
融合领导者影响与隐式信任度的群组推荐方法
2022-05-15 06:35王永贵林佳敏何佳玉
计算机工程与应用 2022年9期
王永贵,林佳敏,何佳玉
1.辽宁工程技术大学 电子与信息工程学院,辽宁 葫芦岛125105
2.辽宁工程技术大学 软件学院,辽宁 葫芦岛125105
近年来,在海量的信息时代下,互联网技术快速发展。推荐系统已经融入了人们网络生活中的方方面面,作为目前突出的应用网络个性化来解决信息过载问题的技术,其能够快速引导用户获得想要的信息。现有的推荐算法主要是关注单一用户的建议,在日常活动中,用户是以各式各样的群组形式出现,例如看电影、聚餐、团购、旅游等,这就促进了群组推荐系统的发展。与现有的个性化推荐不同,群组推荐既需要考虑群组内每个成员的偏好,还需考虑整个群体的偏好,根据组员的共同特征进行推荐,由于推荐准确度的影响因素复杂,因此提高群组推荐准确度照比单一推荐难度较大。2011年ACM 推荐系统大会(RecSys2011)以“为家庭群组推荐电影”为主题举办了上下文感知电影推荐挑战赛(CAMRa2011),促进了群组推荐在电影、餐饮、旅游等领域的推广与应用[1-2]。群组推荐研究受到越来越多的关注并成为一个活跃的研究领域。
为了提高群组推荐的准确度,国内外需要研究者对群组推荐系统进行了多方面的改进。针对创建群组方法,文献[3]通过将每个用户的偏好与项目的特征进行相似度比较,偏好相似的用户划分为一个群组,提高了推荐精度,但对于庞大数据集,相似度计算时间复杂度偏高;为了降低复杂度,文献[4]利用K-meams聚类分别基于时间点和标签为选择依据将用户、项目划分到多个簇中进行推荐,提高了后续群组推荐的精度和稳定性,但K-meams属于硬聚类,算法将每一个处理对象划分到互斥的数据集中,与实际应用中用户可以分属在不同群组的情况略有差异,影响了群组推荐的效果;文献[5]将K-means聚类进行优化,结合了遗传算法生成网络社交圈,计算圈子中重叠的用户的状态并进行群组推荐,有效地提高了推荐的准确度,但这种方法仅在小规模群组内推荐效果提高显著,大规模的群组推荐效果略有不佳。针对群组推荐中如何融合整体成员偏好的问题,文献[6]提出一种基于聊天的假期计划群组推荐系统,它将推荐作为一个增量过程,用户可以对项目进行点评,推荐中用户在阅读其他成员对项目的评价后需要表达自己的意见,对于新用户,他们的偏好取决于老成员的偏好和行为,因此对于没有发表过评论的用户不能对其他用户产生影响,并且这个系统时间复杂度较高;文献[7]提出一种根据群组成员之间的讨论信息获取成员偏好的酒店群组荐系统,该系统可以考虑每个成员的意见,但数据的稀疏性影响推荐结果;文献[8]提出一种针对旅游群组的推荐算法,该系统考虑了组中用户的关系从而预先设置了影响权重(权重通过分析定义),具有较好的推荐效果,但它仍存在局限性,如爸爸与儿子的关系密切,但兴趣可能和儿子完全不同,该推荐的公平性和成员满意度可能降低;文献[9]提出的算法考虑到地理位置不同和用户关系等因素会影响用户权重,提出地理社会群组推荐模型,将不同权重的群体成员偏好进行融合,实验证明了方法的有效性,但在大规模群组内算法准确度仍有待提高;文献[10]通过描述组内用户之间的Hellinger 距离来提取潜在的信任信息建立社会关系矩阵,群组推荐效果比传统算法效果更好,但未考虑信任的非对称距离关系的影响。
