
双重对比学习框架下近红外-可见光人脸图像转换方法
2022-05-10 12:13单晓全孙琦景韩春军张旭东
光电工程 2022年4期
孙 锐,单晓全*,孙琦景,韩春军,张旭东
1 合肥工业大学计算机与信息学院,安徽 合肥 230009;
2 工业安全与应急技术安徽省重点实验室,安徽 合肥 230009;
3 安徽省蚌埠市公安局科技信息科,安徽 蚌埠 233040
1 引 言
近红外(Near-infrared,NIR)图像传感器由于可以很好地克服自然光的影响,能在各种光照条件不佳以及夜间场景下工作而受到广泛应用[1-2]。在刑侦安防领域,近红外人脸图像通常不能直接用于人脸检索与识别[3-5],因为近红外传感器获取的单通道图像缺失了原始图像的自然色彩,对人眼视觉很不友好。与真实的可见光(visible,VIS)人脸图像相比,近红外人脸图像的人脸识别性能也较差。因此将近红外人脸图像转化为可见光人脸图像,还原人脸图像的色彩信息,有助于进一步提高人脸图像的主观视觉效果和跨模态识别性能,为构建全天候的视频监控系统提供技术支撑。
近年来,近红外-可见光图像转换与近红外图像的彩色化[6-11]引起了人们的广泛关注与研究。Limmer等人[8]基于深度学习的方法提出了一种利用深度多尺度卷积神经网络对近红外图像进行着色的方法,然而该方法往往不能还原清晰的细节。生成对抗网络(Generative adversarial network,GAN)[12]出现后在灰度图像的彩色化中得到了广泛的应用,因为它可以产生丰富且较清晰的细节。Liu 等人结合了变分自编码器和GAN,构建了基于共享潜在空间假设和循环损失的无监督图像到图像转换网络UNIT[13],随后将其拓展至多模态,提出了MUNIT[14]。Isola 等人提出的Pix2pix GAN[15]使用UNet[16]作为生成器,并提出了PatchGAN 结构作为判别器,可以在生成的彩色图像中保留更多细节,较大程度提升了生成图像的质量。Wang 等人在Pix2pix GAN 的基础上提出了升级算法Pix2pix HD[17],该算法采用多级生成的方式,先生成低分辨率的图像再将其输入到另一个网络中生成更高分辨率、更高质量的图像。然而Pix2pix GAN 与Pix2pix HD 算法都是针对已配对的数据集设计的,人脸的近红外-可见光图像对的采集非常困难,因为像素级匹配的近红外-可见光人脸数据集比未配对的数据集成本更高。所以,非配对的图像转换模型更适合于近红外-可见光人脸图像转换任务。
Zhu 等人提出的CycleGAN[18],是一种流行的非配对图像到图像的转换模型。CycleGAN 通过引入循环一致性损失,可以同步实现图像到图像的双向转换。与UINT、MUNIT 等模型相比,CycleGAN 鲁棒性更好,更易于训练。Wang 等人基于CycleGAN 结构提出了FFE-CycleGAN[19],采用通用的面部特征提取器来代替CycleGAN 原始生成器中的编码器,在保持可见光域和近红外域的共同面部特征的同时,学习近红外域的特征。Dou 等人[20]提出了一种具有不同大小生成器的非对称CycleGAN 方法。近红外域到可见光域的转换使用复杂网络,可见光域到近红外域的转换使用简单网络,与CycleGAN 相比更加适用于非对称转换任务。Kancharagunta 等人提出了一种循环合成生成对抗网络CSGAN[21],该算法在一个域合成图像和另一个域循环图像之间使用了一种新的目标函数循环合成损失。随后Kancharagunta 等人又提出了一种新的循环判别生成对抗网络CDGAN[22],通过结合用于循环图像的附加判别器网络来生成高质量和更逼真的图像。Taesung 等人提出了一种基于对比学习的图像到图像转换网络CUT[23],该方法创新性地将对比学习的思想应用到图像转换领域,并引入了多层对比损失,实现了一种轻量级的图像转换模型。基于CUT网络,Han 等人提出的DCLGAN[24]使用两套对比学习的设置实现了图像到图像的双向转换。
