
全卷积神经网络图像语义分割方法综述
2022-04-21 05:12姚庆安金镇君冯云丛
计算机工程与应用 2022年8期
张 鑫,姚庆安,赵 健,金镇君,冯云丛
长春工业大学 计算机科学与工程学院,长春 130102
语义分割是将场景图像分割为若干个有意义的图像区域,并对不同图像区域分配指定标签的过程。然而语义分割的难点主要体现在两个方面:一是类内实例间的相异性和类间物体的相似性;二是复杂的背景大幅度提高了语义分割的难度。
图像语义分割的传统方法是利用图片中边缘、颜色、纹理等特征将图片分割成不同的区域。如基于阈值[1-4]、边缘[5-8]、聚类[9-12]、图论[13-16]等常用的经典分割方法。由于计算机的硬件设备限制,图像分割技术仅能对灰度图像进行处理,后期才逐渐发展到对RGB图像进行处理的阶段。随着GPU的飞速发展,深度学习(deep learing,DL)[17]技术为语义分割技术的发展提供有效的支撑。研究人员使用卷积神经网络(convolutional neural network,CNN),通过端到端的训练方式推理每个像素的语义信息并实现有意义图形区域的分类。由于CNN特征学习和表达能力的优势明显,使其成为图像语义分割领域优先考虑的方法。
2015年IEEE国际计算机视觉与模式识别会议(IEEE Conference on Comper Vision and Pattern Recognition),Long等人提出了全卷积神经网络(fully convolutional network,FCN)[18],至此图像语义分割进入了全卷积神经网络时期。全卷积神经网络在深度学习中表现出强大的潜能,逐渐成为解决图像语义分割问题的首选。对比前两个时期,全卷积神经网络通过像素级到像素级的训练方式,能够获得更高的精度和更好的运算效率,已经成为图像语义分割的研究热点。然而随着对该领域研究的深入,如何有效提高不同应用场景下图像语义分割的精确度一直是该领域的研究痛点。
目前存在的文献综述[19-23],虽然对图像语义分割进行了总结,但是普遍缺乏对于应用场景的深刻了解,如文献[19]仅对语义分割进行整体概述介绍;文献[20]将语义分割分为传统方法和深度学习的方法展开分析;文献[21]将语义分割进一步细化为全监督和弱监督学习方法进行阐述;文献[22]从语义分割研究领域入手进行梳理;以及文献[23]侧重于主流语义分割算法的总结。但是这些综述文献都未能根据不同应用领域有针对性地对精度需求和创新方向进行详细的解释,因此对全卷积神经网络图像语义分割方法进行综述必不可少。经过总结和整理了相关研究后得到,如图1所示。从语义分割常用神经网络引入。按照图像语义分割模型的应用场景不同,分为经典语义分割方法、实时性语义分割方法和RGBD语义分割方法,对每类具有代表性的方法进行叙述总结,并对不同应用场景下的方法进行延展。
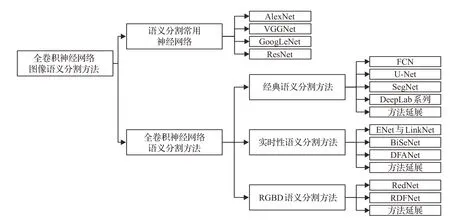
图1 全卷积神经网络图像语义分割方法分类Fig.1 Classification of semantic segmentation methods for fully convolutional neural network images
1 语义分割常用神经网络
1.1 AlexNet
2012年Krizhevsky等人提出的AlexNet[24]架构以绝对优势在ImageNet竞赛中以84.6%的准确率夺得冠军,掀起CNN在各个领域的研究热潮。AlexNet网络结构共8层,包括5个卷积层和3个全连接层[23]。其网络采用Relu激活函数,局部响应归一化(local response normalization,LRN)提高模型的泛化能力,应用重叠池化(overlapping)和随机丢弃(dropout)预防过拟合。
1.2 VGGNet
