
钻井溢流风险的自适应LSTM预警方法
2022-04-21 04:41王钰豪郝家胜彭知南段慕白
控制理论与应用 2022年3期
王钰豪 ,郝家胜 ,张 帆 ,魏 强 ,彭知南 ,段慕白
(1.电子科技大学自动化工程学院,四川成都 611731;2.川庆钻探公司钻采工程技术研究院,四川广汉 618000)
1 引言
近年来,随着勘探技术的快速发展,大量的油气资源在深度高以及地质情况复杂的区域被探测到.在这些区域的油井钻井具有周期长、钻井事故频发的特点,导致钻井保持各项参数在安全范围内十分困难.溢流是最常见和高风险的钻井事故.为了防止溢流发生,在钻井过程中需要时刻保持井底压力大于地层压力,然而随着钻井深度增加,井下条件愈发复杂,压力控制难度加大.当井底压力小于地层压力时,地层中的流体会沿着岩石间的空隙侵入钻井液,融入钻井液随着环空上返,特别是气体在上返的过程中会随着压力减小而膨胀,造成钻井液返出量增大发生溢流,如果不及时加以控制,会恶化成井喷等重大安全事故,给人员和财产带来极大的威胁.因此,如何尽早检测溢流并及时通知现场人员采取相应的处理措施,对有效降低和预防溢流风险十分关键.
目前大多数井场,对于溢流复杂普遍采取人工坐岗预警,要求钻井人员时刻保持高度集中的注意力,综合多种参数的趋势给出当前是否溢流的评估.但是该方法受限于坐岗人员的识别经验,主观性极强.然而,溢流往往反映在参数的连续和细微变化中,即使是经验丰富的预警人员也很难准确发觉,导致精准度较低.因此实现高质量、高效率、高安全的钻井是未来石油行业发展的趋势,人工坐岗预警智能化是其中较为关键的一环,凭借钻井作业数据构造算法模型,提高钻井过程溢流预警的准确率,降低漏警、虚警率.
随着机器学习、人工智能和大数据等新兴科技的快速发展,利用高性能计算机的强大运算能力,探索基于人工智能技术的井下复杂预警的方法是石油行业未来发展的必然趋势.与人工坐岗监测相比,计算机拥有更快的速度,更准确严谨的预警结果,在不久的将来,钻井工程师可以不用呆在井场,远程操控中心能够得到所有的实时钻井数据,在极短的时间内进行综合判断,快速得出预警结果,帮助工程师迅速得出后续处理方案,对现场人员进行正确的指导,将钻井过程中的风险降到最低,实现钻井成本最小化,利益最大化.
近些年来,国内外越来越多的科研人员,机构开展了复杂井下预警安全算法的研究.文献[1–3]分析特定钻井字段的变化趋势,通过实时计算的方法预警钻井复杂,其中哈利伯顿公司[1–2]通过计算数据序列的斜率模拟预期变化,对实际值与预期值的差值积分计算溢流概率.文献[4–6]对井下参数变化情况进行仿真建模,模拟复杂发生时的参数特征变化给操作人员提供参考.文献[7–8]将传统的机器学习算法引入溢流预警,验证了贝叶斯[7]、决策树[8]、KNN[8]等算法学习溢流相关参数之间非线性关系的可行性.文献[9–12]将全连接网络引入钻井作业,通过大量数据对网络进行训练,提高了复杂预警的准确率以及钻井作业效率,表明了深度学习在钻井领域的可行性.文献[13–14]根据钻井数据具有的序列特征引入长短期记忆网络,其中文献[13]使用模拟生成的井涌数据集训练(long short-term memory,LSTM),网络在测试集上的预警成功率较高,验证了LSTM处理钻井序列数据的能力.
国内机构对溢流预警的研究起步稍晚,不过仍有相应成果.文献[15–16]对钻井特征参数进行监控计算,通过数学逻辑判断规则[15]以及设定阈值[16]对复杂进行预警.文献[17–18]研发的系统基于模糊数学理论,结合钻井参数对溢流、井漏等复杂进行推理.文献[19–21]引入支持向量机[19–20]、随机森林[20]对井下工况进行自主识别[19]、溢漏复杂判断[20–21],提高了钻井作业的安全以及效率.文献[22–23]引入深度学习,分别应用卷积神经网络[22]、BP神经网络[23]实现了井下复杂的准确预警.
从上述文献调研结果来看,在钻井领域通过引入动力学建模、传统机器学习、神经网络等算法,实现对复杂的推演预警具有较高的可行性,给后续研究提供了一定参考.值得注意的是,现有的结果没有考虑到一个现实情况,即往往石油钻井过程中产生的溢流部分数据量较正常段少,且每口油井之间的数据差异性大,仿真数据只能模拟固定模式下的规律,难以刻画不同钻井的特性,并且同时一口井不可能再次开采,因此如何实现基于已有的实钻数据实现跨井检测值得进一步研究.
本文针对现有的方法存在的问题,利用川渝地区30余口已完钻的油井数据,提出了一种钻井溢流风险自适应LSTM预警方法,通过设计基于滑动时间窗的数据扩充技术,解决溢流部分数据偏少的问题;再者,通过计算一段时间内数据平均值增量,实现不同井数据之间共性特征的自适应提取以提高预警算法对不同钻井的适应性;最后,通过离线测试和现场早期溢流预警实验,验证了所提出的溢流风险自适应预警方法的有效性.
2 基于滑动窗口的自适应特征提取
不同油井之间的数据在绝对数值上差异性较大,因此算法在运行时要具备针对不同场景的自适应能力,可以屏蔽这种差异性,专注数据的趋势.本文采取特定的处理方法对数据进行自适应特征提取,该方法不仅需要屏蔽不同井数据的差异性,还要对数据变化趋势进行量化提取.同时在整个钻采过程中,溢流段的长度较短,为了对有限的数据集进行更充分的利用,需要采用一定的数据扩充手段,增大训练集容量.
2.1 自适应增量特征提取
在发生气侵或者溢流时,相同的字段在不同油井情况下具体的数值是不等的,但是趋势是类似的.因此为了屏蔽不同钻井之间的差距,着重于趋势本身,开发针对不同井的数据自适应特征提取方法.
窗口长度为L的钻井序列(即含有L个数据点),计算后L/2个数据点的平均值vα,以及前L/2个数据点的平均值vβ,两个平均值相减得到相对变化量∆v,具体计算见下式:

