
半监督跨领域语义依存分析技术研究
2022-04-12 04:14毛达展李华勇邵艳秋
中文信息学报 2022年2期
毛达展,李华勇,邵艳秋
(北京语言大学 国家语言资源监测与研究平面媒体中心,北京 100083)
0 引言
依存分析是一种句子结构的解析方式,其将句子的句法或语义结构解析为一系列二元、非对称依存关系,这些依存关系构成了句子的依存树(或依存图)。不同于句法依存树分析,语义依存图分析是一种深层次的语义解析,其描述的是句子各个组成部分间的语义关系[1],具体示例如图1所示,其允许更复杂的依存结构(如多父节点、非投射等)。由于其能够直接表达深层语义信息,因此应用价值更大。然而,现有的语义依存分析研究使用的数据集往往来自课本或者新闻等单个领域, 这样即使依存分析器在一个数据集上取得了较高的性能,当迁移到其他目标领域时,分析器的性能也会大幅度下降。
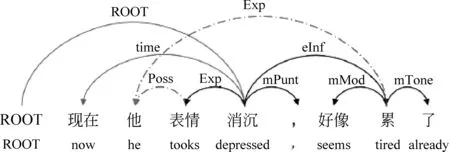
图1 语义依存分析示例
根据目标领域的数据有无标注,领域适应可以划分为无监督领域适应(目标领域完全没有标注数据)和半监督领域适应[2](目标领域存在少量标注数据,同时也有大量无标注数据)。 由于语义依存分析本身的复杂性,目前纯粹基于无监督的跨领域语义依存分析的研究进展相对滞后。而半监督的领域适应虽然仍需要少量的数据标注,但是其可以利用一定的监督信号指导领域适应,领域迁移效果更好,迁移后的模型实用价值更大,也能更好地与语义依存分析任务结合。因此本文关注于针对语义依存分析任务的半监督领域适应。本文的主要贡献如下:
(1) 提出了一个新的基于对抗学习的领域适应框架。该框架支持一个模型同时解决面向多个目标领域的领域适应问题。该框架在实验数据集上的性能明显优于基线模型。
(2) 将预训练语言模型融合到了对抗领域适应框架中,从而进一步提升了模型的领域适应能力。同时本文详尽讨论分析了应用预训练语言模型解决语义依存分析任务以及领域适应时的一系列细节问题。
1 相关工作
1.1 依存分析
现有的依存分析方法主要有两种,分别是基于转移的算法[3]和基于图[4-5]的算法。早期的这两种依存分析器需要手动定义复杂的特征模板,这费时费力且需要很强的背景知识,限制了分析器的进一步发展。[6]
近年来,神经网络方法被广泛应用在依存分析中[3,7]。在这些基于神经网络的依存分析器的研究工作中,双仿网络依存分析器取得了目前最优的性能[7]。因此,双仿网络依存分析器在本文中将作为后续对依存分析进行领域适应研究的基础。
1.2 领域适应
最近,随着ELMO、 BERT[8]等上下文表示的预训练模型兴起,大量工作开始研究基于预训练上下文表示的领域适应方法,并取得了较好的结果,展示了其在领域适应任务上的巨大潜力,Liu等人[9]分析了上下文表示中的语言学知识和可迁移性,Mulcaire等人[10]使用上下文表示提升了跨语言任务的迁移效果。受到这些工作的启发,本文将预训练模型融入到依存分析的领域适应模型中,探究上下文信息对跨领域依存分析是否有帮助。
