
咽拭子采集机器人表情识别与交互
2022-04-21 05:16郭馨蔚刘伟锋孙富春张津丽张国平
计算机工程与应用 2022年8期
郭馨蔚,马 楠,刘伟锋,孙富春,张津丽,陈 洋,张国平
1.北京科技大学 机械工程学院,北京 100083
2.北京工业大学 信息学部,北京 100124
3.北京联合大学 北京市信息服务工程重点实验室,北京 100101
4.清华大学 计算机科学与技术系,北京 100084
当前,全球新冠肺炎疫情呈现扩散蔓延态势,国内疫情防控工作控制良好,其中核酸检测工作呈现常态化,且需求量较大。常态化疫情防控工作要求下,咽拭子采集机器人发挥了重要作用。团队设计研制的咽拭子采集机器人系统主要由采样系统、头部固定托架模块、咽拭子装卸模块和机器人箱体模块构成。其中,咽拭子采集机器人系统采集到摄像头获取的受试者面部图像,通过识别算法,计算出咽后壁采集位置的空间位置坐标,实现采集过程中受试者口腔内部的视觉导航定位,并且能够在采集过程中动态地捕捉受试者的位姿变化,及时调整采集部位与末端采集轨迹,实现高效采样;视触融合算法通过读取压力传感器采集的触觉力序列,控制运动模块实现力位混合的采样力反馈柔性控制,降低采样过程中受试者口腔组织结构的创伤风险;通过采样机构模块中固定咽拭子端舵机的控制,可实现拟人的咽拭子采集咽后壁擦拭动作。采样机构按照上述视觉导航与视触融合方法完成采集流程。咽拭子采集机器人系统可以对受试者进行高效采样,但是缺乏对受试者采集过程中面部表情的感知,导致无法知道受试者在采集过程中是否舒适,因此本文在原有咽拭子采集机器人系统上增加表情识别模块,通过摄像头获取受试者在采集过程中的表情状态信息,并使用表情识别算法分析表情状态,最后通过建立通信把表情识别结果发送给咽拭子采集机器人控制模块[1],控制模块根据表情识别的交互反馈结果做出决策,从而提高受试者的舒适度。
面部表情识别(facial expression recognition,FER)一般划分为两大类。一类是面部动作编码系统(facial action coding system,FACS)中定义的44个面部动作,FACS提供的是一个通用的参考点[2-4],这些动作的组合形成了一套完整的面部表情和具有相似面部外观的面部表情;另一类被划分为6种基本情感情绪表情:愤怒(anger)、高兴(happiness)、悲伤(sadness)、惊讶(surprise)、厌恶(disgust)、恐惧(fear)[5],1个中性表述(normal),共7种。FACS可以描述任何视觉上可识别的动作表情,因此只有部分应用在面部表情中。同时,由于这6种情感情绪表现,不一定会全部在本文的应用场景下体现。咽拭子采集机器人采集过程中,受试者的面部表情是一项重要的研究内容。基于上述的文献调研情况,本文根据现实场景采集过程中所传达出的信息,最终确定三种重要的表情分类类型:无感、较为不适、难受。通过表情识别这一重要表情标签的人机交互过程,交互传递到智能采样系统,可以提高采样工作的准确率、舒适度、适用性。
面部表情识别通常包括人脸的初始检测、相关人脸信息的提取和跟踪,以及面部表情分类[6]。在咽拭子采集机器人这一应用场景下,其执行流程可描述为:人脸检测,人脸校正,数据集抽帧,动态描述提取,表情识别。该表情识别交互任务则需重点解决遮挡去除及微表情识别的拓展[2,6]、表情分类及划定[3-4]、自采集数据集的定义[6-7]、关键帧识别及处理[8]、交互集成[9-10]等5方面问题。理想情况下,一个鲁棒的识别模型应该能够对大部分,或者至少是视觉上可识别的面部表情进行分类。因此,选取合适的评价指标和评价方式也是衡量识别任务完成度及模型适用性的关键步骤[11-12]。综上,咽拭子采集机器人FER系统应归纳为三个部分:表情数据预处理、特征提取和表情分类[2]。
FER数据预处理方面,遮挡去除及微表情拓展是预处理阶段的重点工作。现阶段FER领域所应用的最广泛的CK+、RAF-DB、JAFFE、MMI、Affect-Net及FERplus等公共数据集,往往体现出人口统计学差异[13],或为单个或为小型化[14],含噪声标签[15-16],非正面及非对称[17]等其他相关问题。本文应用场景有其特殊性,但这些问题也是自采集数据集所面临的重要问题,给数据集定义工作提供了方向和支撑。相关文献为数据集定义与处理提供了可参考方法,如最大池化降维[6]、数据增量[18]、数据生成考虑多角度最优[19]、邻域平滑性[11]等。针对本文自采集数据集,需通过保证受试者人口统计学分布均匀、保证数据样本量、保证采集环境稳定以及保证正面正对采集等相对理想条件,从而简化预处理过程。
