
基于Graph Transformer的知识库问题生成
2022-04-12 04:15周光有
中文信息学报 2022年2期
胡 月,周光有
(华中师范大学 计算机学院,湖北 武汉 430000)
0 引言
问答(Question Answering,QA)系统利用信息检索,在海量的非结构化或者结构化的数据中推断自然语言问句的答案。问答任务是人工智能的核心研究之一,就目前所研究的QA而言,大部分的训练数据都是以QA对作为标注数据,例如,基于知识库的SimpleQuestions[1]数据集,基于文本的Wiki QA[2]数据集,以及阅读理解所用的SQuAD[3]数据集等。这些数据集受规模大小等条件限制,且标注花费昂贵,随着问答系统、阅读理解等领域的发展,对标注数据的需求越发强烈,因此,本文探索的问题生成(Question Generation,QG)任务可以为QA系统的研究提供一个扩充数据集途径。
当下,QG任务开始逐渐成为一支有力的研究方向。给定一篇包含多个事实/知识点的文本和标准答案,传统的QG任务根据答案与这些事实逆向生成内容丰富、角度多元化的问句。随着深度学习研究的推进,QG任务也开始具有了多样性。给定一些数据,例如,结构化的知识图谱或SQL,半结构化的表格,甚至无结构化的文本等,QG系统都能根据输入的数据自动生成自然语言的问题。问题生成虽然不是新兴任务且其研究领域较为小众,但随着图像处理、自然语言处理等各领域研究的相互影响,使得研究者们开始将注意力放在了QG任务上。基于知识库的QA系统很难理解自然语言问题,依靠目前常用的知识图谱和数据库也不一定可以回答出该问题。由于QG系统可以从已有的知识库生成QA系统需要的标准“问题-答案”对数据,故当出现一个新问题时,QG系统生成的问句与已有的“问题-答案”对进行相似计算,向用户推荐知识库内已存在的相接近的问题,间接解决问答的问题。此外,由于能够与QA任务共用数据集,如给定知识库时,生成的问句可以为基于知识库的问答系统提供更大的训练数据集,与基于知识库QA任务的可成为对偶任务。传统的QG系统使用人工设定的模板或规则来生成问答对解决特定领域的QA任务。本文着重于结构化知识库上的QG任务。传统的问题生成方法多采取模板的方式。例如,Duma和Klein[4]使用关系定义的模板来生成简短的描述,并相应地替换主语和宾语实体的占位符标记。另外Seyler等人[5]从知识库三元组中生成问句,实体与谓词的表达由它们在知识库和给定词典中所存在的标签决定。Seyler等人[6]参考基于模板的方法来描述结构化查询并生成自然语言问题。然而,这种基于规则的方法无法识别单词的语义内容,且可扩展性较弱。
如今随着深度学习的热潮,尤其是随着Sequence-to-Sequence[7](Seq2Seq)框架和编码-解码结构[8]为自然语言生成[9]任务带来了新的研究方向,并在机器翻译[10]、智能对话[11]等任务获得优异的成绩,一系列以基于神经网络的QG系统被提出。Serban等人[12]采用基于注意力的编码-解码框架在SimpleQuestions数据集上训练模型,并生成了30MB的标签数据。Khapra等人[13]将给定知识库中的所有实体转换为一组关键字,然后以Seq2Seq结构进行建模。ElSahar等人[14]采用Zero-Shot使模型能够泛化未遇见过的谓词和实体的问题。Wang等人[15]在Seq2Seq基础上加入复制机制[16],使模型能解决OOV问题。
