
基于规则与统计相结合的藏文文本自动查错方法研究
2022-04-12 04:15:08完么扎西尼玛扎西
中文信息学报 2022年2期
完么扎西,尼玛扎西
(1. 青海师范大学 民族师范学院,青海 西宁 810008;2. 西藏大学 信息科学技术学院,西藏 拉萨 850000)
0 引言
文本自动校对技术作为自然语言处理领域的重要应用技术之一,在图书、报纸、网络媒体、语音输入、文字识别、文本编辑、辅助教学等领域具有广泛的应用价值。
汉语和英文等语言的文本自动校对技术的研究起步早,发展速度快,自动校对理论和技术也比较成熟。英文文本自动校对的研究早在20世纪60年代就已经展开[1],自动校对技术已经十分成熟,目前已出现了一批实用的商品化系统,比如嵌入Word字处理软件的Spelling Checker等。英文的词与词之间有明显的分隔符,所以英文自动校对主要以词为单位从非词错误检测(Nonword Error Detection)、隔离词错误纠正(Isolated-Word Error Correction)和上下文相关词校对(Context-Dependent Word Correction)等三个方面进行了研究[2]。其中,非词错误的查错技术主要采用N-gram分析技术和词典查找技术;隔离词纠错技术主要采用最小编辑距离技术(Minimum Edit Distance Techniques)、相似性关键技术(Similarity Key Techniques)、基于 N-gram 的技术(N-gram-Based Techniques)、基于规则的技术(Rule-Based Techniques)、概率统计技术(Probabilistic Techniques)和神经网络技术(Neural Net Techniques)等;上下文相关词的错误也叫作真词错误(Real-word Error),其校对方法主要有基于规则和基于统计这两种。其中,基于规则的方法可分为基于接受的方法、基于松弛的方法和基于期望的方法;基于统计的方法采用了词的二、三元模型和词性的二元模型[3]。
汉语文本自动校对技术的研究始于20世纪90年代初期,比起英文相对较晚,但发展速度快,也已有一些商品化的文本自动校对软件,如黑马、方正金山、啄木鸟、人工智能校对通、三欧和文捷等[4]。由于汉英语言的差异性,汉语自动校对主要以字、词和句子为单位从词法、语法和语义等三个层面上对真词错误的校对技术进行研究,主要采用基于上下文的局部语言特征、基于语言学知识、基于概率统计和基于深度学习等方法[5-7]。
藏文文本自动校对的研究起步与汉语几乎同步[8],但发展速度较慢,该领域的研究文献还不多见,就目前现有的藏文文本自动校对相关的文献来看,校对技术的研究主要集中在藏文字的自动查错上。由于藏文既不同于英文等其他西方拼音文字,又不同于汉语等表意文字,所以藏文文本自动校对主要以(音节)字、梵音转写藏文字、虚词和实词等为单位,从拼写文法、词法和语法等三个层面进行研究,采用文法规则、查字典和N-gram模型等方法[9-14]。这些方法总结起来主要集中在四个方面: ①建立藏文电子辞典,将待检查文本进行分字或分词,并与电子词典进行匹配,进而完成藏文字、词自动查错任务; ②分析研究藏文字的拼写规则及藏语虚词的接续规则,建立相应的规则库及模型,从而进行藏文拼写检查及虚词语法检测; ③在藏文字拼写规则的基础上,建立一种辅助字库,包括梵音转写藏文、音译和借音等不符合现代藏文拼写规则的字,按规则和字库匹配相结合的方式进行藏文自动查错。其中,方法①的弊端非常明显,这种方法只能对藏文电子辞典中已收录的藏文字或词进行自动查错,无法检查电子辞典中未收录藏文字或词。例如,其他文种人名、地名以及外来名词等。同时,这种方法的效率不高。方法②的基本思路是对的,但由于技术、方法不够完善,使得相应模型的适应面不广,不能够识别特殊结构的藏文字,效率不高。方法③虽然借鉴上述两种方法的优点,但仍然存在两种方法的弊端,效率低。
针对目前藏文文本自动查错方法的不足,本文提出一种基于规则和统计相结合的自动查错方法。首先以藏文拼写文法为基础,结合形式语言与自动机理论,构造37种确定型有限自动机识别现代藏文字;然后利用查找字典的方法识别梵音藏文字;最后利用互信息和t-测试差等统计方法查找藏文词语搭配错误和语法错误等真字词错误,实现藏文文本的自动查错。
1 藏文文本中常见的错误类型分析
藏文文本中的错误来源与汉英文本中的错误来源基本相似,归纳起来主要有输入过程中造成的错误和原稿造成的错误两种。目前,常见的文字录入技术有键盘录入、语音输入、OCR识别和手写识别等[5]。但对于藏文信息处理而言,语音输入、OCR识别和手写识别等技术尚未成熟,还没有出现实用的商品化系统。因此,现在常见的文字录入方式主要还是键盘录入。在文字录入过程中,易造成替换错误、易位错误、丢失错误和插入错误等[15]。如下面的输入错误(1)括号内的是正确的。:



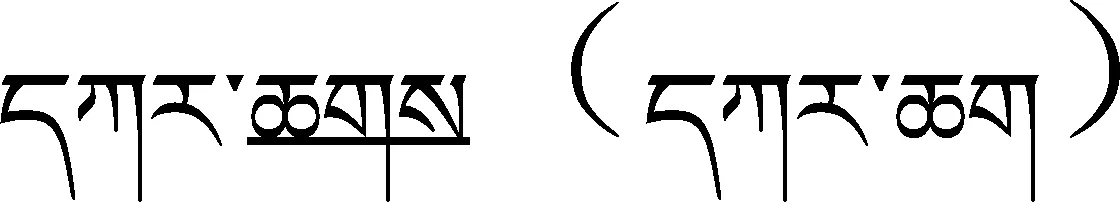

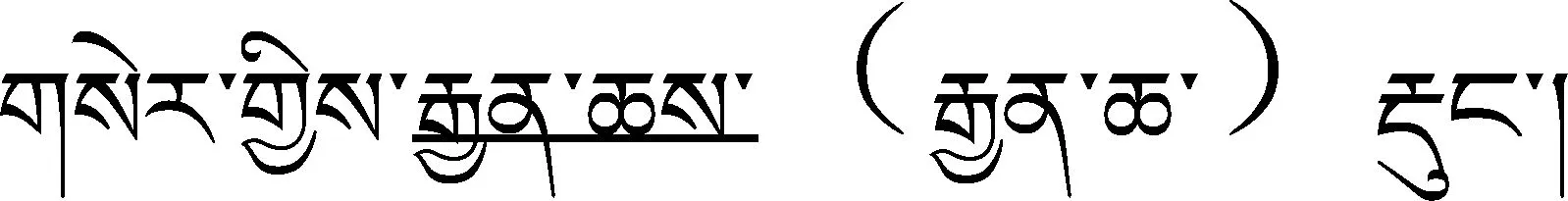


2 藏文文本自动查错方法
2.1 藏文非字错误的自动查错方法
2.1.1现代藏文字的自动查错方法
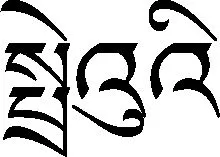
由于字数限制,本文只介绍现代藏文字的基本拼写结构16对应的拼写形式文法。有关现代藏文字的拼写结构对应的拼写形式文法可参阅文献[16-17],这里不再一一介绍。该拼写结构包括六或七个构件,其形式文法为:
藏文拼写形式文法G16:藏文前加字、上加字、基字、下加字、元音符号、后加字及再后加字拼写构成的藏文字的文法G16是一个四元组(VT,VN,S16,P),其中:
(1) 终结符
VT=VB∪Vo;其中:

(2) 非终结符集合
VN={S16,A,B,C,D,E,F,G,H,I};
(3)S16为VN中的非终结符,且为起始符号。
(4) 文法G16的产生式集合为:P={
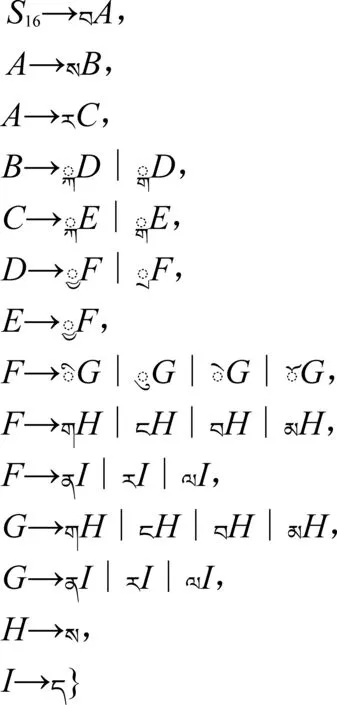

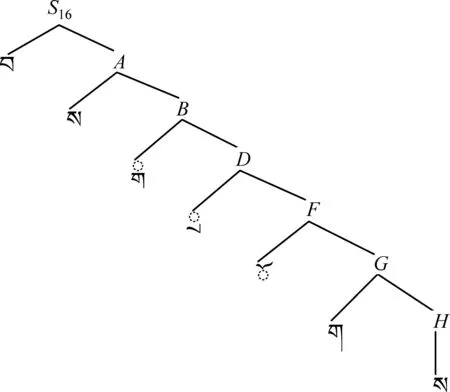
图1 藏文字的分析树
从形式文法和分析树中不难看出,上述文法G16是一种右线性正则文法。同理,藏文37种拼写形式文法都为右线性正则文法。因此,根据形式语言与自动机理论,可以构造相应的37种确定型有限自动机DFAMi(i= 1, 2, 3,…,37)识别文法Gi生成的语言L(Gi),即文法Gi定义的藏文字。因此,接受语言L(G16)的确定型有限自动机状态转移图如图2所示。
传统藏文文法中藏文字被定义为藏文书面语中以分字符(“·” tesk)为界点的语法单位。但是,实际使用的藏文真实文本中藏文字一般以藏文字符编码“u0F40-u0FBC”之外的任意字符(包括非藏文字符)为结束标志。有了藏文字的结束标志,可以将待检查的藏文文本以藏文字为单位进行自动拼写检查,因而本文设计的现代藏文字的查错方法由如下步骤得以实现。
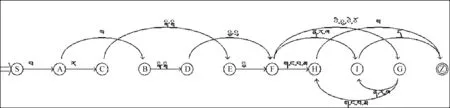
图2 识别L(G16)的DFA M16状态转移图
首先,将文法Gi(i=1,2,3,…,37)转换成非确定型有限自动机(NFA)Mi(i= 1,2, 3,…,37),因为文法Gi(i=1,2,3,…,37)对应的自动机并不都是DFA[17];
其次,将NFAMi(i= 1,2,3,…,37)转换成DFAMi(i= 1,2,3,…,37);
再次,为了进一步提高效率,将集合的首字母替换DFAMi(i= 1,2, 3,…,37)分割后的状态集,并生成MinDFAMi(i= 1,2,3,…,37);
最后,用MinDFAMi(i= 1,2,3,…,37)识别藏文字。
该方法不涉及藏文语料库覆盖性的问题,效率高,且能有效识别所有符合拼写文法的藏文字,包括特殊结构的藏文字和部分梵音转写藏文字。
2.1.2 梵音转写藏文字的自动查错方法
梵音转写藏文字是指梵文的音转写成藏文的字,也叫梵音藏文。梵音藏文形式多样、结构复杂,不像现代藏文字那样有统一的拼写规则,无法用规则的方法完成自动查错任务。因此,本文采用了文献[12]的字典查找方法。
2.2 藏文真字、词错误的自动查错方法

