
全卷积注意力机制神经网络的图像语义分割
2022-05-17 06:02欧阳柳瞿绍军
计算机与生活 2022年5期
欧阳柳,贺 禧,瞿绍军,2+
1.湖南师范大学 信息科学与工程学院,长沙410081
2.湖南师范大学 湖南湘江人工智能学院,长沙410081
语义分割(semantic segmentation)是计算机视觉核心研究热点之一,其目的是为图像划分成具有语义信息的区域,并给每个区域块分配一个语义标签,最终得到每个像素都被语义标注的分割图像。语义分割是室内导航、地理信息系统、人机交互、自动驾驶、虚拟增强现实系统、场景理解、医学图像处理以及目标分类等视觉分析的基础。复杂环境的非结构化、目标多样化、形状不规则化以及光照变化、物体遮挡等各种因素都给语义分割带来巨大的挑战。近年来,深度学习在计算机视觉领域的应用越来越广泛,卷积神经网络的分割算法(convolutional neural network,CNN)在图像分割领域取得了突破性的进展。语义分割是图像理解中的常用技术,它可以预测图像中每个像素的类别,实现对图像的分割归类,对图像进行细致的理解。Long 等人提出的全卷积网络(fully convolutional network,FCN)在图像分割任务上表现出巨大的潜力。在深度学习的发展之下,借用深层次卷积神经网络可以从图像中学习具有不同层次的特征表示方法。全卷积网络将分类网络应用到卷积网络中,将传统卷积神经网络中的全连接层替换为卷积层,使用跳跃层的方法组合中间卷积层产生的特征图,然后进行转置卷积。由于跳跃层和转置卷积的原因,FCN 的预测结果和原始图像相同。FCN 兼顾全局语义信息和局部语义信息,将图像级别分类延伸到了像素级分类。FCN使用卷积层替换了CNN 中的全连接层,存在两个问题:(1)随着卷积池化,分辨率在不断缩小,造成部分像素丢失;(2)没有考虑特征图原有的上下文的信息。因此,大量的研究人员在此基础上提出了改进的语义分割模型,如PSPNet(pyramid scene parsing network)中金字塔池化模块能够融合多尺度的上下文信息,有效利用了上下文信息。Ronneberger 等人提出了一种编码器-解码器的网络模型U-Net(U 型网络)。U-Net 由收缩路径和扩展路径组成,收缩路径利用下采样捕捉上下文信息,提取特征,扩展路径是一个解码器,使用上采样操作还原原始图像的位置信息,逐步恢复物体细节和图像分辨率。OCNet(object context network)通过计算每个像素与所有像素的相似度,形成一个目标上下文特征图,然后通过聚合所有像素的特征来表示该像素。DeepLab-v3 网络中将带孔卷积和空洞金字塔池化方法结合,构建了空洞空间金字塔池化模块(atrous spatial pyramid pooling,ASPP)。通过使用不同空洞率的卷积来捕获多尺度的上下文信息,有效增强了感受野,提高分割结果的空间精度。
