
Sea fog detection based on unsupervised domain adaptation
2022-04-28 03:39:10MengqiuXUMingWUJunGUOChungZHANGYuoWANGZhnyuMA
Chinese Journal of Aeronautics 2022年4期
Mengqiu XU, Ming WU,*, Jun GUO, Chung ZHANG, Yuo WANG,Zhnyu MA
a School of Artificial Intelligence, Beijing University of Posts and Telecommunications, Beijing 100876, China
b International School, Beijing University of Posts and Telecommunications, Beijing 100876, China
KEYWORDS Deep learning;Sea fog detection;Seeded region growing;Transfer learning;Unsupervised domain adaptation
Abstract Sea fog detection with remote sensing images is a challenging task.Driven by the different image characteristics between fog and other types of clouds, such as textures and colors, it can be achieved by using image processing methods.Currently,most of the available methods are datadriven and relying on manual annotations.However,because few meteorological observations and buoys over the sea can be realized, obtaining visibility information to help the annotations is difficult. Considering the feasibility of obtaining abundant visible information over the land and the similarity between land fog and sea fog, we propose an unsupervised domain adaptation method to bridge the abundant labeled land fog data and the unlabeled sea fog data to realize the sea fog detection. We used a seeded region growing module to obtain pixel-level masks from roughlabels generated by the unsupervised domain adaptation model. Experimental results demonstrate that our proposed method achieves an accuracy of sea fog recognition up to 99.17%, which is nearly 3% higher than those vanilla methods.
1. Introduction
Deep learning-based methodscan perform very well in the image recognition task on the top of large-scale data with enough accurate labels. However, sufficient enough labeled data or accurate labels are unfeasible in some application fields, while similar data with precise labels related to these tasks are feasible, such as sea fog detection task. As there are few meteorological observation stations and offshore buoys over the sea to obtain visibility information for supporting sea fog detection,it is hard to obtain sufficient enough labeled data,and thus the traditional image recognition methods cannot work well on those tasks. Meanwhile, in the land fog detection task, there are sufficient labeled data and we can train a‘‘good”model by those data to detect the fog.This inspired us to think: can the knowledge on land fog detection be transferred into the task of sea fog detection?
Sea fog is a type of advection fog,which is formed when air lying over a warm water surface transports over a colder water surface, resulting in cooling of the layer of air below its dewpoint.Due to its poor visibility, sea fog has a great impact on marine fisheries,shipping,platform operations,coastal aviation and highway traffic,military activities and so on.Therefore, the detection and forecast of sea fog are significant for marine activities.
The basic task of the sea fog detection is judging whether an image contains sea fog areas. Nowadays most approaches to sea fog detection rely on remote sensing data from meteorological satellites. Anthis and Cracknellutilized both AVHRR and METEOSAT data to detect fog areas and predict fog dissipation. Jiang and Weiused multi-channel threshold method for daytime fog monitoring task with the VIRR data of FY-3A satellite, and the characteristic parameters of fog, such as the optical thickness, the vertical thickness and the visibility, have also been estimated. Critically, manual annotations used for the above methods are likely not accurate due to the lack of human cognitive knowledge (e.g. it is hard to distinguish between low cloud groups and fog because they have similar texture features),and thus there is controversy on the performance of these methods. An approachused data obtained from Cloud-Aerosol Lidar and Infrared Pathfinder Satellite Observation(CALIPSO) satellite which can provide ground-truth of sea fog following the orbit of the satellite with its unique capability of vertical-resolved measurements. However, the detection areas of CALIPSO satellite are small and limited by its orbit and the approach does not meet real-time requirements.
When new datasets or task-specific datasets are lack of labels, fine-tuningis usually an effective solution. However, if there exists a large domain gap between the source and the target domains, fine-tuning may not be performed well on fitting new datasets and tasks. To minimize the domain gap between the source and the target domains,domain adaptation methodsbased on deep learning have been proposed, which learn more transferable representations and high-level semantics features compared with the conventional ones, which learn shallow representations of instances.For example, Tzeng et al.proposed a framework which combines discriminative modeling, untied weight sharing,and a Generative Adversarial Networks (GAN) loss.Although these algorithms have made great progress on their research fields, there are still a lot of spaces and challenges in applying to actual scenes.
In this work, we first analyze the difference between land data and sea data, which verifies the feasibility of transferring knowledge of land fog detection to sea fog detection.Since the domain gap between sea data and land data exits and it is a lack of labels on sea data, we choose an unsupervised domain adaptation method based on adversarial discriminative loss.This method utilizes remote sensing images data from Himawari-8 satellite and visibility information of surface meteorological observation on land.Meanwhile,in order to obtain accurate pixel-level annotations, we design a processing module with seeded region growing algorithm to generate pixellevel sea fog detection results. We demonstrate that our method is superior to other unsupervised domain adaptation approaches and has an advantage of providing pixel-level detection results.
Our contributions are mainly as follows:
(1) To the best of our knowledge, our work here is the first to use domain adaptation framework for sea fog detection.In order to solve the limitation that accurate labels cannot be obtained in sea fog detection, we propose a method to transfer the knowledge learned from land data to sea fog detection task based on the inherent similarity between images of two different domains.
(2) To deal with the differences between land data and sea data, we propose an unsupervised domain adaptation method to minimize the domain gap between the source of land and the target of sea. The approach achieves an accuracy of 99.17%on sea fog detection,which is higher than other unsupervised methods.
