
基于模糊聚类算法的S700K型电动转辙机运行状态评估
2022-05-10 11:45魏文军武晓春高利民
铁道学报 2022年4期
魏文军,李 政,武晓春,高利民
(1.兰州交通大学 自动化与电气工程学院, 甘肃 兰州 730070;2.兰州交通大学 光电技术与智能控制教育部重点实验室, 甘肃 兰州 730070;3.中国国家铁路集团有限公司 铁路基础设施检测中心, 北京 100081)
S700K型电动转辙机(以下简称S700K转辙机)是实现转换道岔、锁闭道岔和反映道岔状态的关键机电一体化设备,广泛应用于高速铁路中,其稳定性对于列车安全运行有重要的作用[1]。现阶段,铁路部门主要采用计划型检修和故障型抢修两种方式来保障转辙机正常运行,对人工经验要求较高,存在过剩维修、安全风险大等问题[2]。随着行车密度和列车运行速度的增加,对于转辙机维护策略提出更高的要求。近年来,国内外研究者对转辙机故障诊断进行深入研究,提出了大量有效、具有实用意义的诊断算法[3-6],然而实际中需要对转辙机整个运行周期进行评估,得知它处于正常状态、亚健康状态还是故障状态,从而提高转辙机的检修效率,但目前对转辙机运行周期内的状态评估研究较少,评估算法尚不成熟。
要实现对S700K转辙机运行状态的评估,状态信息提取是首要问题,转辙机在不同运行状态下,其动作曲线呈现不同特性。现在的研究大多集中在故障特征提取上,许庆阳等[7]提出利用Fisher准则函数和主成分析(PCA)相结合的算法,对转辙机动作功率曲线进行信号特征提取,解决了信号冗余带来的特征集维数过大问题,但忽略了时频域特征的权重分析,难以充分表征状态信息。钟志旺等[8]对转辙机功率曲线进行时域分析,以均方根值、峭度、峰值因子等时域指标构建特征参数,但存在信号特征信息单一,对细节分量不敏感等问题。周祥鑫等[9]采用小波阈值分析方法,实现信号序列降噪和特征分析的目标,但存在基函数和阈值参数的选择困难等问题。
特征提取后需要基于特征对状态进行评估,王瑞峰等[10]将灰色关联度和神经网络相结合,建立灰色神经网络模型,通过训练来确定待检曲线当前运行状态,但对样本集数量要求高,实际上转辙机真实故障数据很少。黄世泽等[11]利用弗雷歇距离定义的相似度函数,将相似度最大的模板曲线作为输出状态,但易受个体差异和外界环境的干扰,不具有推广意义。
考虑上述不足,引入新的方法,在进行特征提取时,文献[12]提出利用LMD分解方式提取滚动轴承振动信号特征,具有自适应、特征提取充分等优势,同时考虑到排列熵对信号序列复杂度敏感[13],将LMD分解和PE相结合以定量描述转辙机在不同状态下的特征变化,解决微小特征的充分提取。在进行运行状态评估时,模糊聚类分析是对研究对象进行多元分类的算法[14],以不同的置信因子形成动态聚类图,进而能够直观表达分类情况,且具有不需要训练、精度高和适用于实时评估分析的特点。