2014年由牛津大学计算机视觉组合和Google Deep-Mind公司提出的VGGNet[25],在ImageNet竞赛中以精确度92.7%获得亚军。它与AlexNet[24]网络相比,主要创新是叠加使用3×3滤波器将网络深度提升到16~19个权重层,使其在感受野不变的条件下,减少参数计算,同时网络深度增加有效地改善网络对语义信息的提取。
1.3 GoogLeNet
2014年Szegedy等人提出的GoogLeNet[26]以精确度93.3%取得ImageNet竞赛中的冠军。它采用比VGGNet[25]更深的网络结构,共22层,最亮眼的是提出Inception模块。Inception将不同感受野的滤波器对输入图进行卷积和池化,通过1×1卷积降维后拼接输出。GoogLeNet将这些模块堆叠在一起形成一个抽象的网络结构。同时抛弃全连接层。Inception的引入不仅削减网络复杂性,而且还考虑到内存和计算成本。
1.4 ResNet
2015年由微软研究院提出的ResNet[27]以精度96.4%成为ImageNet竞赛的冠军。其残差模块,能够成功地训练高达152层深的网络结构,残差结构通过引入跳跃连接来解决梯度回传消失的问题,真正解决网络深层架构的问题。
2 全卷积神经网络图像语义分割方法
全卷积神经网络对图像语义分割具有里程碑的意义。按照应用场景不同,从高分割精度的经典语义分割方法、高效率的实时性语义分割方法和复杂场景的RGBD语义分割方法三个方面进行阐述。表1对这三类方法从方法特点、优缺点等几个方面进行了分析和比较。下面对其进行详细的介绍。
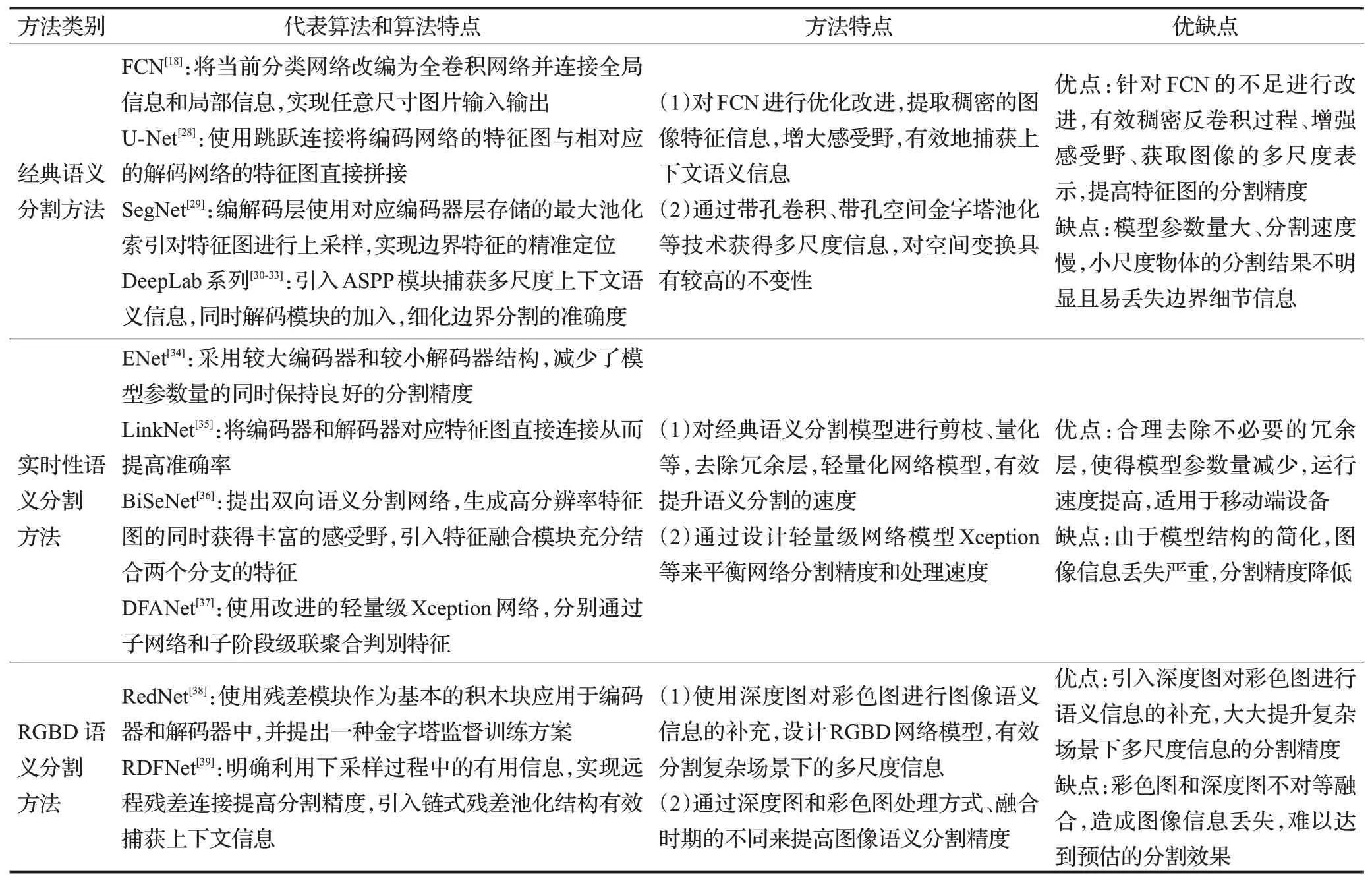
表1 图像语义分割方法分析与总结Table 1 Analysis and summary of image semantic segmentation methods
2.1 经典语义分割方法
经典语义分割在应用中具有里程碑的意义。从经典网络模型FCN[18]、U-Net[28]、SegNet[29]、DeepLab[30-33]和方法延展展开详细的叙述。
2.1.1FCN
2015年Long等人提出全卷积网络(FCN)[18],首次实现任意图片大小输入的像素级语义分割任务,其结构如图2所示。FCN将CNN模型中的全连接层替换为全卷积层以实现像素级的密集预测,使用反卷积对特征图进行上采样,并提出跳层连接充分融合全局语义信息和局部位置信息,实现精确分割。同时FCN微调常用经典网络的预训练权重来加快网络收敛速度。
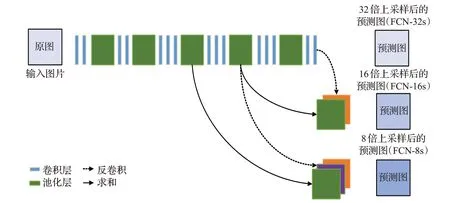
图2 FCN结构图Fig.2 Structure diagram of FCN
尽管FCN实现了分类网络到分割网络的转换,但是FCN也有许多不足:(1)上采样过程粗糙,导致特征图语义信息丢失严重,严重影响分割精度;(2)跳跃连接未能充分利用图片的上下文信息和空间位置信息,导致全局信息和局部信息的利用率低;(3)网络整体规模庞大,参数多,导致计算时间过长。正是FCN的提出与不足,才为全卷积神经网络的发展奠定了里程碑的基础。
2.1.2U-Net
2015年Ronneberger等人提出的用于医学图像分割的U-Net[28],是一个对称编解码网络结构,如图3所示。U-Net的独特之处是使用镜像折叠外推缺失的上下文信息,补充输入图片的语义信息,通过跳跃连接将编解码器中的特征图直接拼接,有效地融合了深层细节信息和浅层语义信息。
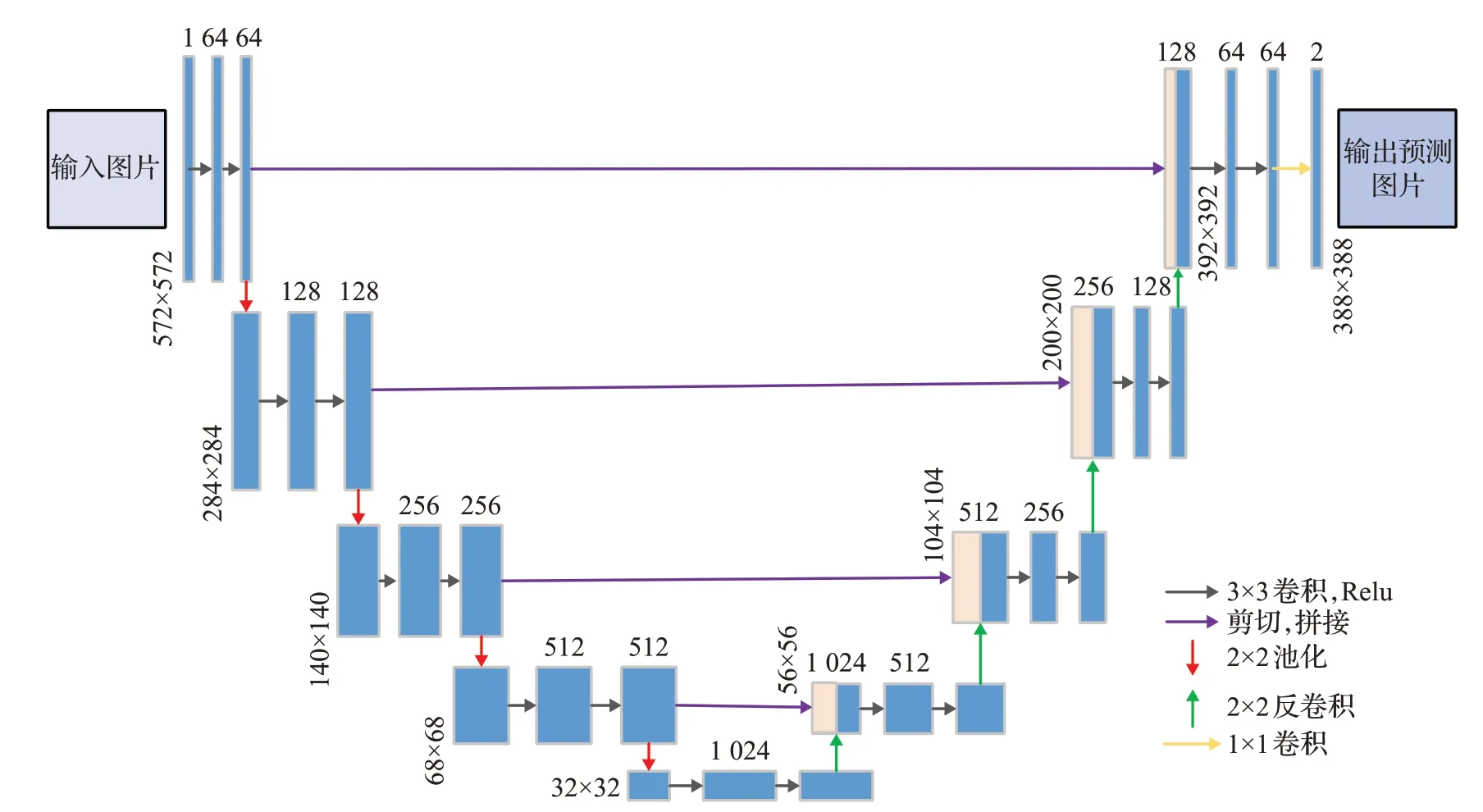
图3 U-Net网络架构Fig.3 Network architecture of U-Net
同时U-Net提出一个加权交叉熵损失函数,如公式(1)所示:

其中,ω是一个权重图谱,通过形态学操作的计算方式计算获得,如公式(2)所示:
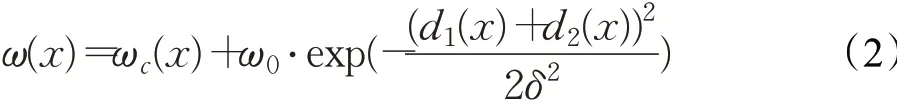