(3) To obtain actually applicable labels, we design a seeded region growing processing module to generate pixel-level annotations of sea fog areas.The initial seeds are chosen by the Category Classifier trained by unsupervised domain adaptation method.
2. Related work
2.1. Domain adaptation
One idea of domain adaptation based on deep learning to solve unavailable annotations issuesis mapping data from different domain distributions to the same feature space in favor of minimizing the distances between different domains, which relies on the researches on how to represent the distance between different domains as domain discrepancy.
Some methods make contributions to the representation of distances between source domain and target domain.Sejdinovic et al.proposed that Maximum Mean Discrepancies (MMD)can represent distances between embeddings of distributions to Reproducing Kernel Hilbert Spaces (RKHS). Similarly,Gretton et al.proposed Multi-Kernel Maximum Mean Discrepancies (MK-MMD) through constructing multi-kernel functions.Furthermore,some methods utilize domain distance representations and deep learning methods.For example,Tzeng et al.added MMD function to a pre-trained 8-layer AlexNetto minimize the distance of the source and the target domains.
Aim to seek out common features from different domains used for recognition, Long et al.mitigated the harmful effects of domain shift by adding three adaptation layers based on MK-MMD function. Other methodsuse adversarial discriminative loss to change domain distributions in the spirit of Generative Adversarial Networks (GAN). For example,Ganin and Lempitskyproposed an approach by adding a domain classifier connected to the feature extractor to promote that features are invariant with respect to the shift between the domains. Tzeng et al.combined discriminative modeling,untied weight sharing, and an adversarial discriminative loss to be trained on unlabeled data from the target domain.Besides, some methodsalso applied discriminative models to Open Set Domain Adaptation(OSDA) if source and target domain data shared some same categories.
Although domain adaptation methods have made great progress on research field, the ability that domain adaptation methods are applied to actual senses still needs improvement.
2.2. Sea fog detection
Sea fog detection task is defined as whether an image contains sea fog areas. Different from traditional methods using the threshold selection approaches based on the variation of brightness temperature and reflectivity of sea fog,current sea fog detection methods combined with deep learning benefit from extracting features from large amounts of data. For example, Convolutional Neural Network (CNN) was used in fog images classification based on Himawari-8 Standard Data(HSD8) collected from Anhui Province, China.Qu et al.used Deep Convolutional Neural Network(DCNN)for cloud detection task based on data of FY-3D/MERSI and EOS/MODIS. Furthermore, it is necessary to focus on the location of sea fog, so a more meaningful task is supposed to combine segmentation task with sea fog detection task.Zhu et al.utilized the PCA method of data preprocessing and the U-Net deep learning model for sea fog detection based on MODIS multi-spectral images. Liu et al.proposed a daytime sea fog retrieval model combined with Fully Convolutional Network (FCN) and fully connected Condition Random Field(CRF). Unfortunately, the methods above need massive labeled data, while it is hard to obtain precise annotations of sea fog due to few observations and buoys over the sea.
Due to the lack of labels on sea fog data, it is difficult to judge whether detected fog areas are accurate,and some methodsprovide specific evaluation of sea fog detection by using observed value of observations and buoys. Besides, a few methods focused on sea fog detection by using transfer learning to solve the above problem.Jeon et al.applied a Convolutional Neural Network Transfer Learning(CNN-TL)model of identifying sea fog with varying band combinations. However, there are few methods and researches using knowledge transfer methods from similar distribution data source or task to deal with sea fag detection task.
2.3. Seeded region growing
Seeded Region Growing (SRG) was proposed by Adams and Bischof,where the images can be segmented in an unsupervised way by controlling a number of seeds provided. Since the early algorithmis dependent on the order of pixel processing,Mehnert and Jackwaypresented an improved seeded region growing algorithm in which pixel order is independent.A key problem of SRG method is how to choose provided seeds accurately and quickly.Baxi et al.utilized Global Positioning System (GPS) information as seeds with latitude and longitude records to recognize ground cover types based on satellite image data. In addition, some methodspresented that the initial seeds are automatically selected on color images segmentation tasks through being transformed into YCCcolor space.
In addition,SRG algorithms can play an important role in refining rough-annotations results.For example,Huang et al.used SRG algorithms to generate segmentation masks,the initial seeds of which are provided by category classifier.
3. Study area, data and annotations
The meteorological satellites have the characteristics of wide observation range,a large number of observations,fast observation time, and high quality of observation data so that they are widely applied in meteorological research. For example,Himawari-8 satellitecan detect up to 16 Advanced Himawari Imager(AHI)observation bands,which contain visible bands,nearly infrared bands, and infrared bands. The details and detection categories of every band observed from AHI are shown in Table 1. The main detection category of every AHI band is different so that it is possible to choose three AHI bands to synthesize color images dedicated to sea fog detection. In addition, the detection accuracy of Himawari-8 satel-lite is less than 1 km.Therefore,we chose remote sensing data from Himawari-8 satellite in our study as examples.Undoubtedly, our methods can also be applied to remote sensing data observed from other satellites.