受到OCNet 和DeepLab-v3 的启发,本文提出了空洞空间金字塔注意力模块(atrous spatial pyramid pooling attention module,ASPPAM)和位置注意力模块(position attention module,PAM),在多个并行分支中使用多个不同空洞率的卷积来获取不同尺度的上下文信息,加入一个计算像素之间相关性的模块,用以增强像素之间相关度。高层特征涉及整个场景的理解,保留了物体的综合特征,低级语义信息具有非常丰富的空间信息,保留了很多细节,PAM 将高级信息和低级信息进行融合,可以很好地处理图像的边缘和细节,以解决高级语义信息丢失的问题。
本文的主要贡献如下:
(1)为了学习像素之间的相关性,提出了PSAM(pixel similarity attention module),并将其嵌入ASPP模块,增强了像素之间的联系,得到新的ASPPAM,丰富ASPP 上下文信息。
(2)提出了PAM,通过融合低层特征和高级特征,突出低层特征细节信息和边缘信息,提高分割效果。
(3)将ASPPAM 和PAM 结合,提出一种新的基于注意力感知的全卷积网络CANet(context attention network),并在Cityscapes测试集中取得了较好的结果。
1 相关工作
1.1 基于神经网络方法的语义分割
FCN 极大地推动了图像语义分割的发展,并且成为许多神经网络的基本模型。目前提高语义分割的方法有:Deeplab-v1 中使用空洞卷积代替池化层,加上条件随机场(conditional random fields,CRFs),目的是改善深度神经网络的输出结果,捕捉边缘细节。该方法的缺点是没有注意图像的多尺度信息,对小物体分割的分割效果不明显。进而在DeepLabv2 中加入了空洞空间金字塔池化模块(ASPP)。使用不同的空洞率的卷积来得到不同的感受野,空洞率小的感受野小,对小物体识别效果较好,空洞率大的感受野大,对大物体的识别效果好,解决了物体的多尺度信息的问题。但是随着空洞率的增大,卷积核的有效参数越来越少,最终会退化成1×1 的卷积核。在PSPNet中,作者提出了一个全局先验结构,将输入划分为不同大小的区域块,分别对这些块进行特征提取,然后上采样到和输入尺寸一样大小,将所有得到的特征在通道上进行合并,将不同尺度的特征信息进行融合,提高了分割的性能。
1.2 空洞空间金字塔池化