损失函数的目的是紧密细胞间的分割。此外,U-Net网络采用了自适应权重初始化方法:标准方差为 2/N(N为神经元输入结点的数量)的高斯分布初始化权重。
显然U-Net网络编解码器同层间直接进行跳跃连接,特征图之间语义差别大,不可避免地增加了网络学习的难度。因此基于U-Net出现了一系列改进的网络结构,如UNet++[40]、UNet3+[41]、Attention UNet[42]等,目的是充分利用深浅层语义信息,稠密特征图融合,提高语义分割精度。
2.1.3SegNet
SegNet[29]将对称编解码结构推向高潮,其结构如图4所示。SegNet没有跳层结构,使用批标准化(batch normal,BN)加快收敛抑制过拟合,其最大的创新是上采样使用最大池化(max-pooling)方法[22],即编码阶段的下采样过程中保留最大池化值和对应索引值,在解码阶段利用最大池化索引对输入的特征图进行上采样,最后经过卷积层得到稠密的特征图。SegNet使用极少数据量保存索引值却将低分辨率特征映射到输入分辨率中,实现对边界特征的精确定位。
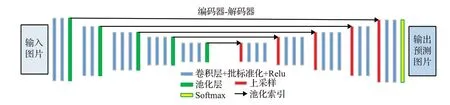
图4 SegNet网络架构Fig.4 Network architecture of SegNet
SegNet充分考虑内存占用问题,在空间复杂度上具有优势,然而除非存储量十分有限,SegNet就其网络本身,优势并不明显。
2.1.4Deep Lab系列
2016年Chen等人提出的DeepLab v1[30],抛弃VGG16[25]的全连接层,将最后两次池化步长改为1,深度卷积网络(deep convolutional neural network,DCNN)的部分卷积层替换为空洞卷积(atrous convolution),通过增大感受野来获得更多的语义信息。同时提出全连接条件随机场(connditional random field,CRF)的后处理方法对分割结果图进行细节增强,但是易丢失图片中详尽的细节信息。
2017年,Chen等人对DeepLab v1进行扩展提出了DeepLab v2[31],使用网络为ResNet[27]并提出带孔空间金字塔池化(atrous spatial pyramid pooling,ASPP)模块,实现多尺度目标的处理。多尺度特征提取的采样率(rate)分别为6,12,18,24。同时DeepLab v2仍然需要CRF做后处理。
同年12月,Chen等人在DeepLab v1、v2的基础上提出DeepLab v3[32],如图5所示。使用ResNet[27],在级联ASPP模块中增加了全局平均池化和1×1的卷积层,有效处理多尺度分割目标的任务,同时引入批标准化batch normal(BN)。DeepLab v3在丢弃CRF后处理的情况下,取得比DeepLab v1和DeepLab v2更高的精确值。
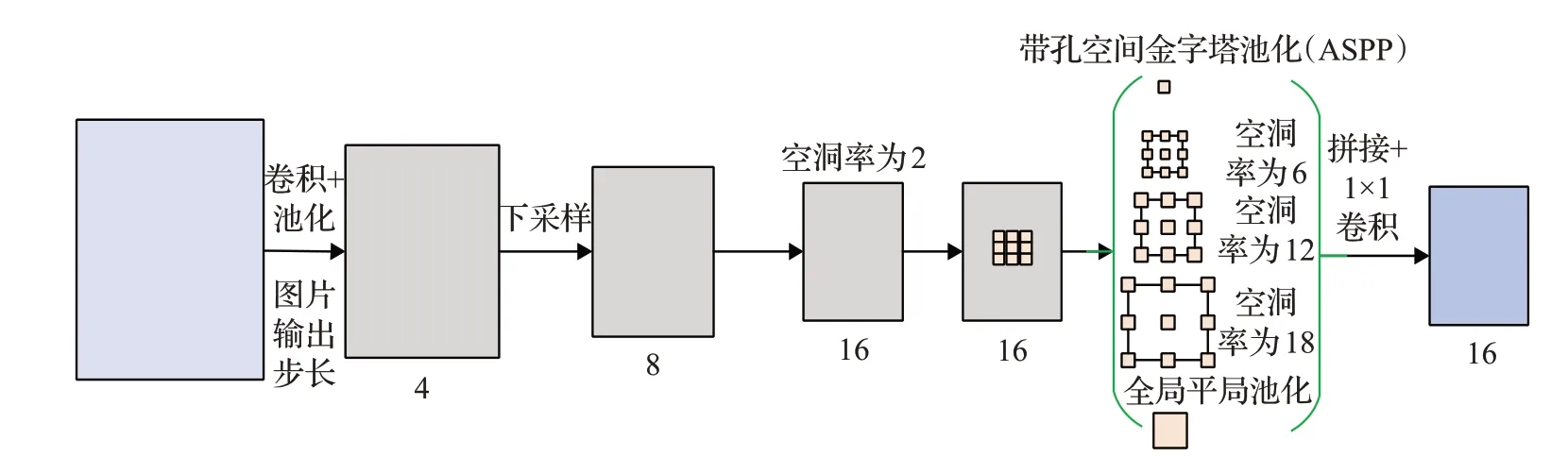
图5 DeepLab v3模型结构Fig.5 DeepLab v3 model structure
2018年Chen等人提出DeepLab v3+[33],结合编解码结构设计了一种新的编解码模型,如图6所示。以DeepLab v3为编码器结构提取丰富的上下文信息,简单有效的解码器用于恢复语义对象边界信息,同时在ASPP模块和解码网络中添加深度可分离深度卷积(depth wise separable convolution),提高了网络的运行速率和鲁棒性,大幅度提升了分割准确度。
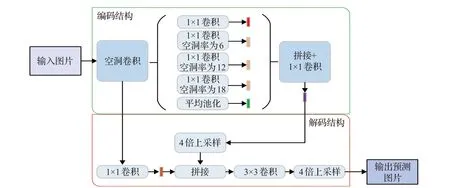
图6 DeepLab v3+模型结构Fig.6 DeepLab v3+model structure
DeepLab系列尽管成果斐然,但就其网络而言,存在细节分割丢失严重、计算量大、上下层语义信息关联性差等问题。因此基于DeepLab网络结构以及针对网络某个问题提出很多新的网络结构,如文献[43-44]等,有针对性地完善网络结构,解决多尺度目标的分割任务。