通过以上分析,本文提出基于模糊聚类的S700K转辙机运行状态评估算法。首先,对不同运行状态下的转辙机功率曲线进行LMD频域分析,并计算不同频率分量下的PE值,从而获取特征向量;然后,以不同运行状态下的转辙机特征向量建立样本集,并结合测试集完成初始模糊矩阵的构建,利用模糊聚类算法形成动态聚类图;最后,根据样本集中聚类类别数,当选定特定置信因子值时,对测试集和样本集进行匹配分类,从而实现对S700K转辙机运行状态的实时评估。通过实例进行验证分析,该算法能够准确评估转辙机运行状态,具有实用价值。
1 状态评估算法
1.1 局部均值分解(LMD)
LMD算法最早是由Smith提出的自适应信号处理方法[15],相比经验模态分解(EMD)解决了模态混叠、端点效应等问题,在处理非线性、非平稳信号时有独特的优势。
LMD分解过程可描述为:通过对信号序列局部极值点的滑动平均处理,将分离出的调频信号和包络信号相乘得到一系列乘积函数(Production Function, PF)分量。假设任意原始信号为x(t),LMD分解将原信号分解成n个PF分量和一个单调函数ui之和,即
( 1 )
LMD分解流程见图1,确定原始信号x(t)的所有极值点为ni,所有相邻两个极值点之间的均值mi经滑动平均处理后求得局部均值函数mik。包络估计值ai进行滑动平均处理后求得包络估计函数aik,其中hik(t)和sik(t)分别为中间变量,最后得到具有不同频率特性的ui(t)为LMD分解结果。
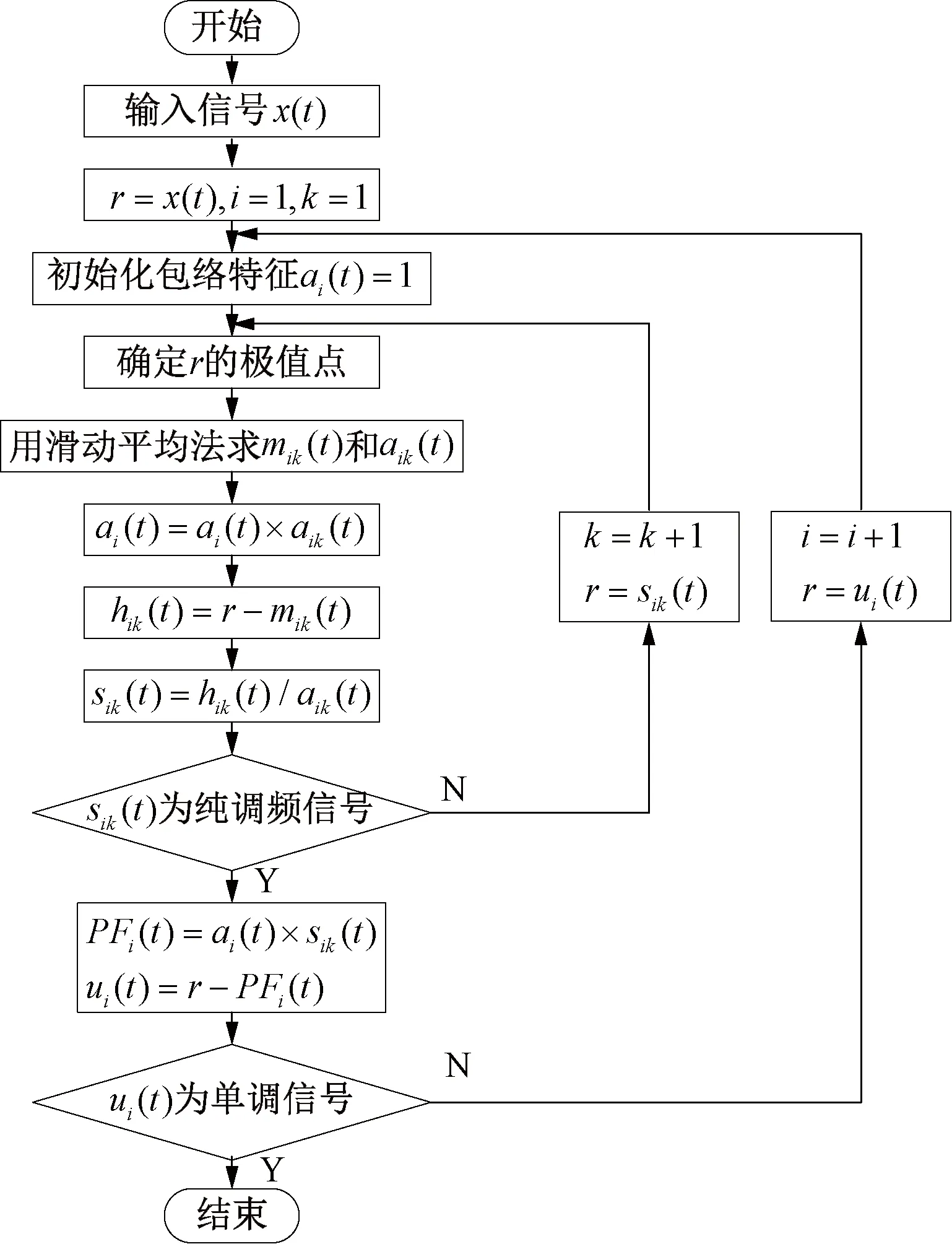
图1 LMD分解流程
1.2 排列熵(PE)
排列熵是衡量信号序列复杂度指标,对于任意信号序列X={x(i)∣i=1,2,…,n},当时延参数为τ,嵌入维度为m时,PE具体计算步骤如下:
(1) 粗粒化处理:将一维信号序列X在尺度因子s下进行粗粒化处理,形成n/s维向量。
( 2 )
式中:1≤j≤⎣n/s」,⎣n/s」为向下取整函数;y为粗粒化后的信息序列,即y={y(j)|j=1,2,…,⎣n/s」}。
(2) 相空间重构:对粗粒化后的信号序列进行相空间重构,重构矩阵为
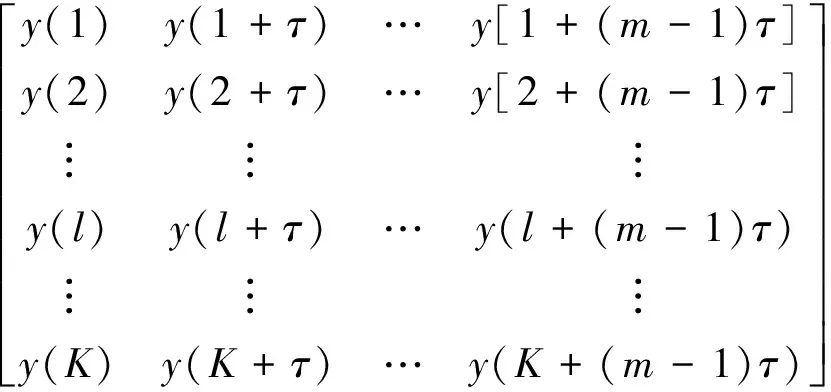
( 3 )
式中:l=1,2,…,K;K=⎣n/s」-(m-1)τ,m为嵌入维度。
(3) 熵值计算:将重构矩阵行向量进行升序排列,记S(l)=(i1i2…im)(l=1,2,…,K且K≤m!)为重构行向量元素所在列的索引。重构排序共有m!种,记S(l)在重构排序中的概率分布为Pl,并统计重构矩阵行向量不同排序的概率,则熵值为
( 4 )
(4) 归一化处理:对Hp(m)进行归一化处理,则为
Hp(m)=Hp(m)/ln(m!)
