
基于深度度量学习的卫星云图检索
2022-05-10 12:13金柱璋方旭源黄彦慧尹曹谦
光电工程 2022年4期
金柱璋,方旭源,黄彦慧,尹曹谦,金 炜
宁波大学信息科学与工程学院,浙江 宁波 315211
1 引 言
气象卫星能从空中监测不同尺度的天气现象,其所获取的卫星云图对于天气分析与预报均有重要的作用。近年来,随着气象卫星技术的发展,卫星云图的空间光谱分辨率和采集频率不断提高,如何管理海量的卫星云图,设计高效的云图检索系统成为困扰气象工作者的难题。卫星云图检索属于图像检索范畴,主要包括基于文本的图像检索(text-based image retrieval,TBIR)和基于内容的图像检索(content-based image retrieval,CBIR)。由于TBIR 需耗费大量时间进行标注,CBIR 已成为图像检索的主流技术,并在云图检索中得到应用。徐坚[1]设计了一个基于颜色和纹理特征的云图检索系统,提高了云图特征的表达能力;上官伟[2]通过提取云图的形状特征,并对特征加权提高了检索精度;李秀馨[3]利用模糊C 均值聚类分割出各云系后,提取云系特征,进一步改善了对于云系的表征能力;徐晔晔[4]结合Otsu 和改进分形维数算法首先对云系进行分割,并利用多特征融合实现了红外云图检索。虽然上述方法在云图检索性能上各有优势,但均采用人工定义的底层特征来表征云图,难以捕获云图蕴含的气象语义信息,且特征维度往往较高,算法的计算复杂度不容忽视。
随着人脑视觉感知机制研究的兴起,深度学习在各领域异军突起,特别是深度卷积神经网络(deep convolutional neural networks,DCNN)在图像分类[5]、检索[6]和分割[7]等领域都得到了广泛的应用。区别于传统自然图像,卫星云图具有多波段特点,当使用传统二维卷积神经网络(2D convolutional neural networks,2D CNN)提取特征时,难以有效刻画云图的波段信息。受Roy 等人在高光谱图像分类工作[8-9]的启发,本文通过构建残差三维-二维卷积神经网络(residual 3D-2D convolutional neural network,R3D-2D CNN),提出了一种基于深度度量学习的卫星云图检索方法。该方法首先利用三维卷积和二维卷积分别提取云图的光谱信息和空间信息,以空谱联合特征捕捉的策略表征云图蕴含的气象语义信息。在此基础上,针对部分云图在特征空间存在类内差异大类间差异小的问题,采用深度度量学习[10-12](deep metric learning,DML),通过三元组训练方法[10],将云图映射到度量空间中,使得样本特征间的距离满足检索的要求。同时,鉴于传统三元组损失易使模型落入局部最优的情况,本文对三元组损失函数进行改进,在解决早熟收敛问题的同时,进一步拉近相似云图在嵌入空间中的距离,并引入哈希学习以汉明距离计算云图间的相似度,从而在保证检索精度的情况下提高了检索效率。
2 数据获取及模型构建
2.1 数据集构建
