
基于匹配策略和社区注意力机制的法律文书命名实体识别
2022-04-12 04:15郭力华王素格符玉杰裴文生
中文信息学报 2022年2期
郭力华, 李 旸,王素格,3,陈 鑫, 符玉杰,裴文生
(1. 山西大学 计算机与信息技术学院,山西 太原 030006;2. 山西财经大学 金融学院,山西 太原 030006;3. 山西大学 计算智能与中文信息处理教育部重点实验室,山西 太原 030006;4. 北京市律典通科技有限公司,山西 太原 030006)
0 引言
在各类司法案件中,法律文书是记录案件信息的主要载体,其关键要素实体(证据名、证据内容、卷宗号等)可以作为调查、公诉以及判决等环节的关键性内容。若将大量法律文书中的证据名、证据内容和卷宗号等实体进行准确识别,可以提升司法案件的办案效率,缓解司法工作人员的工作压力。命名实体识别作为自然语言处理的一项基础性工作,在通用领域中已经取得了很好的效果。然而,在司法领域,证据名和证实内容与以往的人名、地名以及组织机构名相比其长度较长,且实体内部以及实体之间都存在一定的关联性。例如,“被告人户籍信息表[证据名](证据卷P23[卷宗号])。证实被告人肖某、男,1989年6月25日出生于贵州省平坝县,作案时已达刑事责任年龄[证实内容]”,其中证据名实体“被告人户籍信息表”与证实内容相关联,而且证实内容实体中的“1989年6月25日出生”与“刑事责任年龄”相关联。对于识别准确程度要求较高的法律文书,边界判别至关重要,仅使用现有的分词方法会出现分词错误,从而导致错误传递问题;另一方面,若使用词典资源,则需要大量人工标注等问题[1]。由于长短期记忆网络(LSTM)在序列到序列问题中有选择性“记忆力”优势,因此,基于LSTM-CRF模型[2]在通用领域的一般命名实体识别中取得了不错的性能,但是面对长度较长的法律文书命名实体识别,若仅采用LSTM,在较长的序列中,先输入的内容将被后续输入的内容稀释或覆盖,而基于卷积神经网络(CNN)的方法只能获得局部信息。对于图网络Lattice-LSTM[1]和Collaborative Graph Network模型[3],两者都需要外部词典获得分词边界信息,而词典匹配的词作为结点构造图网络的过程较为复杂,模型训练参数量也较大。Ma等[4]提出一种利用匹配词分区简化使用词典的方法,避免了构造复杂的图网络,但是在计算匹配词权重时采用了静态词频,而在法律文书中某些证据要素仅在特定段落位置出现,导致它们的词频权重较小。
