
基于神经网络的连动句识别
2022-04-12 04:14曲维光魏庭新顾彦慧周俊生
中文信息学报 2022年2期
孙 超,曲维光,魏庭新,顾彦慧,李 斌,周俊生
(1. 南京师范大学 计算机与电子信息学院,江苏 南京 210023;2. 南京师范大学 文学院,江苏 南京 210097;3. 南京师范大学 国际文化教育学院,江苏 南京 210097;4. 昆山震川高级中学,江苏 苏州 215300)
0 前言
通常情况下,动词是句子理解的关键,对句子的理解一般从动词入手。现代汉语中动词连用的现象大量存在,但相似形式所代表的语法结构和语义结构却不一定相同,有时甚至千差万别。在句子级别的语义研究方面,谓词所处的事件框架中包含的各种语义关系构成了句子的语义结构。连动句包含多个谓词,蕴含了十分丰富的知识。连动句表示的是多个事件,且这些事件相互依赖并呈现出语义上的时序、方式、目的、因果等关系[1]。因此获取连动句的方法将在自然语言理解领域中发挥重要的作用,有效的连动句识别可以在大规模语料中获取其中的连动句,从而便于对连用的动词或动词性短语之间的语义关系进行研究,有助于自然语言处理中句子级别的语义分析任务和句法解析任务的研究,获取连动句的方法将在常识获取、智能网页等人工智能应用领域中发挥重要的作用,同时也为其他特殊句式的获取和处理提供了思路,从而帮助人们更加深入地理解自然语言。
连动句是汉语中一种较特殊的句式结构,在汉语中非常普遍。对连动句的研究可以从马建忠的《马氏文通》(成书于1898年)中找到最早的踪迹[2]。随后,又有很多语言学家对连动句作了深入研究,其中,赵元任(《北京口语语法》)、张志公(《汉语语法常识》)、丁声树等(《现代汉语语法讲话》)、吕叔湘(《现代汉语八百词》)等都曾对连动结构做过分析和界定[2]。一般认为,连动句是指句中谓语为连动谓语的句子,即这个句子的谓语是两个或两个以上的动词连用,这些动词之间没有联合、动宾、偏正或主谓等关系,也没有明显的语音停顿,不使用关联词语连接,而且这些动词都由同一个主语发出[3]。
综合前人的研究[4-7],本文将所研究的连动句定义如下: 在一个单句中,含有两个或两个以上的动词(或动词结构)且动词的施事为同一对象。其中第一个动词(简称V1)的主语位置出现的名词短语NP1位置固定,而第二个动词结构(简称V2)所对应的名词短语NP2,与V1的NP1同形,且必须隐含。其句法格式为: NP1+V1+(NP2=[NP1])+V2,且V1和V2之间在语义上具有时序、目的、方式和原因等关系。例如,“我去图书馆看书”,此句中的“去”和“看”两个动词的主语都是“我”且只出现在第一个动词的主语位置,两个动词皆为动作行为动词。而像“地面人员看到丁毅找准跑道”一句中也含有两个动词“看到”和“找准”,但两者的主语分别是“地面人员”和“丁毅”,所以此句属于本文定义的非连动句。
抽象语义表示(Abstract Meaning Representation, AMR)是近年来一种新兴的句子级别的语义表示方法,它突破了传统的句法树结构的限制,将一个句子语义抽象为一个单根有向无环图,很好地解决了论元共享的问题[8]。在连动句中,存在内部概念节点论元共享的现象,即在一个单句中多个谓词共享同一施事论元角色,这种V1、V2的施事论元共享现象正是连动句区别于其他特殊句法结构的最主要特征,而在AMR中会将缺省的论元进行补全,得到完整语义表示。基于此特征,可以从AMR图中获取可能的连动句,再经过人工校对得到连动句集合和非连动句集合,故本文选取了李斌等[9]设计建立的中文AMR语料作为部分实验数据集。
本文的数据集主要由两部分组成,第一部分是使用抽象语义表示(AMR)体系标注的人教版小学1~6年级语文教材;另一部分是清华树库的语料,经过人工标注赋予每个句子连动句或非连动句的标签。