然而,近红外人脸图像不同于其它的近红外图像,如图1 所示,若人脸轮廓以及面部肤色等细节在着色的过程中被扭曲将会很大程度地影响生成人脸图像的视觉效果与图像质量。因此,有必要根据人脸图像的特点设计算法来强化近红外人脸图像在着色过程中细节信息的保留。

图1 部分算法由近红外生成的可见光图像(首行)与真实可见光图像(末行)对比Fig.1 Comparison of the VIS image (the first row) generated by some algorithms from NIR domain with the real visible image (the last row)
针对近红外人脸图像在着色过程中存在的挑战,本文提出了双重对比学习框架下的近红外-可见光人脸图像转换方法。该方法以双重对比学习网络为基础,采用双重对比学习的方式从图像局部细节出发增强生成图像的质量并且能够实现图像到图像的双向转换。同时,由于StyleGAN2[25]网络相较ResNets[26]能够提取人脸图像更深层次的特征,本文构建了基于StyleGAN2 结构的生成器网络并将其嵌入到双重对比学习网络中替换原始的ResNets 生成器,进一步提升生成人脸图像的质量。此外,本文设计了新的面部边缘增强损失,确保面部边缘信息在图像转换的过程中不被扭曲,提高生成人脸图像的视觉效果。主要贡献如下:
1) 本文提出了一种基于StyleGAN2 网络的双重对比学习框架,构建了基于StyleGAN2 结构的生成器网络并将其嵌入到双重对比学习网络中,利用双向的对比学习挖掘人脸图像的精细化表征。
2) 针对近红外域图像中人像外部轮廓模糊、边缘缺失的特点,本文设计了一种面部边缘增强损失,利用从源域图像中提取的面部边缘信息进一步强化生成的人脸图像中的面部细节。该损失与传统的边缘损失相比误差更小,更加贴合近红外-可见光人脸图像的转换任务。
3) 实验表明本文方法在NIR-VIS Sx1 和NIR-VIS Sx2 两个数据集上的生成效果明显优于近期的主流方法。本文方法生成的可见光人脸图像更加贴近真实图像,能够更好地还原人脸图像的面部边缘细节和肤色信息。
2 本文方法
对比学习作为一种常用的自监督学习方法,其指导原则是:通过自动构造相似实例和不相似实例,学习一个表示学习模型,通过这个模型,使得相似的实例在投影空间中比较接近,而不相似的实例在投影空间中距离较远。应用在图像转换领域的对比学习核心思想是通过构造正负样本使输入和输出图像的对应图像块之间的互信息最大化[23]。如图2 所示,生成的人脸图像中黄色图像块应与输入图像中绿色图像块之间互信息最大,与输入图像中其他蓝色图像块之间的互信息较小。在GAN 做图像转换时应用对比学习可以很好地增强生成图像局部质量,进而提升生成图像整体的质量。双重对比学习网络即使用两套对比学习网络,能够实现图像到图像的双向转换。
然而,仅使用双重对比学习网络在近红外-可见光人脸图像转换任务中并不能生成令人满意的人脸图像。因为StyleGAN2 网络通过将图像的潜在特征在潜在空间进行解纠缠变换,能够提取人脸图像更深层次的特征,所以本文构建了基于StyleGAN2 结构的生成器网络并将其嵌入到双重对比学习框架下。最终本文方法的网络框架图如图2 所示。
2.1 网络概述
如图2 所示,其中近红外域人脸图像记作X域,可见光域人脸图像记作Y域,G、F分别为X→Y、Y→X这两个方向的生成器,Dx、Dy分别为X域和Y域的判别器,最终的目标是不断学习优化G和F这两个方向的映射。生成器前半部分被定义为编码器,后半部分为译码器。即G由Genc与Gdec组 成,F由Fenc与Fdec组 成,它们被依次应用于生成目标域图像yˆ=G(x)=Gdec(Genc(x))、xˆ=F(y)=Fdec(Fenc(y))。