Himawari-8 气象卫星是日本发射的新一代静止卫星,其上搭载的成像仪(Advanced Himawari Imager,AHI)较上一代卫星在频带数量、空间分辨率和时间频率方面都有很大改善[13]。该卫星具有3 个可见光、3 个近红外和10 个红外观测波段,3 个可见光波段中心波长分别为0.46 μm、0.51 μm 和0.64 μm,3 个近红外波段中心波长分别为0.96 μm、1.6 μm 和2.3 μm,10 个红外波段中心波长分布于3.9 μm~13.3 μm 之间。其中,可见光和近红外波段的云图数据以反射率形式呈现,而红外波段以亮度温度形式呈现,二者可以分别反映云层的厚度和云层的高度[14]。如果将不同模态的卫星云图简单融合设计云图检索系统,不仅难于提高检索的准确度,而且将带来额外的计算复杂度。因此传统云图检索算法往往基于3 个可见光波段进行设计,这就忽略了能够提供如水/冰相态、粒子大小和光学厚度等云物理参数的其它波段[13]的信息。为了综合利用不同波段的信息,本研究选取3 个可见光和3 个近红外波段的云图数据开展检索系统的研究。
本文所选取的Himawari-8 气象卫星云图由日本宇宙航空研究开发署的P-Tree 系统所发布,研究区域为东经121°~125°,北纬28°~32°的中国东南沿海,时间范围包括2017 与2018 年每日北京时间10 点至11 点。我们将全圆盘云图数据依据研究区域的经纬度进行截取,生成大小为81 pixel×81 pixel 的不同时刻的6 波段云图后组成数据集,并对各云图依据对应气象站的历史天气状况记录进行标注。数据集包括1244 个时次的阴天云图、372 个时次的晴天云图、1219 个时次的雨天云图和792 个时次的台风云图,图1 为研究区域不同天气状况的可见光波段1 的云图示例。
在此基础上,为了刻画完整的天气系统,本文参考云图数据集LSCIDMR[15]的构建方法,以1000 pixels×1000 pixels 大小的滑动窗口对Himawari-8 的北半球云图进行截取,并参照LSCIDMR 的标注将所截取的云图标注为热带飓风、锋面、西风急流、雪等不同的天气系统;为了控制算法的计算复杂度,本文将6 通道的1000 pixels×1000 pixels 的云图缩小为128 pixels×128 pixels;为了使不同类别天气系统的云图数量基本均衡,我们筛选了632 个时次的锋面云图、628 个时次的西风急流云图、717 个时次的雪天云图和698 个时次的热带飓风云图组成北半球区域云图数据集,图2给出了不同天气系统可见光波段1 的云图示例。下文的研究将分别基于东南沿海区域云图数据集和北半球区域云图数据集展开,为了叙述简洁,将它们分别简称为沿海云图数据集和北半球云图数据集。
2.2 模型构建
设卫星云图数据集为I={x1,x2,...,xi,xn},n代表数据集样本的数量,xi为每时次的云图,其对应的天气标签为yi。为了实现云图检索系统,本模型应用哈希函数将卫星云图编码为二值哈希码:h:I→{-1,1}K×n,其中K为哈希码的位数。我们首先构建残差三维-二维卷积神经网络模型以刻画云图的空谱联合特征,然后通过度量学习监督模型训练,提取云图的哈希码特征。图3 为算法流程图。
本模型采用两个时次的同类云图和一个时次的非同类云图组成三元组,开展度量学习训练。三元组通过R3D-2D CNN 生成近似哈希码,经过二值化操作转换成哈希码后存储到哈希码库中。在测试阶段,待检索云图的哈希码同云图库中历史云图的哈希码进行比对,并通过计算汉明距离返回检索结果。
2.2.1 残差三维-二维卷积神经网络
为了提取卫星云图的空间及多波段光谱特征,本文在二维卷积网络的基础上,构建了如图4 所示的残差3D-2D 卷积神经网络。