( 5 )
根据熵值定义可知:信号序列越复杂,熵值越大,用于量化不平稳、非线性信号特征。
1.3 模糊聚类分析算法
模糊聚类分析是在给定的n个对象下,根据对象特征之间的相似度完成样本归类分析。本文采用基于模糊关系的传递包法建立模糊等价矩阵,当置信因子λ∈[0,1]从大到小变化时,由对应的布尔矩阵形成动态聚类图。算法实现主要包括以下步骤:
Step1建立模糊矩阵X。
域U={x1,x2,…,xn}为给定的n个对象,每个对象又有m个指标表示其特性
xi=(xi1,xi2,…,xim)i=1,2,…,n
( 6 )
于是,对应模糊矩阵为
( 7 )
Step2数据标准化(X→X″)。
模糊矩阵中数据存在着不同量纲,为使其数据标准化,通常需要两种变换方式。
(1) 平移-标准差变换
( 8 )
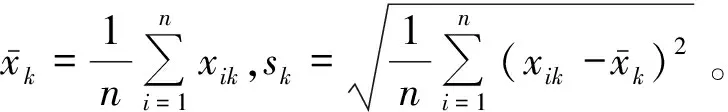
经上述变换后消除了量纲的影响,但是为使x′ik在区间[0,1]内,需要进一步变换。
(2)平移-极差变换
( 9 )
可知0≤x″ik≤1,实现了数据标准化。
Step3建立模糊相似矩阵(X″→R)。
引用聚类统计量rij=R(xi,xj)描述样本(或变量)之间相似度指标,采用距离法对相似系数rij进行计算,当c选取合适参数时0≤rij≤1,即
rij=1-cd(xi,xj)
(10)
式中:d(xi,xj)为海明距离,其计算方法为
(11)
Step4建立模糊等价矩阵(R→R*)。
为使矩阵R具有传递性,需要将R改造成模糊等价矩阵。设R∈Mn×n,即R属于一个n×n的矩阵M,当其存在一个最小自然数k(k≤n),使得传递闭包t(R)=Rk,对于一切大于k的自然数l满足Rl=Rk,则t(R)为模糊等价矩阵,其中Rk的计算方式如下