针对上述问题,本文在字级别提出了一种基于最大正向匹配策略和社区注意力机制的法律文书命名实体识别方法(FMM-CAM)。首先利用最大正向匹配策略获取句子中与词典匹配的所有词,再将其按字在词中的位置分类存放在B、M、E和S四个匹配词社区中。由于Xu等[5]利用自注意力机制获得相似法律条文和案件事实之间的关联性信息,在区分易混淆法律条文中取得了较好的性能,因此,本文受其启发利用社区自注意力机制,在匹配词社区中获得匹配词的关联性权重。同时,利用Word2Vec获得法律文书中每个字对应的向量表示,并将其和对应的中文BERT预训练模型的字向量进行拼接编码,以解决一词多义的问题。在此基础上,将字的编码信息和词的信息相融合,通过一个BiLSTM进行建模,获得新的语义表示。最后利用CRF将句子进行解码,获得最优标记序列。实验结果表明,本文方法可以对法律文书中证据名、证实内容和卷宗号等长实体进行有效识别。
1 相关工作
命名实体识别是关系抽取和问答系统等许多自然语言处理任务中的基础任务。早期主要由语言学家依据数据集的特征人工构建特定规则模板或者词典,此类方法人工成本高,泛化能力差。在现有的工作中主要分为两类,一是统计机器学习方法,例如,支持向量机(SVM)、隐马尔可夫(HMM)和条件随机场(CRF)等,其中,CRF是利用内部及上下文特征信息对某一个位置进行标注,且其目标函数不仅考虑输入状态的特征函数,还包含了标签转移特征函数,在命名实体识别中取得了较好的效果,但是这些方法都受到了特征工程的困扰。随着深度学习的迅速发展,同时考虑到CRF的优势,目前大多数工作将CNN和LSTM等深度学习方法和CRF方法相结合。例如,Collobert等[6]采用CNN-CRF模型进行命名实体识别,其优势利用CNN捕获句子中局部关键特征,对特定领域的短实体识别取得了较好的性能。