该方法可以有效的提取数据本身的趋势,屏蔽不同井的差异性,平均值计算的引入规避了单个点带来的不确定性,平缓了数据的抖动.
2.2 滑动窗口样本扩充
深度学习模型是一种基于数据驱动的方法,在数据量较少情况下难以保证模型的表现效果,溢流数据有限且持续时间较短,因此采用滑动窗口的思想进行扩充.
对于一组连续的n条数据,时间窗口长度为L,第1条数据到第L/2条数据使用式(1)计算得到vβ,第(L/2)+1到第L条数据使用式(2)计算得到vα,最后使用式(3)计算∆v完成一次自适应特征提取,随即时间窗移动一步,重复操作,直到时间窗走到最后一格.
该扩充技术原理如图1所示,该方法能够在有限数据的情况下,获取尽可能多的窗口序列.

图1 滑动窗口过程Fig.1 Process of sliding window
3 预警模型组成结构
本节将给出预警模型组成,主要包括一维卷积,长短期记忆网络以及全连接.
3.1 长短期记忆网络
LSTM是对普通循环神经网络的增强,普通循环神经网络经常产生梯度消失或者梯度爆炸的问题,长短期记忆网络通过更改单元内部结构,能够避免时间步过长产生的上述问题,理论上可以学习任意时间步长度的数据,LSTM的详细结构如图2所示.基于LSTM的算法可以实现语言翻译、机器人操控、语音识别图像识别、手写文字辨识、疾病诊断分析、股票趋势预测、音乐构成等任务.