FER特征提取方面,关键帧抽取及多类特征提取是该阶段的重点工作。针对不同类型的数据集和特征提取目的,相适应地采用局部子域法,即增加通道注意模块突出有效特征[2];掩膜法,即重建及域信息共享[20];融合特征提取,即从显著区提取LBP(local binary pattern)和HOG特征[21];稀疏表示,即提取纹理的特征(LBP、Gabor小波和LPQ)[22]等方法。而关键帧抽取及多类特征提取则关注的是本文应用场景下动态变化的特征:时间阶段的变化(开始-顶点-结束)和3种情绪强度的变化,这些变化的出现在不同的被采集者之间有很大差异,使识别分类任务非常具有挑战性。根据对自采集数据集的定义,需从每个视频中提取定义空间和时间特征的顶点帧或密集轨迹描述符HOF和MBH用于训练。针对一系列关键帧,需提取其多类特征,本文主要提取其时空特征、光流特征和运动单元特征这3类。
FER分类任务方面,20世纪90年代,图像处理即在人像处理、跟踪和识别领域的应用日益广泛。到2015年以来得益于深度学习方法的良好应用,FER领域发展迅速,表情分类方法逐渐地归结于几种主流的方法——卷积神经网络及其变体(convolutional neural networks,CNN)[6]、光流(optical flow)[8]以及局部二值模式(local binary pattern,LBP)[23]。在本文的应用场景下,动态描述比静态描述更适合识别任务的进行,可以将其与密集光流相结合给出时空描述符[8]或动态纹理[23]来识别面部表情。其他相关研究的关注点也往往聚焦在时空密集轨迹描述符、动态纹理表达适用于训练和识别,如大型通用高斯混合模型[24]和基于Expressionlet的中层模型[25]。现有的浅层特征提取模型丢失了大量有效的特征信息,识别精度较低。而基于深度学习的人脸表情识别方法也存在过拟合、梯度爆炸和参数量问题等。卷积神经网络骨干结构在人脸表情识别过程中具有一定的局限性,因此在算法层面,本文将其与人工特征提取方法相结合,这样改进网络结构目的是为了保证能够重构不确定性图像,从而提高分类结果的准确性。
1 相关工作
目前,根据表情识别在各个方面的一些研究[26],可将识别方法分为两类,一类是基于人工特征提取的方法,另一类是基于深度神经网络的方法。在人工特征提取方法中,本文主要研究了时空特征提取、光流特征提取和运动单元提取方法的应用;在深度神经网络方法中,主要研究了主流CNN框架下的变体方法及应用。本文在实际构建算法框架过程中,将人工提取方法与深度神经网络方法相结合,重点将表情图像时空特征提取,关键帧提取,基于LBP、光流和运动单元的特征提取加入到识别网络的构建。
1.1 基于人工特征提取的方法
在面部表情识别算法应用的早期,大多数方法都利用人工特征提取,常用的方法有两种。一种是基于外观的方法,特别是基于像素值的方法。在此,像素值属于面部表情的数量外观,其优点是信息损失较少,但通常以高特征维数为代价。另一种是基于几何的方法,它考虑的是特征区域的位移而不是像素点,其优点是特征维数低,计算量小,但是它对光照的变化更敏感。
1.1.1面部表情时空特征提取
基于外观方法的特征提取逐渐地以时空特征为主流,Zhao等人[23]提出了一种鲁棒的动态纹理描述符,这是从纹理域到时间域的一种拓展,用于三个正交平面的局部二值模式(local binary patterns from three planes,LBP-TOP),近些年来该纹理描述符已被广泛用于面部表情识别领域。该方法同时考虑了视频形式数据集的时间和空间信息,时空信息体现在3种类型的平面,分别为XY平面、XT平面和YT平面。以本文应用场景下的一个视频序列为例,可以将其分别看作沿T时间轴、Y空间轴和X空间轴的XY、XT和YT平面的堆栈。最后分别从该三种类型的平面导出3个直方图,并组合成一个直方图作为动态视频纹理描述符,如图1所示。由于其对光照变化和图像变换的鲁棒性,该方法得到了广泛的应用。
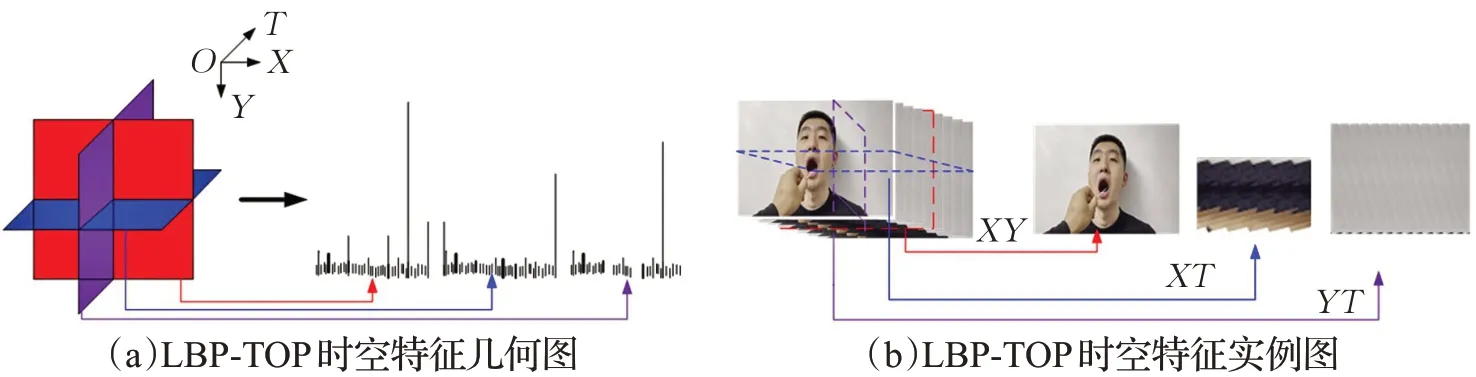
图1 LBP-TOP时空特征几何图与实例图Fig.1 LBP-TOP spatiotemporal feature geometry and instance graph
1.1.2面部表情光流特征提取