LSTM可以解决长序列中梯度弥散问题,通过构造一种特殊的有选择性记忆的门控机制,可以捕获长距离的上下文信息。Huang等[7]提出了一种BiLSTM-CRF模型的命名实体识别方法,该方法利用BiLSTM获得文本序列的上下文特征信息,并利用CRF作为模型的解码层。Rei等[8]在BiLSTM-CRF的基础上融合了注意力机制,弥补了LSTM存在选择性记忆的缺点。通过注意力机制动态的获取BiLSTM编码器的中间信息,最后通过CRF关联序列标签信息。在字级别的中文命名实体识别上,Zhang[1]提出了一种Lattice-LSTM模型,之后,Sui等[3]在该模型上进行了改进,提出了性能更好的协同图网络(Collaborative Graph Network)。
相比于通用领域的命名体实体,法律领域的研究相对较少,谢云[9]提出了一种基于片段级别的GCNN-LSTM模型。王礼敏[10]提出了一种基于多任务学习模型的法律文书命名实体识别。
上述方法大多数是针对长度比较短的实体进行识别,且没有考虑到法律文书中实体之间紧密的依赖关系,若直接在法律文书上进行长实体识别其效果并不理想。针对长实体识别任务,王得贤等人[11]提出了基于字和词的BiLSTM和注意力模型的法律文书命名实体识别,其利用BiLSTM隐藏层获得字序列的分词信息,但受到LSTM长距离记忆被稀释和覆盖的局限性,在法律文书中某些长度较长实体的边界识别会受到影响。因此,本文提出了一种利用最大正向匹配策略和社区注意力机制的法律文书命名实体识别方法(FMM-CAM),该方法基于字级别的且利用最大正向匹配策略,获得词典分词信息的社区注意力方法。
2 法律文书命名实体识别模型
本文的目标是识别法律文书中的证据名、证实内容、卷宗号等较长实体,且实体间关联性较强。为了准确获取长实体边界信息,本文采用了最大正向匹配原则,通过字典树查找与该字匹配的所有词,最大正向匹配过程如图1所示。
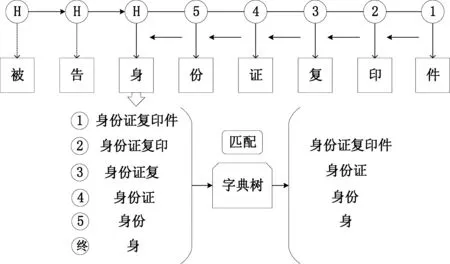
图1 最大正向匹配策略的匹配过程图