图2 本文网络框架图。为简化网络结构,同一性损失在图中未标示,详见2.4.4 节Fig.2 The structure diagram of the proposed method.To simplify the network structure,the identity loss is not indicated in the figure,see Section 2.4.4 for details
对于每个方向的映射,在原图中随机选择若干图像块,用编码器提取图像块的特征,再通过一个两层MLP 网络把提取的特征投影到共享的嵌入空间,在此基础上计算图像块多层对比损失,利用对比学习的思想使生成图像对应位置的图像块特征更加贴近原图。此外,在原图与生成的目标域人脸图像中同时裁剪出面部区域,并对此区域使用Sobel 算子[27]提取边缘并计算面部边缘增强损失,进一步强化生成的人脸图像中的面部细节。
2.2 生成器结构
在各式生成对抗网络中,StyleGAN[28]网络由于显著地提升了生成图像的分辨率和质量,并且在多个不同数据集上的生成效果都很稳定,一经提出就引起了广泛关注。然而StyleGAN 生成图像中存在类似水滴的斑状伪影,在生成器网络的中间特征图中此类伪影更加明显。升级后的StyleGAN2 网络通过权重解调、延迟正则化与路径长度正则化等方法重点解决了初代网络中存在的伪影问题,进一步提高了图像的生成质量。同时,StyleGAN2 网络也成为了人脸生成领域较为先进的模型。相比双重对比学习网络中原始的ResNets 生成器,StyleGAN2 网络通过将图像的潜在特征在潜在空间进行解纠缠变换,能够提取图像更深层次的特征。此外,在网络结构上StyleGAN2 吸收了ResNets 网络的部分优点,探索了残差连接设计和其它与ResNets 类似的残差概念。因此在人脸图像生成任务中,使用基于StyleGAN2 的生成器网络的生成效果要优于ResNets 网络。
本文的生成器由编码器和译码器构成,结构如图3 所示。原始的StyleGAN2 网络实现的是从向量到图像的转换过程,即通过将潜在向量或随机噪声输入到生成模型中可以输出高质量的生成图像。在此基础上,本文构建的生成器则完成了从输入图像到潜在向量再到输出图像的完整转换过程,通过编码器部分的多个样式块(Style block)将2 56×256大小的输入人脸图像转换为512 维潜在向量z∈Z,译码器来自于StyleGAN2 网络的生成模型,负责将潜在向量z归一化后通过8 个全连接层映射为潜在向量w∈W进行特征解纠缠,最终潜在向量w再经多个样式块生成256×256大小的目标域人脸图像。图3 中绿色样式块包括调制、3 ×3卷积、解调与实例归一化等操作,StyleGAN2 网络利用样式块进行权重解调以简化模型设计。
2.3 判别器结构

图3 本文生成器结构图Fig.3 The structure diagram of generator in the proposed method
本文方法中判别器Dx、Dy均 为 7 0×70 PatchGAN结构。该网络包含五个卷积层,其中第一层由卷积-激活函数(LeakyReLU)构成,中间三层均由卷积-实例归一化-激活函数构成,最后一层只由一个卷积构成。该判别器每次从原图中选取7 0×70大小的图像补丁判别真假,最终输出一个3 0×30大小的矩阵,输出矩阵的均值将作为对图像的评价。
一般的GAN 判别器是针对整张图像输出一个真或假的矢量作为评价,而PatchGAN 通过逐次叠加的卷积层最终输出一个矩阵,其中每个元素实际代表原图中7 0×70大小的图像补丁。这样的补丁级判别器架构比全图像判别器的参数更少,并且对输入图像尺寸的适应性更强。
2.4 损失函数
本文方法共结合了四种损失,包括面部边缘增强损失、图像块多层对比损失、对抗性损失和同一性损失,具体细节如下文所述。
2.4.1 面部边缘增强损失
