
应用量子行为粒子群优化算法的文本对抗
2022-05-15 06:35徐尹翔陈祺东
计算机工程与应用 2022年9期
徐尹翔,陈祺东,孙 俊
江南大学 人工智能与计算机学院,江苏 无锡214122
深度神经网络被广泛应用于图像、语音、自然语言等各个领域[1-3]。尽管如此,有研究表明深度神经网络对于对抗攻击十分脆弱[4-5],即向输入数据添加微小的扰动就能够改变深度神经网络给出的结果。例如,文献[5]中向一张熊猫图片中添加扰动后,图像的语义在人眼看来并无变化,而卷积神经网络(convolutional neural network,CNN)将熊猫识别为了长臂猿。深度神经网络的脆弱性引发了对于安全的担忧,比如在路牌上贴上面积极小的涂鸦就能让自动驾驶系统无法正确地识别路牌,可能造成严重的后果[6]。对于对抗攻击的研究可以帮助构建更鲁棒的深度神经网络,同时可以启发关于如何防御对抗攻击的研究[7]。然而,关于自然语言处理领域的对抗攻击研究远少于对于图像领域对抗攻击的研究。部分原因是图像的像素值是连续的,易于实施基于梯度的对抗攻击,且像素值微小的扰动几乎无法被人类肉眼所察觉,也不会带来图像语义的改变。而自然语言是离散的,词语的微小变化也可能导致语义的改变。深度神经网络在自然语言处理方向上的应用也十分广泛,包括垃圾邮件过滤、情感分析[3]和虚假新闻检测[8]等。因而,自然语言处理领域的对抗攻击十分具有研究价值。
目前自然语言处理领域的对抗攻击方法可以按照对抗攻击时所更改的元素分成三类:字符级别的对抗攻击、词级别的对抗攻击以及句级别的对抗攻击。关于字符级别的对抗攻击,Ebrahimi 等人[9]通过增加、删除、替换、交换字符等操作来构建对抗样本;Belinkov等人[10]通过打散单词内部的字符、用键盘上临近的字母替代等方法构建对抗样本;Hosseini 等人[11]通过在单词中增加点(.)、空格等字符来构建对抗样本。字符级别的更改往往可能造成语法的错误,而且拼写检查或者语法检查就可以防范这类攻击[12]。句级别的对抗攻击方法是通过增加句子或者复述句子来达成对抗攻击的效果。Jia等人[13]和Wang等人[14]通过在段尾增加句子来实现机器阅读理解任务上的对抗攻击。Iyyer 等人[15]通过将原始句子输入神经网络生成复述的句子作为对抗样本,这样的对抗样本基本没有语法和语义的问题,但是对输入的改动过大。Zhao等人[16]将原始输入映射到流形空间,对其添加扰动后再生成对抗样本。