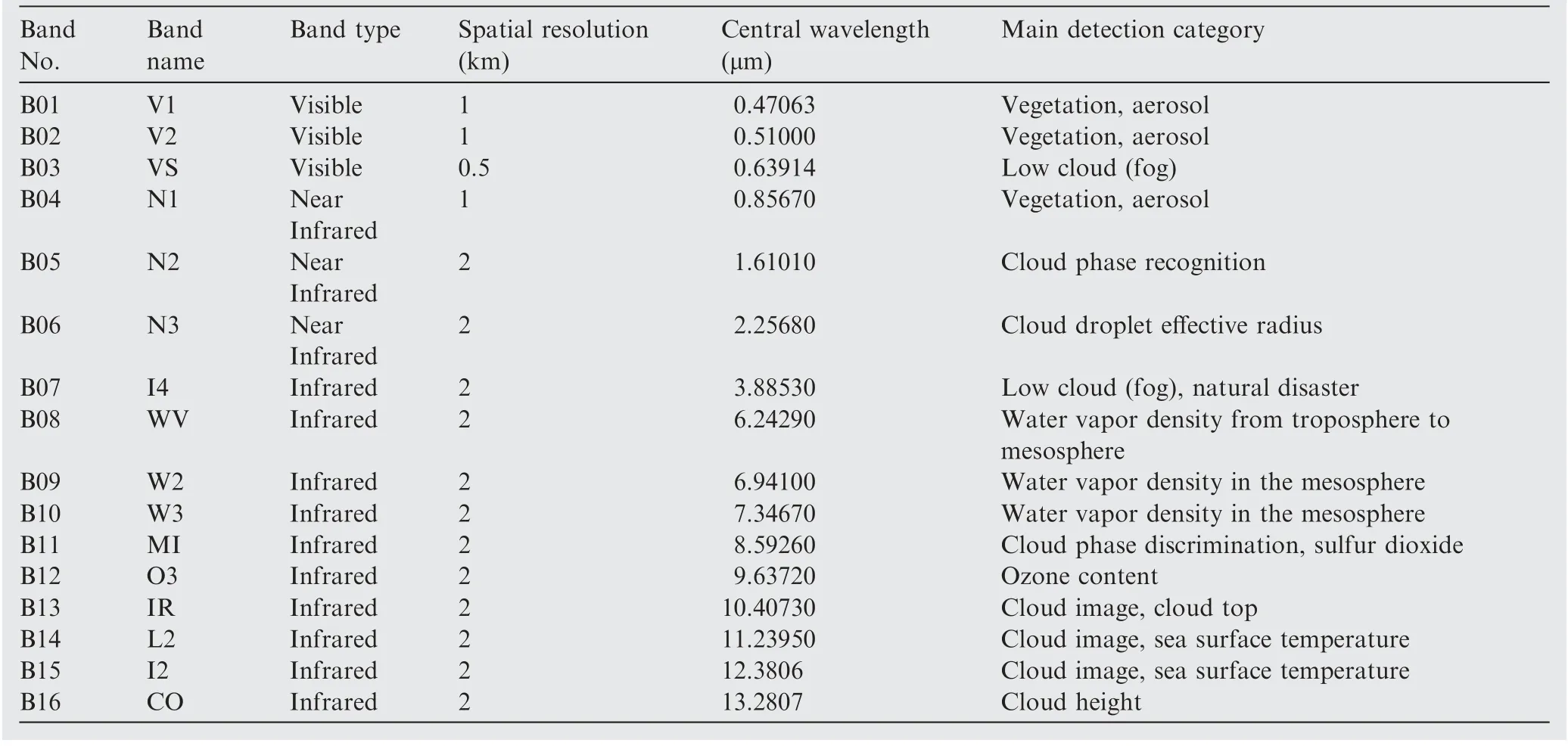
Table 1 AHI observation bands details on Himawari-8 satellite.

Fig. 1 A sea fog occurrence from Himawari-8 satellite observed from AHI sensors on April 17, 2017, at 00:00 UTC (08:00 Beijing standard time).
In our study,we mainly focused on parts of the Yellow Sea and Bohai Sea where the longitude is in the range of 115.00°E to 128.75°E and the latitude is in the range of 27.60°N to 41.35°N since sea fog occurs frequently in this area. Fig. 1(a) shows a sea fog occurrence in our study area from Himawari-8 satellite on April 17, 2017, at 00:00 UTC (08:00 Beijing standard time).From 2017 to 2019,a total of 492 data samples are selected in our study area to generate experimental dataset, and each AHI observation band is defined as a channel of data.
As shown in Fig. 1 (b), each AHI observation band can be reverted to a gray-scale image and there are different image characteristics for the detection category of bands. We can synthesize any three AHI observation bands to generate color images. However, the Red-Green-Blue (RGB) images synthesized by B01, B02 and B03 are difficult to distinguish fog and other cloud groups visually. Taking an example as shown in Fig. 2 (a), it is hard to judge which cloud area should be annotated as ‘Fog’ label or ‘Unfog’ label only based on RGB images without other supplementary information.According to the detection categories of the 16 AHI observation bands of the Himawari-8 satellite and the physical meanings, we argue that some bands are closely related to the fog recognition, such as B03, B04 and B14, and we have proved this argument through t-distribution Stochastic Neighbor Embedding (t-SNE)experiments. More experiment details and results are shown in Section 5. Thus, we synthesize B03,B04 and B14 AHI bands to color images in our study in order to annotate fog areas conveniently.

Fig. 2 Comparison between two types of synthesized images taking an occurrence on April 17,2017 at 00:00 UTC on our study area as an example.
