Transactions on Image Processing, 27(4): 2049-2062[DOI: 10.1109/TIP.2018.2794218]
Chen C, Chen Q F, Do M and Koltun V.2019.Seeing motion in the dark//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision.Seoul, Korea(South): IEEE: 3185-3194[DOI: 10.1109/ICCV.2019.00328]
Chen C, Chen Q F, Xu J and Koltun V.2018a.Learning to see in the dark//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City, USA: IEEE: 3291-3300[DOI: 10.1109/CVPR.2018.00347]
Chen W, Wang W J, Yang W H and Liu J Y.2018c.Deep retinex decomposition for low-light enhancement//Proceedings of British Machine Vision Conference 2018.Newcastle, UK: BMVA
Chen Y S, Wang Y C, Kao M H and Chuang Y Y.2018b.Deep photo enhancer: unpaired learning for image enhancement from photographs with GANs//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City,USA: IEEE: 6306-6314[DOI: 10.1109/CVPR.2018.00660]
Cheng H D and Shi X J.2004.A simple and effective histogram equalization approach to image enhancement.Digital Signal Processing, 14(2): 158-170[DOI: 10.1016/j.dsp.2003.07.002]
Dai D X and Van Gool L.2018.Dark model adaptation: semantic image segmentation from daytime to nighttime//Proceedings of the 21st International Conference on Intelligent Transportation Systems.Maui, USA: IEEE: 3819-3824[DOI: 10.1109/ITSC.2018.8569387]
Fan M H, Wang W J, Yang W H and Liu J Y.2020.Integrating semantic segmentation and retinex model for low-light image enhancement//Proceedings of the 28th ACM International Conference on Multimedia.Virtual Event(Seattle, WA), USA: ACM: 2317-2325[DOI: 10.1145/3394171.3413757]
Fu X Y, Liao Y H, Zeng D L, Huang Y, Zhang X P and Ding X H.2015.A probabilistic method for image enhancement with simultaneous illumination and reflectance estimation.IEEE Transactions on Image Processing, 24(12): 4965-4977[DOI: 10.1109/TIP.2015.2474701]
Fu X Y, Zeng D L, Huang Y, Zhang X P and Ding X H.2016.A weighted variational model for simultaneous reflectance and illumination estimation//Proceedings of 2016 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Las Vegas, USA: IEEE: 2782-2790[DOI: 10.1109/CVPR.2016.304]
Guo C L, Li C Y, Guo J C, Loy C C, Hou J H, Kwong S and Cong R M.2020.Zero-reference deep curve estimation for low-light image enhancement//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Seattle, USA: IEEE: 1777-1786[DOI: 10.1109/CVPR42600.2020.00185]
Guo X J, Li Y and Ling H B.2017.LIME: low-light image enhancement via illumination map estimation.IEEE Transactions on Image Processing, 26(2): 982-993[DOI: 10.1109/TIP.2016.2639450]
Hai J, Xuan Z, Han S C, Yang R, Hao Y T, Zhou F Z and Lin F.2021.R2RNet: low-light image enhancement via real-low to real-normal network[EB/OL].[2021-06-28].https://arxiv.org/pdf/2106.14501.pdf
Hao S J, Han X, Guo Y R, Xu X and Wang M.2020.Low-light image enhancement with semi-decoupled decomposition.IEEE Transactions on Multimedia, 22(12): 3025-3038[DOI: 10.1109/TMM.2020.2969790]
Hasinoff S W, Sharlet D, Geiss R, Adams A, Barron J T, Kainz F, Chen J W and Levoy M.2016.Burst photography for high dynamic range and low-light imaging on mobile cameras.ACM Transactions on Graphics, 35(6): #192[DOI: 10.1145/2980179.2980254]
Hu Y M, He H, Xu C X, Wang B Y and Lin S.2018.Exposure: a white-box photo post-processing framework.ACM Transactions on Graphics, 37(2): #26