上述生成模型只考虑到对未出现过的三元组或低频出现的生僻词的解决方法,但对于生成信息量丰富和多样化的问题的考虑有所欠缺。受Cai[17]和Koncel-Kedziorski等人[18]工作的启发,本文着重于加强对三元组的多粒度语义特征表示,采用双编码层: 基于Graph Transformer的图编码层和基于BERT[19]加强的词级编码层。本文预先将知识库中的实体、关系构成知识图谱,赋予实体全局化的语义向量,然后针对该三元组,结合Transformer结构[20]的并行性对输入节点进行特征细化。同时,为了充分利用词语粒度的语义向量,三元组的词语序列先通过BERT预训练模型获取向量表征,再使用双向门控循环单元(Gated Recurrent Unit,GRU)[8]网络计算上下文向量。最后,本文将两个编码层联合获得更完善的三元组特征表示,再输入解码层生成问句。本文在英文数据集SimpleQuestions上进行实验,实验的评测结果证明了该方法的有效性。综上,本文的贡献如下:
(1) 基于知识库的QG模型,率先提出使用基于Graph Transformer的方法为实体获取丰富的背景信息;
(2) 为完善三元组的特征表示采用图和词级的表示,结合知识图和BERT分别进行初始化,再用神经网络对其泛化;
(3) 自动评测和人工评估的结果表明,本文模型生成的问题信息量更丰富,表达形式更多样化。
1 模型设计
为了解决知识库中单个三元组存在背景信息量少、语义表达不够完善等问题,受Koncel-Kedziorski[18]和Cai[17]等人的工作启发,本文采用具有图神经网络特征的Transformer结构作为编码层,结合知识图谱对实体和关系进行表示,以图的形式作为输入,并且还使用BERT预训练模型获得词语的语义表示。与Seq2Seq模型结合,从而针对任务目标规范适合本数据集的语义向量表示,以获得更准确的潜在语义,使得模型生成的问题更加丰富流畅。
1.1 模型结构
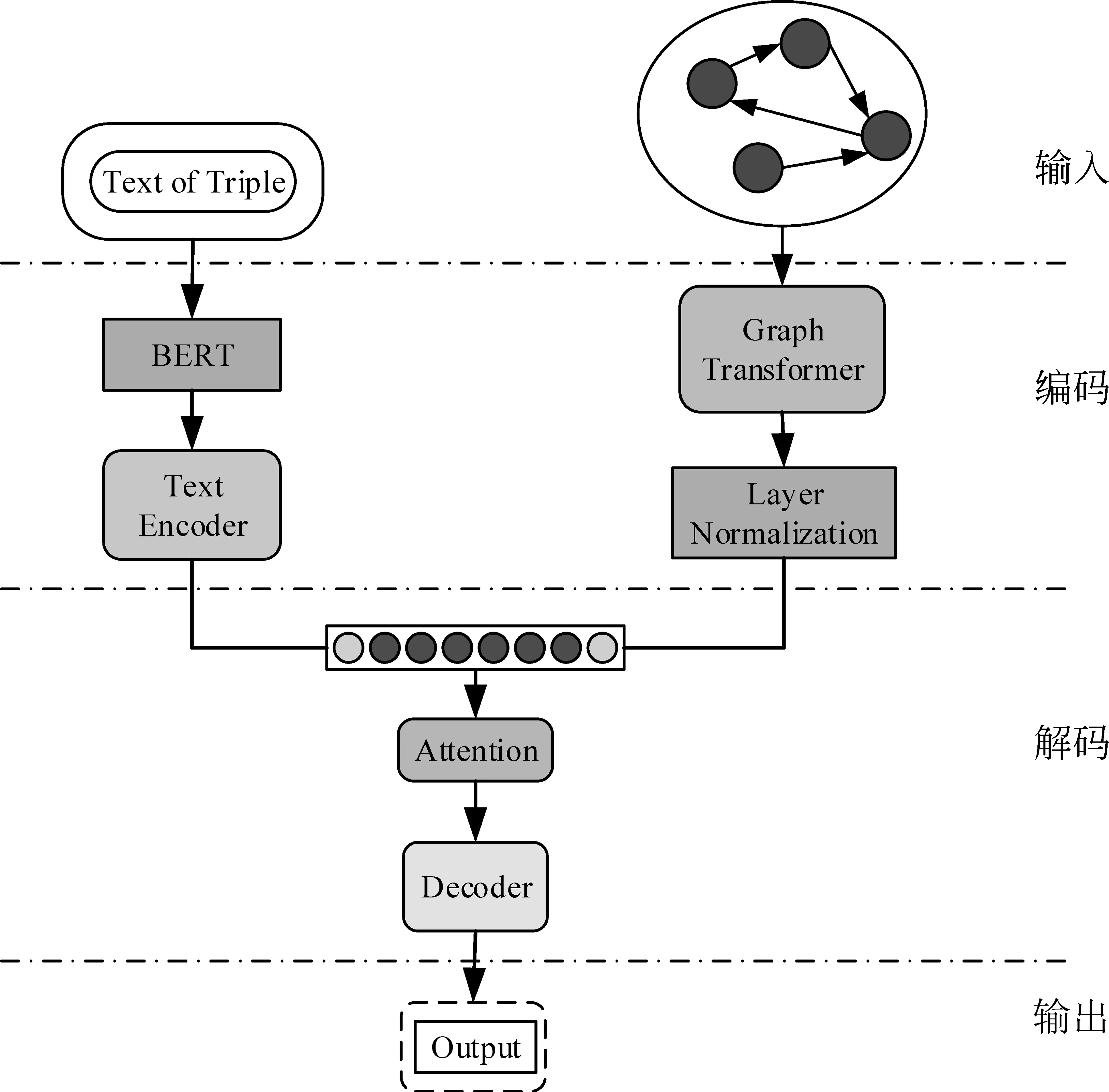
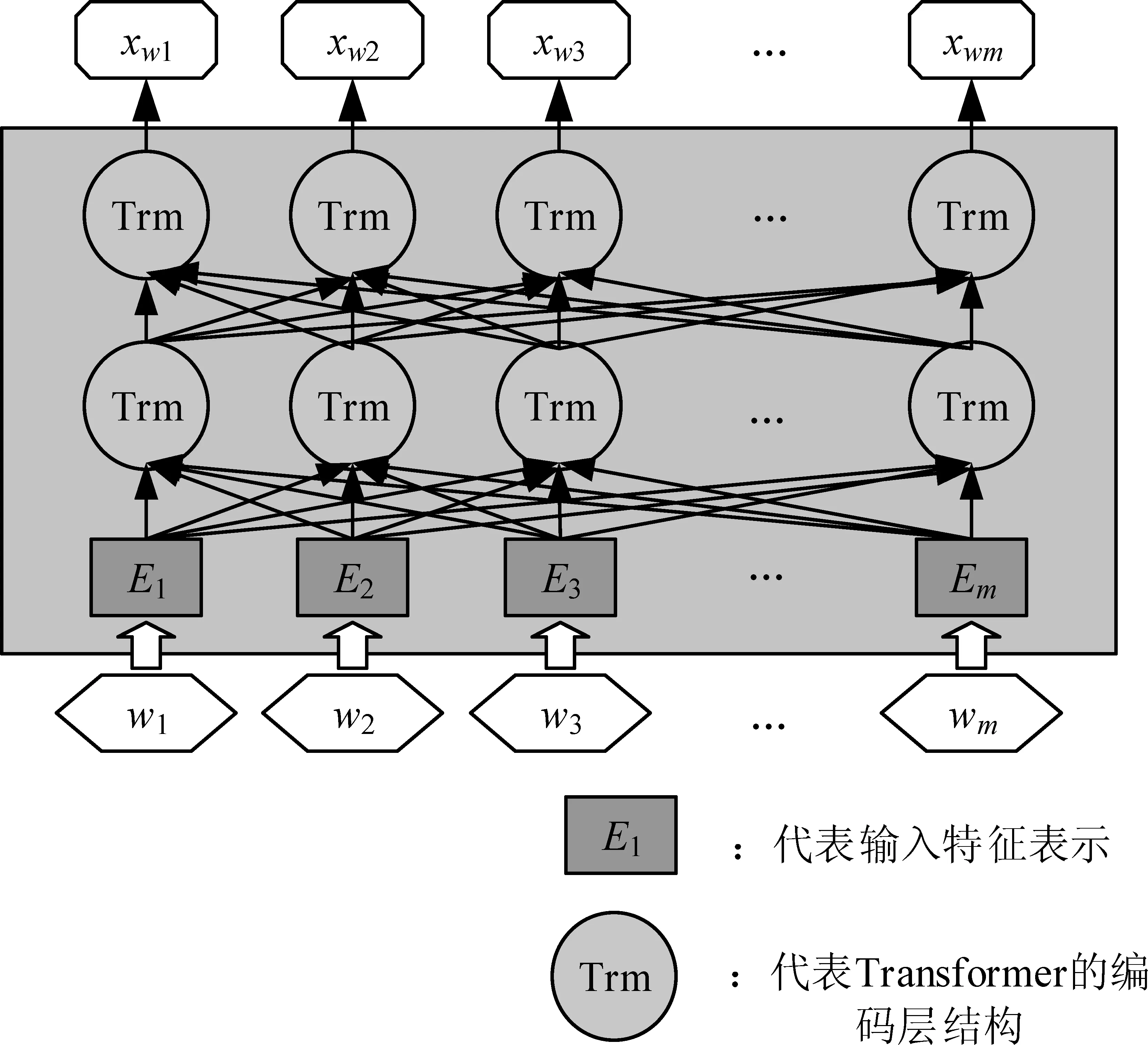
图1 模型结构图双编码层在解码端连接
本节将介绍基于Graph Transformer(GT)的知识库问题生成模型(简称GT-KBQG)[20-21]。GT-KBQG模型的结构如图1所示,该模型由三个模块组成,分别为GT编码器、基于BERT预处理的文本编码器,以及基于Attention机制的GRU解码器。具体来看,首先三元组进行构图预处理,之后使用GT编码器对三元组在图中的向量表示etriple=(es,pr,eo)进行编码,同时以自然语言文本形式表示的三元组w={w1,…,wi,…wm}通过BERT预处理转换为向量形式xw={xw1,…,xwi,…,xwm},通过双向GRU编码器编码。然后将以上两个编码层结果结合作为解码器的隐藏层初始化状态,解码器结合Attention机制[10]获得上下文向量,以此加强问题的生成效果。
1.2 基于Graph Transformer的图编码层