本文提出的连动句的识别方法分为两步。第一步: 首先利用简单的规则剔除语料中一部分非连动句;第二步: 基于神经网络做文本分类,将连动句与非连动句看作两个类别的文本进行分类,使用BERT编码,利用多层CNN和BiLSTM模型联合获取特征,进行句子分类,标签为连动句的文本,即为模型识别出的连动句。此方法不需要手工筛选复杂特征,降低了对NLP领域的前置知识的需求。文本分类的实验结果达到92.71%的准确率,连动句识别的F1值为87.41%。同时本工作也可以帮助AMR标注,定位连动句的位置,在后续工作中进一步完成连动句中连动词和主语的识别以及连动词间的语义关系识别,进而实现连动句的AMR自动标注。
1 相关工作
近年来针对连动句的研究主要集中于连动句的对外教学研究以及从汉语言文学角度研究分析连动句的句法和语义问题,针对连动句识别的研究工作较少。
2013年许有胜提出了连动结构的自动识别和分析方法[10]。他主要从形式特征和语义角色两个方面编制出一些规则,尝试对连动结构进行自动识别和分析。但是由于连动结构的复杂性,所设置的规则并不能涵盖所有情况,使得他提出的自动识别方法在很多环节的处理上都存在问题,但它提供了一种“基于规则识别”的思路。
2017年刘雯旻等提出了一种规则和统计相结合的连动句识别方法[11],他们构建了基于连动句形式特征和语义角色的基础规则库和被动名词库,利用互信息计算谓语动词与主语候选项的搭配强度,从而达到连动句识别的目的,实验结果达到79.42%的准确率,F1值为70.83%。
随着深度学习的发展,神经网络在解决文本信息处理相关任务中取得了较大的进展。本文将连动句的识别问题视为文本分类问题,提出一种基于神经网络的识别方法。深度学习的文本分类方法需要将文本输入到一个深度网络中,得到文本的表示形式,然后将文本表示形式输入到Softmax函数中,得到每个类别的概率。目前,利用神经网络对文本进行分类已经取得很多进展。Kim 最早提出将CNN应用于文本分类任务[12],Lai等提出RCNN模型,更好地利用了上下文信息[13],Conneau等在此基础上提出VDCNN 模型,采用了深度卷积网络方法[14]。Liu等针对文本多分类任务提出基于RNN的不同共享机制模型[15],Wang提出了DRNN 模型,通过固定信息流动的步长提高文本情感分析的准确率[16]。
虽然许多神经网络的模型在文本分类任务中都取得了不错的分类效果,但连动句与非连动句的分类又与一般的文本分类任务不同,许多形式上十分相似的句子很可能不属于同一类别, 更 需要关注句中动词间的语义关系和它们的施事。基于此,本文利用BERT得到文本的表示形式,在训练过程中可以根据上下文动态地调整词向量,将其与多层CNN和BiLSTM进行组合作为连动句识别的模型,在人工构建的语料库上取得了不错的效果。
2 模型设计
本模型采用BERT的输出结果作为字表示,将BiLSTM层与两层CNN获取的局部特征相结合,用Concatenate连接,再经过一个全连接层,最后通过Softmax层输出最终的判断结果,整体模型结构如图1所示。

图1 模型结构图
2.1 文本表示
BERT是基于Transformer的双向编码器表示(Bidirectional Encoder Representation from Transformers)[17],旨在通过联合调节所有层中的上下文来预先训练深度双向表示。使用双向的Transformer进行编码,使得在处理每个词的表示时都要考虑上下文信息,具体模型结构如图2所示。同时BERT在预训练的过程中使用了Masked LM和Next Sentence Prediction两种方法,迫使模型更多地依赖于上下文信息去预测词汇和句子,并且赋予了模型一定的纠错能力,分别捕捉词语和句子级别的表示。

图2 BERT模型图