图2 LSTM结构图Fig.2 Structure of LSTM
LSTM中存在3个门,分别是遗忘门ft,决定上一时刻的单元状态ct−1有多少保留到当前单元状态ct;输入门it,决定了当前时刻网络的输入xt有多少保存到单元状态ct;输出门ot,控制单元状态ct有多少输入到当前输出值ht.
遗忘门计算见式(4),Wf是遗忘门的权重矩阵,[ht−1,xt]表示把两个向量连接成一个更长的向量,bf是遗忘门的偏置项,σ是sigmoid函数

输入门的计算见式(5),Wi是输入门的权重矩阵,bi是输入门的偏置项

随后计算候选单元状态c˜t用于更新当前时刻单元状态ct,见式(6),它是由上一次的单元状态按元素乘以遗忘门ft,再用候选单元状态按元素乘以输入门it,再将两个运算结果相加而成
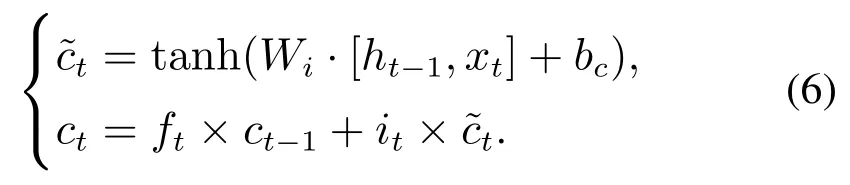
输出门的计算见式(7)
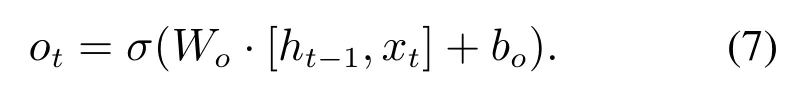
LSTM最终的输出ht是由输出门和当前单元状态共同决定的,见式(8)

