
基于DFCNN-CTC 和Transformer 的中文语音识别*
2022-04-27 09:04郭文明
火力与指挥控制 2022年3期
杨 璐,郭文明,,韩 芳
(1.北京邮电大学计算机学院(国家示范性软件学院),北京 100876;2.可信分布式计算与服务教育部重点实验室,北京 100876;3.新疆工程学院信息工程学院,乌鲁木齐 830023)
0 引言
语音识别是让计算机听懂人类的语音,并转换成人类能读懂的文字,实现人与机器的交互。随着互联网的不断发展,百度、阿里、科大讯飞等都开发出相对成熟的语音识别系统,但有些公司涉及内部语音保密和投资成本等问题,需要开发满足自己需求的语音识别系统,本文基于此背景展开研究。
语音识别技术最早开始于1952 年,贝尔实验室研发出的10 个孤立数字的识别系统。语音识别的目标是给定语音输入的情况下,找到对应可能性最大的文字序列,根据此目标将语音识别分为声学模型(acoustic model)和语言模型(language model)两个部分,二者对语言现象训练学习到的特征越多,识别结果越准确。但在很多语音识别的应用中,可能输入一段较长语音或将多句话连续输入,则识别的结果是没有空格或标点符号的一连串汉字,为此需要为识别结果添加适当的标点停顿,增强文本的可读性。
因此,本文引入语音端点检测技术,通过捕捉语音中说话者的停顿位置添加标点符号,帮助人们更准确地理解文本,以DFCNN 输出端融合CTC 作为声学模型,实现模型的端到端训练,引入Transformer作为强语言模型建立语音识别系统进行研究。
1 相关工作
在声学模型领域中,基于DNN-HMM 的混合模型架构,卷积神经网络(convolutional neural network,CNN)能够充分利用上下文信息,将深度神经网络(deep neural network,DNN)和性能更好的长短时记忆网络(long-short term memory,LSTM)集成到该模型中,构成CNN-LSTM-DNN(CLDNN)架构,解决了在训练过程中产生的梯度消失问题。随后提出一种全新的语音识别模型架构全序列卷积神经网络(deep fully convolutional neural network,DFCNN),经过大量实验证明,DFCNN 比目前流行的、学术界效果最好的双向LSTM 语音识别系统的识别率提升了15%以上,它直接将语谱图特征作为输入,最大程度减少了信息损失,再经过不断地卷积池化,使模型能学到很长的历史和未来信息,相比BLSTM具有更强的稳健性,输出端与连接时序分类器(connectionist temporal classification,CTC)相融合,相比BLSTM-CTC 系统的性能提升了15%。
在语言模型领域中,传统的N-gram 模型虽然具有简单的结构和高训练效率,但是模型不具备所需要的语义上的联系,且参数过大,因此,无法有重大的突破。Vaswani 等提出了一种非递归序列到序列的新模型Transformer,在许多任务中都有突出表现,如预训练语言模型、端到端语音识别等。它的一个关键组件是自注意力机制,用于计算整个输入序列所贡献的信息,并在每个时间步中将序列映射到一个向量,能够在分析预测长文本时捕捉间隔较长的语义关联,并且可以利用分布式GPU进行并行训练,计算效率更高,在一定程度提升了模型的训练效果。
现在大多数语音识别系统的识别结果为可读性较差的整段文字,且输入的语音长度为十几秒的短语音。近年来,人们将基于深度学习的模型引入到解决自动添加标点符号的问题中,比如CRF 模型对自动标点的预测,利用词的词法信息和句法信息构建自注意力机制模型,预测中文标点符号,它们主要是对语音识别后的文本信息进行预测,模型通过学习词与词之间的位置信息、当前词在语义环境中的词性和句法作用来预测标点,但大多数模型的性能较差、预测准确率低,这使得语音识别的最终准确率也大大降低,而且在模型训练过程中需要耗费大量时间和成本。语音端点检测可以看作语音帧的二分类问题,其方法可以分为3 种,第1种是基于声学特征的端点检测,根据语音和非语音在声学特征上的分布规律,设定阈值区分语音和非语音信号,第2 种是基于统计模型的无监督端点检测,采用高斯分布进行建模,并使用软决策方法进行判别,第3 种是基于机器学习的有监督端点检测,引入神经网络可以提高模型的判别能力。因此,本文引入语音端点检测,直接对输入的语音进行处理,通过捕捉语音中说话者的停顿位置添加标点符号,在保证准确率的同时节约成本,解决了连串汉字的断点问题。
2 本文方法
本文实现的语音识别系统框架如图1 所示。主要包括端点检测、声学模型和语言模型3 个部分。输入的音频文件可选择本地文件或使用录音功能录制的文件,经过端点检测模型获取到一个List 集合,再经过声学模型将语音信号转化成对应的拼音信息,经过语言模型将拼音转化成对应的文本内容,最终将带有标点的文本保存,完成语音到文字的识别。