空洞空间金字塔池化是在金字塔池化模块基础之上引入了空洞卷积而形成。语义分割中池化层增大感受野的同时,也会减少图像的尺寸,然后在上采样扩大图像尺寸来获取分割图。在通过池化层时,整个图像分辨率会变小,随后进行上采样,分辨率会扩大,整个过程中必然会丢失一些信息。如何在不通过池化层也能达到增大感受野的效果,空洞卷积是一个很好的方案。空洞卷积在传统的卷积核的每个像素之间填充一定的像素,目的是可以增大感受野。空洞卷积存在一定的缺陷,在空洞率(填充像素变量)越来越大的同时,卷积核中的不连续会造成卷积核中参数不能全部用于计算,这会导致卷积核退化成1×1 的卷积核,提取特征效果会降低,空洞空间金字塔的解决方案是:将输入的特征图进行全局平均池化,外加一个1×1 的256 通道的卷积层和批处理化层。
1.3 编码器-解码器结构
在图像分割领域要解决“池化操作后特征图分辨率不断降低,部分像素空间位置信息丢失”等问题,除了对卷积结构进行优化之外,另一类方法是使用编码器-解码器结构。编码器通常由多个卷积层和池化层组成,作用是从原图中获取含有位置信息和语义信息的特征图,解码器通常由反卷积层和反池化层构成,作用是恢复特征图中丢失的空间维度信息和位置信息,生成稠密的预测图。编码器使用卷积或者池化等操作来获取图像的空间位置信息和图像的特征信息,卷积或者池化都会使得图像的分辨率降低,为了得到和原图像相同分辨率大小的分割图,解码器就是为了恢复图像分辨率存在的,解码器使用转置卷积或者上池化,使得缩小的特征图恢复原图像的分辨率的大小,还原原始图像的空间位置信息和图像细节信息。U-Net 就是典型的编码器和解码器结构。在编码器过程使用下采样操作,缩小分辨率,在解码器使用上采样操作,逐步恢复物体的空间位置信息和图像分辨率。
1.4 注意力模块
注意力机制的基本思想是在运算中忽略无关信息而关注重点信息,通过注意力机制学习上下文信息,并且进行优化得到自我注意力模块,捕获数据或者特征的内部相关性。PANet(path aggregation network)中作者认为高层的特征信息可以对低层的特征信息进行指导,因此注意力机制必须发生在不同的层之间。解码器的作用在于恢复像素类别的位置信息,经过编码器提取的特征带有充分的分类信息可以作为指导低层的信息。Woo 等人提出了一种轻量、通用的注意力模块(convolutional block attention module,CBAM)。该模块分别在特征图的空间和通道上引入注意力模块,在不显著增加计算量和参数量的前提下能提升网络模型的特征提取能力。文献[19]提出了自我注意力机制,并将其运用到视频动作识别任务,自我注意力机制可以有效地捕捉不同位置之间的远程依赖关系,每个位置都可以在不造成特征图退化的情况下获得全局感受野。OCNet中,使用自我注意力机制来计算像素之间的相似度,通过利用同一目标的其他像素来为当前像素分类,获取目标上下文,并且在金字塔池化模块和空洞空间金字塔池化模块上做了实验,结果在Cityscapes和ADE20K数据集上取得了SOTA(state of the art)的结果。
2 本文方法
