
考虑交通运行条件影响的驾驶员特征聚类
2022-04-26 06:50:32张建波孙建平徐春玲郭镜霞温慧敏宋国华
交通运输系统工程与信息 2022年2期
张建波,孙建平,徐春玲,郭镜霞,温慧敏,宋国华
(1.北京交通大学,交通运输学院,北京 100044;2.北京交通发展研究院,城市交通运行仿真与决策支持北京市重点实验室,城市交通北京市国际科技合作基地,北京 100073)
0 引言
驾驶员特征是影响道路交通运行效率与安全的关键因素。文献[1]统计表明,超过90%的道路交通事故与驾驶员的危险行为直接或间接相关。随着车载自诊断系统(On-board Diagnostics,OBD)、车联网等技术的发展,驾驶员画像与聚类研究[2]已经成为道路安全管理、驾驶辅助系统开发等诸多工作的重要支撑。
现有的驾驶员特征分析与聚类模型十分丰富,如K-means,层次聚类和DBSCAN(Density-Based Spatial Clustering of Applications with Noise)等;模型输入参数则因数据来源(主要有OBD、驾驶模拟器、自然驾驶和仿真等)的不同而存在差异。Wang等[3]利用驾驶实验平台采集驾驶员行为数据从谨慎性、稳定性、冲突倾向性和熟练性等4 个方面评估驾驶员特质。吴坚等[4]通过动态虚拟仿真系统采集驾驶员驾驶过程中的制动踏板数据用于驾驶员分类模型的训练。Fugiglando等[5]则利用OBD采集公交数据进行K-means聚类。Yao等[6]基于OBD和全球定位系统(Global Positioning System,GPS)数据采集车辆在特定线型道路上的左转数据,利用动态时间归整算法(Dynamic Time Warping,DTW)和隐含马尔柯夫模型(Hidden Markov Model,HMM)聚类驾驶行为特性。
但少有研究在聚类分析中考虑不同交通运行条件变化(如设施类型、平均速度、交通相等)对驾驶员驾驶行为特征的随机性影响。上述研究中关于驾驶行为特征适用于各种交通条件的基本假设与实际应用模型(如机动车排放模型(Motor Vehicle Emission Simulator,MOVES))中的基本假设是不一致的。近期的部分研究也关注到了这一问题[7]。Zhai 等[8]考虑时段、道路类型和气象条件等因素提出考虑情景感知的驾驶员评估方法。Martinelli等[9]在驾驶员特征聚类中区分了城市道路和高速公路的设施条件。然而,交通运行条件对驾驶员特征聚类结果的影响并没有得到充分分析。