图1 语音识别系统框架图
2.1 DFCNN-CTC 声学模型
DFCNN-CTC 由4 部分组成,网络结构如图2所示。第1 部分为输入层,接收输入的声学特征,即通过对时域信号进行分帧、加窗、傅立叶变换、取对数得到的语谱图特征,接着特征数据经过规范化层和零填充层的处理,确保数据归一为标准正态分布且批处理中的所有语句具有相同长度。
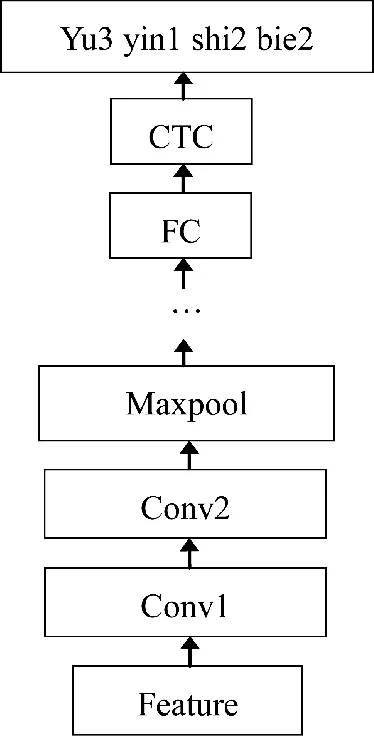
图2 DFCNN-CTC 网络结构图
第2 部分为卷积池化层,包含5 组CNN-Maxpool 层,每组由2 个CNN 和1 个Maxpool 构成,CNN 层使用3*3 的卷积核对声学特征进行卷积操作,Maxpool 层通过提取最大参数来降低参数数量。经过较多的卷积层和池化层,模型能够学到更多的历史和未来信息。
第3 部分为全连接层,它的每个神经元与前一池化层的所有神经元进行连接,整合卷积池化层的分类特征并加以区分。每个神经元的激活函数使用ReLU 函数。
第4 部分为CTC 输出层,用于生成预测的拼音序列,网络结构如图3 所示。x 为输入序列,h 为Encoder 的输出,LC(liner classifier)为线性分类层,t为最终的输出序列。由图3 可以看出,CTC 具有较强的条件独立性,即每个单词的输出之间是各自独立的,这使得最终结果出现结巴重复的词,因此,将DFCNN 作为CTC 的Encoder 层,利用其较深的卷积池化结构,使模型学习到更多有用的信息。同时,CTC 算法不需要对数据进行对齐操作和一一标注,引入空白占位符使得输入和输出之间有了合理的对应关系,可以输出对齐的结果。

图3 CTC 网络结构图
2.2 引入Transformer 语言模型
在传统的语音识别系统中,大多将注意力放在声学模型的改进上,忽略了语言模型N-gram 存在字词之间语义的相似性、训练时的参数过大等问题,因此,本文引入强语言模型Transformer,结合DFCNN 声学模型构建语音识别系统。
Transformer 能学习到输入序列与输出序列之间的对应关系,它的结构包括编码器和解码器两个主要模块,编码器编码时间序列,解码器结合编码器的输出和上一时间步长的输出来生成下一时间步长的输出,直到生成结束符为止。Transformer 将声学模型输出的拼音序列作为输入,先经过文本嵌入层,将文本中词汇的数字表示转变为向量表示,通过高维空间捕捉词汇间的关系;再经过位置编码层,词汇位置的不同可能会产生不同的语义信息,将位置编码加入到词嵌入向量中,弥补位置信息的缺失,两层结果相加作为编码器的输入。
编码器旨在对原始信息进行编码表示,编码表示能够体现出该字符序列的语义信息。编码器由6个编码单元组成,每个编码单元有多头注意力机制层(multi-head attention)、残差连接和归一化层(add& normalization)以及前馈神经网络层(feed forward)。其中,多头注意力机制层利用多个自注意力机制(self-attention),从不同的信息维度提取字符的向量表示。自注意力机制的每个输出都考虑了所有输入序列的信息,具有可以并行计算和考虑全局信息的优点,其网络结构如图4 所示。
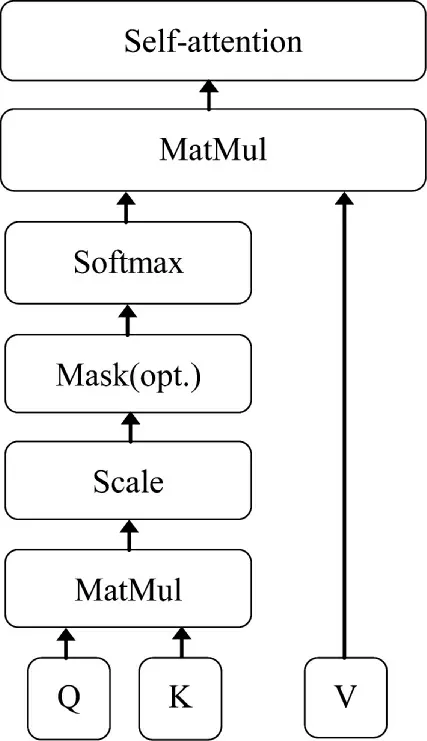
图4 自注意力机制网络结构图
自注意力机制的计算输出矩阵表示为:

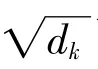
但在实际应用中,单个Self-attention 的拟合能力较差,常使用多头注意力机制。在并行执行每个独立计算的自注意力机制之前,使用一组线性变换层,并将其输出连接到另一个线性投影中,从而得到最终的输出。多头注意力机制使模型能够在不同的表示子空间中,在不同的位置共同关注信息,让每个注意力机制去优化每个词汇的不同特征部分,均衡偏差,让词义拥有来自更多元的表达。多头注意力机制表示为:

残差连接层可以避免梯度消失问题,归一化层采用BN(batch normalization)算法,在每层的每批数据上进行归一化,将输入转化成均值为0 方差为1的数据,防止经过多层前向计算后数据偏差过大。
在编码器的子层中还包括前馈神经网络层,由于自注意力机制对复杂过程的拟合程度不够,通过增加两层线性网络来增强模型能力。该层网络可表示为:
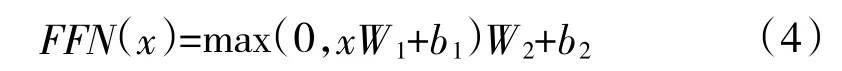
每个解码器比编码器多一个掩码多头自注意力层,利用掩码张量,保证在预测句子时仅依赖于已知的输出量,将已经传入的后一个未来字符信息进行遮掩。编码器可以并行计算,但是解码器类似于RNN 网络,需要一步一步去解码。最后,通过线性层和sofemax 层将解码器的输出转换为输出词的概率分布。
2.3 引入语音端点检测技术
在实验过程中发现,最终得到的语音识别结果是整段文字,不易于读者理解,也不利于该文本后续的处理和使用,同时可识别的最长语音为16 s,经过实验测试,随着语音长度参数的增大,模型训练时所需要的参数和时间呈指数增长,对计算机设备的要求较高。基于以上出现的问题,将语音端点检测(voice activity detection,VAD)引入语音识别系统中,通过分析语音帧的特征,使模型能够区分语音和非语音信号,解决连串汉字的断点问题。
VAD 可以将语音信号自动打断,将音频信号划分为发音部分(voiced)、未发音部分(unvoiced)和静默部分(silence),算法过程如下:首先对语音信号进行分段,以帧为单位实现分帧操作,接着从每一帧数据当中提取梅尔频率倒谱系数(mel-frequency cepstral coefficient,MFCC)特征,然后在一个已知语音和静默信号区域的数据帧集合上训练一个分类器模型,最后用训练好的模型对未知的音频信号分类,得到最终的分类结果。
在本文中,VAD 接收输入的语音文件进行分类,通过获取检测得到的断点,即每段发音部分的起止时间,将这些起止时间保存到一个List 集合中,最终将List 值和原始语音文件作为语音识别的输入,继续之后的识别操作。引入VAD 可以检测到说话者停顿时间较长的位置信息,作为一句话的结束添加标点符号,并且对需要识别的语音数据长度没有要求。在公开数据集的特征与标注数据下,训练后得到的分类模型准确率达到98%。
VAD 训练的模型是基于深度卷积长短时记忆网络(convolutional long-short term memory deep neural network,CLDNN),是一种组合形式的网络结构。首先输入原始语音,经过2 个CNN 层提取局部特征,每层核大小为1*3,加入BN 层和ReLU 激活函数防止过拟合,CNN 层将输入的低级特征转化成高级特征,可以消除输入频率的变化,做特征之间的映射和转换;LSTM 层容易学习连续时间步长间的结构,可以充分利用上下文信息进行时序建模,学习时序信息;DNN 将局部和时序特征映射到可分空间中,输出当前帧的预测结果。VAD 使用二元交叉熵BCE(binary cross-entropy)作为损失函数,模型的网络结构如图5 所示。
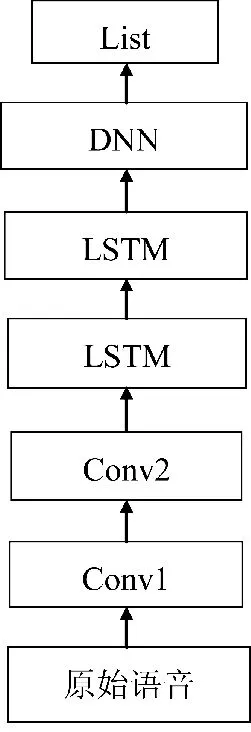
图5 CLDNN 网络结构图
图6 和图7 分别为没有经过端点检测的识别结果和本文系统的识别结果,语音数据为Thchs30 测试集中的语音文件。由图5 和图6 的结果表明,没有经过端点检测的结果是一连串文字,需要读者自己理解断句,而引入端点检测的语音识别结果中,每句话由逗号分开,句子意思表达清晰,两者对比显然本文系统的识别结果更具可读性,也更易于读者理解。