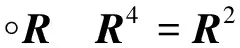
(12)
Step5聚类分析R→Rλ。
置信因子λ∈[0,1]从大到小变化时,称Rλ=[rij(λ)]为模糊矩阵R*对应的布尔矩阵,其中
(13)
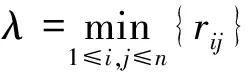
2 转辙机运行状态评估流程
转辙机运行状态评估对铁路线路安全运行至关重要。针对在不同运行状态下,S700K转辙机动作功率曲线之间的差异特性,提出基于模糊聚类分析算法对其进行运行状态评估。该算法的基本流程见图2。
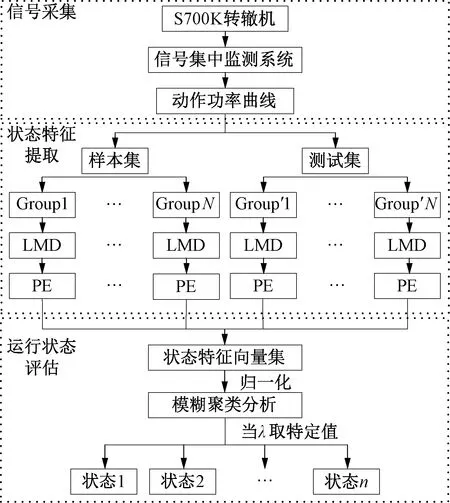
图2 转辙机运行状态评估流程图
(1) 信号采集
信号集中监测中心通过启动继电器(1DQJ)进行实时电流和电压监测,完成S700K转辙机转换过程的动作功率曲线采集。
(2) 状态特征提取
首先将动作功率曲线分为样本集和测试集,样本集包括Group 1、Group 2、…、GroupN,N个样本对象中共有n种不同状态(N≥n),测试集与之类似。每种状态有多条曲线,在极端情况下如果只有一条曲线样本,由后面的仿真可以看出,本算法也适用。对每一功率曲线进行LMD分解,计算不同PF分量的PE值,建立转辙机运行状态特征向量。
(3) 运行状态评估
以运行状态特征向量集构建模糊矩阵,并按照模糊聚类算法依次建立模糊相似矩阵→模糊等价矩阵→布尔矩阵→动态聚类图,置信因子λ取不同值时,聚类图对应分类数也不相同。当分类数等于样本集中n种不同状态时,λ对应特征值为测试集中不同运行状态的分类评估。
3 实验部分
3.1 转辙机功率曲线分析
S700K转辙机广泛应用于高速铁路,主轴采用三相异步电动机,其拉力F和输出功率P为
(14)
(15)
则S700K转辙机转换过程中P与F的关系为