上述权重矩阵都是未知的参数,在训练网络的过程中,网络的实际输出与理想输出存在偏差,通过误差反向传播算法调节权重矩阵的元素,目的让偏差达到最小.
3.2 一维卷积
一维卷积神经网络的卷积核可以看作是一种特征提取器,可以从时间序列中提取局部的信息作为序列的特征,是一种更高层次的抽象方法,在此次试验中,也考虑在长短期记忆网络的基础上叠加一维卷积网络,目的是加强网络的特征捕捉能力,能够进一步挖掘数据中的隐藏特征.一维卷积的计算流程如图3所示.
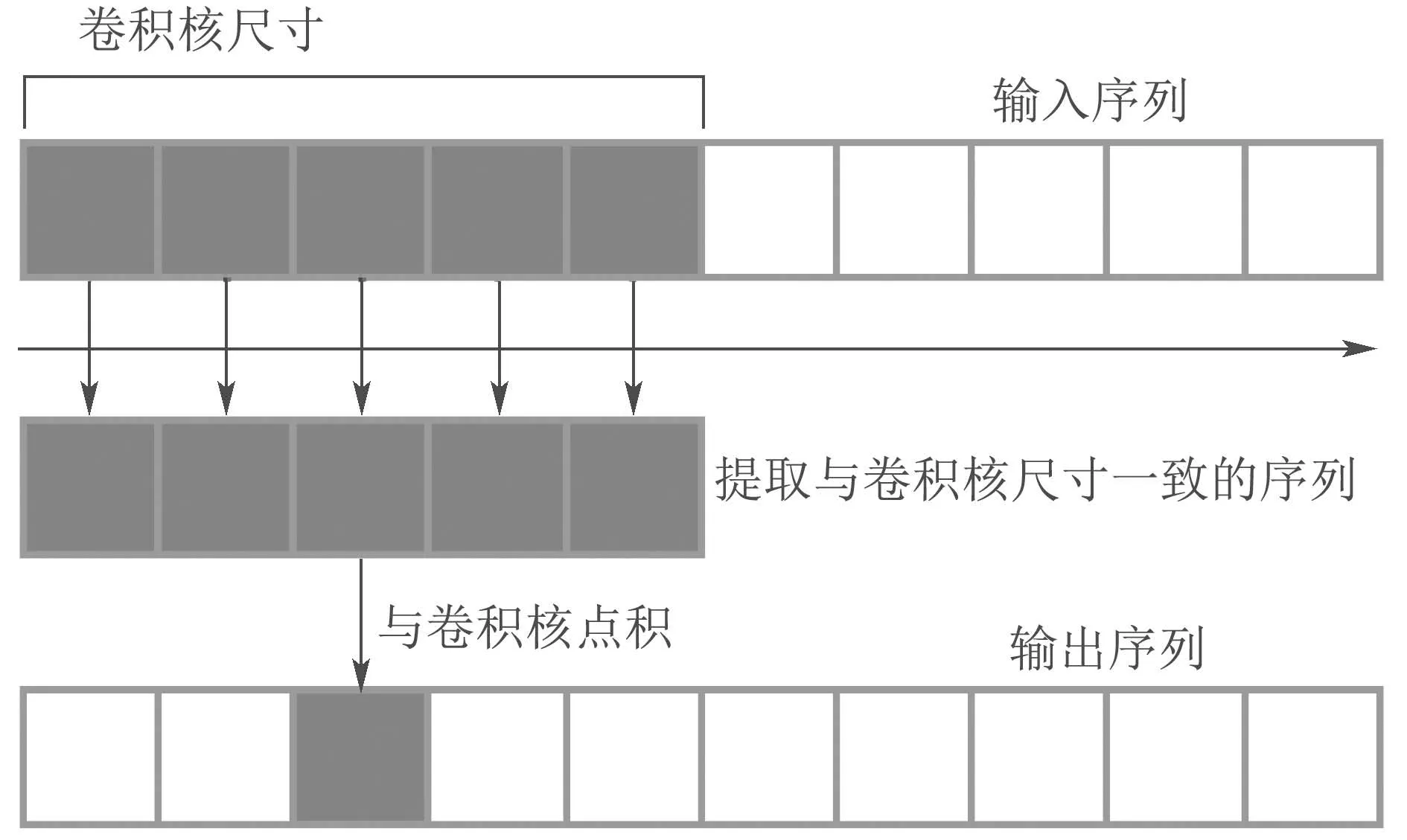
图3 一维卷积计算流程Fig.3 Convolution calculation flow
卷积核沿着输入序列移动,每移动一次就与序列的对应位置做内积提取特征.假设卷积核长度(kernel size)为w,每次移动一格,序列长度为L,则输出序列的长度为L −w+1,若规定对边界进行填充,则输出序列的长度与输入序列保持一致.其中卷积核的参数也是通过误差反向传播算法优化迭代.
3.3 全连接层构造
在实际使用LSTM时通常在输出端连接全连接层进行降维,本文在LSTM输出端连接一层含有1个神经元的全连接层,同时使用sigmoid激活函数将最终结果映射到0–1表示异常的概率.激活函数见式(9)
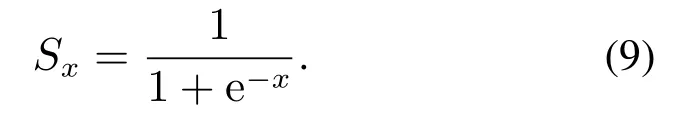
当x=0时,Sx=0.5,当x趋近于正无穷时,函数值趋近于1,当x趋近于负无穷时,函数值趋近于0.
4 钻井数据处理流程
搭建模型之前需要对原始数据进行一系列的处理,最终构造成适合模型输入的训练样本.整个流程包括采集实验数据、数据滤波、数据标定等.
4.1 实验数据收集
剔除掉部分由于设备故障导致的采集错误,此次实验总共使用川渝地区具有溢流记录的20余口井,采集周期4~5 s.每口井包括73个字段,可分为描述信息与钻井工程参数,描述信息包括日期、层位、钻头尺寸等,钻井工程参数包括转盘转速、大勾负荷、钻时、总烃、钻井液密度等.训练井与测试井的比率为3:1.部分井信息见表1.