图像转换领域传统的边缘损失[20]是直接对生成的目标域图像和源域图像提取边缘,计算两张图像边缘之间的损失。然而,这种直接提取图像边缘的方法在近红外人脸图像中并不可取。以图4 所示CASIA NIR-VIS 2.0 数据库[29]为例,其近红外图像中人像的头发与背景几乎融为一体,头发的外围轮廓很难分辨,在此情况下若使用传统的边缘损失直接对近红外图像提取边缘,则与可见光图像提取的边缘相比会产生极大的误差。于是本文提出了针对近红外人脸图像特点的面部边缘增强 (facial edge enhancement,FEE) 损失,对近红外域和生成的可见光域人脸图像仅裁剪出面部区域,在面部区域上提取边缘并计算损失。如图4 所示,裁剪后的面部区域在近红外与可见光条件下均可以提取到较为完整的边缘信息,以此指导人脸图像的生成,保证在人脸图像转换的过程中面部边缘不被扭曲。
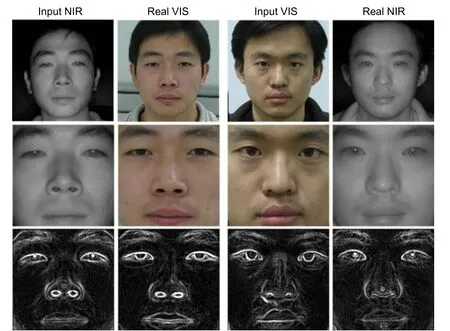
图4 在近红外和可见光条件下分别对人脸图像裁剪出面部区域并提取边缘Fig.4 Crop out facial regions and extract edges from face images in NIR and VIS conditions respectively
最终,本文的面部边缘增强损失定义为源域图像与生成的目标域图像分别提取面部边缘得到的边缘图像之间的L1 距离。其表达式如下所示:

2.4.2 图像块多层对比损失
如图2 所示,在生成的人脸图像中随机选取的黄色图像块称为查询样本,那么在输入图像中相同位置的绿色图像块即为相应的正样本,输入图像中除正样本位置外随机位置选取的蓝色图像块即为相应的负样本。先将查询样本、正样本和N个负样本映射为K维向量,分别记作v、v+∈RK和v-∈RN*K。对K维向量进行L2 正则化后转换为一个(N+1)路分类问题,此时排除负样本选出正样本的概率在数学上可以表示为交叉熵损失,表达式如式(2)所示:

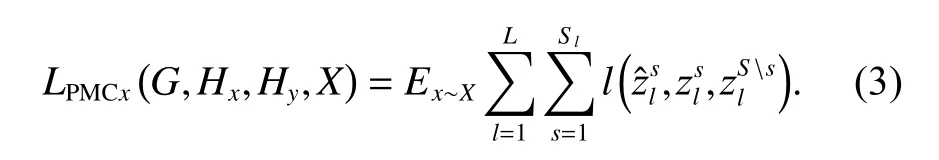
同理,Y→X方向的图像块多层对比损失可以表示为:
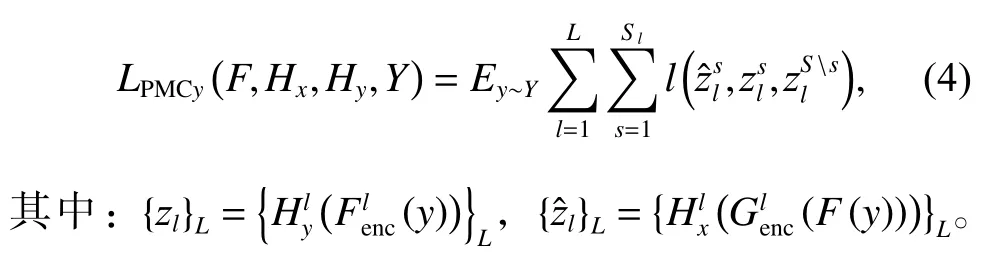
2.4.3 对抗性损失
对抗性损失[12]的目的是使生成器生成的图像在视觉上与目标域图像更加相似。对于从近红外域到可见光域的映射G:X→Y,其对抗性损失为
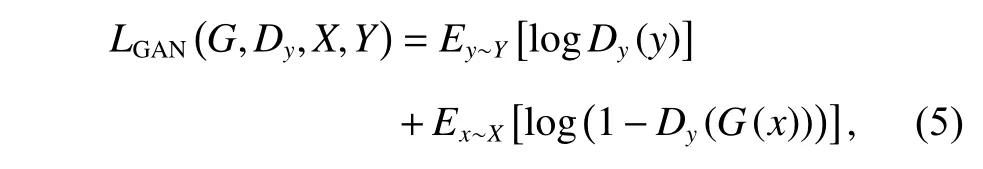
其中:生成器G试图生成更加逼真的可见光域人脸图像G(x),而判别器Dy则试图区分生成的可见光域人脸图像G(x)与真实的可见光域人脸图像。
同理,对于从可见光域到近红外域的映射F:Y→X,其对抗性损失为
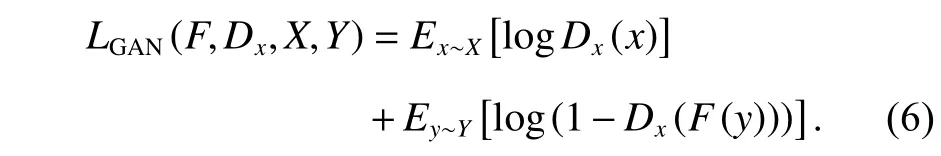
2.4.4 同一性损失
生成器G负责从近红外域到可见光域图像的映射,然而若将可见光域图像输入到生成器G中,理想中的生成器对此时的输入应该不做任何的更改而输出。同理,理想中的生成器F对输入的近红外域图像也应该不做任何的更改而输出。这种情况下真实的输出图像与输入图像之间的L1 损失被定义为同一性损失(identity loss)[18]。通过同一性损失可以纠正生成器的色偏,更好地还原目标域图像的色彩信息。其表达式如下:
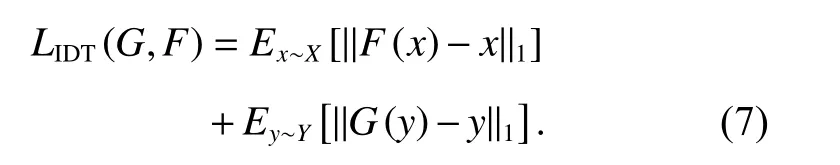
2.4.5 总损失函数
本文通过图像块多层对比损失引入对比学习的思想,使生成图像的整体质量得到了很好的增强;通过面部边缘增强损失保证人脸图像在转换的过程中面部边缘不被扭曲,强化面部细节的保留;通过对抗性损失和同一性损失来进一步优化生成器和判别器,使生成的图像更加贴近目标域真实图像。总损失函数表达式如下:

根据经验和多次实验,本文中各权重参数分别设置为 λFEE= 1,λPMC= 2,λGAN=1,λIDT=1。
3 实验结果及分析
3.1 数据集预处理