(16)
式中:Re、n、η分别为转辙机传动系统的等效力臂、转速、电机转换效率,由此可知S700K转辙机机械性能与其动作功率曲线特性保持一致性,转辙机的运行状态就是其动作功率曲线的变化状态。
转辙机功率曲线特性大致可分为启动解锁、转换、锁闭三大阶段。健康状态动作功率曲线在解锁阶段出现峰值,转换阶段比较平稳,锁闭阶段有“小台阶”。在转辙机全周期运行状态评估中,当转辙机处于健康和故障之间的亚健康状态时,动作功率曲线发生微弱变化,如转换阶段振动和回路电流偏大等现象,因此如何表征转辙机功率曲线微小特性成为评估运行状态的关键。本文调研了中国铁路兰州局集团有限公司信号集中监测中心的S700K转辙机功率曲线数据,以40 ms为采样周期,总结典型运行状态下的功率曲线,见图3,对应运行状态分类及分析如表1所示。
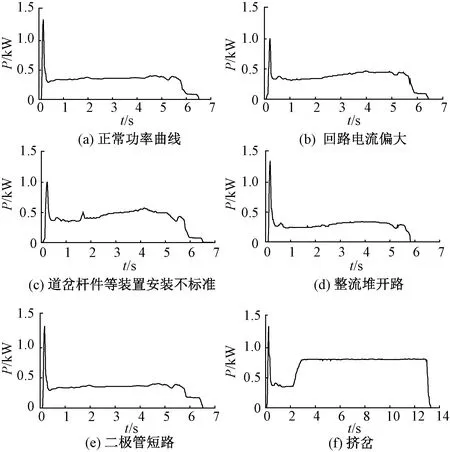
图3 S700K转辙机典型运行状态功率曲线

表1 S700K转辙机典型运行状态功率曲线分类及分析
3.2 功率曲线LMD分解及PE分析
S700K转辙机可分为4种不同的运行状态,即健康、亚健康、故障和严重故障。在不同的运行状态下其动作功率曲线呈现非线性、不平稳特性,而有些动作功率曲线之间相似度很高,如亚健康状态下,表示回路电流过大和转换阶段振动的曲线特征差异性低。为充分表征曲线特征信息,本文利用LMD分解对不同状态下的功率曲线进行频域分析,利用其解决模态混叠、端点效应以及微小特征频率分解的优势,提取功率曲线的细节分量,从而构造动作功率曲线的多维信号特征集,有利于后续进行的模糊聚类分析。以S700K转辙机健康状态动作功率曲线为例,对其进行LMD分解,见图4。
图4 转辙机健康运行状态LMD分解图