为了获得证据等实体之间的关联关系,本文利用自注意力机制计算句子中每个字对应的所有匹配词之间的关联性权重,然后将获得的长实体边界信息和实体间的关联性权重融入到模型中,从而建立法律文书命名实体识别模型FMM-CAM。该模型主要包括字符编码模块、BERT表示模块、匹配词分区模块、自注意力模块、社区匹配词压缩模块、语义表示模块和解码模块七个模块,整体结构如图2所示。
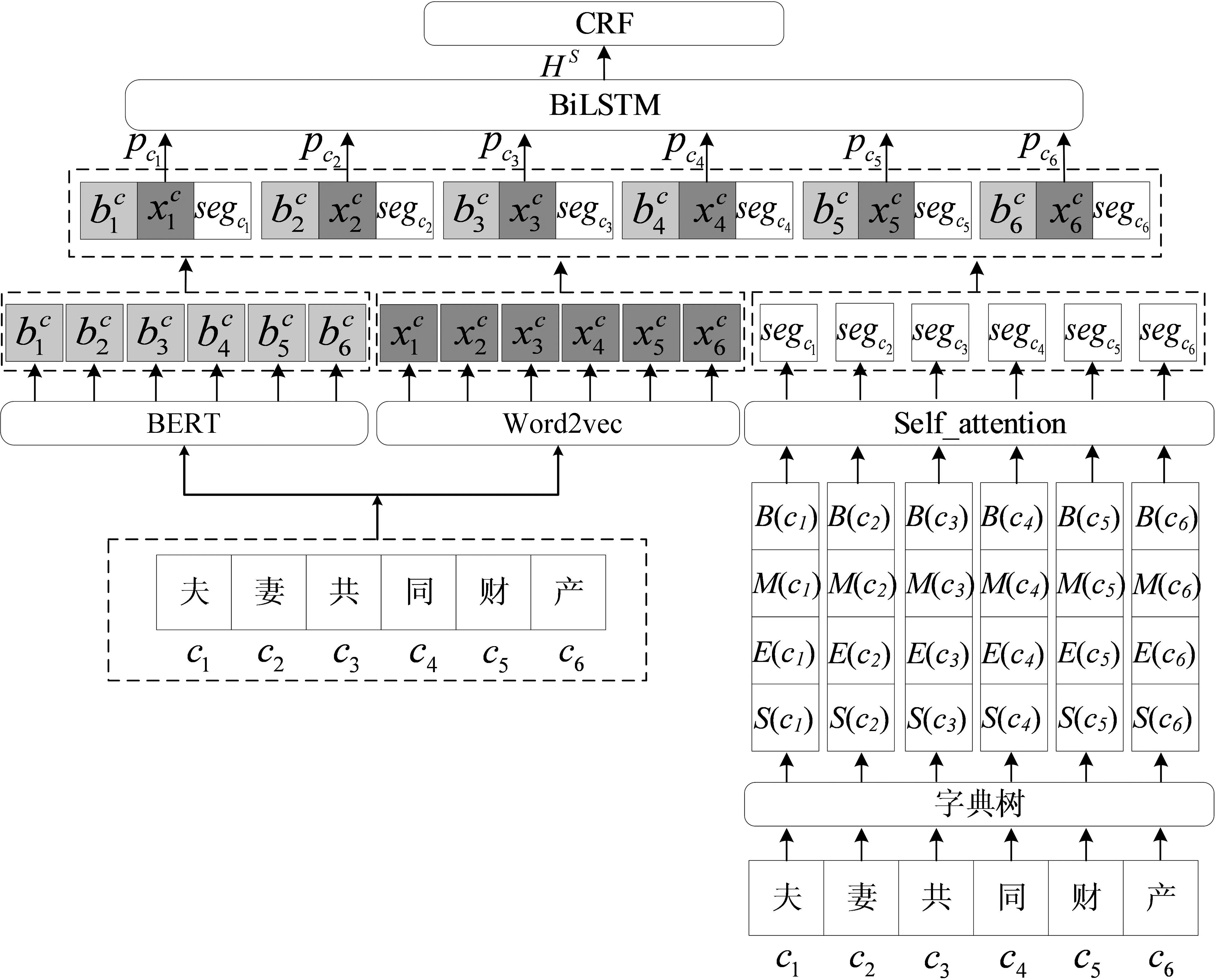
图2 模型整体结构图
2.1 字符编码模块
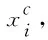
其中,ev×d1表示字向量的嵌入映射,v表示词表大小,d1表示向量维度。
2.2 BERT表示模块
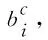
其中,bv×d2表示BERT中文预训练词嵌入映射,v表示词表大小,d2表示字向量维度。
2.3 匹配词分区模块
利用字级别的命名实体识别,可以避免分词带来的错误累积问题,但是字级别缺乏词的边界信息,也会影响命名实体识别的效果。因此,为了准确获得词的边界信息,将法律文书句子S={c1,…,ci,…,cn}中每个字ci,利用最大正向匹配策略与一个外部字典树进行匹配,然后将与字ci匹配的所有词按照字ci在匹配词中的位置分配到四个社区。B(ci)为以字符ci开头的匹配词社区;M(ci)为包含字ci且ci不作为开头或结束位置的字匹配词社区;E(ci)为以字符ci结尾的匹配词社区;S(ci)为以单个字符ci作为匹配词社区,详细匹配社区的信息如式(3)~式(6)所示。
B(ci)={wi,k=ci,ci+1,...,ck|wi,k∈L,i (3) M(ci)={wj,k=cj,...,ci,...,ck|wj,k∈L,1≤j (4) E(ci)={wj,i=cj,cj+1,...,ci|wj,i∈L,1≤j≤i} (5) S(ci)={ci|ci∈L} (6) 其中,L为外部词典,n表示该句子中字的个数。 如果某一个字符ci对应的社区为空,则将“None”添加到该空社区中。具体实例如图3所示。 图3 匹配词分区图 其中,w表示句子S中包含字ci的匹配词,d3表示匹配词的嵌入维度,a(wi,w)为匹配词wi与w的关联性权重。 (10) (11) (12) (13) 图4 匹配词社区压缩计算示例图 由于相邻标签之间具有一定的关联性,因此,CRF通过加入状态转移,使其在预测标签时保证上下文具有关联性。这些转移参数可以在训练时被CRF层自动习得。因此,模型的最后一层采用CRF进行解码。 其中,Ai,j表示在转移矩阵中标签yi转移到标签yj的值。 给定句子S,标签序列y的条件概率如式(18)所示。 其中,YS为给定句子S的所有可能标签序列。 标签序列的log似然函数如式(19)所示。 解码时输出分数最高的预测序列为y*,如式(20)所示。 为了验证本文方法对法律文书中长实体边界识别的有效性,采用Pytorch实现本文所提出的模型,运行环境为Python3.7。本文所有的实验都在一台NVIDIA TITAN Xp GPU上进行。 本文采用与文献[11]相同的数据集,该数据集包含刑事、民事领域共5 000条句子。其中,数据集的训练集、验证集和测试集的文本数分别为: 4 000、500和500。本文方法是字级别的,因此,将该数据集处理为单个字的标注数据,标注实体为三类: 证据名(EDN)、证实内容(EDC)和卷宗号(EDA)。为了细化词的边界,将原来的BIO标签修改为BMESO形式,其中,B,M和E分别表示实体的第一个字、中间字和最后一个字,S和O分别表示单字实体和非实体字。 本文选用精确率P、召回率R和F1值为法律文书命名实体识别结果的评价指标。法律文书识别的三类实体的示例见表1。 表 1 法律文书实体示例 黑体字表示属于实体 为了验证本文提出方法的性能,在法律文书数据集上将本文方法FMM-CAM与以下六种方法进行对比实验。 BiLSTM-CRF: 该模型是通用领域广泛使用的方法,主要使用BiLSTM和CRF联合。 CNN-LSTM-CRF[12]: 该模型主要使用CNN、BiLSTM和CRF联合。 Att-LSTM-CRF[8]: 该模型在LSTM-CRF模型基础上运用自注意力机制获取长序列中词语间的上下文关系。 Lattice-LSTM[1]: 该模型显式地利用字序列之间的关系获得分词信息。 