
联合RMSE损失LSTM-CNN模型的股价预测
2022-05-15 06:35方义秋葛君伟
计算机工程与应用 2022年9期
方义秋,卢 壮,葛君伟
重庆邮电大学 计算机科学与技术学院,重庆400065
金融市场起着社会资源再分配的重要作用,其健康良性发展有利于增加社会投资热情,加快经济建设的进程。如今,我国金融市场建设日趋完善,因交易产生了海量的数据,再加上算力大幅度提高,催生了金融从业者和研究人员使用机器学习和深度学习的研究热情。
经过历代研究人员的不懈努力,目前已经开发出很多算法用于股票预测。早前,差分自回归移动平均(autoregressive integrated moving average model,ARIMA)模型[1]因其统计特性被众多研究人员用于时间序列预测。然而,ARIMA 模型只能提取数据中的线性特征,在对具有高度非线性特征的股票数据研究中,适合提取非线性特征的机器学和深度学习方法逐渐占据主流。机器学习算法中的支持向量机(support vector machine,SVM)因其训练过程类似于求解线性约束的二次规划,得到的解,本身就是最优解,避免了非线性模型中经常遇到的局部极小值、过度拟合和维数灾难等问题[2],在股票预测研究中也逐渐火热起来。其中,将SVM用于时间序列分析也被称作支持向量回归机(support vector regression,SVR)。但是,SVR 依然存在核函数选择、参数太多调优困难、提取浅层特征等问题[3]。深度神经网络传递的层数更多,结构更复杂,能将数据中的浅层信息,转化为更抽象的高特征信息[4],性能强大,适用性广泛。循环神经网络(recurrent neural network,RNN)能够处理时间序列数据中的依赖关系,因此被用于股票预测研究中。然而,RNN 在训练过程中会出现,损失函数的梯度随时间呈现指数下降,也即梯度消失的问题[5]。LSTM 在RNN 的基础上增加了可以对单元进行控制的门限结构,从而可以处理长时间的时序数据,同时又能遗忘那些不重要的特征信息[6]。这正好符合研究人员渴望从大量历史股票交易数据中一探究竟的心理预期,因此,各种和LSTM 有关的预测算法接踵而来。CNN主要在图像识别、文本识别、目标识别和目标检测等领域有广泛应用[7],因其能提取数据中的局部特征和深层特征的特点[8],可以将股票时序预测转换为图像分类,用于股票预测。BP 神经网络将每次迭代产生的误差向前传导,具有很好的非线性拟合能力[9],在研究股票的内在规律方面有着广泛的应用。
金融市场十分复杂,毕竟决定股票价格的涨跌并非只有账面数字,还有本身就十分复杂的人为因素,例如舆论导向、政治环境和新闻事件。这形成了股票数据高噪声、难预测的特点。单一模型在考虑如上因素时,不会面面俱到,当然,模型自身固有属性也是原因之一。最近,大量研究人员试图通过模型-模型和方法-模型这样的组合,来达到考虑问题更加充分,预测更加准确的目的。针对股票数据中高维非线性的特点,Yu等人[10]利用局部线性嵌入(local linear embedding,LLE)将处理过的数据输入BP 神经网络,在与单一BP、主成分分析PCA-BP(principal component analysis,PCA)和ARIMA的对比中发现,LLE-BP 的预测精度更好。神经网络的性能会受到时间窗口、批处理大小和隐藏层单元数目等诸多因素的制约,容易陷入局部最小值。而且,这些参数的调节往往依赖有经验的研究人员手动调节,耗时费力,浪费计算机资源。