本文旨在分析交通运行条件(道路类型和平均速度)对驾驶行为特征的影响,提出一种改进的驾驶员聚类方法,以提高驾驶员聚类面向不同数据采集和交通场景时的适用性和可靠性。
1 数据准备
本文利用“智驾盒子”采集了北京市部分私人小汽车的脱敏运动轨迹数据。该设备以1 s的时间粒度实时采集运行车辆的位置、速度、油耗和发动机运行参数。经过预处理,共筛选出2020年5月315 名驾驶员在20 个工作日的驾驶行为数据3400余万条,驾驶员的平均驾车时长达到29.7 h。小汽车的运行轨迹数据依据车辆行驶路径实时匹配了道路类型(包括快速路、主干路和次支路)等信息。本文利用的车辆瞬时运行轨迹数据主要包括车辆id、记录时间、道路类型、车辆瞬时速度和加速度等。全部样本数据的统计情况如表1所示。
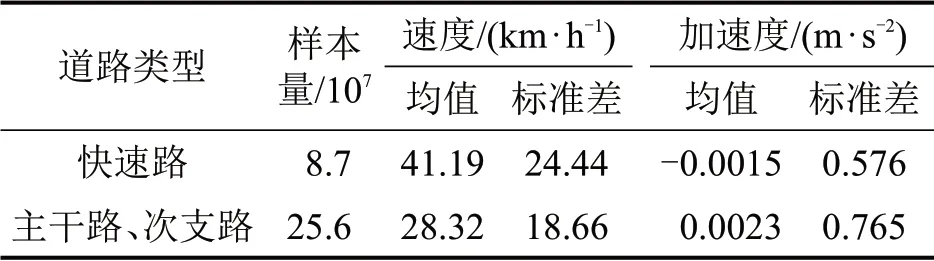
表1 车辆轨迹数据的统计情况Table 1 Statistics of vehicle motion data
2 交通运行条件对驾驶行为参数的影响分析
本节旨在分析道路类型和运行速度对驾驶员驾驶行为特征参数的不确定性影响。
2.1 考虑道路类型和平均速度的驾驶行为数据分类
首先,根据道路类型将轨迹数据切分为快速路和非快速路两类。随后以30 s 的时间长度将单一道路类型条件下的车辆运行轨迹切分为短轨迹片段;计算短轨迹片段的平均速度并以10 km·h-1为标准划分速度区间,由此得到分道路类型(快速路和非快速路)和平均速度([0,10) km·h-1,[10,20) km·h-1,…,[80,90) km·h-1)的分类轨迹数据池。平均速度及速度区间的计算公式为
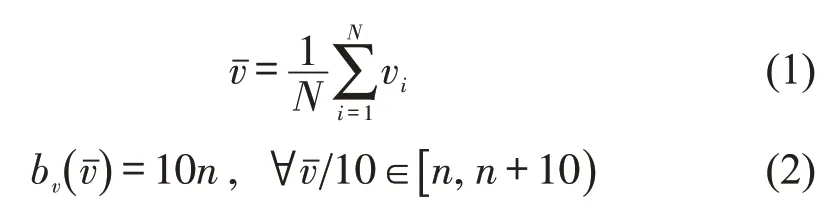
式中:N为样本数;vi为车辆逐秒轨迹中的第i秒速度(km·h-1);为轨迹片段的平均速度(km·h-1);bv为速度区间编号;n为表示速度区间的整数(8 ≥n≥0)。
轨迹分类如图1所示,210 s的逐秒轨迹被切分为7个短轨迹片段,并根据道路类型和平均速度对其进行分类。这有助于真实反映不同交通运行条件下驾驶行为差异。而时长30 s 的轨迹切片结果可以与多种模型的实际需求相耦合,这些模型通常基于1,3,5 min 等不同集计粒度(例如浮动车数据集计的5 min,快速路机动车工况分布集计的180 s等)。