本章首先介绍论文提出的语义分割网络CANet的整体结构,然后分别详细介绍ASPPAM 和PAM,损失函数采用常用的交叉熵损失函数。
2.1 网络的整体结构
本文的整体网络结构如图1 所示,该模型由扩展的FCN、ASPPAM 和PAM 三个摸块组成。采用在ImageNet 上预先训练的ResNet-101的扩展为主干网络,并且去掉ResNet 最后的全连接层,图1 中每个带有“Res”字样的蓝色块的详细结构如表1 所示,“7×7,64,stride:2”表示卷积核为7×7,输出通道数为64,步长为2。Res 每个大块都包含一个基本结构(Baseblock:包含残差(residual)结构),具体结构如表1 中Res 块的矩阵所示,“1×1,64”表示卷积核为1×1,输出通道数为64。矩阵外的“×3”表示输入数据将会执行这个矩阵结构3 次,后续结构以此类推。在Res4 块后添加ASPPAM(空洞空间金字塔注意力模块)来提取深度特征,获得高级语义信息,此时特征映射的大小减小到原始图像的1/8。同时,将低级语义信息传到PAM(位置注意力模块),PAM 主要关注低级语义信息中的边缘信息和细节信息,补充高级语义信息丢失的空间信息,最后将两个注意力模块的输出特征进行融合,经过上采样恢复成最终的预测分割图。
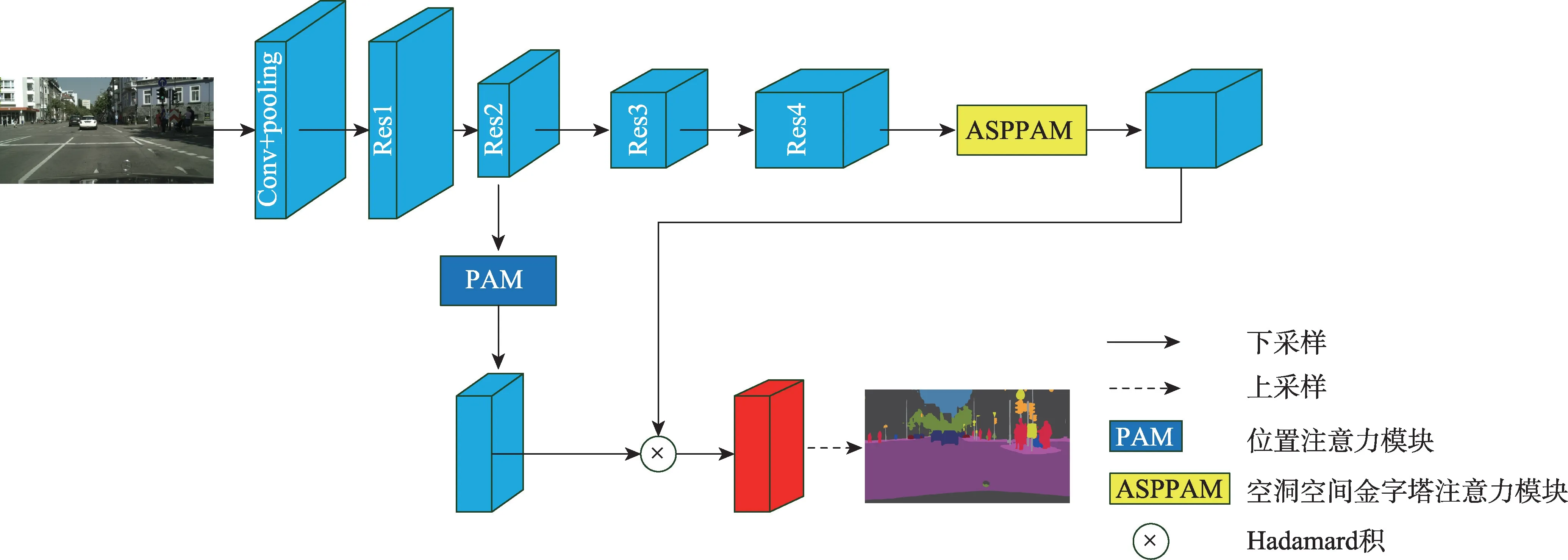
图1 CANet网络结构图Fig.1 CANet network structure diagram
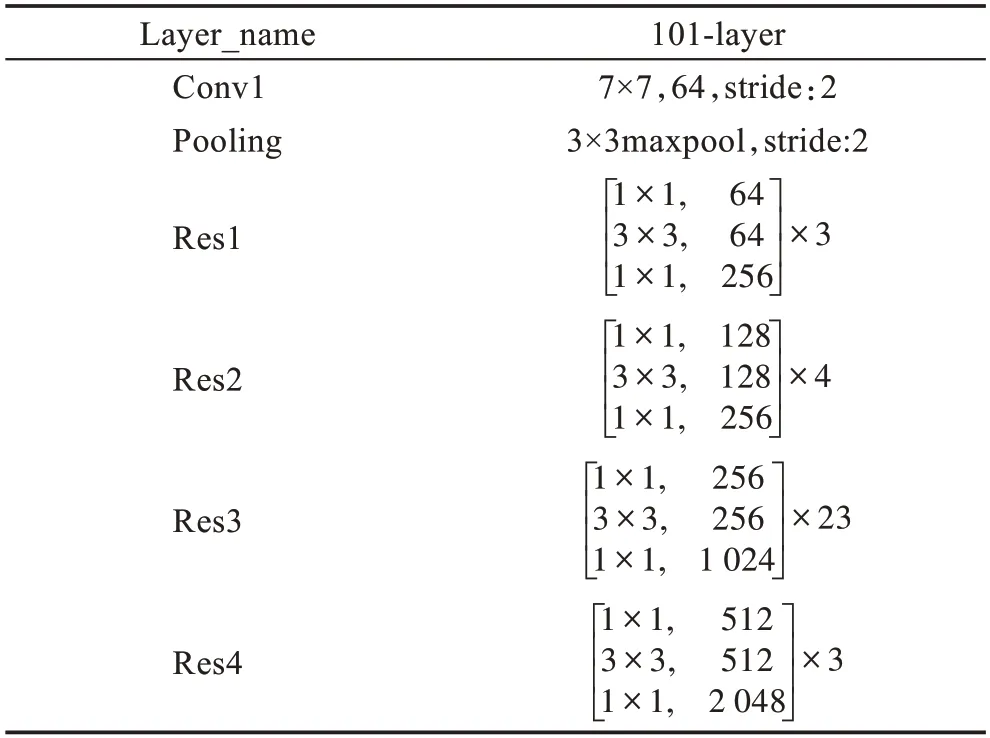
表1 ResNet-101 四个块的结构Table 1 Four blocks structure of ResNet-101
2.2 空洞空间金字塔注意力模块
ASPPAM 结构将深度神经网络的部分卷积层替换为空洞卷积,在不增加参数的情况下,扩大了感受野,从而获得更多的特征信息。1×1 Conv 卷积的目的是防止空洞率过大造成卷积核参数不能完全利用的问题。针对空洞卷积造成的空间信息丢失的问题,DeepLab-v3 采用的是引入解码器结构来恢复目标的空间信息。空间信息的丢失不利于像素级的分类任务,本文采用的是在提取特征的并列结构上加入上下文注意力模块来解决这个问题。像素注意力模块的作用是增强像素之间的联系,注意力机制的作用就是将重点放在所注意的目标像素上,增强目标像素的权重,ASPPAM 模块中的空洞卷积则是获取不同尺度的上下文信息。原始图片如图2 所示,大小和通道数分别为(1 024,2 048)和3,将经过ResNet-101 提取的高级特征图可视化,高级特征图大小和通道数分别为(128,256)和512,横纵坐标为分辨率,高级特征的通道可以看作特定类的响应,将高级特征图可视化为512张单通道的图片,图3为未使用ASPPAM模块得到的高级特征图,图中部分特征图因丢失像素严重和相关类别像素的缺失导致提取特征为空,可视化结果为黑色,这个问题不利于后续像素预测任务。