词级别的对抗攻击方法一般通过替换单词进行对抗样本的构建。相对于字符级别对抗攻击方法生成的对抗样本,词级别攻击方法生成的样本有更好的语义连贯性和更少的语法错误。而相对于句级别攻击方法得到的对抗样本,词级别攻击方法生成的对抗样本的改动率相对较小,更不易被察觉。词级别对抗方法在语义语法连贯性和改动率上均能取得相对较好的效果。Papernot 等人[17]使用基于梯度方法进行攻击,随机选取替代词替换原始的输入词,这种替换方法会原始输入的破坏语义。Samanta 等人[18]和Ren 等人[19]使用同义词替换单词,可以较好地保持语义。Alzantot 等人[20]从词向量空间中寻找距离较近的词作为替换词,并使用基因优化算法搜寻对抗样本。Liang 等人[21]通过增加、删除及替换词的方法来构建对抗样本。Zang 等人[22]使用基于义原的方法来寻找替换词,然后使用粒子群优化算法搜索对抗样本,在多个数据集上取得了最佳效果。
然而,现有词级别对抗方法存在对于对抗样本的全局搜索能力较弱,易于出现“早熟”和陷入局部最优的情况,因此提升空间较大。本文提出了一种改进的词级别文本对抗方法,对搜索优化算法进行优化,采用改进的量子行为粒子群优化算法(QPSO)来更有效地搜索对抗样本,实验证明本文方法取得了较好的结果。
1 义原及量子行为粒子群优化算法介绍
1.1 义原及知网(HowNet)
义原在语言学中是指最小的不可再分的语义单位。一个词可以使用一个包含有限个义原的集合来进行表示。Dong 等人[23]使用2 089 个义原标注了约10 万个中文词及对应的英文单词,形成了义原知识库,即知网(HowNet)。知网中的每个单词都被表示为树形的结构,由于一个单词可能有多重语义,每个语义都是一个义原树。如图1所示,“笔记本”这个词含有“笔记册子”和“笔记本电脑”两种词义,在知网中两种词义都用义原表示出来,形成了树状结构。类似知识库还有普林斯顿大学构建的语义知识库WordNet。WordNet是基于单词的知识库,知网是基于概念的知识库,相对于WordNet,知网(HowNet)可以找到更多的语义相关的词。
