
机器阅读理解技术及应用研究
2022-04-12 02:11吕文蓉郭泽晨
西北民族大学学报(自然科学版) 2022年1期
吕文蓉,郭泽晨,马 宁
(中国民族信息技术研究院 中国民族语言文字信息技术重点实验室,甘肃 兰州 730030)
0 引言
机器阅读理解(Mechine Reading Comprehension;MRC)任务由一个四元组
完形填空类任务是给定一个篇章D以及一个缺失某个词的句子Q,推测Q中的缺失词.多项选择类任务根据给定的篇章D、问题Q和一系列候选答案集合C,模型从候选答案集合C中为问题Q找出正确答案A.片段抽取类任务根据问题Q和对应的上下文篇章D,模型从D中抽取一个拥有最大条件概率的连续片段作为问题答案.答案生成类任务中的答案需要模型生成,它的回答形式没有限制,更适合于实际应用场景.
1 国内外研究现状
1.1 国外研究现状
早期著名的MRC系统是由Lehnert等人[2]在1977年研发的QUALM系统.20世纪90年代末,Hirschman等人[3]构造了第一个机器阅读理解数据集.2013年,Richardson等人[4]构建了全新的机器阅读数据集MCTest,这是一个多项选择类数据集.在该数据集进行训练,模型准确率可达到63%~70%.2015年至今,Hermann等人[5]建设了大规模机器阅读理解数据集CNN/Daily Mail,同时提出基于注意力机制的网络模型,该模型在CNN/Daily Mai数据集上能大幅提升.此后,机器阅读理解任务因其开放性和交互性在NLP领域取得了更多关注,从而各种模型和数据集接连被提出,如 Standford Attention Reader,AS Reader等模型,斯坦福大学的SQuAD 数据集[6],微软研究院的MSMARCO[7],华盛顿大学的NewsQA[8],NarrativeQA[9]数据集等.
1.2 国内研究现状
2017年,哈工大讯飞联合实验室提出AoA Reader[10]模型.同年,百度发布大规模中文数据集DuReader[11].2018年,IDST团队在SQuAD比赛中提出深度神经网络模型SLQA,它采用细粒度融合方式融合注意力向量,以便更好地理解问题和段落之间关系.同时在单词和句子级别上应用多粒度注意力机制,使模型在构建问题和段落表示时能适当注意最重要内容.2019年,百度发布ERNIE模型[12],用于语言理解的持续预训练框架,通过多任务学习逐步建立和学习预训练任务.实验结果表明,该模型在命名实体预测、语篇关系识别、句子顺序预测等任务中有较大改进.
2 机器阅读理解模型
2.1 注意力机制模型
注意力机制在编码或解码阶段对不同内容生成权重,权重大小代表当前内容对最终预测结果的重要性.权重计算有多种形式,同时还要综合各方面信息.机器阅读理解模型基本都要直接或间接使用注意力机制提升准确率.
注意力机制实现流程如图1所示,[x1,x2,...,xN]代表上下文信息,q为问题的向量表示,s为打分函数.注意力机制分为计算注意力分布和加权平均两个步骤.计算注意力分布先通过打分函数s计算上下文中每一个词和问题q的相关性,然后经过softmax函数层,得到注意力分布αi,如公式(1).