图4 为使用了ASPPAM 模块可视化的高级特征图,相关类别的特征更加聚集,特征为空的现象减少了很多(可视化结果为黑的特征图),丢失像素的问题得到了解决。从图4 中可以看出,所提出ASPPAM 模块起到了一定的作用。SENet(squeeze-and-excitation network)通过特征图学习特征权值,然后通过单位乘的方式得到一个加权后的新的特征图,采用池化操作来传播注意力特征图,但是忽略了像素本身就具有一定的关系。

图2 原始图片Fig.2 Original picture

图3 未使用ASPPAM 提取的高级特征图可视化结果Fig.3 Visualization results of advanced feature map extracted without ASPPAM

图4 使用ASPPAM 提取的高级特征图可视化结果Fig.4 Visualization results of advanced feature map extracted with ASPPAM
PSAM 通过计算特征图中每个像素之间的联系,得到一个经过细化之后的特征图。并列结构的四个分支通过收集来自不同感受域的信息获得更多的上下文信息,然后和经过PSAM 得到的细化特征图合并,最终目的是通过结合细化特征图和全局特征图来增强像素之间的依赖性和类之间的区分。该模块结构如图5 所示,计算方法如式(1)~(3):

图5 像素相似注意力模块Fig.5 Pixel similar attention module
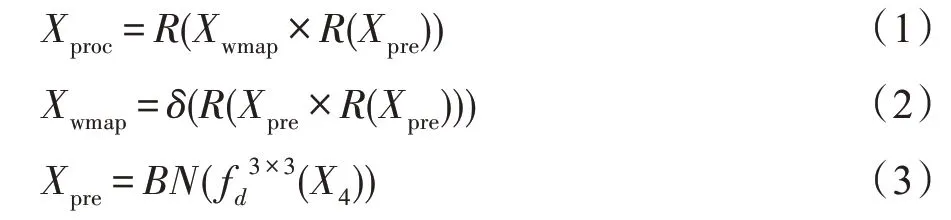
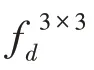
把上述得到特征图融入到ASPP 模块,该结构如图6 所示,计算方法如式(4)~(7):

图6 空洞空间金字塔注意力模块Fig.6 Atrous spatial pyramid pooling attention module
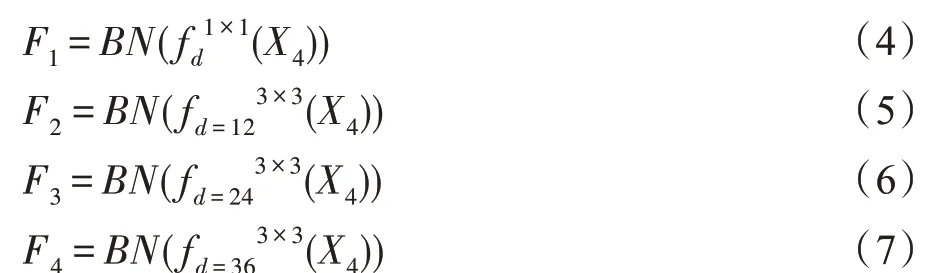
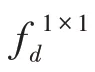
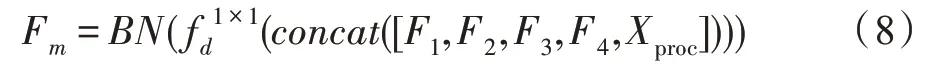
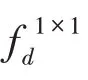
2.3 位置注意力模块