本文在NIR-VIS Sx1 和NIR-VIS Sx2 两个数据集上分别建立了训练集和测试集。这两个数据集分别来自CASIA NIR-VIS 2.0 数据库[29]的S1 和S2 部分。S1 部分包含了来自202 位受试者的3002 张近红外图像和2095 张可见光图像,本文从中选择了1000 对近红外-可见光图像对组成了NIR-VIS Sx1 数据集。S2部分包含了来自308 位受试者的5455 张近红外图像和1891 张可见光图像,本文从中选择了1236 对近红外-可见光图像对组成了NIR-VIS Sx2 数据集。两个数据集虽然同属亚洲人脸,但本质上有着较大的区别。NIR-VIS Sx1 数据集中近红外域人脸图像较为清晰,可见光域人脸图像均为纯白色背景。而NIR-VIS Sx2数据集中近红外域人脸图像相对较模糊,可见光域人脸图像因光照不足导致肤色普遍偏暗,并且少部分人像背景为杂乱的室外建筑。
本文在每个数据集中选择75%的图像对作为训练集,其余图像对作为每个数据集中相应的测试集。在实验前,根据眼睛、嘴巴和鼻子等面部器官坐标对每个数据集中的近红外和可见光人脸图像进行预对齐处理,随后以人脸位置为中心统一将图像裁剪并缩放到2 56×256大小。
3.2 实验设置
实验环境:PC 平台为Ubuntu 18.04.5 LTS 系统,Intel Core i7-8700 CPU,Nvidia GeForce GTX 1070Ti GPU,8 GB 显存,使用的软件为PyCharm 2021.1,CUDA 10.1,cuDNN 8.0.5。本文方法使用 β1= 0.5、β2=0.999 的Adam 优化策略,学习率为0.0001,训练周期为400 轮并且学习率在训练总周期一半后线性衰减,批量训练样本数为1。
3.3 定性实验分析
本文选取了CycleGAN[18]、CSGAN[21]、CDGAN[22]、UNIT[13]、Pix2pixHD[17]五种图像转换网络与本文方法作比较,分别在预处理的NIR-VIS Sx1 和NIR-VIS Sx2 数据集上进行了多重验证实验。实验结果如图5所示。
从图5 中可以看出,原始CycleGAN 方法的性能较弱,生成的人脸图像不够清晰,且人脸肤色还原度较差。CSGAN 方法在NIR-VIS Sx1 数据集上生成的人脸图像较为清晰,但在NIR-VIS Sx2 数据集上生成的人脸肤色信息失真严重。CDGAN 方法在NIR-VIS Sx1 数据集上生成效果优于CycleGAN 但人像外部轮廓不够清晰,在NIR-VIS Sx2 数据集上表现较差,生成的人脸较为模糊且背景十分杂乱。UNIT 方法相较CycleGAN 在人脸肤色重建方面性能有所提升,在两个数据集上生成的人脸均和真实可见光人脸较为贴近,但生成的人脸图像中头发等细节仍不够清晰。Pix2pixHD 作为Pix2pix GAN 的升级算法,确实拥有较为出色的性能。在NIR-VIS Sx1 数据集上,Pix2pixHD 生成的人脸图像有着清晰的面部细节和更加真实自然的人脸肤色。然而在NIR-VIS Sx2 数据集上Pix2pixHD 生成的效果不尽理想,例如在图5 第Ⅵ行中对于人像额头上的刘海未能很好地还原,在第Ⅶ行中忽略了人脸皱纹细节导致与真实可见光图像相差较大。本文方法在NIR-VIS Sx1 和NIR-VIS Sx2 两个数据集上都表现出了稳定且更加优异的性能,尤其在图5 第Ⅲ、Ⅵ和Ⅶ行生成的可见光人脸图像不仅保留了更完整的面部细节,还重建了更加真实的肤色信息。
3.4 定量实验分析
为了进一步衡量各种图像转换网络生成的人脸图像质量,本文引入了结构相似性(structural similarity,SSIM[30])与峰值信噪比(peak signal to noise ratio,PSNR[31])两项指标。SSIM 用于衡量两幅图像相似度,取值在0~1 之间,数值越大表示相似度越高。同样地,PSNR 数值越大表示两张图片均方误差越小、图片越接近,单位是dB。在NIR-VIS Sx1 和NIR-VIS Sx2数据集上,CycleGAN、CSGAN、CDGAN、UNIT、Pix2pixHD 与本文方法所生成的人脸图像的平均结构相似性与平均峰值信噪比分别如表1 和表2 所示。