Huang H B, Yu A J and He R.2021.Memory oriented transfer learning for semi-supervised image deraining//Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Nashville, USA: IEEE: 7728-7737[DOI: 10.1109/CVPR46437.2021.00764]
Ignatov A, Kobyshev N, Timofte R and Vanhoey K.2017.DSLR-quality photos on mobile devices with deep convolutional networks//Proceedings of 2017 IEEE International Conference on Computer Vision.Venice, Italy: IEEE: 3297-3305[DOI: 10.1109/ICCV.2017.355]
Jiang H Y and Zheng Y Q.2019.Learning to see moving objects in the dark//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision.Seoul, Korea(South): IEEE: 7324-7333[DOI: 10.1109/ICCV.2019.00742]
Jiang Y F, Gong X Y, Liu D, Cheng Y, Fang C, Shen X H, Yang J C, Zhou P and Wang Z Y.2021.EnlightenGAN: deep light enhancement without paired supervision.IEEE Transactions on Image Processing, 30: 2340-2349[DOI: 10.1109/TIP.2021.3051462]
Jin D, Ma L, Liu R S and Fan X.2021.Bridging the gap between low-light scenes: bilevel learning for fast adaptation//Proceedings of the 29th ACM International Conference on Multimedia.[s.l.]: ACM:2401-2409[DOI: 10.1145/3474085.3475404]
Jobson D J, Rahman Z and Woodell G A.1997.A multiscale retinex for bridging the gap between color images and the human observation of scenes.IEEE Transactions on Image Processing, 6(7): 965-976[DOI: 10.1109/83.597272]
Kim Y T.1997.Contrast enhancement using brightness preserving bi-histogram equalization.IEEE Transactions on Consumer Electronics, 43(1): 1-8[DOI: 10.1109/30.580378]
Kong X Y, Liu L and Qian Y S.2021.Low-light image enhancement via Poisson noise aware retinex model.IEEE Signal Processing Letters, 28: 1540-1544[DOI: 10.1109/LSP.2021.3096160]
Land E H and McCann J J.1971.Lightness and retinex theory.Journal of the Optical Society of America, 61(1): 1-11[DOI: 10.1364/JOSA.61.000001]
Lee C, Lee C and Kim C S.2013.Contrast enhancement based on layered difference representation of 2D histograms.IEEE Transactions on Image Processing, 22(12): 5372-5384[DOI: 10.1109/TIP.2013.2284059]
Li C Y, Guo C L and Chen C L.2021b.Learning to enhance low-light image via zero-reference deep curve estimation.IEEE Transactions on Pattern Analysis and Machine Intelligence[DOI: 10.1109/TPAMI.2021.3063604]
Li C Y, Guo C L, Han L H, Jiang J, Cheng M M, Gu J W and Loy C C.2021a.Low-light image and video enhancement using deep learning: a survey[EB/OL].[2021-04-21].https://arxiv.org/pdf/2104.10729.pdf
Li C Y, Guo J C, Porikli F and Pang Y W.2018b.LightenNet: a convolutional neural network for weakly illuminated image enhancement.Pattern Recognition Letters, 104: 15-22
Li J, Wang Y B, Wang C A, Tai Y, Qian J J, Yang J, Wang C J, Li J L and Huang F Y.2019.DSFD: dual shot face detector//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Long Beach, USA: IEEE: 5060-5069[DOI: 10.1109/CVPR.2019.00520]
Li J Q, Li J C, Fang F M, Li F and Zhang G X.2021c.Luminance-aware pyramid network for low-light image enhancement.IEEE Transactions on Multimedia, 23: 3153-3165[DOI: 10.1109/TMM.2020.3021243]
Li M D, Liu J Y, Yang W H, Sun X Y and Guo Z M.2018a.Structure-revealing low-light image enhancement via robust retinex model.IEEE Transactions on Image Processing, 27(6): 2828-2841[DOI: 10.1109/TIP.2018.2810539]