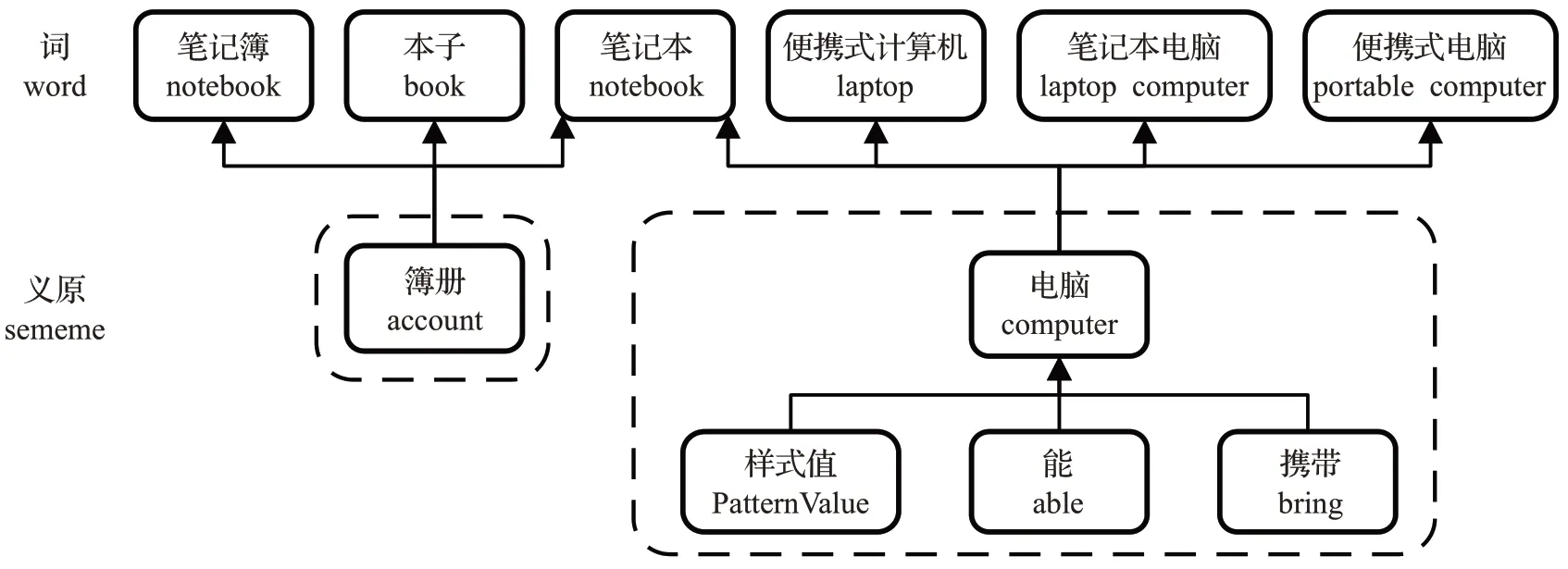
图1 笔记本(notebook)在HowNet中的义原树以及与笔记本共享相同义原的词Fig.1 Sememe tree of notebook in HowNet and other word sharing the same sememes
1.2 量子行为粒子群优化算法(QPSO)
量子行为粒子群优化算法是对粒子群优化算法[24]的一种改进算法,由Sun 等人[25]于2004 年提出,其灵感来自于量子力学理论以及对于典型粒子群的轨迹分析。量子行为粒子群优化算法是一种概率算法,其应用量子力学中的Delta 位势阱模型来约束粒子,其粒子仅更新位置,没有速度的概念,更新方程与经典PSO 有很大不同。假设一个包含M个粒子的粒子群在D维空间中进行搜索,在第t次迭代开始时第i个粒子在第j维的位置为记录了该粒子在第t次迭代及之前的所有时刻中第j维的最佳位置,记录了整个粒子群在第t次迭代及之前的所有时刻中第j维的最佳位置,则在QPSO 中,第t次迭代时,该粒子在第j维的位置更新公式如下:
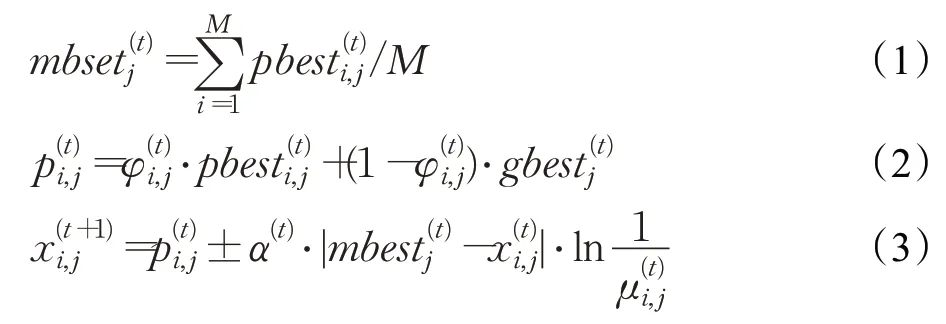
2 基于ID-QPSO的文本对抗算法
本文提出一种基于义原和改进的量子行为粒子群优化算法的文本对抗攻击方法。具体来说,先采用基于义原的方法得到单词的替代词集,然后应用改进的离散的量子行为粒子群优化算法(ID-QPSO)搜索得到对抗样本。
基于义原的替代词选取方法由Zang 等人[22]最先提出。该方法将与原始输入词拥有相同义原的词作为替代词。相比较于其他的寻找替换词的方法,如基于词向量距离的方法或者基于同义词的方法,基于义原的方法能够找到更多的优质的替代词,因而本文也采用该方法来寻找替代词。具体举例如下:“笔记本(notebook)”这个词含有“笔记册子”和“笔记本电脑”两种词义。