图5 在两个数据集上的对比实验结果。从左到右依次为:输入NIR 人脸图像、CycleGAN、CSGAN、CDGAN、UNIT、Pix2pixHD、本文方法、真实VIS 人脸图像。其中Ⅰ~Ⅲ行来自NIR-VIS Sx1 数据集,Ⅳ~Ⅶ行来自NIR-VIS Sx2 数据集Fig.5 The comparison experimental results on two datasets.From left to right:input NIR face image,CycleGAN,CSGAN,CDGAN,UNIT,Pix2pixHD,the proposed method,and real VIS face image.Where rows Ⅰ~Ⅲ are from NIR-VIS Sx1 dataset,and rows Ⅳ~Ⅶ are from NIR-VIS Sx2 dataset

表1 NIR-VIS Sx1 数据集上各图像转换网络性能比较Table 1 Performance comparison of image translation networks on the NIR-VIS Sx1 dataset
在NIR-VIS Sx1 数据集上,原始CycleGAN 方法生成图像的两项指标均为最低分、性能较差,本文方法取得了最高的SSIM 分数,同时 Pix2pixHD 方法生成结果的两项指标与本文方法均较为接近。在NIRVIS Sx2 数据集上,CDGAN 方法生成图像的两项指标比CycleGAN 方法更低、表现更差,本文方法生成图像的质量显著优于其他方法,SSIM 与PSNR 两项指标均获得了最高分并远超其他方法。
由于SSIM,PSNR 这两项评价指标都是对图像逐像素计算的,当输入图像与目标域图像并非像素级对齐的情况下,使用Fréchet Inception Distance (FID)[32]指标更为有效。FID 是计算生成图像分布和真实图像分布之间距离的一种度量。FID 分数越低意味着生成图像分布与真实图片分布之间越接近,图像质量越好;反之,分数越高则意味着生成图像质量越差。本文同样计算了各图像转换网络分别在NIR-VIS Sx1 和NIRVIS Sx2 数据集上生成图像的FID 分数,结果如表3所示。本文方法在两个数据集上均获得了最低的FID分数、生成的图像质量最好。CycleGAN 方法在NIRVIS Sx1 数据集上FID 分数最高、表现最差。CDGAN方法在NIR-VIS Sx2 数据集上生成的人脸最为模糊且图像背景杂乱,因而FID 分数最高。

表2 NIR-VIS Sx2 数据集上各图像转换网络性能比较Table 2 Performance comparison of image translation networks on the NIR-VIS Sx2 dataset
同时,在表3 中本文还计算了各图像转换网络在测试阶段平均处理单张图像所用时间。CSGAN 与UNIT 方法平均处理单张图像用时和本文方法相近,而Pix2pixHD 与CDGAN 方法平均处理单张图像用时均未超过0.1 s,速度上明显优于本文方法,所以模型的轻量化也将成为本文方法进一步优化的方向。
3.5 消融实验
本文分别在NIR-VIS Sx1 和NIR-VIS Sx2 数据集上做了多项消融实验,进一步验证本文添加的基于StyleGAN2 结构的生成器与各项损失函数的有效性。实验结果如图6 所示,其中“Baseline”为Han 等人提出的原始DCLGAN[24]方法。
