
融合句子结构特征的汉老双语句子相似度计算方法
2022-04-12 04:46李炫达周兰江张建安
中文信息学报 2022年2期
李炫达,周兰江,张建安
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
0 引言
老挝与我国云南接壤,其语言老挝语属汉藏语系,在机器翻译中属于资源稀缺型语言。汉老双语句子相似度计算是指计算汉语和老挝语之间的句子语义相似程度,是抽取汉老双语平行句对的重要方法,在老挝语研究中具有非常重要的地位。
近年来,传统方法和基于神经网络模型的方法在跨语言句子相似度计算任务中均取得了很好的效果,然而目前主流的传统方法如基于双语词典匹配的方法[1-2]、基于特征工程的方法[3-4]等往往需要大规模的语料数据和提取大量的文本特征来表征句子相似度;基于神经网络模型的方法[5-8]虽然可以使用网络结构提取文本特征,通过计算特征向量间的距离来表征句子相似度,但在面对跨度较大的语言时,其使用网络结构提取特征的效果较差,因此对于语言结构差异性较大的语言,大多考虑在神经网络模型中融合传统方法文本特征。
目前已有的工作大多为使用基于特征工程的方法提取文本特征后,将其对应的特征向量与句子的分布式表示进行拼接以融合特征信息[9],通过神经网络模型表征句子的相似度。老挝语的基础研究薄弱,目前还没有成熟的句法分析工具,难以使用传统方法提取特征,因此本文在研究了汉语和老挝语的句子结构异同后,构建了一种根据关键词性和位置信息来获取老挝语句子结构特征的特征模板,提出一种融合句子结构特征的汉老双语句子相似度计算方法。不同于目前提取特征向量再进行拼接的方法,由于本文特征模板提取句子结构特征需要确定词性和位置信息,因此需要先添加特征标记,再将含有特征标记的句子进行分布式表示,并映射到共享的语义空间,最后通过带有自注意力(self-attention)机制的双向长短时记忆网络(BiLSTM)模型得到汉老双语句子的相似度分数。实验结果表明,与目前主流方法相比,本文方法在有限的语料下具有更优的表现,模型的F1值达到了70.24%。
本文的主要贡献如下:
(1) 提出一种通过关键词性和位置信息来获取老挝语句子结构特征的特征模板。
(2) 将汉-老双语词嵌入映射到共享的语义空间,减少了汉、老语言间的差异性。
(3) 在BiLSTM网络中加入自注意力机制,有效提高跨语言句子相似度计算模型的效果。
本文组织结构如下: 引言部分介绍本文的研究背景及目的,第1节为相关工作,综述双语句子相似度计算的相关文献;第2节介绍汉语和老挝语句子结构的异同;第3节介绍本文使用模型的结构;第4节为本文模型的设置与相关实验的结果;第5节为总结与展望。
1 相关工作
传统的双语句子相似度计算方法主要有以下三类方法。
(1) 基于双语词典匹配的方法这类方法的思想是使用双语词典将源语言和目标语言转换为中间层语言,通过计算词的相似度来衡量句子的相似性,如石杰等人[1]使用多语言版本的WordNet将汉语和泰语转换为英语,通过转换后文本的特征词匹配来计算相似度;闫红等人[2]通过HowNet的多义词消歧对句子中的词语进行处理,以词语相似度为基础计算了句子的相似度。