藏文文本中存在大量的单字词,单字词的错误会造成多字词的错误,并对自动分词造成严重干扰。因此,本文借鉴文献[20-22]的研究方法,并利用藏语言自身的结构特征,以藏文字为研究单位,拟采用基于互信息的字字接续关系和t-测试差等方法进行查错。
2.2.1 基于互信息的字字接续判断模型
设有句子S=C1C2…CiCi+1…Cm,其中,CiCi+1为两个相邻的藏文字。根据信息论的理论,互信息反映两个变量之间的关联程度[23]。因此,字容量为N的藏语语料库中,两个相邻的藏文字Ci和Ci+1之间的互信息由式(1)进行计算:
(1)
其中,p(Ci,Ci+1)为Ci,Ci+1的邻接同现概率;p(Ci)和p(Ci+1)分别为藏文字Ci和Ci+1的独立概率。根据最大似然估计,对邻接同现概率和独立概率可用式(2)~式(4)进行估计,即
其中,count(Ci,Ci+1)为Ci,Ci+1在语料中邻接同现的总次数;count(Ci)为Ci在语料中出现的总次数;count(Ci+1)为Ci+1在语料中出现的总次数。

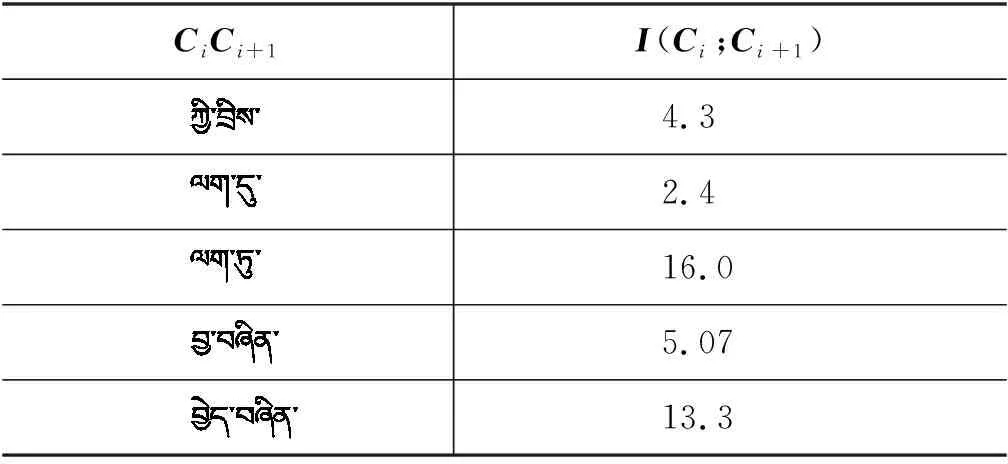
表1 相邻两个字的互信息

2.2.2 基于t-测试差的字字接续判断模型
假设Ci-1CiCi+1为藏文字串,则Ci相对于Ci-1和Ci+1的t-测试可定义为如下形式[24]:
(5)
其中,p(Ci+1|Ci) 和p(Ci|Ci-1) 分别是Ci+1关于Ci,Ci关于Ci-1的条件概率,∂2(p(Ci+1|Ci)) 和∂2(p(Ci|Ci-1)为各自的方差,其值可用最大似然估计进行估计,即
t-测试是一种相对度量,反映三个字之间的结合程度,但这是直接挂靠在字上的,不像互信息那样挂靠在两个字之间。为此,特引入t-测试差[25]将两者的挂靠对象统一起来。对藏文字串Ci-1CiCi+1Ci+2而言,Ci和Ci+1之间的t-测试差可用式(8)定义:
Δt(Ci,Ci+1)=tCi-1,Ci+1(Ci)-tCi,Ci+2(Ci+1)
(8)