表1 部分溢流井记录Table 1 Partial overflow well records
4.2 钻井数据滤波
钻采数据一般通过安装传感器进行采集,但是井场环境复杂,干扰较大,经常会出现急剧增大,减小的跳变点,这些异常点对模型的精度有较大的干扰,所以需要剔除掉.考虑到不同井的数据具有不同的变化范围,很难找到统一的标准,因此采用中值滤波算法对数据进行处理,该算法不需要考虑不同油井数据之间的差异性,具有较强的通用性.
算法的主要思路为,对于钻井序列中的某一采集点,用以该点为中心,给定长度序列的中位数进行替换,假设数据序列是x1,x2,···,xn,按从小到大排列后的新序列为y1,y2,···,yn,记新序列的中位数为ymedian.
当n为奇数时,中位数为

当n为偶数时,中位数为

4.3 标记
精准的标记可以提高网络的识别准确率,减小产生误判的可能性.通过比对钻井现场日志以及与钻井专家就标记问题进行探讨,将坐岗人员主要监测的字段作为模型输入,包括立管压力、出口流量、总池体积、钻时等.
根据这些字段的变化趋势,对每口井中的溢流段,正常段进行抽取,凭借专家经验对数据进行标注,0表示正常钻井段,0.5~1表示溢流的可能性从低到高,0.5表示有气侵等情况需要注意,1表示溢流已经发生.部分标定参考见表2.

表2 标记参考Table 2 Mark reference
以单口溢流井为例,溢流段长度8~15 min不等,选取距离溢流记录点较远的数据作为正常段,普遍维持在30~45 min,最终所有溢流井正常样本4500组,异常样本13500组.
4.4 z-score标准化
录井数据各个字段之间量纲差异性较大,使用zscore标准化处理数据有利于网络的训练,在梯度下降时收敛更快,相较于最大最小归一化方案,均值、方差比极大极小值更有普适性.在本文中,z-score标准化公式为

其中:Xscale是标准化后的数据,X代表当前样本;u代表均值,σ为方差.
5 模型训练
本文在模型的训练过程中,通过对比实验结果得出表现相对最好的预警模型,包括模型的结构、自适应窗的长度.
5.1 结构训练
分别搭建单层长短期记忆网络、双层长短期记忆网络、一维卷积叠加长短期记忆网络,以模型的损失以及测试井上的性能确定初始的网络结构.
将训练井的数据进一步划分为训练集、验证集,其中验证集不参与模型的训练,在模型完成一轮训练后用来校验模型性能.目前采取的训练方法为,每当验证损失下降时就保存模型,目的是寻找全局最优参数.
漏警表示模型对确定的异常段给出较低的预警值,虚警表示模型对确定的正常段给出了较高的预警值.训练结果见表3.

表3 模型结构实验Table 3 Structural design experiment
在实际钻采作业的过程中,漏警相对于虚警是比较严重的,虚警只是耗费人工进行排查,为了避免风险是可以接受的.当前数据集的情况下,优选的网络结构为一维卷积叠加双层长短期记忆网络.
5.2 滑动窗口长度分析
在正常钻进过程中,伴随着数据的小范围波动,如果时间窗太短会捕捉到这种波动特征导致模型虚警,随着时间窗的长度加长,这种小范围的波动会被平均值所抵消,所以虚警率会随之下降,同时某些溢流特征也会由于平均值计算而被抹去,模型会漏警.
在确定模型结构的基础上,结合实际情况分别取不同窗口长度做对比实验,统计模型在不同窗口长度下的表现情况,综合得出最佳窗口长度,实验统计结果如表4所示.

表4 窗口长度与模型性能Table 4 Window length and model performance
漏警次数的优先级别最高,经过上述实验,目前模型的滑动窗口长度取为50个数据点.
6 离线数据验证与现场部署实验
离线实验使用已有的数据集测试模型,将结果结合录井日报与钻井专家校验标注进行对比分析.现场实验则将模型部署于实际钻采井场,实时读取接受采集软件传送的数据并返回模型计算结果.
6.1 离线数据验证
下图分别是在井编号为w204hxx–1(图4),zsxx3(图5)两口已经完钻的井上做的试验,其中纵坐标表示溢流风险的概率,范围0~1,将原始钻井数据的时间字段转换后作为横坐标.