(2) 基于特征工程的方法这类方法的思想是通过抽取文本特征来表示句子的语义信息,从而计算句子间的相似度,如Tian等人[3]通过提取句子的序列特征、句法分析特征、句子对齐特征来表示句子语义信息,计算英语、阿拉伯语和西班牙语间的句子语义相似度;黄洪等人[4]利用依存句法分析方法得到句子中各成分的关系特征,以获取句子的核心词和关键词,通过词匹配的方法计算句子相似度。
(3) 基于机器翻译模型的方法这类方法的思想是将源语言翻译成目标语言来计算跨语言句子的相似度,如Erdmann等人[10]将双语维基百科的文章翻译为同一语言来计算文章的相似度,构建了双语词典;Wu等人[11]将目标语言翻译为英语后,通过WordNet词典中层次树结构的非重叠信息计算了英语、阿拉伯语和西班牙语间的句子语义相似度。
传统方法虽然取得了不错的效果,但基于双语词典匹配的方法仍需要大量的双语词典资源来解决未登录词问题,特征工程的方法需要人工抽取大量的文本特征以保证句子语义信息的准确性,机器翻译模型的方法依赖于翻译的效果。随着深度学习的兴起,基于神经网络模型的跨语言句子相似度计算方法在无需传统特征的基础上取得了较好的结果[12-14]。Mueller等人[5]提出了一种连体LSTM网络结构(Siamese LSTM),通过将句子对输入到共享参数的LSTM网络,得到特征向量后计算向量间的曼哈顿距离表征句子对的相似度;李霞等人[6]分别运用卷积神经网络(convolutional neural network,CNN)和注意力机制(attention mechanism)得到每个句子的局部语义信息和全局语义信息,将其拼接后传输到全连接网络层,计算得到句子间的相似度分数;Chi等人[7]将改进的连体LSTM网络与注意力机制结合,得到更加准确的句子语义向量,通过全连接网络层计算向量间的相对差与相对积来获得句子间的相似性分数。Chien等人[8]通过学习转换矩阵将训练好的汉语词嵌入映射到英语词嵌入语义空间,然后计算汉语和英语句子的平均逐词相似度,从而获取平行句子对。
2 汉语-老挝语句子结构异同
老挝语的句子构成分为主要成分和次要成分,主要成分指句子的主谓(或主谓宾)成分;次要成分指解释句子主要成分的附加部分,即定语、状语、补语等。汉语和老挝语的主要成分具有相同的顺序结构,均为主谓宾顺序(SVO),并且汉语和老挝语的主要成分通常由相同词性的单词构成[15],如表1所示的例句为经过词性标注和句子主要成分标注处理的句子,其中,/p、/r、/v、/u、/m、/n、/a分别表示介词、代词、动词、助词、数词、名词和形容词性标记;Subject,Verb,Object分别表示句子的主语、谓语和宾语。通过表1可知,具有完整主谓宾结构的汉老双语句子,其主谓宾在句子中具有相同或相近的位置,并且通常由相近词性的单词来构成主谓宾成分;缺少宾语结构的汉老双语句子,其主语和谓语具有相同或相近的位置,并且同样由相近词性的单词来构成主谓成分。
汉语和老挝语的主语都可以由名词、代词等词性充当,并且在句子中处于相同的位置;谓语由动词、形容词等词性充当,并且谓语都位于主语之后;宾语构成的词类一致,并且都位于谓语之后。因此对于老挝语,可以通过句子中的名词、代词、动词和形容词以及其在句子中对应的位置来识别老挝语句子的主要成分,提取句子的结构特征。

表1 汉语-老挝语句子结构示例
