
融合全局与局部特征的深度卷积神经网络算法
2022-05-17 06:02:04程卫月张雪琴林克正
计算机与生活 2022年5期
程卫月,张雪琴,林克正,李 骜
1.黑龙江工商学院,哈尔滨150025
2.哈尔滨理工大学 计算机科学与技术学院,哈尔滨150080
表情是人类在交际中传达情感的重要载体,研究表明,55%的情感或意向信息是通过面部表情传达的,面部表情包括六种基本情绪:快乐、悲伤、愤怒、惊讶、厌恶和恐惧。面部表情识别旨在让机器来识别预测这六种表情。
随着机器学习、深度学习的迅速发展,基于深度神经网络的方法被应用到面部表情识别中,相比于传统方法,如人工标注、浅层学习等,深度神经网络具有良好的自学习能力、并行处理能力和较高的分类精度。手工特征提取方法具有光照鲁棒性和尺度不变性,如方向梯度直方图、局部二值模式(local binary pattern,LBP)、尺度不变特征变换和Gabor变换等,它们侧重于关注人脸的主要组成部分:眼睛、眉毛、鼻子和嘴巴等。基于卷积神经网络(convolutional neural networks,CNN)的人脸表情识别方法,大多强调表情的完整性,从整体图像中提取特征,忽略局部区域的细粒度信息。例如,Shin 等人提出通过训练20 多个不同的卷积神经网络,寻找具有较强面部表情识别能力的CNN 结构,平均识别率达到59.93%。
近年来,在图像分类领域已经有学者使用手工特征与深度特征融合。例如,Connie 等人将传统尺度不变特征变换与CNN 提取的特征相结合,进一步提高面部表情识别的性能;Zou 等人将Gabor 特征与深度特征融合,在姿态变化的人脸中表现出较好的识别率。
为提高人脸表情识别率,获取更有效的面部表情特征,提出融合全局与局部特征的深度卷积神经网络算法(deep convolutional neural network algorithm fusing global and local features,GL-DCNN),其网络结构由两个CNN 分支组成:第一个分支采用改进的VGG19(visual geometry group)网络,提取出人脸的整体特征;第二分支主要对纹理特征进行处理,为减少光照等噪音的干扰,采用中心对称局部二值模式(central symmetric local binary pattern,CSLBP)算法,该算法可以大幅度降低处理时间,同时有很强的抗噪能力,将处理后的特征输入到自主设计的浅层CNN 中训练。将两个分支输出的特征进行加权融合,最后使用softmax 分类器完成人脸表情分类任务。