从图6 中可以看出,使用ResNets 生成器的原始基线方法在近红外-可见光人脸图像转换任务中表现极差,生成的可见光图像几乎为同一人脸作微调的结果,无法还原真实的人脸细节。本文方法在去除基于StyleGAN2 结构生成器后生成图像的面部细节相比原始基线方法更加清晰,但生成的图像与真实图像仍然相差较大。去除对抗性损失的方法已经不能有效区分近红外域与可见光域的图像,无法正常地训练网络模型,所以生成的图像与输入图像相近。去除同一性损失的方法生成的图像整体上质量较好,但不能很好地纠正生成器的色偏,导致生成的人脸肤色不够真实。去除图像块多层对比损失的方法在生成的图像面部出现了冗余的细节,且肤色有一定的偏差。去除面部边缘增强损失的方法生成的人脸图像整体上与真实图像较为接近,但在眉毛、眼眶和鼻子底部等边缘细节上重建得不够清晰。于是本文方法在基于StyleGAN2结构生成器的基础上进一步综合各项损失函数,能够在生成的人脸图像中保持清晰的面部细节,有效提升了人脸图像的视觉质量。
本文同样计算了在NIR-VIS Sx1 数据集上各项消融实验生成图像的平均结构相似性与平均峰值信噪比指标,实验结果如表4 所示。原始基线方法的性能较差,本文方法在去除基于StyleGAN2 结构的生成器后相较基线方法性能提升较为有限。去除对抗性损失的方法性能最差,SSIM 与PSNR 指标均为最低。最后,本文方法明显优于其它消融方法,达到了最高的SSIM 与PSNR 指标。

表3 各图像转换网络在不同数据集上FID 性能与平均单张测试耗时比较Table 3 Comparison of FID performance and average single test time of each image translation network on different datasets

图6 在两个数据集上的消融实验结果。从左到右依次为:输入NIR 人脸图像,基线方法,分别去除StyleGAN2、LGAN 、LIDT 、LPMC、 L FEE 的本文方法,本文方法,真实VIS 人脸图像。其中Ⅰ~Ⅱ行来自NIR-VIS Sx1 数据集,Ⅲ~Ⅳ行来自NIR-VIS Sx2 数据集Fig.6 Results of the ablation experiments on two datasets.From left to right:input NIR face image,Baseline method,the proposed method without StyleGAN2、L GAN 、L IDT 、L PMC、LFEErespectively,the proposed method and real VIS face image.Where rows Ⅰ~Ⅱ are from NIR-VIS Sx1 dataset and rows Ⅲ~Ⅳ are from NIR-VIS Sx2 dataset

表4 NIR-VIS Sx1 数据集上各消融方法性能比较Table 4 Performance comparison of ablation methods on the NIR-VIS Sx1 dataset
3.6 讨论
本文设计的面部边缘增强损失,利用从源域图像中提取的面部边缘信息进一步强化生成人脸图像中的面部细节。所以,选择合适的边缘提取方法确保在可见光和近红外条件下都能提取到准确完整的面部边缘十分重要。本文选择了Roberts 算子、Prewitt 算子、Sobel 算子、Laplacian 算子和Canny 算子分别对可见光和近红外人脸图像提取面部边缘,结果如图7 所示。使用Roberts 算子和Laplacian 算子得到的图像边缘较为微弱,使用Canny 算子得到的二值图像轮廓过于粗犷、人脸细节损失较多,所以这三种算子均不适用于本文的面部边缘提取任务。使用Prewitt 算子得到的边缘图像整体较为接近Sobel 算子得到的边缘图像,但Sobel 算子能够提取到更加完整的边缘细节,如第一行图像中的鼻翼边缘与第二行图像中的嘴唇边缘。
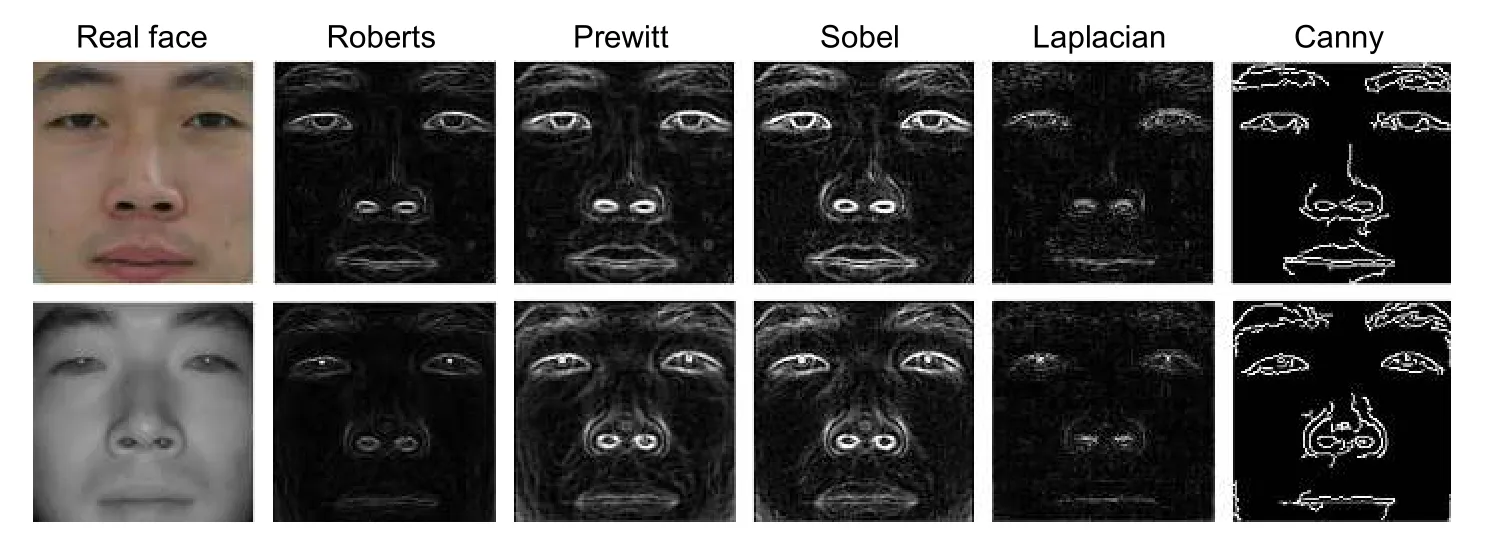