“笔记册子”语义的义原为“簿册(account)”,与该义原相同词有“笔记簿(notebook)”“本子(book)”;“笔记本电脑”语义的义原为:“电脑(computer)”“样式值(Pattern Value)”“能(able)”“携带(bring)”,与该义原相同的词为“便携式计算机(laptop)”“笔记本电脑(laptop computer)”以及“便携式电脑(portable computer)”。如此便通过义原找到了“笔记本”的替换词。如果对于一个词而言,没有其他的词和该词拥有完全相同的义原,那么这个词没有替换词。
对于一个句子,找到其每个词的替代词之后,应用改进的量子行为粒子群优化算法进行对抗样本的搜索。搜索空间是由句子每个词的替代词组成,因而是离散空间。为了适应搜索空间的离散特征,对量子行为粒子群优化算法进行了改动。具体而言,首先定义优化算法的搜索空间。假设输入的句子为xorig,句子长度为D,其第j个词表示为wj,wj及其替代词共同组成的集合为S(wj),则算法的搜索空间为S={S(wj)|j=1,2,…,D},即整个搜索空间为D维,每一维对应于相应的替代词集合。将一个对抗样本作为QPSO 算法中的一个粒子,粒子群一共包含M个粒子,因此初始时将输入句子复制M份作为M个初始粒子的位置,初始时第i个粒子位置向量记为。第t次迭代时,首先遍历的每个位置,找到每个位置上对模型伤害最大的词组成替换词的向量。然后,使用该替换词的向量以一定的概率对进行变异操作,具体见图2,其中是第i个粒子第j维上找出的对模型伤害最大的词,变异为的概率,对模型的伤害成正相关。
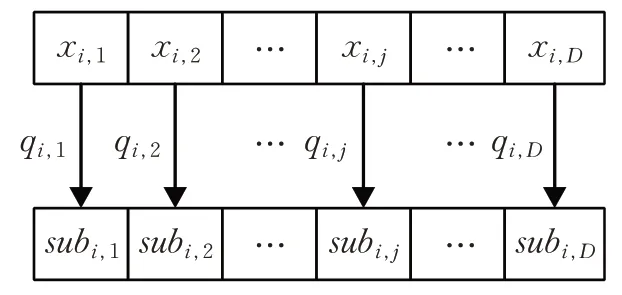
图2 对的变异操作Fig.2 mutation operation for
在算法中,采用下述离散化方式进行离散:

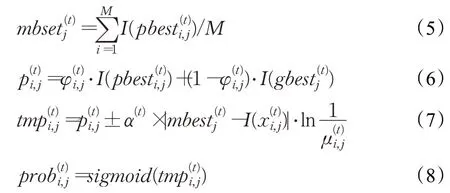
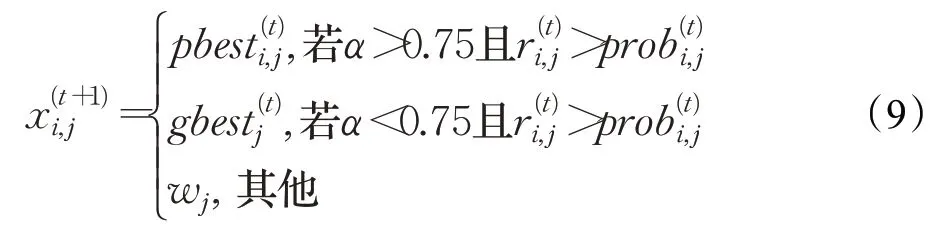
其中,r是在[0,1]上均匀分布的随机变量;α是收缩扩张系数,定义如下:

T为最大迭代次数,t为当前迭代次数。
提出的基于ID-QPSO 的文本对抗算法总体步骤如图3所示。
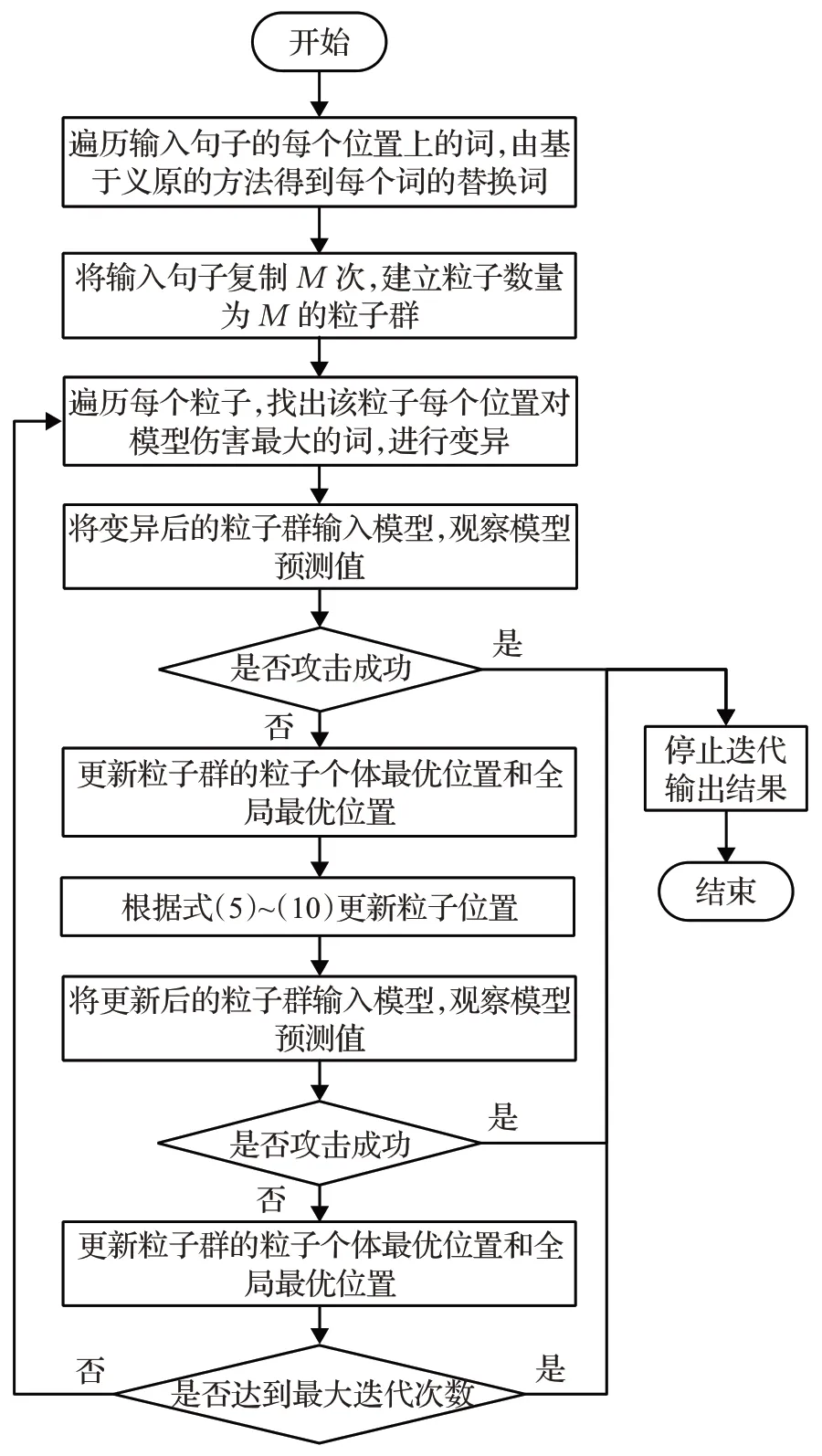
图3 基于ID-QPSO的文本对抗算法Fig.3 ID-QPSO based adversarial attack algorithm for texts