2.1.5方法延展
Lin等人提出了多路径细化网络(RefineNet)[45]。RefineNet用于解决空间信息丢失问题,首先输入来自ResNet[27]网络中4个不同尺度、不同分辨率的特征图,然后把4个特征图分别送入由残差卷积单元构成的4个精细化模块(RefineNet block)中求和,充分利用下采样过程中的所有可用信息,有效地实现高分辨率的预测任务。
Zhao等人提出金字塔场景解析网络(PSPNet)[46],提出一个金字塔池化模块。该模块级联多个具有不同步长的全局池化操作来聚合更多的上下文信息实现高质量的像素级场景解析,同时提出深度监督优化策略,降低模型优化的难度。
Peng等人提出GCN[47]。GCN提出对于输入图片进行分类和定位操作时有效的感受野至关重要,提出GCN模块采用大的卷积核替代通常小卷积核堆叠的方法来提高感受野,使用边界细化模块细化边界信息。论文作者提出当卷积核大小为11时效果最好。
Yu等人提出DFN[48]网络。DFN从宏观角度出发针对类内不一致和类间不一致的问题,提出平滑网络(smooth network,SN)和边界网络(border network,BN)。前者通过引入注意力机制和全局平均池化选择更具区分性的类别特征信息,后者通过深度语义边界监督来区分不同类别的特征。同时还有改编于U-Net[28]的网络Fusionnet[49]用于自动分割连接组学数据中的神经元结构,它在网络中引入基于求和的跳跃连接,用更深的网络结构来实现更精确的分割。DeconvNet[50]的解码器部分将反卷积和反池化组成上采样组件,逐像素分类完成分割任务。还有针对视频的语义分割的文献[51-53]。文献[51]提出将静态图像语义分割的神经网络模型转换为视频数据的神经网络技术,主要原则是使用相邻帧的光流来跨时间扭曲内部网络表示,提高性能的端到端训练。文献[52]提出基于时空变压器门控递归单元
STGRU(spatio-temporal transformer gated recurrent unit)的GRFP模型,结合多帧未标注信息来提高分割性能。以及文献[53]采用类似生成对抗网络(generative adversarial networks,GAN)[54]的网络结构。通过预测未来帧学习判别特征,与单帧的简单分割相比,语义分割效果显著。由此可知,经典模型发展相对饱和,横向领域研究将会为其精度提升注入新的血液。
2.2 实时性语义分割方法
实时执行像素级语义分割的能力在延时满足的应用中至关重要,针对这一应用场景,实时性语义分割应运而生。通过具有代表性的实时性网络架构ENet[34]与LinkNet[35]、BiseNet[36]、DFANet[37]展开阐述,并对模型优化方向提出方法延展。
2.2.1ENet与LinkNet
2016年Paszke等人提出ENet[34],次年Chaurasia等人提出LinkNet[35]。其中ENet针对低延迟操作的任务提出适合的网络模型结构,采用较大的编码结构和较小的解码结构,大大削减参数数量。同时采用PReLUs激活函数确保分割精度。LinkNet则是直接将编码器和解码器对应部分连接起来提高准确率,在不增加额外操作同时保留编码层丢失的信息,减少计算量。然而编解码网络的简化,不可避免丢失空间分辨率,减弱分割精度。如何平衡语义分割精度和分割效率,成为实时性分割模型的重要突破口。
2.2.2BiSeNet
2018年Yu等人提出BiSeNet[36],分为空间分支路径(spatial path,SP)和上下文分支路径(context path,CP),如图7所示。SP共三层,每层包括一个步长为2的3×3的卷积,BN层和Relu层,有效地保留原始图片的空间尺寸并编码丰富的空间信息。CP采用轻量级网络Xception和平均池化来兼顾感受野和实时性。同时模型加入注意力机制模块(ARM)来引导特征学习,最后使用特征融合模块(FFM)将全局特征和局部特征进行有效融合。