BERT模型的输入不仅仅是字本身,它由三个Embeddings向量合成,包含更多信息,输出则是已经融入全句语义的各个字的向量表示。BERT输入向量表示如图3所示,其中Token Embeddings层将各个字转换成固定维度的向量,在BERT中每个字都会被转换成768维向量表示。BERT能够处理输入句子对,Segment Embeddings层的作用是区分两个句子,前一个向量将0赋给第一个句子中的各个token,后一个向量是把1赋给第二个句子中的各个token。在本文中,输入的是一个句子,所以Segment Embeddings全为0。Position Embeddings实现编码序列的顺序性,当一个句子同一个字出现多次时,Position Embeddings提供了不同的向量表示。最终对“我去图书馆看书”一句编码,得到3个维度为(1,9,768)的向量,3个向量按位相加最终得到大小为(1,9,768)的合成表示,富含更加丰富的语义信息。

图3 BERT输入向量表示示意图
2.2 特征提取
2.2.1 BiLSTM层
将待判断的单句进行字级别的编码后将结果送入BiLSTM层,BiLSTM不仅利用字在句子中的前后顺序信息,同时还可以捕获双向的较长距离的语义依赖关系,从而更好地判断当动词间相隔较远情况下是否可以构成连动关系。
BiLSTM可以学习输入词的前后信息,从而有助于分类。 给定由n个字组成的句子X,将它表示为一组向量(x0,x1,…,xn-1),通过式(1)~式(5)计算每个时间t的LSTM单元[18]。其中xt,ht-1,ct-1表示输入,ht和ct表示输出。it、ot、ft分别表示输入门、输出门和遗忘门。Wi、Wo、Wc分别表示输入词向量xt,隐藏层状态ht和记忆单元ct的权重矩阵,bi、bf、bc和bo分别表示偏差向量。“⊙”表示按位乘操作,σ表示sigmoid激活函数。
it=σ(Wi[Ct-1,ht-1,xt]+bi)
(1)
ft=σ(Wf[Ct-1,ht-1,xt]+bf)
(2)
ct=ft⊙ct-1+it⊙tanh(Wc[ht-1,xt]+bc)
(3)
ot=σ(Wo[Ct-1,ht-1,xt]+bo)
(4)
ht=ot⊙tanh(ct)
(5)
通过LSTM可以得到与句子长度相同的隐层状态序列{h0,h1,…,hn-1},将前向LSTM与后向LSTM结合成为BiLSTM。通过对正向的时间序列和反向的时间序列进行训练,使输出的数据中尽量多地包含上下文信息。解决了LSTM网络缺乏对上下文联系的问题,从而使模型获取更多的上下文信息[19]。本文中使用的是两个BiLSTM堆叠形成的模型,中间使用一个全连接层进行降维,前一层BiLSTM的输出作为下一层BiLSTM的输入。
2.2.2 CNN层
卷积神经网络是神经网络中提取局部特征的一种网络[20],具有强大的特征学习和表示能力,它的基本结构由四层构成,分别是输入层、卷积层、池化层、全连接层。本模型中使用了两层CNN网络进行串联,第一层CNN的输入使用BERT的输出,将第一层CNN的输出和BERT的输出进行拼接作为第二层的输入。卷积层本质上是特征提取器,输入经过过滤器进行卷积操作后得到新的特征。设滤波器W∈m×n,卷积得到式(6):
(6)
其中,m≪M,n≪N。另外,在卷积的标准定义基础上,根据不同任务的需求,可调整滤波器的滑动步长(stride)、引入零填充(zero padding)来增加卷积的多样性,更灵活地进行特征抽取。两层滤波器采用不同的滑动步长,获取不同尺度的局部特征信息,有利于捕获句中不同距离动词间的信息。卷积层[21]通过局部连接大大减少了网络参数的数量,通过权重共享使特征提取与数据位置无关,但其输出的神经元个数并没有显著地减少,容易造成过拟合,所以在卷积层之后再加上一个池化层,使用Max-pooling进行降维,同时增加平移不变性。模型更关注是否存在某些特征而非其位置,使得网络对一些细小的局部形态改变保持不变性,在减少数据量的同时保留有用的信息,最终得到固定长度的输出。
2.2.3 分类预测
将经过CNN层获得的特征与经过BiLSTM层获得的特征进行拼接,通过全连接层将特征整合到一起,同时对网络进行Dropout 处理,以防止过拟合,随后送入Softmax层进行预测。由于在数据集中连动句与非连动句分布不均,连动句数量较少,在计算损失函数时使用加权损失函数,使模型更多地关注样本数较少的类,更有利于模型识别连动句。