We compare two types of synthesized images at the same time as shown in Fig. 2. One is a RGB image, and the other is synthesized by B03, B04 and B14 AHI bands. We find that in the synthesized images, high-cloud can be effectively distinguished from other types of clouds by their blue color. However, it is still unclear how to precisely distinguish low-cloud areas and fog areas due to their similar characteristics. Furthermore,we evaluate on a cloud occurrence using observation values from CALIPSO satellite since CALIPSO can accurately detect cloud height used for determining cloud type following its orbital track. Taking a cloud occurrence at 05:00 UTC on March 29,2018 as an example,as shown in Fig.3,if we annotate pixel-level mask for fog detection only based on human experience, both B-C area and C-D area would be annotated as ‘Fog’ label and other areas would be annotated as ‘Unfog’label. However, according to the observation values of CALIPSO satellite, A-B area and B-C area should be annotated as ‘Fog’ label and C-D area should be annotated as‘Unfog’ label. Therefore, in order to obtain accurate annotations, the auxiliary information is necessary.
Although CALIPSO satellite can provide more precise information for supporting sea fog detection, it does not meet our annotation demands since the detection areas of CALIPSO are linear following its orbit and not real-time.Surface observation stations and buoys obtain visibility information every half an hour, which is shorter than CALIPSO satellite and we consider that surface observation stations and buoys are near real-time. Therefore, we chose surface observation stations and buoys to obtain visibility information for fog detection annotations.We divide the visibility value of surface observation stations into three parts according to fog definition.(A) The visibility value is more than 2 km, and the corresponding observation station is indicated by a green dot. (B) The visibility value is between 1 km and 2 km, and the corresponding observation station is indicated by a red dot. (C) The visibility value is less than 1 km, and the corresponding observation station is indicated by a blue dot. Since the detection areas of surface observation stations and buoys are fixed and cannot fit the boundary of clouds well, we mark bounding boxes of land data. The annotation criterion is shown in Fig. 4(a). If an observation station in a cloud area contains only red dots or blue dots, classification label is marked with a bounding box as ‘Fog’ label (as yellow arrow shows), while cloud area with green dots is annotated as‘Unfog’ (as blue arrow shows). If dots of different colors are confused, they are not annotated (as purple arrow shows).
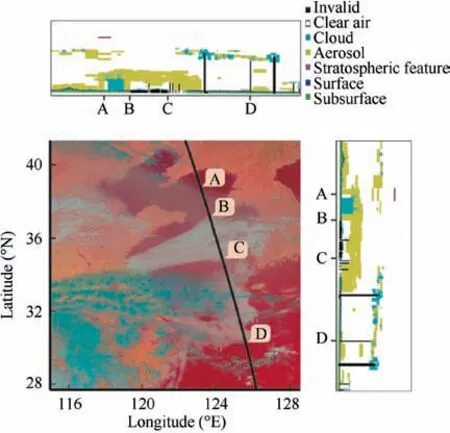
Fig. 3 Evaluation using observation values from CALIPSO satellite on a cloud occurrence on March 29, 2018 at 05:00 UTC on our study area.
During the annotation of remote sensing data, we record location information of every annotation, and location information consists of the coordinate values of left-top corner point, and height and width of rectangular box, as shown in Fig. 4(b).
The minimum values of height and width of all of annotations are 65 pixel and 97 pixel. Thus, we fixed the size of the remote sensing patch data as 64 × 64 to facilitate the domain adaptation classification task. We chose 480 samples as training data, containing 240 samples from land as source domain data with precise labels and 240 samples from sea as target domain data without labels. Based on the condition of visibility information provided by a few observation stations and buoys over the sea,we collect 120 samples from sea as test data containing 60 samples labeled ‘‘Fog” and 60 samples labeled‘‘Unfog”. The details of training dataset and test dataset are shown in Fig.5.Yellow block represents training dataset containing source domain labeled data from land and target domain unlabeled data from sea. Green block represents test dataset containing target domain data from sea with precise labels.
4. Method
In this section, we propose an unsupervised domain adaptation method for sea fog detection based on the knowledge obtained from land fog detection. Our major task is to minimize the differences between the source and target domains,to make the classifier trained on the source domain work well on the target domain. Specifically, in our task, the source and target domains are land fog and sea fog,respectively. In addition,in order to generate pixel-level masks,we designed a processing module using seeded region growing methods to optimize the rough-labels generated by the Category Classifier trained on the source domain data.
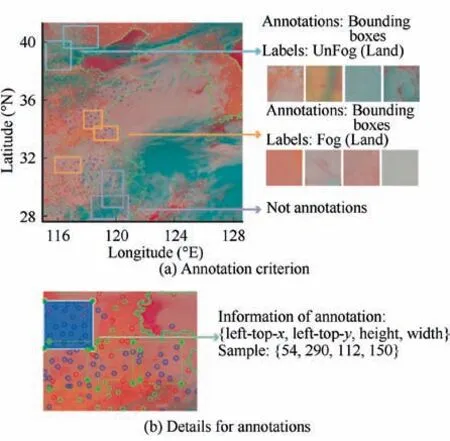
Fig. 4 Annotation criterion of remote sensing data observed from AHI sensor and one sample of part of remote sensing data annotation.
4.1. Feasibility analysis
Land fog and sea fog have a certain visual similarity as shown in Fig.5.But since generation mechanisms of land fog and sea fog are different, we argue that a domain gap between land data and sea data may be excepted.For verifying this,we select 100 samples from land drawn as blue points and 100 samples from sea as green points and use t-SNEapproach to map them into two-dimensional representations as shown in Fig. 6(a). We can see that land data and sea data have different data distribution and a domain gap exists.
Considering the existing domain gap and the lack of labels of target domain over sea, unsupervised domain methods are feasible to achieve sea fog detection.