宋刚等人[11]提出了一种基于自适应粒子群优化(particle swarm optimization,PSO)的LSTM 股票价格预测模型(PSO-LSTM),减少了人为因素的影响,提高了模型的预测性能。金融市场对新闻事件十分敏感,投资者的行为会受到舆论的影响,造成股价拐点的发生。现有模型很难考虑到这方面的因素,因此,在拐点发生时,模型会产生误判,相比市场真实的反应,往往具有一定的滞后性,这也是目前研究人员想要突破的难点之一。徐月梅等人[12]提出了一种基于CNNBiLSTM(bi-direction long short term memory)模型,利用CNN提取新闻文本中的特征和BiLSTM判别文本数据中的情感极性,提高了模型预测精度。贺毅岳等人[13]则利用自适应噪声完备集合经验模态分解(complete ensemble empirical mode decomposition with adaptive noise,CEEMDAN)将股市指数分解为高频分量、低频分量和趋势项,分别建立LSTM模型,再加和集成各模型的预测值,最终发现此模型的预测误差更小,时滞性更低。党建武等人[14]将CNN从股指数据中提取到的隐藏特征输入到门控循环单元(gated recurrent unit,GRU)做进一步的训练,得到了更好的预测效果。
LSTM 神经网络的细胞单元具有存储数据进行顺序学习,在时序特征提取方面具有巨大优势,显示出更为优异的成绩,许多研究将其视为一个基准模型[15]。CNN 在挖掘数据中的局部特征和深层特征具有优势。本文结合LSTM 和CNN 各自的优势,提出联合RMSE损失LSTM-CNN 模型,并建立了BP、LSTM、CNN 和LSTM-CNN融合模型作为对比。最终通过五个模型在浦发银行、沪深300指数和上证综指三个数据集上的实验结果,证明了本文所提联合RMSE 损失LSTM-CNN模型具有良好的有效性和普适性。
1 数据表示与处理
1.1 特征选择
神经网络的输入项是输出项的影响因素,而股价是输出项,所以输入项应该是那些与股价有关系的影响因素。影响股价涨跌的因素很多,针对个股预测总结起来大体上为与股票交易相关的各类基本交易数据如:开盘价、最高价、最低价、收盘价、昨收价、换手率、涨跌幅、成交量和成交额等。进一步,根据基本交易数据提炼出来的交易类指标,它主要是根据价格和成交量衍生出来的技术指标以及大盘指数这类指标;此外,基本面因素也能影响股市涨跌。基本面因素包含国家、行业经济发展的水平以及公司自身的经营水平。另一类指标是公司财务指标,包括市盈率、市净率等指标,这类指标反映了公司的经营情况与内部价值。
基本面因素缺乏量化方式,而个股当日的基本交易数据是当前情况的最好反映。因此,本实验选取最能反应股票涨跌的这9 个基本交易数据,即开盘价、最高价、最低价、收盘价、昨收价、换手率、涨跌幅、成交量、成交额。
1.2 数据集划分
实验数据使用沪深300中的浦发银行(证券代码为600000)、沪深300 股指(证券代码为399300)和上证综指(证券代码为000001)2010 年1 月4 日到2021 年3 月31日共计2 685天的股票数据进行训练和测试。数据集分为训练集、验证集和测试集三个部分,其中训练集用于训练模型,从2010 年1 月4 日到2019 年1 月11 日,占整个数据集的80%;验证集用于选择模型超参数,从2019 年1 月14 日到2020 年2 月24 日,占整个数据集的10%;测试集用于测试模型的性能,从2020 年2 月25 日到2021 年3 月31 日,占整个数据集的10%。三者的组成如表1所示。
