
基于自注意力机制的中文医疗命名实体识别*
2022-05-10 07:28颜柏杨
计算机与数字工程 2022年4期
颜柏杨 吴 陈
(江苏科技大学计算机学院 镇江 212003)
1 引言
在智慧诊疗领域,构建医学知识图谱对辅助决策和问答系统至关重要,需要借助命名实体识别处理非结构化的临床文本,然后将提取出的实体映射到知识图谱相同的结点。文本挖掘通常需要用到自然语言处理,命名实体识别(Named Entity Recognition,NER)是其重要的组成部分,作用是从半结构或非结构化文本中识别出疾病名称、症状和药品等医学实体。医学知识图谱构建通过医疗实体和实体间的关系连接而成,因此NER的精度关系到临床医疗知识图谱的严谨性。
国外通用实体识别技术发展比较完善,Bikel提出了基于齐次马尔科夫假设和观测独立假设的隐马尔科夫模型[1],该方法使用MUC-6数据集达到了90%的准确率。Liao提出了条件随机场模型[2],跳出了HMM算法观测独立假设,提升了NER的准确度。Feng[3]提出了基于BiLSTM神经网络结构的实体识别方法,该方法使用上下文的单词嵌入和字符的单词嵌入。相比需要手动添加特征模统计学习的算法,Huang提出了Bi LSTM-CRF模型[4],采用BiLSTM抽出文本特征,条件随机场算法处理字与字间的序列概率,该模型在NER和词性标注任务上达到state of the art。当文本过长时,LSTM提取的特征并不完整,Luo提出了基于注意力[5]的双向长期短期记忆只需很少的特征工程即可实现更好的性能。
中文命名实体识别相对国外发展较晚,Wang、Liu[6]实现了基于中文字符的实体识别,Yang等[7]在提出的Lattice-LSTM模型是目前MSRA数据集上的最优模型,相较与字符层次的方式,该模型很少出现边界标注错误的问题,其效果优于基于字符和基于单词的LSTM基线模型。
通用命名实体识别的发展推动了医疗行业NER的前进。Zhao针对生物医学文本使用隐马尔科夫模型[8](HMM),并基于单词相似度进行平滑处理。实验表明,基于单词相似度的平滑可以通过使用很多没有打标记的序列来提高性能。Sahu提出了端到端递归神经网络模型用于疾病名称识别[9]。同时在RNN结合卷积神经网络获得基于字符的嵌入特征。
虽然国外医疗实体识别取得较大的发展,但是中文医疗实体与英文构词法不同。本文实现基于自注意力机制[10]的命名实体识别,利用Transformer-CNN-BiLSTM-CRF进行序列标注,提升了模型对医疗实体的识别率,平均F值达94%。
2 Transformer-CNN-BiLSTMCRF
Transformer-CNN-BiLSTM-CRF模型整体结构如图1所示,模型主要由四部分构成,分别是多层Transformer特征提取层,CNN层,BiLSTM层以及CRF层。

图1 Transformer-CNN-BiLSTM-CRF网络结构
基于Transformer网络可以通过拼接组成多层、泛化性能更好的复杂模型,抽取更多字级、词级、句子级甚至句间关系特征。之后把多维度序列的特征传入CNN-Bi LSTM,接下来的部分为CRF层,用于计算每个输入向量的实体类别标签,如身体部位(body)、症状(symp)等实体类别,使用“B-”代表实体开头,“I-”代表实体除头以外字符。
2.1 Transformer层
Transformer的核心时编码器,其内部结构如图2。

图2 Transformer编码器
Transformer对输入进行位置编码,免去了序列前后顺序的约束:
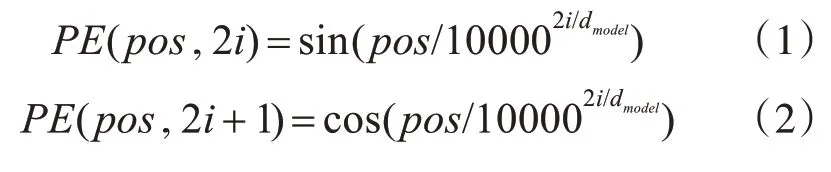
使用正弦、余弦函数对给定位置的词语做编码,表示词汇之间的位置偏移。
Transformer中最重要的是自注意力机制,在自注意力机制中,每个词对应3个不同的向量,它们分别是Q矩阵,K矩阵和V矩阵表示,序列输入后每个字符的打分score由Q和K矩阵相乘得到。