图4 离线试验(1)Fig.4 Off-line test(1)

图5 离线试验(2)Fig.5 Off-line test(2)
查阅录井日报,w204hxx–1于t=840 s记录气侵异常,停止钻井进行后续处理.钻井专家对井场数据进行复验,发现t=651 s钻井液烃含量上升,总池体积缓慢上升,确定产生气侵异常并进行了后验标注,模型的预警结果于t=615 s开始上升,提前于专家监测到异常,吻合度较高.
查阅录井日报,zsxx3于t=431 s记录溢流,随后钻井工人关井进行后续处理,专家根据采集数据以及井场实际记录,确定t=278 s左右出口流量上升,立管压力缓慢下降,对数据进行了后验标注,模型的预警结果在t=328 s开始上升,虽然相较于专家的后续标注延迟了50 s,但是提前于井场人工记录103 s.
通过离线实验,提出的模型具备一定的预警能力.接下来,为了更好的验证以及后续模型的优化,将模型部署到现场采集平台,对现场钻井过程进行实时预警.
6.2 现场实时预警
根据现场实时采集的特点,构造出适合的模型调用方案,包括存储数据的队列长度维护、异常点去除、调用模型、结果存储等,具体流程如图6所示.
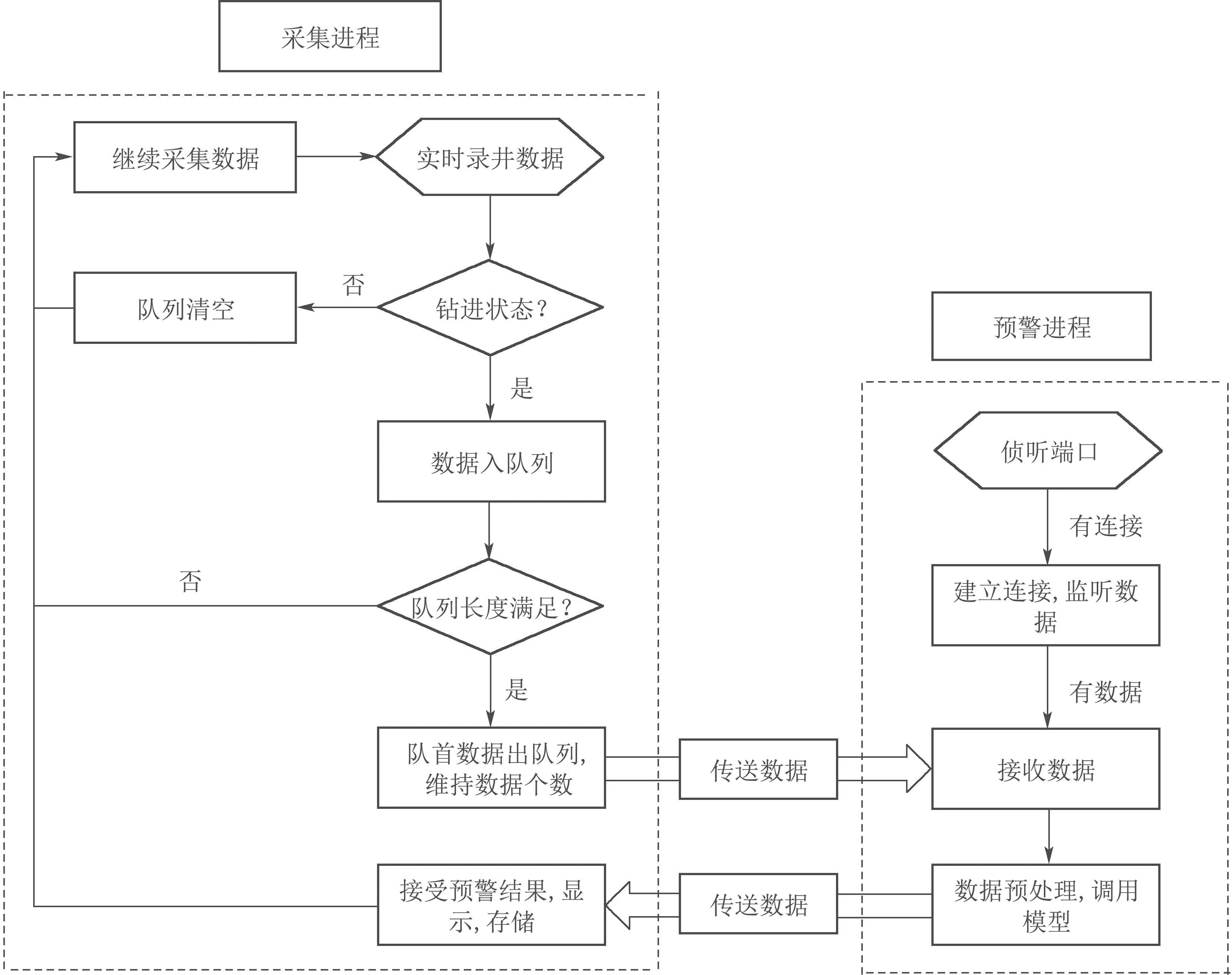
图6 实时流程图Fig.6 Real time scheme
目前为止,模型只对钻进状态进行预警,所以在流程图中不考虑非钻进状态,在队列中的数据满足输入后,采集软件将数据通过TCP发送到预警算法,算法处理数据计算出当前溢流风险值返回给采集软件.
将模型部署到某钻井平台进行实时验证,把数据库中的预警结果导出,挑选部分绘制见图7.