为了让实体之间的联系更加紧密和结构化,有学者将其构成图的形式(实体为节点,关系为边),即知识图谱。本文利用已构成的知识图谱赋予数据集中的三元组丰富的背景知识,结合Transformer结构,在丰富的背景知识中抓取对本数据集针对任务有利的语义信息,使实体之间获得更紧密的关系,使单个实体的语义向量也更加丰富。
1.2.1 知识图谱预处理
英文知识库FreeBase[22]的实体原始表示为独立的id形式,且FreeBase主要由社区成员收集整理,数量庞大,常被视为可靠的知识图谱。SimpleQuestions数据集基于FreeBase得到,故其原始实体也是id形式,为了使模型能够获取更多的实体背景信息,本文将以大规模知识库预先训练获得的知识图谱作为SimpleQuestions数据集中实体的信息网背景图。与词嵌入的思想一致,本节主要是获得知识图谱的嵌入(Knowledge Graph Embedding,KG-Emb)[23]。
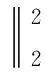
本文选用TransE方法对事实三元组进行图的预处理,将实体作为整体转为向量的表示。选择TransE主要有以下几个考虑: 首先,与其改善结构如TransH、TransR等相比,TransE的参数较少;其次,TransE的主要层次关系的表示非常有效;最后,所有关系模型在多关系的实验分析中, TransE的效果良好。本文直接采用了Huang[27]等人在FB2M数据集上所提供的基于TransE的KG-Emb。
1.2.2 Graph Transformer
本文使用预处理后的知识图谱作为KG-Emb,本编码层的输入是具有全局语义信息的实体和关系,并基于Transformer结构,在全局图的背景语义下进一步捕捉主语实体、关系、宾语实体之间的关联,使作为输入的三元组具有更加符合本任务的语义粒度表示。Vaswani等人[21]提出的Transformer结构,通过全局上下文建模的多头自注意力机制来实现高效且并行的计算,具有并行性的优点,克服了RNN的在长序列上的顺序计算结构的缺点。
作为图编码器,GT参考Transformer编码层结构,由几个相同的网络块组成,根据其并行计算特性,输入节点之间可直接进行信息传递,图2表示的为单个网络块,左边部分的eo、es和pr分别表示从KG-Emb中获取的主语实体、宾语实体以及谓词的语义向量,通过Graph Transformer结构计算抓取语义信息,使实体向量更加丰富和符合本文任务。
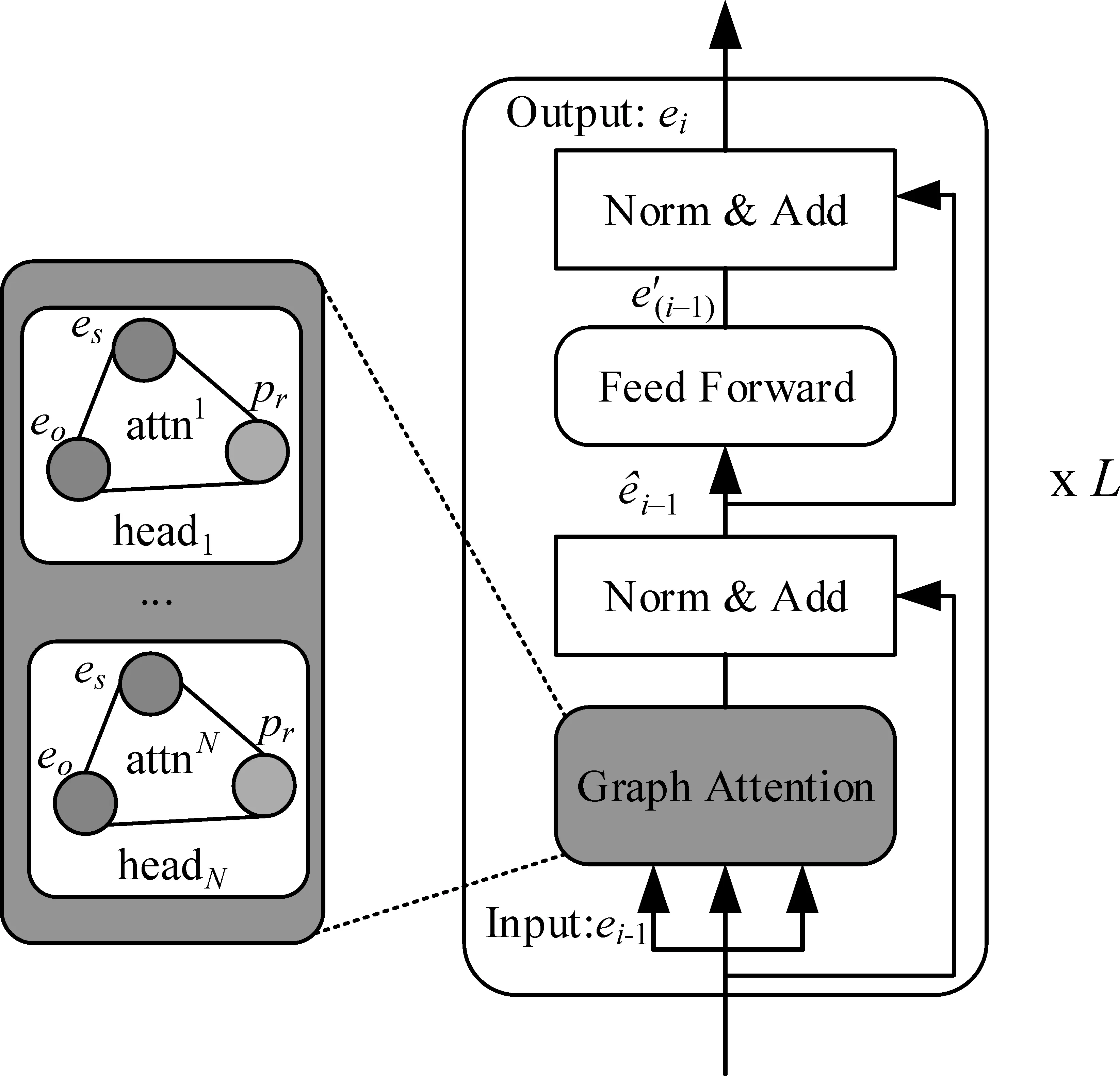
图2 Graph Transformer结构
本文使用N头注意力机制在图2所示的网络块中堆叠L次,在输入残差网络之前进行拼接。Graph Transformer的具体计算如式(1)所示。
(1)
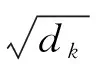
(2)
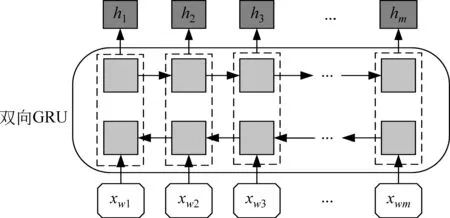
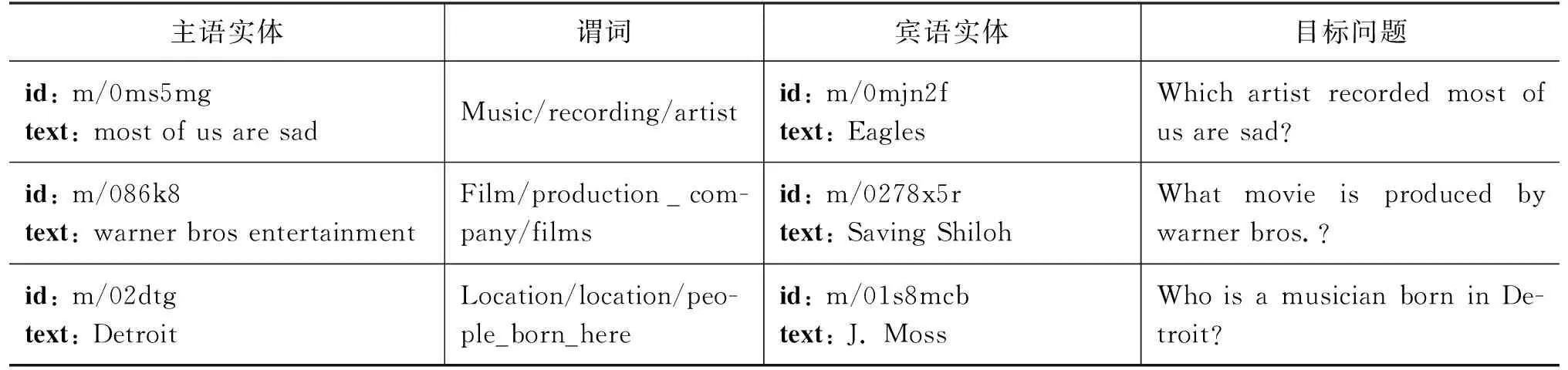
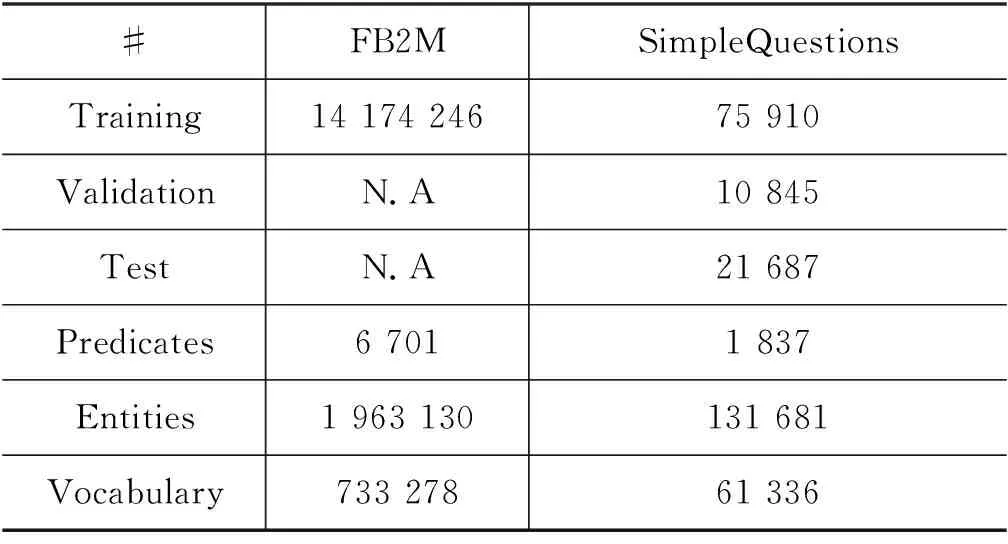