3 实验
3.1 数据集
为了验证攻击方法的效果,在三个数据集上进行了实验,分别是IMDB数据集[26]、SST-2数据集[27]和SNLI数据集[28]。三个数据集均为文本分类任务。IMDB数据集和SST-2数据集为情感分类任务,SNLI数据集为自然语言推理任务。
IMDB数据集[26]是一个包含了50 000条电影评价的数据集,其中25 000 条作为训练集,25 000 条作为测试集。每条评论都被标注为积极或消极。
SST-2 数据集[27]同样是电影评论领域的数据集,其包含了约11 000 条评论,被划分为训练集、验证集和测试集。
SNLI 数据集[28]是斯坦福大学发表的一个自然语言推断数据集,该数据集包含了570 000对句子,每对句子的关系被标注为矛盾、蕴含或中立,其中550 000对被划分为训练集,10 000对作为验证集,10 000对作为测试集。
3.2 被攻击模型及对比方法
选择Bi-LSTM 模型以及BERT 模型作为被攻击模型。Bi-LSTM后接最大池化的模型由Conneau等人[29]于2017 年提出。BERT 模型是Devlin 等人[30]于2019 年提出的预训练语言模型,提出时在11 项语言任务上取得了最好效果。本文的Bi-LSTM使用300维的GloVe词向量[31],隐层维数设置为128维;BERT模型用的base版。
选取了三个方法作为实验的对比方法。第一个对比方法是Alzantot 等人[20]提出的方法,该方法在词向量中寻找替换词,通过限制词向量空间的距离来控制替换词的数量,然后使用基因算法搜索对抗样本。第二个对比方法是Ren等人[19]提出的方法,使用同义词作为替换词,然后使用贪婪算法来进行对抗样本的搜索。第三种方法是Zang等人[22]提出的方法,使用基于义原的方法得到替换词,然后使用粒子群优化算法来搜索对抗样本,该方法是目前的最优方法。
3.3 实验细节及评价标准