综上所述,现有的群组推荐中存在以下方面需要进一步研究:(1)成员划分到群组的方法主要由随机群组或结合传统硬聚类,但实际情况是,有共同偏好的用户会优先组成群,并且每个用户可以属于多个群组,这样就会影响推荐效果;(2)现有的获取群组成员相互影响的方法如设置固定的权重限制存在一定的局限性,忽略了个别影响力因子大的用户对整个群体的影响,且在大规模的群组中推荐的满意度与准确率偏低;(3)现有的群组推荐忽略成员之间的隐式信任,包括共同评分项目与评分距离等因素,导致推荐精度偏低。本文的重点在于改进群组推荐在群组创建与群组内成员影响的计算方法,提高推荐的准确性和成员的满意度。
针对上述问题,本文提出了一个考虑领导者影响与隐式信任度的群组推荐算法,该算法的优势在于:
(1)利用模糊C均值聚类(FCM)算法与皮尔逊相关性(PCC)结合的方法划分高相似度用户群组,提高群组成员之间的相似性。
(2)使用一种领导者影响的计算方法获取领导者影响权重,领导者是在与群组活动相关的领域中拥有经验和知识的人,他们比其他成员更受信任并且对成员的影响较大。领导还可以向成员提供相似的观点,考虑到小组成员之间的信任度和相似度,将信任度和相似度最高的人选为小组的领导者,并将成员的意见引向共同的兴趣,并采用隐式信任度量计算方法,结合相似度和信任度获取成员影响权重,以保持群组成员间的公平性,提高领导者发现和影响过程的效率。提高推荐的准确度。
(3)引入时间因子,在评分预测时考虑时间因素,根据人类记忆遗忘曲线提出的一种模拟人类兴趣变化的时间函数,将该函数融入到项目的评分预测。通过不同评分时间给予不同得分权重,来模拟用户的兴趣变化,更能准确预测用户对项目的评分。
1 融合领导者影响与隐式信任度的群组推荐
1.1 群组形成
聚类[11]是一种机器学习技术,表示在无规则的庞大数据集中将相似的数据归为一组(类),其中同一组的数据相似度较高,两个不同组中的任意两个数据相似度较低。该技术提高了数据挖掘的效率,特别是在大数据研究中。群组的形成[12]是群组推荐的首要基础环节,通过聚类算法找到一群具有相似偏好兴趣的用户是当前热门的创建群组的方法,它将相似的用户数据汇聚,形成不同的簇,大大减少了搜索用户创建群组的时间。大多数的群组发现使用的聚类如K-means 聚类算法属于硬聚类,即将一个用户数据准确地归属于一类簇中,虽然在以往的研究中得到了很好的效果,但在与实际应用中一个用户可以分属于多个群组的情况不符,因此本文针对以上选择了模糊C 均值聚类算法对初始用户数据进行聚类。模糊C为软聚类算法,可以将用户数据以不同隶属度分属到不同的簇中,实现了一户多组,并与皮尔逊相关系数结合检测每个簇中的相似用户,创建高相似度的群组,为后续的群组推荐奠定了更精准的基础。
模糊C 均值聚类算法(fuzzy c-means clustering algorithm,FCM)[13]是一种从模糊属性高度普遍的数据集中提取规则和挖掘数据的有效算法。FCM聚类算法在每次迭代时,会计算得到一个隶属度矩阵和一个聚类中心的集合。根据算出的隶属度矩阵和聚类中心集合求出目标函数的值。算法最终目的是尽可能找到较小的目标函数值。
设数据样本集为X={x1,x2,…,xn}的有限集合,其中n是样本数。定义将数据集X划分为k个簇,簇中心为C=ci(i=1,2,…,k),隶属度矩阵U=[uij],目标函数定义使聚类算法最小化公式如下:
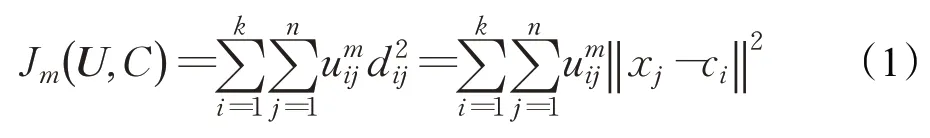
其中,m表示模糊聚类中的模糊指数,m∈[1.25,2.5];uij表示元素xi在以ci为中心的簇中的隶属度,0≤uij≤1,1≤i≤k,1≤j≤n;∑uij=1 表示样本点到任意聚类中心的隶属度总和为1;‖xi-cj‖表示样本点xi到聚类中心ci之间的欧氏距离。反复迭代更新隶属度和聚类中心,使得目标函数最小化,即Jm(U,C)收敛,利用上述条件使目标函数导数为零,得到隶属度和聚类中心的迭代更新公式。