1 深度学习与特征提取
1.1 卷积神经网络模型
典型的卷积神经网络通常包含三种基本操作,即卷积、池化和全连接,通过对图像不断地进行卷积和池化运算,在保留人脸重要信息的情况下,提取出不同尺度的抽象特征。卷积神经网络结构图如图1所示。

图1 卷积神经网络结构Fig.1 Structure of convolutional neural network
卷积层(convolutional layer)是CNN 的核心,它主要对图像特征进行提取,当数据输入时,卷积层利用不同尺度的卷积核对数据进行卷积操作,将输出值经过激活函数进行非线性变换,得到当前层的特征,运算如式(1)所示。

池化层(pooling layer)在CNN 中的主要作用是对上一层卷积层的特征进行降维。它可以有效地减少计算量,特别是避免了过多特征所造成的溢出现象。最大池函数如式(2)所示,它将图像大小下采样为原尺寸的1/。
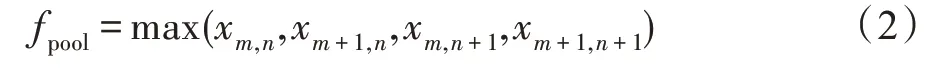
在全连接层(full connection layer)中,实现了从特征到类别的转换,全连接层用于综合前向提取的特征,将卷积层或池化层的局部信息与类别判别相结合。由于其全连通特性,一般全连通层也具有最多的参数。从卷积层提取特征后,将网络连接到全连接层,既可以提高网络的特征提取能力,又可以限制网络的规模。每个神经元的输出如式(3)所示:

其中,为前一层神经元数量;是第层与前层的连接强度;是偏置;(·)是激活函数。
Dropout 层也是CNN 的常用结构,Dropout 是一种正则化技术,用于减少过拟合,在每次训练时,随机减少单元之间的连接,在完整的网络中随机采样一个网络,只更新采样网络的参数,这样可以提高网络的泛化能力。
采用反向传播和随机梯度下降法(stochastic gradient descent,SGD)对模型进行优化,用一小部分数据就可以对参数进行一次更新,这个数据远小于训练样本,这有效地提高了训练速度,用于解决训练数据量过大的问题。随机梯度下降法的迭代更新过程如算法1 所示。
SGD 训练迭代算法

1.2 CSLBP 算法
CSLBP 算法的主要思想:比较以中心像素点为中心对称的邻域值对,对比两者像素点灰度值之间的大小,当差值大于等于0 时,二进制编码为1,否则为0。并将二进制值转换为十进制的CSLBP 值。CSLBP 仅产生/2 个二进制模式,当使用直方图来描述局部纹理特征时,CSLBP 的直方图维数为2,低于局部二值模式(LBP)的直方图维数2,极大地降低了特征维数,节省了存储空间。这种算子可以表达图像局部纹理的空间结构,对光照变化具有一定的鲁棒性,并且计算复杂度较低。CSLBP 算法的编码规则定义如式(4)、式(5)所示。