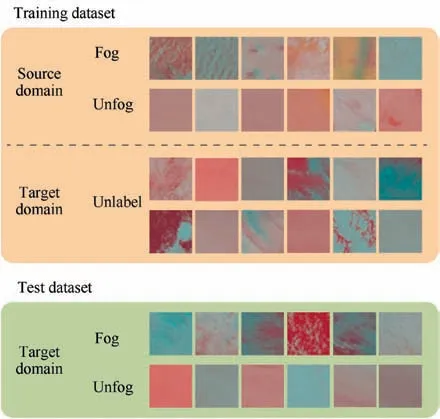
Fig. 5 Details of training dataset and test dataset.
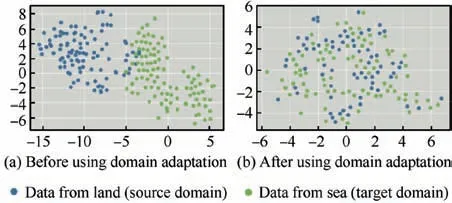
Fig. 6 t-SNE37 experiment results.
4.2. An overview of method
A brief overview of the proposed method is shown in Fig. 7,which mainly consists of two parts.
The first part is the unsupervised domain adaptation algorithm shown in the blue frame. The inputs are labeled land data and unlabeled sea data both after cropping and data pre-processing. We used Feature Maps Extractor to extract features from the source and the target domains,and then utilized a Category Classifier to distinguish between fog or unfog areas using the labeled source domain data.To reduce the distance between the source and target domains, a Domain Discriminator is used. Besides, feature maps from source domain are trained to classify fog areas and unfog areas with precise annotations in Category Classifier, making it predict the test data.
As shown in the red frame in Fig.7,in order to be applicable, we design a processing module based on seeded region growing method as the second part.We record location of test data after cropping.And test data are sent to Category Classifier trained on the first part to obtain its predicted result annotated as ‘Fog’ label or ‘Unfog’ label. This module is used to refine the rough-labels of sea fog areas, which are the results generated by Category Classifier trained on land data in the first part. In addition, to generate more accurate pixel-level masks,we add the relative location information of left-top corner of each patch to its rough-label.
4.3. Unsupervised domain adaptation

In order to mitigate the harmful effect of domain shift, the presentation distance between the source and the target domain needs to be reduced. In other words, one needs to maximize the domain confusion. We use a GAN structure to train our Feature Maps Extractor, by making the discriminator confused between the mappings from the source and target domains to enhance the effectiveness of the Extractor.For this purpose, we define the loss function Lof Domain Discriminator using domain labels as follows:
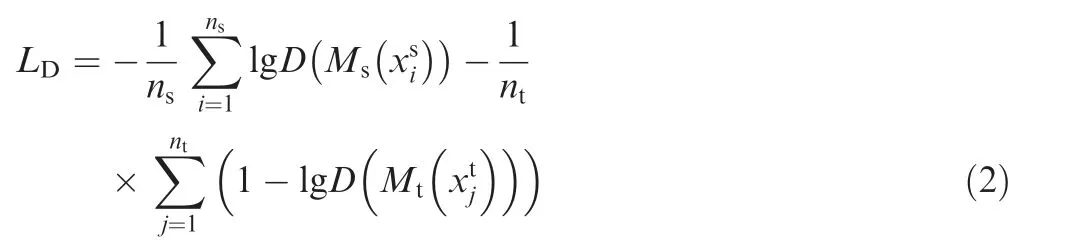
Due to the lack of annotations of target domain, the Category Classifier cannot optimize with labels like source domain data.Following Refs.,we use entropy minimization loss of target domain data to refine the classifier adaptation. We use the entropy loss Lonly acting on target data, which is defined as
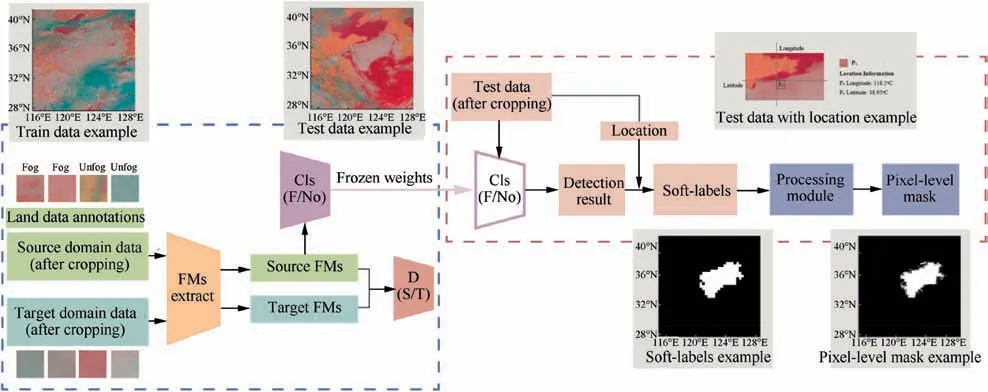
Fig. 7 A brief overview of proposed method, which contains an Unsupervised Domain Adaptation algorithm as the first part in blue frame and a Seeded Region Growing module as the second part in red frame.

The total loss of unsupervised domain adaptation method is as follows:

where α and β are hyper-parameters for trading off these losses.More details of unsupervised domain adaptation experiments are described in Section 5.