3 融合句子结构特征的汉老双语句子相似度计算模型
3.1 模型结构
本文构建模型的基本思路如下: 首先对汉语和老挝语的平行句对进行分词和词性标注预处理,通过汉语句法分析工具和本文提出的老挝语句子结构特征标记模板分别获取汉、老句子的句子结构特征,加入特征标记;其次,预训练含有特征标记的汉语和老挝语词向量分布式表示,使用双语种子词典将汉老双语词嵌入映射到共享的语义空间,通过带有自注意力机制的双向长短时记忆网络(BiLSTM)获取含有长距离语义信息的双语句子对特征向量表示;最后,分别计算双语特征向量的相对差和相对积,将结果拼接后传输到全连接网络层计算出相似度分数,模型的结构如图1所示。
本文模型由以下部分构成:
(1)预处理层: 对给定的汉语、老挝语双语句子进行分词和词性标注,分别使用CoreNLP工具和本文提出的特征模板对汉语和老挝语添加句子结构特征标记。
(2)词嵌入层: 输入预处理好的具有句子结构特征标记的汉老双语句子对,利用预训练的方式映射在共享语义空间的双语词向量进行转换,得到对应的词向量序列。
(3)BiLSTM层: 针对句子训练的问题,是一个典型的序列到序列的问题,BiLSTM可以较好地捕捉到句子之间的特征[16],将汉老双语句子对应的词向量序列输入到BiLSTM网络中,得到含有双向语义信息的特征向量。
(4)自注意力层: 自注意力层可以有效捕获长距离语义特征[17]。将含有双向语义信息的特征向量传输到自注意力层中,得到含有长距离语义信息的汉老双语句子特征向量。
(5)全连接层: 将得到的汉老双语句子特征向量分别进行按位减和按位乘操作,把结果进行拼接后传输到全连接网络层中计算得到汉老句子对的相似度分数。
3.2 老挝语句子结构特征标记模板
老挝语是一种缺少语料资源的稀缺语言,由于缺少成熟的句法分析工具,无法直接获取句法特征向量。本文在对汉语和老挝语句子结构进行研究后,发现汉老双语句子成分相似[15],并且具有相同的主谓宾结构(SVO),因此可以通过关键词性和位置信息在原句中添加句子成分标记, 获 取句子结构特征。使用实验室开发的老挝语分词工具[18]和词性标注工具[19]对老挝语句子进行处理,保留句子中的名词、动词、形容词和代词词性,按以下规则构建特征标记模板来获取老挝句子结构标记:
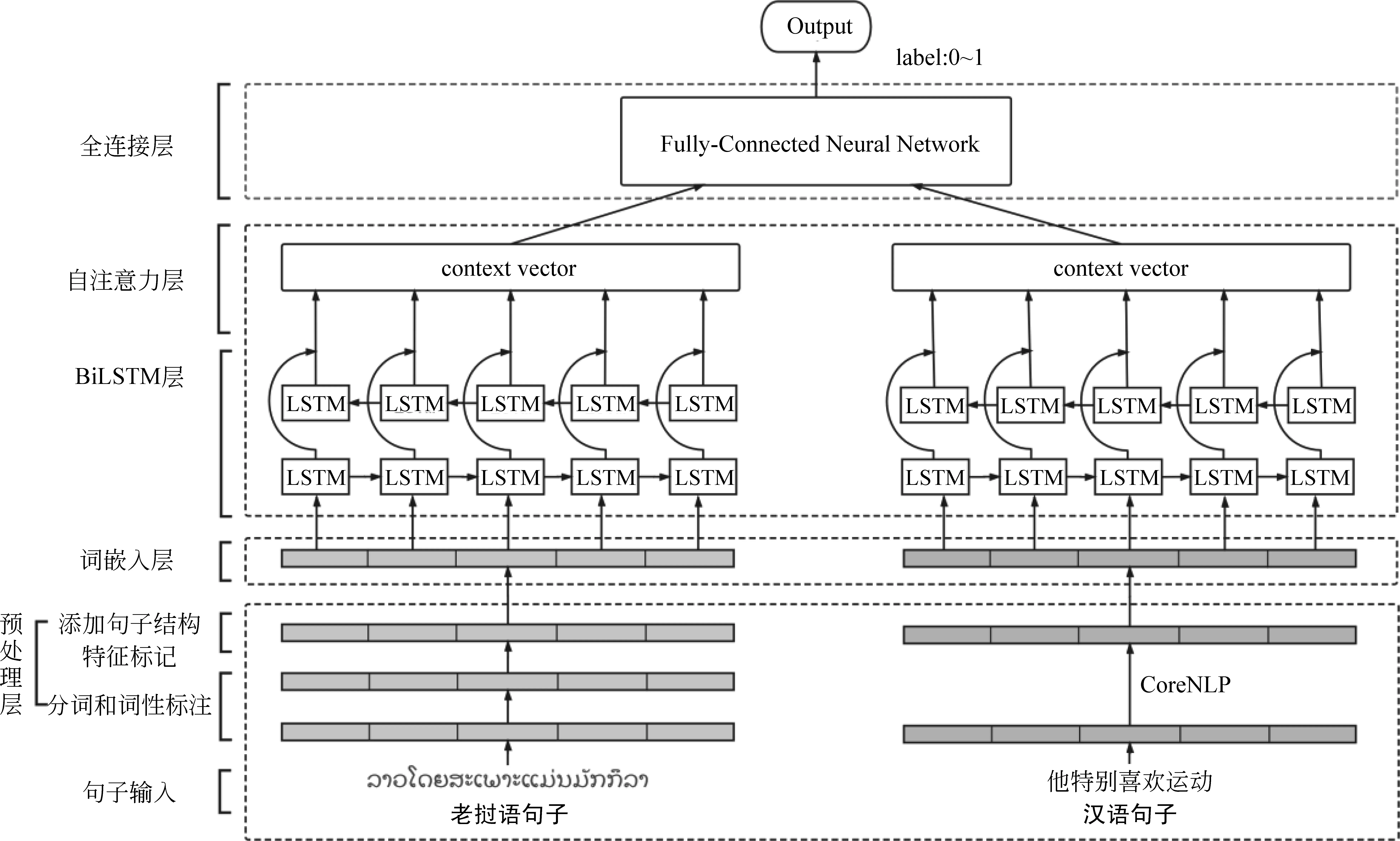
图1 融合老挝语句子结构特征的汉老双语句子相似度计算模型图
(1) 若老挝语句子保留的词性中拥有除动词和形容词词性以外的其他词性,则将句子中连续的动词和形容词词性视为一个成分,在末尾添加标记verb;将老挝语句子中连续的名词、代词词性视为一个成分,在末尾添加标记func_tag;
(2) 若句子仅有一个verb标记且具有多个func_tag标记,则verb前的func_tag标记部分为主语成分,替换func_tag为sub标记;verb后的func_tag为宾语成分,替换为obj标记;
(3) 若句子仅有一个verb标记和一个func_tag标记,且func_tag位于verb之前,则把句子视为缺少宾语的主谓句,func_tag为主语成分,将其替换为sub标记;
(4) 不满足以上条件时,句子多为成分不全的简单句或具有从句的复杂句,使用特征标记模板难以获取句子结构特征,因此不做处理。