算法FCM步骤如下:

皮尔逊相关系数(Pearson correlation co-efficient,PCC)[14]是广泛用于相似度测量的著名方法之一。PCC通常是将用户对共同物品的评价作为衡量他们相似度的标准,计算相似度的准则如公式(4)所示:
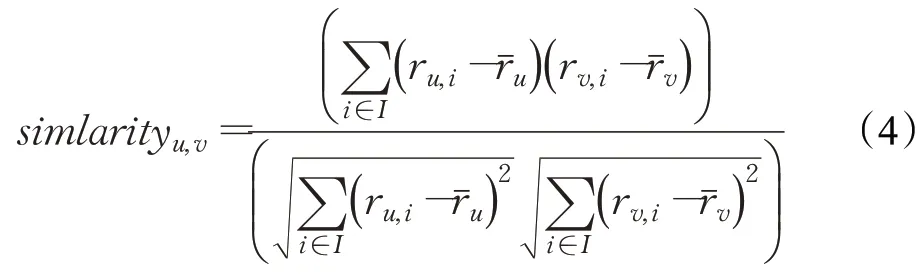
其中,ru,i、rv,i分别表示用户u对项目i的评分和用户v对项目i的评分;分别表示用户u的平均评分和用户v的平均评分,相似度值在[-1,+1]之间。在此测度中,相关系数为负的用户不相似,相关值为正的用户相似。
1.2 信任度计算方法
信任是社交网络中最重要的概念之一,可以快速影响用户的决策。信任是指人与人之间信任程度,通过对一个人的能力、了解程度和可靠性等来建立对这个人的信任,它显示用户对他人的信任程度。信任度量是指利用信任来帮助决定群体中成员间的互动程度,它的一个重要属性是不对称,也就是说成员彼此间信任的程度是不一样的。故在获取成员影响和选择领导者的过程中,文本采用PCC和信任度量相结合的方法,其中为了度量用户之间的信任值,本文使用了一种隐式的信任度量方法弥补PCC忽视的偏好距离的问题,即使用非对称的信任度量方法。所提出的信任度量是基于两个用户对被评价对象的项目的交集partner和他们之间的距离distance的线性组合隐含地估计的。信任度量如公式(5)所示:

其中,partner表示所建立的用户之间非对称信任度,distance表示用户的评分距离(欧氏距离),由公式(6)、(7)所示:
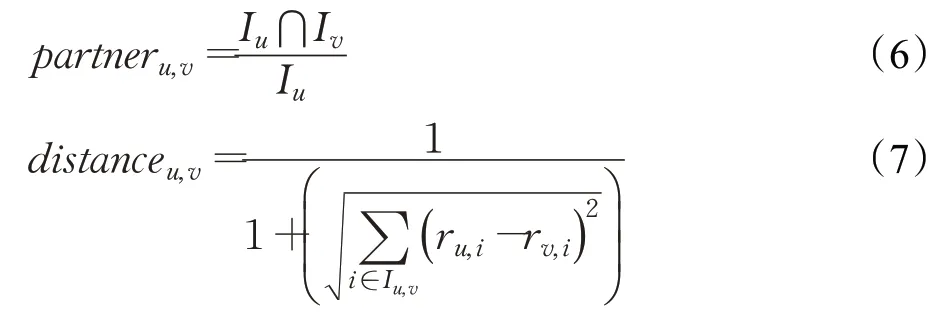
其中,Iu、Iv表示成员u、v评分不为零的项目,Iu∩Iv表示成员u、v共同评分的项目。由于partner关系值在[0,1]的范围内,distance距离值范围是[0,1],Trust信任值也在[0,1]范围内。
1.3 领导者影响
在群体活动中,群组推荐以满足一个群体的共同偏好为原则生成一个群组推荐列表。与传统针对单一用户推荐不同的是群组成员之间的偏好受彼此影响,故影响是群体活动中非常重要的因素之一。在本文中,影响分为领导者影响和成员影响,领导者影响是社会群体中最突出的因素之一。在小组活动中,领导者是成员中最信任的人,也是在与小组活动相关的领域中拥有经验和知识的人。此外,领导还可以向成员提供相似的观点。为了得到领导者的影响值,需要在形成群组后在组中确定领导者,本文引入领导者影响方法,将成员信任度和相似度最高的用户选为群组的领导者,并将成员的意见引向共同的兴趣。领导者在群组内的影响力被定义为相似度和信任度的总和比组内成员人数N(除了领导者),相关的函数如下。
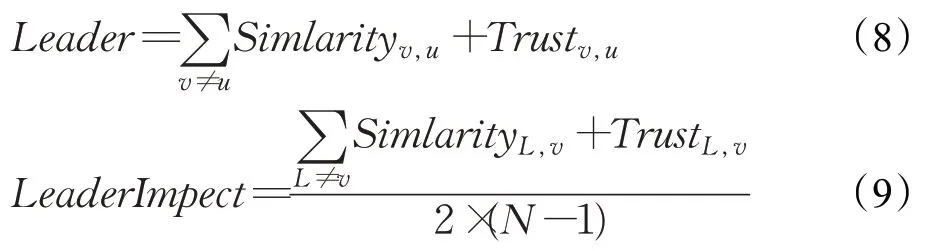
其中,领导者影响力大小体现了其在群体中的影响程度,并用于计算领导者对成员的影响权重,其取值范围为[0,1]。
得出领导者在群组内的影响后,利用公式(10)、(11)分别估算出领导者L和成员v彼此间的影响权重和成员u与成员v彼此间的影响权重[15-16]。领导者对成员的影响不是恒定的,而是根据每个成员对信任和相似值的依赖程度而变化。此外,各成员的影响权值是可变的,且各成员之间的影响权值是不对称的。