对抗学习已经被证明可以明显提升跨领域依存分析器的性能[11-12]。但是大部分的工作为了抽取不同领域之间的无关特征,都把领域无关的特征和领域私有的特征混合在一起,这就不可避免地损失一些领域私有的信息[13]。陈等人[14]针对中文多粒度分词任务,提出了一个Shared-Private模型。在这个模型的基础上,本文对私有编码器进行简化,不同领域的私有编码器统一成一个,并增加领域预测的辅助任务。Liu等人[15-16]引入了正交约束来消除共享空间和私有空间之间的冗余信息。
2 基于对抗学习的领域适应依存分析模型
与一般基于对抗的跨领域依存分析做法一样,把混合源领域和目标领域的数据输入到Biaffine编码器[7],但本模型增加了BERT通用编码层、领域共享双编码器、领域分类辅助任务以及正交约束等可能对模型性能有提升作用的组件,模型结构如图2 所示。
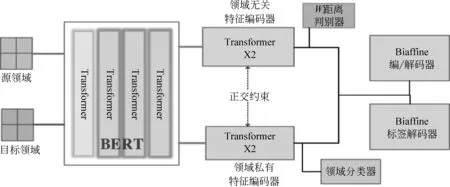
图2 基于对抗学习的领域适应依存分析模型结构
2.1 BERT通用编码层
经典的依存分析器采用词向量加词性向量的静态表征,有时也会以字符向量表示加以辅助,这种经典的组合方式不能为每个词提供基于上下文的正确表示,也无法很好地解决未登录词问题。近年来,随着BERT等预训练语言模型的涌现,越来越多的研究开始使用预训练语言模型替换经典的词向量输入,同时也有大量研究表明BERT等预训练语言模型对于跨领域迁移有着很好的帮助,因此本文使用BERT作为底层编码。BERT是多层Transformer神经网络[12]的堆叠,形式化地,BERT每层的处理过程可表示,如式(1)所示。
hi,j=BERTj(xi)
(1)
其中,i表示第i个输入,j表示第j层BERT,xi是输入的字符。
BERT默认选择使用最后一层BERT输出作为整体输出,但是已有大量研究表明,BERT等预训练语言模型每层的编码信息并不相同,一般BERT底层涉及一些语言基础知识,BERT中层编码了一定的句法结构知识,BERT高层则编码了语义知识,且BERT和训练时的任务相关度很高。因此直接使用最后一层BERT输出可能不是最好的方案,为此,本文引入了层加权机制,以一种可训练的方式加权平均不同BERT层的输出。层加权机制可形式化,如式(2)所示。
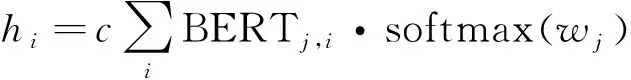
(2)
其中,wj是一个可训练的“权重”标量,用来对应每一层BERT输出;c是一个可训练的缩放标量,用于缩放最后的加权表示;BERTj,i表示第j层BERT在第i个位置的输出。
经过层加权机制后,可以得到对应输入的字符序列表示。由于依存分析是基于词语级别的,所以需要从字符序列映射到词语序列。本文采用简单的尾字表示法完成映射,即对于每个词语只选择尾字对应的表示来作为整个词语的表示。