JCWA-DLSTM[11]: 该模型使用RNNLM预训练模型形成字与词对应表示,通过自注意力机制获得每个词的权重,再拼接两个BiLSTM获得字、词上下文信息,最后将字和词的信息,通过一个CRF获得分数最高的标签序列。 SoftLexicon(LSTM)+BERT[4]: 该模型利用外部词典产生字在匹配词的位置信息,用于确定分词边界信息。 模型训练阶段,初始学习率设置为0.001 5,优化采用Adamax[13],其学习率的边界范围更简单。经过反复测试,结合本文数据的特点,实验参数设置如表2所示。 表2 实验参数设置 利用3.2节设计的六种方法以及直接利用BERT模型进行微调与本文方法FMM-CAM进行对比实验,实验结果见表3。 表3 不同方法实验结果 由表3可以看出: (1) 本文提出的FMM-CAM模型在精确率P、召回率R和F1值评价指标中,均优于其他六种模型,说明本文方法识别法律文书中证据等实体关联性较强且长度较长的实体是有效的,BERT(fine-tune)模型也证明,在基于字级别的中文命名实体识别中,利用词信息对准确获得实体的边界信息是重要的。 (2) JCWA-DLSTM和Att-LSTM-CRF两个模型均使用了自注意力机制,其效果均优于没有使用自注意力机制的BiLSTM-CRF、CNN-LSTM-CRF和Lattice-LSTM模型,说明自注意力机制有助于学习句子内部实体间相关联的依赖关系。SoftLexicon(LSTM)+BERT在三个评价指标上均高于JCWA-DLSTM,主要原因是采用了外部词典可以获得所有与该字相关的匹配词,增加词的边界信息。而本文FMM-CAM模型在三项评价指标上均高于SoftLexicon(LSTM)+BERT,说明本文方法一方面使用自注意力机制增强了关联性较强实体权重,使法律文书长实体的边界识别更为准确。另一方面,通过词典匹配,使其匹配的词更加全面,提升了实体识别的召回率。 为了验证FMM-CAM模型在各个部分的性能,本文设计了消融实验。将模型去除字编码(Word2Vec)模块记为-Word2Vec,将模型去掉BERT表示模块记为-BERT。将匹配词社区自注意力模块替换为静态的词频权重计算,得到模型记作-Self_attention。