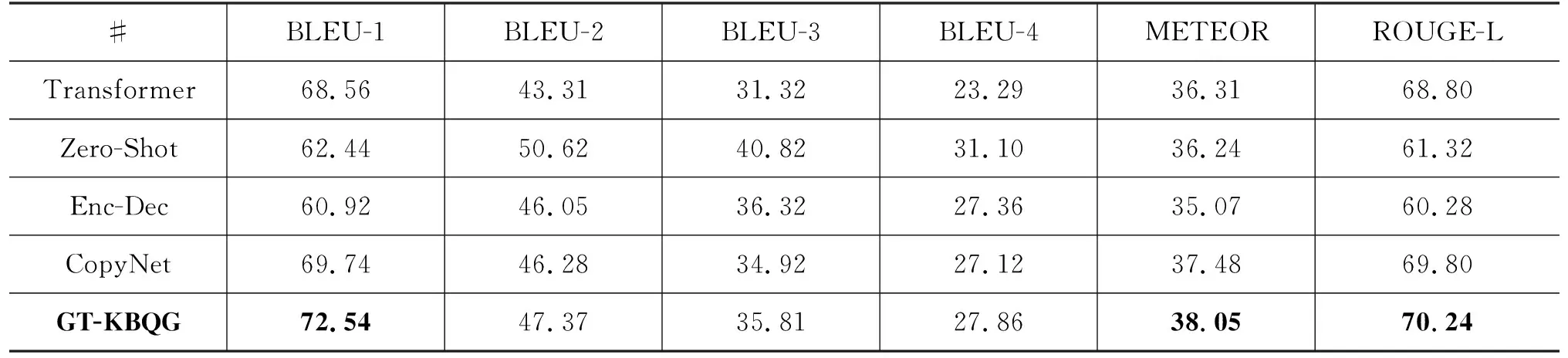
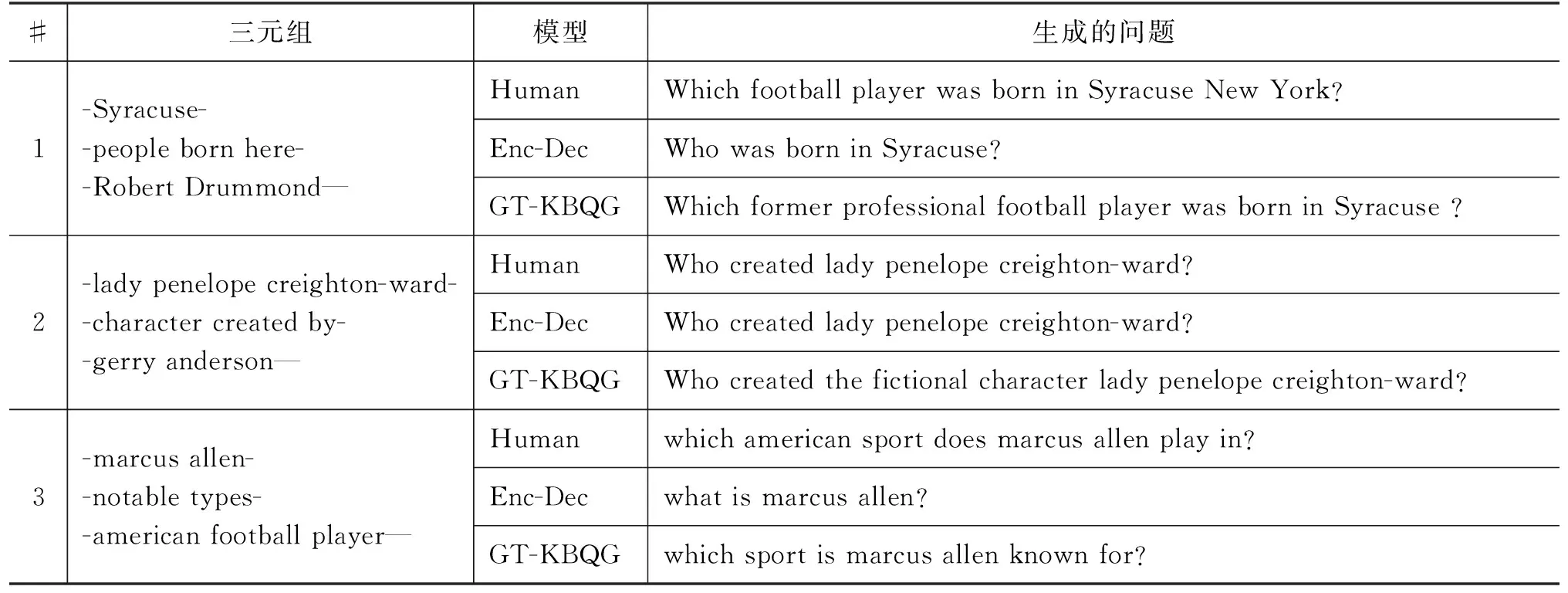
式(1)和式(2)中出现的qi、ki、vi是第i(i (3) 其中,ei由第i-1层标准化计算得来,即为第i层的输入。通过块状网络扩展多头注意力层,如图2所示,每个块状网络都具有衔接层转换,如式(4)、式(5)所示。 式(5)中,第i层的最终输出作为第i+1(≤L)层的输入。式(4)中,FF(·)为两层前馈网络,其中,LN为标准化层,两层之间具有非线性变换,本文选取ReLU非线性变换以及残差网络的前馈进行计算。通过知识库构图之后,每个实体和关系拥有对应的向量化表示,实体与关系的拼接作为i=1时的初始输入,如式(6)所示。 e1=Concat(es;pr;eo) (6) 图1中的Layer Normalization层,对最终的输出结果eN实行层标准化如式(7)所示,与词级编码层进行融合。 eN=LNoutput(eN) (7) 多个块状网络的堆叠使得信息可以从图进行传播。从GT编码层输出的最终结果与下一节的文字编码结果进行组合作为解码器端的输入。 在2018年,Jacob Devlin等人[19]提出BERT预训练模型,在自然语言处理领域获得极大的反响,在预训练和精调下,刷新了十多项NLP任务的记录。BERT是基于Transformer结构的Encoder,其并行结构擅长捕捉长距离依赖,避免了RNN的顺序结构带来的缺点。BERT为双向Transformer结构,未标记文本的深层双向表示由所有层的双向上下文共同进行条件化来预训练。与已提出的预训练模型相比,经过巨量语料训练的BERT具有捕捉到真正意义上的双向上下文信息的能力。由于BERT的出色表现,在Python库中已经收纳整理了可以调用的BERT函数库,使用者安装好BERT环境(1)https://github.com/hanxiao/bert-as-service,再自行将所需数据导入就可以直接使用。SimpleQuestions数据集中实体原始为独立的id形式,而在目标问题中用自然语言的单词形式表示,且id形式尽管可以展现出实体的唯一性,但实体的描述词语中会出现一些语义相通的词汇,有助于问题的生成,所以本节将三元组的实体以自然语言形式作为模型输入的一部分。本文主要考虑通过表现良好的语义表示来生成问句,以此来验证这些表示是否在本任务中有效。考虑到BERT在编码方面表现优异,本文用其捕捉词语级别的表示。 由上文可以了解到,Transformer擅长捕捉长距离信息,适用于长文本任务。而三元组的词级输入为短字符串,采用顺序计算结构的GRU作为编码器更有优势,通过GRN双向编码,获得三元组词语粒度的嵌入向量表示。首先,通过BERT预处理泛化每个词的嵌入向量的语义信息,再采用双向GRU的最后一个隐藏状态作为每个词生成d维嵌入,如图3所示。 图3 BERT预处理结构图 图3中,每个输入三元组表示为单词型序列w={w1,…,wi,…,wm},调用BERT函数进行预处理编码,得到维度一致的向量矩阵xw={xw1,…,xwi,…xwm}。