图6 无语音端点检测的识别结果

图7 本文系统的语音识别结果
3 实验
3.1 前期准备
3.1.1 声学模型和语言模型参数
语音信息是采样率为16 KHz 的单通道数据,在经过分帧(帧长25 ms、帧移10 ms)以及加汉明窗进行分析后,最终提取200 维的语谱图特征作为声学模型的输入。经过DFCNN-CTC 结构,学习率(learning_rate)为1e-3,该参数可以确定每次迭代的步长,使损失函数收敛到最小,本文使用离散下降的方法更新学习率,初始设置一个较大的值,随着迭代次数的增加,不断减小数值;批处理大小(batch_size)为32,大的batchsize 可以使梯度计算更加稳定,同时减少训练时间,但是对计算机的算力要求较高;dropout 为0.3,应用于除输入层和输出层以外的所有层中,dropout 层是按照设定的概率暂时将部分神经网络训练单元从网络中移除,防止训练时过拟合;采用CTC loss作为损失函数、Adam 优化器进行优化,Adam 优化器可以使参数信息较平稳。
在Transformer 语言模型结构中,提取200 维特征,与声学模型保持一致;批处理大小为40,减小批处理大小会使解码速度变慢,识别结果变差;词嵌入向量为512;多头注意力数为8,增加多头注意力数目会使训练时间变长,识别结果几乎没有差异;学习率为0.000 3,具体更新方法同声学模型;dropout为0.2。
3.1.2 数据集
本文采用Thchs30 和ST-CMDS 两个中文数据集,总计140 h,包括115 988 条语句,其中,训练集110 000 条,验证集1 493 条,测试集4 495 条,训练集、验证集和测试集的比例为73∶1∶3。
Thchs30 数据集是由清华大学语音与语言技术中心(CSLT)出版的开放式中文语音数据库,是在安静的办公室环境下,通过单个碳粒麦克风录取,大约40 个小时,内容以文章诗句和新闻为主,由会说流利普通话的大学生参与录音,全部为女声。
ST-CMDS 是由一个AI 数据公司发布的语音数据集,大约100 个小时,内容以平时的网上语音聊天和智能语音控制语句为主,由855 个不同说话者参与录音,同时有男声和女声。由于原始语料库没有划分数据集,因此,参考了Thchs30 的划分方法,随机选择了100 000 条语句作为训练集,600 条语句作为验证集,2 000 条语句作为测试集。
3.2 实验结果
针对本文提出的DFCNN-CTC 结合语言模型Transformer 的中文语音识别系统,为了验证该系统的性能,将两个数据集分别在DFCNN 结合3-gram和本文系统模型上进行实验验证,测试结果如表1所示。WER 是指语音转文字的词错误率,是语音识别任务性能的评测指标,计算公式如下所示:

表1 两个数据集在不同系统模型的WER(%)

为了使识别出的词序列和标准词序列保持一致,需要进行替换、删除或者插入某些词。其中,S 表示替换的次数,I 表示插入的次数,D 表示删除的次数,N 表示标准词序列中词的个数。
由表1 中两个不同数据集的验证结果表明,本文提出的DFCNN-CTC 结合Transformer 语音识别系统在不同数据集上的词错误率都有明显下降,分别下降了6.1%和7.7%,体现了较好的性能和泛化能力。这是因为Transformer 相比3-gram 模型并行对整句语音进行建模,每个单词在训练时与句子的所有单词都建立了联系,不仅提高训练速度,而且使单词之间有了语义联系,识别结果更准确。
本文还通过比对不同模型识别所用的时间来验证模型的性能,实验结果如表2 所示。在表2 中,N 表示从Thchs30 数据集的测试集中抽取语音数据的条数,从测试结果可以看出,本文提出的系统模型在识别相同数目的语音文件时,测试时间有明显的减少,识别速度相比DFCNN-3-gram 模型提升了33%左右。

表2 不同系统模型的测试时间(s)
为了验证声学模型DFCNN-CTC 结合强语言模型Transformer 的语音识别系统的优势,将该系统与BLSTM系统、DFSMN-3-gram、DFSMN- Transformer、DFCNN-3-gram 系统作对比,实验结果如表3 所示。
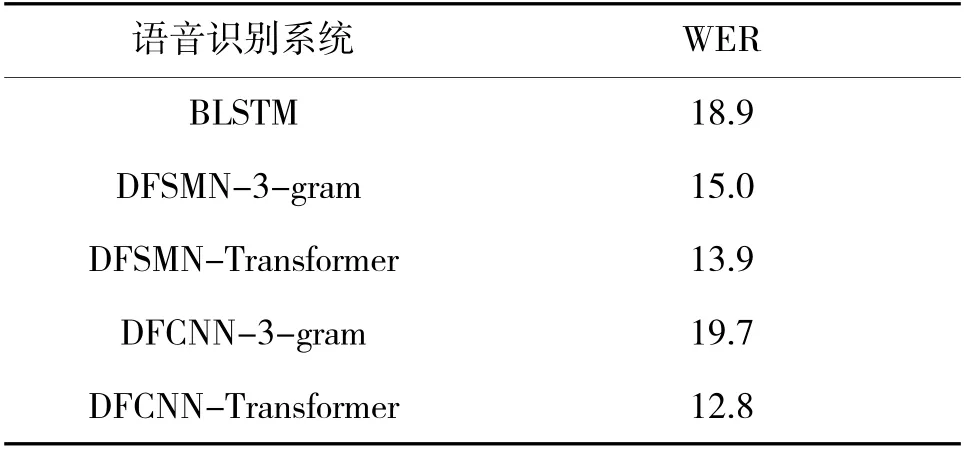
表3 不同语音识别系统的WER(%)
由表3 中的数据表明,本文提出的语音识别系统相较于其他系统,在识别准确率上具有一定的优越性,准确率达到了87.2%。对比声学模型可以得出结论:DFCNN 结合Transformer 相比DFSMN 结合Transformer 的词错误率下降了1.1%,这可能是因为DFCNN 和DFSMN 虽然都有很深的模型结构,但DFCNN 中的卷积池化结构能够学习到更多的语音特征;对比语言模型可以得出结论:Transformer 的核心组件注意力机制使整句话中字词之间有了语义上的联系,整体优于3-gram 模型,词错误率分别下降1.1%和6.9%。
4 结论
本文引入语音端点检测技术,使系统得到的最终识别结果为可读性高的带标点文本,同时对输入的语音长度不受限制。引入强语言模型Transformer,将其和声学模型DFCNN-CTC 相结合,建立了DFCNN-CTC-Transformer 自动语音识别系统。实验结果表明,新的语音识别系统总体性能优于某些现有的系统,准确率有明显提升。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
智慧电力(2022年4期)2022-05-19
计算技术与自动化(2022年1期)2022-04-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
语数外学习·高中版中旬(2020年8期)2020-09-10
南方周末(2020-01-02)2020-01-02
中学生数理化·教与学(2019年8期)2019-09-18
数学大王·中高年级(2018年7期)2018-08-29
中学生数理化·中考版(2014年5期)2016-12-22