其中,WeightL,v表示领导者L对成员v的影响权重值;Weightu,v表示成员u对成员v的影响权重值。
1.4 影响过程
为了展示群组内领导者与成员之间的影响过程,定义一组样本,其中包含5名成员。影响过程中的初始信息包括计算成员的相似度和信任度,分别如表1、表2所示。
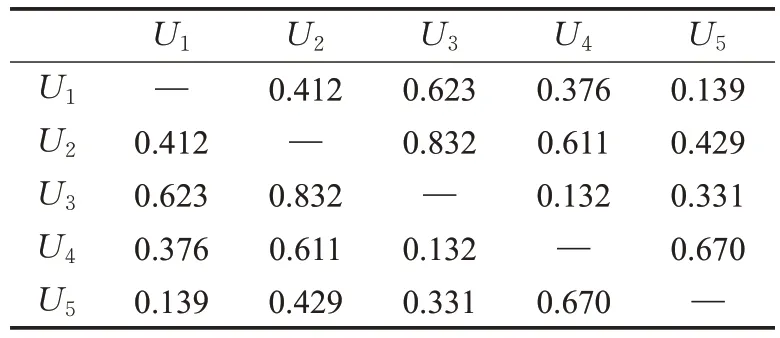
表1 成员相似度Table 1 Similarity of members
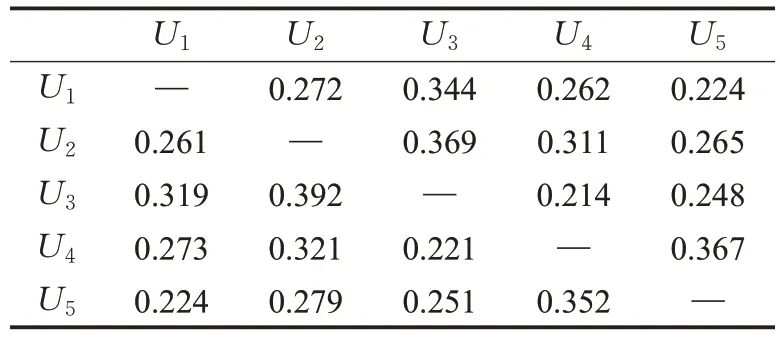
表2 成员信任值Table 2 Trust of members
如表1 所示,可以看出PCC 具有一定局限性,如用户U1对用户U2的相似度值等于用户U2对用户U1的相似度值,并没有考虑到用户评分之间的距离。因此采用隐式信任度量方法,如表2 所示,通过成员关系级别和他们的评分距离来解决PCC的局限性,该方法的特点是用户的信任度属于不对称性,即用户U1对U2的信任值与U2对U1的信任值是不同的,信任度的不对称性取决于成员之间的伙伴关系水平,如果两个用户的评价项目数量相同,则他们对彼此的信任值相同,即U1对U5的信任值。由于事先构建了群组的评分矩阵,成员的信任值估算是统一的,信任值的大小基于项目的增多而变得更加多样化。根据表1、表2 中提供的相似度和信任值,当一个成员对他人的相似度和信任值之和达到最大值时,该成员被选为领导者。每个成员的相似性和信任度的总和根据公式(8)以如下形式计算:
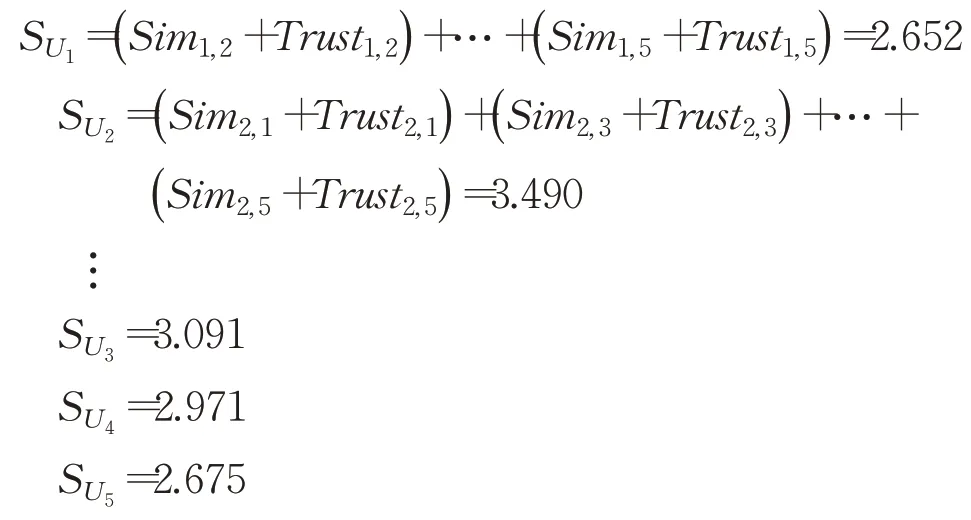
根据所有的值可以看出,U2值最大为3.490,被选为小组领导者。因此领导者影响值根据公式(9)得出:
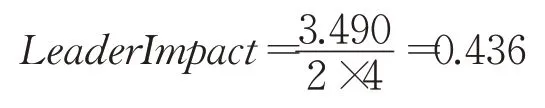
在确定领导者并计算其在群组内的影响后,利用公式(10)估计领导者和成员之间相互影响的权重,领导者U2对成员U1影响与成员U1对领导者U2影响按以下方式计算,权重矩阵如表3表示。
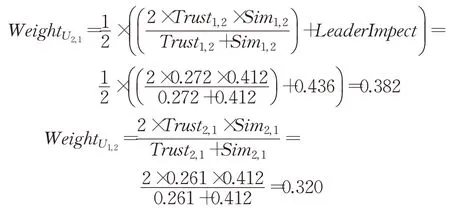
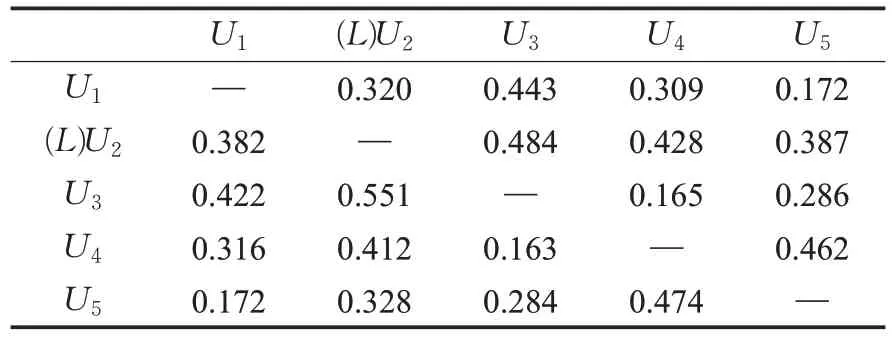
表3 成员影响权重值Table 3 Influence weights of members on each other
2 融合时间函数的评分预测
2.1 基于人类遗忘曲线的时间权重函数
根据群组成员的影响力来评估每个成员对项目的评分预测。一个成员对某个项目的评分是根据他的评价减其他成员的评价,乘影响权重来调整的。以往的群组推荐中没有考虑到成员的兴趣偏好随时间变化而变化的问题,例如用户在某电影刚上映时,兴趣度很高,随着时间的推移,用户对这部电影感兴趣的程度随着电影热度的降低而下降,这就是兴趣迁移现象。所以忽略时间推移对群组推荐结果的影响具有片面性,必须要考虑时间因素对推荐结果产生的影响,体现群组推荐的实时性和提高推荐准确度。
艾宾浩斯记忆遗忘曲线[17-18]是用来模拟人类大脑对新事物遗忘规律的曲线模型,它指出人类的记忆量随着时间的推移遗忘的速度会逐渐减慢,最后达到一个基本平稳的值,如图1所示。
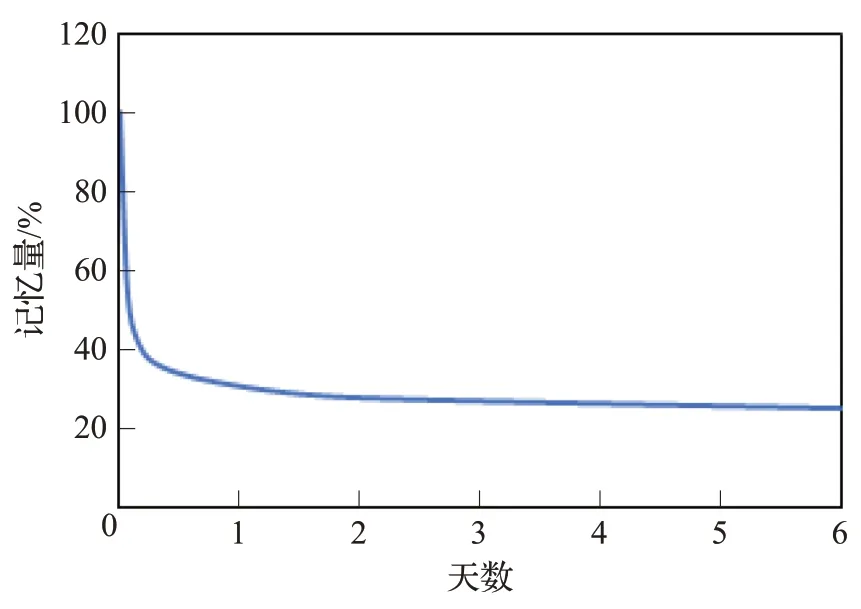
图1 艾宾浩斯曲线Fig.1 Ebbinghaus forgetting curve