然后,将经过BERT预处理后的语义向量输入文本编码器中,即图3的词级编码器(Text Encoder),其由双向GRU对xw进行正向和反向读取来抓取输入序列xw的有效语义信息,详细结构如图4所示,式(8)和式(9)可表示该过程。 图4 Text Encoder结构图 s0=ReLU([eN;hm]Ws) (10) 本文的解码器用来预测生成语义上流利且合适的简单问题,由于Transformer的并行结构性能效果非常好,我们观 察了在Transformer结构上的任务,发现优良的并行结构使得模型在计算时存在注意力过长的问题,导致了生成的序列中出现了与输入不相关的词汇。 由于本文任务生成简单问题而非长序列,顺序结构的RNN类网络每步的预测计算都依赖上一步的输出,其过程更贴合本文的任务目标。因此,本文使用基于注意力机制的GRU作为解码器。生成第t个单词的概率分布如式(11)所示。 (11) (12) 当前t时刻的隐藏状态st和通过注意力机制计算上下文向量ct的详细计算由式(13)和式(14)给出。 其中,αt为第t时间步的对齐向量,详细计算如式(15)所示。 (15) 为了保证生成问句时句子主语的完整性,本文采用模板方法,将主语用占位符表示,在完成预测之后,再将问题对应的三元组主语补充上去。 本文使用了具有id形式的英文数据集SimpleQuestions,表1为文本与id形式的问答对示例。本文的输入分为两部分。 表1 SimpleQuestions数据集id和文本形式样例 其一为对三元组进行构图预处理之后的实体-关系的向量表征。在实验过程中,对输入三元组进行构图操作,FreeBase被视为可靠的知识库,SimpleQuestions中所有事实基于FreeBase。由于FreeBase规模巨大,故在一些研究工作中,对FreeBase实行子集提取,如FB2M、FB5M等。SimpleQuestions中的三元组可在FreeBase的子集FB2M里查询到,故本文选取Huang等人[27]所提供的基于FB2M训练TransE得到图嵌入作为本文KG-Emb。表2列出了FB2M与SimpleQuestions两者的具体信息。 表2 数据集统计信息 其二为自然语言形式下的文本三元组通过BERT预处理之后的词向量表征。BERT预处理模型经过海量数据的预训练,可以赋予词语更完善的语义向量。并且,在编码端无需人为构造单词表,所有单词都可由BERT获得语义信息丰富的向量表征,这可以减轻诸多实体里出现的大量低频词汇所带来的单词量的压力,以加快模型的计算速度。 本文使用了一组在自然语言处理领域中较为完善的自动评估指标来评测模型效果: BLEU[28],METEOR[29],ROUGE-L[30]。考虑到语言表达的复杂性,本文还采用了人工评测的方法,邀请三位自然语言处理领域的研究生对生成的问题进行评估。 BLEU: BLEU在翻译任务中最早被使用,是将候选文本与一个或多个参考文本进行比较的评估标准。它是一种语法度量,用于计算生成的文本与参考文本之间的n元重叠。由于BLEU只考虑单词的连续匹配准确率,故其无法考虑到句子的语法以及语义方面的效果,如BLEU-1考虑的是单个单词之间的匹配度,BLEU-2则考虑连续两个单词的匹配度等。 METEOR: METEOR是基于准确率与单词召回率上的加权调和平均数,其目的是改进BLEU标准固有的一些缺点。