
一种用于问答系统的加权目标图方法*
2022-05-10 07:28唐卫玲胡广朋
计算机与数字工程 2022年4期
唐卫玲 胡广朋
(江苏科技大学计算机学院 镇江 212003)
1 引言
问答系统的概念最早是在二十世纪六十年代被提出,目的是希望计算机可以像人脑一样理解人们用自然语言进行的提问然后给出答案。目前,一个成熟的问答系统的工作流程可分为问句处理、智能检索以及答案生成三步[3]。首先要将用户提问的问句解析成与知识库中存储的信息形式一样的结构化表达及关键字,然后根据解析出的结构化表达和关键字从知识库中匹配出相关的问题模板以及答案,再把上述结果交由答案处理模块进一步分析处理,最终将处理整合后的答案返回给用户。简而言之,问答系统就是根据用户的提问去知识库中匹配相应的问题和答案。
为了提高问题匹配的准确率和效率,本文提出了一种基于规划识别的问题匹配方法。采用加权目标图的规划识别方法[1],将用户提问问句的关键词、知识库中的问题以及问题的构成词作为目标图的节点,词语在句子中的权重和词语之间的相似度作为支持程度。
2 加权目标图
2.1 加权目标图定义
加权目标图是一种加权分层有向与或图,由节点和加权边组成[7]。节点代表动作,加权边是节点之间的连接,代表动作之间的支持关系,其权值表示节点之间的支持程度[4]。节点之间存在整体与部分、抽象与具体两种关系,在加权目标图中分别用带圆弧的虚线和实线将其连接起来[4],效果如图1所示。
由图1可知,在设定的加权目标图中,将用户提问的问句中提取出来的关键词作为已观察到的动作序列,将知识库中的问题作为要识别的目标,同时在问题和构成词、构成词和关键词的推导计算中分别引入了词语相似度和权重来表示它们之间的支持程度。

图1 加权目标图
2.2 支持程度
由上述目标图的设定可知,这里仅要考虑具体对抽象的支持程度以及部分对整体的支持程度,定义如下。
1)部分对整体的支持程度
若规划a1,a2,…,ai,…an是规划a的组成部分[8],则每个部分ai(1≤i≤n)对整体a的支持程度为p(a|ai),在本文中将其设置为该构成词在其问题句中所占的权重。
目前,比较常见的词语权重计算方法为TF-IDF,该方法就是根据特征词在当前文档中出现的次数以及在整个文档库中出现的次数来判断其重要程度[5]。这种算法的缺点在于单一的依赖词频进行权重计算,因此本文将词语的词性、长度、位置信息加入到权重计算中,同时也将同义词问题考虑了进来,改进后的权重计算如式(1)所示:
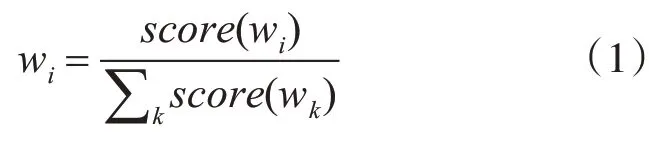
其中,∑k score(wk)表示该篇文档中所有特征词的词语得分之和,score(wi)表示该词语的得分,计算公式为
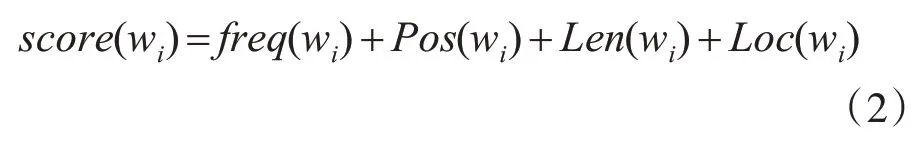
其中,fre q(wi)表示词频-逆文档频率,计算公式为
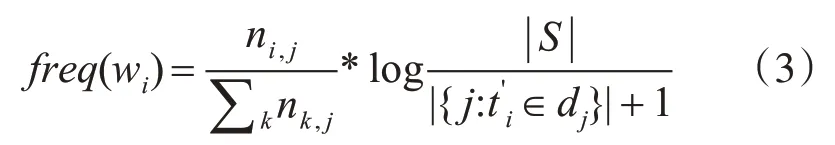