基于几何方法的特征提取发展到现在,光流(optical flow)法是这类方法的代表。光流与空间运动物体在观测图像平面内像素运动的瞬时速度有关,该方法做了两个假设:一是亮度恒定;二是随时间的变化不会引起位置的剧烈变化。所以该方法能有效地保留客观运动信息,无论提取宏表情特征还是提取微表情特征,光流法都能适用。因此该方法适合于本研究中的面部表情识别扩展到微表情的识别。因此该方法适合于本研究中的面部表情识别做到微表情的拓展。Perveen等人[24]利用动态核和稳健的光流方法,结合直方图定向光流(histogram of oriented optical flow,HOOF)特征来评估面部肌肉运动的方向。该方法采用神经网络对人脸特征点进行定位,减少了蒙面对人脸的干扰,并与光流相结合,在降低特征维数的同时提高了运动信息的利用率,所以将人工特征与神经网络相结合是合理的发展方向。同样地,以本文应用场景下的一个视频序列为例,通过光流法分割提取关键帧的操作如图2所示。
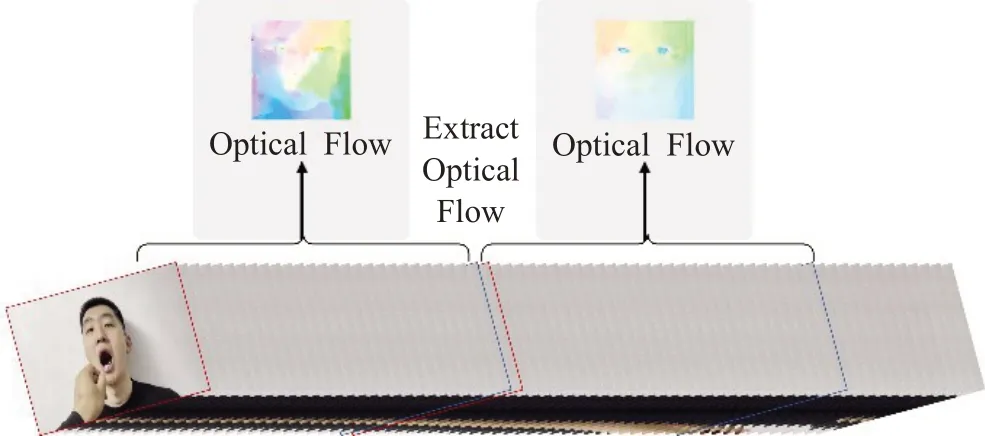
图2 基于光流的帧特征提取Fig.2 Frame feature extraction based on optical flow
帧特征提取过程中,特征提取部分所需的光学运动因素与情感因素感兴趣区域均通过光流变化来反映。在此,实验要求自采集数据集环境稳定;其次是时间的变化不会引起位置的剧烈变化。这样才能利用相邻帧之间位置变化引起的灰度值变化来进行光流特征提取。结合提取过程可知,光流是利用帧序列中像素在时间域上的变化以及在相邻帧之间的相关性来找到帧间对应关系的,通过帧间对应关系计算出帧间物体的运动信息。此外,进行咽拭子采集所得到的部分表情数据和宏表情存在区别,考虑到其瞬时性、细微化特点,利用光流法进行特征提取有较大优势。同时,在检测到面部微表情的运动信息后,将光流法和LBP方法结合也可以进行有效的识别。实验中光流提取效果如图3所示,可见其感兴趣区域从选取点到目标区域的迁移。

图3 光流主要特征区域识别及提取Fig.3 Recognition and extraction of main feature areas of optical flow
1.1.3面部表情运动单元特征提取
除上述两种特征提取方法外,本文还通过识别面部肌肉动作(action units,AUs)来适应面部表情的不确定性权重问题。面部动作是经专人利用专业知识标记编码面部动作单元所得的解剖学标签[27-28],本文利用到其中的16个标签,如表1所述。She等人[29]利用了数据的潜在分布和成对不确定估计方法,进行人脸识别;Chen等人[30]提出了一种基于AUs校准的面部表情识别方法,该方法利用面部动作单元(AUs)的识别结果来纠正数据集中的性别标注偏差,根据AU的识别结果构建三元组并合并到目标函数中,有效地消除了表情注释偏差问题。在本文的应用场景下,这种局部肌肉运动信息强度相较微表情来看,强度大且数量较多。因此,其组合具有更好的非线性表征能力,应用于相对宏观情绪表达较为适用。通过AUs及其对应光流分割提取特征的网络结构如图4所示。光流特征在此可以作为运动单元的一个参照,即通过光流图可以很直观地分辨出运动部位。卷积层从光流中提取特征向量,在特征向量的顶部和底部分别应用两个平均池,得到降维的特征向量,然后对每个特征向量使用两层全连接分类器,舍弃底部只保留顶部。
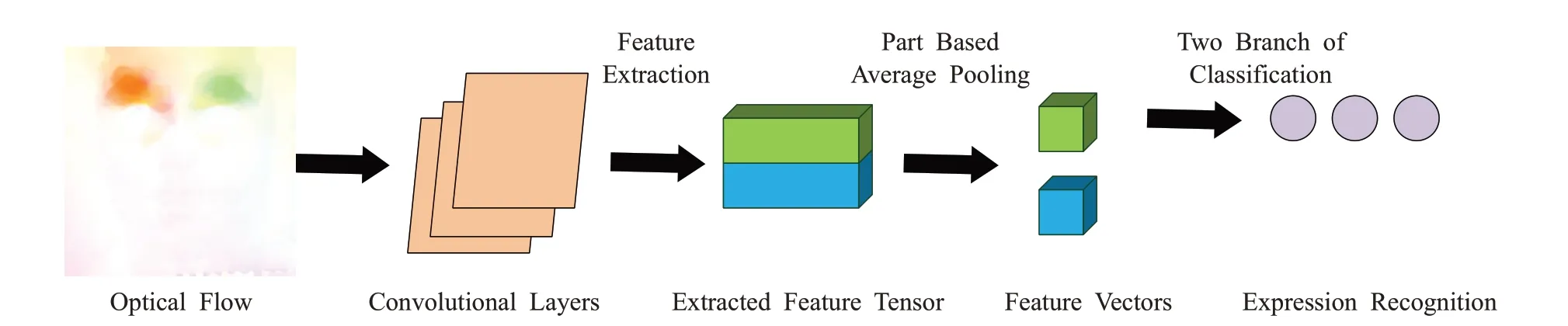
图4 AUs及其对应光流分割提取特征的网络结构Fig.4 AUs and its corresponding optical flow segmentation and extraction feature network structure
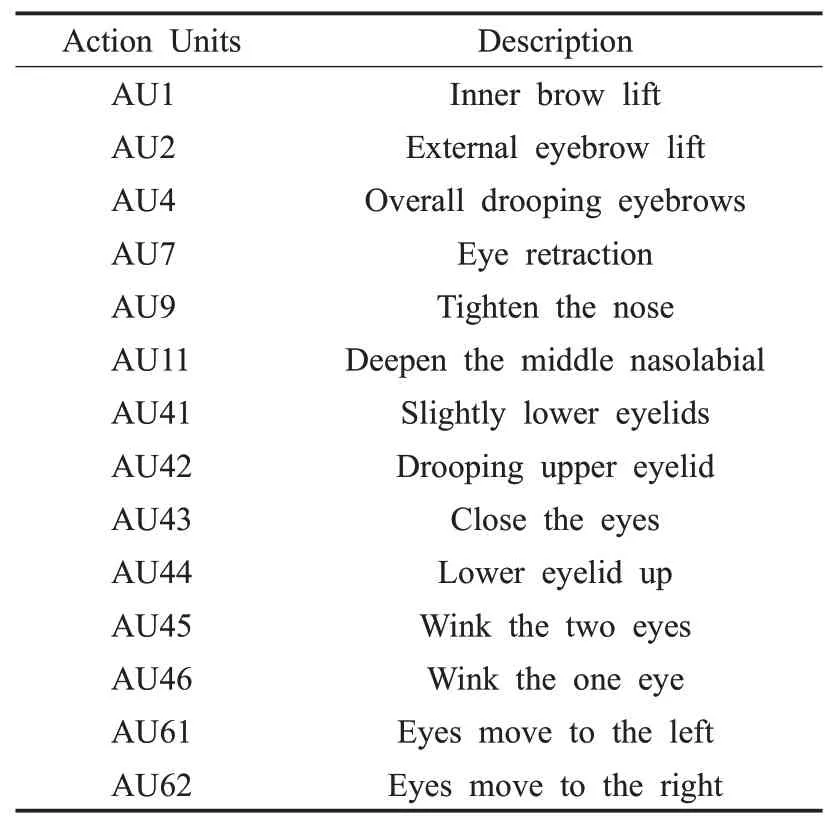
表1 主要运动单元编码Table 1 Major action units coding
1.2 基于深度神经网络的方法
随着卷积神经网络(convolutional neural network,CNN)在图像识别领域的广泛应用,其性能不断提升,很多学者把CNN用于表情识别领域,并通过不断地调整其结构可以更有效地提取人的面部表情[30]。Li等人[31]提出了一种具有注意力机制的卷积神经网络(attention convolutional neural network,ACNN),它可以感知人脸的遮挡区域和未遮挡区域。ACNN是一个端到端的学习框架,结合了来自面部感兴趣区域(ROI)的多个表示,每个表示通过一个设计的单元模块进行加权,该单元模块根据重要性从该区域本身计算自适应权重,从而提高了对非遮挡人脸和遮挡人脸的识别精度。Sajjanhar等人[32]提出了一个基于VGG卷积神经网络的面部表情识别算法,有效地提取了面部表情,并且提高了表情识别的效率。Zhang等人[33]提出了一种相对不确定性表情学习方法,该方法将表情的不确定性看做是一个相对的概念,没有为所有数据集假设高斯不确定性分布,而是建立了一个额外的分支,通过特征混合从样本的相对难度中学习不确定性,同时使用不确定性作为权重来混合面部特征并设计一个加法损失来促进不确定性学习,解决了模糊的面部表情和不一致的标签对识别结果的影响。She等人[29]提出了一种潜在标签挖掘和样本间不确定性估计方法,该方法主要解决了标签模糊问题。对于潜在的标签挖掘,引入一个辅助的多分支学习框架,以更好地挖掘和描述标签空间中的潜在分布;对于样本间的不确定性估计,充分利用实例之间语义特征的成对关系来估计实例空间中的歧义程度。同时,所提方法独立于主干架构,不会增加计算量。