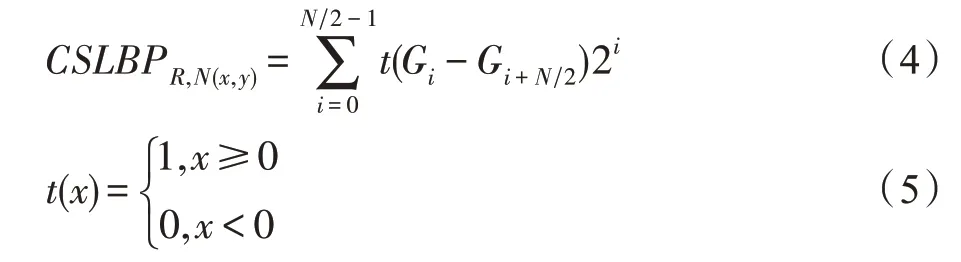
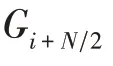
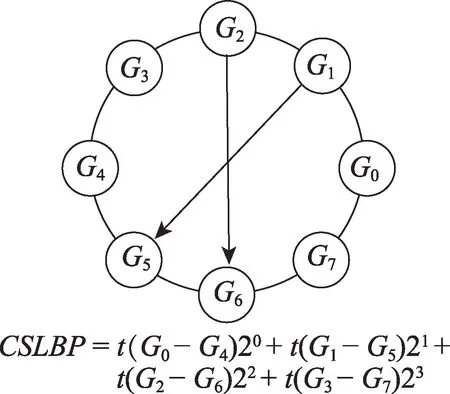
图2 8 邻域像素下CSLBP 计算实例Fig.2 Computing examples of CSLBP in 8 neighborhood pixels
2 GL-DCNN 算法
2.1 GL-DCNN 模型
用两个分支CNN 来提取人脸表情特征,一个分支处理全局特征,另一个提取局部特征。对于全局分支CNN 采用改进的VGG19网络模型,VGG19网络模型在浅层CNN 的基础上,增加几个卷积层,由于加入卷积层比加入全连接层更有利于图像分类,VGG19网络模型比浅层卷积神经网络更容易克服面部表情多样性和复杂性的不足,最终达到更好的分类精度。VGG19 网络结构如图3 所示。
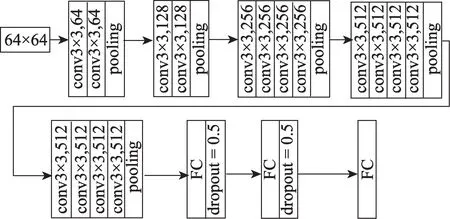
图3 VGG19 网络模型Fig.3 VGG19 network model
VGG19 网络模型采用的是3×3 卷积核、2×2 池化核,激活函数采用ReLU,如式(6)所示。
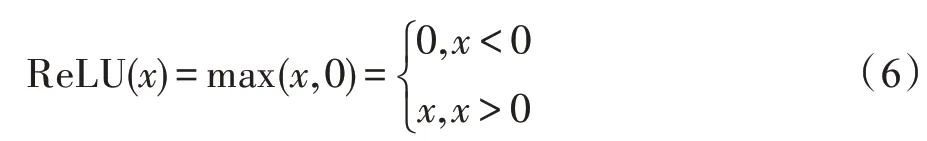
网络的输入是一个灰度图像,为64×64 像素。它包含5 个最大池化层,在每个最大池化操作之后添加一个Dropout层,Dropout率为0.25。
VGGNet(visual geometry group net)由大型图像数据库ImageNet 训练而成,它有很强的学习深度特性的能力。为了减少训练时间,提高网络训练的效率,采用迁移学习的方法,用经过训练的VGG19 网络作为本模型的预训练模型,对VGG19 网络模型的结构进行优化。由于人脸表情识别输出6 种情绪,即6 个类别,设置第一个全连接层为500,最后一个设置为6,这样就减少了网络参数,降低了计算复杂度。
为解决训练过程中神经网络参数多导致的过拟合问题,在每个池化层及最后的全连接层还使用Dropout方法。Dropout多用于池化与全连接层后,参数常设置为0.5 左右,它的原理如图4 所示。图4 左边为正常的全连接层,右边为经过使用Dropout 后的全连接层。可以看出,Dropout 可以对全连接中的某些节点进行选择性失活,按照一定的概率让一些隐藏的神经元节点暂时失去作用,从而减少实际训练参数,有效避免过拟合现象。