高级特征具有非常丰富的语义信息,低级语义信息保留了更多的细节,融合高级特征和低级特征可以更好地处理图像的边缘和细节,DeepLab-v3+中提出了一种有效的解码结构。SENet 提出的SE 模块在通道维度上做聚合操作,这种注意力机制可以更加注重信息量最大的通道特征,抑制不重要的通道特征。受到CBAM 和SENet 启发,本文提出的PAM模块,将高级特征和跳跃层的低级特征通过相应点的像素的Hadamard 积(矩阵中对应元素相乘)融合,利用高级信息指导低级信息,可以得到很好的分割性能。设计结构如图7 所示,图7 中“low feature”的蓝色块是来自ResNet第二个块的特征图,“high feature”绿色块是经过ASPPAM 处理过的高级特征图。相对应的计算方法如式(9):
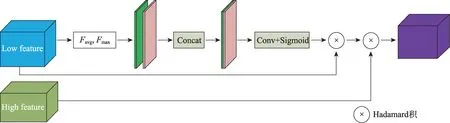
图7 位置注意力模块Fig.7 Position attention module
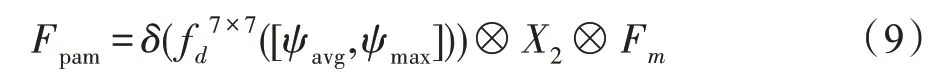
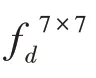
3 实验结果和分析
本章先介绍实验使用的数据集、评估指标和网络参数设置,然后与现有的注意力语义分割网络进行对比,最后进行实验分析。
3.1 实验数据集与评估指标
本文使用常用的公共数据集Cityscapes 语义分割数据集,从全世界50 个不同城市的街道场景中收集5 000 幅高质量的像素级标注的大型数据集,其中训练集、验证集和测试集分别由2 975、500 和1 525张图像组成。数据集分为大类和小类,大类包括地面、建筑、人、天空、自然、背景、道路标志和车辆。小类包含33 个类别,本文只使用了19 个类别,图片分辨率均为2 048×1 024,彩色图片均为RGB 3 通道。数据集还提供20 000 张粗注释的图像用于训练弱监督分类网络的性能。
本文使用常用的语义分割评估指标mIoU(mean intersection over union),图像像素每个类的IoU 的值累加后的平均值。详细的计算公式如下:
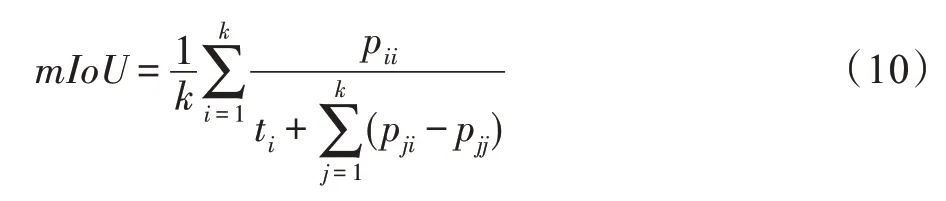
其中,表示像素的类别数;p表示实际类别为,实际预测类别也为的像素的数目;t表示类别为像素的总数;p表示实际类别为,实际预测类别为的像素的数目。
3.2 网络参数
本文使用深度学习框架Pytorch-1.4,并实现了文章所提出的网络模型。图片预处理使用了随机尺度调整、随机裁剪和随机翻转等方法对训练数据进行处理,并将图像的大小调整为769×769 作为网络输入,将经过PAM 模块和ASPPAM 模块处理后的特征图和标签间的像素级交叉熵损失相加作为网络的损失函数。在两个Tesla-T4 GPU 上使用带动量的随机梯度下降优化算法训练本文网络,批处理大小为2,初始学习率设为0.01,动量和衰减系数为0.9和0.000 5。
3.3 实验结果分析