Liang J X, Wang J W, Quan Y H, Chen T Y, Liu J Y, Ling H B and Xu Y.2021.Recurrent exposure generation for low-light face detection.IEEE Transactions on Multimedia: 1609-1621[DOI: 10.1109/TMM.2021.3068840]
Lim S and Kim W.2021.DSLR: deep stacked laplacian restorer for low-light image enhancement.IEEE Transactions on Multimedia, 23: 4272-4284[DOI: 10.1109/TMM.2020.3039361]
Liu J Y, Xu D J, Yang W H, Fan M H and Huang H F.2021a.Benchmarking low-light image enhancement and beyond.International Journal of Computer Vision, 129(4): 1153-1184[DOI: 10.1007/s11263-020-01418-8]
Liu M Y, Breuel T and Kautz J.2017.Unsupervised image-to-image translation networks//Proceedings of the 31st International Conference on Neural Information Processing Systems.Long Beach, USA: Curran Associates Inc: 700-708
Liu R S, Ma L, Zhang J A, Fan X and Luo Z X.2021b.Retinex-inspired unrolling with cooperative prior architecture search for low-light image enhancement//Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Nashville,USA: IEEE: 10561-10570[DOI: 10.1109/CVPR46437.2021.01042]
Loh Y P and Chan C S.2019.Getting to know low-light images with the exclusively dark dataset.Computer Vision and Image Understanding, 178: 30-42[DOI: 10.1016/j.cviu.2018.10.010]
Lore K G, Akintayo A and Sarkar S.2017.LLNEt: a deep autoencoder approach to natural low-light image enhancement.Pattern Recognition, 61: 650-662
Lyu F F, Liu B and Lu F.2020.Fast enhancement for non-uniform illumination images using light-weight CNNs//Proceedings of the 28th ACM International Conference on Multimedia.Virtual Event(Seattle, WA), USA: ACM: 1450-1458[DOI: 10.1145/3394171.3413925]
Ma K D, Zeng K and Wang Z.2015.Perceptual quality assessment for multi-exposure image fusion.IEEE Transactions on Image Processing, 24(11): 3345-3356[DOI: 10.1109/TIP.2015.2442920]
Ma L, Lin J, Shang J J, Zhong W, Fan X, Luo Z X and Liu R S.2020.Learning multi-scale retinex with residual network for low-light image enhancement//Proceedings of the 3rd Chinese Conference on Pattern Recognition and Computer Vision.Nanjing, China: Springer[DOI: 10.1007/978-3-030-60633-6_24]
Ma L, Liu R S, Zhang J A, Fan X and Luo Z X.2021.Learning deep context-sensitive decomposition for low-light image enhancement.IEEE Transactions on Neural Networks and Learning Systems, Early Access[DOI: 10.1109/TNNLS.2021.3071245]
Mittal A, Soundararajan R and Bovik A C.2013.Making a “completely blind” image quality analyzer.IEEE Signal Processing Letters, 20(3): 209-212[DOI: 10.1109/LSP.2012.2227726]
Pang T Y, Zheng H, Quan Y H and Ji H.2021.Recorrupted-to-recorrupted: unsupervised deep learning for image denoising//Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Nashville, USA: IEEE: 2043-2052[DOI: 10.1109/CVPR46437.2021.00208]
Pisano E D, Zong S Q, Hemminger B M, Deluca M, Johnston R E, Muller K, Braeuning M P and Pizer S M.1998.Contrast limited adaptive histogram equalization image processing to improve the detection of simulated spiculations in dense mammograms.Journal of Digital Imaging, 11(4): 193-200[DOI: 10.1007/BF03178082]
Pizer S M, Amburn E P, Austin J D, Cromartie R, Geselowitz A, Greer T, Ter Haar romeny B, Zimmerman J B and Zuiderveld K.1987.Adaptive histogram equalization and its variations.Computer Vision, Graphics, and Image Processing, 39(3): 355-368[DOI: 10.1016/s0734-189x(87)80186-x]