从图4可以看出:转辙机健康运行状态功率曲线被分解为4个不同频率特性的PF分量,其中PF4分量满足没有足够极值点的LMD分解终止条件。为提供信号序列有效特征信息,本文采用PE算法对每个PF进行量化分析,参考文献[16]取n≥5m!,以40 ms为采样周期时,m取值为4,τ一般小于2。不同运行状态下功率曲线经LMD分解得到PF分量,并对各分解分量进行PE值计算,由不同分量的PE值组成特征向量。图5为转辙机不同运行状态下LMD排列熵分布图,从图5中可以出,不同运行状态下排列熵曲线不重合,能够有效区分不同转辙机运行状态。转辙机不同状态下的样本特征向量如表2所示。
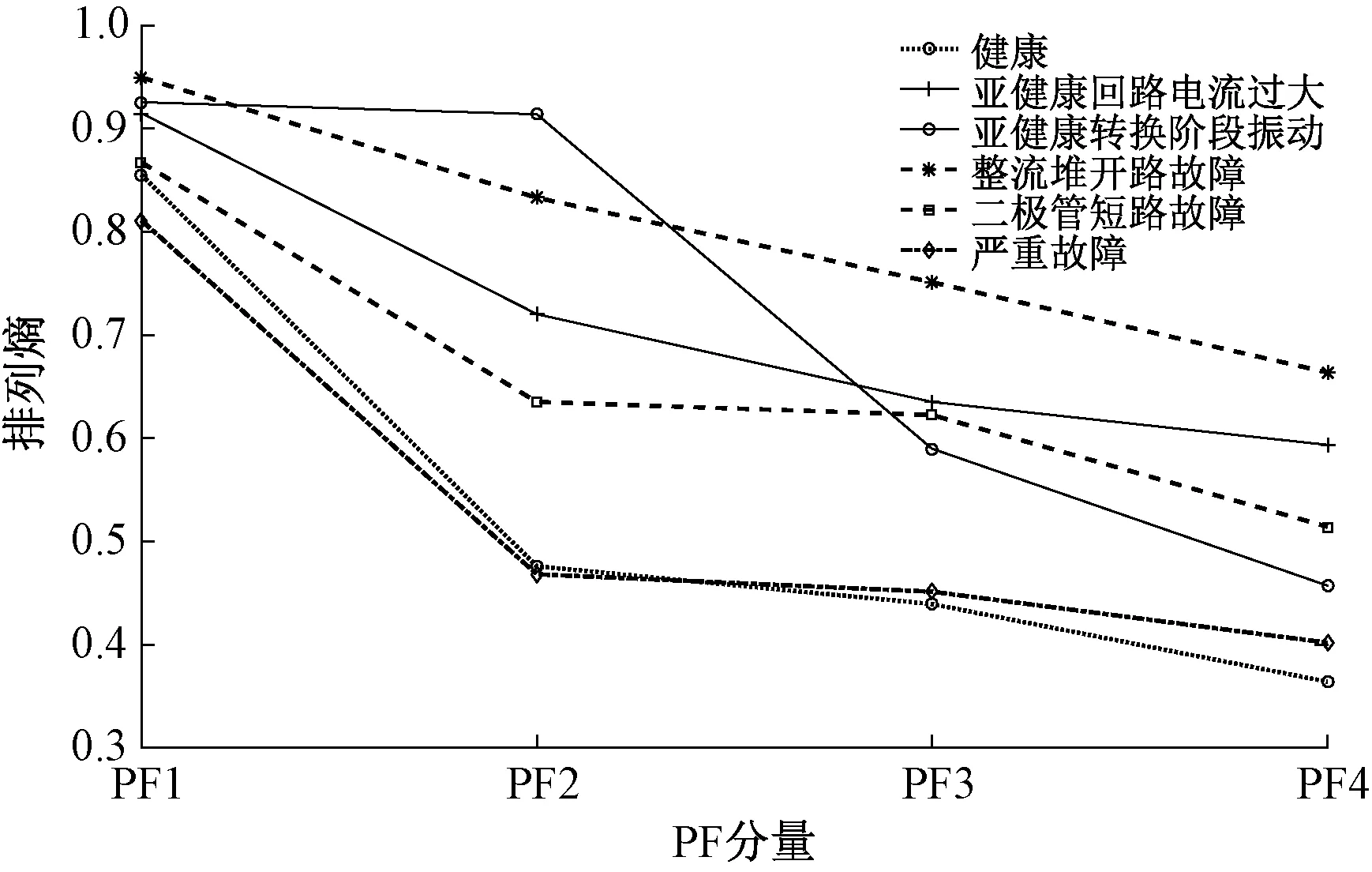
图5 转辙机不同运行状态下排列熵分布
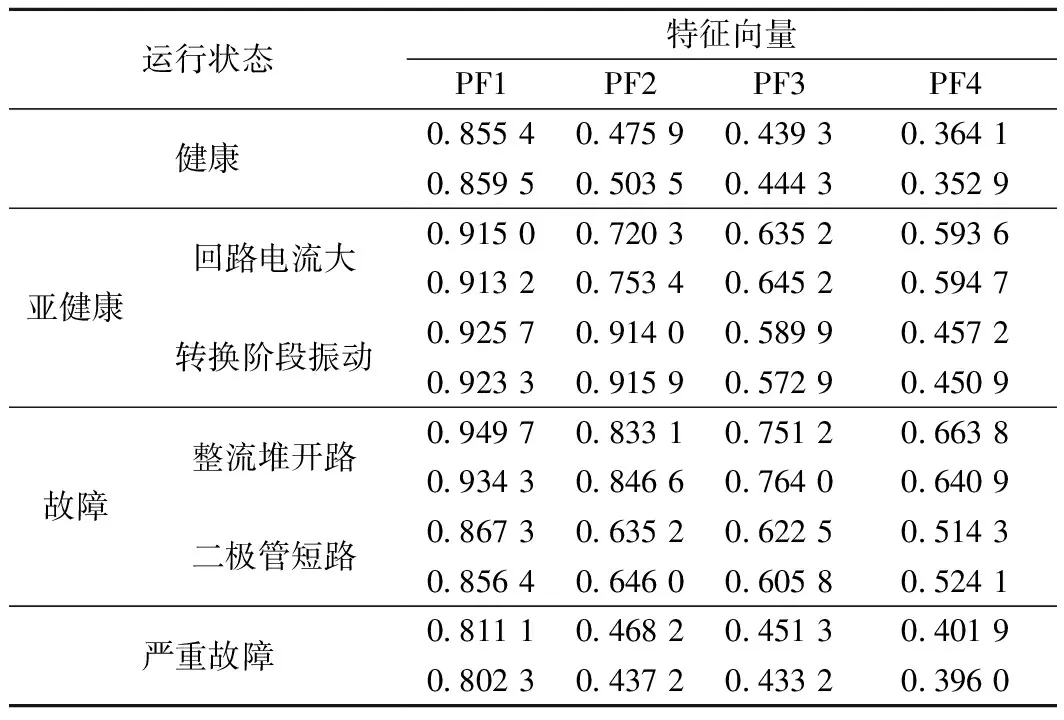
表2 转辙机不同状态下的样本特征向量
3.3 基于模糊聚类分析的转辙机运行状态评估
3.3.1 建立转辙机运行状态评估模型
通过对不同运行状态下S700K转辙机动作功率曲线LMD分解,建立了以不同频率特性PF分量排列熵为元素的特征向量。选取在6种运行状态下典型功率曲线各2组作为样本集,共组成12个运行状态对象。利用模糊聚类算法对其进行聚类分析,从而实现转辙机运行状态评估,具体实现步骤如下:
Step1构建初始模糊矩阵。
根据表2数据,定义在不同状态下样本特征向量依次为f0~f11,则初始模糊矩阵X可表示为:X=[f0f1f2f3f4f5f6f7f8f9f10f11]。模糊矩阵X中的元素以排列熵表征功率曲线特征,为消除不同量纲的影响,并都分布于0到1的区间内,如式(8)、式(9)对其进行标准化处理后的矩阵X″为
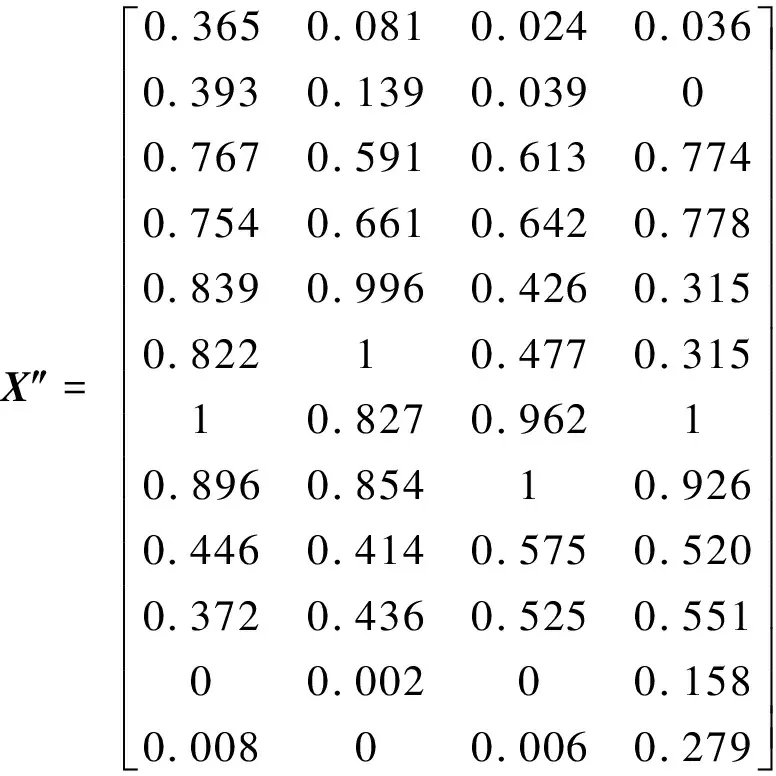
(18)