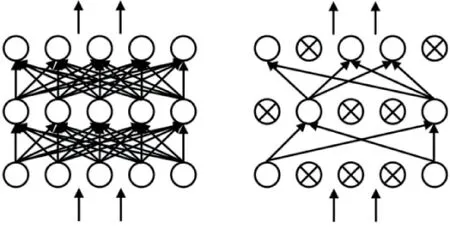
图4 Dropout原理图Fig.4 Schematic diagram of Dropout
对于局部特征分支的CNN,构造一个浅层卷积神经网络来提取局部特征。首先,使用CSLBP 算法对输入的图像进行一次特征提取,获取图像的局部纹理特征;其次,将其输入浅层神经网络,让其自动地从CSLBP 图像中提取与表情相关的特征。浅层神经网络的结构如图1 所示,具体的参数设计为:第一个卷积层使用64 个滤波器对输入的人脸CSLBP 图像进行滤波,使用的是7×7 卷积核,输出64 张64×64像素的图像,之后是2×2 池化核操作对图像进行下采样。第二个卷积层使用256 个3×3 卷积核来映射前一层,接着使用2×2 池化核操作。之后输出到一个包含500 个神经元的全连接层,全连接层使用Dropout操作来防止过拟合,设置Dropout=0.5。
2.2 分支特征加权融合
第一个分支经过VGG19模型得到特征向量1,第二个分支经过CSLBP 局部神经网络模型得到特征向量2 。对1 和2 采用两个级联的全连接层对其进行降维,对1 和2,分别设其两个级联的节点个数为500 和6,如式(7)、式(8)所示。
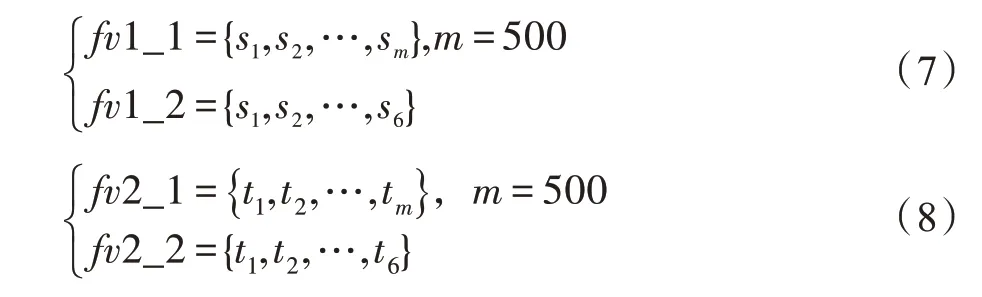
其中,1_1 与2_1 表示第一层全连接层,1_2 与2_2 表示第二层全连接层。
降维后的加权融合网络如图5所示,其中CSLBP_CNN 表示CSLBP 局部神经网络模型。
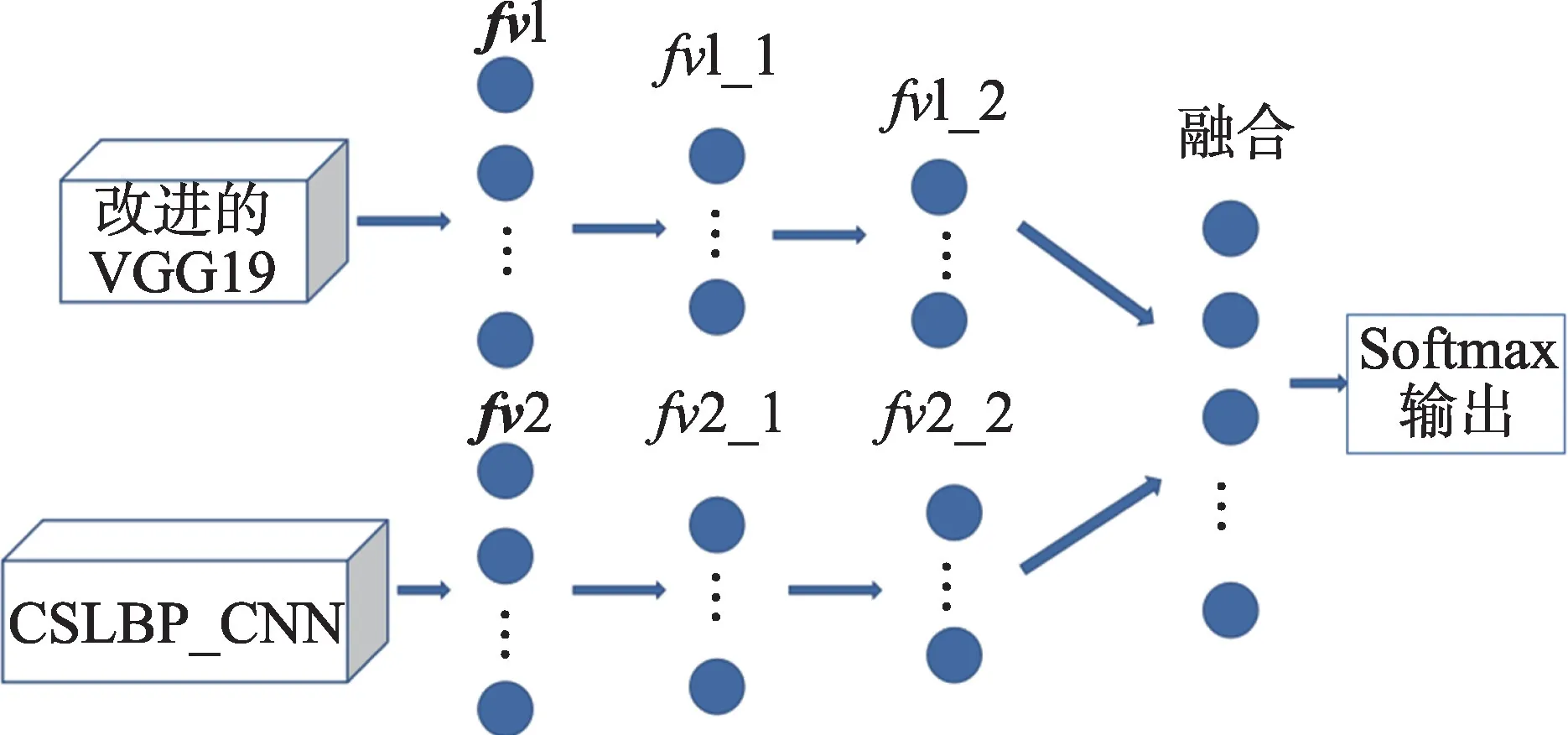
图5 加权融合网络Fig.5 Weighted fusion network
降维之后,1_2 与2_2 采用加权融合方法构造融合后的特征向量,v(=1,2,…,6)的构造方法如式(9)所示。

其中,为权值系数,用来调节两个分支的比重,用交叉验证法对进行了实验计算,发现取0.7 时网络表现较好。
在融合特征向量的基础上,采用维度为6 的softmax 分类器对表情进行分类。在softmax 中,将分为类的概率表达式如式(10)所示。

其中,=1,2,…,。与的值都在(0,1)范围内,对于给定输入且=1,2,…,(=6),=的概率用矩阵形式表示如式(11)所示。
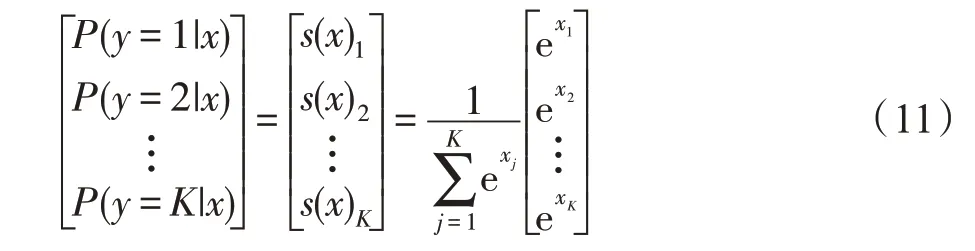