而multi-head attention是将Q向量,K向量和V向量经过线性映射成多份,对每一组矩阵做Attention,输出h×dv,然后对各组通过注意力运算后的矩阵进行拼接,这样可以获得不同位置不同语义空间的特征。本文head参数设为8,隐藏层维度d设为512,这里设置更多的head可以提取到单个字符、专有名词的词性特征。
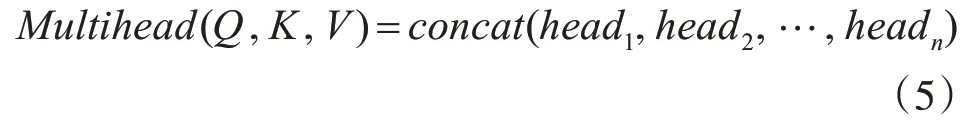
由于多层encoder模型在训练集上表现变差,在transformer中添加残差连接,通过添加shortcut connections减轻因为模型复杂而带来的性能退化问题。
随着训练进行,参数经过每一层线性与非线性激活函数后,梯度随着网络的加深而增大,Transformer使用Batch normalization对每一层做批归一化,消除了梯度弥散情况,加快模型收敛速度。

2.2 CNN-BiLSTM层
文本序列通过transformer后,输出高维度的特征矩阵。在序列标注任务之前加入卷积层[11],利用其卷积(conv)和池化(pool)的特性,压缩矩阵的维度。循环神经网络模型[12]能按时序获取卷积后的信息,在算法实现上容易产生梯度消失或爆炸问题。Hochretr[13]提出的包含记忆unit和门机制的LSTM模型,可在更长的时间维度提取特征,消除了梯度弥散的情况。Gravs[14]优化了记忆unit和门机制,本文采用Graves等提出的改进门限机制:
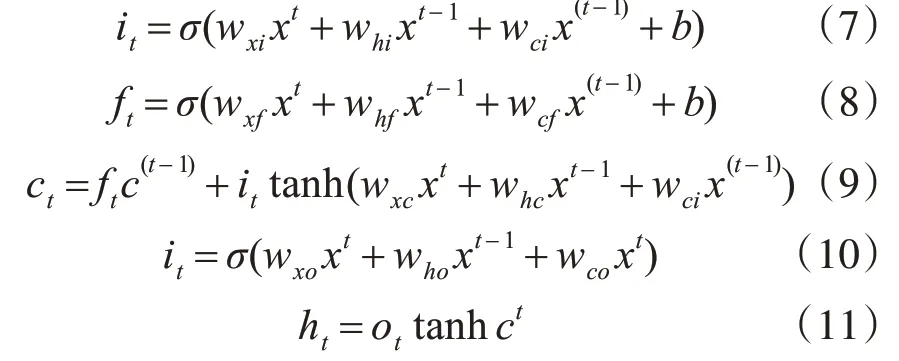
式(7~9)表示表示输入门、遗忘门和输出门,均使用前一时刻的隐藏单元与当前时刻信号作为门控单元的输入。
2.3 CRF层
条件随机场(Conditional Random Fields,CRF),是对于一组随机输入变量(x1,xi…,xn)条件下另外一组随机输出变量(y1,yi…,yn)的条件概率分布模型,如果输出序列满足Markov[15]独立假设:
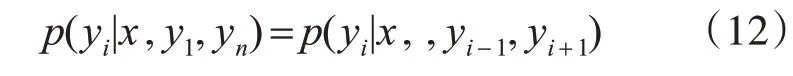
在CRF解码时,通过转移概率矩阵A对序列进行打分即:
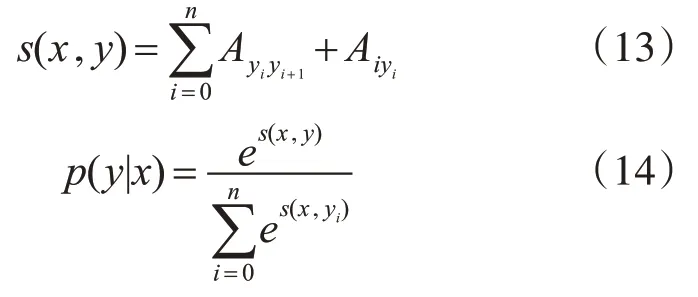
在训练过程中,使用对数似然函数是来最大化关于正确标签序列的概率,如式(14),维特比算法[16]常用于序列解码,计算现阶段的标签值到第i+1标签值的最短路径,即输出序列几率最大的组合:
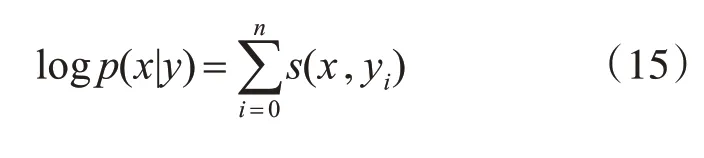
3 实验及结果分析
3.1 实验数据和评价指标
因为医疗数据涉及患者隐私,所以本实验采用2018年CCKS评测任务二共600份的电子病历作为实验数据,CCKS的病历文本已采取脱敏处理,同时标定症状、疾病、药品、检查检验多个类别实体。本文使用三元集{B,I,O},“B”实体的第一个字符,“I”是其余部分,“O”不属于任何类型词。所有实体标签如表1。