Ren W Q, Liu S F, Ma L, Xu Q Q, Xu X Y, Cao X C, Du J P and Yang M H.2019b.Low-light image enhancement via a deep hybrid network.IEEE Transactions on Image Processing, 28(9): 4364-4375[DOI: 10.1109/TIP.2019.2910412]
Ren X T, Yang W H, Cheng W H and Liu J Y.2020.LR3M: robust low-light enhancement via low-rank regularized retinex model.IEEE Transactions on Image Processing, 29: 5862-5876[DOI: 10.1109/TIP.2020.2984098]
Ren Y R, Ying Z Q, Li T H and Li G.2019a.LECARM: low-light image enhancement using the camera response model.IEEE Transactions on Circuits and Systems for Video Technology, 29(4): 968-981[DOI: 10.1109/TCSVT.2018.2828141]
Sakaridis C, Dai D X and van Gool L.2019.Guided curriculum model adaptation and uncertainty-aware evaluation for semantic nighttime image segmentation//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision.Seoul, Korea(South): IEEE: 7373-7382[DOI: 10.1109/ICCV.2019.00747]
Sakaridis C, Dai D X and van Gool L.2020.Map-guided curriculum domain adaptation and uncertainty-aware evaluation for semantic nighttime image segmentation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(6):3139-3153[DOI: 10.1109/TPAMI.2020.3045882]
Sakaridis C, Dai D X and van Gool L.2021.ACDC: the adverse conditions dataset with correspondences for semantic driving scene understanding//Proceedings of 2021 IEEE/CVF International Conference on Computer Vision.[s.l.]: IEEE: 10765-10775
Shen L, Yue Z H, Feng F, Chen Q, Liu S H and Ma J.2017.MSR-Net: low-light image enhancement using deep convolutional network[EB/OL].[2021-09-17].https://arxiv.org/pdf/1711.02488.pdf
Shi Y M, Wu X P and Zhu M.2019.Low-light image enhancement algorithm based on retinex and generative adversarial network[EB/OL].[2021-09-17].https://arxiv.org/pdf/1906.06027.pdf
Tan X, Zhang Y H, Cao Y, Ma L Z and Lau W H.2020.Night-time semantic segmentation with a large real dataset[EB/OL].[2021-09-17].https://arxiv.org/pdf/2003.06883.pdf
Tao L, Zhu C, Xiang G Q, Li Y, Jia H Z and Xie X D.2017.LLCNN: a convolutional neural network for low-light image enhancement//Proceedings of 2017 IEEE Visual Communication and Image Processing.St.Petersburg, USA: IEEE: 1-4[DOI: 10.1109/VCIP.2017.8305143]
Triantafyllidou D, Moran S, McDonagh S, Parisot S and Slabaugh G.2020.Low light video enhancement using synthetic data produced with an intermediate domain mapping//Proceedings of the 16th European Conference on Computer Vision.Glasgow, UK: Springer: 103-119[DOI: 10.1007/978-3-030-58601-0_7]
Wang L W, Liu Z S, Siu W C and Lun D P K.2020.Lightening network for low-light image enhancement.IEEE Transactions on Image Processing, 29: 7984-7996[DOI: 10.1109/TIP.2020.3008396]
Wang R X, Xu X G, Fu C W, Lu J B, Yu B and Jia J Y.2021a.Seeing dynamic scene in the dark: a high-quality video dataset with mechatronic alignment//Proceedings of 2021 IEEE/CVF International Conference on Computer Vision.[s.l.]: IEEE
Wang R X, Zhang Q, Fu C W, Shen X Y, Zheng W S and Jia J Y.2019a.Underexposed photo enhancement using deep illumination estimation//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Long Beach,USA: IEEE: 6842-6850[DOI: 10.1109/CVPR.2019.00701]
Wang S H, Zheng J, Hu H M and Li B.2013.Naturalness preserved enhancement algorithm for non-uniform illumination images.IEEE Transactions on Image Processing, 22(9): 3538-3548[DOI: 10.1109/TIP.2013.2261309]