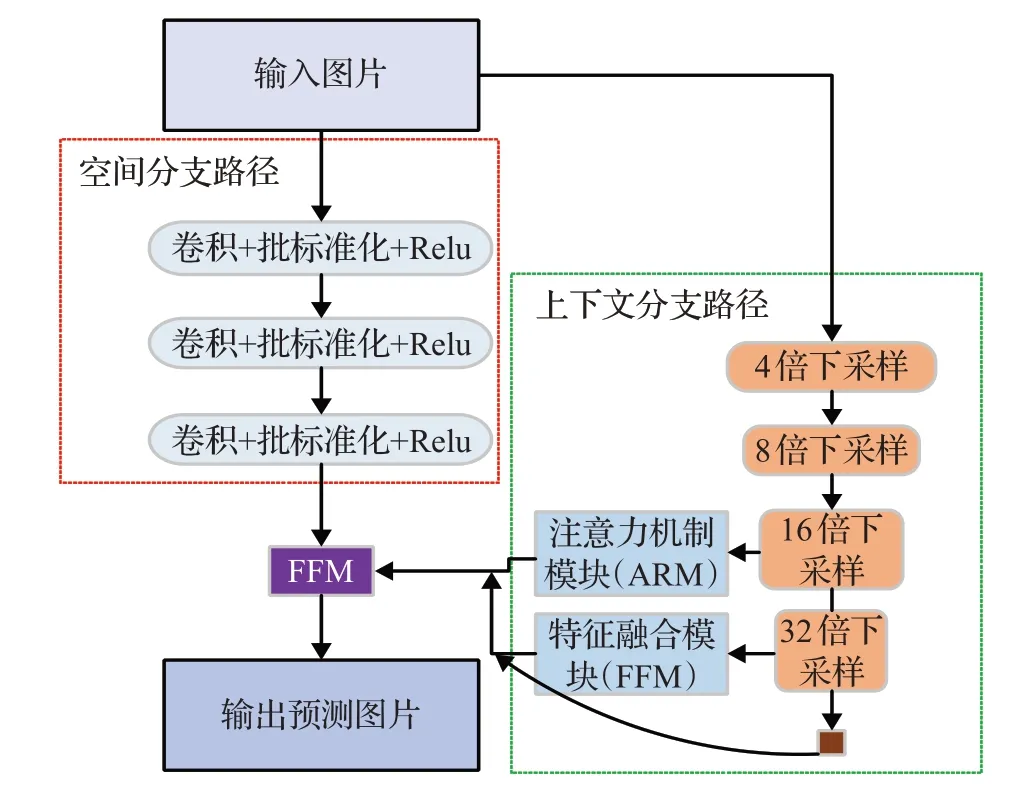
图7 BiSeNet模型结构Fig.7 BiSeNet model structure
BiSeNet证实了实时分割中双路径网络的有效性能,但是不可避免造成算法耗时增加。STDC[55]重新思考BiSeNet,进一步缩短了实时推理时间,削减网络冗余,也为网络瘦身提供新的研究思路。
2.2.3DFANet
2019年Li等人提出DFANet[37],如图8所示,DFANet开启了在主流移动端处理器上做高清视频级应用的可能性。其中编码器是3个改进的轻量级Xception网络,由网络级特征聚合和阶段级特征聚合连接在一起。作者保留全连接层增加感受野,并和1×1卷积组成注意力模块。解码器是将编码器3个阶段的特征图采用双线性差值的方式上采样后融合细化语义信息。
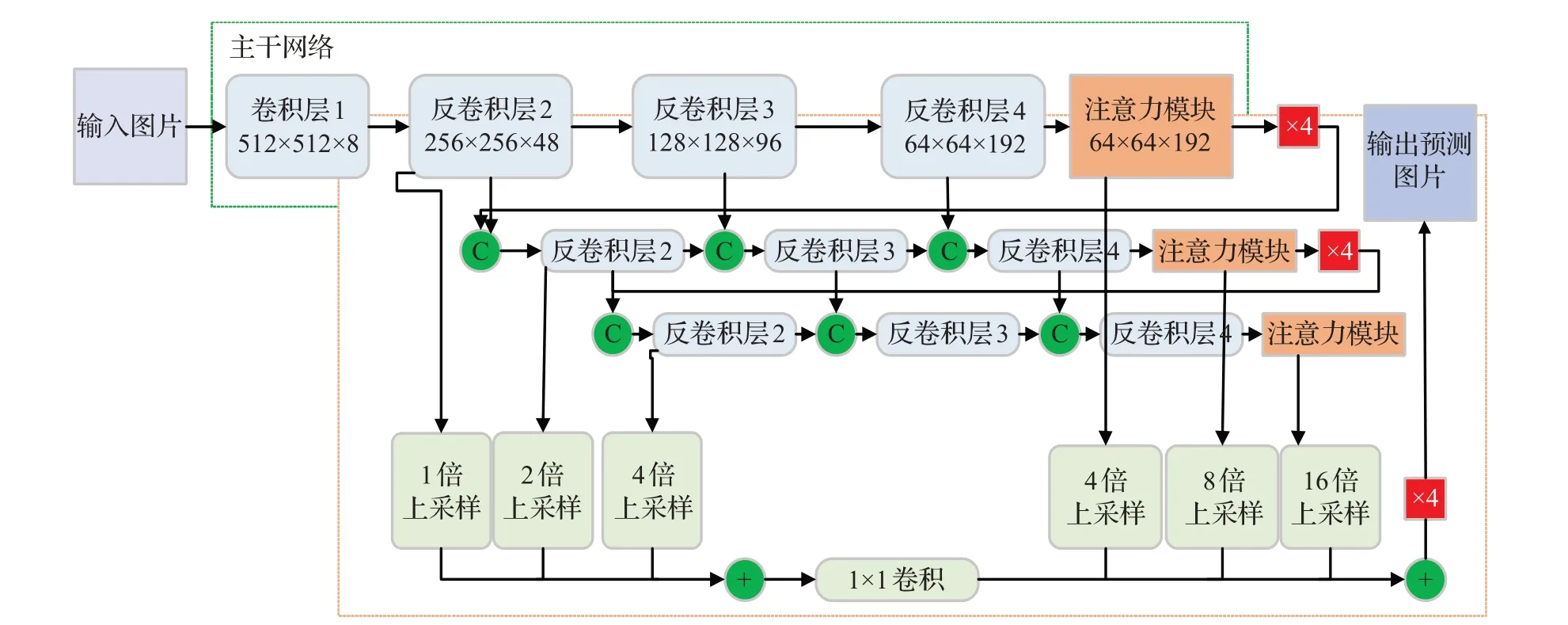
图8 DFANet模型结构Fig.8 DFA model structure
DFANet改进轻量级网络的思想,刷新了实时语义分割的计算量的记录。但是优化计算成本、内存占用会损失分割精度,因此如EsNet[56]、DFPNet[57]等网络的提出很好地平衡了实时性网络中速度和精度的追求。
2.2.4方法延展
Light-Weight RefineNet[58]在RefineNet[45]基础上,将网络改编为更加紧凑的架构,使其适用于在高分辨率输入图片上实现更快速率的分割任务。类似于将网络模型轻量化的模型压缩方法有模型裁剪、模型量化、知识蒸馏[59]、神经结构搜索(neural architecture search,NAS)[60]等,其中模型裁剪按照裁剪规则和敏感度分析对参数进行重要性分析,剪掉不重要的网络连接。模型量化是将浮点数映量化到最低位数,使得参数计算量和模型体积减少,从而加快模型的推理速度。知识蒸馏将复杂网络的知识迁移到小网络,通常的实现过程是用复杂网络监督小网络的训练,从而提高小网络的精度。以及NAS是通过模型大小和推理速度力约束来设计更高效的网络结构。因此,有效的模型瘦身和轻量化网络结构会促进实时性语义分割性能,实现对高分辨率图像的精准快速分割。
2.3 RGBD语义分割方法
随着室内复杂场景分割问题的显露,提出RGDB语义分割。主要思想是使用深度图(deep image)对RGB图进行语义信息的补充。其中深度图也叫距离影像,指将从图像采集器到场景中各点的距离(深度)作为像素值的图像。首先从RedNet[38]、RDFNet[39]来介绍RGBD语义分割。然后针对其算法融合阶段进行方法延展。
2.3.1RedNet
2018年,Jiang等人提出的RedNet[38]网络,如图9所示。RedNet使用残差模块作为基本块应用于编码解码结构中,深度图和彩色图使用相同下采样方式。网络先短跳进行深度图和彩色图融合,再将融合结果通过远跳和同尺寸的解码器模块融合,并提出一种金字塔监督的监督训练方法来提高复杂场景的分割精度。
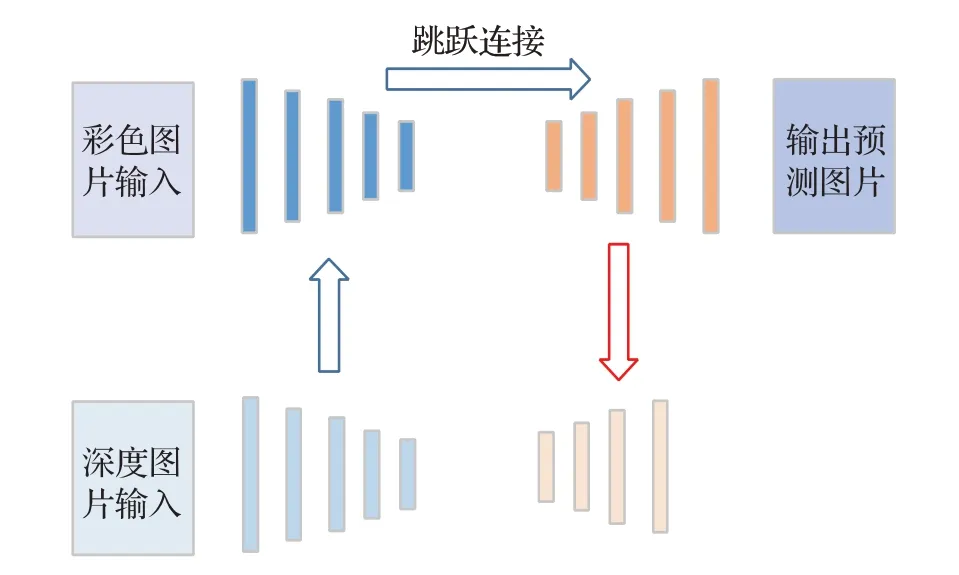
图9 RedNet模型结构Fig.9 RedNet model structure
然而,彩色图和深度图本身差异明显,如何让深度图有效地给彩色图以语义补充,提高模型分割精度,是复杂场景下RGBD语义分割追求的目标。目前有文献[61-62]对深度图进行有效处理。
2.3.2RDFNet
2017年Park等人提出的RDFNet[39],编码部分使用多模态特征融合模块(multi-modal feature fusion,MMF),如图10所示。该模块充分利用彩色图和深度图之间的互补特征提取语义信息。解码器特征优化模块与RefineNet[45]一样,采用多个级别学习融合特征的组合,以实现高分辨的预测。