2.2 领域共享双编码器
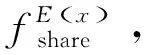
TS(X)=Skip(FF,Skip(MultiHead,X))
(3)
Skip(f,h)=LayerNorm(h+Dropout(f(h))
(4)

(5)
其中,GELU[18]代表高斯误差线性单元激活(Gaussian error linear units)函数。
为了保证领域无关特征编码器可以提取到领域共享的特征,我们在领域无关编码器上额外连接了一个对抗判别器——W距离分类器基于对抗学习的方式强制编码器编码领域无关特征。同时,为了保证领域私有编码器可以提取到每个领域的私有信息,我们在领域私有编码器上也额外连接了一个领域分类器。
2.3 对抗判别器
“领域无关”特征编码器除了连接依存任务所需的解码器Biaffineedge和Biaffinelabel外,还额外连接一个对抗判别器Dadv(x),负责提取领域之间的不变特征。
参考WGAN的实现,本文采用基于W-asserstein距离(以下简称W距离)[19-20]的对抗判别器。在使用基于W距离的损失作为对抗损失时,对抗判别器实际上是一个W距离回归网络。
形式化地,对于源领域的输入数据Xsource和目标领域的输入数据Xtarget,经过领域特征编码器后,我们分别得到对应的表示分布Ps和Pt,则Ps和Pt之间的W距离等于:

(6)

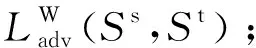
由上述可知,基于W距离的对抗学习过程是一个minmax训练,即:
其中,Θdis表示判别器的参数,Θshare表示领域无关特征编码器的参数。
在训练时我们通过先进行minΘdis训练,然后再进行maxΘshare训练的方式交替完成整个训练过程。
2.4 Biaffine解码层
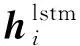
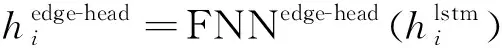
(8)
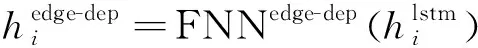
(9)

(10)
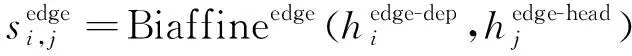
(11)
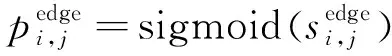
(12)
训练时,依存弧解码器的损失定义为,如式(13)所示。
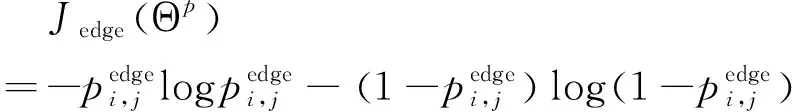
(13)
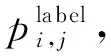
训练时,依存标签解码的损失定义如式(15)所示。
最后将依存弧概率和依存标签概率传给解码算法,就能得到最后的依存图。