Step2建立模糊相似矩阵。
为定量描述样本之间的相似度指标,如式(10)、式(11)引用海明距离计算算法建立模糊相似矩阵R为
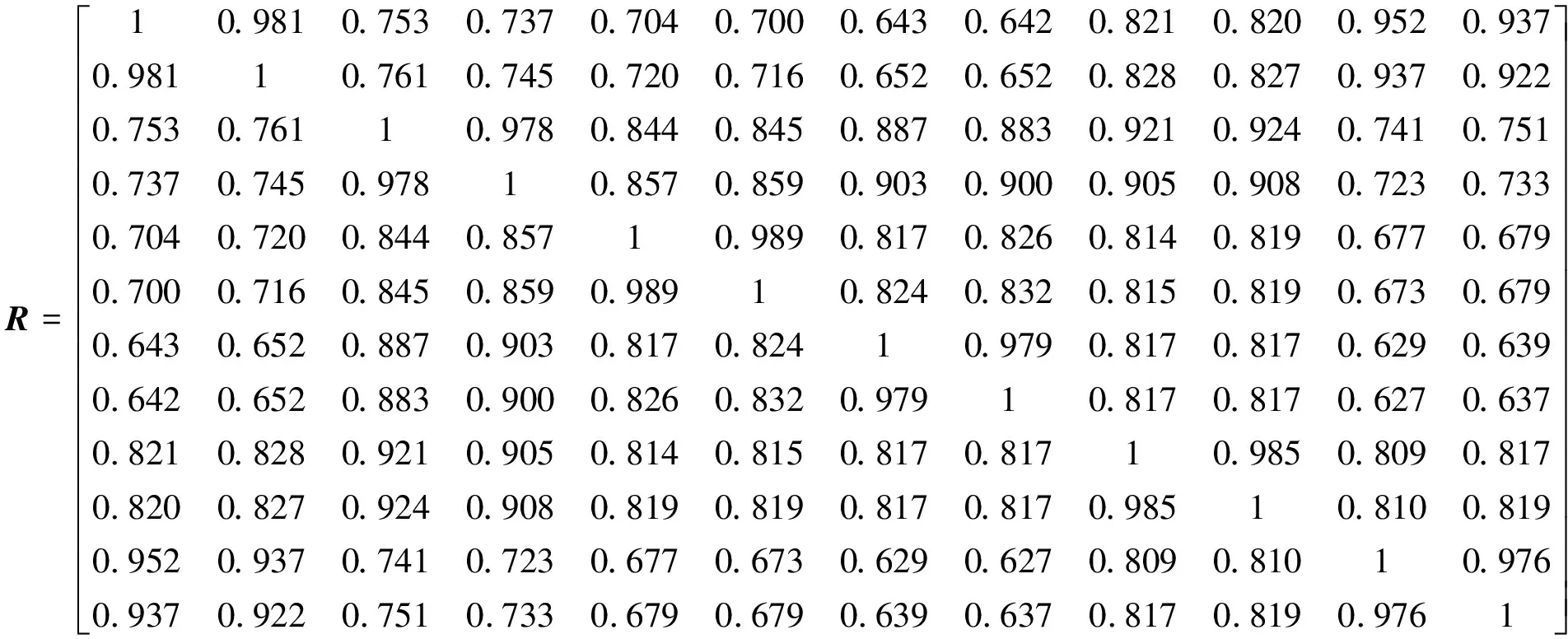
(19)
Step3建立模糊等价矩阵。
模糊相似矩阵R不一定具有传递性,为了实现运行状态评估,需要将R改造成模糊等价矩阵R*。根据式(12),利用传递闭包算法求得模糊等价矩阵R*=t(R),即样本集的模糊等价矩阵R*为
(20)
Step4模糊聚类分析
在模糊等价矩阵R*中,如式(13)利用置信因子λ建立等价布尔矩阵,当λ从大到小变化时,形成相应的动态聚类图。
3.3.2 实例评估结果及分析
本文以中国铁路兰州局集团有限公司信号集中监测中心的历史监测数据为基础,另外随机抽取关于健康状态和严重故障状态下功率曲线历史数据各1组作为测试集。测试集标签为d0~d1,经LMD分解后PE值如表3所示。结合上节转辙机运行状态评估模型,对重构初始模糊矩阵X=[f0f1f2f3f4f5f6f7f8f9f10f11d0d1]进行模糊聚类分析,对应动态聚类图见图6。
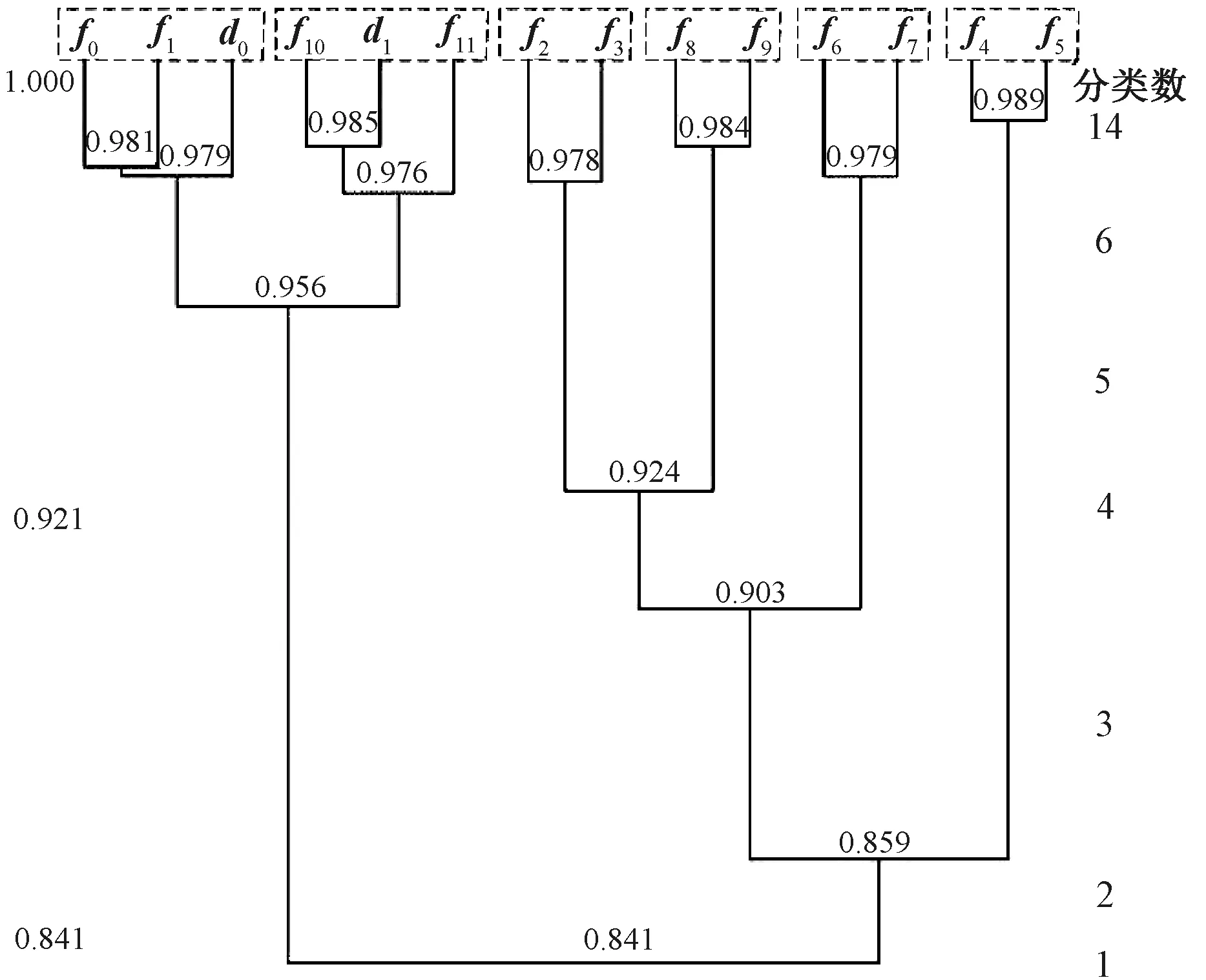
图6 转辙机运行状态评估动态聚类图
由图6可知,当λ等于0.956时,转辙机运行状态分类数为6,再根据样本集对应状态分类,则{f0f1d0}属于健康状态,{f10f11d1}属于严重故障状态,从而实现了测试集中的转辙机运行状态评估。
由于S700K转辙机故障发生率低,样本数据集采集相对困难,本算法可以实现单个或多个现场功率曲线的聚类分析,不需要大量数据提前训练。为进一步验证该算法的有效性,将兰州铁路局集团公司信号集中监测中心关于S700K转辙机正常、亚健康、故障和严重故障等不同运行状态下的功率曲线各5组作为测试集,共计30组分别逐个输入模糊聚类状态评估模型中。