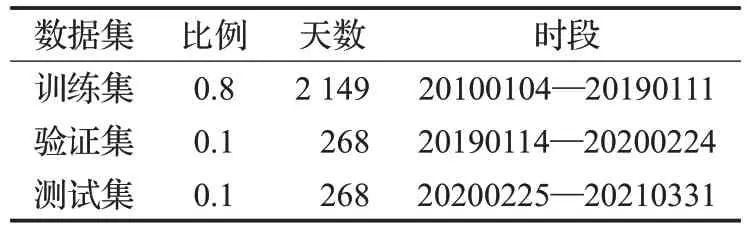
表1 数据集划分Table 1 Data set partitioning
1.3 数据处理
股票的各个交易指标具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,为了消除指标之间的量纲影响,需要进行数据标准化处理,以解决数据指标之间的可比性。原始数据经过数据标准化处理后,各指标处于同一数量级,同时又不消除数据原本的特征属性,适合进行综合对比评价。本次实验中采用最大-最小标准化的方式处理数据,标准化公式如式(1)所示:

1.4 训练数据的表现形式
实验数据将同一种数据分成两种不同的表现形式,即用于LSTM 模型训练的文本形式,和用于CNN 模型训练的图像形式。为了保证两种训练数据形式的独立性,将以上9个交易数据分为两部分。
1.4.1 股票数据的文本表现形式
LSTM 中使用的数据应是要提取的时间序列数据的时序特征。在这项研究中,选择6个关键基本交易数据作为对LSTM的输入。用pre_close、change、pct_chg、volume、amount、close分别表示昨收价、涨跌额、涨跌幅、成交量、成交额、收盘价。
如图1所示,设置窗口长度为30天,滚动窗口长度为1天,预测期设置为5天。这意味着,将根据每天的当前时间点,通过查看之前30天的数据,预测5天后的股价。这些设置也适用于CNN时间序列数据的窗口长度和预测长度。训练数据的输入和输出组成结构如图2所示。

图1 窗口长度、预测窗口长度和整个采样周期滚动窗Fig.1 Window length,prediction window length and whole sampling period rolling window

图2 训练数据的输入和输出组成结构Fig.2 Input and output components of train data
1.4.2 股票数据的图像表现形式
使用股票时间序列数据中的开盘价、最高价、最低价、收盘价、成交额,创建了股票图表图像作为CNN 的输入,如图3所示。
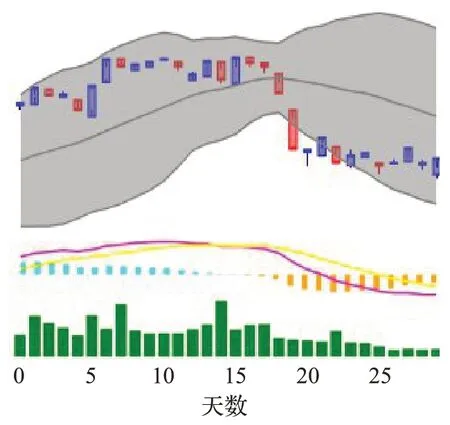
图3 由30天股票数据所生成的图像Fig.3 Image generated from 30 days of stock data
图3上方的柱状部分是由最高价、最低价、开盘价、收盘价组成的烛台图。图上方的灰色条带为布林带,由布林线指标中的上轨线、中轨线和下轨线组成。布林线指标利用统计学原理,求出股价的标准差和信赖区间,从而去确定股价波动的范围和未来走势,利用波段显示股价的安全高低价位。
图3 中间的曲线和柱状部分是由指数平滑异同移动平均线(moving average convergence/divergence,MACD)中的MACD 线、信号线、离差图组成。MACD是股票交易中一种常见的技术分析工具,用于判断股票价格变化的强度、方向、能量,以及趋势周期,以便把握股票买进和卖出的时机。
图3最下方的柱状部分,由交易量数据组成。为了将数据输入CNN,调整并裁剪这些图像为112×112像素。
2 模型结构和原理
2.1 LSTM原理和建模
2.1.1 LSTM原理和结构
RNN最初用于学习时间序列数据的序列模式。然而,随着网络的加深而出现的消失梯度问题并没有得到解决。解决这个问题的网络是LSTM。
LSTM 是一种递归神经网络,适用于从时间序列中提取时序特征,具有学习长期时间序列依存关系的能力。