在训练时,通过最小化依存损失Jparser(Θp)从而训练得到一个领域内依存分析器,依存分析损失由依存弧损失和依存标签损失相加得到如式(16)所示。
Jparser(Θp)=βJlabel(Θp)+(1-β)Jedge(Θp)
(16)
其中,β是一个超参数,用来控制最终损失中两个解码器损失的相对大小。
2.5 领域分类辅助任务
我们希望私有编码器能够提取领域私有的信息,但仅通过最小化依存任务的损失Lparser无法保证私有特征编码器真正提取到对应领域的私有信息,因此本工作又额外引入了一个私有辅助任务,即领域分类任务,负责判断编码器编码的特征属于哪一个领域。这一辅助任务类似于文本领域分类,由一个领域分类器fc(x)实现,其包括一层全连接神经网络和一个softmax 层,如式(17)所示。

训练时,领域分类器的交叉熵损失Lclassify定义,如式(18)所示。
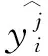
通过最小化Lclassify,可以迫使领域私有特征编码器编码对应领域的私有特征。
2.6 正交约束
加入辅助任务后可以保证领域私有特征编码器学习到了领域的私有信息,但是私有特征编码器可能会学习到一部分领域无关特征,造成特征冗余表达。为了确保这两个编码器之间不存在冗余的特征,本工作在两个编码器之间增加了一个正交约束,在训练时惩罚领域私有编码器中和“领域无关”编码器重合的特征,从而促使领域私有信息编码器不提取领域间的不变特征。正交约束损失的定义如式(19)所示。
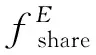

由上述公式可知,Frobenius范数代表了矩阵的所有元素平方和的开方。因此,通过最小化正交约束Ldiff,就迫使STP的乘积最小化,进而等价于迫使两个矩阵相互“正交”,从而使得两个编码器的输出特征互不重叠。
2.7 联合训练

其中,依存分析的任务损失定义,如式(22)所示。
Lparser(Θp)=βLlabel(Θp)+(1-β)Ledge(Θp)
(22)
上述β、λ、γ、η均为控制损失大小的超参数。注意,当使用目标领域的无标注数据时,Lparser只在源领域的数据上计算。
3 实验部分
3.1 数据集介绍
本研究的源领域数据集来自the SemEval-2016 task9和《博雅汉语》。经过调研,选择两大类4小类目标领域,一大类是文学风格,主要包括散文(《文化苦旅》)、小说(《小王子》《少女小渔》)、剧本(《武林外传》)三个子目标领域。另一大类是下游应用,主要是医疗诊断文本子目标领域。
依据中文语义依存图标注规范,依托语义依存图标注平台,我们组织了6名语言学专业的学生做数据标注。对于每个目标领域,我们只标注了少部分数据,然后将其划分为训练集、验证集、测试集,并对剩余的无标注数据做了清洗和筛选,如表1所示。