其中,(=|)是在输入为的情况下类别为的概率。式(10)中的每一个元素都对应于一个唯一的表达式类,是以元素值最大的类为预测类。因此,模型的损失函数可表示为式(12)。
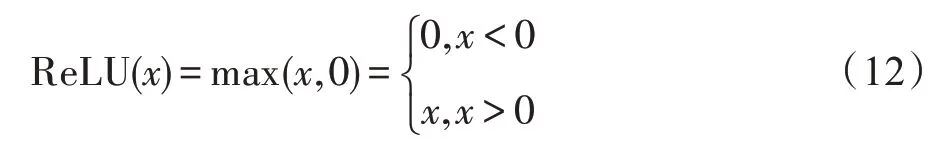
其中,Z表示真实标签,y表示softmax 函数的输出。
2.3 GL-DCNN 模型框架设计
在改进的VGG19 和浅层卷积神经网络结构基础上提出GL-DCNN 算法,算法的总体框架如图6 所示。
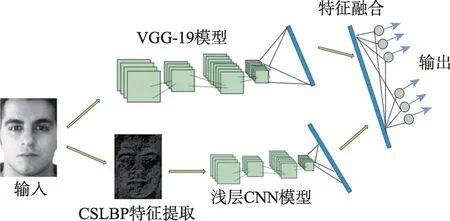
图6 GL-DCNN 模型Fig.6 GL-DCNN model
图6 中,人脸图像经过预处理后,获得64×64 像素的人脸灰度图,同时送入两个分支,其中一个在送入卷积神经网络时会进行CSLBP 处理提取局部纹理特征,VGG19 和浅层卷积神经网络部分参数如表1和表2 所示。
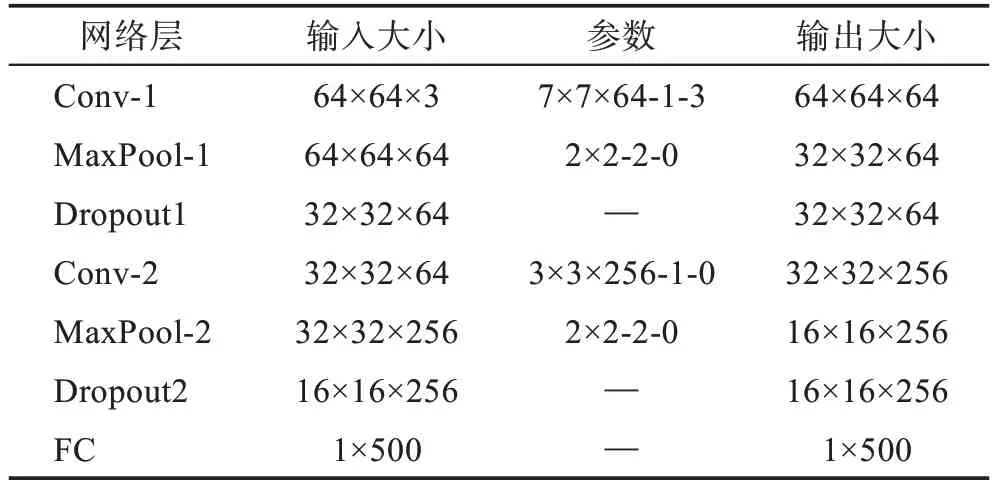
表1 CNN 的网络配置Table 1 Configuration of CNN
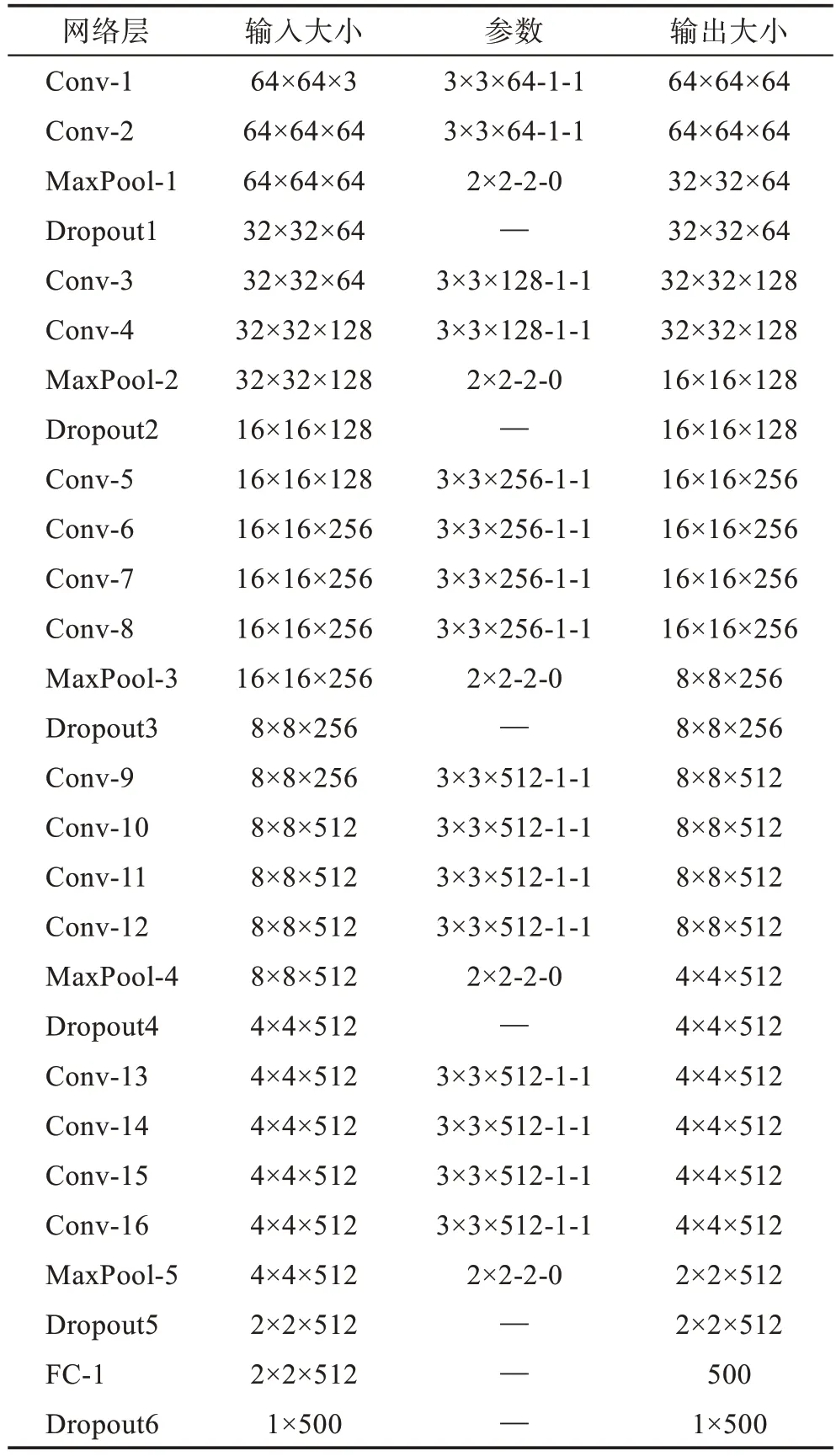
表2 改进的VGG19 网络配置Table 2 Configuration of improved VGG19
整体分支专注于从整个图像中提取抽象表示,而局部分支专注于提取特定区域的纹理信息,这两个分支的聚合不仅增加了特征提取的数量,而且提高了模型的表达能力。特征提取之后对双分支人脸图像的输出进行加权融合,最后对融合结果进行softmax 分类,预测当前的面部表情。
3 实验结果与分析
3.1 实验环境及数据预处理
实验中使用的实验平台:CPU 主频为3.7 GHz,内存为32 GB,Nvidia Ge Force GTX 980Ti GPU,操作系统为Windows 10,64 位,编程语言为Matlab 和Python3.6,模型训练框架为Tensorflow,开发工具为Matlab 2017R 和PyCharm。
实验采用JAFFE 数据集和CK+数据集,用以评估算法的性能。实验之前,将图像统一为64×64 像素大小,并将所有图像进行归一化处理,利用CSLBP算法处理两个数据库中的人脸表情图像。
CK+数据集共包含123 个人的327 张有标签的表情图像,包括Angry(生气)、Disgust(厌恶)、Fear(恐惧)、Happy(高兴)、Sad(悲伤)、Surprise(惊讶)和Contempt(轻蔑)。为了和JAFFE 数据集的表情对应,将轻蔑的表情去掉,剩309 张图片。图7 为CK+数据集上6 种表情的示例图像。