四种模型在法律文书数据集中的实验结果如表4所示。 表4 消融验证实验结果 由表4实验结果可以看出: (1) FMM-CAM相比-Word2Vec模型和-BERT,在三种指标上均有提升,说明Word2Vec和BERT的联合使用有利于命名实体识别。而-BERT在三种指标上下降较多,说明中文BERT预训练模型的字嵌入所表达语义信息更为准确。 (2) -Self_attention与FMM-CAM的性能相比,其性能下降明显,说明基于自注意力机制的匹配词关联性权重的计算对法律文书长实体边界的识别是有效的。 综上所述,本文的 FMM-CAM充分利用了Word2Vec和BERT联合表示以及自注意力机制,使其在法律文书的长命名实体识别上取得了较好的效果。 为了验证本文FMM-CAM模型在其他领域中的适用性,选用了社交领域的Weibo数据集和 Resume 简历数据集,并选择性能较好的模型SoftLexicon(LSTM)+BERT[4]进行对比实验,实验结果如表5所示。 表5 模型领域泛化性实验结果 由表5实验结果可以看出: FMM-CAM模型不仅对法律文书中的证据名、证实内容、卷宗号等关联性较强的长实体识别具有较好的效果,而且在社交和简历领域的效果也超过了现有的SoftLexicon(LSTM)[4]模型。充分说明本文提出的FMM-CAM模型具有较好的领域适应性。 本文采用字级别的最大正向匹配策略,提出了FMM-CAM法律文书命名实体识别方法。该方法利用了Word2Vec和BERT联合表示以及自注意力机制,使其与词典匹配词信息更加充分和全面。与目前通用领域性能较好的方法相比,本文方法在法律文书中较长且具有较强关联性的证据名、证实内容和卷宗号实体的边界确定上取得了较好的效果,从而提升了法律文书实体识别的性能。另外,值得指出的是,本文还在Weibo和Resume简历领域的数据集验证了FMM-CAM方法,均取得了较好的性能,说明本文方法不仅可以用于法律文书中的长命名实体识别,而且可以用于其他领域的命名实体识别中。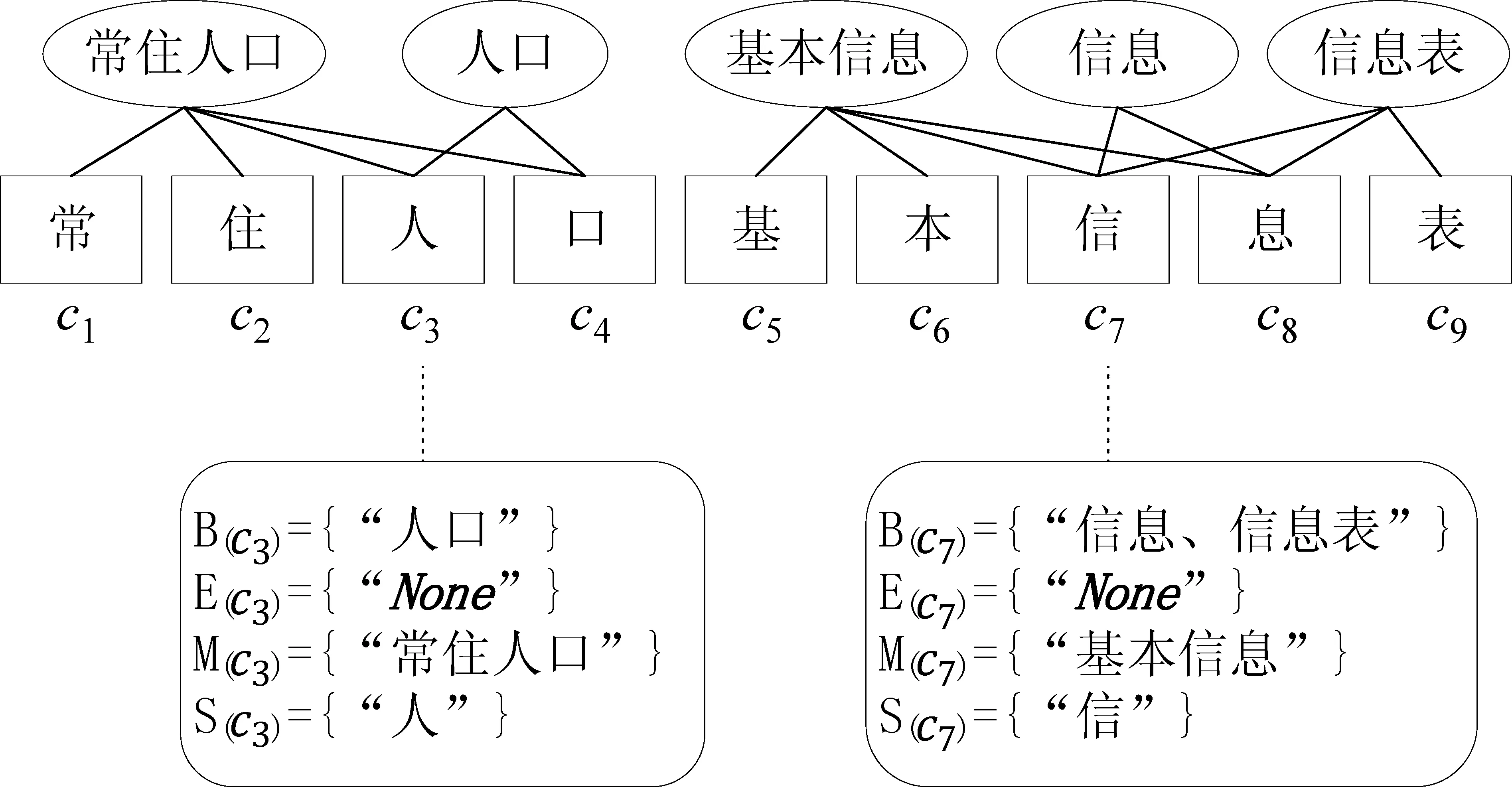