用户的兴趣同人类记忆遗忘过程类似,都是随时间推移呈下降趋势。因此,根据人类遗忘曲线设置权重是解决兴趣迁移问题的一种方法。传统的方法是在计算相似度时引入时间函数来改进相似度计算公式,经实验证明这种引入方式可以提高推荐效果。在之后的研究发现,在预测评分时引入时间函数来改进预测评分公式也是一种有效方法。时间权重函数如公式(12)、(13)所示:

其中,f(tvi)表示时间权重因子,且f(tvi)∈(0,1),Δt表示两个时间差值;tvi表示用户v对项目i的评分时间,tvf表示用户v初始的评分时间。
本文引入基于人类记忆遗忘曲线提出的模拟人类兴趣变化的时间函数,将该函数引入到评分预测中,通过赋予不同评分时间不同得分权重的方式模拟用户的兴趣变化。改进后的评分预测公式如下所示:
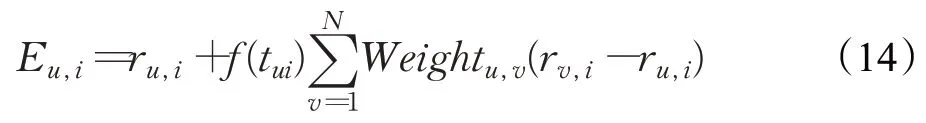
其中,用户评分时间越久远,时间权重f(tvi)越小,预测评分值Eu,i越低;如果一个成员未能对一个项目进行评分,那么他的评分将被认为等于系统中的最低评分,即ru,i=1。如果预测评分小于1,则必须将其重新调整为1。如果预测的评分大于5,则必须将其调整为5。
2.2 偏好融合
为了得到群组对某一项目的预测评分,群组推荐算法涉及到群组中用户的偏好融合问题。群组偏好融合策略[19]是群组推荐的关键技术,是将群组成员的偏好融合缓解群组成员之间的偏好冲突,使推荐结果尽可能满足所有群组成员。偏好融合策略包括均值策略(average strategy,AVG)、公平策略(fairness strategy)、最大满意度策略(most pleasure strategy,MP)和最小痛苦策略(least misery strategy,LM)等[20-23]。使用不同的融合策略可以满足群组共同偏好、公平性、可理解性等不同的需要。具体定义如下:
定义1(均值策略)以群组所有成员的评分取平均值作为群组对项目的评分。

其中,Pgi表示群组g对项目i的评分,rui表示用户u对项目i的评分。
定义2(公平策略)以轮流选择群组内某成员的评分作为群组对项目的评分。

定义3(最大满意度策略)以群组内最高的成员评分作为群组对项目的评分。

定义4(最小痛苦策略)以群组内最低的成员评分作为群组对项目的评分。

策略的选择应根据应用领域、成员偏好和群体特征选择合适的聚合类型。均值策略是群组推荐系统中目前最常用的偏好融合策略,但推荐结果可能引起个别用户的不满,即“痛苦”,最小痛苦策略则是为了避免这种“痛苦”现象,将最低评分作为群组评分,过滤可能引起痛苦的低评分,但可能因为恶意用户评分影响推荐结果。文献[24]根据调研真实群组的用户行为表示,在小规模的数据集上对多种融合策略的推荐算法进行对比,均值策略的推荐效果最好;文献[25]基于内容的群组推荐中最小痛苦策略的推荐准确度最高;本文分别选择了均值策略和最小痛苦策略融合群组成员评分,以确定每个项目的群组得分,在对所有项目进行分组评分后,推荐n个得分最高的项目。算法流程图如图2 所示。阴影部分为本文创新。
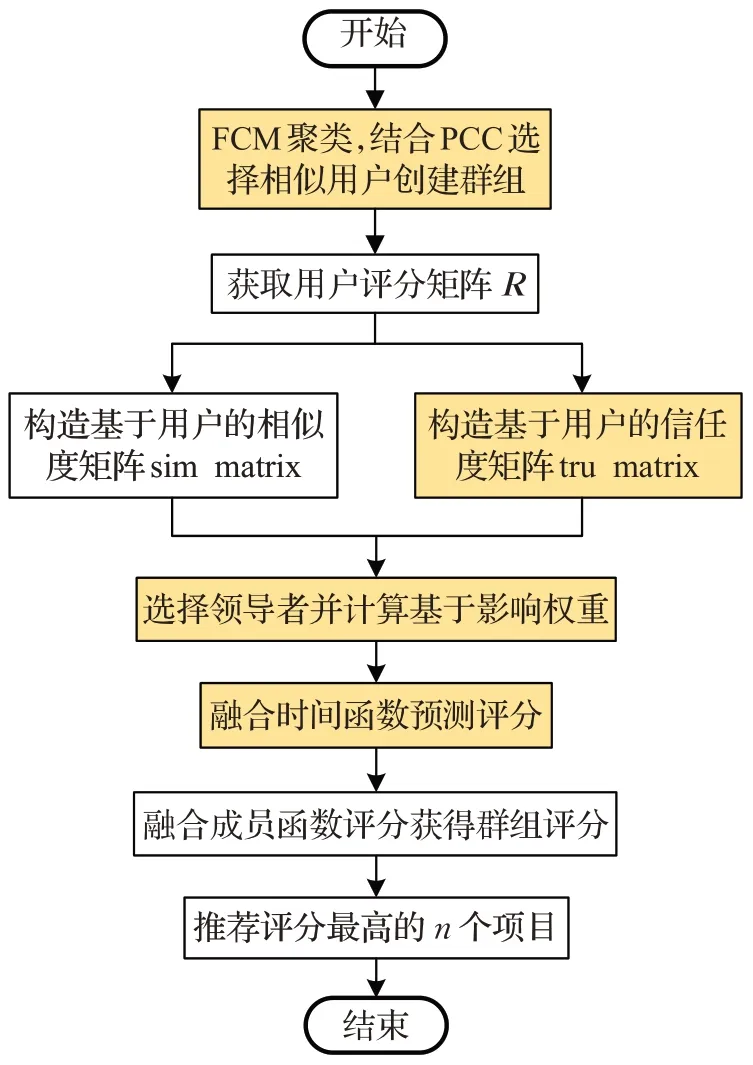
图2 本文算法流程图Fig.2 Flow chart of proposed algorithm
2.3 算法复杂度分析
将本文算法GRS-IT 与SC-GRS 算法的时间复杂度进行对比分析。