表1 实体标签
取该CCKS2018中500份病历当作训练集,100份当作测试集,分为两组做统计,各个类型实体分布如表2所示。
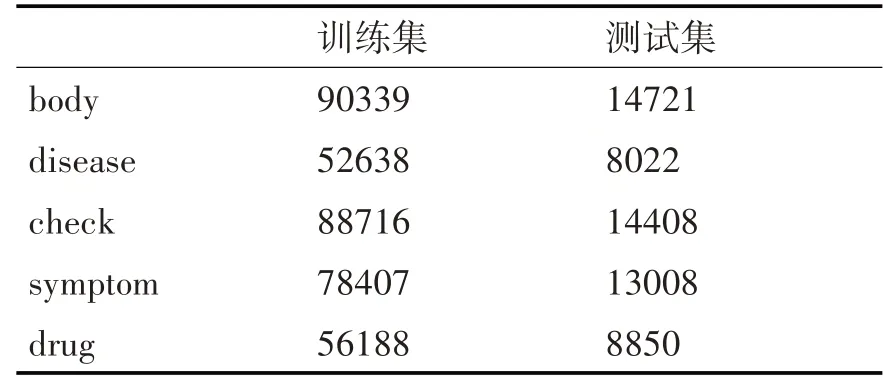
表2 CCKS文本数据统计
医疗领域实体识别任务通过召回率R、精确率P和F值来综合评判,并定义T正确标识的实体,定义F标识无关的实体、Fn为模型没有检测到的相关实体个数。
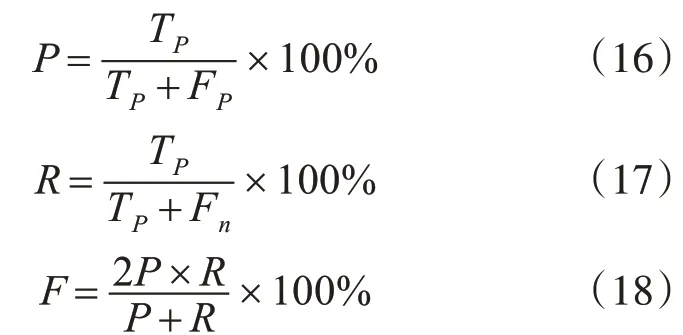
3.2 实验结果
本文的实验环境是GTX1080Ti的Gpu,python3.6和tensoflow1.14。
实验一共有四组,模型分别为CRF、BiLSTM-CRF、Word2Vec-BiLSTM-CRF和Transformer-CNN-BiLSTM-CRF。其中基于统计的方法CRF作为基准模型,使用开源工具CRF++,手动添加Unigram模板。
本文设计的Transformer-CNN-BiLSTM-CRF模型采用的多头注意力机制提取序列特征。在Transformer中设置了6层ecnoders,每个encoder层设置multi-head数目为8。
在测试集上,四个实验F1曲线如图3所示。
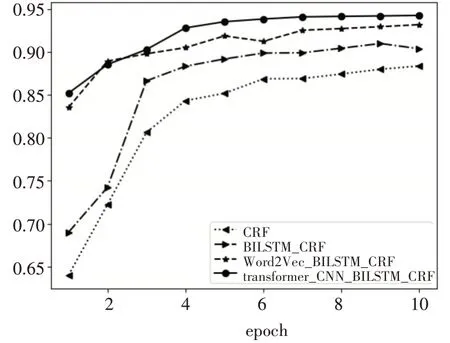
图3 F-score曲线
根据表3,Transformer-CNN-BiLSTM-CRF准确率比传统统计学习的方法提高了6%,F值高了7%。比Word2Vec-BiLSTM-CRF准确率高了0.6%,F值高了2%。