3 实验设置
3.1 连动句识别流程

图4 连动句识别流程
本文对连动句的识别流程如图4所示。第一步,首先需要对语料进行切分操作,本文对连动句的识别以单句为单位,以标点符号“。”、“,”、“: ”、“;”为切分依据,之后再对语料进行词性标注。本文中使用的词性标注器是用清华树库语料作为原始语料、用BiGRU-CRF模型自行训练所得,该模型可以实现对动词的细分类。本文采用范晓的《汉语动词概论》的分类系统[22],动词可根据其表义功能分为动作行为动词、心理动词、使令动词,存现动词、判断动词、能愿动词、趋向动词、先导动词。动作行为动词和心理动词可充当连动句中的V。像“科长的口袋一下子鼓了起来”一句中,“起来”被标注为趋向动词,所以本文认为该句中只含有一个动词“鼓”。更加精准的词性标注,有利于语料在进行规则筛选时预先识别出更多的非连动句。
由于在真实语料中连动句与非连动句所占比例相差很大,且大部分的简单非连动句(句中不含动词或只含有一个动词或动词结构)比较容易分辨,为了使神经网络模型将注意力放在学习与连动句在形式上比较相似的非连动句上,更好地学习两者的特征,本文首先制定了相应规则对语料进行预处理,预先识别出部分非连动句,其余句子可能为连动句,作为连动句的候选集送入神经网络进行分类。
本文设计规则,预先筛选出以下三种条件的句子,将其排除在连动句候选集之外:
条件一: 不含动词或只含有一个动词(或动词结构)的句子。
条件二: 含有关联词的紧缩句或复句。例如,“常海一进病房就大咧咧地坐到程信的病床上”句中含有“一……就……”形似连动,但该句属于紧缩句。
条件三: 只含有多个动词和虚词的句子。当一个长句经过标点切分为独立小句或有些小句充当标题时,句子中只含有动词和虚词,缺少大量信息,不足以判断是否为连动。例如,“竞争与冲突”“搜索前进”等句子缺乏上下文信息,无法判断动词的主语,进而无法判断其是否为连动句。
通过第一步简单规则的辅助,可识别出大量非连动句,使连动句候选集中连动句与非连动句的占比差距大大缩小,从相差14倍多缩小到相差不到3倍,表1展示了筛选前后连动句与非连动句的数据变化。

表1 规则筛选处理对比表
经过规则筛选后得到的连动句候选集中除连动句外,还含有大量的非连动句。这些非连动句中有一部分是和连动句相差明显的句子,例如,“我在天色微明时走到了杨柳镇”根据语义可以得到“微明”和“走到”的施事明显不一致;但还有部分与连动句相似度很高的其他特殊句式,例如,兼语句“他帮助妇女摆脱贫困”,虽然此处“帮助”和“摆脱”的施事并不一致,但此类句子在句式上与连动句相似,有一定区分难度。又如含有被动语义的句子,在判断动词的施事时也可能遇到困难,例如“他被通知住院”,“通知”和“住院”的施事并不相同,但在“他被诊断宣判生命只剩2个月”中“诊断”和“宣判”的施事又是同一个,该句为连动句,这些相似度极大的句子给本文的工作带来困难,也是神经网络模型需要重点学习的内容。
3.2 评价标准
本实验采用精确率(Precision)、召回率(Recall)、F1值(F1-measure)、准确率(Accuaracy)作为评价标准,计算如式(7)~式(10)所示。其中,TP: 正确分类中连动句个数;FP: 错误分类中连动句个数;TN: 正确分类中非连动句个数;FN: 错误分类中非连动句个数。
3.3 实验数据
连动句中V1和V2有共同的主语,在传统的语义表示方法上,由于树结构的限制,一般只标注主语和核心谓词的关系,而连动结构中其他谓词与主语的关系则被隐含。但这种隐含的语义关系正是连动结构区别于其他特殊句法结构最重要的特点。而在AMR中将补充出句中省略或隐含的成分,以还原出较为完整的句子语义,弥补传统句法表示的严重缺陷。
例如,“小白兔连忙挎起篮子往家跑。”一句的AMR文本表示如图5所示,“挎”和“跑”的施事arg0都是“白兔”,原句中第二个动词“跑”的主语被省略了,在AMR图中会将此缺省补全,同时它也表示出了两个动词间的语义关系,此例中两个动词间的语义关系为“temporal(时序)”。