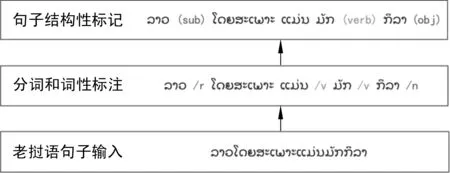
图2 老挝语句子结构标记过程图
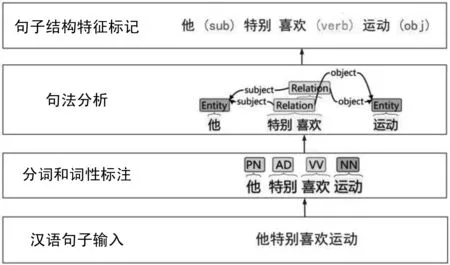
图3 汉语句子结构标记过程图
图3为使用CoreNLP对例句“他特别喜欢运动”进行标记的过程,首先经过分词和词性标记处理后,通过CoreNLP的句法分析得到句子的主谓宾成分,最后将多余句子成分标记去除后,替换为和老挝语相同的标记(sub)、(verb)、(obj)。
通过以上处理,即可在汉语和老挝语句子中加入特征标记。
3.3 含有句子结构特征的汉老双语词向量分布式表示
词向量分布式表示可以将单词映射到低维空间中,不同的维度可以表征不同的语义信息。对于跨度较大的语言,通常将不同语言的词嵌入映射到相同的向量空间中,保证单语言下的语义不变性,同时确保具有相同语义的词非常接近。汉语和老挝语的语言差异性较大,因此在本模型中通过利用汉老双语种子词典映射的方式将汉语和老挝语映射到共享的语义空间。
对于分别预训练好且带有特征标记的汉语和老挝语词嵌入矩阵S、T,与Artetxe[20]等人的方法类似,引入双语种子词典M,通过SVD以自学习的方式和迭代算法学习线性转换矩阵,得到最佳映射矩阵W*后对汉语词嵌入矩阵进行线性变换得到S′,即可将汉语和老挝语词向量映射在共享的语义空间,如式(1)、式(2)所示。
S′=SW*
(1)
(2)
其中,Si表示第i个汉语的词嵌入,Tj表示第j个老挝语的词嵌入。随机抽取100对汉老双语词向量,映射前和映射后的词嵌入在二维空间下的分布如图4、图5所示。

图4 映射前的汉老双语词嵌入图

图5 映射后的汉老双语词嵌入图
通过以上处理,即可将汉老双语分布式表示映射到共享的语义空间,缩小语言的差异性。
3.4 双向长短时记忆网络(BiLSTM)层
BiLSTM通过一个正向顺序读取句子的LSTM和一个反向顺序读取句子的LSTM来分别生成两个隐藏状态,将其拼接得到含有双向信息输出的网络结构。LSTM的计算如式(3)~式(8)所示。
其中,it表示LSTM的输入门,ft表示遗忘门,ot表示输出门,ht为LSTM网络输出的隐藏状态;Wi、Wf、Wo、Wu、Ui、Uf、Uo、Uu是权重数据;bi,bf,bo,bu为偏置量。

(9)
通过以上处理,即可分别得到含有双向语义信息的汉老双语句子特征向量表示。
3.5 自注意力网络(Self-Attention)层
自注意力层是一般注意力机制(attention)的一种特殊情况[17],与一般的注意力机制相比,自注意力机制可以无视词之间的距离而直接计算依赖关系,对于捕获句子长距离依赖关系和学习句子内部结构的特点具有更好的效果。本文处理的对象为汉老双语句子对,使用自注意力机制可以得到更加准确的句子特征表示。将BiLSTM网络层得到的汉老双语句子输出状态H1和H2分别输入到自注意力层,通过自注意力层学习词和特征的重要性,同时学习句子的序列信息,最终分别得到含有长距离语义信息的汉老双语句子对特征向量。自注意力层的计算如式(10)所示。
a=softmax(wl2tanh(wl1H))
(10)
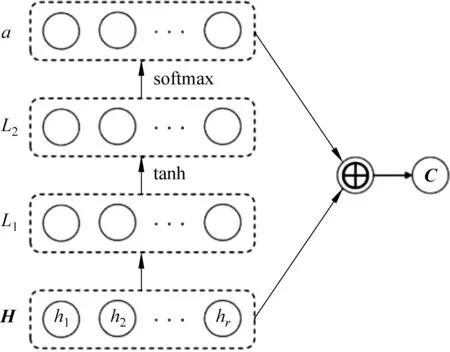