为了更有效地进行实验,从IMDB数据集中随机选取500条数据,从SST-2数据集和SNLI数据集中各随机选取了1 000 条数据来进行实验。同Alzantot 等人和Zang等人的实验设置一样,在选取被攻击的句子时,选取的句子必须是长度在10 到100 之间且模型能够给出正确预测的句子。如果模型不能正确预测原始的句子,那么没有进行对抗攻击的必要。同时为了保持对比实验的一致性,将量子行为粒子群优化算法的最大迭代次数T设置为20,将粒子群的粒子数量M设置为60,同Alzantot等人和Zang等人的实验设置保持一致。
实验中对三个数据集采用相同的评价标准,即攻击成功率和对抗样本平均改动率,计算公式如下:
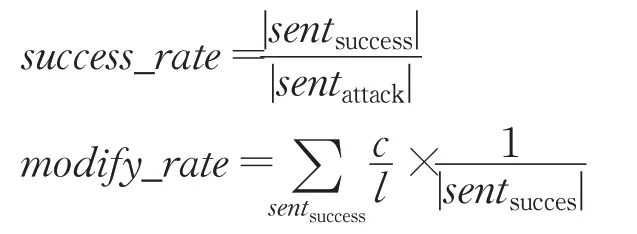
其中,|sentsuccess|表示攻击成功的句子数量,|sentattack|表示被攻击的句子的总数量,c为该样本中改动的单词的数量,l为该样本原始输入中单词的总数。只统计改动率不超过25%的攻击成功的对抗样本,将其他情形都视为对抗攻击失败。
3.4 实验结果
对抗攻击成功率的结果展示在表1中,本文提出的方法在6 个实验中的5 个上取得了最高的成功率。实验结果还显示同为分类任务,SST-2 的攻击成功率比IMDB的攻击成功率要低。因为IMDB数据集的平均句子长度超过200,而SST-2的平均句子长度只有大约17,因此对SST 中的句子进行攻击很容易超过25%的改动率限制,造成攻击失败。
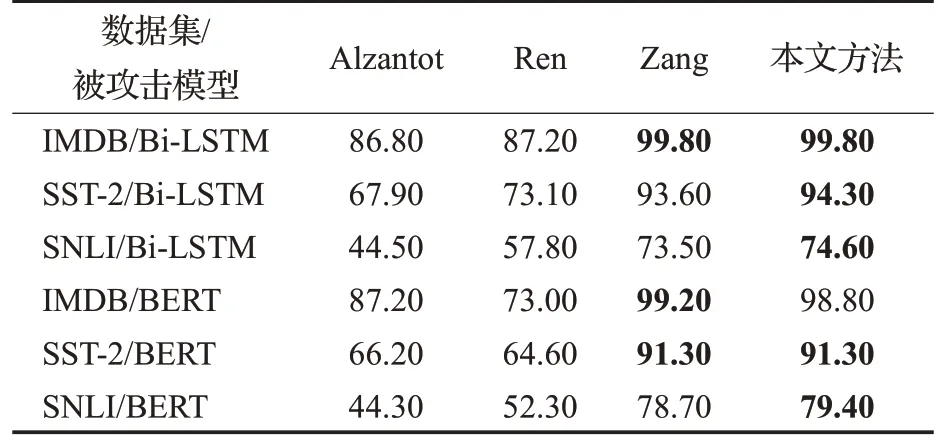
表1 对抗攻击成功率Table 1 Adversarial attack success rate %
攻击成功的对抗样本改动率结果展示在表2中,本文的方法在6个实验中的4个上取得了最小的样本平均改动率。表1和表2的结果证明本文的攻击方法能够以较少的改动率获得较高的攻击成功率。
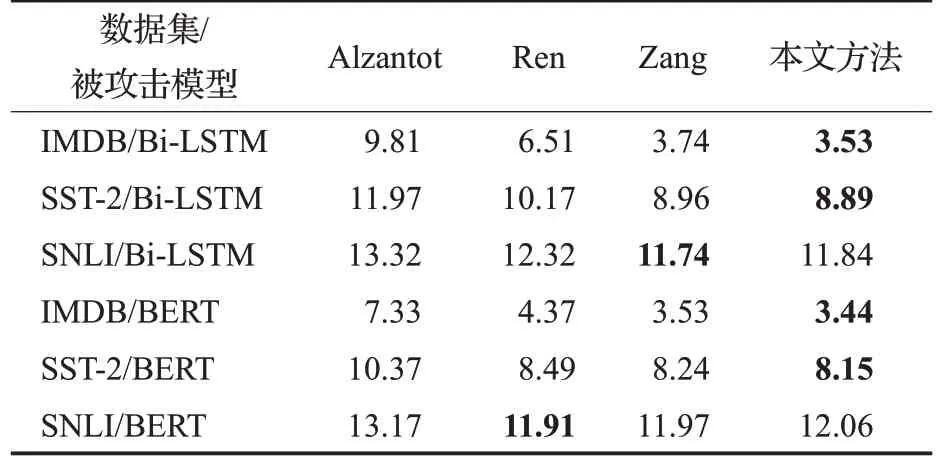
表2 攻击成功的对抗样本的平均改动率Table 2 Average modification rate of adversarial examples attacking successfully %
3.5 人工评测及案例分析
为了评价生成的对抗样本的语法语义正确性,从SST-2 中选取了500 个句子,各对比方法和本文的方法在这500个句子对Bi-LSTM模型的攻击都获得了成功,也就是都生成了攻击成功的对抗样本。请3 位专业人员对500 个原始句子及各对抗攻击方法生成的对抗样本进行打分。打分原则是:
(1)有语法错误而且语义不通的为1分;
(2)只有语法错误或者语义错误的为2分;
(3)语法和语义均无错误的为3分。
评分结果如表3所示。SST-2数据集中的原始句子是收录的用户对电影的评论,因此原始句子也存在一些语法错误或者语义不顺畅。Zang 等人[22]提出的对抗方法和本文方法生成的对抗样本得分相近,因为寻找替换词的方法相同,替换词空间一致,而语法语义的错误主要由替换词的不合适造成,因此两种方法的评分相近。

表3 语法语义人工评分Table 3 Grammatical and semantic scores
表4列出了一些针对Bi-LSTM模型在SST-2数据集上生成的对抗样本。列出了两个句子及Zang等人方法和本文方法针对这两个句子生成的对抗样本。对抗样本中更改的词被以及原始文本中对应的词都以斜体粗体的形式标出。从表中可以看出,本文方法和Zang 等人方法由于搜索算法不同,在替换位置的选取及替换词的选择上有所区别。在所示的两个案例中,本文方法可以通过改动相对较少的词来成功实施对抗攻击。

表4 对抗样本实例Table 4 Adversarial examples
4 结论
本文提出了一种改进的词级别文本对抗攻击方法。通过改进搜索优化算法,本文的方法可以更有效地搜索到对抗样本。实验证明本文方法得到的对抗样本在保持原有语法语义正确性的情况下,成功率更高,改动率更低,是一种更有效的文本对抗方法。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
昆明医科大学学报(2022年1期)2022-02-28
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
开放教育研究(2020年2期)2020-03-31
浙江工业大学学报(2017年5期)2018-01-22
中国修辞(2017年0期)2017-01-31
作文周刊·小学一年级版(2016年7期)2016-08-11
作文周刊·小学一年级版(2016年13期)2016-05-10
长江学术(2016年4期)2016-03-11