模糊C 均值聚类、相关性、信任度计算权重和评分融合四部分组成本文算法的复杂度。设项目的总数为Im,群组数为Ng,群规模为,N个用户加入个群组,每个成员对个项目评分,每个项目有个用户评分,成员信任关系数量为,相关性复杂度为,信任度复杂度为,评分融合复杂度,可以看出,本文算法的运算复杂度主要受以上影响,且为线性变化。SC-GRS 算法主要包括GA 算法、K-mean 聚类、相关性,假设在第k(k<Tmax)次迭代时满足终止条件,每次迭代时间为Ti(i=1,2,…,k),GA 算法复杂度为O(k×Ti),相关性复杂度为。分析可知SC-GRS算法与本文算法在运行时间性能上的差异主要取决于迭代的运算复杂度与群组规模大小,SC-GRS 算法仅在较小规模的群组中效果更好,随着群组规模的增大效果降低较快,且迭代次数越高,时间复杂度越高。相比SC-GRS算法,GRS-IT算法的时间复杂度小于SC-GRS算法的时间复杂度,并且GRS-IT 算法在大规模数据集的实际应用中更为合适,具有较大的优势。
3 实验
为了更好地重现本文算法的仿真结果,仿真参数FCM初始模糊指数设置为2,迭代终止阈值设为1.0E-6,用户的评分数据如果小于1 的评分则设置为1,如果大于5 的评分则设置为5,评价指标中满意度的阈值设置为4。具体如表4所示。
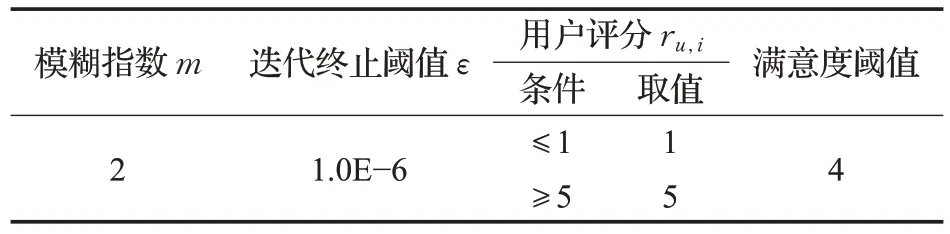
表4 参数信息Table 4 Parameter information
3.1 数据集简介
目前,根据数据集属性,群组推荐在国内外普遍使用传统个性推荐方法的数据集并从中创建群组。本文采用的是推荐系统领域著名的MovieLens100K 数据集来进行实验,实验中随机划分80%训练数据集训练模型和20%测试数据集检测算法的准确度。数据集信息见表5。其中,数据集中用户至少对20部电影进行评分,从1~5对项目进行排序,1分表示不感兴趣,5分表示最感兴趣。

表5 数据集信息Table 5 Dataset information
3.2 评价指标
本文选择归一化折损累计增益(normalized discounted cumulative gain,nDCG)衡量生成Top-n推荐列表的准确率,公式如下所示。

其中,{i1,i2,…,ik}是项目的评分列表;g表示群组,n表示推荐列表的前n个;rg、ik表示群组对项目ik的真实评分。nDCG是DCG的真实值与DCG的最大值的比值,DCG的最大值即推荐列表的最佳DCG值,nDCG的数值越大,表示推荐的准确度越高。公式如下所示:

此外,均方根误差RMSE是评价推荐系统的常用标准,衡量用户的真实评分与预测评分的均方根误差指标,本文选择RMSE 作为评价推荐质量好坏的指标,公式如下所示:
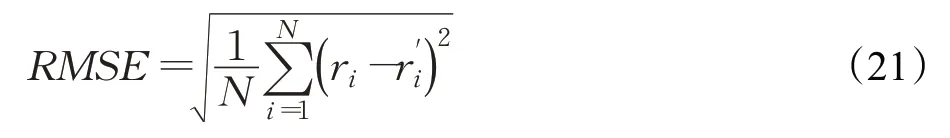
其中,N表示群组中参与预测的项目数目;ri表示成员/用户对项目i的实际评分;表示成员/用户对项目i的预测评分,RMSE结果值越小,推荐的准确度越高。
以上介绍的nDCG 和RMSE 标准用来评估本文算法的准确度,为了评估群组成员对推荐结果是否满意,本文使用一种满意度指标GSM,以群组每个成员为基础衡量群组的满意度,公式如下所示:

其中,为了提高实验的准确性和效率,设置一个成员的满意度阈值,根据文献[26]表示,满意度阈值过低,可能导致群组推荐整体准确性产生偏差,阈值设定过高,不能真实地反映推荐项目与用户偏好情况,故阈值设置为4,即评分大于或等于4的成员对推荐的结果表示满意;表示为成员评分在4分以上的项目;Ir表示推荐的项目;Nir表示推荐项目的个数。
3.3 准确度结果分析
为了评价本文算法的综合性能,将本文GRS-IT 与其他群组推荐算法进行对比实验。
(1)HERMES 群组推荐系统,根据现有的成员关系设置不变权重预测成员评分,再通过聚合技术进行推荐。