图1 不同天气可见光波段1 的云图。(a) 阴天;(b) 雨天;(c) 晴天;(d) 台风Fig.1 Visible band 1 cloud images of different weather(a) Cloudy;(b) Rainy;(c) Fair;(d) Typhoon

图2 不同天气系统可见光波段1 的云图。(a) 雪;(b) 锋面;(c) 西风急流;(d) 热带飓风Fig.2 Visible band 1 cloud images of different weather systems.(a) Snow;(b) Frontal surface;(c) Westerly jet;(d) Tropical cyclone
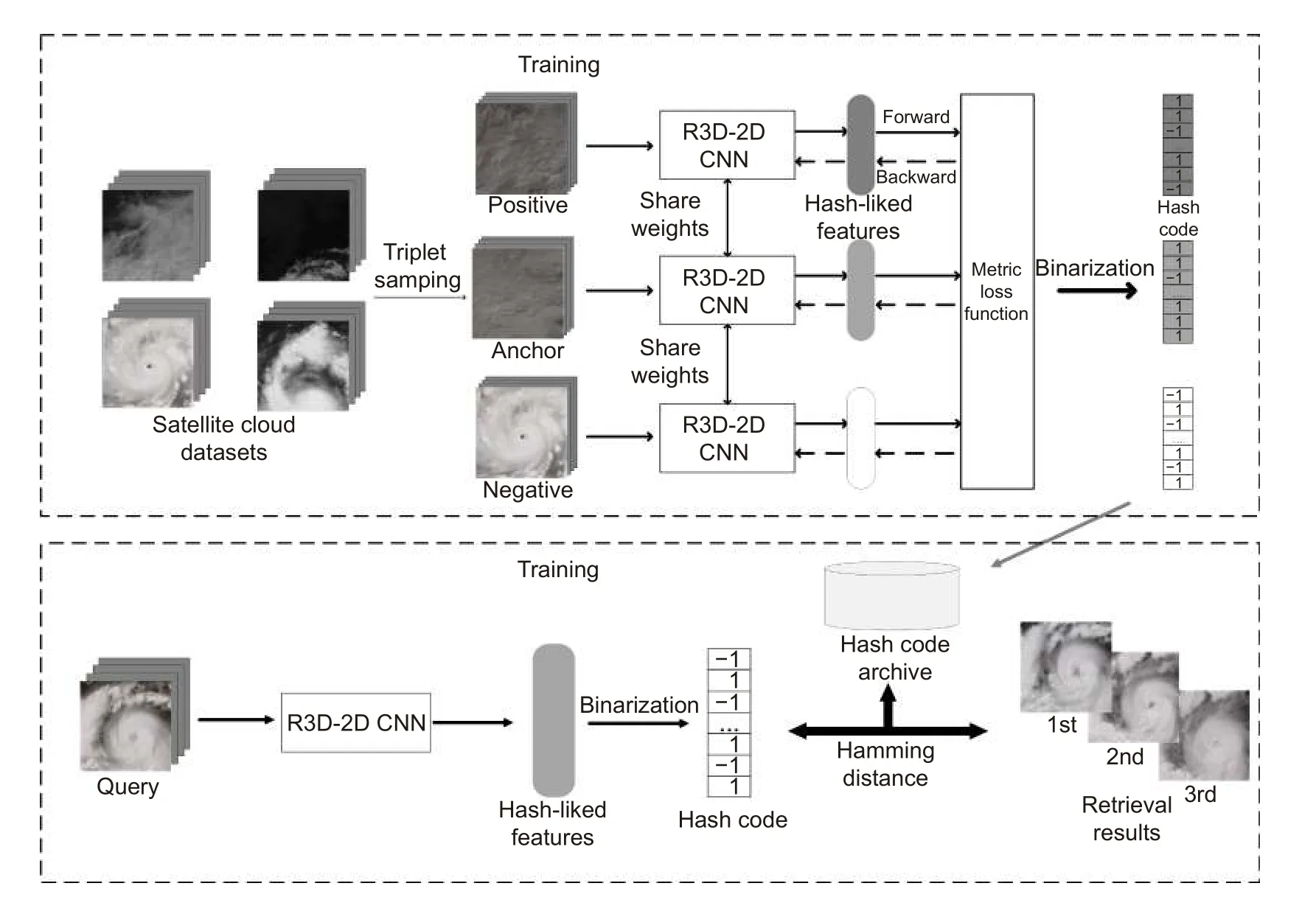
图3 算法流程图Fig.3 Overall algorithm flow chart