LSTM 的结构如图4 所示。一般,LSTM 由输入门it、遗忘门ft、输出门ot这3个门组成。Ct为当前细胞单元的状态,ht为隐藏层的状态,xt为输入数据。

图4 LSTM结构Fig.4 LSTM structure
结构的输出向量包含当前细胞单元状态向量和隐藏层状态输出向量。结构的输入包含上一时刻细胞单元的状态向量、上一时刻隐藏层输出向量和当前时刻的输入数据3个向量。LSTM网络先经过遗忘门计算上一单元的被遗忘程度,0 表示完全舍弃,1 表示完全保留;下一步是输入门,决定有多少信息需要输入到单元中,然后更新单元状态;输出门的作用是决定需要输出的部分;最后再进行误差反向传播。下列运算公式中,运算符“·”代表向量外积,“+”代表向量叠加运算。
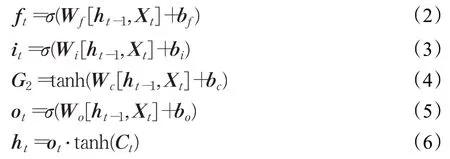
2.1.2 LSTM模型构建
为了提取股票时间序列数据的序列特征,设计了LSTM模型。数据生成为堆叠数据类型,以便数据可以同时输入。该模型被设计用来预测t+5 时刻的收盘价,使用的值从t-30 到t。
根据研究,LSTM 为两层时所表现的结果最佳[16]。构造两层全连接层,以提高非线性预测能力。基于此使用两层LSTM和两层全连通层构建模型,提高模型非线性预测能力。图5为LSTM建模。
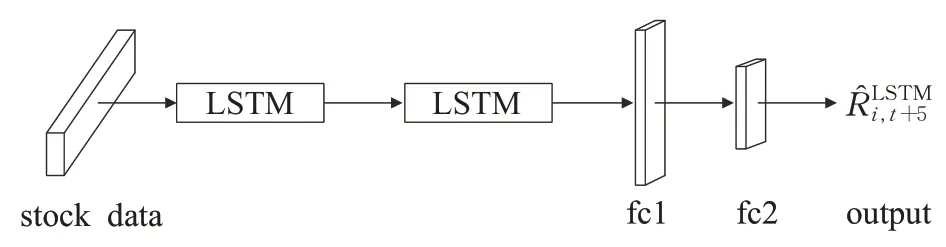
图5 LSTM模型Fig.5 LSTM model
2.2 CNN原理和结构
2.2.1 CNN原理
CNN对输入数据进行逐层卷积和池化操作。卷积层是CNN 的核心,它利用局部连接和权值共享对输入进行卷积操作,提取数据的深层特征[14]。卷积过程可以用以下公式表示:

其中,C为卷积层的输出特征图,X为输入数据;f(·)为非线性激活函数;U为卷积操作;W为卷积核的权重向量,b为偏置项。
池化层通过一定的池化规则对卷积层的输出执行池化操作,保留主要特征,同时减少参数数目和计算量,防止过拟合。池化过程可以用以下公式表示:

其中,p表示池化层的输出特征图;pool(·)表示池化规则,如平均池化、最大池化等。
CNN 的特点是能够提取数据中的隐藏特征,并将其逐层结合,生成抽象的高层特征。然而,CNN不具备记忆功能,缺乏对时序数据时间相关性的考虑。
2.2.2 CNN模型构建
通过深化网络,可以提高网络的性能。但是,会出现由于消失梯度问题而产生的过拟合和退化问题。因此,在保持网络深度的同时,使用一种防止过拟合和退化问题的方法变得非常重要。这里使用残差学习和瓶颈方法[17]克服这一问题。
利用残差学习和瓶颈方法设计了图6 所示的有三个权重层的bottleneck 构建块。如图6 所示在快捷连接的情况下,输入X通过激活函数映射到特征F(X),而不经过权值层。公式(9)中,H(X)或F(X)-X被视为一个优化的映射,X是一个输入矩阵,F(X)和H(X)是输出矩阵。

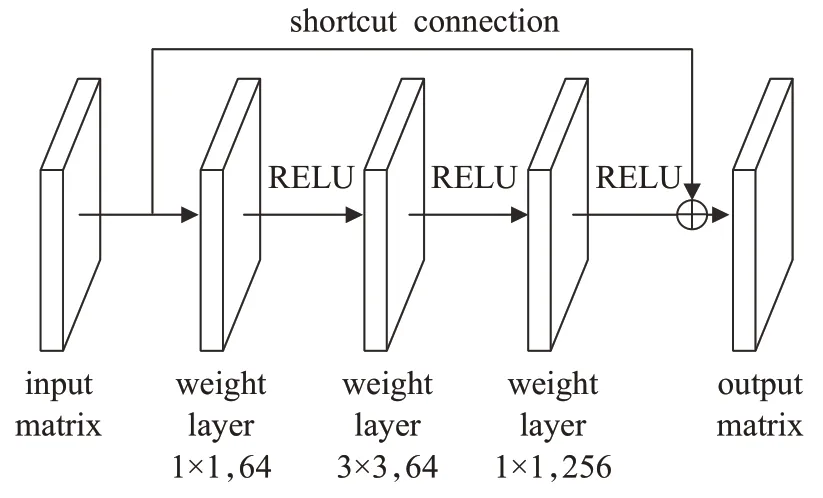
图6 bottleneck构建块Fig.6 Bottleneck building blocks
基于上述理论构建CNN 模型,如图7 所示。其中conv1、conv2、conv3 为卷积层,fc1、fc2 和fc3 为完全连接层。
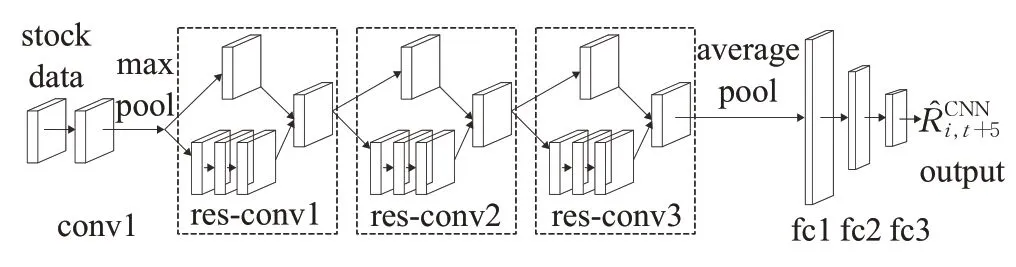
图7 CNN卷积建模Fig.7 CNN convolution modeling