图5 AMR文本表示图
本文根据AMR图抽取出小学语文1~6年级课本中所有共享论元arg0的句子,但在这些句子中可能还包含一些动补结构、谓词宾语句、紧缩句等,例如在“戴嵩决定画一幅《斗牛图》。”一句中,AMR将“决定”和“画”的arg0都标注为“戴嵩”,所以抽取算法也会将该句抽取出来,但该句是谓词宾语句,所以对抽取出的句子还要再加以人工校对。同时又对清华树库的语料进行人工标注,共计40 667个完整的句子。将句子切分为独立小句后,得到11万个分句,其中7 200个独立小句为连动句。经过第一步处理后,共计25 052个独立小句进行第二步神经网络模型的实验,按照6:2:2的比例划分训练集、开发集和测试集。
3.4 实验参数设置
使用BERT的基础版本,网络层数设置为12,隐藏层数设置为768,self-attention head设置为12。在BERT中要预先设置max_seq_length参数,未达到此长度的句子要做padding处理,而超过此长度的数据将会被截断,造成信息丢失。同时若此参数设置过大会占用大量内存空间。本实验主要参数设置如表2所示。

表2 模型参数设置
3.5 实验结果及分析
为验证本文提出的方法的有效性,本实验主要与以下几种目前流行的文本分类模型进行对比,实验结果如表3所示。
(1)基于规则和统计: 刘雯旻等在2017年提出,他们构建了基于连动句形式特征和语义角色的基础规则库和被动名词库,利用互信息计算谓语动词与主语候选项的搭配强度,在他们人工标注的数据集上进行实验。
(2)FastText: 利用简单的三层模型(输入层、单层隐藏层、输出层),根据上下文预测文本的类别[23]。

表3 不同文本分类模型结果对比 (单位: %)
(3)TextCNN: 利用CNN来提取句子中的关键信息,先将文本分词做词嵌入得到词向量, 再将词向量经过一层卷积,一层最大池化,最后将输出外接softmax实现文本类别的预测。
(4)TextRNN: RNN模型具有短时记忆功能,其通过前后时刻的输出链接保证了“记忆”的留存,比较适合处理自然语言等序列问题,引入门控机制后,能够解决长时依赖问题,捕获输入样本之间的长距离联系。
(5)BERT: 用Transformers作为特征抽取器的深度双向预训练语言模型,在许多自然语言处理任务中有很好的表现。
通过表3展示出的不同文本分类模型进行连动句识别的结果可知,本文提出的模型在连动句与非连动句分类的任务上具有很好的效果。除基于规则和统计的方法使用作者标注的语料外,其余神经网络的模型均使用本文中介绍的利用简单规则筛选后的语料。对比结果发现,FastText模型基本没能学习到连动句的特征,在本任务上的效果较差;TextCNN和TextRNN的效果相差不大,但都表现得还不够理想;而BERT模型F1较之前的模型有较大的进步,通过进一步分析BERT模型识别错误的句子发现,BERT 模型对长句的识别效果比较差。“连动句”这种语言现象可以出现在任何领域,它关注的是动词与动词的发出者之间的关系,而不是整个句子的语义关系,而且与词序有关。本文提出的模型使用BERT编码使模型获得了更多的语义信息,BiLSTM 层可以提取上下文不同距离的语义化信息,同时CNN层可以获取局部的特征,将多种特征进行组合,从而完成对连动句与非连动句的区分。
在时间消耗方面,本文所提出的模型的收敛速度很快,图6和图7展示了模型在开发集上的迭代次数与Loss和Acc的变化曲线,由图可知模型在迭代几轮后便可得到在开发集上效果最好的模型参数,之后Loss值会发生小范围的波动。为防止模型训练造成过拟合的问题,所以在实验中设置了提前终止参数,并使用dropout 使模型得到更好的泛化效果。
图6 Loss变化曲线图