经与信号段工作日志进行对比分析,结果表明:运行状态评估结果能够准确表征测试集的状态类型,验证了该算法在小样本情况下,对S700K转辙机运行状态进行评估的有效性。
4 结论
为实现S700K转辙机运行状态评估,根据其动作功率曲线呈现非线性、不稳定的特性,本文提出了基于模糊聚类算法的转辙机运行状态评估算法,并有以下结论:
(1)LMD分解方式在处理非线性信号时,利用其有自适应的优势对转辙机功率曲线进行细节分量的提取。排列熵用于表征不同频率特性下乘积函数分量PF的复杂度,且对信号突变敏感。通过对特征参数的分析,能够充分提取在不同运行状态下的功率曲线特征。
(2)以不同分量排列熵构建初始模糊矩阵,利用模糊聚类分析,将不同运行状态下的功率曲线形成动态聚类图。当置信因子为特定值时,实现测试集与样本集的匹配,故而实现转辙机运行状态评估。实验结果表明:该算法结构简单,适用于小样本分析,不需要提前训练,即可实现S700K转辙机全周期运行状态评估,具有较强的实用性。。
猜你喜欢
中学生数理化·八年级物理人教版(2022年6期)2022-06-05
中学生数理化·八年级物理人教版(2022年6期)2022-06-05
中学生数理化·八年级物理人教版(2022年6期)2022-06-05
铁道通信信号(2020年4期)2020-09-21
铁道通信信号(2020年3期)2020-09-21
铁道通信信号(2020年1期)2020-09-21
铁道通信信号(2020年8期)2020-02-06
中学生数理化·八年级物理人教版(2019年6期)2019-06-25
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