在输入阶段,调整股票图表图像的大小为112×112像素,然后调整卷积和完全连接层的数量以及各种超参数,如卷积的维数、神经元的数量、完全连接层和dropout比例等。
表2显示了经过反复实验优化的CNN模型的结构。
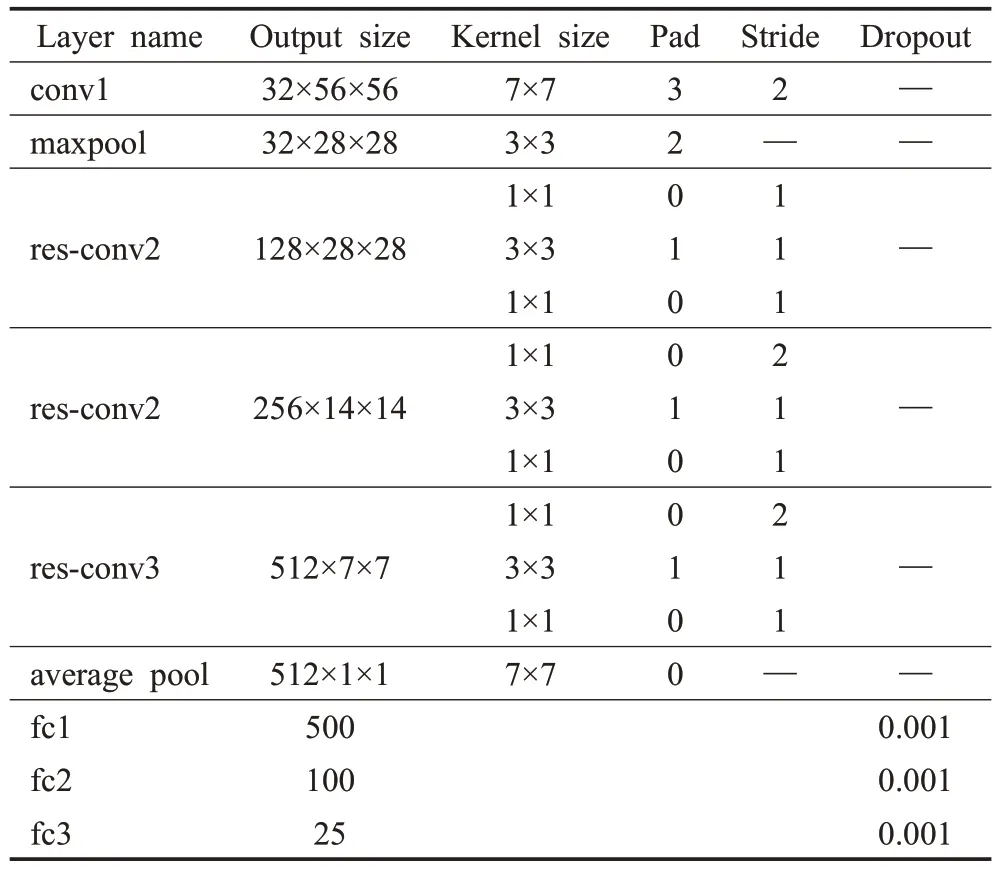
表2 CNN模型参数Table 2 CNN model parameters
2.3 联合RMSE损失LSTM-CNN结构和建模
在预测股票价格时,将股票图表图像与同一数据中的股票时间序列数据同时训练,可以使两个模型互补。图8 为提出的联合RMSE 损失LSTM-CNN 模型的体系结构,该模型的构建共分三步进行。
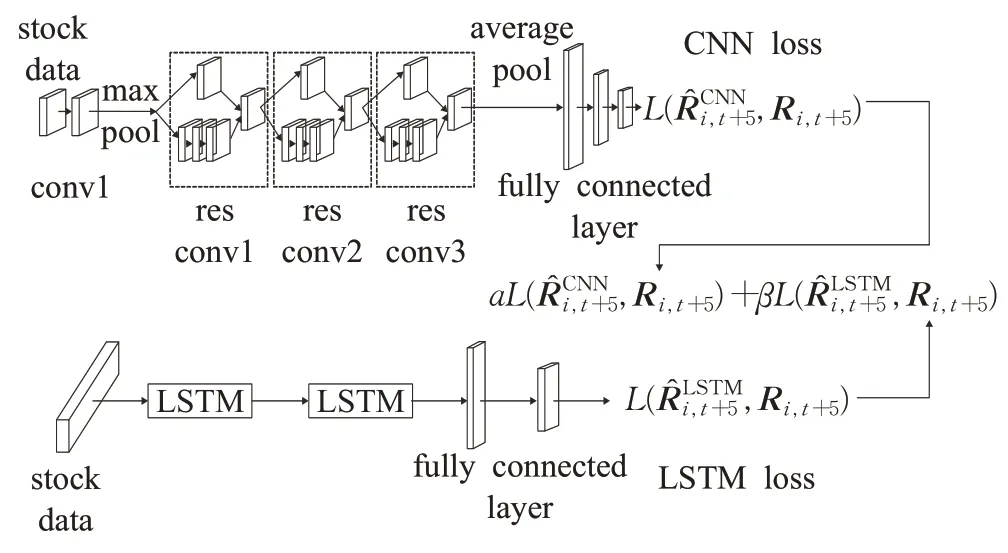
图8 联合RMSE损失LSTM-CNN模型结构Fig.8 Combined RMSE loss LSTM-CNN model structure
第一阶段采用CNN模型架构,使用与表2相同的架构。第二步是建立LSTM模型,采用图5中的结构。第三步按照一定比例联合两个模型的损失值。各模型的损失函数定义如公式(10)、(11)所示:
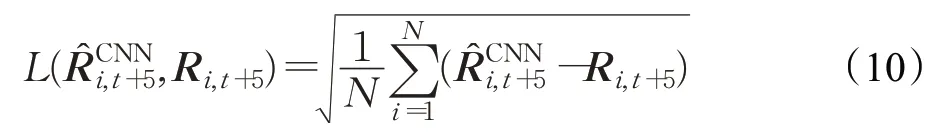
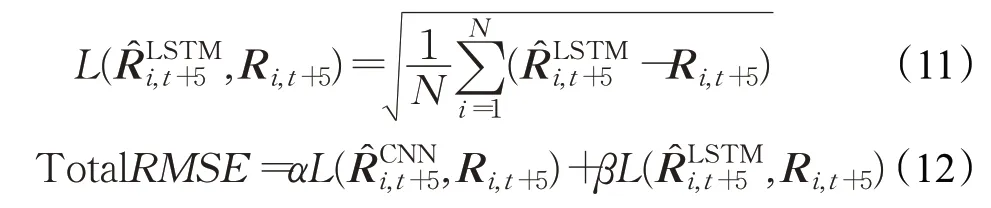
式中,N为数据点个数,为预测值,R为目标值。为CNN模型的损失函数,为LSTM 模型的损失函数。α和β值是总均方根误差的权重。这些参数反映了各模型损失的反映程度。从这两种损失中,可以使用公式(12)推导出总RMSE。在实验中发现,参数α值升高β值下降,会使模型的预测表现向CNN 模型靠近,模型预测值的局部表现会更加突出,反之,则会使模型向LSTM靠近,模型预测值的整体趋势会更加突出。而且,参数α值不易过大,β值则对模型的预测精度影响更大,但是,当β值达到一定程度时,再增大反而会影响整个模型的预测精度,所以两个值要在合理的区间内取值。经过反复实验,将参数α和β值分别设为0.1和0.9,以反映联合训练模型中LSTM的损失大于CNN 模型损失,并使所提模型的预测效果更好。此外,通过CNN和LSTM的总RMSE损失,期望产生一种正则化的效果,达到模型互补和防止过拟合。
联合模型的预测值,需要按照α和β的值加权求和,以达到两种模型互补的效果。如公式(13)所示为CNN 分支部分的预测值为LSTM 分支的预测值,为两个分支预测值的加权和。

2.4 模型评估指标
选择三个性能指标,均方根误差(root mean square error,RMSE),均方根绝对误差(root mean absolute error,RMAE)和平均绝对百分比误差(mean absolute percentage error,MAPE),来评估所提模型和各个对比模型的预测能力。RMSE大小与数值无关,是揭示相对较大预测误差的好方法,RMAE是揭示模型的系统偏差的有用方法,MAPE 大小与数值有关,是统计预测准确性的一种方法。这些方程如下所示,其中是预测值,Ri是真实值。
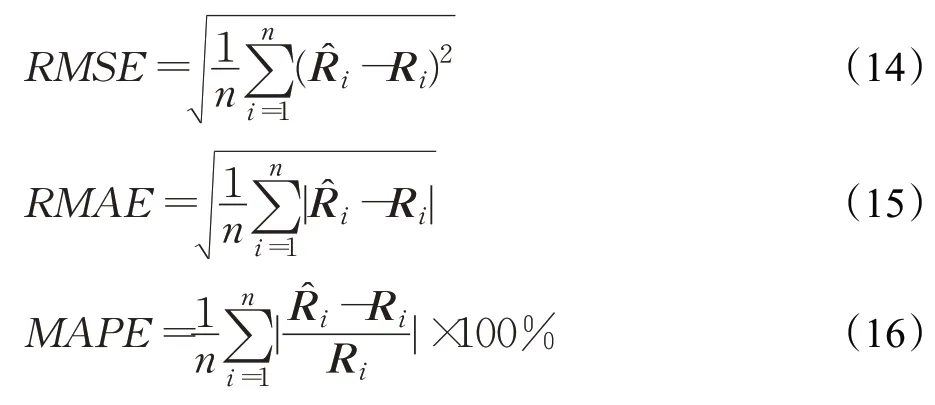
3 实验结果与讨论
为了验证联合RMSE 损失LSTM-CNN 的可行性,分别在浦发银行、沪深300股指和上证综指三个数据集上建立了BP、LSTM、CNN、LSTM-CNN 和联合RMSE损失LSTM-CNN五个模型。
3.1 浦发银行数据集上的实验结果