同时为了验证模型各层结构在实验中所起到的作用,特设置消融实验,结果如表4所示。由实验结果可知,使用随机初始化的字符级别的词向量代替BERT,实验的F1值降低了约20%,可见语义信息的获取和使用在连动句识别中起到了至关重要的作用,同时在训练过程中,本文提出的模型也会对词向量进行微调,以达到更好的表现。与此同时,本文在获取特征时也采取了局部特征和全局特征组合的方式,更有助于连动句识别。
图7 Acc变化曲线
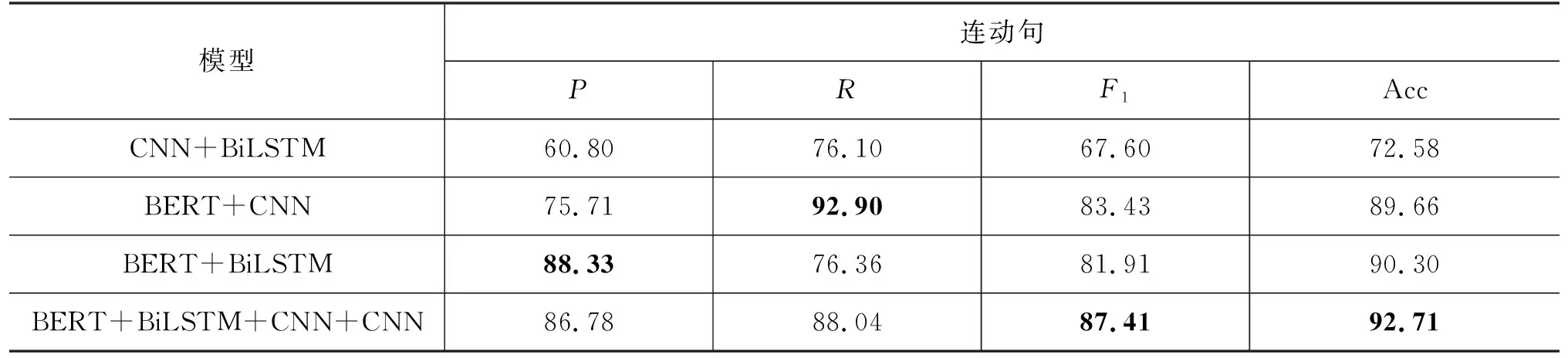
表4 消融实验结果 (单位: %)
通过实验发现,在使用BERT+CNN模型时,实验的R值较高,这是因为CNN侧重于提取句子局部信息,当句子局部出现两个动词或动词短语时,这一特征就会被CNN捕捉到,然而并非所有两个动词短语连用都是连动结构,可能是紧缩复句、兼语句、动词短语作宾语句等其他语言现象,因此造成这一模型R值较高而P值较低。而使用BERT+BiLSTM的模型则恰好相反,它的P值较高,Bi-LSTM 侧重于捕捉句子全局信息,从整句角度去考察句子特征,因此比较容易将同样包含两个或两个以上动词的复句、兼语句、动词短语作宾语句等从句子层面排除在外,然而连动结构除了在句法层出现外,还可以以短语形式出现在定语、状语的多个句法位置,BiLSTM模型对这类连动结构的识别能力较差,导致R值较低。本文使用的模型将两者的优势集中起来,提高了模型的F1值。
根据实验结果我们发现连动句的识别错误分为两种:
其一是将非连动句错误地识别为连动句,主要分为以下几种情况:
(1) 汉语中一些动词的主语并非动词的施事者,导致模型判断出错。例如,“出租车招手即停”一句中,句子的主语是“出租车”,但“招手”的施事是“人”而“停”的施事是“出租车”,二者并不相同。
(2) 部分动词或动词短语作状语的状中结构和动词或动词短语作宾语的动宾结构识别易出错,它们在形式上与连动句相似,例如,“宋东山心平气和地向小伙子笑笑”,此句中“心平气和”和“笑笑”的施事皆为“宋东山”,但该句为状中结构而非连动句;又如“川川总爱刨根问底”,“刨根问底”为动词,充当“爱”的宾语,且二者的施事都为“川川”,此句为动宾结构。
其二是某些连动句无法识别出来,主要分为以下两种情况:
(1) 对多义词的识别效果不好。汉语中很多词语存在一词多义现象,但有些词语模型无法识别出它的动词义项,导致模型判断出错。例如,“小刚看见这句话火了”,“火”有多个义项,可以是名词、动词、形容词,此时模型识别比较困难。
(2) 对长句的识别效果不好。例如,“海淀区红山口甲3号国防大学医院疑难病研究中心的法集河使用近百味中药炮制膏药”模型识别为非连动句,但对“法集河使用近百味中药炮制膏药”可正确识别其为连动句。当句子某些修饰成分过长时,会影响模型的识别效果。
4 总结与展望
本文基于小学1~6年级语文教材和部分清华树库的语料构建了连动句数据集,介绍了一种基于神经网络的连动句识别方法,先对语料进行切分和词性标注工作,再通过简单的规则进行第一轮非连动句的判断,之后使用BERT进行编码,将BiLSTM和CNN模型获取的特征组合,进行第二轮连动句与非连动句的判断,进而完成连动句的识别任务。实验表明,该模型取得了不错的识别效果。
我们下一步工作是进一步提高连动句识别的准确率,同时从语料中识别出的连动句中进一步找出其中的连动词,并识别它们之间的语义关系,从而帮助处理CAMR中连动句式的标注与解析工作。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
通信技术(2021年12期)2022-01-25
考试与评价·高一版(2020年2期)2020-10-29
文化学刊(2020年5期)2020-01-02
疯狂英语·新阅版(2019年11期)2019-09-10
计算机应用与软件(2018年9期)2018-09-26
长江学术(2016年4期)2016-03-11
人间(2015年21期)2015-03-11
长江学术(2015年1期)2015-02-27
外语教学理论与实践(2014年2期)2014-06-21