图7 分别使用各边缘提取方法得到的边缘图像对比。从左到右依次为:真实人脸图像、Roberts 算子、Prewitt 算子、Sobel 算子、Laplacian 算子、Canny 算子Fig.7 Comparison of edge images obtained by using each edge extraction method separately.From left to right:real face image,Roberts operator,Prewitt operator,Sobel operator,Laplacian operator,Canny operator
为了进一步比较使用Prewitt 算子和Sobel 算子对本文方法生成效果的影响,本文分别使用这两种算子应用到面部边缘增强损失中,在NIR-VIS Sx1 数据集上进行对比实验并计算生成图像的平均结构相似性与平均峰值信噪比,实验结果如表5 所示。使用Sobel算子的方法在SSIM 和PSNR 性能上均优于使用Prewitt 算子的方法,所以本文最终选定Sobel 算子作为面部边缘损失中的边缘提取方法。
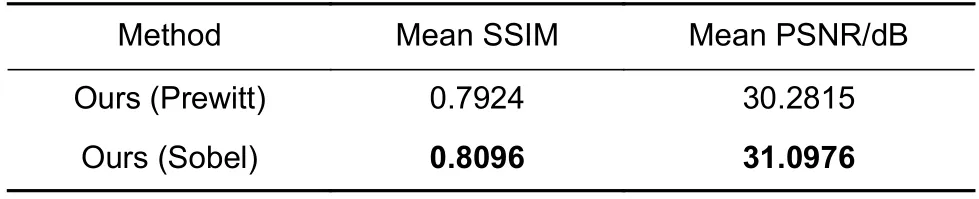
表5 NIR-VIS Sx1 数据集上分别应用Prewitt 算子与Sobel 算子的性能比较Table 5 Performance comparison of applying the Prewitt operator and Sobel operator respectively on the NIR-VIS Sx1 dataset
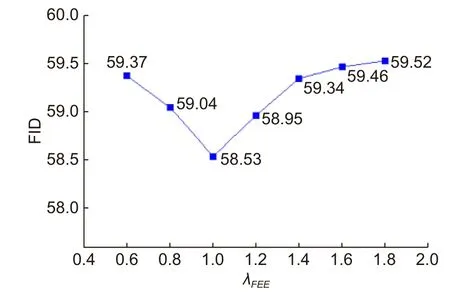
图8 NIR-VIS Sx1 数据集上不同 λFEE取值对本文方法性能的影响Fig.8 The effect of different values of λFEE on the performance of our method on the NIR-VIS Sx1 dataset
本文在确定各项损失函数权重参数时,参考了基线模型DCLGAN[24]中关于 λPMC、λGAN和 λIDT这三项权重的设置,于是本文重点评估了 λFEE的不同取值对本文方法性能的影响。如图8 所示,横轴为面部边缘增强损失的权重参数 λFEE,纵轴为在NIR-VIS Sx1 数据集上本文方法生成图像的FID 分数。从图8 中可以看出,λFEE取值的变化确实会影响本文方法的性能,当 λFEE=1 时,生成图像的FID 分数最低、图像质量最好,故本文中设置 λFEE=1。
4 结 论
本文提出了一种新的双重对比学习框架下的近红外-可见光人脸图像转换方法。该方法构建了基于StyleGAN2 结构的生成器网络并将其嵌入到双重对比学习框架下,使用基于StyleGAN2 结构的生成器网络提取人脸图像更深层次的特征,同时利用双向的对比学习挖掘人脸图像的精细化表征。此外,由于近红外域图像中人像外部轮廓模糊、边缘缺失,本文提出了施加在源域图像与生成的目标域图像之间的面部边缘增强损失,确保面部边缘信息在图像转换的过程中不被扭曲,进一步提高生成人脸图像的视觉质量。最后,在NIR-VIS Sx1 和NIR-VIS Sx2 两个数据集上的实验结果验证了本文方法的有效性和优越性。与近期主流的方法相比,本文方法生成的人脸图像不仅保留了更完整的面部细节,还重建了更加真实的肤色信息。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
四川大学学报(自然科学版)(2021年6期)2021-12-27
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
计算机应用(2020年12期)2020-12-31
校园英语·上旬(2020年1期)2020-05-09
动漫星空(2018年9期)2018-10-26
卷宗(2017年16期)2017-08-30
文苑(2015年9期)2015-09-10
奇闻怪事(2014年5期)2014-05-13