图7 CK+数据集中6 种表情的示例图像Fig.7 Sample images of 6 expressions in CK+dataset
JAFFE 数据集包含10 名日本女性的213 幅图像,每个人每种表情有3 至4 张,每个人有7 种表情,包含Angry(生气)、Neutral(中性)、Disgust(厌恶)、Fear(恐惧)、Happy(高兴)、Sad(悲伤)和Surprise(惊讶)。实验中只选取6 种表情的183 张图片,图8 展示了JAFFE 数据库中的样本。表3 是两个数据库中6 类表情的数量分布。

图8 JAFFE 数据集中6 种表情的示例图像Fig.8 Sample images of 6 expressions in JAFFE dataset
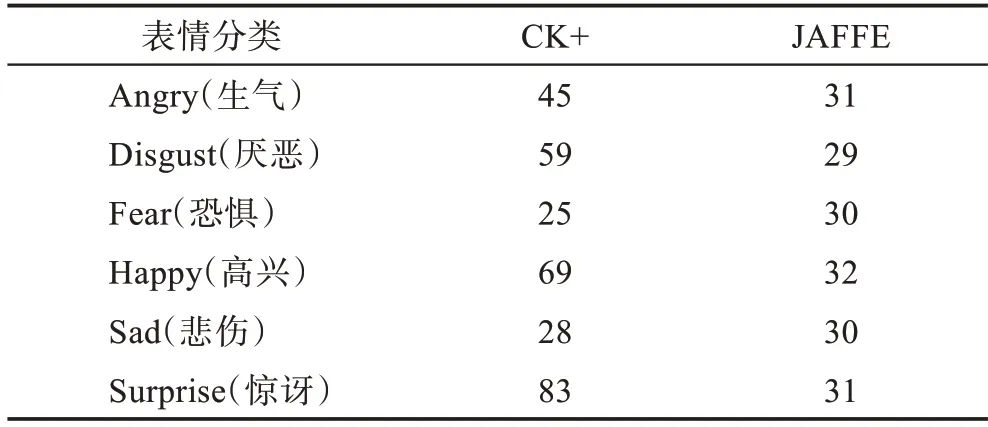
表3 CK+与JAFFE 数据集的6 类表情数量分布Table 3 Number distribution of 6 types of expressions in CK+and JAFFE datasets
3.2 结果与分析
对每个数据集,选择愤怒、厌恶、恐惧、快乐、悲伤和惊讶这6类基本表情作为分类任务的目标。CK+数据集中使用数据增强法将数据扩充到原始图像的5 倍进行训练,JAFFE 数据集中数据扩充10 倍进行实验,两个数据集都采用十折交叉验证,每个批量设置为64,初始学习率设置为0.01。
图9 为CK+数据集在GL-DCNN 模型上实验的混淆矩阵,它的每一列代表了分类器预测得到的类别,每一行代表了数据的真实归属类别。
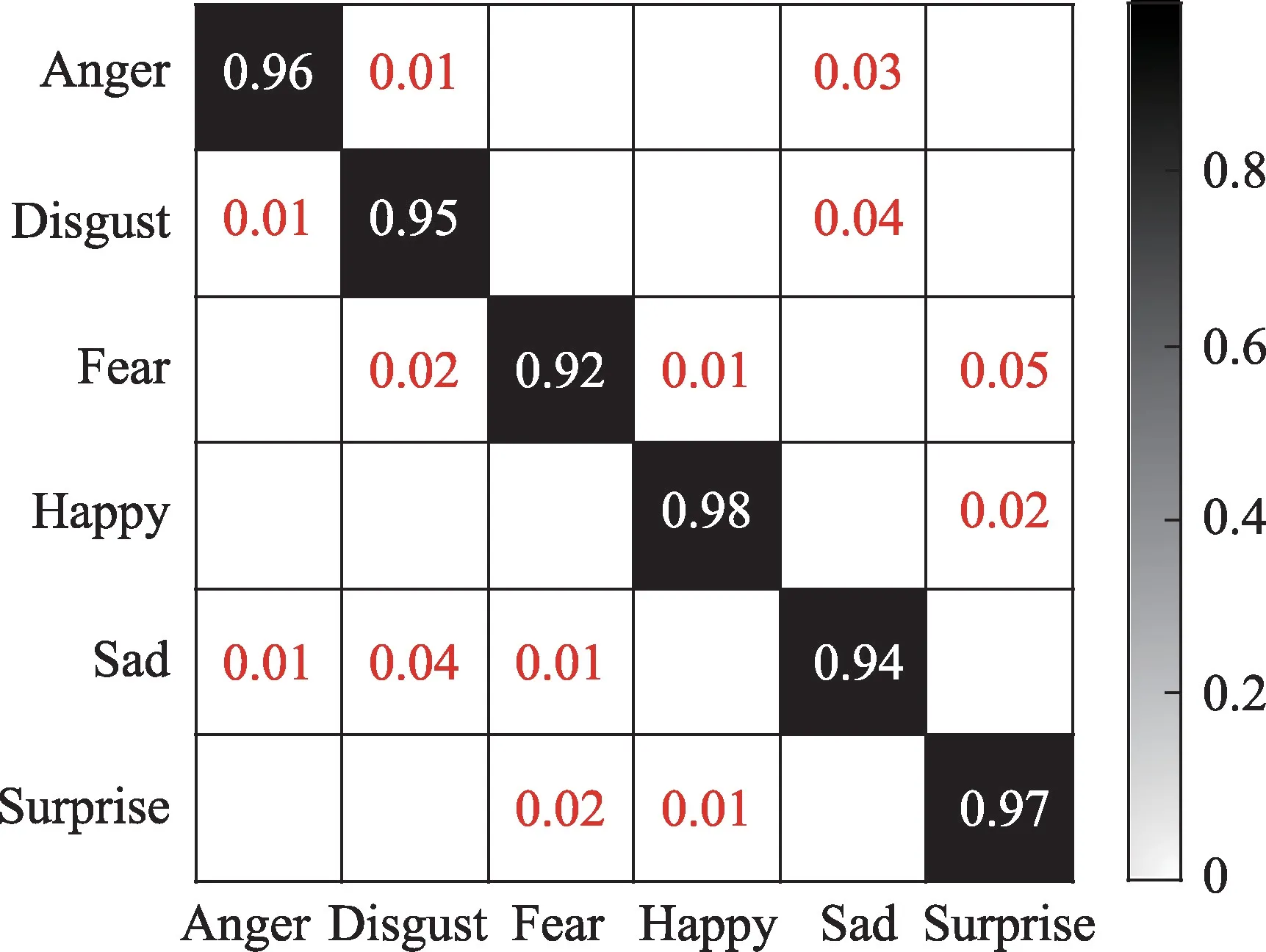
图9 GL-DCNN 方法在CK+数据集上的混淆矩阵Fig.9 Confusion matrix of GL-DCNN method on CK+dataset
由图9 可看出,该方法对于Happy 表情最容易识别,识别率达到98%。从表3 可以看到,Happy 表情的样本数量并不是最多的,说明GL-DCNN 算法对纹理特征的学习是十分有效的,预测结果不会偏向于样本数量多的数据。Surprise 表情的识别率达到97%,因为它的表情更夸张,特征更容易学习,所以Surprise 表情的识别率也较高。Disgust与Sad 会被混淆,在识别中会导致错误,可能是因为它们的表情有相似之处,尤其是嘴的部分。对于Fear 表情相对识别较弱,一是因为样本数较少,可学到的特征相对较少,但是正确识别率也达到92%左右,说明网络中融入的局部特征分支是可以提高图像的表达能力。对于一个不均匀分布的样本集,GL-DCNN 的正确识别率在92%~98%之间,说明GL-DCNN 能有效识别表情在外观上的变化。