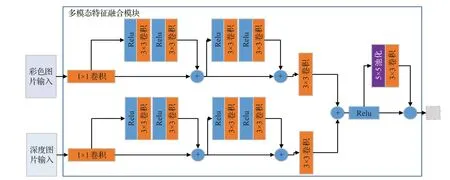
图10 RDFNet模型结构Fig.10 RDFNet model structure
RDFNet网络提出MMF模块对彩色图和深度图进行处理,通过考虑深度信息来实现更好的分割性能。目前,有效使用深度信息仍然是值得深入思考的问题,如ACNET[63]、MCA-Net[64]等网络的提出,为RGBD语义分割在复杂场景下的应用提供了新的创新思路。
2.3.3方法延展
通过RedNet[38]和RDFNet[39]可知,RGBD模型的关键是彩色图和灰度图的有效融合。Li等人[65]提到RGBD模型可分为早期、中期和晚期融合,根据中期融合又细分为浅层中期融合和深层中期融合。然而早期融合与浅层中期融合的网络虽然在融合过程中很好地保留了空间线索,但是RGDB图像中的视觉信息和深度图中的几何信息在底层没有得到矫正,特征信息较少。而后期融合与深层中期融合,他们融合了表示语义信息的高级特征,在不同模式下得到的结果更加兼容,但是两者互补的空间线索被大大削弱。因此,如文献[66-67]对深度图进行详细介绍,文献[68-71]通过对RGBD模型融合方式进行创新来提高分割精度。合理应用深度图对RGB图进行补充,一定会有效提高RGBD语义分割的分割精度。
3 图像语义分割实验分析与对比
3.1 数据集
根据全卷积语义分割方法应用场景的不同,整理了语义分割的常用公共数据集,分为2D数据集和2.5D数据集,如表2所示。
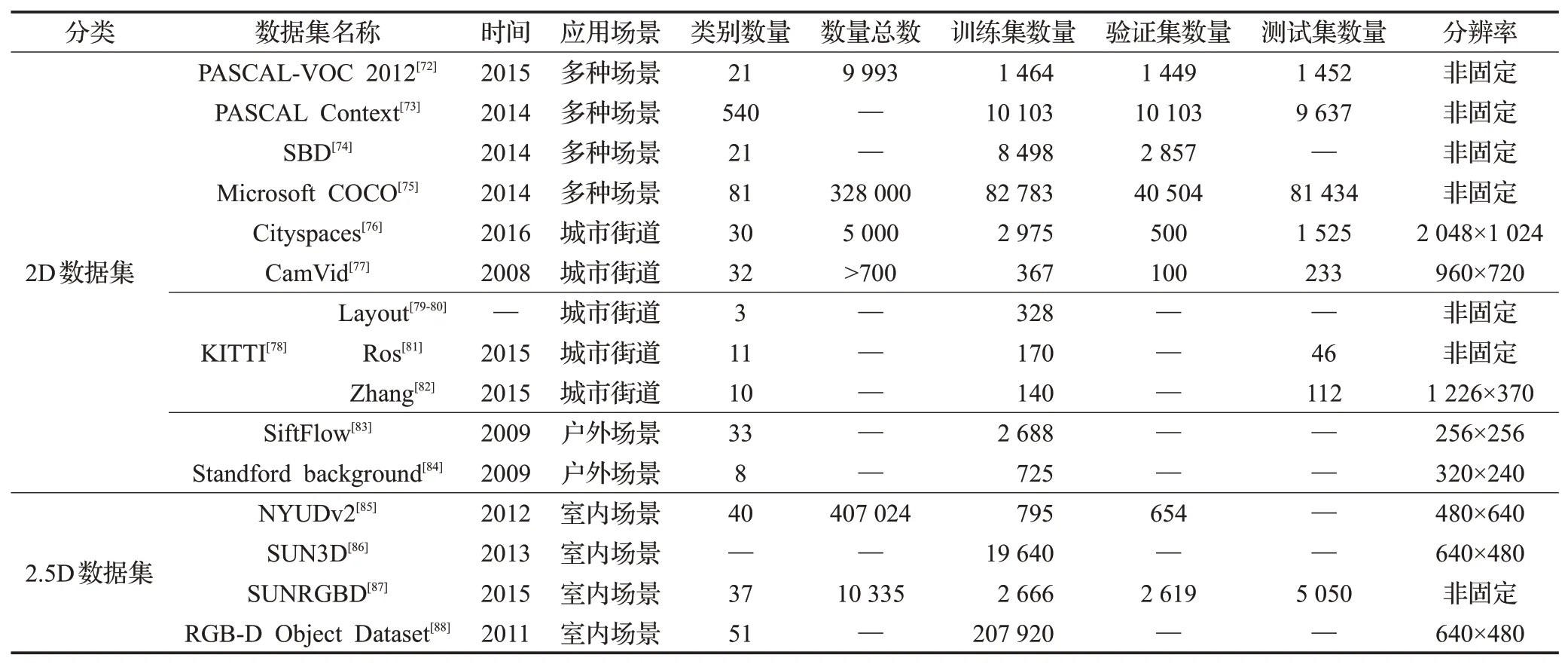
表2 常用分割数据集Table 2 Popular segmentation datasets
3.1.12D数据集
PASCAL Visual Object Classes[72](简称PASCAL VOC):数据集由一个国际计算机挑战赛提供,从2005年一直发展到2012年,由于每年发布带标签的图像数据库并开展算法竞赛而产生一系列高质量的数据。目前数据集PASCAL VOC 2012最为常用。数据集包含20种类别(人、动物、交通工具、室内物品等),图片大小不固定,背景复杂多变。
PASCAL Context[73]:数据集由PASCAL VOC数据集扩展得到,总共有540个类,包含10 103张语义标注的图像。该数据集类别繁多且许多类比较稀疏,因此在评估语义分割算法性能时,通常使用前59个类作为分割评判标准。
Semantic Boundaries Dataset[74](简称SBD):数据集由斯坦福大学建立,继承了PASCAL VOC中的11 355张语义标注图像,其中训练集8 498张图像,验证集2 857张图像,图片大多数为户外场景类型,实际应用中已逐渐替代PASCAL VOC数据集。
Microsoft Common Objects in Context[75](简称COCO):数据集由微软公司开源和推广,包含80个图像实例,82 782张训练图片,40 504张验证图片和81 434张测试图片,其中测试图片分为四类用于不同的测试。数据集中图像类别丰富,大多数取自复杂的日常场景,图中的物体具有精确的位置标注。
Cityscapes[76]:数据集由奔驰公司于2015年推行发布,专注于对城市街景的语义理解。提供了50个不同城市街景记录的立体视频序列,包含20 000张弱注释图片和5 000张的高质量的强注释的图片,涵盖了各种时间及天气变化下的街道动态物体,同时提供了30个类别标注,像素为2 048×1 024的高分辨率图像,图像中街道背景信息复杂且待分割目标尺度较小。此数据集可用于实时语义分割研究。
CamVid[77]:数据集由剑桥大学的研究人员于2009年发布,CamVid由车载摄像头拍摄得到的5个视频序列组成,提供了不同时段701张分辨率为960×720的图片和32个类别的像素级标签,包括汽车、行人、道路等。数据集中道路、天空、建筑物等尺度大,汽车、自行车、行人等尺度小,待分割物体尺度丰富。