它还考虑到了一些其他指标没有发现的功能,例如,同义词匹配等,使其与人工评价的效果距离更近一步。 ROUGE-L: ROUGE是使用基于召回率的相似度量进行计算的指标,其基本思想是使用模型生成的文本和参考文本的n元组共现概率作为评价的基础,但无法评价句子是否流畅。在本文的评估中,选择ROUGE-L作为评估标准,其基本思想是匹配两个文本单元之间最长的公共序列。 人工评估(Human Evaluation): 尽管自动评测在某种程度上可以估量生成的问句与参考问句有多相近,但是当语义相近而语法表达结构不同时,许多隐藏着的限制就显示出来。由一个目标问句和两个模型预测的问句组成的一个例子可以更清楚地说明这个问题,如表3所示。尽管表中的三个句子在语义表达方面类似,但是利用自动评测标准来度量时分数差距却有将近20个百分点。此外,自动评测也不能确定是否有三元组中相关的关系词出现在预测的问句中。因此,人工来评测给出句子的流畅度与相关度是必不可少的。 表3 BLEU值得分举例 本文做了多个对比实验以证明提出方法的有效性,具体的对比模型如下详释,Zero-Shot与 Enc-Dec 模型的计算以及预处理保持与原始文章一致,其余模型保持与本文一致的预处理,但不加入图层次的编码层。 Transformer[21]: Transformer是当前在机器翻译任务上非常火的模型。本文使用Transformer作为一个对比实验,观察它在此文任务中的表现。 Zero-Shot[14]: Zero-Shot利用特殊标识符替代关系词以解决在测试集可能出现的而在训练集里未出现的关系词的问句。在该模型中,SimpleQuestions数据集三元组的实体和关系以TransE嵌入为初始化。 Enc-Dec[12]: Enc-Dec是根据Serban等人的工作来实现的。本文只使用了单占位符,Serban等人还使用了多类占位符(MP)作为输入序列,但由于在文章中并没有将这些占位符的类别罗列出来,并且MP所带来的贡献并不大,故在本文的实验方法中,不能报告以MP作为输入的实验结果。 CopyNet: Wang等人[15]在基于知识库的QG任务上融入了复制机制,本文复现了融合复制机制的CopyNet模型。 本文使用多编码层,在单词粒度上的编码器使用双向GRU结构,每个GRU隐藏节点数为500,由BERT初始化词向量,维度为768;基于图的编码器使用5个多头注意力机制和4个循环块的Transformer结构,使用TransE对三元组进行构图初始化,维度为250。解码器使用结合Attention的单层GRU结构,每个GRU隐藏节点数为1000,用GloVe[31]预训练好词嵌入对词向量初始化。本文基于Tensorflow平台[32],采用Adam优化算法[33]。学习率初始化为1e-3,每500步进行一次衰减。模型使用mini-batch方式训练,batch大小设置为64。 2.5.1 自动评测 如表4所示,GT-KBQG在BLEU-1、BLEU-2、METEOR和ROUGE-L指标上性能提升效果明显。Transformer模型虽然具有并行性的计算优势,但仅靠输入的单个三元组获取的语义背景信息始终不够完善,依赖并行结构的特征,其得到的效果虽然在BLEU-1上优于Zero-Shot和Enc-Dec模型,但在BLEU-2,BLEU-3和BLEU-4指标上均逊色于Zero-Shot模型。