图9为BP模型在浦发银行测试集上的预测值与真实值对比图。从图中可以看出,BP 模型的非线性拟合能力是很优秀的,既能反映出股价局部的细微变化又能反映出整体走势。然而,缺点也是十分明显的,预测值的滞后性较高,精度低。
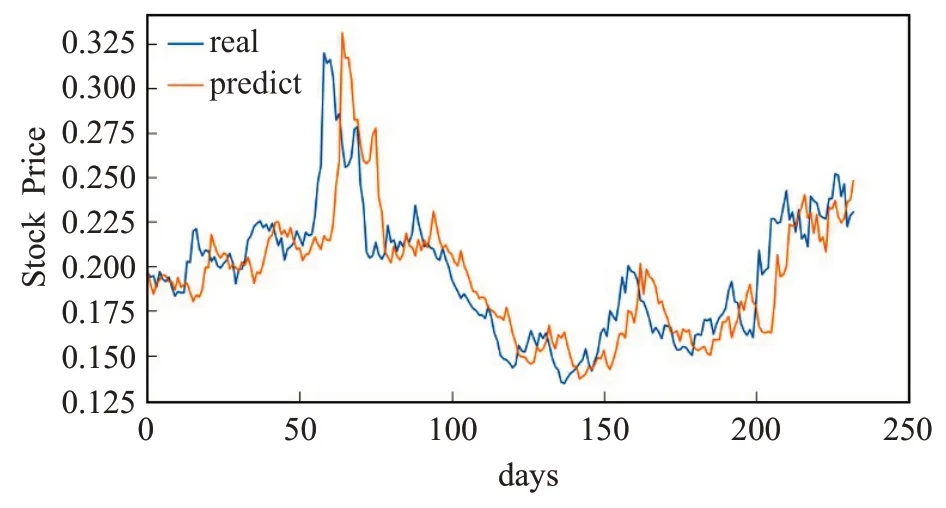
图9 BP模型的预测值与真实值Fig.9 Predicted and true values of BP model
图10 为LSTM 模型在浦发银行测试集上的预测值与真实值对比图。从图中可以看出,LSTM模型的预测效果,总体趋势和真实值接近,滞后性比BP 模型要好。但是,局部的细微表现不足,过于平缓。
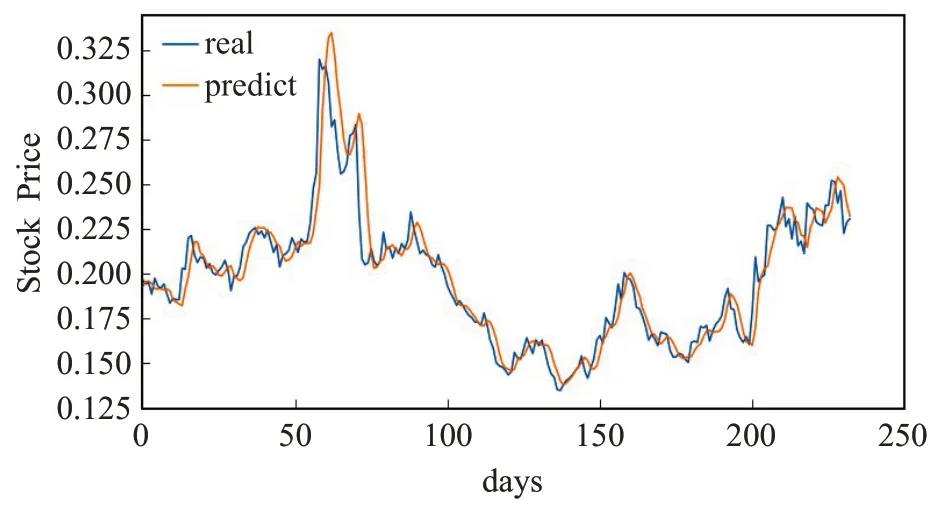
图10 LSTM模型的预测值与真实值Fig.10 Predicted and true values of LSTM model
图11为CNN模型在浦发银行测试集上的预测值与真实值对比图。由图可知,CNN模型的预测效果,虽然总体趋势表现较差,但是局部效果表现突出,能够反应出股票局部细微的变化。从另一个方面说明,CNN 模型更加适合做特征分类,也就是说在预测股价涨跌方面,预测效果会更好。
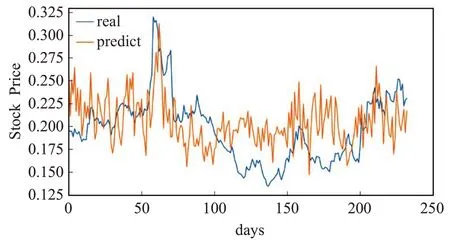
图11 CNN模型的预测值与真实值Fig.11 Predicted and true values of CNN model
图12 为LSTM-CNN 融合模型在浦发银行测试集上的预测值与真实值对比图。从图中可以看出,LSTM-CNN 的预测效果,模型表现出了CNN 和LSTM两个模型的优点,其整体趋势和局部的细微变化,均表现较好。
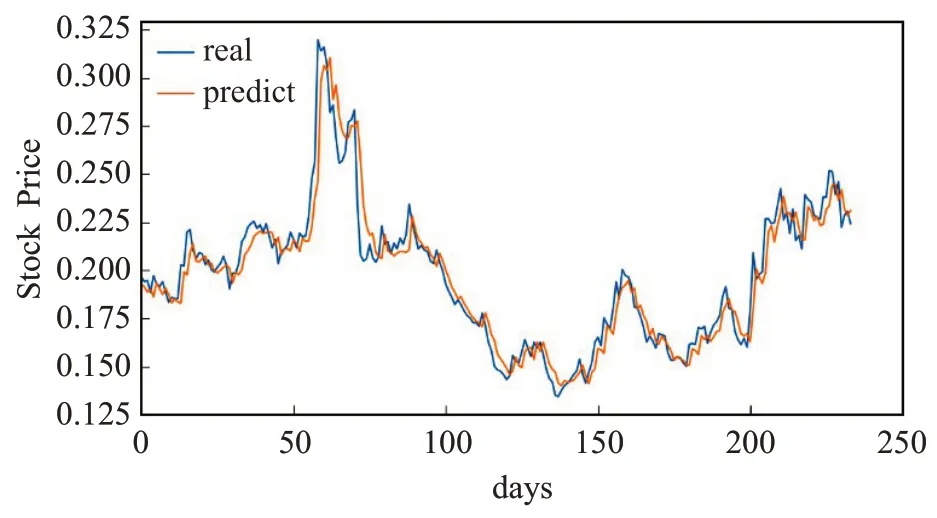
图12 LSTM-CNN融合模型的预测值与真实值Fig.12 Predicted and true values of LSTM-CNN fusion model
图13 为联合RMSE 损失LSTM-CNN 模型在浦发银行测试集上的预测值与真实值对比图。从图中显示的信息来看,联合RMSE 损失LSTM-CNN 模型同样结合了LSTM 模型和CNN 模型的优点。模型预测值的总体趋势,局部表现以及滞后性,相比上面四个模型要更好。
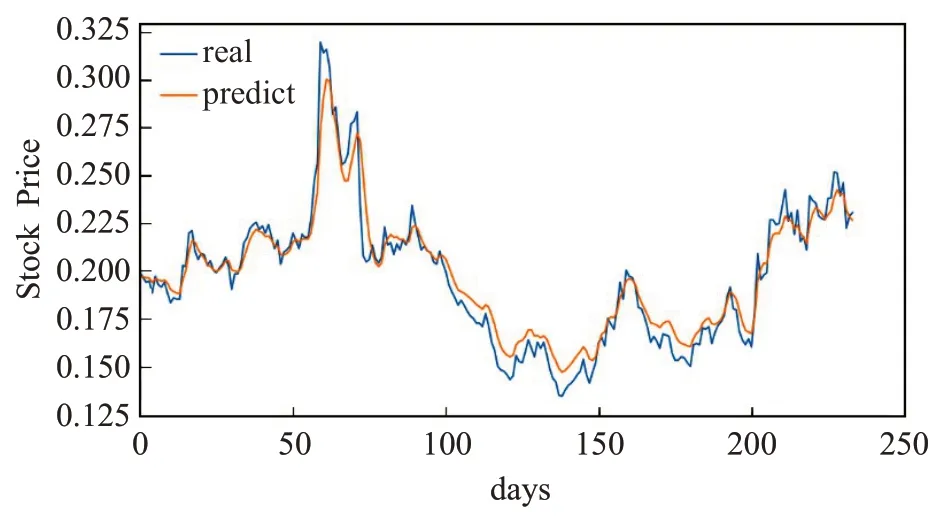
图13 联合RMSE损失LSTM-CNN 模型的预测值与真实值Fig.13 Predicted and true values of combined RMSE loss LSTM-CNN model
通过列出五个模型的RMAE、MAPE、RMSE可以更好地反映出各个模型的优劣。
根据表3 中数据,五个模型的优劣顺序如下:联合RMSE 损失LSTM-CNN、LSTM-CNN、LSTM、BP、CNN。五个模型中表现最好的是联合RMSE 损失LSTM-CNN模型。相比表现次之的LSTM-CNN,本文所提模型的RMAE值要低4.24%,MAPE值低0.04个百分点,RMSE值低16%,这也说明了所提模型具有可行性。
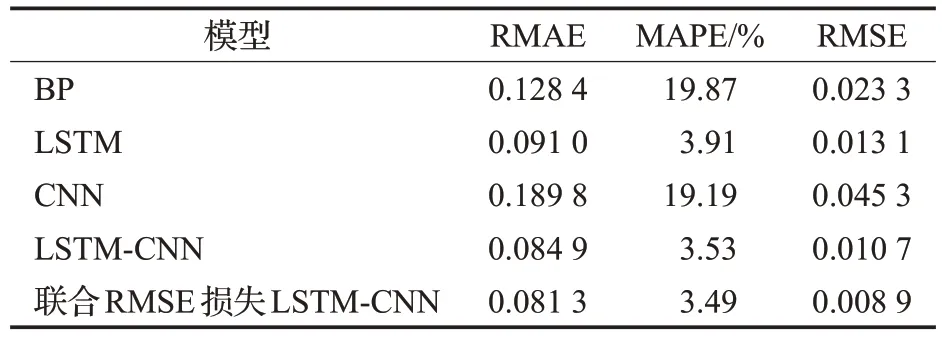
表3 不同模型在浦发银行数据集上的预测性能Table 3 Prediction performance of different models on Shanghai Pudong Development Bank data set
3.2 沪深300指数数据集上的实验结果