Wang W J, Yang W H and Liu J Y.2021b.HLA-Face: joint high-low adaptation for low light face detection//Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Nashville, USA: IEEE: 16190-16199[DOI: 10.1109/CVPR46437.2021.01593]
Wang Y, Cao Y, Zha Z J, Zhang J, Xiong Z W, Zhang W and Wu F.2019b.Progressive retinex: mutually reinforced illumination-noise perception network for low-light image enhancement//Proceedings of the 27th ACM International Conference on Multimedia.Nice, France: ACM: 2015-2023[DOI: 10.1145/3343031.3350983]
Wang Y, Chen Q and Zhang B.1999.Image enhancement based on equal area dualistic sub-image histogram equalization method.IEEE Transactions on Consumer Electronics, 45(1): 68-75[DOI: 10.1109/30.754419]
Wu H Y, Qu Y Y, Lin S H, Zhou J, Qiao R Z, Zhang Z Z, Xie Y and Ma L Z.2021a.Contrastive learning for compact single image Dehazing//Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Nashville, USA: IEEE: 10546-10555[DOI: 10.1109/CVPR46437.2021.01041]
Wu X Y, Wu Z Y, Guo H, Ju L L and Wang S.2021b.DANNet: a one-stage domain adaptation network for unsupervised nighttime semantic segmentation//Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Nashville, USA: IEEE: 15764-15773[DOI: 10.1109/CVPR46437.2021.01551]
Xu J, Hou Y K, Ren D W, Liu L, Zhu F, Yu M Y, Wang H Q and Shao L.2020a.STAR: a structure and texture aware retinex model.IEEE Transactions on Image Processing, 29: 5022-5037[DOI: 10.1109/TIP.2020.2974060]
Xu K, Yang X, Yin B C and Lau R W H.2020b.Learning to restore low-light images via decomposition-and-enhancement//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Seattle, USA: IEEE: 2278-2287[DOI: 10.1109/CVPR42600.2020.00235]
Xu L, Yan Q, Xia Y and Jia J Y.2012.Structure extraction from texture via relative total variation.ACM Transactions on Graphics, 31(6): #139[DOI: 10.1145/2366145.2366158]
Yang S, Luo P, Loy C C and Tang X O.2016.WIDER FACE: a face detection benchmark//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas, USA: IEEE: 5525-5533[DOI: 10.1109/CVPR.2016.596]
Yang W H, Wang S Q, Fang Y M, Wang Y and Liu J Y.2020.From fidelity to perceptual quality: a semi-supervised approach for low-light image enhancement//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Seattle,USA: IEEE: 3060-3069[DOI: 10.1109/CVPR42600.2020.00313]
Yang W H, Wang S Q, Fang Y M, Wang Y and Liu J Y.2021.Band representation-based semi-supervised low-light image enhancement: bridging the gap between signal fidelity and perceptual quality.IEEE Transactions on Image Processing, 30: 3461-3473[DOI: 10.1109/TIP.2021.3062184]
Yasarla R, Sindagi V A and Patel V M.2021.Semi-supervised image deraining using Gaussian processes.IEEE Transactions on Image Processing, 30: 6570-6582[DOI: 10.1109/TIP.2021.3096323]
Ye X Y, Luo X H, Wang P and Chen H Y.2019.Face recognition with superposed linear sparse representation based on discriminative nonconvex low-rank matrix decomposition.Journal of Image and Graphics, 24(8): 1327-1337(叶学义, 罗宵晗, 王鹏, 陈慧云.2019.基于非凸低秩分解判别的叠加线性稀疏人脸识别.中国图象图形学报, 24(8): 1327-1337)[DOI: 10.11834/jig.180585]
Yu F, Xian W Q, Chen Y Y, Liu F C, Liao M, Madhavan V and Darrell T.2018a.BDD100K: a diverse driving video database with scalable annotation tooling[EB/OL].[2021-06-12].https://arxiv.org/pdf/1805.04687.pdf