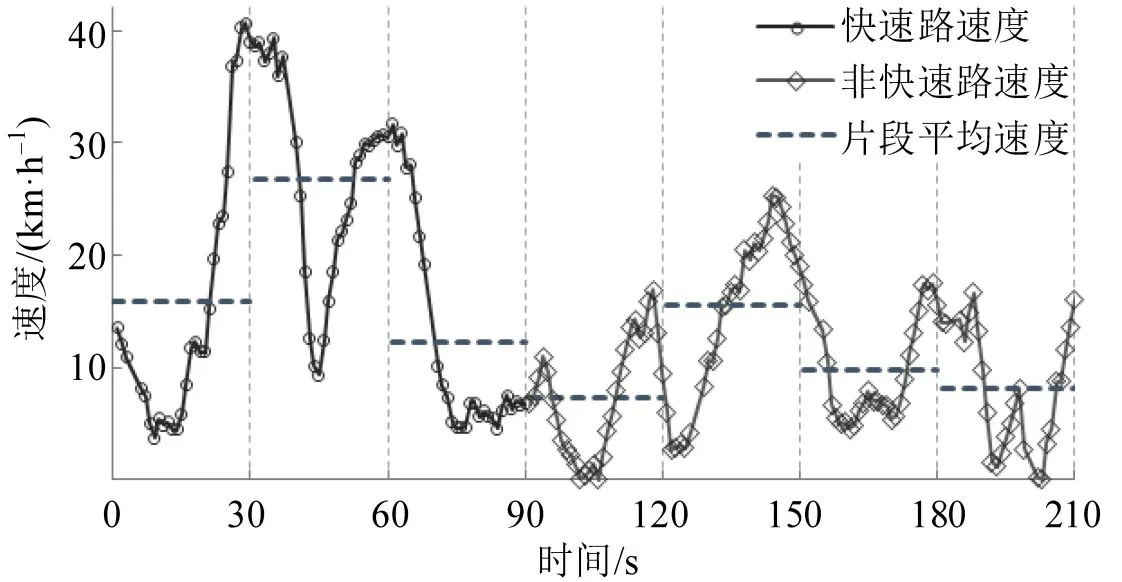
图1 驾驶行为估计切片分类示例Fig.1 Example of splitting vehicle motion segments
由文献[10]证明在相同的速度区间下,主干路和次支路的小汽车运行工况分布具有较高一致性,因此本文将主干路、次支路合并归类为非快速路。这一道路类型的分类方法能保证车辆轨迹的连续性,降低对数据量的要求。
最后由分类数据计算得到不同道路类型和平均速度样本的驾驶行为特征参数,需注意的是,当短轨迹片段时长不足20 s 时,将其归类为无效数据,不参与后续的驾驶员特征参数计算。
2.2 不同交通运行条件下的驾驶行为参数可变性
以速度变异系数和加速度标准差为例,实证分析不同交通运行条件下的驾驶行为特征参数的可变性。速度变异系数和加速度标准差计算公式为
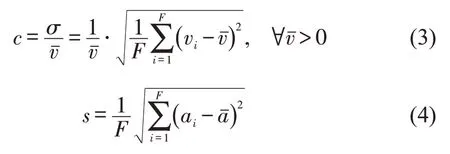
式中:F为分类数据的样本量;c为速度变异系数;σ为分类数据的速度标准差;为分类数据的平均速度(km·h-1);s为分类数据的加速度标准差;ai为分类样本中的第i秒瞬时加速度(m·s-2);为分类样本平均加速度(m·s-2)。
如图2所示,无论是快速路还是非快速路,速度变异系数都随着平均速度的增加而减小,而加速度标准差则随着平均速度的增大呈现先增大后减小的趋势。对于每个平均速度区间,非快速路上的速度变异系数和加速度标准差均高于快速路上的统计结果。这证实了在不同的交通条运行件下,驾驶行为在速度和加速度变化方面存在显著差异。交通运行条件的不同会显著地影响驾驶员的行为特征。
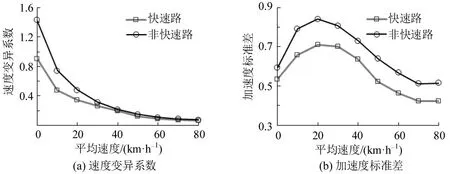
图2 不同交通条件下驾驶员速度和加速度特征对比Fig.2 Comparison of driver speed and acceleration characteristics under different traffic characteristics
如图3所示,加速度分布也因交通运行条件的不同而存在差异。在快速路条件下,平均速度区间20 km·h-1的加速度分布比50 km·h-1区间更为分散,而相同速度区间下,非快速路的加速度分布比快速路路上的加速度分布更为分散。