单一模型可能存在随机性,为了更好地探究模型,以及其存在的优缺点,在沪深300指数数据集上进实验与测试,实验结果如图14~18所示。
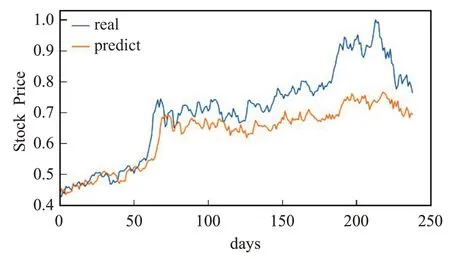
图14 BP模型的预测值与真实值Fig.14 Predicted and true values of BP model
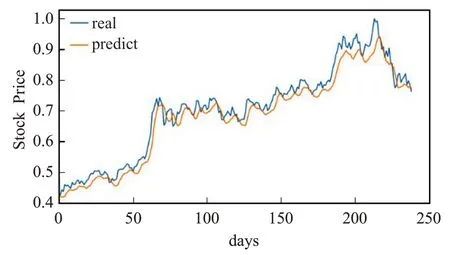
图15 LSTM模型的预测值与真实值Fig.15 Predicted and true values of LSTM model
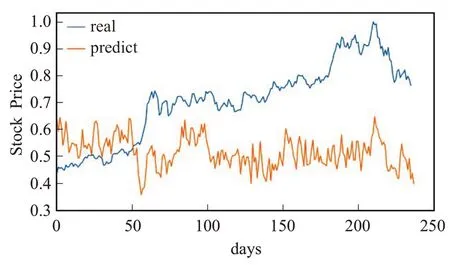
图16 CNN模型的预测值与真实值Fig.16 Predicted and true values of CNN model
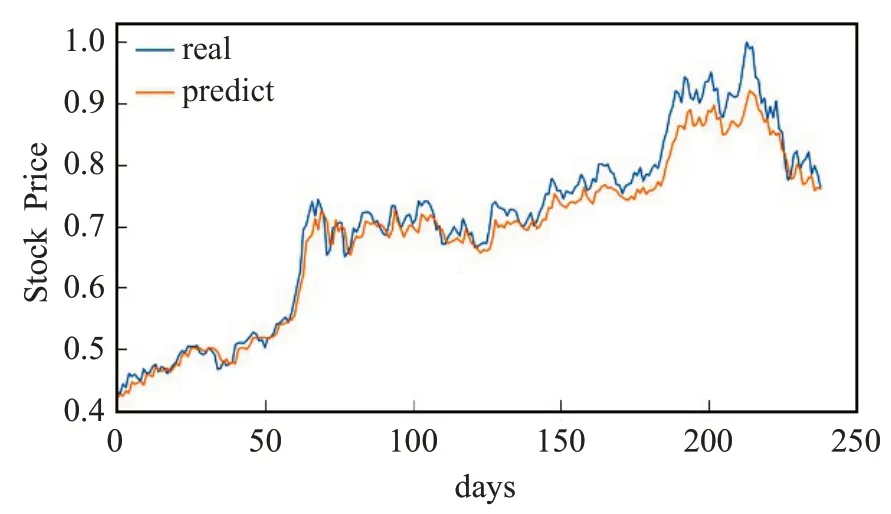
图17 LSTM-CNN融合模型的预测值与真实值Fig.17 Predicted and true values of LSTM-CNN fusion model
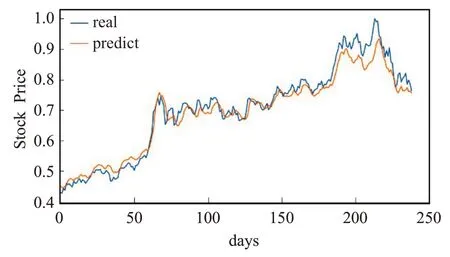
图18 联合RMSE损失LSTM-CNN模型的预测值与真实值Fig.18 Predicted value and true value of combined RMSE loss LSTM-CNN model
从图14~18 中可看出,相较于浦发银行数据集,BP模型的局部表现和整体趋势都差了很多;LSTM整体趋势较好,局部表现依旧欠佳;CNN 的局部表现良好,整体趋势较差。LSTM-CNN 和联合RMSE 损失LSTMCNN模型无论是整体趋势还是局部表现都表现得非常好,十分接近真实值。
通过列出五个模型的RMAE、MAPE、RMSE可以更好地反映出各个模型的优劣。
根据表4 中的数据,五个模型的优劣顺序如下:联合RMSE 损失LSTM-CNN、LSTM-CNN、LSTM、BP、CNN。复合模型的表现均优于单一模型,本文所提模型和LSTM-CNN 性能表现一致。其中,RMAE 值相差无几,MAPE 值低0.04 个百分点,RMSE 值低1%,整体而言略好于LSTM-CNN。
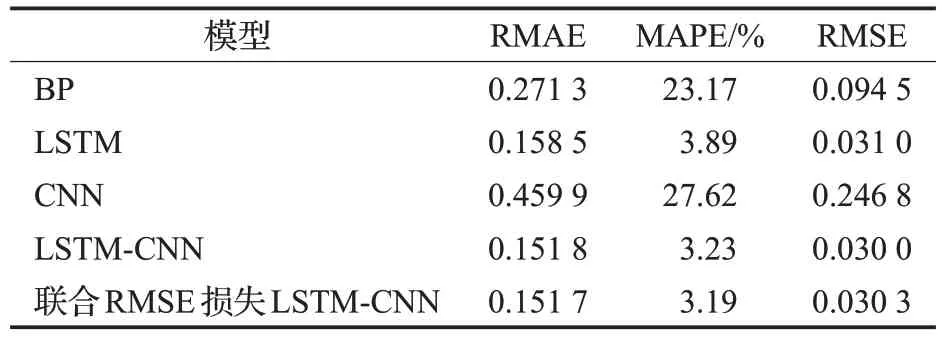
表4 不同模型在沪深300指数数据集上的预测性能Table 4 Prediction performance of different models on Shanghai and Shenzhen 300 index data set
3.3 上证综指数据集上的实验结果
五个模型在上证综指数据集上的实验结果如图19~23所示。
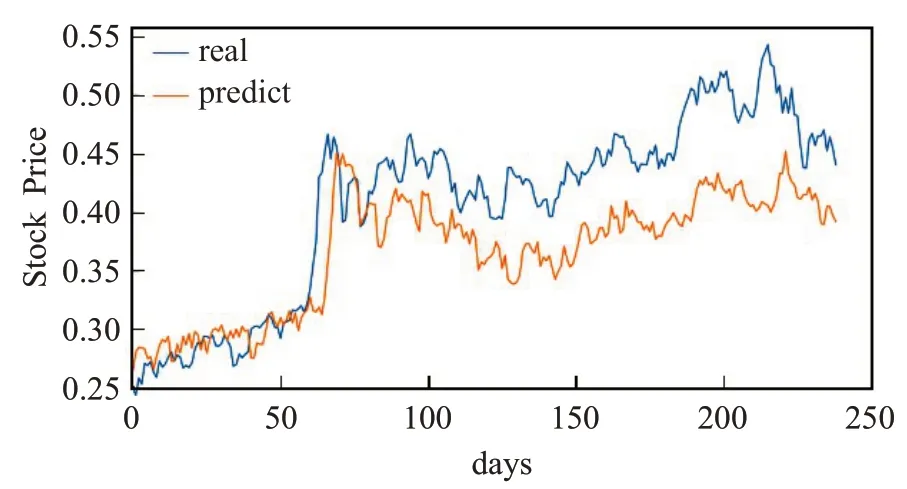
图19 BP模型的预测值与真实值Fig.19 Predicted value and real value of BP model
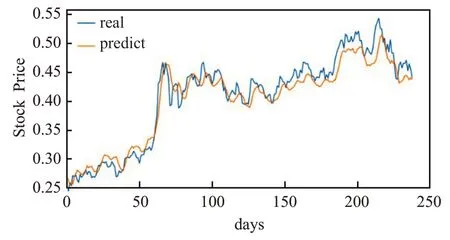
图20 LSTM模型的预测值与真实值Fig.20 Predicted value and real value of LSTM model
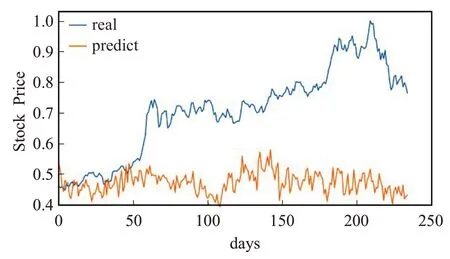
图21 CNN模型的预测值与真实值Fig.21 Predicted value and real value of CNN model