其中,ni,j表示该词语在文档dj中出现的次数,∑k nk,j表示文档dj中所包含的词语总数;|S|表示整个文档库中文档的总数目表示文档?库中包含词语ti或其同义词的文档的数目。这里在传统IDF算法基础上进行了改进,在计算逆文档频率时,将包含给定特征词的同义词的文档也统计在内。这是因为考虑到不同用户对同一问题的表述可能是多种多样的,而知识库中存储的问题-答案对是唯一的;此外,知识库中存储的是简短的问题-答案对,而一个简短的句子,一般不会出现两个语义完全一致的词语,因此如果不把包含特征词的同义词的文档也统计在内,就会导致结果出现较大偏差。
Pos(wi)表示词语的词性权重,规定若该词为人名、地名、机构名这类名词则权重为1,其他名词权重为0.5,动词权重为0.4,形容词权重为0.3,除此之外的词性权重均为0。Len(wi)表示词语的长度权重,若词长大于3,则将其权重定义为中l eni为该词长度,Lmax为该句中最长的词语的长度。Loc(wi)表示词语的位置权重,规定位于句首的词语权重为0.6,其他位置为0.4。
2)具体对抽象的支持程度
若规划a1,a2,…,ai,…an都是抽象规划a的具体化[8],则每个具体规划ai(1≤i≤n)对抽象a的支持程度为p(ai),抽象a最终的概率为max{p(ai)}。在本文中将具体对抽象的支持程度设置为问句中的关键词与问题构成词之间的相似度,这里采用Simhash来计算相似度。
2.3 目标图求解算法
本文采用基于加权目标图的规划识别算法来实现问答系统的问题匹配环节,其基本思想是将加权目标图、观察到的智能体的动作集合o={o1,o2,…,on},在本文中即为问句中提取出的关键词序列以及一个给定的阈值φ作为算法的输入,经过一系列的处理、计算最终返回给用户一个带有各种结果可能出现概率的、完整的加权目标图,具体过程描述如下。
初始化目标图:利用全部已观察到的动作集合o={o1,o2,…,on}构造初始目标图,oi(i=1,2,…,n)为从用户提问的问句中提取出来的关键词序列。
生成完整的加权目标图,求出最佳匹配问题:这里采用自底向上的扩充目标图的解法,首先根据目标图,找到其中每个节点的父节点,若子节点xi(i=1,2,…,n)出现则其父节点a出现的概率p(a)计算公式如下。
1)若子节点xi(i=1,2,…,n)与其父节点a之间是具体与抽象的关系,则父节点出现概率p(a)为
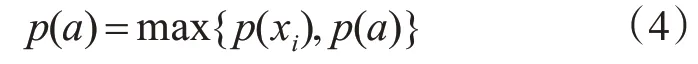
2)若子节点xi(i=1,2,…,n)与其父节点a之间是部分与具体的关系,p(a)则为

然后将1)或2)中求得的概率p(a)和初始设定的阈值φ进行比较,若p(a)>φ,则将a保留在目标图中,否则删掉节点a以及其后继所有的节点。这样就能得到完整的加权目标图,从而通过已观察到的动作得到所有可能结果以及各个结果的可能性大小,选择概率最大的识别结果作为最终结果。
下面以简化的问答知识库为例,验证基于加权目标图的问题匹配方法的有效性。现假设知识库中仅有“土豆发芽了还能吃吗?”和“土豆皮是干垃圾还是湿垃圾?”两个问题句。经过处理之后,“土豆发芽了还能吃吗?”主要包含3个构成词:土豆、发芽、吃;“土豆皮是干垃圾还是湿垃圾?”主要包含3个构成词:土豆皮、干垃圾、湿垃圾。当用户提问“马铃薯的皮属于什么垃圾?”,根据上述加权目标图的定义,构造问答规划知识图,如图2所示。
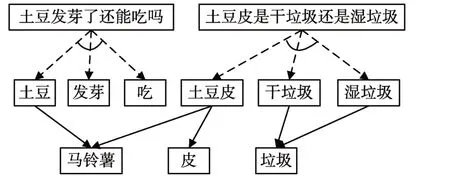
图2 问答规划知识图
已观察到的动作为“马铃薯”、“皮”和“垃圾”,运用上述加权目标图算法进行求解,生成的目标图如图3所示。