图7 在线预警Fig.7 Online warning
查阅录井日报,pl0xx1(图7)在t=242 s左右出口流量与总烃含量缓慢上升,预警模型于t=202 s开始上升,推测应该是钻遇气包,其中气体浸入钻井液随着环空上返,在中途一小段时间内出口流量上升速度减缓,模型预警值有所下降,后续由于气包内的气体源源不断浸入钻井液,出口流量上升速度加快,预警值也逐渐上升,在气体排完后,出口流量与总烃恢复正常,模型预警值降低,结果与专家校验数据后的标注吻合度较高.
6.3 模型评估
模型离线验证,在线预警的应用结果表明,该算法的设计具有一定的合理性与先进性,对于提高钻井作业的溢流复杂预警水平,减轻操作人员的负担,降低事故发生风险有积极的意义.现场人员无需时刻关注录井参数的变化情况,只需要在模型输出达到较高值后进行复验,如果目前有溢流风险则表明模型成功预警,若当前没有风险,则表明模型虚警,将对应的数据记录用于后续模型的更新优化.
截止到目前,模型仍然存在虚警和漏警等问题,数据覆盖面不足是主要原因.钻采是一项复杂的工程,由于不同区块、井眼尺寸、钻具组合、层位等众多因素,导致正常状态或者气侵溢流都对应着许多不同的模式,仅凭一个模型识别所有状态难度是极大的.后续研究应该就实际预警效果,吸取现场使用人员和钻井专家的建议,在此基础上不断的改进完善,希望发挥更全面,稳定的作用.
7 结束语
本文在基于钻采现有业务知识与数据信息的基础上,对当前存在的溢流预警方法适应性较低的问题做出了改进,提出了一种自适应的LSTM预警算法,该算法基于滑动时间窗口扩充数据集,通过平均值增量计算实现自适应特征提取,具有一定的通用性.
通过离线测试和在线实验,结果表明本文提出的自适应预警方法在实际钻采环境下表现良好,以较低的虚警率完成对溢流早期的及时预警,为现场人员处理溢流争取了宝贵的时间,确保了钻井人员的安全与钻井过程的高效性,对提高钻井过程溢流预警水平具有积极意义.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
新民周刊(2017年11期)2017-04-05
珠江水运(2015年12期)2015-07-25
中国水运(2015年5期)2015-07-13
中国水运(2014年7期)2014-08-11
科学时代·上半月(2013年6期)2013-08-22