为了识别具有不确定性的面部表情特征,Wang等人[34]提出了一个简单而有效的自修复网络(self-cured network,SCN)。它建立在传统CNN的基础上,由自注意重要性加权、秩正则化和重标签这三个关键模块组成。在给定一批具有不确定表情样本的人脸图像的基础上,首先通过骨干网提取深度特征,然后自注意重要性加权模块使用全连接层和sigmoid函数为每个图像分配一个重要性权重,这些权重乘以样本重加权方案的对数。为了显著降低不确定样本的重要性,进一步引入秩正则化模块对权值进行正则化。在秩正则化模块中,首先对学习到的权值进行排序,然后将其分为高重要性组和低重要性组。最后,再通过一种基于边际的损失(rank regularization loss,RR-Loss),在这些组的平均权值之间添加一个约束。为了进一步完善所提出的SCN,Wang等人还加入了重标签模块,对低重要性组中的一些不确定样本进行修改。这个重标签操作的目的是寻找更多的干净样本,然后增强最终的模型。整个SCN网络以端到端方式进行训练,并能容易地添加到常用CNN主干中。
2 咽拭子机器人表情识别与交互的ESCN模型
为了实现咽拭子机器人对受试者面部表情的识别与交互,本文提出了有效自修复网络模型(efficient self-cured network,ESCN)。该模型主要包含三部分:用于接收人脸表情图片视频帧,生成类识别能力的特征提取加权网络(feature extraction weighted network,FEWN)、捕捉面部表情区域并加权的多尺度注意力机制特征融合网络(multi-scale attention mechanism feature fusion blocks,MAFN)和通过重标签校正的线性聚合分类网络(division and linear aggregation output,DLAN),其框架如图5所示。
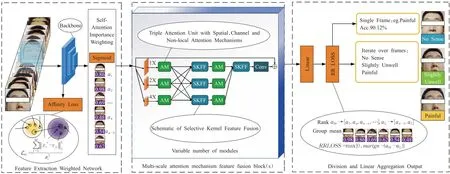
图5 ESCN网络框架结构图Fig.5 ESCN network frame structure diagram
2.1 特征提取加权网络
作为一个图像分类算法框架,同时也作为很经典的一些神经网络的分类算法的变体,结构中骨干网络来自于Resnet18和LResnet,其创新之处在于这个框架会在图像进入网络之前对该图像和标签的权重做预处理,即判断哪些图像可以具有高权重。其中部分图像的标签存在错误,在此便做了一个分类并进行加权。该方法非常适合咽拭子采集表情识别交互这个任务的训练。因为在本文这个任务的训练过程中,部分标签可能并不能很好地表示被采集者的表情,如有时被采集者无表情的时候,就标注了痛苦。此时就需要降低该标签权重,则忽略或以低权重进入第二部分结构。
2.1.1特征预处理
进入特征聚类网络模块的图像数据是经过数据预处理之后的关键帧序列。这一部分将面部表情关键帧规定在440×370像素,面部范围设定为额头至嘴唇上部区域。再通过抽帧分割提取情绪表达帧,其情感表达显著特征区域如图6所示,图中各子图每上下对应两张为一组,表示一名受试者的特征预处理后表情图像,故可由这些进入骨干网络的显著特征区域来确定运动单元进行LBP、光流及AUs特征提取。

图6 特征预处理后表情图像Fig.6 Expression images after feature preprocessin
特征预处理过程中,需要利用到图像掩膜[20]。通过图像掩模矩阵,可以重新计算图像中的每一个像素值,因此掩模矩阵控制了原始图像当前位置以及周围位置像素对新图像当前位置像素值的影响力度。具体为在处理公共数据集和自采集数据集时,将数据集中图像的面部表情额头以下到唇上区域,认定为光学运动因素与情感因素感兴趣区域,对唇下区域进行掩模操作。其处理方式有两种:一是将唇上区域视为1值区域保留计算,将唇下区域视为0值区域屏蔽舍弃,这样的目的是完全舍弃唇下区域;二是0值区域也可以利用OpenCV通过指定的数据值、数据范围、有限或无限值和注释文件来定义图像掩模矩阵,也可以应用任意组合作为输入来建立掩模矩阵,这样操作的好处是能保留部分可以作为分类依据的特征。