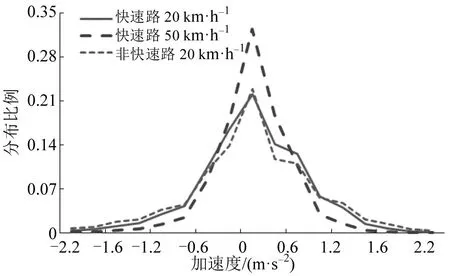
图3 不同交通条件下驾驶员加速度分布对比Fig.3 Comparison of acceleration distribution under different traffic conditions
3 改进的驾驶员特征聚类方法
本节提出一个改进的考虑交通运行条件影响的驾驶员特征聚类方法。整个聚类方法包括轨迹片段归类和高斯混合模型聚类两个步骤。
González 等[11]利用轨迹数据证明了利用速度和加速度变化检测危险驾驶行为的可行性,并认为基于真实驾驶行为数据的驾驶员分析是最客观的。Ma等[12]则对驾驶员激进性评估算法进行了比较研究,指出高斯混合模型(Gaussian Mixture Model,GMM)对激进行为的特征参数具有更强的鲁棒性。考虑上述因素,本文提出的驾驶员特征聚类方法如图4所示,主要流程包括:首先对轨迹数据进行切片和分类处理,随后提取稳定的易获取的驾驶行为特征参数;基于高斯混合模型聚类获取驾驶员特征标签。
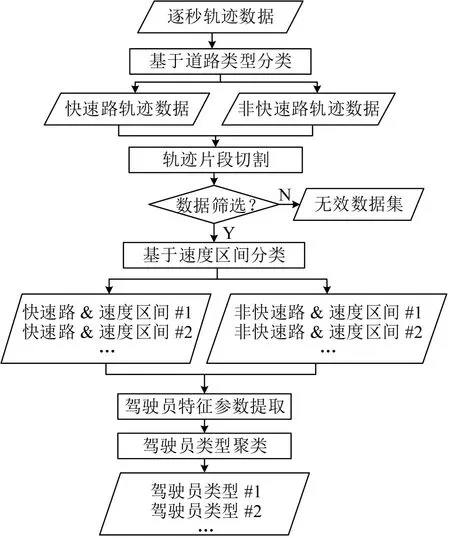
图4 考虑交通特征差异的驾驶员特征聚类方法Fig.4 Improved driver clustering framework
Step 1 机动车轨迹片段归类与参数提取。
将机动车轨迹数据按道路类型分为快速路和非快速路两个数据集,再以30 s的时间长度对连续轨迹进行切片处理。依据轨迹片段的平均速度对其进行分类,由此得到带有道路类型和平均速度区间标签的轨迹片段数据池,作为驾驶员特征聚类的基础数据。最后提取驾驶员在不同交通运行条件下的驾驶行为基本特征参数,包括:速度变异系数(Speed Variation Coefficient,SVC),加速度标准差(Acceleration Standard Deviation,ASD),减速度均值(m⋅s-2,Deceleration Mean,DM)。