图6 自注意力机制计算过程
自注意力层的计算过程如图6所示,其中,H表示BiLSTM网络层的输出结果,H∈RT×j,T为句子长度,j为LSTM单元的输出维度,wl1和wl2为自注意力网络层学习得到的权重矩阵。通过将汉语和老挝语的输出结果H1和H2输出自注意力机制层,经过第一层线性网络层L1和第二层线性网络层L2计算后分别得到句子中词的特征权重分数a1和a2,将其与对应的向量和加权求和,得到含有长距离语义信息的汉老句子对特征向量C1和C2,计算如式(11)所示。
Ci=ai⊕Hi
(11)
通过自注意力层的计算,即可分别得到含有长距离语义信息的汉老双语句子特征向量表示。
3.6 汉老双语句子相似度表示
对于汉老双语句子对S1和S2,通过3.1~3.5节所描述的方法获取含有长距离语义信息和句子结构信息的汉老双语句子语义表示向量C1和C2后,分别对其进行按位减和按位乘操作,捕获句子对间的匹配信息,将结果进行拼接后传输到全连接网络层,计算汉老双语句子对的相似度分数p。具体计算如式(12)~式(15)所示。
其中,W1,W2,Ws,b,c为模型参数,p为取值介于0至1之间的相似度分数。模型采用交叉熵(cross entropy)作为目标函数,如式(16)所示。
L=ylog(p)+(1-y)log(1-p)
(16)
通过以上公式,即可计算得到汉老句子对S1和S2的相似度分数p。
4 实验及分析
4.1 实验设置与评价
4.1.1实验数据与模型设置
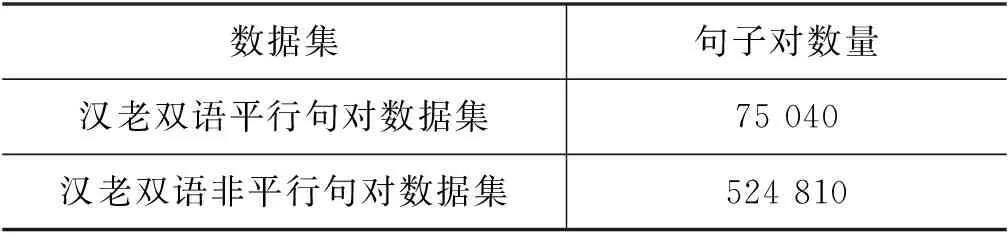
表2 汉老双语数据集
实验在固定随机种子数下使用10折交叉验证,将构建的汉老双语平行句对语料库的90%作为训练集,剩余的10%作为测试集分别训练10次,取实验结果的均值,每次训练使用的数据集划分如表3所示。

表3 数据集划分
模型实现使用Python语言及Keras框架,表4 列出了模型的实验参数设置。
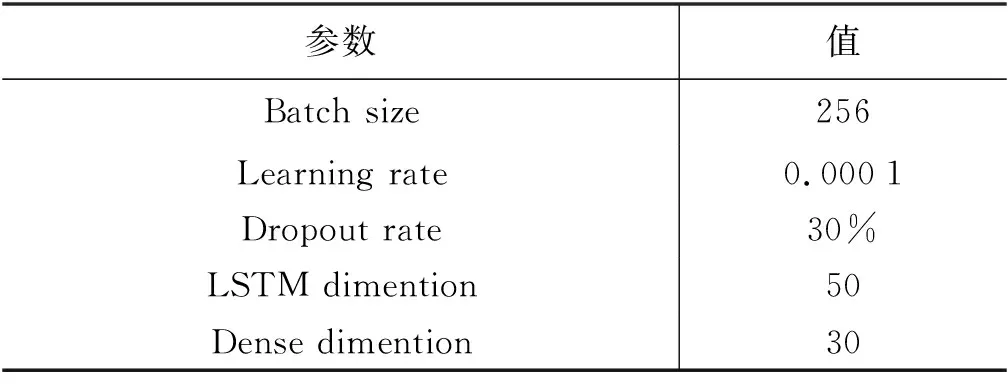
表4 模型超参数
4.1.2 评价指标
本文按照标准评价指标,统计了各种方法的准确率P和召回率R,在此基础上将各方法的F1值作为衡量模型是否可以正确分类汉语-老挝语的平行句子的最终评价指标。采用0.5作为句子相似的判别阈值,当句子对的相似度分数大于0.5时即将其分为相似句子对。准确率P、召回率R、F1值的具体计算如式(17)~式(19)所示。
4.2 模型对比实验
本文使用的模型框架为带有自注意力机制的BiLSTM模型,在此基础上加入了句子结构特征来丰富句子语义表示。为了验证自注意力机制对模型的有效性,在不同设定下训练了四个模型,每个模型的设定如下:
(1) BiLSTM模型;
(2) 带有注意力机制(attention)的BiLSTM模型;
(3) 带有自注意力机制的BiLSTM模型;
(4) 加入句子结构特征(struct_tag)的带有自注意力机制的BiLSTM模型,即本文方法。
其中,设定(1)是本文的基准模型(Base Model);设定(2)和设定(3)是为了比较不同注意力机制对模型性能的影响;设定(4)为本文方法。此外,与目前主流的3种跨语言句子相似度计算模型作了对比:
(1)Siamese LSTM模型[5]: 将平行句对分别输入共享参数的LSTM网络提取句子对的特征向量,通过计算特征向量间的曼哈顿距离得到句子对的相似度分数。模型结构设置与超参数均与原文一致,LSTM隐状态维度为50维,优化算法选择Adadelta。
(2)CNN+Self-Attention模型[6]: 对输入的平行句对分别运用CNN和自注意力机制(self-attention)得到每个句子的局部语义信息和全局语义信息,将其拼接后计算特征向量间的相对差和相对积,将结果拼接后传输到全连接网络层计算得到句子间的相似度分数。模型结构设置与超参数均与原文一致,其中,CNN卷积核设定为300,池化操作中的k设置为3,自注意力机制设置8个头,每个头的参数矩阵设置为16维,全连接层中第一层神经元节点设置为900,第二层设置为6。
(3)LSTM+ Attention模型[7]: 对输入的句子对使用带有注意力机制的LSTM提取句子对的特征向量,计算特征向量间的相对差和相对积,将结果拼接通过全连接网络层计算相似度分数。模型结构设置与超参数均与原文一致,其中LSTM隐状态维度为50,dropout设置为0.2,损失函数中L2正则设置为0.000 1,优化算法使用Adam。
以上7个模型均在相同训练语料下采用10折交叉验证进行实验,并且固定随机种子数,实验结果如表5所示。

表5 不同模型对比结果

续表
由表5可知,加入注意力机制可有效提升模型性能,与基准模型相比F1值提升了5.88%,这是由于注意力机制可以快速提取数据的重要特征,而自注意力机制作为注意力机制的改进,将注意力机制替换为自注意力机制后模型的F1值进一步提升了1.02%,原因是自注意力机制减少了对外部信息的依赖,可以更有效地捕获数据和特征的内部关联性。设定(2)和设定(3)训练的模型相比较,说明了自注意力机制在研究句子相似度任务上的有效性。此外,加入句子结构特征使模型的F1值提升了3.07%,说明设定(4)的特征方法对于汉老双语句子相似度的研究是有效的。
另一方面,Siamese LSTM模型和CNN+Self-Attention模型与本文模型相比F1值分别低了10.75%及4.82%。分析原因后发现Siamese LSTM模型的框架虽然对于跨语言句子相似度计算具有较好的适应性,并且LSTM网络可以在一定程度上捕获句子的特征信息,但对于高维度的特征向量,通过曼哈顿距离来度量相似性存在一定的误差;而CNN+Self-Attention模型则是对同一语系或差异性较小的语言具有较好的效果,汉语-老挝语的语言跨度较大,虽然通过自注意力机制可以在一定程度上提取句子更加准确的语义特征,但CNN提取的汉老双语句子特征具有较大差异性,因此与本文方法相比该方法的实验结果较差。LSTM+Attention模型相比本文模型的F1值低了4.57%,并且与模型(2)相比F1值低了0.48%,出现这一结果的原因是BiLSTM网络相比LSTM网络可以更好地进行句子建模,增加句子语义表示的准确性。
总结而言,在汉老双语句子相似度计算任务中,由于语言差异性较大,BiLSTM网络相比于LSTM网络和CNN网络可以更好地对句子进行建模,并且加入自注意力机制和句子结构特征可以进一步提升模型效果。