2.1.2自注意重要性加权(self-attention importance weighting)
在图像进入网络时,会出现并不具备明确特征的样本,样本却在训练时被赋予了明确的标签,降低了网络的泛化能力。为了缓解这个问题,本文在骨干网络中引入自注意重要性加权模块来捕获面部表情特征,其特点和优势在于可以对输入的图像进行重标签,应用于本文场景中的表情三分类任务中,从而保证机械臂获得正确的交互决策依据。不防假设F=[x1,x2,…,x N]∈RD×N表示N张图象中的面部表情特征,自注意重要性权重将F作为输入,输出每个特征的重要性权重值。具体来说,自注意重要性加权模块由线性全连接(FC)层和sigmoid激活函数组成,可以表示为:

其中,αi是第i个样本的重要性权值,W a是用于注意的FC层的参数,σ是sigmoid函数。有了自注意权重,执行损失权重的模块为对数加权交叉熵损失,其可表示为:
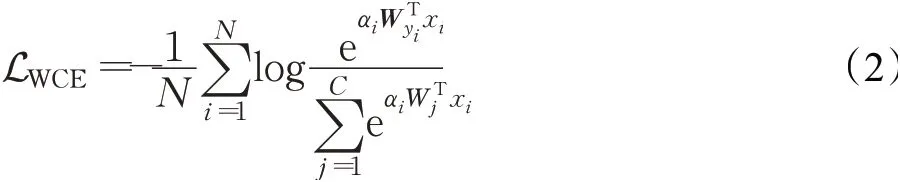
其中,Wj是第j分类器,LWCE与α呈正相关。
2.1.3亲和力损失(affinity LOSS)
咽拭子受试过程中受试者的表情反馈是连续的、渐变的,在一段视频中许多过渡图像帧可能会被判别为另一种表情。因此,本文期望网络能够重新考虑连续情感表达在分类时的敏感性,从而引入亲和力损失函数来考虑表情特征潜在相似性,其本质就是利用亲和力损失函数来扩大类边际,保证良好的可分性。具体描述为:在每一次训练中,促使特征更加接近所属类中心,同时促使不同类中心更好地分离开来。如给定类中心c∈Rm×d,从d维高斯分布中做随机抽样,然后利用如下函数(3)来最大化类间距且最小化类内间距:

其中,M是Y的维数,d是类中心的维数,σc表示类中心之间的标准偏差。
2.2 多尺度注意力机制特征融合网络
2.2.1三重注意力机制单元(triple attention mechanism unit)
对于第二部分结构多尺度注意力机制特征融合网络的整体理解,应从经第一结构所得出的1×1卷积、2×2卷积、4×4卷积深度的特征图开始,三者独立进入三重注意力机制单元,如图7所示。其中空间注意力单元接受输入并提取空间特征,通道注意力单元接受输入并提取通道特征,Non-Local接受输入并提取局部特征。上述三个维度的特征最终被计算合成一张注意力图,然后交叉进入特征融合模块(SKFF)。
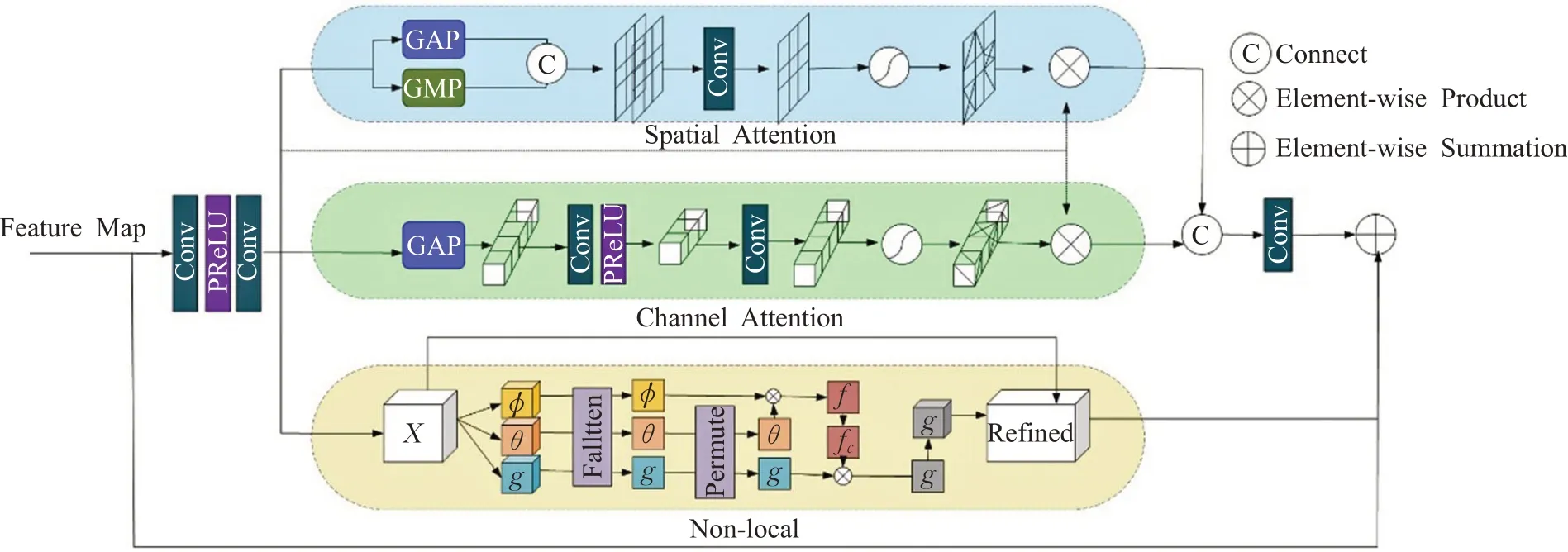
图7 包含空间、通道和Non-local注意机制的三重注意单元Fig.7 Triple attention unit with spatial,channel and non-local attention mechanisms
2.2.2选择性核特征融合(selective kernel feature fusion)
对于特征融合模块的整体理解应从并行交叉进入的注意力图开始,如图8所示,这一结构通过两个操作符来动态调整所接收的信息。融合操作符(Fuse)通过组合来自多分辨率流的信息生成全局特征描述符。选择(Select)操作符使用这些描述符重新校准不同数据流聚合后的特性映射,然后为三个(或多个)数据流提供两个操作符的详细描述。SKFF模块接收来自三个(或多个)并行卷积流的输入,携带不同规模的信息。首先,将这些多尺度特征结合起来,使用一个元素求和,L=L1+L2+L3。然后,在空间维度上应用全局平均池化GAP(global average pooling)跨越空间维度L∈RH×W×C来计算的通道统计量s∈R1×1×C。接下来,应用一个通道降尺度卷积层来生成一个紧凑的特征表示z∈R1×1×r。最后,特征向量z通过三个并行的通道扩大卷积层(每个分辨率流一个),并提供三个特征描述符v1、v2和v3,每个维度1×1×C。选择操作符将softmax函数应用于v1、v2和v3,产生注意激活s1、s2和s3,使用它们分别自适应地重新校准多尺度特征图L1、L2和L3。特征重新校准和聚合的整体过程定义为:
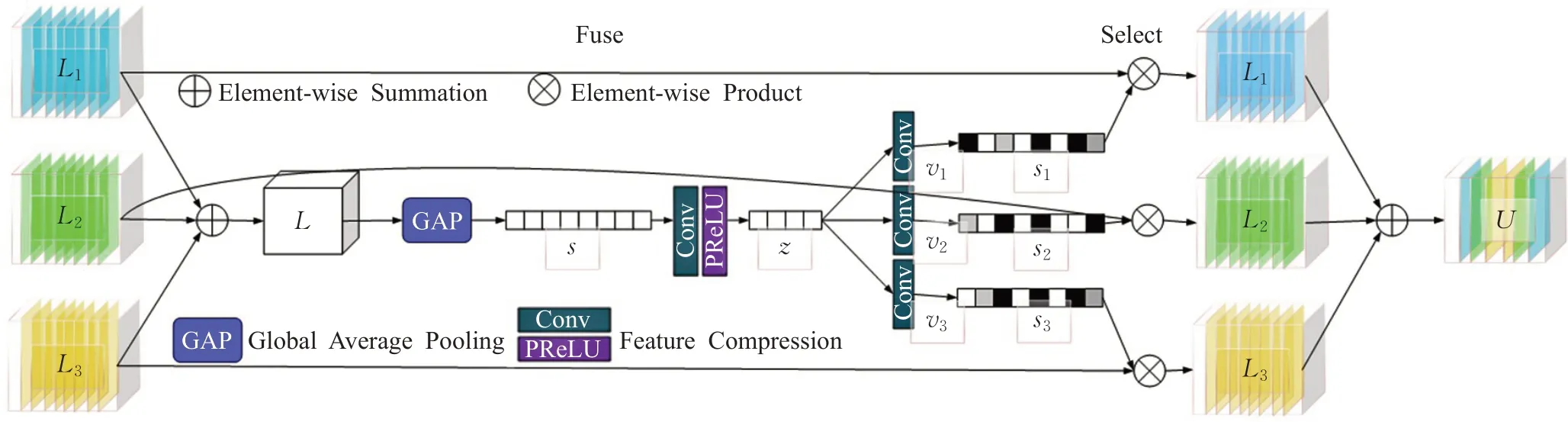
图8 选择性特征融合(SKFF)示意图Fig.8 Schematic of selective kernel feature fusion(SKFF)

在此明确SKFF使用的是~6×这一参数,而不是级联聚合,参数小且聚合效果较好,其结构如图8所示。
经重新校准并聚合后的特征图再分别进入一次三重注意力机制单元得出注意力图,然后再进行一次特征校准并聚合,卷积所得注意力图进行下一步分类计算。
2.3 线性聚合分类网络