驾驶行为特征参数既要能反映驾驶员特征与交通运行条件之间的关联性[13],也要易于获取,能够从不同数据来源中获得,以提升聚类方法的适用性。速度变异系数能在反映驾驶行为中速度波动水平的同时剔除速度量纲的影响,加速度标准差体现了驾驶员的加减速波动性,而减速度均值则能够体现车辆减速的强度水平。相比于加速度,减速度更能体现驾驶员自身特征,降低车辆性能的约束。最后,对于每个驾驶员,总共有3 类特征参数(速度变异系数、加速度标准差和减速度均值)乘2个道路类型(快速路和非快速路)再乘5 个平均速度区间(vˉ=10、20、30、40和50),共计30 个特征值输入到聚类模型中。
Step 2 基于典型特征参数的高斯混合模型聚类。
将上述典型交通运行条件下的驾驶行为特征参数作为输入,采用无监督机器学习的高斯混合模型对驾驶员类型进行聚类。
本文选择高斯混合模型进行驾驶员特征聚类。高斯混合模型是一种具有无监督学习特性的聚类方法,其优势是可以用概率形式表示事物的非线性或随机性特征。高斯混合模型P(x)通过多维高斯模型概率分布的混合表示可以拟合出任意形状的数据分布,即
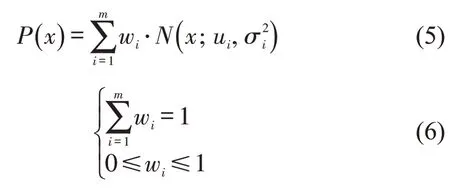
式中:m为模型中基本高斯分布函数的个数;wi为第i个高斯分布的混合系数;ui为第i个高斯分布的均值;σi为第i个高斯分布的标准差。
上述聚类框架具有两个优势:一方面,驾驶员的轨迹片段分类能有效降低交通运行条件对驾驶员驾驶行为特征的不确定性干扰,使得利用实际交通运行状态下机动车轨迹数据的驾驶员特征研究具有更好的可比性(在不同驾驶员之间)和更为稳定的稳定性(针对同一驾驶员);另一方面,高斯混合模型是一种基于无监督学习的机器学习方法,高斯混合模型对于聚类边缘并没有严格的硬空间约束,更符合驾驶员驾驶行为的随机性特点。
4 案例聚类与分析
利用改进的聚类方法对315 名驾驶员数据进行聚类,讨论分析是否考虑交通运行条件影响对驾驶员聚类效果的影响。
4.1 驾驶员聚类特征分析
在案例中,驾驶员聚类结果被分为激进、普通和保守这3 类,其占比分别为37.5%、45.7%和16.8%。聚类完成后的驾驶员驾驶行为特征参数统计如图5所示,不同类型驾驶员的驾驶行为特征均值在不同的交通运行条件下显著不同。在相同的道路类型和平均速度条件下,驾驶员类型越激进,其平均的速度变异系数、加速度标准差和减速度均值均更大。这些参数均表明,驾驶行为激进性与其聚类标签具有一致性。
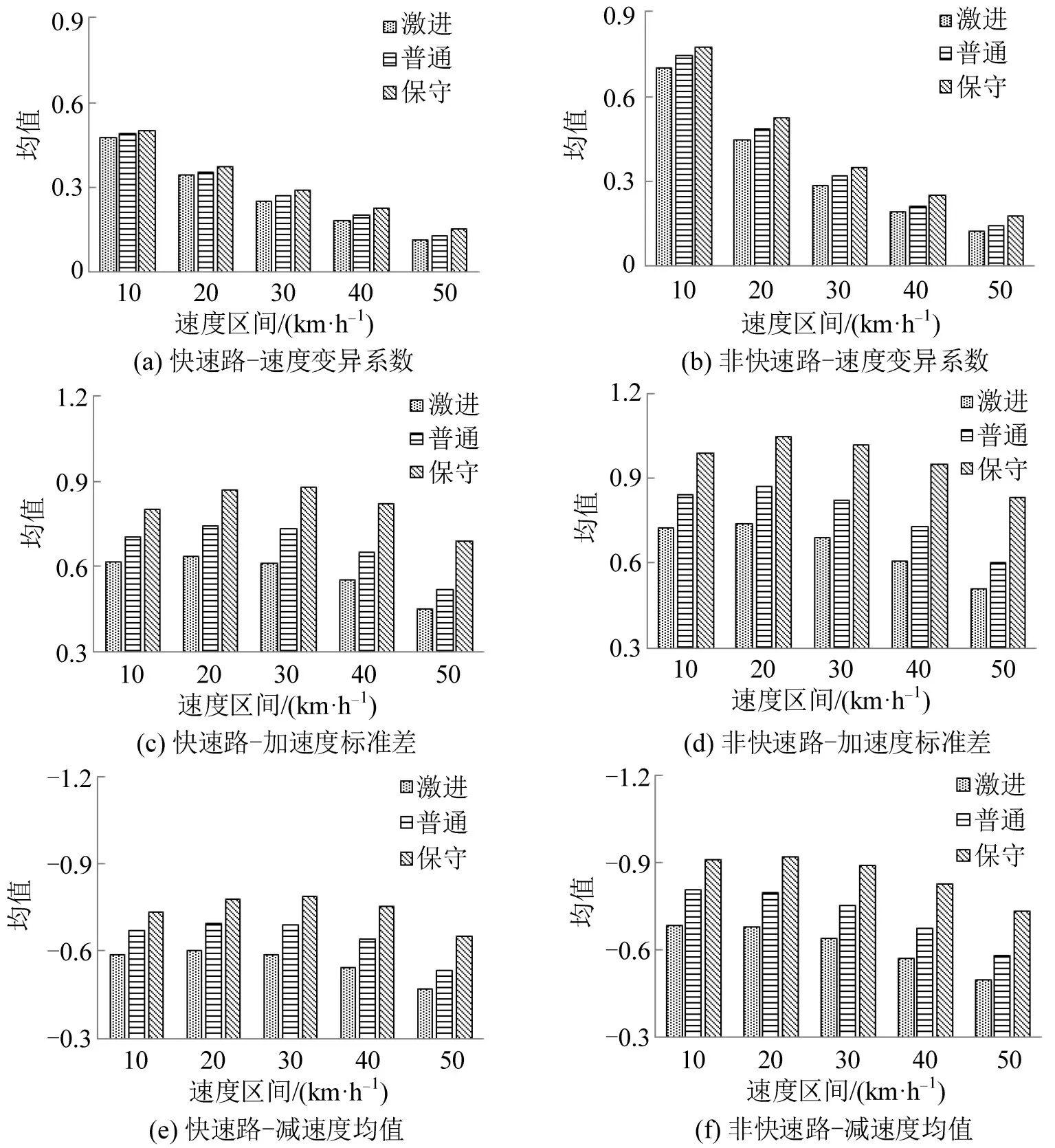
图5 不同类型驾驶员特征参数的对比Fig.5 Comparison of driving-behavior parameter means of different types of drivers