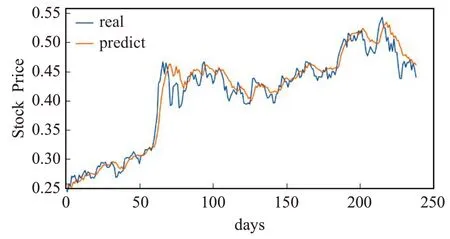
图22 LSTM-CNN融合模型的预测值与真实值Fig.22 Predicted value and real value of LSTM-CNN fusion model
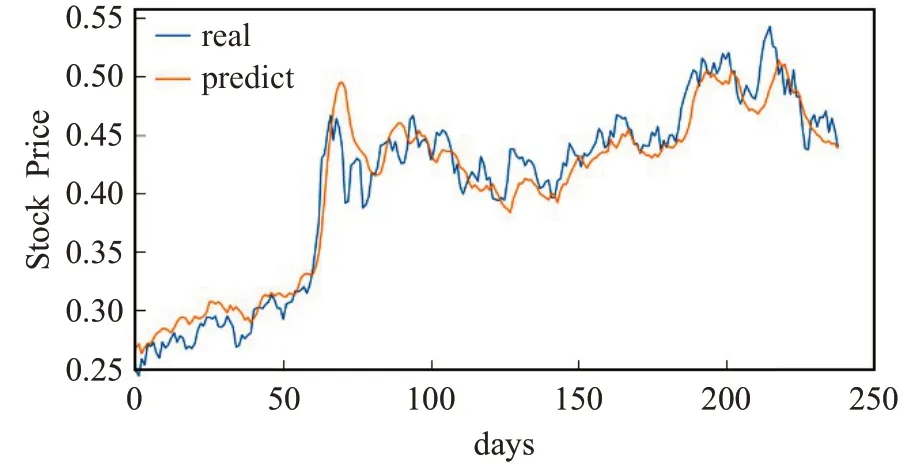
图23 联合RMSE损失LSTM-CNN融合模型的预测值与真实值Fig.23 Predicted value and real value of combined RMSE loss LSTM-CNN model
如图19~23 所示,BP、LSTM 和CNN 模型在上证综指数据集上的表现和在浦发银行和沪深300 指数数据集上的表现一致;而LSTM-CNN 和联合RMSE 损失LSTM-CNN模型的局部表现均有所下降。这可能和数据集有关,沪深300指数综合了上海证券交易所和深证证券交易所表现良好的300只股票的情况,相比上证综指要更稳定一些。通过表5 可以更加准确地看出各个模型的预测效果。
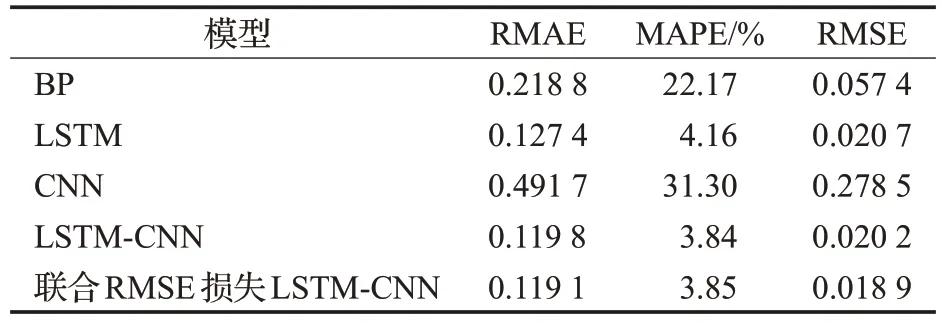
表5 不同模型在上证综指数据集上的预测性能Table 5 Prediction performance of different models on Shanghai Composite Index data set
根据表5中的数据,五个模型的优劣顺序如下:联合RMSE 损失LSTM-CNN、LSTM-CNN、LSTM、BP、CNN。其中,联合RMSE 损失LSTM-CNN 和LSTM-CNN 的表现相当,前者MAPE值比后者高0.01个百分点,而RMAE值低0.5%,RMSE值低6%,总体略好于LSTM-CNN。
综和各个模型在浦发银行、沪深300指数和上证综指三个数据集上的表现,可以看出,单一模型在做时序数据预测时,考虑到的影响因素不够全面,多模型组合预测时的表现要更好。同时也证明了联合RMSE 损失LSTM-CNN模型具有良好的有效性和普适性。
4 结语
本文提出的联合RMSE损失LSTM-CNN模型结合了LSTM提取时序特征的优点和CNN提取局部特征和深层特征的优点,在做股票预测时,既能表现出股价的整体走势,又能表现出局部的细微变化。通过在浦发银行、沪深300 指数和上证综指数据集上的表现可以得出,相比于BP、LSTM、CNN和LSTM-CNN模型,其总体趋势、局部表现和滞后性都有更好的表现。
此外,股票数据具有一定的时效性,训练数据的大小和各个数据集的比例要合理分配。模型在波动比较大的地方,预测效果有待改进。原因是真实的股票波动不仅仅受限于股票基本交易指标,而且与时事联系紧密,例如公司的经营状况、财务状况、投资人的主观意识还有新闻事件等等。将这些因素量化代入模型也可以提高模型的性能。后续还可以结合金融领域的一些数据处理和分析方法进行改进。
猜你喜欢
大学数学(2022年6期)2023-01-14
今日农业(2021年19期)2022-01-12
四川大学学报(自然科学版)(2021年6期)2021-12-27
环境保护与循环经济(2021年7期)2021-11-02
数学小灵通·3-4年级(2021年5期)2021-07-16
电子产品世界(2021年6期)2021-02-10
今日农业(2019年15期)2019-01-03
共产党员(辽宁)(2015年2期)2015-12-06
文苑(2015年9期)2015-09-10
读者·校园版(2015年19期)2015-05-14