图10 为JAFFE 数据集在GL-DCNN 模型上实验的混淆矩阵。

图10 GL-DCNN 方法在JAFFE 数据集上的混淆矩阵Fig.10 Confusion matrix of GL-DCNN method on JAFFE dataset
由图10可看出,GL-DCNN识别Anger 表情和Happy 表情的效果最好,识别率都达到了96%,因为高兴或者生气的表情特征较其他特征更为容易判断;其次对Surprise 表情的识别率达到94%左右,有3%的数据被错误预测为Happy,主要由于Happy 表情和Surprise 表情都有张大嘴的动作,增加训练样本数量可以提高识别率;对恐惧的识别明显低于其他分类,但也能达到89%左右,其中有将近5%的样本被错误分为惊讶,可能两种表情在几个面部区域上动作幅度相似。但是对于厌恶与悲伤这两个表情的分类容易互相干扰,经常将厌恶分类为悲伤或者悲伤分为厌恶,可能是训练时使用的样本较少。对于一个均匀分布的样本集,GL-DCNN 也有较好的表现,识别率高达96%,说明GL-DCNN 对整体特征和局部特征的学习是十分有效的。
实验中对比的算法主要有人工提取特征的方法、CNN+LBP 算法、单模态CNN 模型、VGG16 模型、卷积神经网络融合SIFT 特征,实验结果如表4所示。

表4 不同算法在CK+与JAFFE数据集上识别性能比较Table 4 Comparison of recognition performance of different algorithms on CK+and JAFFE datasets
由表4 可以得出,首先GL-DCNN 方法从整体上是优于其他算法的,尤其在JAFFE 数据集上,识别率高于其他方法3~6 个百分点,GL-DCNN 与人工特征提取方法相比较,无论在结果上,还是时间复杂度上,都表现出较好性能。单模态CNN 方法只是单纯地将人脸灰度图像输入神经网络中训练,相比简单CNN 模型与LBP 结合的人脸识别方法,GL-DCNN 既关注样本的整体信息,也关注局部的纹理信息,因此会有更好的识别效果。VGG16 模型尽管在识别方面表现出了较好的性能,但是相比GL-DCNN 提出的方法识别率略低。这也说明了自动学习的深度特征能很好地用来识别和分类,再加上对于局部特征的补充,使得整体模型有了更好的识别率,由此可见对于局部学习的方法确实有利于提高分类的效果。另外样本是用数据增强法扩充的,因此样本中包含有旋转变化的图像,利用CSLBP 算法对旋转不变具有鲁棒性优势,并和深度网络结合,使得整体的识别效果有了提高,但是在时间复杂度上略显不足。