将ASPPAM 模块和PAM 嵌入到FCN 上,计算像素之间的依赖关系,本文所提结构ASPPAM 和PAM在Cityscapes 验证集上的结果如表2 所示。为了验证注意力模块的性能,本文对两个模块进行消融实验,ResNet-baseline 的mIoU 为68.1%,ResNet-baseline 的FPS(每秒传输帧数)为25。与基本的ResNet-baseline相比,在ResNet-baseline 基础上加入ASPPAM 模块的mIoU 为73.8%,提高了5.7 个百分点,因为ASPPAM增加了计算量,所以FPS 降低了3 帧。而PAM 模块目的是细化边缘与细节,分割性能提升不明显,在ResNet-baseline 基础上加入PAM 的mIoU 为69.3%,提高了1.2 个百分点,PAM 的计算消耗小,FPS 降低1帧。本文也将没有经过任何改进的ASPP模块进行了实验,其mIoU 为70.7%,FPS 为23 帧。实验结果表明,ASPPAM模块对场景分割有很大的帮助,FPS帧数变化较小。考虑到计算成本,最终使用下采样率为8的ResNet-101为骨干网络,表2结果均来自Cityscapes官方提供的工具包Cityspacescripts计算得出。

表2 两个模块对网络性能的影响Table 2 Impact of two modules on network performance
与当前先进的网络进行了比较,数据集为Cityscapes 的测试集,将官方提供的测试集图片通过本文网络预测出分割图,经过官方测试,结果如表3 所示。
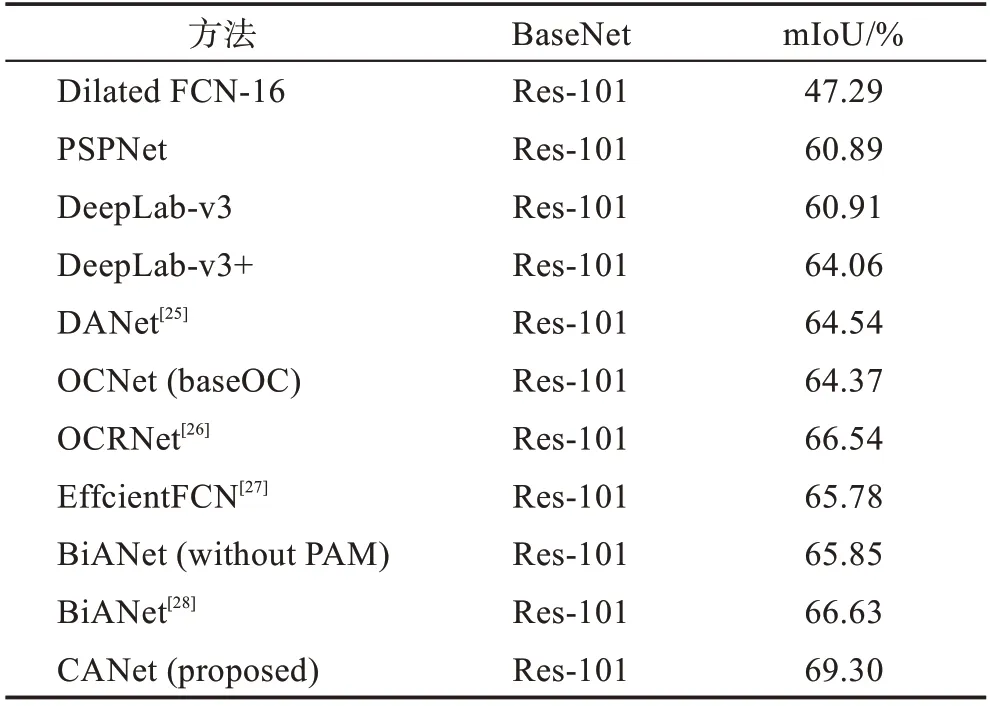
表3 与各种先进网络的比较Table 3 Comparison with various advanced networks
表3中,本文提出的注意力机制的mIoU为69.30%,显著改善了以往FCN 网络的性能。ASPPAM 模块在该数据集的验证集上比基准网络提高了5.7 个百分点。同时,本文与当前比较流行的网络进行了比较:相比于原始的Dilated FCN-16,本文模型提高了接近22个百分点的性能;和含有ASPP 的DeepLab-v3 相比,本文性能提升了5 个百分点;和最新的双边注意网络BiANet 相比,本文性能提升了3 个百分点。本文网络两个模块强调了像素之间的依赖性和低层次空间的细节。该方法在Cityscapes测试集获得了更好的性能。在数据集上预测的19 个类别的准确率如表4所示,CANet的Bus和Train的分割精度显著提高,一些细小物体相比于其他网络分割精度有所提升。

表4 Cityscapes验证集上各个类别的准确率Table 4 Accuracy of each category on Cityscapes verification set %