与Enc-Dec模型相比,GT-KBQG在METEOR(+2.98)和ROUGE-L(+9.96)指标上性能提升非常明显,从一方面说明GT-KBQG生成的问题与目标问题的语义和词语共现效果更好,但在3-gram和4-gram重叠(BLEU-3、BLEU-4)匹配上,效果却不明显,说明了词语共现性提升,但可能表达形式更丰富,故在多元匹配上与目标问句相符的较少。与其他基准模型对比,CopyNet模型效果提升也十分明显,但由于其着重于对三元组中出现的低频词进行处理,而未考虑信息表达的多样化,故在1-gram和2-gram上的词语共现不如GT-KBQG,且在BLEU-3和BLUE-4上的效果也逊色于Zero-shot模型。虽然在BLEU-1的匹配上,GT-KBQG效果最优,但是在多元匹配上与Zero-Shot依然存在差距。根据后面的人工评价,我们推测是因为与参考问句的一致性导致的。多元匹配对词语组成问句序列具有严格要求,但由于GT-KBQG模型的BLEU-1效果最好,又说明本模型具有与参考问句相匹配的更多个词语,推测是因为在语句表达形式上与参考问句一致性没有Zero-Shot高,但在总体的语义表达上,METEOR(+1.81)和ROUGE-L(+8.92)又优于Zero-Shot,说明虽与参考问句表达形式一致性不高,但是表达目的应该是一致的。 表4 自动评估结果 2.5.2 人工评价 由于语言表述的复杂性,自动评测只能表现出针对单一目标问题的参考文本的效果,无法完全说明生成的问题是否合适。因此本文还以人工评价的方式对模型进行评估。表5中Sim.(similar)表示生成的问句与参考问句近乎一致的句子占被选评估集的比例,基线模型与本模型所占比例都达到一半左右,具有较高的一致性。本文除了要考虑生成问句的一致性外,还关注生成句子是否具有多样性,同时对背景信息描述是否丰富,表5中的Var.(variety)表示生成的问句比参考问句描述更丰富的比例。 本文在测试集中随机抽取三份数据用于人工评价,每份数据集有300个三元组-问题对,同时每份数据集以3个人参与,与标准问题以一对示例的形式进行标注。由表5所示,GT-KBQG 模型与目标问题的一致性不是最高,即在Sim.结果上,比Transformer(-0.99%)、Zero-Shot(-2.47%)、Enc-Dec(-1.42%)和CopyNet(-2.4%)的 结果都低,可以推测出目标问题比较简单,但也会出现不少具有实体描述信息的问句。但是在Var.上的评价结果GT-KBQG最好,比基准模型中表现最好的CopyNet高了13.67个百分点,这证明了本文对三元组特征表示的加强赋予模型更加丰富的背景信息,从而使生成的问句中的实体描述的信息更多。 表5 人工评估结果 (单位: %) 2.5.3 样例分析 在评测的结果上,只能基于评估数据对生成的问题进行推测分析,无法直观感受生成问句的质量效果,表6选取目标问题与Enc-Dec模型 GT-KBQG 模型进行样例对比。 根据表6中所展示的样例可以看出,比起 Enc-Dec 模型,GT-KBQG能生成更加具有描述性的问题,如在示例1和示例3中,Enc-Dec所生成的问题正确但非常简洁,实体描述信息非常少,该类问题可以有非常多的回答,若与QA系统作为对偶学习任务,可能会降低系统的准确度。