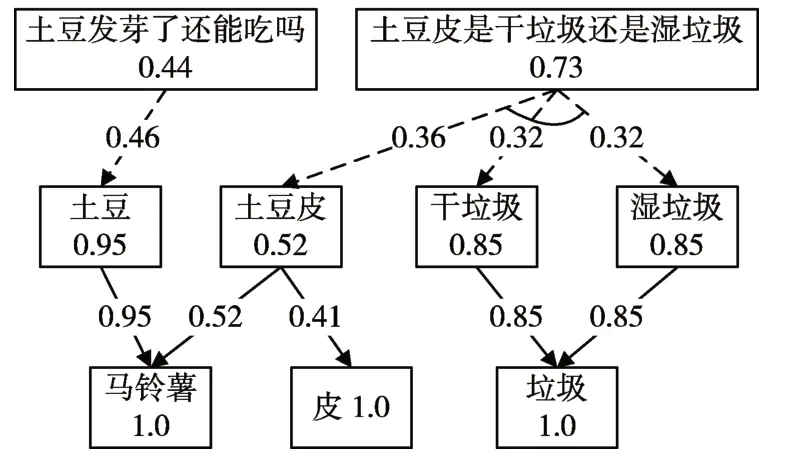
图3 完整加权目标图
由图3可知,用户提问的问句是“土豆发芽了还能吃吗?”的概率为0.44,而提问“土豆皮是干垃圾还是湿垃圾?”的概率为0.73,因此系统最终判定用户输入的问句为“土豆皮是干垃圾还是湿垃圾?”,显然这个判定是正确的。
3 实验
3.1 实验平台及数据说明
问答系统的运行环境为Windows10操作系统、Tomcat-7.0.70服务器、MySQL数据库、JDK1.8、Eclipse Mars2。
本实验使用维基百科的百科问答数据集。其中所有数据都是维基百科上,截止到2018年的百科问答数据,总共有150万个经过事先筛选的、拥有较高参考价值的问题和答案。所有的问题都有自己所属的类别,数据集中问题的类别总数为492,其中相关问题个数超过10个的类别有434类。此外,本文以“沃森”机器人的Java开源版本Question Answering System(QASystem)为基础,构建了基于规划识别的QASystem(Plan Recognition Question Answering System,PR-QASystem),然后将两者进行对比。
3.2 实验结果评估标准
本文中的实验结果使用P-R曲线作为评估指标。其中,P代表precision(精准率),R代表recall(召回率)。P-R曲线就是以这两个属性为变量绘制出的曲线,其中精准率为纵坐标,召回率为横坐标。精准率的原理见式(6):

3.3 实验结果分析
本文选取P-R曲线作为实验结果评估标准,经过多次调整阈值,得到了本文基于加权目标图的PR-QASystem与QASystem的P-R曲线如图4所示。

图4 系统P-R曲线图
一般认为,如果一个算法的P-R曲线完全包裹住了另外一个算法的P-R曲线,则说明前者的性能要优于后者,否则按照其与坐标轴围成的几何图形的面积大小进行判断,面积大的则性能更好,显然本文基于加权目标图的问题匹配方法在一定程度上提高了系统的性能。
4 结语
本文以用户提问问句的关键词、知识库中的问题以及问题的构成词为节点,以词语在句子中的权重和词语之间的相似度为支持程度,构建了加权目标图,实现问答系统的问题匹配环节。通过实验证明,这种融合了改进后的权重和相似度的加权目标图方法在问答系统中具有一定的可行性与有效性,能够帮助系统更加准确地匹配出正确答案。但是本文是在分词结果是完全正确的基础之上进行的,且仅仅是利用关键词进行问题匹配而未考虑上下文语境、语义,因此本系统还有很大的改进空间。
猜你喜欢
客联(2022年3期)2022-05-31
心理学报(2022年5期)2022-05-16
中国新闻周刊(2021年26期)2021-07-27
电脑爱好者(2021年9期)2021-05-12
当代陕西(2020年17期)2020-10-28
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
电脑爱好者(2017年7期)2017-05-06
——基于与QuestionPoint的对比
新世纪图书馆(2014年11期)2014-02-23
科学导报·学术论坛(2013年5期)2013-06-26