Finally, the proposed method for sea fog detection is optimized as
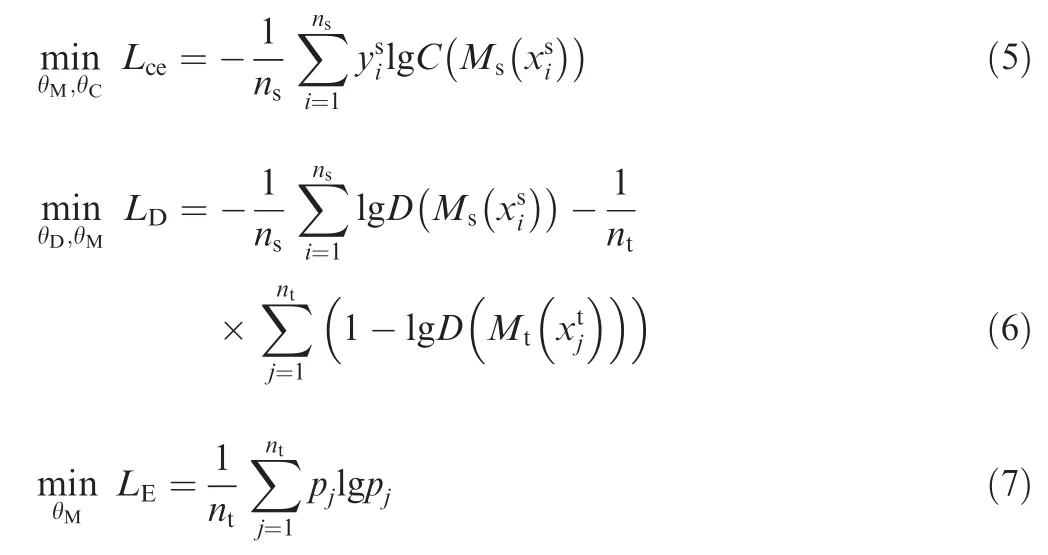
where θ, θand θare the optimized parameters of Feature Maps Extractor model,Category Classifier model and Domain Discriminator model, respectively.
4.4. Processing based on seeded region growing
We can obtain predicted results of sea fog recognition through the Category Classifier trained on unsupervised domain adaptation methods on the first part in our proposed method,but it is hard to be applicable since the patch areas identified by the classifier are just partially matched with the fog areas.In order to generate pixel-level masks by utilizing the patches data and predicted results, we make a further processing module. We take parts of the Yellow Sea and Bohai areas during 2018 as application data to avoid confusion with data in unsupervised domain adaptation, that the longitude is in the range of 115.00°E to 128.75°E and the latitude is in the range of 27.60°N to 41.35°N. The resolution of every remote sensing image data is 2500 × 2500 pixels.
Firstly, each application data is cropped into patches data in size of the 64×64 pixels sliding by every 64 pixels in the vertical and horizontal directions. The location information of every patch is recorded, containing latitude and longitude of the left-top corner. We can obtain results of sea fog recognition based on application data patches through the Category Classifier in the first part.Then we convert these sea fog recognition results to rough-labels. If patch data is recognized as‘‘Fog”, it will be converted to a white patch with the value of RGB=0 in the corresponding location on the whole application image. Otherwise, the patch is converted to black patches with the value of RGB = 255.
The further processing is to generate accurate pixel-level masks for sea fog detection using seeded region growing method.The seeded region growing method is an unsupervised method based on similarity calculating between adjacent pixels. We define white points from rough-labels as initial seeds set {S}. Near points set {S’} is chosen according to the fourneighbor or the eight-neighbor rule. Since we only consider to find more fine-grained region to fit sea fog edge and region,we use the distance between different pixel value of adjacent points, rather than distance between pixel value and mean value. Thus, the distance D is defined as

5. Experiments
5.1. t-SNE experiments
We use t-SNEapproach to visualize data distribution based on mapping high-dimensional data to a two-dimensional representation or three-dimensional representation.
Since each AHI band has its own detection category based on center wavelength,we argue that different AHI bands have different abilities to distinguish fog areas and unfog areas.We design a t-SNE experiment using pre-trained weights only on data from land to prove that argument. The t-SNE results of some AHI bands are shown in Fig. 8, where the purple points represent 100 samples labeled as ‘Fog’ from land and the orange points represent 100 samples labeled as ‘Unfog’ data in each AHI results figure. It shows that different AHI bands have different abilities to distinguish fog area and unfog areas due to its own center wavelength and detection category. We draw a conclusion that B01 and B14 can perform well in distinguishing fog areas and unfog areas while B01 and B16 cannot. It also can be explained why we select B03, B04 and B14 to synthesize color images.
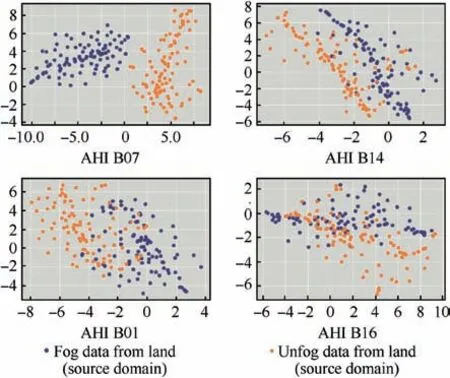
Fig.8 Some t-SNE experiment results of different AHI bands to distinguish fog area and unfog areas.

Table 2 Clustering evaluation results on sea fog detection task.
5.2. Unsupervised domain adaptation experiments
Unsupervised domain adaptation experiments in this paper are mainly divided into three parts with different purposes as follows:
(1) Clustering experiments, which only train and evaluate on sea data. We design these experiments to prove that data over sea without annotations cannot address sea fog detection with well performance.
(2) Contrastive detection experiments, which train deep learning algorithms on land data but directly evaluate them on sea data.