表5 给出用CPU 和GPU 遍历一个训练样本集所需时间和识别率的对比。从表5 可以看出,在识别率差不多的情况下,训练时间上,GPU 所用时间远少于CPU,主要因为GPU 可以并行处理数据。

表5 使用CPU 和GPU 的训练时间和识别率比较Table 5 Comparison of training time and recognition rate using CPU and GPU
4 结束语
本文针对传统CNN 存在仅从整个图像中提取特征而忽略了有效的局部细节信息的问题,提出了一种融合全局与局部特征的深度卷积神经网络算法。采用了两个网络模型分别提取全局与局部信息进行特征融合:一方面,基于迁移学习的方法,使用已训练好的VGG19 模型进行全局特征提取,降低了网络的训练时间;另一方面,在训练阶段引入CSLBP 局部学习方法,增加了网络处理特征时的多样性,实现了特征互补,使整体模型在分类时表现出明显优势。实验中使用的是CK+、JAFFE 数据集,图片数量相对不足,而且不同类别的样本数目也存在差距,卷积神经网络的训练依赖大量的数据,如果数据太少,容易产生过拟合问题。进一步工作将研究应用在较小样本上的网络模型。
猜你喜欢
中学生数理化·七年级数学人教版(2022年11期)2022-02-22 22:13:22
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
数学物理学报(2021年2期)2021-06-09 08:54:42
计算机工程(2020年3期)2020-03-19 12:24:50
电子制作(2019年11期)2019-07-04 00:34:38
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
中国交通信息化(2018年3期)2018-06-13 03:27:58
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
发明与创新(2016年38期)2016-08-22 03:02:50
艺术生活-福州大学厦门工艺美术学院学报(2016年3期)2016-07-31 19:42:13