相比以上两个模型,GT-KBQG对于提问对象“Robert Drummond”的描述更进一步,该问题提供了“Robert Drummond”的之前的职业信息“football player”,比Human对实体所述的信息更细,但比起人工生成的问题,GT-KBQG 的描述仅针对了对象实体,Human行对主题实体也进行了描述,可以让读者了解“Syracuse”处于New York。但总体上来看,与Enc-Dec模型相比,GT-KBQG生成问句时着重于对实体背景信息的描述,产生的问题更加精准化和多样化。在自动评测结果中,尽管对Enc-Dec模型进行了改善,但在多元重叠效果上并不太明显,对生成的问题进行人工评价,发现其原因除了模型自身依旧存在缺陷之外,与目标问题也有关联。例如,样例2,目标问题较为简单,Enc-Dec模型本身存在生成句简短的特征,故与目标问题完全匹配,而进行改善的模型尽管生成了更加丰富的实体背景信息,但在自动评测指标上的结果却不如Enc-Dec效果好,而GT-KBQG预测出的背景信息越多、越完善,其BLEU等自动指标结果值就会越低。 表6 样例对比 本文提出了基于Graph Transformer的问题生成模型,缓解了模型生成单一化的问题。与直接附加上下文信息作为输入的模型不同,本文仅对三元组本身的表示进行多样化加强,进而获得丰富的语义背景信息。在SimpleQuestions数据集上进行实验,与基准模型相比,人工评测与自动评测的结果证明了对三元组语义加强操作在一定程度上丰富了问题生成的多样性。本文尽管在实验结果上展现出较好的效果,但依旧有许多问题待解决,比如与人工生成的问题依旧存在差距,且遇到未涉及的三元组或实体关系时,需要一个更完善的图。在后续工作上,可以考虑构造出更大、更完善的知识图谱。由于时间、环境、设备、页面篇幅等因素的限制,本文提出的GT-KBQG模型只在SimpleQuestions数据集上进行了实验验证,未来的工作将会在多种数据集上进行研究,并将进一步进行消融实验分析。1.3 基于BERT增强词级表示的编码层
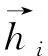

1.4 基于Attention机制的GRU解码层
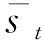
2 实验结果与分析
2.1 实验数据
2.2 评价标准

2.3 基准模型
2.4 实验设置
2.5 结果分析

3 总结与展望
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
计算机与生活(2022年3期)2022-03-13
北京大学学报(自然科学版)(2022年1期)2022-02-21
五邑大学学报(自然科学版)(2019年3期)2019-09-06
计算机技术与发展(2018年12期)2018-12-20
计算机系统应用(2017年5期)2017-06-07
长江学术(2016年4期)2016-03-11
海军航空大学学报(2015年1期)2015-11-11
人间(2015年21期)2015-03-11
长江学术(2015年1期)2015-02-27