(3) Main detection experiments using the proposed unsupervised domain adaptation method based on labeled land data and unlabeled sea data.
5.2.1. Clustering experiments
We use clustering methods such as K-Meansand K-Means-DEC(which combines an encoder-decoder structure and KMeans) to achieve sea fog detection based on unlabeled data.The models then use the precise labels to evaluate the results of sea test data, and the precise labels are obtained by visible values from observation stations and buoys over the sea. The results are shown in Table 2. K-Means-DECachieves more accurate results of sea fog detection compared with KMeans.From the results, we can see that K-Means-DEC method performs much better than K-Means, but is still not high enough for real application.
In order to analyze sea fog detection results of K-Means-DEC method, we got a confusion matrix based on clustering labels and true labels as shown in Fig. 9 (a). As we can see,through clustering,all samples with‘Fog’true labels are recognized as ‘Fog’, while 24 samples with ‘Unfog’ true labels are misclassified to ‘Fog’ category. It suggests that some types of clouds are similar to fog in color or texture. Therefore, the supervised information or precise labels are needed for distinguishing different types of cloud.
5.2.2. Contrastive detection experiments
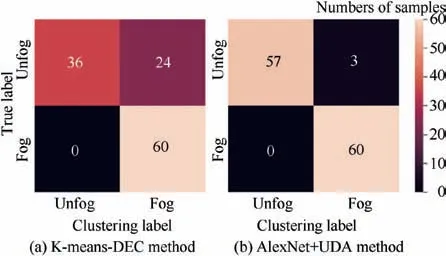
Fig.9 Confusion matrix based on results of K-Means-DEC and AlexNet + UDA methods.
We chose different deep learning algorithms to achieve fog detection, including AlexNet,ResNet-18and ResNet-50with or without pre-trained model on ImageNet dataset. We have these algorithms only trained on the source domain(land data with precise labels) but directly evaluated on the target domain (sea data without labels). The fog detection results are shown in lines 1, 4-6 in Table 3.
As we can see, these deep learning methods achieved a relatively good performance. It suggests that fog data from land and from sea have a high similarity. Thus, it is feasible to transfer knowledge from land fog to sea fog. Besides, pretrained model shows higher accuracy than traditional model.
5.2.3. Main detection experiments
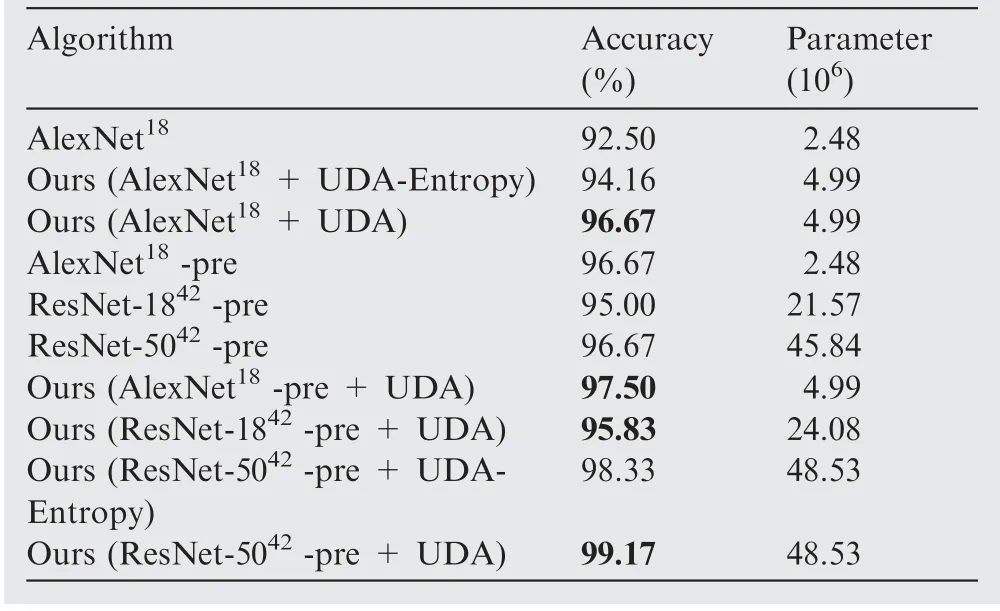
Table 3 Results of fog detection and sea fog detection experiments.
(1) Experiment details and results.
We further use unsupervised domain method proposed to achieve detecting fog areas with higher accuracy. We choose standard network architectures except fully-connected layers to make up Feature Extractor,used in above contrastive detection experiments,such as AlexNet,ResNet-18and ResNet-50. Discriminator consists of three fully-connected layers,which are 1024-way layer, 1024-way layer and classification layer, respectively. Category Classifier is designed as a bottleneck structure with a batch-norm layer and a leaky-ReLU layer with a fixed negative slope of 0.2.Besides,we design comparative experiments to prove the effectiveness of entropy loss used in target domain data.

Fig.10 t-SNE visualization results of data distribution on 120 target domain samples.The numbers represent the serial numbers of 120 samples.
In the experiments, we set hyper-parameters α = 0.3 and β = 0.1. In order to optimize loss conveniently, we use three optimizers named as Opt, Optand Optfor Feature Maps Extractor, Category Classifier and Domain Discriminator, respectively. All optimizers use Stochastic Gradient Descent (SGD), where momentum is set to 0.9 and weight decay is set to 5 × 10. The learning rate of Optand Optare set to 5 × 10and the learning rate of Optis set to 5 × 10.