(2)COM组推荐,通过聚集具有不同权重的成员来估计一个群组对项目的偏好。它能够结合用户的选择历史和个人对内容因素的考虑,如地理影响,进行推荐。
(3)SC-GRS 群组推荐通过遗传算法与K-mean 聚类生成圈子,社交圈的主要特征为用户信任、用户关系、用户相似度,然后计算每个成员在各圈子中的状态,得到用户在不同圈子中的影响大小,最后通过Top-n完成推荐。
图3~图6 的实验利用均值策略和最小痛苦策略对以上三种群组推荐方法以及随机用户群组推荐方法作为参照对象与本文方法进行对比,并分别比较组规模在5、10、15、20,25 时群组推荐的准确度,进行5 次测试再取平均值作为最终结果以保证实验结果的公平性。在均值策略下的群组推荐结果对比如图3 和图5 所示;在最小痛苦策略下的群组推荐结果对比如图4 和图6所示。
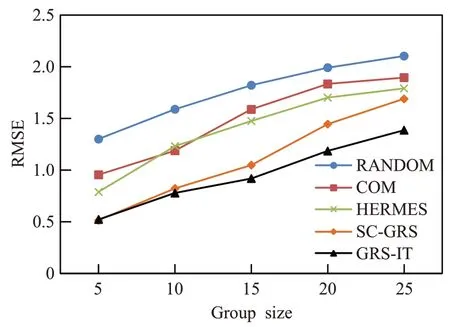
图3 均值策略下的RMSE对比图Fig.3 RMSE contrast figure under AVG
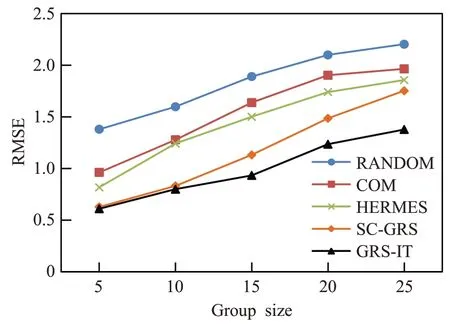
图4 最小痛苦策略下的RMSE对比图Fig.4 RMSE contrast figure under LM
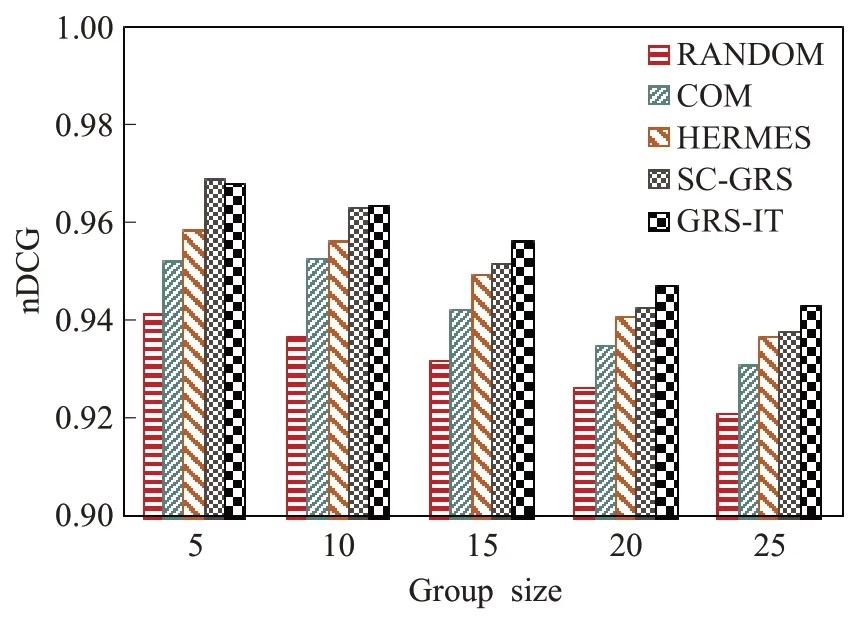
图5 均值策略下的nDCG对比图Fig.5 nDCG contrast figure under AVG
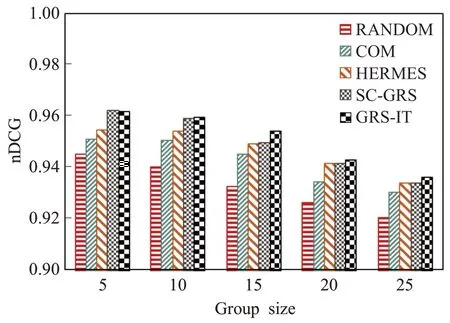
图6 最小痛苦策略下的nDCG对比图Fig.6 nDCG contrast figure under LM
由图3 和图4 分析可以看出,五种方法在群组规模扩大的过程中RMSE 值逐渐升高,而GRS-IT 通过FCM与PCC创建群组提高群组内成员的相似性,并通过相似度与信任度选出群内领导者从而获取成员间影响权重,在群组规模从5到25的情况下能保持较低的误差率,照比其他的三种方法改进推荐准确度的效果明显,显示出GRS-IT算法的优越性。
由图5 和图6 的实验结果表明,在AVG 和LM 策略下,GRS-IT 在规模为5 时的nDCG 值最佳,分别为0.968 2、0.962 1。随着群组规模的扩大,五种方法的nDCG 值逐渐下降,但GRS-IT 算法仍然保持着较高的准确度,始终高于RANDOM、HERMES 和COM 群组推荐算法,SC-GRS 在群组规模较小时能保持较高的nDCG 值,但随群组规模的扩大nDCG 值明显下降,HERMES 由于使用固定权重的人际关系(如夫妻、儿女、父母、朋友等)来影响群组成员,需要提前设置关系权重,随着规模的扩大成员关系减弱,推荐准确度随着规模的扩大而降低。GRS-IT算法对比AVG和LM下的nDCG结果可以看出,AVG的nDCG值普遍高于LM,具有更好的偏好融合效果。也能说明LM 因用户的恶意评分等不良因素影响了推荐准确度。本文算法采用不同融合策略的实验对比如图7所示。
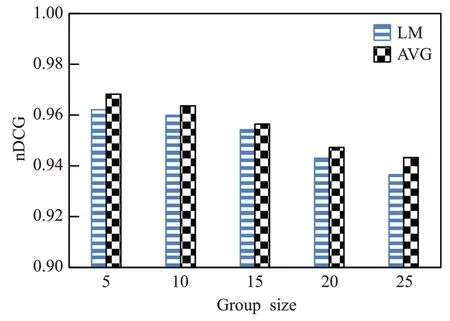
图7 不同融合策略下的nDCG对比图Fig.7 nDCG contrast figure under different fusion strategies
3.4 满意度结果分析