进入第三部分结构的注意力图携带了充足的特征,然后对其进行线性层类置信度的计算,即可做单步和多步输出。输出结果在建立通信的基础上同时将这一决策依据反馈给机械臂,以进行柔性力度反馈交互。上文中提到的自注意重要性模块的权值在(0,1)中可以是任意的。考虑到输出分类的结果被用作机械臂的决策依据时,同一表情类别中不同程度的表情图像应该具有不同的权重,因此本文为明确约束此类样本的重要性,在该模块中引入秩正则化模块来处理权值。在秩正则化模块中,先将学习到的注意权值降序排列,然后以β的比例将其分成两组。秩正则化保证了高重要性组的平均自注意权值高于有边界的低重要性组的平均自注意权值。对此,Wang等人[34]为此定义了秩正则化损失(RR-Loss),可以表示为:
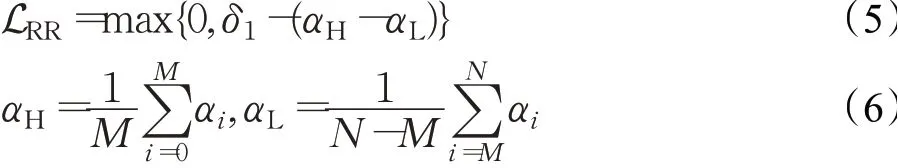
其中,δ1是一个边界,它可以是一个固定的超参数或者一个可学习的参数,αH和αL分别代表高重要性组β×N=M和低重要性组N-M的平均值。在模型训练中,总损失函数Lall=γLRR+(1-γ)LWCE中的γ是一个权衡比。
2.4 表情识别交互
咽拭子机器人表情识别系统通过摄像头获取新冠肺炎核酸检测者的面部表情视频片段,然后把检测者的视频片段输入到表情识别算法机器进行预测并得出结果。咽拭子采集机器人应用表情识别算法的结果实现交互反馈,采用TCP/IP通信协议,使二者建立Socket通信通道进行通讯;在通讯时表情识别算法机器作为发送端,咽拭子机器人作为接收端,只要发送端获得表情识别结果,就会发送给接收端,接收端收到表情识别结果后分析并做出交互决策反馈,最终咽拭子机器人完成一个舒适度动作调整反馈。其交互过程如图9所示:(1)表情识别算法通过摄像头检测并获取被采集者表情;(2)与机器人建立Socket通信通道,完成TCP连接;(3)发送端发送表情识别结果;(4)接收端接收表情识别结果并做出动作反馈,进而完成感知交互过程。
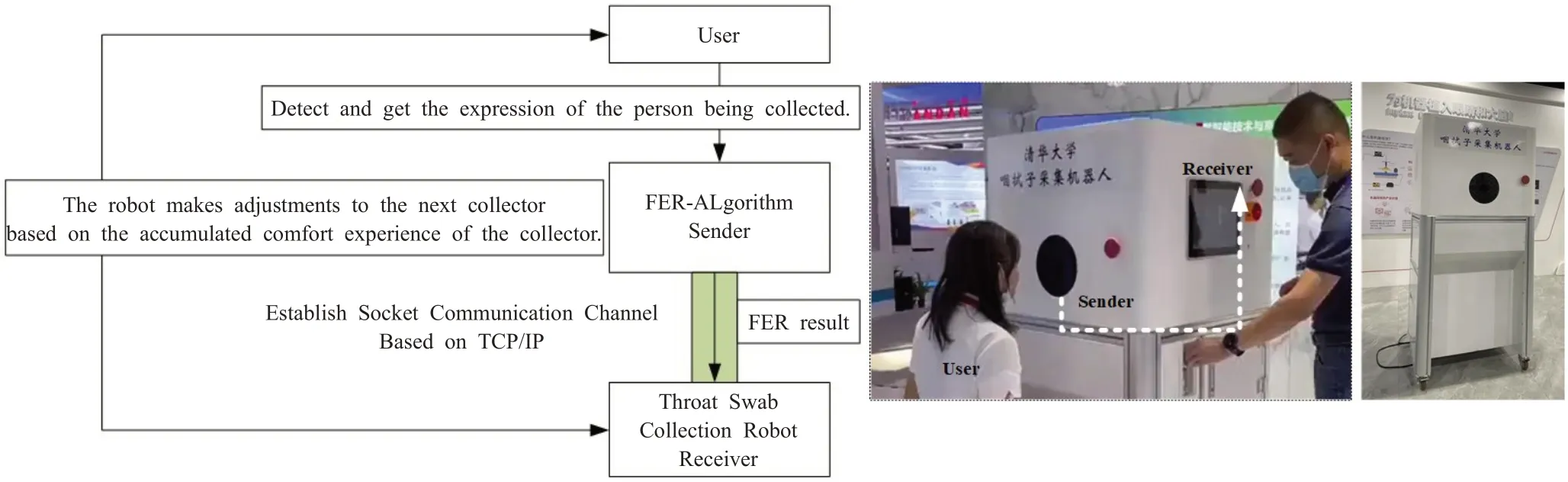
图9 咽拭子采集机器人感知交互过程Fig.9 Throat swab collection robot perception interaction process
3 数据集与实验结果分析
3.1 公共数据集描述
本文的实验采用了RAF-DB[15]和FER-2013[16]这两个公共数据集。为了更好地适应于本文的3分类场景,并执行一个统一的评价指标,这两个公共数据集分类标签适当地调整为三类,即中性、消极、恐惧。
RAF-DB:包含了将近3万张使用基本或复合表情标注的面部图像。在本文实验中,使用6种基本表情的重新归类划分及标注(消极、恐惧)和中性表情的图像,因此有5 000张图像用于训练,2 000张图像用于测试。因数据集本身即是图片类型数据集,所以无需长视频序列帧提取。
FER2013:数据集由35 886张人脸表情图片组成,其中,测试图(Training)28 708张,公共验证图(PublicTest)和私有验证图(PrivateTest)各3 589张,每张图片是由大小固定为48×48的灰度图像组成,共有7种表情,分别对应于数字标签0~6,具体表情对应的标签和中英文如下:0-anger生气;1-disgust厌恶;2-fear恐惧;3-happ开心;4-sad伤心;5-surprised惊讶;6-normal中性。但是,数据集并没有直接给出图片,而是将表情、图片数据保存到csv文件中,因此在实验中需要对其进行重构,尤其是在三分类划分、标注及重构方面。因此同样选取5 000张图像用于训练,2 000张图像用于测试。
3.2 自采集数据集描述
自采集数据集通过结合实验应用场景自定义并采集,其名称为咽拭子采集机器人面部表情识别数据集(pharyngeal swab collection robot facial expression recognition dataset,PSCR-FER)。本研究考虑到咽拭子受试者的面部表情变化的细微性和瞬时性,单张图片无法正确、全面地反映人的表情所表达的情绪。因此,本研究的数据自采集过程中选择采集视频瞬间,通过对长视频序列进行帧分割提取进行识别。样本人群数量为300,考虑年龄分布与性别分布,数据集为视频格式,表情分布具体为三种,即无感、较为不适、难受。对每一个被采集者进行三种柔性力度的自然状态咽拭子采集,即柔和、较为柔和、力度较大这三种,以得到每一位被采集者的三种表情分布反馈。针对每一个长视频序列,可按照不通的帧间差提取关键帧,并作随机划分,得到包含3 672张关键帧在内的训练集和包含1 946张关键帧在内的测试集,均包含三种情绪表达的人脸图片。实验中保证每一种情绪表达在单个长视频帧序列中都至少有50帧表情面部图像,也通过使用随机划分,将30帧人脸图像用于训练集,剩余的20帧人脸图像用于测试集。综上,实验所采用公共数据集和自采集数据集归纳如表2所示。