The results of unsupervised domain adaptation are shown in Table 3. We choose different deep learning algorithms to show the effectiveness of domain adaptation, compared with those algorithms trained on land data and directly evaluated on sea data. On the top of these results,we can see that the methods with unsupervised domain adaptation achieved a further improvement. It can be reasoned as an effect of minimizing distance between the source and target domain and extracting more common features of different domains.
(2) Feature visualization.
After adapting using our method, only 3 samples with‘Unfog’ true labels are wrongly predicted as ‘Fog’ category as shown in Fig. 9 (b). After adapting using our method, only 3 samples with ‘Unfog’ true labels are misclassified to ‘Fog’category. Compared with confusion matrix of K-Means-DEC shown in Fig. 9 (a), our method can correctly classify most of the unfog samples that are similar to fog ones. This confirms the feasibility of our method.
In addition, we design a t-SNE experiment to prove the effectiveness of narrowing domain gap between source and target domain. We select the same data in Fig. 6 (a) and the results are shown in Fig.6(b).We can draw a conclusion that the domain gap between source and target domain narrows through using domain adaptation methods, compared with t-SNE experiment results shown in Fig. 6 (a).
Furthermore,we design t-SNE experiments to visualize the target domain data distribution before and after unsupervised domain adaptation (AlexNet with pre-trained model as backbone), as shown in Fig. 10. Comparing Fig. 10 (a) and (c),we can draw a conclusion that different types of data are separable, which is different from the previous data aliasing together.
In addition,we use t-SNE experiments to show the effect of entropy loss on target domain.Comparing Fig.10(b)and(c),we can see that the distance between different classes increases.In other words, entropy minimization loss Laims to enforce the decision boundary to pass through low-density area in the target domain.
5.3. Seeded region growing experiments
In these experiments, we evaluate the seeded region growing algorithm on remote sensing images synthesized by B03, B04 and B14 AHI bands chosen during March to July in 2018 on our study area. Firstly, we crop these remote sensing images to patches with the size of 64 × 64. We record location information containing latitude and longitude of left-top corner of them. Every patch is predicted by the Category Classifier trained on unsupervised domain adaptation method with frozen weights. Then, according to the location of every patch,we revert every patch to synthesized image with predicted label.If predicted label is’Fog’,the pixel values of a mask with the same location will be set to 255,otherwise,the pixel values will be set to 0. We call the masks predicted by the category classifier as rough labels.
In order to make them more accurate for real applications,the seeded region growing processing is performed.We choose seeds with the pixel value of 0 as initial seeds,and then expand the region by the growing algorithm.For optimizing the threshold of θ,we try different values of θ from 0.1 to 0.9,and the optimal three values among them are 0.1, 0.2 and 0.3. The results corresponding to the optimal values are shown in Fig.11.
We can see that after seeded region growing,the regions of sea fog are expanded and the detailed shapes of the fog in the images are formed. Different settings of the threshold are corresponding to different shapes. If the thresholds are not fit,some points belonging to unfog areas would be wrongly selected, such as the red frame area in Refined-Labels(θ = 0.3) shown in Fig. 11(c). From these results, we finally set the threshold value to 0.2.
6. Conclusions
This paper addresses the sea fog detection task utilizing the latest deep learning technology, and it presents a new approach which shows better performance than the conventional ones.The main points of its innovation are as follows:
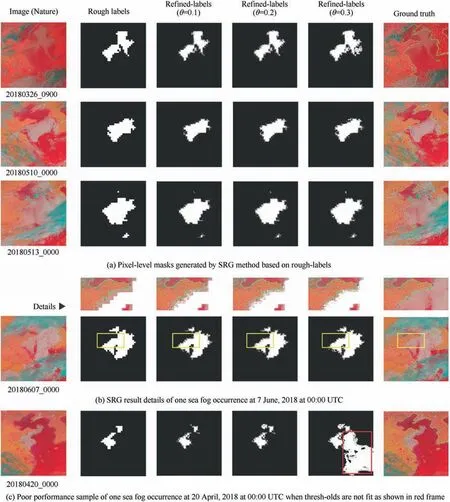
Fig. 11 Results and details of seeded region growing experiments with different thresholds.
(1) Considering the similarity between the land fog and the sea fog,we propose a method of transferring the knowledge learned on land fog detection to the task of sea fog detection, solving the problem of the lack of precise labels of sea fog detection.
(2) In order to minimize the differences between land data and sea data,we present an unsupervised domain adaptation method to extract common features for the source and the target domains.As a result,we achieve the accuracy of 99.17%for sea fog detection using unsupervised domain adaptation, which is higher than unsupervised cluster methods and baselines without unsupervised domain adaptation.
(3) We design a seeded region growing module generating more accurate pixel-level masks to make fog detection more applicable in reality.
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
This work was supported in part by the Ministry of Education-China Mobile Communication Corp(MoE-CMCC)Artificial Intelligence Project, China (No. MCM20190701).
 Chinese Journal of Aeronautics2022年4期
Chinese Journal of Aeronautics2022年4期
- Chinese Journal of Aeronautics的其它文章
- Reduced-dimensional MPC controller for direct thrust control
- A multiscale transform denoising method of the bionic polarized light compass for improving the unmanned aerial vehicle navigation accuracy
- Periodic acoustic source tracking using propagation delayed measurements
- Optimal predictive sliding-mode guidance law for intercepting near-space hypersonic maneuvering target
- Unsteady characteristic research on aerodynamic interaction of slotted wingtip in flapping kinematics
- Overview of current design and analysis of potential theories for automated fibre placement mechanisms