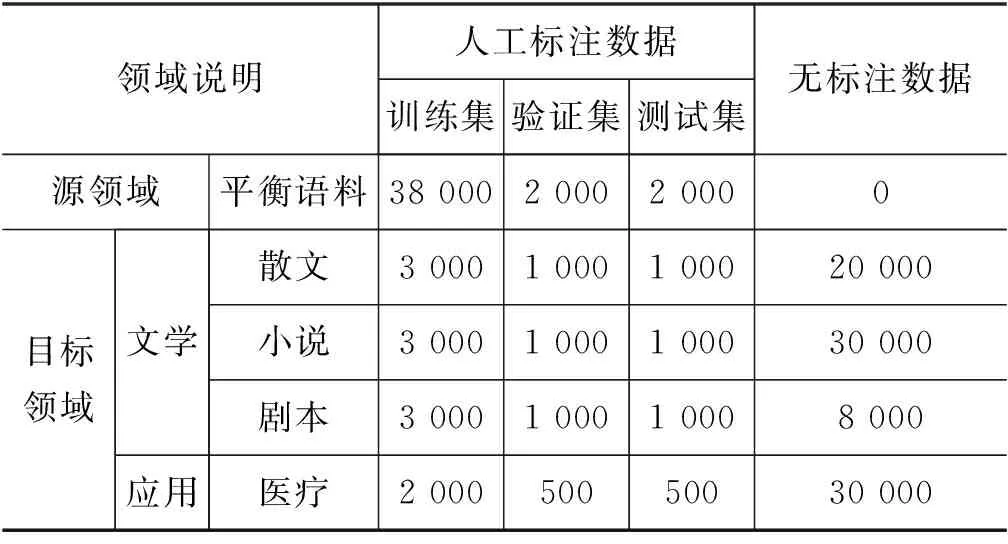
表1 数据集划分
3.2 实验设置
我们尝试了多种预训练语言模型,其层数均为12,隐层向量维度均为768。领域私有特征编码器和领域无关特征编码器都使用两层Transformer神经网络,其中Transformer层的注意力头数为8,隐层向量维度为768,dropout比例为0.2,使用ReLU激活函数。对抗损失的控制参数λ为0.5;领域分类辅助任务损失的控制参数γ为0.05;正交约束损失的控制参数η为0.001;依存损失的控制参数β为0.5。对抗判别器的学习率设置为0.000 1,模型的其他部分的学习率设置为0.001。在训练时使用带L2正则的Adam优化算法,min训练和max训练的交替比例为5∶1。输入最大句长为100,超过此长度的句子将被跳过。本文使用4张NVIDIA Tesla V100-16GB显卡完成训练,单卡的批量大小设置为32。
3.3 基线模型
为了更好地比较提出的模型的领域适应能力,我们选择了两个基线模型,分别是迁移模型Transfer和基于领域分类对抗损失的“共享-私有”模型SP-Adv:
•Transfer: 使用基于LSTM+Biaffine的单领域依存分析模型,在训练时,Transfer模型先在源领域的数据上预训练,然后再在对应的目标领域上进一步微调。
•SP-Adv: 模型使用经典的“共享-私有”框架,同样使用对抗训练,但是既不采用正交约束,也不采用领域预测的辅助任务。
此外,为了进一步对比基于预训练语言模型的动态表征和传统的基于词向量的静态表征之间的差别,我们将预训练语言模型替换为词向量加词性向量,模型其他部分保持不变,得到另一个基线模型,称为LSTM-WAdv。
3.4 实验结果
3.4.1 与基线模型的对比
表2展示了本文模型和基线模型在4个目标领域上的LAS指标,其中Transfer、SP-Adv分别代表两个基线模型的结果,LSTM-WAdv代表在本文提出的模型上去掉预训练语言模型之后的结果,BERT-Wadv、XLNet-WAdv、RoBERTa-WAdv 分别代表使用BERT[22]、XLNET[23]、RoBERTa[24]预训练语言模型的结果。
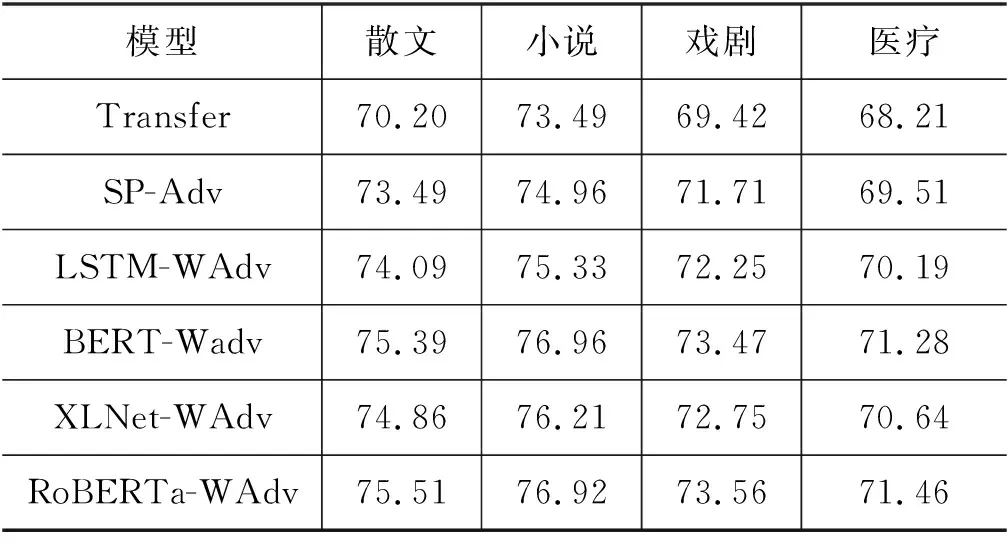
表2 本工作的模型和基线模型在4个目标领域上的LAS指标
为了更加直观地比较差异,我们绘制了模型之间的对比折线图(图3),由图3可以看出,本文提出的基于预训练语言模型和对抗学习的领域适应框架都明显优于两个基线模型。同时使用预训练语言模型的领域适应框架也要优于使用词向量的框架。同时在三种预训练语言模型中,RoBERTa展现了最好的领域适应性能。
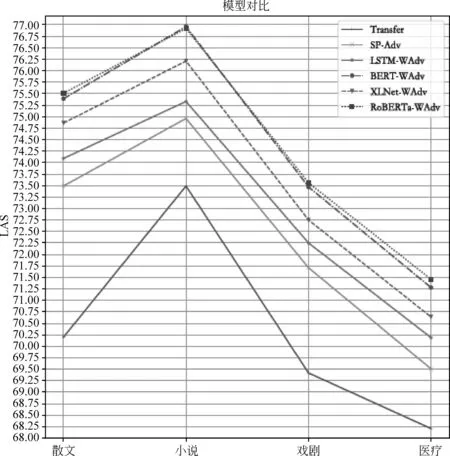