4.2 驾驶员聚类结果对比
为进一步分析改进方法的聚类结果,将前文案例结果与原方法所获得的驾驶员聚类结果进行对比。此处将原聚类方法定义为不考虑交通运行条件影响而直接计算驾驶行为参数进行驾驶员聚类的方法。也就是说两种聚类方法除了是否考虑交通运行条件影响计算输入参数外,样本数据、特征指标与高斯混合聚类模型均保持一致。
两种方法聚类得到的驾驶员类型比例如表2所示。可以看到,只有52.7%的驾驶员被两种方法归为同一类型,而47.3%的驾驶员被归为不同类型。是否考虑交通运行条件会显著影响驾驶员聚类结果。在考虑交通运行条件影响后,保守型驾驶员的比例从9.5%变为37.5%,而约一半(7.0%/15.9%)原来归类为激进型的驾驶员被重新归类为普通型,更有约一半(7.9%/16.8%)在改进方法中归类为激进型的驾驶员在一般方法中被归类为普通型。这些现象表明,是否考虑交通运行条件(道路类型和平均速度)的影响会对驾驶员聚类结果产生显著影响。
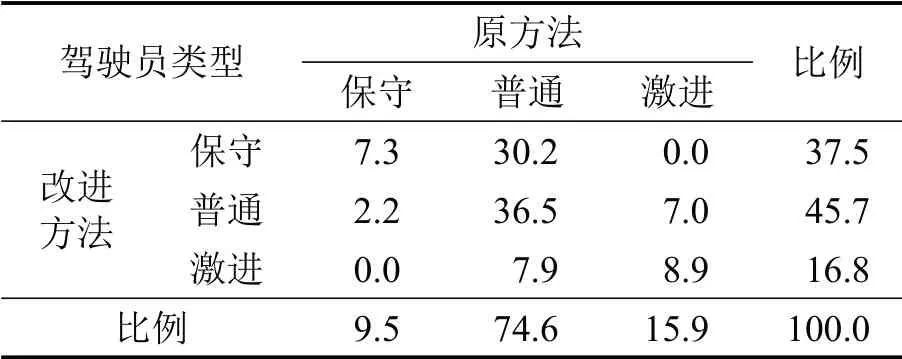
表2 两种方法的驾驶员聚类结果对比Table 2 Comparison of results of different driver clustering methods (%)
由于本文进行的驾驶员特征聚类是一种无监督聚类,驾驶员在聚类前没有确定的驾驶员类型标签,因此难以直接验证改进聚类模型的准确性。作为补充,本文选取Davies Bouldin Index(DBI)和Calinski-Harabaz Index(CHI)两个指标进一步分析两种方法的聚类效果。DBI表示分类适确性,为任意两类别的类内样本到类中心平均距离之和与两类中心点间的距离比。类内距离越小,类间距离越大,DBI 指数会越小。CHI 则定义为组间离散度与组内离散度的比值,CHI 越大表明聚类效果越好。计算公式分别为
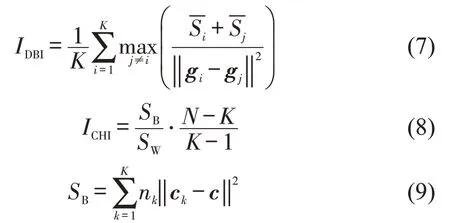
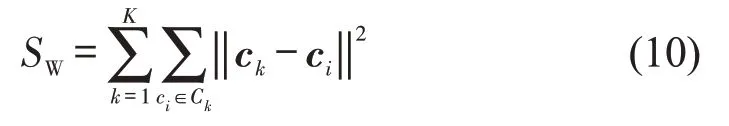
式中:K为聚类的类别数;gi为第i个类别的中心,为类别i中所有点到中心的平均距离;SB为组间分离度;SW为组内紧密度;nk为第k个类别中的样本数;ck为第k个类别的中心;c为样本集合的中心;Ck为第k个类别的样本集;ci为Ck中的第i样本。