图4 残差3D-2D 卷积神经网络Fig.4 Residual 3D-2D convolution neural network
从图中可知,残差3D-2D 卷积神经网络分为两个模块:光谱特征学习模块(spectral feature learning)和空间特征学习模块(spatial feature learning)。其中在光谱特征学习模块(图4 上半部分)中,为了加快模型收敛并克服网络退化,引入了残差块(Spectral_ResBlock)[16]的结构,通过多个残差块,不仅可以提取云图的深层光谱特征,而且通过恒等映射,模型训练时梯度能在高低层间迅速传递,从而促进和规范化模型的训练过程。为有利于云图光谱特征的提取,本文在模型中引入了通道注意力机制。首先通过全局平均池化(global average pooling)和全局最大池化(global max pooling)对特征图进行聚合,之后将聚合的特征图输入一个共享的多层感知机(multilayer perceptron,MLP)来生成对应的特征向量,特征向量按各元素相加并经过sigmoid 激活后获得通道注意力权重向量。最后运用权重向量对原始特征图进行加权,以细化特征图中各个通道的权重,使模型关注有意义的通道而削弱对无意义通道的关注度。在提取云图光谱信息的基础上,为了进一步刻画云图的空间信息,该模型通过矩阵变维操作,改变特征图的维度,输入空间特征学习模块。在空间特征学习模块中(图4 下半部分),本文以残差块的形式构建二维卷积来提取云图的空间信息。考虑到网络最终以哈希码的形式表示卫星云图,我们采用全局平均池化整合特征图的全局空间信息,并输入神经元个数为K的全连接层,以双曲正切函数( tanh)作为全连接层的激活函数,获得K位(-1,1)的近似哈希码。
2.2.2 深度度量学习
由于采用传统交叉熵分类损失训练的深度网络难于全面刻画云图间的差异,致使所提取的云图特征会存在类间差异小、类内差异大的情况[17]。为了解决这一问题,本文引入度量学习,采用三元组训练将云图特征映射到度量空间,使得在度量空间中同类云图间的距离小于非同类云图。三元组t={(ga,gp,gn)}由锚样本、正样本和负样本组成,其中锚样本ga和正样本gp类别相同,而负样本gn则属于不同类别。在训练时,ga和gp组成一组正样本对,而ga和gn组成一组负样本对,通过网络训练,使得正样本对间距离缩小,负样本对间距离扩大[18],如图5 所示。
2.3 目标函数构建


图5 训练后正样本对间距离缩小,负样本对间距离扩大Fig.5 After training,the distance of the anchor-positive decreases and the distance of the anchor-negative increases
传统三元组度量学习采用哈希码以汉明距离来计算样本间的距离,造成使用三元组损失进行模型训练时梯度难于计算,文献[19]对二进制约束进行连续松弛(continuous relaxation),将离散的哈希码转换成近似哈希码(即连续的云图特征向量),经过连续松弛后三元组损失如下:其中 ξ()代表指示函数,当三元组损失L大于0 时为1,其他情况为0。可以看出,三元组损失所训练网络的性能依赖于阈值的设置,当正样本对间的距离与阈值之和小于负样本对间的距离时,梯度为0,模型参数无法得到更新,模型陷入早熟收敛。为解决此问题,Arsenault 提出了无损三元组损失[21]:

式中:N为哈希码位数的4 倍即 4K,ε是一个小正数以避免ln0 的出现。由于正样本对间的距离,因此。利用此损失函数,只有当锚样本与正样本间的距离接近0 时,损失函数才会达到最小值,因此能解决传统三元组损失的早熟收敛问题。然而,式(5)计算的三元组损失缺少对正样本对间距离的限制,从而可能造成同类云图在嵌入空间中不够紧密[22],并降低模型的检索性能。为此,我们在无损三元组损失的基础上对正样本对间的距离进行约束,得到如下所示的损失函数:

式中:λ为平衡参数,而 β规定类内相似度的阈值。我们将卫星云图所对应的近似哈希码使用符号函数(sign)进行二值化处理,生成云图对应的哈希码。在云图检索时,通过待检索云图与云图库中历史云图的哈希码的比较,即可返回检索结果。
3 实验结果与分析
本文实验的硬件环境为Intel Core i5-10600KF CPU@4.10 GHz,32 GB 内存,NVIDIA GeForce RTX 3060,基于Keras 和tensorflow 框架构建深度网络模型。我们将沿海云图数据集和北半球云图数据集分别按8:2 和7:3 划分训练集和测试集。对每时次的云图旋转90°、180°和270°以扩增训练集,尽量减轻网络的过拟合问题。参照文献[23]的策略将锚样本与容易正样本&困难负样本(easy positive &hard negative)组成三元组,采用自适应矩估计(adaptive moment estimation,Adam)优化器进行网络训练,初始学习率设置为1 0-5,目标函数中的超参数 λ、β分别设置为0.01 和0.002。采用准确率(precision,P)和平均精度均值(mean average precision,mAP)两个指标对检索方法的性能进行评估[24]:
式中:L为检索时给定的返回云图数量,m(xi)代表返回结果中与待检索云图xi同 类别的云图数量,Q为待检索图像的总数,为了表示简洁,将PPrecision@L统一简写为P@L。式(8)中,AP 为每张云图的检索精度均值(average precision,AP),计算方法如下:
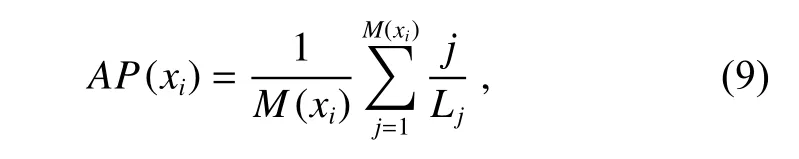
式中:M(xi)表 示在云图数据集中与xi同类别的云图数量,在第j次检索时,当给定返回的云图数量为Lj时,系统刚好检索到j个时次的同类别云图。以下将通过实验分析损失函数和哈希码长度对模型性能的影响,并将本文模型与其他检索算法进行比较。
3.1 损失函数对模型性能的影响
为了评价不同损失函数对于本模型的影响,分别以三元组损失(triplet loss,TL)、无损三元组损失(lossless triplet loss,LTL)和限制正样本对距离的无损三元组损失(constrained lossless triplet loss,CLTL)作为目标函数对模型进行训练,并比较了采用不同损失函数模型的检索性能。实验中,哈希码长度设为64 位,三元组损失中的阈值设定为0.2,实验结果如表1 和表2 所示。
从表1 和表2 可以看出,基于传统三元组损失函数的模型在两个数据集的检索实验中,检索准确率与平均精度均值均不理想,这可能是由于采用传统三元组损失函数时模型早熟收敛落入伪优造成的;采用无损三元组损失的模型在检索准确率及平均精度均值指标上均有所改善,在返回20 张云图时,在两个数据集上检索准确率分别提高了3.49%和3.08%。而采用限制正样本对距离的无损三元组损失函数模型,由于对正样本对间的距离施加约束,使得嵌入空间中同类云图的类簇更加紧密,模型的检索性能得到了进一步的提高,在两个数据集上mAP 分别达到了75.14%和80.14%。

表1 沿海云图数据集中不同损失函数的模型检索性能Table 1 The model retrieval performance of different loss functions in coastal cloud image dataset

表2 北半球云图数据集中不同损失函数的模型检索性能Table 2 The model retrieval performance of different loss functions in the North hemisphere cloud image dataset
3.2 哈希码长度对检索性能的影响
不同的哈希码长度会对检索系统的性能产生影响,以沿海云图数据集为例,将哈希码长度K,分别设定为32、64、128 和256 位,开展检索性能的对比实验,结果如图6 所示。
从上图可以看出,当K=32 时,在返回30 张云图时,准确率仅为68.69%,虽然随着K值的增大,检索性能会得到改善,然而当K达到64 后,模型性能基本趋于稳定。从计算效率上看,K=256 时检索一张云图约需1.71 ms,而K=64 时检索一张云图仅需0.96 ms,综合考虑检索性能与计算效率,本文将哈希码长度设定为64 位。