表3 实验结果
考虑到医学领域数据较难获取,从训练集随机抽取200份病历,测试集中抽取40份,对比四个模型在小样本数据上的结果。如表4所示,基于自注意力机制的方法比F值达到了91.77%。但是基于统计的CRF模型在小样本数据集的准确率F值只有84.71%,出现这样的结果是因为CRF时基于训练序列的概率分布模型,当训练数据很少时模型所能学习到的信息就会减少,而Transformer依然能充分提取少量数据里的特征,准确率相对较好。
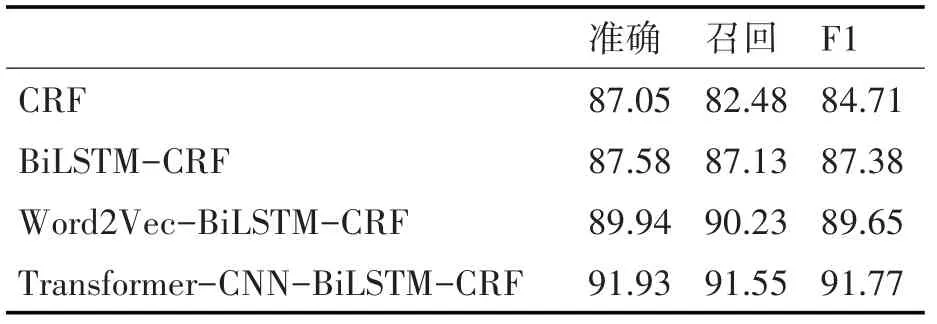
表4 小样本实验
虽然Transformer-CNN-BiLSTM-CRF总体准确率提升很多,但是其对不同类型实体识别的结果却不同,如表5所示。

表5 各类型实体识别结果
其中药品drug识别准确率偏低,主要原因是药品名称中包含身体器官或组织的名称,同时存在修饰词导致名称过长、歧义等信息的干扰。在这些drug实体没有充足上下文时容易预测错误。
以上实验结果表明,虽然基于统计的CRF方法在测试集上的准确度有一定提升,但是需要手动添加特征模板,这都需要花费很多时间。而自注意力模型不但省去了这一环节,而且在把握语义方面比word2vec训练的静态语言模型更加精准,这与Transformer中的自注意力机制选择信息特征的能力有着密不可分的关系,使得命名实体识别任务提升比较大。
4 结语
近年来,中文医疗命名实体识别任务借助深度学习方法取得了快速的发展,本文使用基于自注意力机制的Transformer-CNN-BiLSTM-CRF模型。该模型将使用文本数据进行位置编码作为输入,对比使用循环神经网络,Transformer不依赖上下文支持并行计算的特点,加快了模型训练的速度,同时模型可以充分学习文本的特征信息,增强了字符间的推理能力。虽然Transformer-CNN-BiLSTMCRF比传统的命名实体识别模型效果有所提升,但是对于嵌套、修饰词过长的部分医疗实体较难准确抽取,未来还有很多问题有待研究。
猜你喜欢
电脑报(2021年41期)2021-11-04
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
电脑知识与技术(2019年29期)2019-12-16
电脑爱好者(2019年8期)2019-10-30
读与写·教育教学版(2017年10期)2017-11-10
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