2.4 自注意力模块
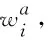
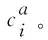
2.5 社区匹配词压缩模块
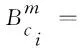
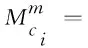
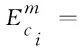


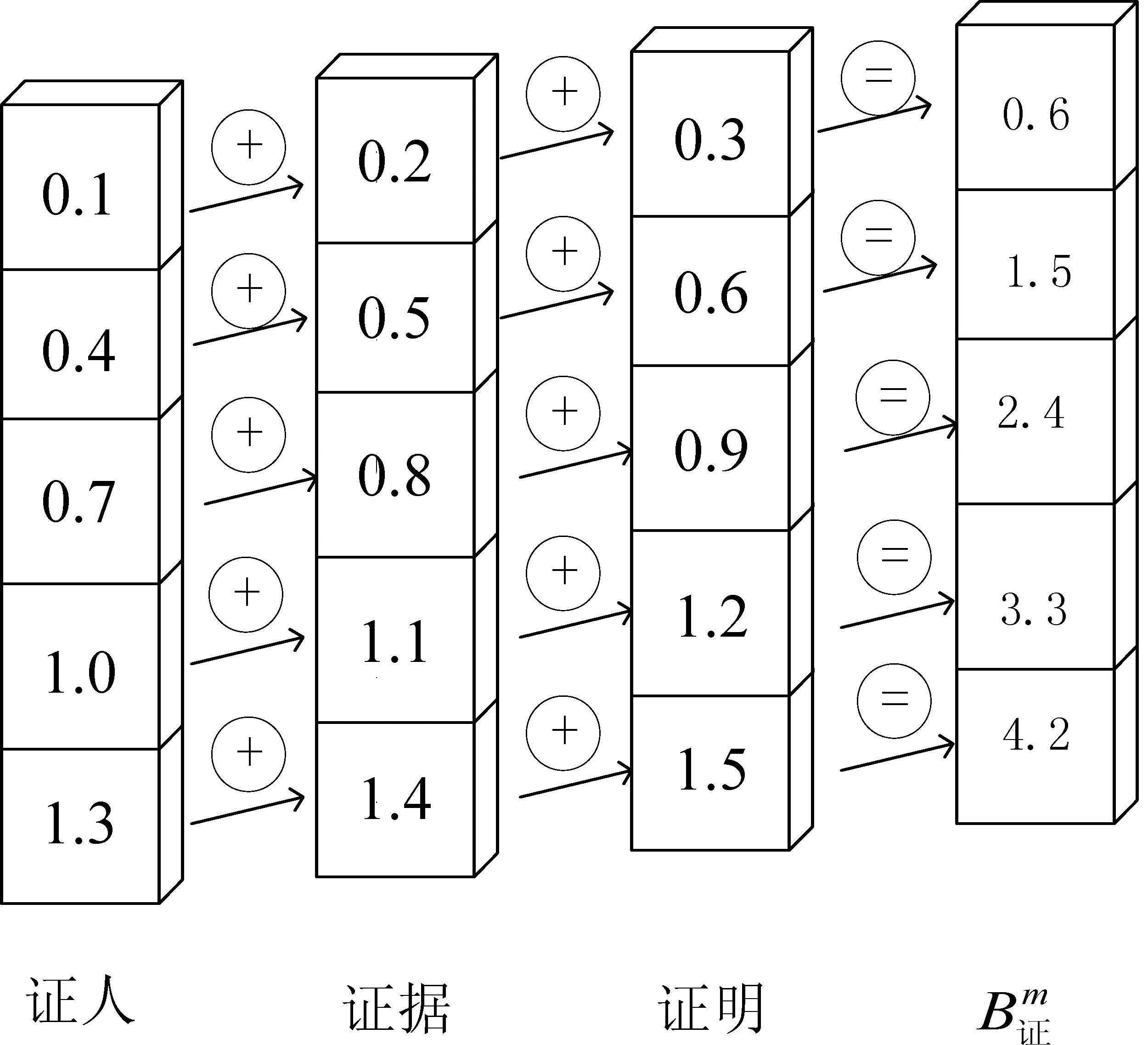
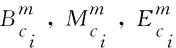
2.6 语义表示模块
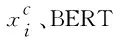
2.7 解码模块
3 实验
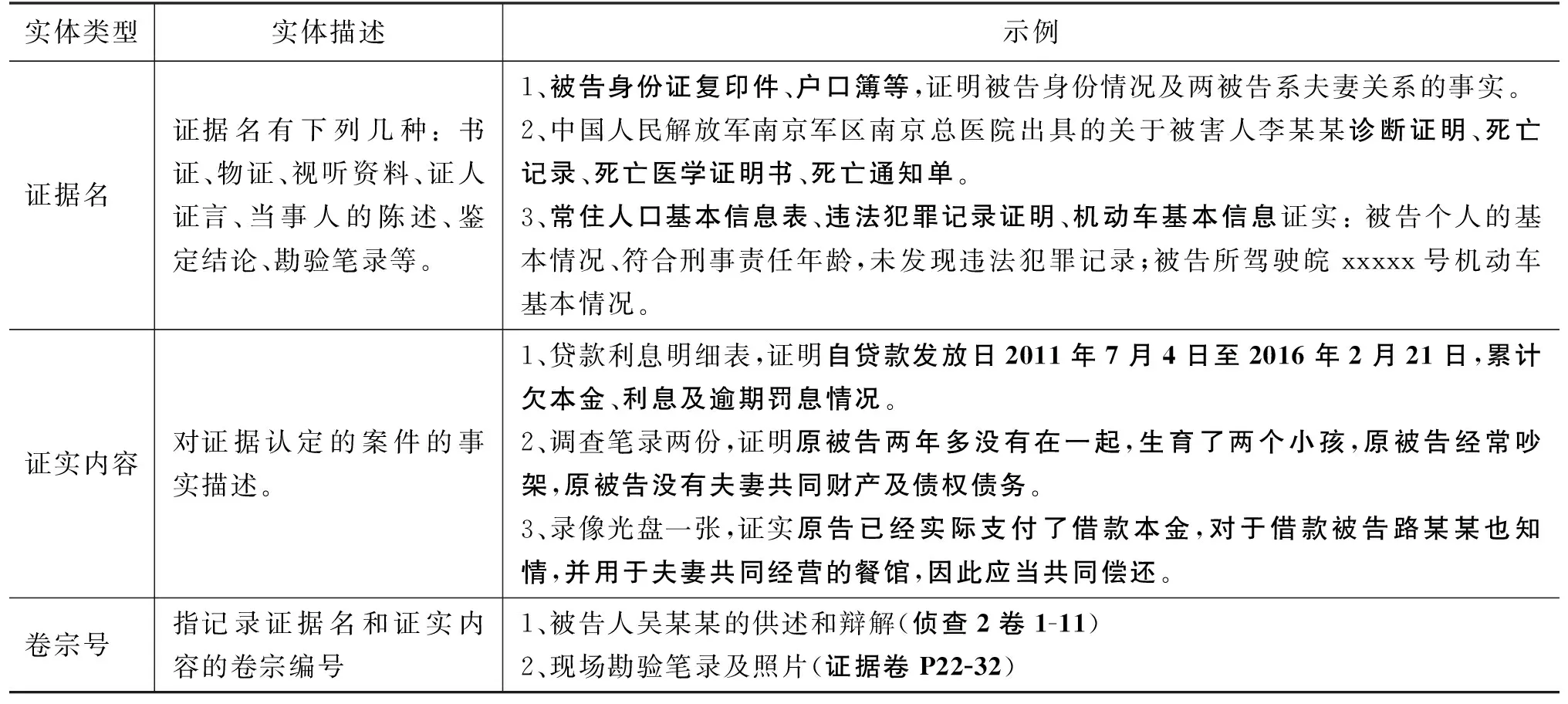
3.1 数据集与评价指标
3.2 实验设计
3.3 实验设置
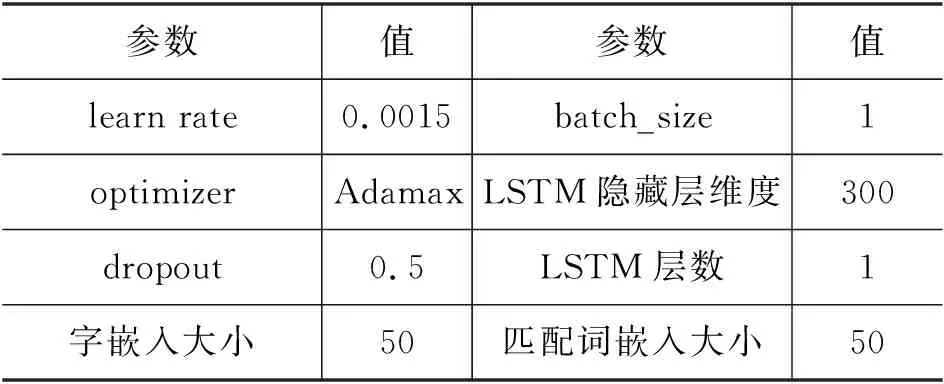
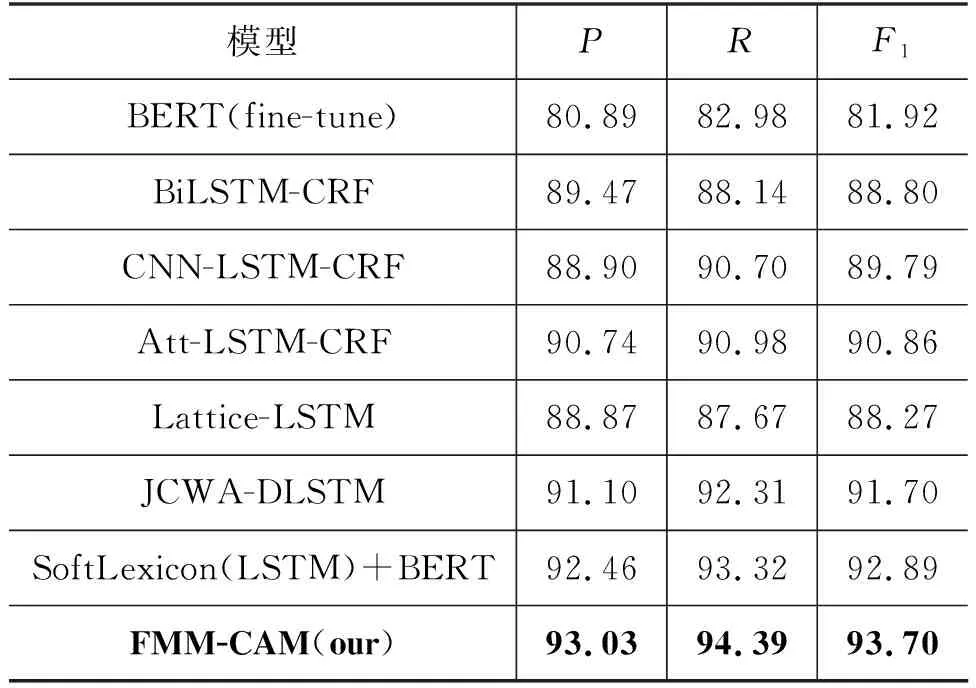
3.4 实验结果分析
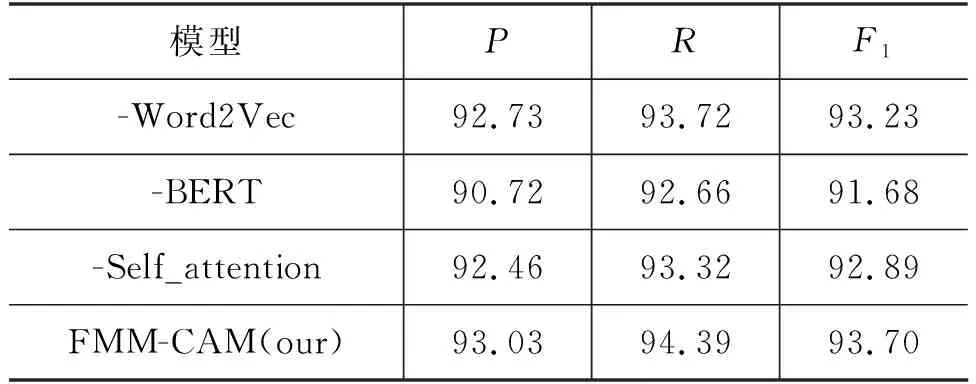
3.5 消融实验
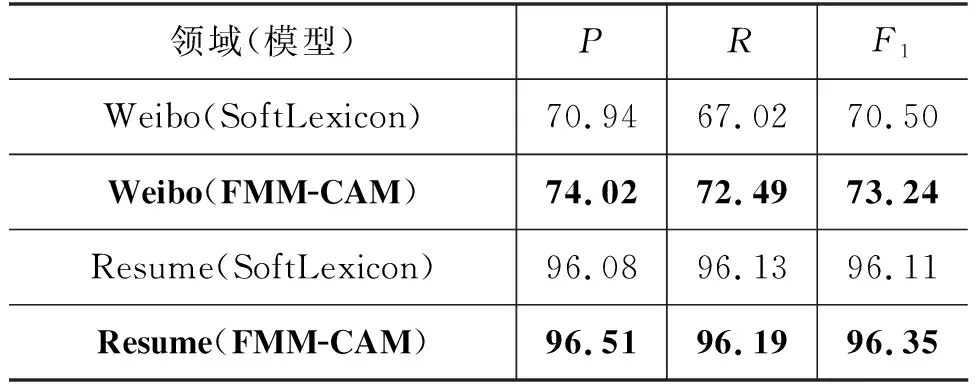
3.6 模型领域泛化性实验
4 结束语
猜你喜欢
小学教学参考(语文)(2022年3期)2022-05-26石油沥青(2022年2期)2022-05-23老年医学研究(2021年5期)2022-01-19法制博览(2021年26期)2021-11-25华北电力大学学报(社会科学版)(2021年2期)2021-07-21中学生数理化(高中版.高考理化)(2021年2期)2021-03-19云南医药(2020年5期)2020-10-27东方女性(2018年3期)2018-04-16散文诗(2017年17期)2018-01-31知识文库(2017年3期)2017-10-20