本文提出的两个模块对网络性能影响的可视化图如图8 所示,可见ResNet-baseline 中有误分的模块,并且一些边缘细节分割不是很连贯。误分造成的原因是ResNet-baseline 中没有多尺度信息,造成比较大的物体会产生误分的现象。比如:绿化带里面混有人行道、天空里面混有植物等,加入了ASPPAM模块后,误分的现象减少了,原因是增强了像素之间的依赖信息,并且由于空洞卷积的原因,增加了多尺度的上下文信息,这样误分的信息大大减少。添加PAM 模块后,低级特征图保留了边缘信息,补充缺少的边缘信息,经过上采样后进行预测,对物体边缘预测提供了一定的帮助。如交通标识牌等在分割图中可以得到直观的比较。
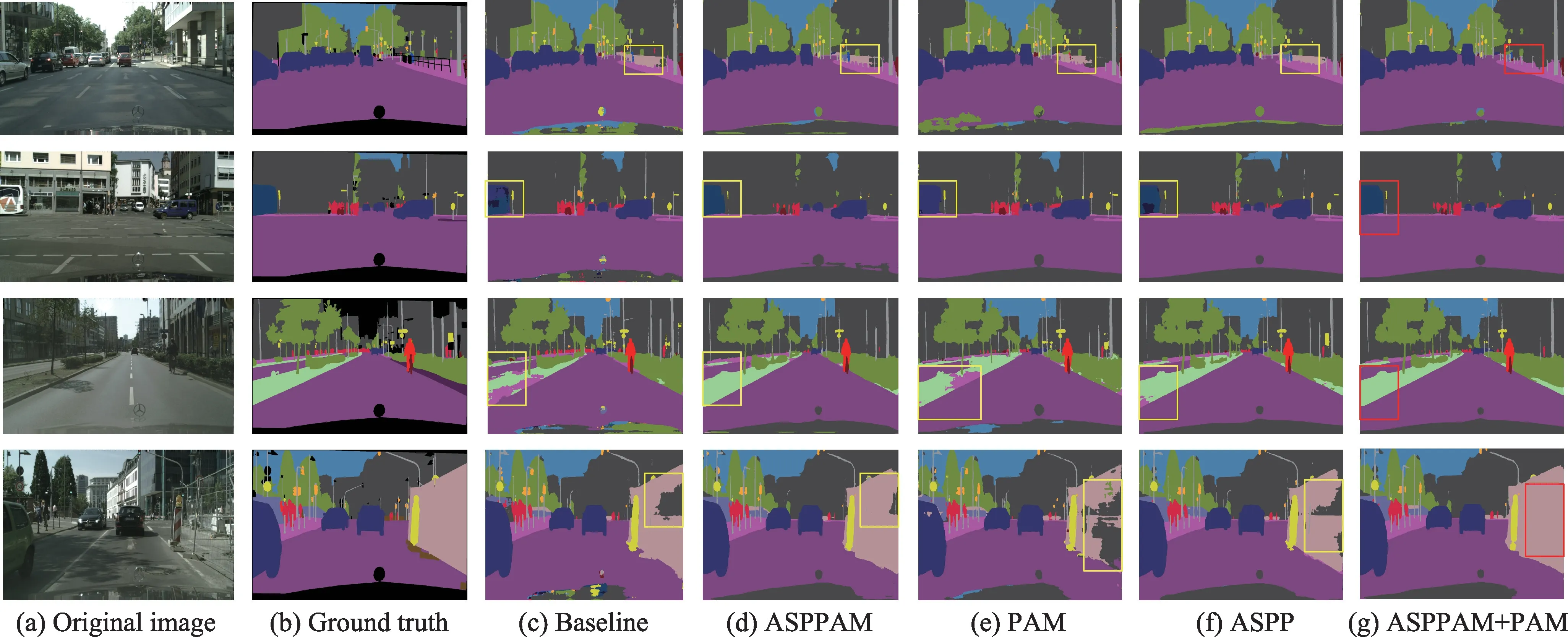
图8 消融实验结果可视化Fig.8 Visualization of ablation experimental results
网络的参数分析:网络主干网络采用的是ResNet-101,网络输入为3 通道的769×769 的彩色图片,分析整个网络的参数(MB)和计算复杂度(GFLOPS),Else 表示最后改变通道数所用卷积和ResNet-101 开始所用卷积的参数量和计算复杂度,括号内百分数为该项在整个网络中的占比,整个网络的参数量和计算复杂度如表5所示。数据是在一张Tesla-T4 GPU显卡上测试的本文模型,输入为3 通道的769×769 的彩色图片,FPS 为20 帧。
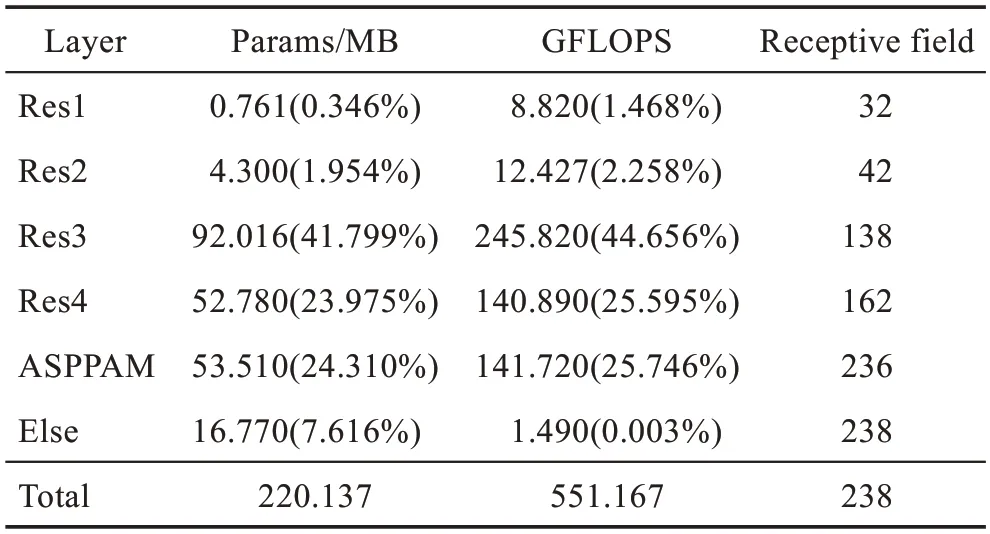
表5 网络参数表Table 5 Network parameters
4 结束语
本文提出了一种改进的全卷积网络(FCN)语义分割方法,并且提出了两个注意力模块:空洞空间金字塔注意力模块(ASPPAM)和位置注意力模块(PAM)。空洞空间金字塔注意力模块增加了用以计算像素之间的依赖性的模块,提高分割精度,位置注意力模块用以融合低级语义信息,补充下采样时丢失的信息。评估和实验结果表明,与PSPNet、OCNet、DeepLab-v3、BiANet等网络相比,采用ASPPAM 模块和PAM 模块具有更好的性能。未来考虑怎样改进骨干网络ResNet来进一步提高分割效果。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
今日农业(2021年11期)2021-11-27
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
学生天地(2020年18期)2020-08-25
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
故事作文·高年级(2017年2期)2017-03-01
长江学术(2016年4期)2016-03-11
人间(2015年21期)2015-03-11