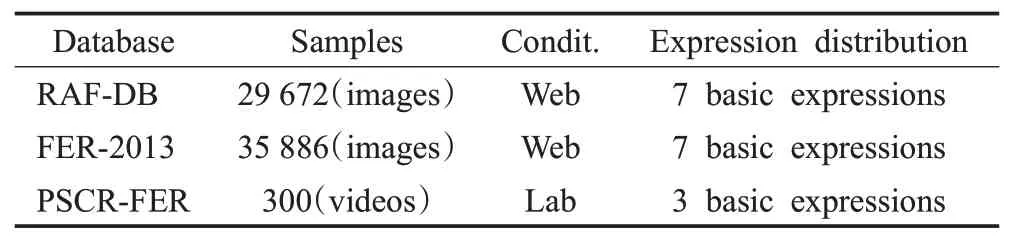
表2 本文所用表情识别数据集Table 2 Facial expression recognition dataset used in this paper
3.3 实验参照
当前在FER研究领域官方排行榜上公布的经实验复现并验证的数据,包含了在62篇文献中针对18个数据集准确率或平均准确率最靠前的18个基准测试。其中就包含本文所使用的RAF-DB和FER2013这两个数据集,分别公布有7种和9种最先进、识别效果最好的方法,见表3和表4。以ResNet为骨干网络的结构占较大比例,因此在对照实验中选取AlexNet、VGG、ResNet18作为参照方法,选取SCN方法作为本文方法的参照,用来对比分析本文方法的性能。
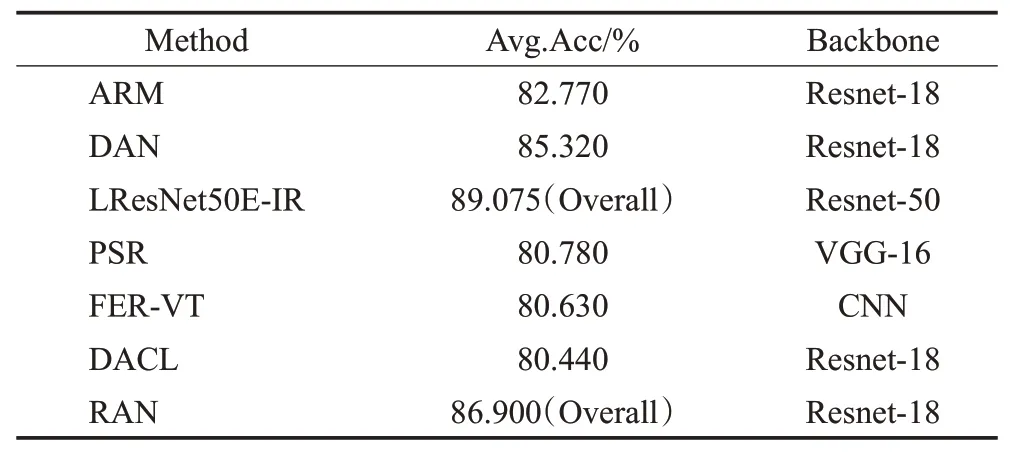
表3 表情识别方法:RAF-DB基准Table 3 Expression recognition method:RAF-DB benchmarks
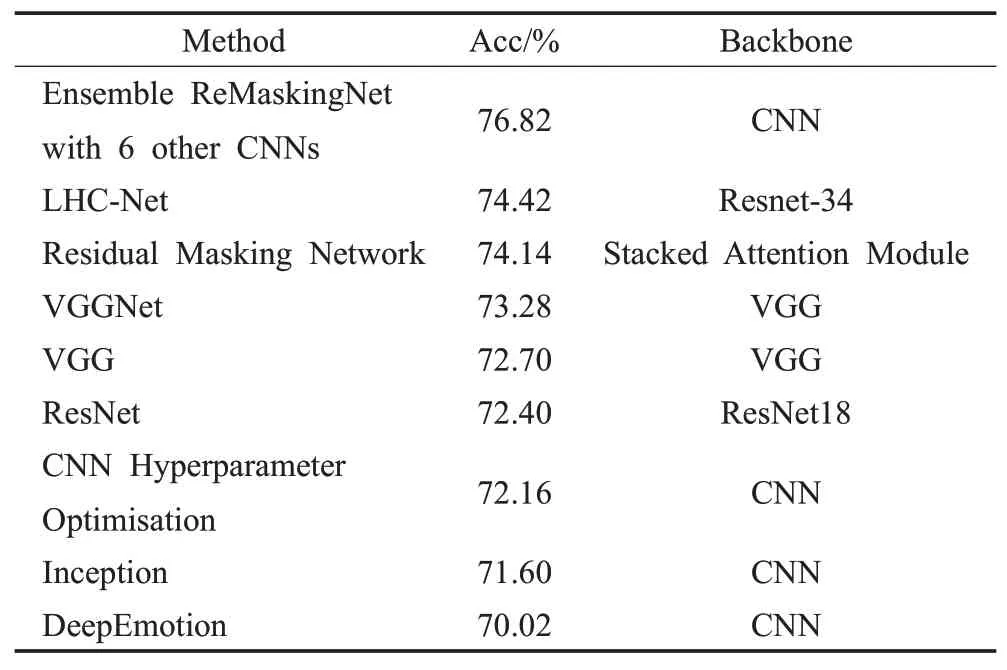
表4 表情识别方法:FER2013基准Table 4 Expression recognition method:FER2013 benchmark
3.4 实验设置
在预处理和面部特征处理方面,利用Dlibml来进行表情定位,统一将图像裁剪缩放至224×224作为groundtruth。实验模型均在pytorch-1.7中实现,服务器的CPU为10700K,频率为3.8 MHz,运行内存大小为64 GB,频率为3 200 MHz,GPU为NVIDIA-GeForce-GTX-3090,批大小设置为32。在每次迭代中,训练图像默认分为70%的高重要性样本和30%的低重要性样本两组,为了保证前述两组样本的平均概率差异大于0.15,因此按照这一差异设置高低重要性组均值之间的边缘界限seta1。整个网络采用Affinity-Loss和RR-Loss联合优化,两种损失的比值设定为1∶1,其影响将在后续的消融实验中研究。倾斜率初始化为0.1,在15个epoch和30个epoch之后再除以10,训练在70个epoch停止。从第10个epoch开始,重新标记模块被包括在优化中,其中重新标记边缘δ2默认设置为0.2。同时,关于分类输出调整为3分类输出。
本文在2个公共数据集和1个自采集数据集上进行了定性和定量的实验,以显示ESCN中各个模块的有效性。对于本文改进的网络,使用ESCN预先训练的权值,实验中设置衰减权重为0.001,学习速率初始化为0.001,每10个周期减少2倍。在测试阶段,在自采集数据集上采用传统的留一交叉验证方法,它的应用是为了确保独立的评估,进行100轮的训练。最后,将改进的ESCN方法与公共数据集上较为通用的方法进行了比较,来验证在数据集较小且噪声面部表情注释不确定性下的识别鲁棒性。由于识别准确率要求和轻量化集成需求,因此选取准确率(Acc)、参数量(Params)和运算速度(Flops)作为性能指标来表征性能好坏,其准确率计算为:

其中TP、TN、FP、FN分别代表真正例、真负例、伪正例、伪负例。同时,通过消融实验和混淆矩阵来验证和避免提出的方法对识别分类问题的过拟合。
3.5 实验结果分析
在这一节内,本文对所提出的ESCN网络进行消融实验,以证明本文方法在咽拭子采集机器人表情识别三分类任务中的有效性。实验所有比较分析均在两个公共数据集和自采集数据集上的三分类任务下进行。
多尺度注意力机制特征融合模块有效性验证。ResNet方法在RAF-DB、FER2013和PSCR-FER三种数据集上的准确率分别为76.214%、73.642%、72.940%。相比之下,在MAFN作用下,自注意力加权后的模型有助于引导学习局部区域特征和运动变化,用于FER的更深层次的卷积,与特征融合组合的性能优于单一骨干网络,因此ESCN方法在3个数据集上的性能分别提升10.437、8.784和17.18个百分点;对照方法SCN在RAFDB、FER2013和PSCR-FER三种数据集上的准确率分别为80.420%、81.924%、85.264%,相比之下由于MAFN有助于网络聚焦于重要的面部运动单元AUs和ROI,并减少FER可能的噪声特征,因此ESCN方法性能提升6.231、0.502和4.856个百分点。综上两点,ESCN中个别成分的贡献得以验证。综合看来,该方法在RAF-DB数据集上的表现较为突出。