4.3 特征标记方法对比实验
由4.2小节设定(4)训练的模型可知,使用特征模板获取句子结构特征可以有效提升模型性能。为了验证本文提出的特征模板的有效性,探索特征模板的不同标记方法对模型结果产生的影响,本节按以下设定额外训练了7个模型,并且与3.2节中的设定(3)和(4)做比较,具体设定如下:
(1) 带有自注意力机制的BiLSTM模型;
(2) 在设定(1)的基础上加入句子的主语特征标记(sub);
(3) 在设定(1)的基础上加入句子的谓语特征标记(verb);
(4) 在设定(1)的基础上加入句子的宾语特征标记(obj);
(5) 在设定(1)的基础上加入句子的主语和谓语特征标记(sub+verb);
(6) 在设定(1)的基础上加入句子的主语和宾语特征标记(sub+obj);
(7) 在设定(1)的基础上加入句子的谓语和宾语特征标记(verb+obj);
(8) 在设定(1)的基础上加入句子的词性标记(pos_tag);
(9) 在设定(1)的基础上加入完整的句子结构特征标记(sub+verb+obj),用struct_tag表示,即本文方法。
在以上9个设定训练的模型中,设定(1)和设定(9)分别为4.2节中设定(3)和设定(4)训练好的模型。在本节中,设定(1)为验证特征标记对模型影响的基准模型;设定(2)、设定(3)、设定(4)和设定(5)、设定(6)、设定(7)是为了探索不同特征标记对模型的影响,以及探索不同组合的特征标记对提升模型性能的有效性;设定(8)和设定(9)则是比较了加入词性特征标记与句子结构特征标记对模型性能的影响。以上模型均使用同一训练语料采用10折交叉验证进行实验,并且固定随机种子数,实验结果如表6所示。
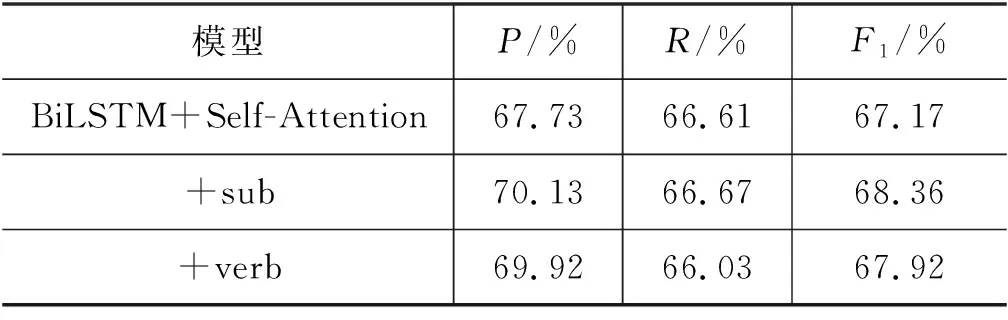
表6 不同特征标记对模型性能的影响

续表
由实验结果发现,在加入一种特征标记的模型中[设定(2)、设定(3)、设定(4)],加入主语标记(sub)的设定(2)对模型效果提升最大,与设定(1)的F1值相比提升了1.19%;加入两种特征标记的模型中[设定(5)、设定(6)、设定(7)],加入主语和宾语标记(sub+obj)的设定(6)对模型的性能提升最高,相比设定(1)的F1值提升了2.43%;而加入完整句子结构特征(本文方法)的设定(9)取得了最好的效果,相比设定(1)的F1值提升了3.07%。设定(2)和设定(6)在两组对比中得到了最好的效果,并且两者均未含有谓语标记(verb),分析后发现原因是由于在句子结构中,谓语成分通常位于句子的中间或末尾,具有模糊的位置关系,通过本文提出的特征模板对老挝语的谓语成分进行标记存在一定的误差;而主语和宾语成分通常位于句子的两端,使用本文的特征模板可以较好地确定标记位置,因此设定(6)在加入两种特征标记的模型中F1值提升最大。设定(8)在加入词性特征标记后相比未加入前的设定(1),模型的F1值反而降低了3.41%,得到这一结果的原因是由于汉语和老挝语虽然在句子的主要成分上具有一致的顺序结构(SVO),但句子的次要成分具有差异性。例如,汉语的定语通常在主语之前,状语在主语之后,而老挝语则正好相反,仅添加词性标记反而使模型更难获取句子的特征信息。