Yu S S, Liu W Y, Zhang Y S, Qu Z, Zhao D L and Zhang B.2018b.DeepExposure: learning to expose photos with asynchronously reinforced adversarial learning//Proceedings of the 32nd International Conference on Neural Information Processing Systems.Montréal, Canada: Curran Associates Inc: 2153-2163
Yuan L and Sun J.2012.Automatic exposure correction of consumer photographs//Proceedings of the 12th European Conference on Computer Vision.Florence, Italy: Springer: 771-785[DOI: 10.1007/978-3-642-33765-9_55]
Zhai P B, Yang H, Song T T, Yu K, Ma L X and Huang X S.2020.Two-path semantic segmentation algorithm combining attention mechanism.Journal of Image and Graphics, 25(8): 1627-1636(翟鹏博, 杨浩, 宋婷婷, 余亢, 马龙祥, 黄向生.2020.结合注意力机制的双路径语义分割.中国图象图形学报, 25(8): 1627-1636)[DOI: 10.11834/jig.190533]
Zhang F, Li Y, You S D and Fu Y.2021c.Learning temporal consistency for low light video enhancement from single images//Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Nashville, USA: IEEE: 4965-4974[DOI: 10.1109/CVPR46437.2021.00493]
Zhang J A, Liu R S, Ma L, Zhong W, Fan X and Luo Z X.2020c.Principle-inspired multi-scale aggregation network for extremely low-light image enhancement//Proceedings of 2020 IEEE International Conference on Acoustics, Speech and Signal Processing.Barcelona, Spain: IEEE: 2638-2642[DOI: 10.1109/ICASSP40776.2020.9053261]
Zhang Q, Nie Y W, Zhu L, Xiao C X and Zheng W S.2020a.Enhancing underexposed photos using perceptually bidirectional similarity.IEEE Transactions on Multimedia, 23: 189-202[DOI: 10.1109/TMM.2020.2982045]
Zhang Q, Yuan G Z, Xiao C X, Zhu L and Zheng W S.2018.High-quality exposure correction of underexposed photos//Proceedings of the 26th ACM International Conference on Multimedia.Seoul, Korea(South): ACM: 582-590[DOI: 10.1145/3240508.3240595]
Zhang Y H, Guo X J, Ma J Y, Liu W and Zhang J W.2021.Beyond brightening low-light images.International Journal of Computer Vision, 129(4): 1013-1037[DOI: 10.1007/s11263-020-01407-x]
Zhang Y H, Zhang J W and Guo X J.2019.Kindling the darkness: a practical low-light image enhancer//Proceedings of the 27th ACM International Conference on Multimedia.Nice, France: ACM: 1632-1640[DOI: 10.1145/3343031.3350926]
Zhang Y, Di X G, Zhang B and Wang C H.2020b.Self-supervised image enhancement network: training with low light images only[EB/OL].[2021-06-17].https://arxiv.org/pdf/2002.11300.pdf
Zhao L, Lu S P, Chen T, Yang Z L and Shamir A.2021.Deep symmetric network for underexposed image enhancement with recurrent attentional learning//Proceedings of 2021 IEEE International Conference on Computer Vision.[s.l.]: IEEE
Zhu G J, Ma L, Liu R S, Fan X and Luo Z X.2021.Collaborative reflectance-and-illumination learning for high-efficient low-light image enhancement//Proceedings of 2021 IEEE International Conference on Multimedia and Expo.Shenzhen, China: IEEE: 1-6[DOI: 10.1109/ICME51207.2021.9428268]
Zhu M F, Pan P B, Chen W and Yang Y.2020.EEMEFN: low-light image enhancement via edge-enhanced multi-exposure fusion network//Proceedings of the 34th AAAI Conference on Artificial Intelligence.Palo Alto, USA: AIAA: 13106-13113[DOI: 10.1609/aaai.v34i07.7013]
猜你喜欢
中国动物保健(2022年10期)2022-11-04
农业工程学报(2022年13期)2022-10-09
航天返回与遥感(2022年2期)2022-05-12
快乐学习报·教育周刊(2022年16期)2022-05-01
新高考·高三数学(2022年3期)2022-04-28
小资CHIC!ELEGANCE(2019年40期)2019-12-10
福建基础教育研究(2019年6期)2019-05-28
计算机应用(2016年10期)2017-05-12
中华建设科技(2016年11期)2017-01-06
水禽世界(2015年6期)2016-03-04