KITTI[78]:目前国际上最大的用于自动驾驶场景的算法评测数据集,可进行3D物体检测、3D跟踪、语义分割等多方面研究。数据集包含乡村、城市和高速公路采集的真实数据图像,原始数据集没有提供真实的语义标注,后来Alvarez等人[79-80]、Zhang等人[81]和Ros等人[82]为其中部分图添加了语义标注。
Sift Flow[83]:数据集是LabelMe数据集的子集,包含33个类别和2 688张分辨率为256×256的训练图像,提供8种不同户外场景,包括山脉、海滩、街道、城市等,图片都具有像素级标注。
Standford background[84]:数据集由斯坦福大学2009年发布,主要来自LabelMe、MSRC、PASCAL VOC等公共数据集。包含715张图片,分辨率为320×240。包括道路、树木、草、水、建筑物、山脉、天空和前景物体共8个类别。
3.1.22.5D数据集
NVUDv2[85]:数据集大都来自微软Kinect数据库,提供了1 449个RGBD图像,捕获了464种不同的室内场景,并附有详细的标注,能够验证3D场景的提示和推断,实现更好的对象分割内场景,并附有详细的标注,能够验证3D场景的提示和推断,实现更好的对象分割。
SUN3D[86]:数据集由美国普林斯顿大学研究小组2013年发布,包含使用Asus Xtion传感器捕获的415个RGBD序列,是一个具有摄像机姿态和物体标签的大型RGBD视频数据库。每一帧均包含场景中物体的语义分割信息以及摄像机位态信息。
SUNRGBD[87]:数据集由4个RGBD传感器获取而得和NYU depthv2、SUN3Dd等数据集组成。包含了10 335张室内场景、146 617个二维多边形标注、58 657个三维边界框标注以及大量的空间布局信息和种类信息。
RGB-D Object Dataset[88]:数据集由美国华盛顿大学的研究小组2011年发布,包括11 427幅人工手动分割的RGBD图像组成,包含300个对象,分为51个类别。另外,还提供了22个带注释的自然场景视频序列,用于验证过程以评估性能。
3.2 性能评价指标
为了衡量分割算法的性能,需要使用客观评价指标来确保算法评价的公正性,运行时间、内存占用和精确度是常用的算法评价指标[89]。
3.2.1运行时间
运行时间包括网络模型的训练时间和测试时间。由于运行时间依赖硬件设备及后台的实现,某种情况下,提供确切的运行时间比较困难。但是提供算法运行硬件的信息及运行时间有利于评估方法的有效性,以及保证相同环境下测试最快的执行方法。
3.2.2内存占用
内存占用是分割方法的另一个重要的因素。图像处理单元(graphics processing unit,GPU)具有高效并行特征以及高内存带宽,但是相比于传统的中央处理器(cencer processing unit,CPU),时钟速度更慢以及处理分支运算的能力较弱。在某些情况下,对于操作系统及机器人平台,其显存资源相比高性能服务器并不具优势,即使是加速深度网路的GPU,显存资源也相对有限。因此,在运行时间相同的情况下,记录算法运行状态下内存占用的极值和均值都是有意义的。
3.2.3精确度
精确度包括像素精度(pixel accuracy,PA)、均像素精度(mean pixle accuracy,MPA)、均交并比(mean intersection over union,MIOU)、频率加权交并比(frequency weighted intersection over union,FWIoU),常使用MIoU来衡量语义分割模型的性能。
像素准确度(PA)是语义分割中最简单的像素级评价指标,仅需计算机图像中正确分类的像素占图像中总像素比值,如公式(3)所示:

其中,pii表示正确分类的像素个数,pij表示本应属于第i类却被分为第j类的像素个数,n是类别数。
平均准确度(MPA)表示图像中所有物体类别像素准确率的平均值,如公式(4)所示:

平均交并比(MIoU)是分割结果真值的交集与其并集的比值,按类计算后取平均值,如公式(5)所示:
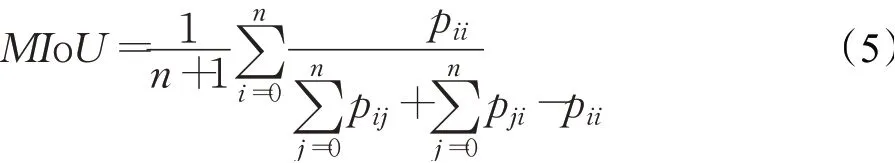
频率加权交并比(FWIoU)是对MIoU改进后的新的评价标准,旨在对每个像素的类别按照其出现的频率进行加权,如公式(6)所示:
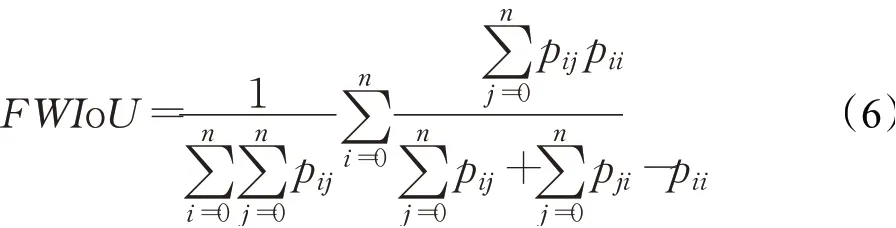
3.3 实验结果分析与对比
不同应用场景下语义分割方法在不同数据集上的实验结果对比如表3所示。选用分割领域标准数据集VOC 2012、Cityscapes、CamVid、SUNRGBD和NYUDv2对经典语义分割方法,实时性语义分割方法和RGBD语义分割方法进行实验结果分析和对比。
针对高精度追求的应用场景经典语义分割方法,多用于室外场景数据集,从表3可知,在VOC 2012数据集上DeepLab v3+的精度高达89.0%,在数据集Cityscapes是可达到82.1%的精度;针对延时满足要求高这一应用场景,实时性语义分割网络DFANet和Light-weight RefineNet在数据集Cityscapes和VOC 2012分别达到71.3%和81.1%的准确率,并且后者每秒传输帧数需要2 055 frame/s;而针对复杂场景下RGBD语义分割方法,对室内复杂场景分割效果要优于经典语义分割和实时性语义分割的模型。
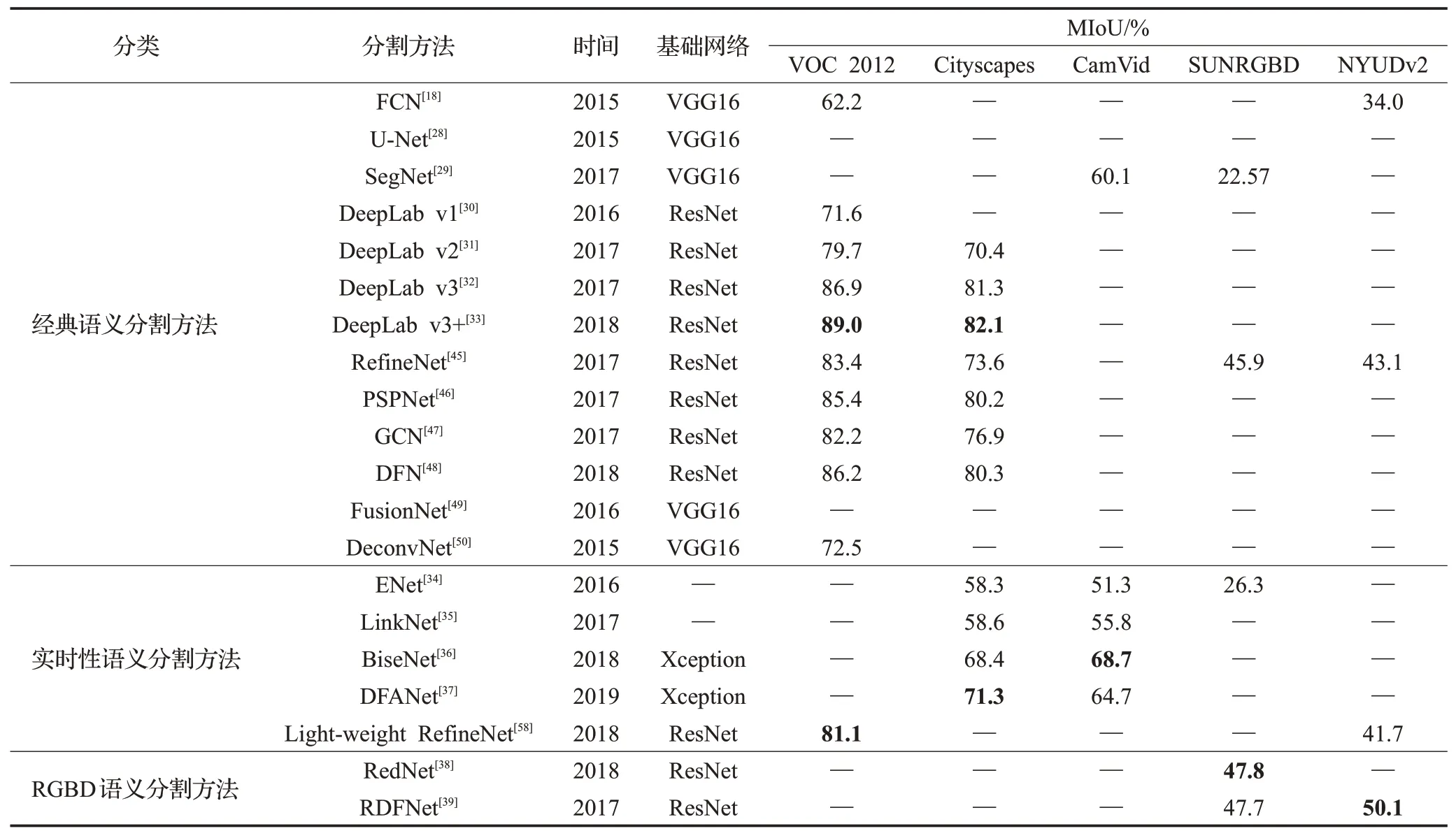
表3 不同语义分割方法在不同数据集上的性能Table 3 Performance of different semantic segmentation methods on different datasets
4 结束语
随着全卷积神经网络在图像语义分割领域的应用,如何提高分割精度成为目前研究的难点和痛点。本文从不同应用场景,针对不同场景下的经典网络结构展开分析总结,发现该领域仍然存在许多未知的问题值得深入探究。
(1)实时性语义分割
现阶段语义分割在实时性网络分割任务上,依旧不够完善,如何平衡语义分割精度和效率依旧是一个必不可少的研究方向。
(2)RGBD语义分割
RGBD网络模型目前的难点依旧是如何充分利用深度信息,有效地融合两者互补的模态,目前依旧是一个悬而未解的问题。
(3)三维场景的语义分割技术
深度图的引入让研究开始关注三维场景。尽管3维数据集难以获取,且标注工作很难,但是3维数据集比2维数据集包含更多的图像语义信息,使得3维场景语义分割有较高的研究价值和广阔的应用前景。
(4)应用于视频数据的语义分割
可用的视频序列数据集较少,导致针对视频语义分割的研究进展缓慢。更多高质量的视频数据的获取和视频中时空序列特征的分析,将是语义分割领域的重要研究方向。
(5)弱监督和无监督语义分割技术
随着基于目标边框、基于图像类别便签、基于草图等弱监督方法的出现,降低了标注成本。但是分割效果并不理想,所以弱监督和无监督的语义分割需要进一步的研究。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
小哥白尼(军事科学)(2022年2期)2022-05-25
北京航空航天大学学报(2021年9期)2021-11-02
开放教育研究(2020年2期)2020-03-31
电子制作(2019年13期)2020-01-14
红领巾·萌芽(2019年8期)2019-08-27
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
长江学术(2016年4期)2016-03-11
CHIP新电脑(2016年3期)2016-03-10