总的来说,使用特征模板获取的句子结构特征对汉老双语句子相似度计算任务是个十分有效的方法,可以弥补语料资源稀缺对模型性能的影响。
4.4 词嵌入映射方法对比实验
为了减少汉老双语的语言差异性,与 Artetxe[20]等人提出的方法类似,本文采用弱监督映射方法将双语词嵌入映射到共享的语义空间。为了验证方法的有效性,本节与目前主要使用的无监督和监督映射的方法[23-24]做对比,其中无监督映射方法指通过自学习方式学习线性变换矩阵进行映射[24],监督映射方法指使用较大双语词典学习映射矩阵的方法[25]。将未经过词嵌入映射的模型作为基准模型(Base Model_2),分别使用unsupervised、supervised和semi_supervised代表无监督、监督和弱监督映射方法,其中弱监督映射方法即本文方法。实验结果如表7所示,模型均在同一数据集下采用10折交叉验证进行实验,并且固定随机种子数,超参数均使用原文中参数,监督映射方法和弱监督映射方法使用的映射词典为同一种子词典(836对常用词)。
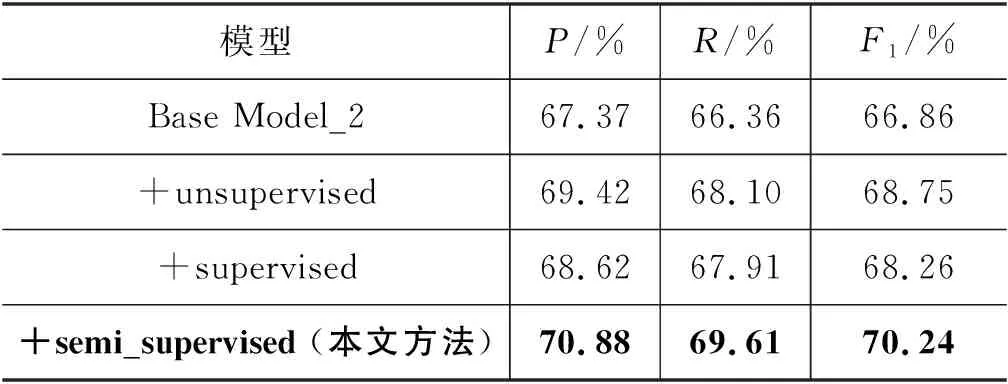
表7 不同词嵌入映射方式对模型性能的影响
由结果可知,在使用了词嵌入映射后模型的性能均获得了提升,与基准模型相比,监督映射方法(supervised)的提升最小,F1值仅提升了1.4%,而无监督映射方法(unsupervised)的F1值提升了1.89%,得到这一结果的原因是监督映射的方法需要在较大规模的双语词典下才能取得较好的效果,而由于老挝语资源稀缺,目前仅拥有小规模的词典,因此效果较差;无监督映射的方法不需要种子词典,而是通过线性变换学习转换矩阵,因此取得了一定的效果。弱监督映射(semi_supervised)的方法取得了最好的效果,F1值提升了3.38%,原因是该方法仅需要较小的种子词典即可学习到效果较好的转换矩阵,并且由于汉语和老挝语的语言差异较大,仅通过无监督映射学习存在一定的困难,因此与无监督方法相比,弱监督方法取得了最好的效果。
综上所述,对于汉语和老挝语的句子相似度计算,通过使用双语词嵌入映射的方法可以有效缩小语言间的差异性,提升模型的性能。
5 结论
本文根据汉语和老挝语句子结构的特点提出一种融合句子结构特征的汉老双语句子相似度计算方法,在将双语词嵌入映射到共享语义空间缩小语言差异性的基础上,通过加入句子结构特征有效提高了汉老双语句子相似度计算模型的性能。实验结果表明,本文方法在有限的训练样本下效果明显优于目前的主流方法,F1值达到了70.24%。下一步将考虑利用该方法提取汉老双语句子对,融入机器翻译和其他老挝语相关的自然语言处理工作中来提升效果。
猜你喜欢
天中学刊(2022年4期)2022-11-08
北京航空航天大学学报(2022年8期)2022-08-31
天津医科大学学报(2021年3期)2021-07-21
大连民族大学学报(2020年2期)2020-06-16
高中生学习·高三版(2016年4期)2016-11-19
长江学术(2016年4期)2016-03-11
人间(2015年21期)2015-03-11
长江学术(2015年1期)2015-02-27
新晨(2013年7期)2014-09-29
新晨(2013年5期)2014-09-29