三重注意力机制单元有效性验证。如表5所示,本文在这一部分消融实验中去掉MAFN中的AM部分仅利用特征融合来进行骨干网络在RAF-DB、FER2013和PSCR-FER三种数据集上的表现。该部分实验提取了表情图像的多尺度特征,经分类器进行表情分类,其准确率相比ResNet骨干网络的准确率分别提升2.386、4.854和2.98个百分点。实验结果表明,加入图像的时空描述特征是有效的,其时空描述在细节信息的表征方面是具有重要价值的。
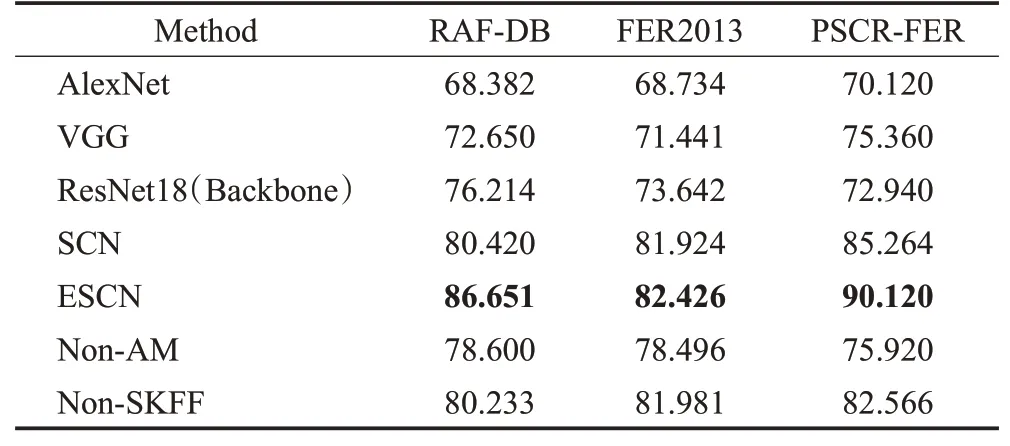
表5 评价指标:准确率Table 5 Evaluation index:accuracy %
线性聚合以及表情识别交互有效性验证。DLAN本文在这一部分消融实验中去掉MAFN中的SKFF部分仅利用注意力模块来进行骨干网络在RAF-DB、FER2013和PSCR-FER三种数据集上的表现。在浅层特征提取模块加入通道-空间-局部注意力模块。首先将浅层特征通过通道空间注意模块生成特征权重图,然后通过与Non-Local按元素相乘得到融合特征,最后经过分类器进行分类其准确率分别提升4.019、8.339和9.626个百分点。在自采集数据集中,不适的识别率较低,如三个数据集的混淆矩阵图10所示,主要原因是其比例较低,并且部分人脸表情存在较为不适和不适的相似性。这两个重要因素导致网络不能很好地将其区别开来。实验结果表明:改进的注意力模块可以有效地进行局部特征选取,与特征融合模块相辅相成。
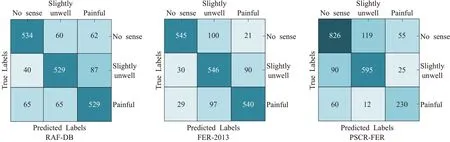
图10 增设三重注意力机制单元的消融实验混淆矩阵Fig.10 Confusion matrix of ablation experiment with triple attention mechanism unit added
综上,三重注意力机制单元促使网络对重要的特征进行加权以提升网络性能,促使提升精度4.019、8.339和9.626个百分点;特征融合模块促使网络提取表情图像的多尺度特征,促使提升精度2.386、4.854和2.98个百分点;二者的共同作用下促使提升精度10.437、8.784和17.18个百分点,可见,ESCN框架的核心网络部分对表情识别的准确性有明显贡献。
现有的超参数设置情况为,MRB数量为2,AM数量为6,SKFF数量为4,下采样倍数为1X、2X、4X,参数量达到33.08 MB,这样保证了轻量化水平,且远小于VGG16网络,同时保证了准确率平均提升4.643~11.058个百分点。本文进行了与先进方法SCN网络的对比,在三个数据集上均得到了相应的提升。在保证准确率提升的同时,其参数量增加较少,如表6所示,便于轻量化集成在咽拭子采集机器人系统的探头模块。
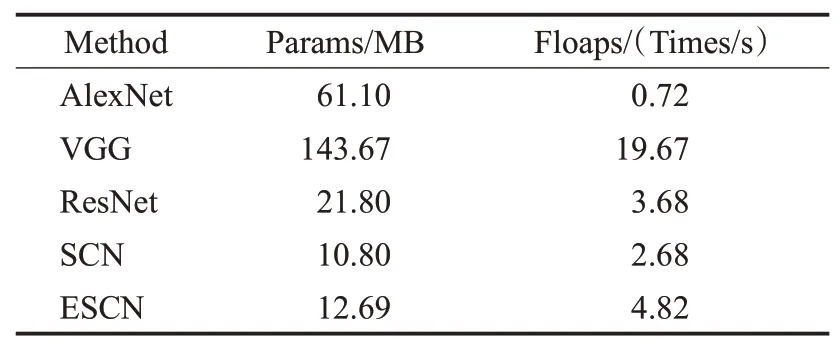
表6 评价指标:参数量Table 6 Evaluation index:parameter amount
4 总结
本文提出了一种基于增强自修复网络(ESCN)的特定场景下人脸表情识别方法。首先输入图像到特征提取模块和骨干网络中;然后通过多尺度注意力机制特征融合模块将浅层、深层和局部注意力特征进行融合;最后经过分类器进行分类。多尺度注意力机制特征融合模块的关键组成部分包括注意力机制加权和特征融合,其可以有效提高了模型的特征提取和识别能力。本文提出的方法在RAF-DB和FER-2013数据集和自采集数据集上进行了三分类任务实验和消融实验,在保证参数量较小的基础上取得了较高的识别准确率。因此,该模型为咽拭子采集机器人系统在表情识别及交互方面提供了重要支撑。在设计网络时,为了减少参数量,仅使用了2个多尺度注意力机制特征融合模块。因此在下一步工作中,继续改进该模块及讨论其数量设定,是使ESCN网络适应逐渐扩充的咽拭子采集表情图像和公共数据集上表情特征分布及识别任务的重要工作支撑。同时,另一项持续性工作是相较于排行榜上针对于本文所采用的2个公共数据集的7种和9种方法,在本文应用场景下的三分类任务的复现和识别准确率的对比。
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
导航定位学报(2022年5期)2022-10-13
导航定位与授时(2022年4期)2022-08-05
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
小型微型计算机系统(2021年12期)2021-12-08
导航定位与授时(2020年4期)2020-07-29
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
当代陕西(2019年10期)2019-06-03