推荐结果的验证是评估的主要部分,因为群组推荐的目标是向群组推荐合适的项目,以最大限度地提高群组成员的满意度。实验将GRS-IT与CF-AV、HERMES、SC-GRS进行比较,并分别在Top-7和Top-11两种不同的推荐列表下对比所推荐项目的成员满意度。HERMES、SC-GRS在上述实验中已经介绍,CF-AV在下面简要介绍。
CF-AV,首先预测CF 策略的组中每个成员的电影评分。使用均值策略,利用预测的成员评分来确定群组评分,然后向群组推荐一个热门电影列表。
实验保持融合策略不变,采用AVG 对四种群组推荐方法进行对比,分别重复进行5次实验再将实验结果取平均值作为最终结果,并分别比较组规模在5、10、15、20、25时群组成员在Top-7、Top-11推荐下的满意度。
如图8所示,Top-7推荐的实验结果表明,GRS-IT在规模为5、10、15、20、25 时的GSM 值分别为93.81%、88.95%、85.42%、80.32%、76.98%,且均高于其他三种算法的GSM值,四种算法的最高GSM值均是在群组规模为5 时,分别为93.81%、92.99%、84.56%、76.72%,且随着规模的扩大GSM逐渐降低。实验结果可以看出三组群组推荐算法的满意度排序为:GRS-IT>SC-GRS>HERMES>CF-AV。
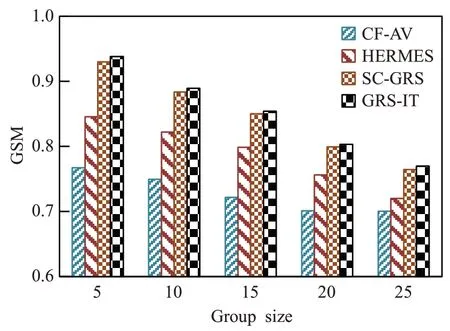
图8 Top-7推荐下的成员满意度对比图Fig.8 GSM contrast figure for Top-7 recommendation
如图9所示,通过上述方法Top-11推荐的实验结果表明,GRS-IT 在规模为5、10、15、20、25 时的GSM 值分别为87.94%、85.9%、80.97%、75.14%、70.44%,且均高于其他三种算法的GSM值,四种算法的最高GSM值均是在群组规模为5 时,分别为87.94%、87.31%、82.66%、74.12%,且随着规模的扩大GSM 逐渐降低。实验结果可以看出在Top-11 推荐下四组群组推荐算法的满意度排序为:GRS-IT>SC-GRS>HERMES>CF-AV。

图9 Top-11推荐下的成员满意度对比图Fig.9 GSM contrast figure for Top-11 recommendation
4 结束语
本文通过模糊C 均值聚类算法和皮尔逊相关性创建高相似度群组,保证用户可以隶属于不同的群组中。为提高群组成员影响对推荐结果的准确度,根据领导者影响力计算方法找出群组内领导者并计算成员和领导者之间的影响权重。为改进相似度计算的对称性,采用了一种非对称性的隐式信任度量方法。引入基于人类遗忘曲线的时间权重函数改进群组成员兴趣变化产生的影响评分结果,最后通过Top-n推荐将项目推荐给群组。实验结果表明,在MoviesLens100K数据集上本文所提出的GRS-IT算法明显提高了推荐的准确度和群组成员的满意度,具有较高的推荐质量。
在未来的研究中,可以从融合策略方面进行研究,提出更适用的融合策略改进GRS-IT,不断提高群组推荐的效果。
猜你喜欢
心理学报(2022年5期)2022-05-16
当代陕西(2020年17期)2020-10-28
网络安全技术与应用(2019年5期)2019-06-05
人大建设(2018年5期)2018-08-16
服装学报(2016年5期)2016-03-06
汽车零部件(2014年1期)2014-09-21
郑州大学学报(理学版)(2012年4期)2012-03-25
军事历史(1986年1期)1986-08-15
军事历史(1983年3期)1983-08-21