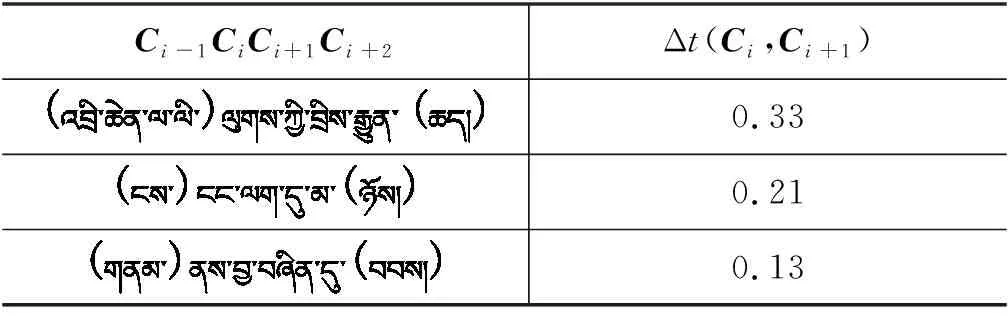
表2 相邻两个字的t-测试差

3 实验结果及分析
本文实验的训练语料是覆盖新闻类、文学类、医学类和期刊类等2 000万字的藏语单语语料。该语料经人工校对,不存在非字错误和真字词错误,并且用词规范,语句标准,完全符合本文实验要求。从三大藏文新闻网(新华网、中国藏语广播网和青海新闻网)中随机抽取100篇文章作为测试集。该测试集中共有49处错误,其中有21处非字错误,14处词语搭配错误,11处虚词接续错误,3处动词形态错误。
在藏文文本自动查错过程中,主要依据如下性能指标: 查错召回率R、查错准确率P、查错F值和误判率E,定义如式(9)~式(12)所示。

(9)
(10)
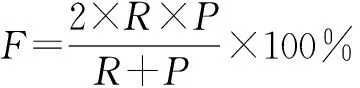
(11)
(12)
根据上述评价指标的计算方法,得到的实验结果的评价指标值如表3所示。
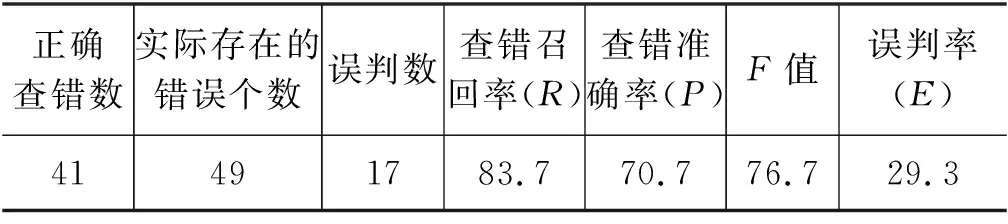
表3 评价指标结果
由于目前缺少藏文文本自动校对方面的实验数据,本文实验结果无法进行比较。表3的实验结果表明,本文方法对提高藏文文本自动查错系统的召回率和查错准确率确实有效,但缺点是训练语料的覆盖面小,未考虑藏语词法、句法和语义层面的知识等,导致如下三种错误:

4 结论
本文以藏文字为研究单位,重点研究了藏文非字错误和真字词错误的查错方法,提出了基于自动机的现代藏文非字错误识别方法,并采用了基于互信息和t-测试差的真字词错误检测技术,通过实验验证了本文方法的可行性和有效性。但藏文文本自动校对技术的研究除了藏文字层面的内容以外,还涉及藏语词法、句法和语义等三个层面的内容,是藏语自然语言处理的重要研究部分。查错后的纠错处理是文本自动校对系统的重要组成部分,对藏文文本自动校对而言,目前尚未发现这方面的研究。因此,下一步将通过研究藏语词法、句法和语义等内容,构建一种综合型的语言知识库,并根据藏文文本的特点, 研究面向藏文文本自动校对的计算语言模型,为计算机校对藏文文本提供自动化的处理技术。
猜你喜欢
西部蒙古论坛(2021年4期)2021-03-02 11:33:18
布达拉(2020年3期)2020-04-13 10:00:07
西夏学(2019年1期)2019-02-10 06:22:34
High Technology Letters(2017年2期)2017-06-27 08:09:22
High Technology Letters(2016年3期)2016-12-05 07:01:07
西藏大学学报(自然科学版)(2016年1期)2016-11-15 05:23:31
新闻传播(2016年17期)2016-07-19 10:12:05
学生天地(2016年26期)2016-06-15 20:29:39
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:53
西北工业大学学报(2015年4期)2016-01-19 03:31:47