图6 哈希码长度对模型的影响Fig.6 The effects of the hash code length on model performance
3.3 不同检索算法性能比较
为了验证本文算法的有效性,在沿海云图数据集和北半球云图数据集上开展了与其它检索算法的对比实验,对比算法包括:1) 基于核的监督哈希(kernelbased supervised Hashing,KSH)[25];2) 基于深度学习的二进制哈希(DLBHS)[26];3) 基于度量学习的深度哈希 (metric-learning-based deep Hashing network,MiLan)[18];4) 深度监督哈希(deep supervised Hashing,DSH)[19]。其中KSH 方法采用三个可见光通道叠加后所提取的GIST 特征[27],DLBHS方法使用VGG16 作为特征提取器,所有方法的哈希码长度均为64 位,实验结果如表3 所示。
从上表可以看出,KSH 方法的检索性能最不理想,mAP 仅有60%左右,这主要是由于KSH 所采用的人工定义的特征难于捕捉云图的深层信息;基于深度学习的DLBHS、DSH 与Milan 方法在获得图像的深度特征后,再生成哈希码,可以有效表征云图的深层信息,因此检索性能有所改善。相较于本文算法,这些基于深度学习方法的检索性能不够理想,一方面是因为在特征提取阶段未能有效刻画云图的光谱信息;另一方面是因为在哈希码生成阶段所采用的相关度量损失函数不够优化。本文方法则通过R3D-2D CNN更好地表征了云图的空间和光谱信息,而且采用改进的无损三元组损失优化了嵌入空间中的样本分布,因此检索性能有了进一步的改善,在沿海云图数据集和北半球云图数据集上,mAP 分别达到75.14%和80.14%。
为了直观展示本文方法的检索性能,给出了不同方法的检索实例。对于沿海云图数据集,选取2018年1 月30 日的多云天气云图(cloudy)作为待检索云图,检索结果如图7 所示。
从图7 可以看出,KSH 方法的检索结果不够理想,Top7 中包含了雨天云图(rainy);DLBHS、DSH与Milan 方法虽然返回的云图均属于多云天气,但没能有效返回相邻时次的相似云图,从视觉表现上看,与待检索云图相似度的排序也不合理,而且返回结果中部分云图的云团形状与纹理表现和待检索云图差异较大;本文方法不仅有效返回了相邻时次的相似云图,而且返回结果大都与待检索云图具有一致的形状与纹理表现。对于北半球云图数据集,选取了2019 年4月21 日的西风急流云图(Westerly Jet)进行检索实验,结果如图8 所示。

表3 各数据集在不同方法下的检索准确度Table 3 Comparison of retrieval performance between different retrieval methods

图7 多云天气云图实例检索结果Fig.7 Retrieval results of cloudy weather image

图8 西风急流云图实例检索结果Fig.8 Retrieval results of westerly jet cloud image
从图8 可以看出,KSH 方法的表现最不理想,返回的云图大都为锋面云图(frontal surface);DSH与Milan 方法的返回结果也均包含与待检索云图非同类的锋面云图,虽然DLBHS 方法的返回结果均为西风急流云图,但从视觉相似度上看,本文方法的返回结果与待检索云图的相似度排序更加合理。
4 结 论
为了提取多波段卫星云图的光谱和空间信息,本文通过残差3D-2D 卷积神经网络来表征卫星云图,同时引入度量学习,采用三元组训练得到云图的哈希码特征,实现云图检索。在模型训练时,通过对无损三元组损失函数增加正样本对间距离的约束,改善了传统三元组损失的收敛性能。实验结果表明,在东南沿海云图数据集和北半球区域云图数据集上,mAP分别达到了75.14%和80.14%,优于其它对比方法;下一步将研究如何更好地利用卫星云图的红外与可见光信息,以提高云图检索方法的性能。
猜你喜欢
导航定位学报(2022年4期)2022-08-15
大数据(2021年6期)2021-11-22
电脑爱好者(2021年8期)2021-04-21
山西大学学报(自然科学版)(2021年1期)2021-04-21
电脑爱好者(2020年20期)2020-10-22
五邑大学学报(自然科学版)(2019年3期)2019-09-06
中国现代中药(2019年5期)2019-07-03
计算机技术与发展(2018年12期)2018-12-20
名家名作(2017年3期)2017-09-15
电脑爱好者(2015年13期)2015-09-10