由上述两种方法得到的聚类结果计算得到评价指标,对比结果如表3所示。改进聚类方法的两个指标都优于原方法的聚类结果,改进方法的驾驶员聚类结果在类内聚合和类间分离方面都有较好的表现。
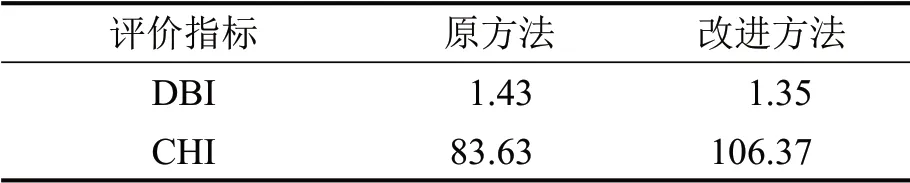
表3 两种方法的驾驶员聚类结果评价Table 3 Evaluation on results of different driver clustering methods
5 结论
本文基于车辆运行轨迹数据分析了交通运行条件对驾驶行为的不确定性影响,并提出一种改进的驾驶员聚类方法,以适应不同交通条件下驾驶行为的变化特性。主要结论如下:
(1)轨迹分析表明不同交通运行条件下的驾驶行为可变性是显著的,在较高的平均速度区间和高等级道路上驾驶行为表现更稳定。驾驶员特征聚类需要考虑降低交通运行条件变化对聚类结果可靠性的不利影响。
(2)为提高聚类模型的适用性和可靠性,提出一种改进的驾驶员聚类方法。通过建立考虑道路类型和平均速度条件的车辆运行轨迹切片和分类方法,提高了驾驶行为特征参数可靠性与可对比性。并通过高斯混合模型建立驾驶员特征的无监督聚类模型。
(3)聚类案例分析表明,改进模型在类内聚集和类间分离方面表现更好。就每种驾驶员类型而言,改进模型与原始模型的聚类结果存在显著差异,表明忽略交通运行条件会产生不可靠的驾驶员聚类结果。
猜你喜欢
中学生数理化·八年级物理人教版(2022年9期)2022-10-24 07:03:56
中国特种设备安全(2021年5期)2021-11-06 05:09:00
装备制造技术(2021年4期)2021-08-05 07:39:54
中学生数理化·八年级物理人教版(2020年9期)2020-11-16 01:17:58
中学生数理化·八年级物理人教版(2019年9期)2019-11-25 07:33:04
上海公路(2019年1期)2019-06-18 11:05:06
制造技术与机床(2017年11期)2017-12-18 06:46:39
武汉理工大学学报(交通科学与工程版)(2015年5期)2015-12-05 02:19:37
电测与仪表(2015年7期)2015-04-09 11:40:04
发明与创新(2015年26期)2015-02-27 10:39:31