图3 本工作的模型和基线模型的对比
3.4.2 无标注数据量对领域适应的影响
为了进一步探索无监督数据量在半监督学习中的影响,我们又做了两组对比实验。这两组实验分别选择前述实验中LAS最高的小说目标领域和LAS最低的医疗目标领域。本文将这两个领域的所有无标注数据划分为相等的10份,从不使用无标注数据到使用全部的无标注数据,逐步增加无标注数据的数量训练模型,并记录对应的LAS指标。
如图4所示,无论是医疗领域还是小说领域,LAS指标都随着无标注数据量的增加呈现接近线性关系的增长。注意,在小说领域,当无标注数据使用超过七成的时候,LAS指标的提升已经非常微弱,这说明此时两个编码器已经基本收敛,无法进一步提升。
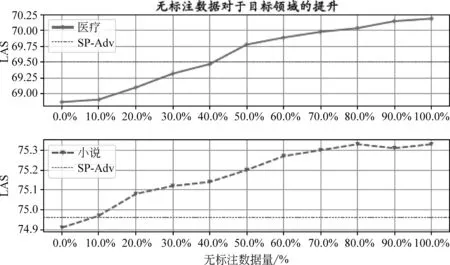
图4 无标注数据量对领域适应的影响
3.4.3 消融实验
为了进一步分析本文提出的不同组件对最终模型领域适应性能的影响,我们在LSTM-WAdv的基础上又做了相应的消融实验,如表3所示,分别记录了去掉对抗损失、去掉正交约束、去掉辅助任务以及去掉私有特征编码器时的实验结果。
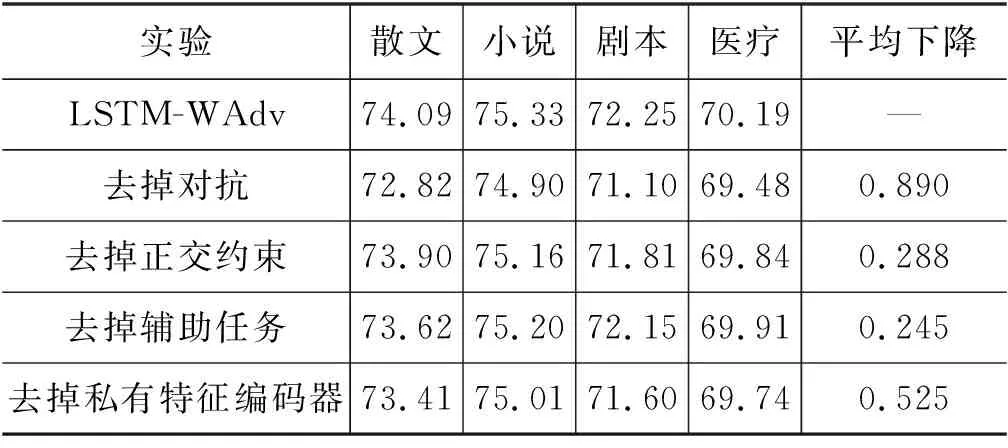
表3 消融实验
从表中可以看出,以上四个组件中,对模型最终效果影响最大的是对抗损失,去掉其之后模型在4个目标领域上平均LAS下降了0.89,这再次证明了对抗学习技术在领域适应任务中的重要作用;其次,影响模型性能的组件是私有特征,去掉其之后模型LAS平均下降了0.525,这里需要注意一旦去掉私有特征编码器,正交约束和辅助任务也相应地失去了作用,因此私有特征的影响要大于其他两个组件。同时从表中也可以看出,四个组件均对模型最终的性能有积极作用,其中影响最小的辅助任务也有0.245的平均共享。上述实验充分证明本文提出的模型方法是有效的。
4 结论
在之前提到的跨领域分析数据集上,本文提出的基于预训练语言模型和对抗学习的领域适应框架都明显优于两个基线模型,在尝试的三种预训练模型中,RoBERTa展现了最好的领域适应性能。在消融实验中,也验证了本文提出的领域适应框架的各个组件对模型最终性能的提升具有积极作用。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
网络安全与数据管理(2022年1期)2022-08-29
数学小灵通·3-4年级(2021年5期)2021-07-16
科学技术创新(2021年5期)2021-03-17
——编码器
演艺科技(2020年7期)2020-08-13
今日农业(2019年15期)2019-01-03
长江学术(2016年4期)2016-03-11
探测与控制学报(2015年4期)2015-12-15
共产党员(辽宁)(2015年2期)2015-12-06
读者·校园版(2015年19期)2015-05-14