图1 注意力机制流程
(1)
其中打分函数s主要运算方式有加性模型、点积模型、缩放点积模型,分别如公式(2)~ (4).
(2)
(3)
(4)
其中W为模型学习参数,d表示文章向量的维度.
得到注意力分布αi后进行加权平均,得到Attention值,如公式(5).
(5)
Attentive Reader[13]模型问题表示由双向LSTM最后一个前向输出状态和最后一个后向输出状态拼接而成,文章中每个词由双向LSTM前向输出状态和后向输出状态拼接而成.训练时模型将问题表示和单词表示输入注意力层,得到问题对文章的注意力加权表征,最后将文章表示和问题表示通过非线性函数进行融合,并使用softmax进行答案预测.
Consensus Attention Sum Reader模型是先计算问题中每一个词与文章中所有词的相似度,然后将计算出的相似度通过Sum、Average、Max三种启发模式融合成一维注意力,最后使用Pointer Network预测答案.
Attention of Attention Reader (AoA Reader)[10]使用两次注意力机制,是层叠式注意力模型.该模型先得到问题与文章的相似度矩阵,再分别计算问题对文章的注意力权重和文章对问题的注意力权重;然后对问题端注意力取平均值,得到和问题表示相同的一维向量,向量中每一个值对应一个词;最后将得到的一维向量与文章端注意力权重进行加权求和,采用Pointer Network挑选出k个候选答案.将候选答案排序并填入问题空缺处形成候选句子.为验证候选句子的合理性,AoA Reader分别采用Global N-gram LM,Local N-gram LM,Word-class LM三个不同验证器对候选句子进行打分,最终选出分值最高的候选句子对应的答案作为输出答案.
Bi-Directional Attention Flow(BiDAF)模型采用编码层—交互层—输出层结构.该模型在编码层先将每个单词的词表编码和字符编码拼接成单词向量,经过一个高速网络输出结果,再输入一个双向循环神经网络LSTM,得到文章和问题中每个单词的上下文编码.在交互层同时计算从文章到问题和从问题到文章的双向注意力,并保留文章每个词的向量信息.最后在输出层采用全连接方式分别预测答案的开始位置与结束位置.
2.2 预训练语言模型
预训练语言模型完成机器阅读理解任务,需要将预训练模型的输出模块替换为机器阅读理解模型的答案预测模块.
2.2.1 ELMo
ELMo预训练模型是双向语言模型.该模型的前向和后向语言模型预测公式和最大化似然函数计算公式如(6)~(8).
(6)
(7)
(8)
ELMo模型具有处理一词多义的能力,能做到语义消歧,有不同层次的表征能力,能更好地捕获语义信息,进行词性标注;有强大的灵活性,能与机器阅读理解模型相结合,结合后模型能取得更好效果.
2.2.2 GPT
GPT是单向语言模型,在Transformer中引入自注意力机制生成上下文编码,并且提出多头注意力机制和位置编码.由于该模型只依靠上文信息进行预测,最大似然估计计算公式如(9).
(9)
GPT模型采用大量无标注语料库进行充分训练,具有很强的文本理解和分析能力.将训练好的GPT模型最后一层引入softmax作为答案输出层,再通过训练对参数进行微调,便能在机器阅读理解任务中取得较好效果.
2.2.3 BERT
BERT预训练语言模型使用多层Transformer结构.该模型在训练时增加了两个任务:完形填空和下一句预测.第一个任务使用掩码机制,随机遮盖或替换文章任意字或词,然后让模型预测被遮盖或替换的部分,该子任务使词表示包含上下文信息.第二个任务是选出两个句子A、B拼接为一句,通过拼接句子的[CLS]标志位预测句子B是否是句子A的下一句,该子任务有利于机器阅读文档,理解语义.BERT模型能完成句子分类、实体提取和阅读理解等任务.
上述三种预训练模型结构差异如图2所示.GPT 使用单向生成式语言模型,ELMo 使用独立的双向语言模型,BERT使用深度双向语言模型,Trm代表Transformer结构.

图2 预训练模型对比图
2.3 推理模型
机器阅读理解领域,答案生成类任务需要模型具有较强的推理能力.模型中引入记忆网络(Memory Networks),能有效减少信息损失,提高推理能力.
记忆网络框架如图3所示,输入文本经过Input模块编码成向量;Generalization模块根据Input输出向量对memory进行读写操作;Output模块通过计算问题与memory的权重得到输出向量,计算如公式(10)、公式(11).最终将向量输入Response模块生成答案,计算如公式(12).
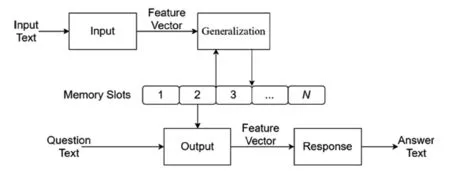
图3 记忆网络框架图

(10)

(11)

(12)
记忆网络模型能解决网络容量不足问题,但需要大量监督,无法进行反向传播训练.为解决上述问题,提出End-To-End Memory Networks模型,将记忆网络和循环注意力机制相结合,把引入的外部知识与问题进行交互,得到答案后不断重复此过程.多次推理后得到最终预测答案,计算预测答案与真实答案交叉熵,再利用反向传播算法缩小交叉熵,实现端到端的训练.Key-Value Memory Networks模型在End-To-End模型基础上优化网络结构,能更好地存储先验知识.
Gated-Attention Reader模型将multi-hop架构和门控注意力机制相结合,具有较高推理能力.该模型能基于特定问题构建更好的文章表示向量来进行更精确的答案选择.Iterative Attention Reader模型未将问题编码成单一向量,而是采用迭代交替注意力机制进行多轮推理,实现对问题和文章的细粒度搜索.ReasoNet模型引入终止门减少推理深度,防止模型因为过度推理陷入过拟合状态.
3 机器阅读理解数据集
数据集是完成机器阅读理解任务的基础,能客观评测检验模型质量,比较模型优劣.不同理解任务需要不同类型数据集.现有开源数据集可分为完形填空式数据集、多项选择式数据集、片段抽取式数据集和答案生成式数据集等.
3.1 完形填空式数据集
完形填空式数据集以填空形式构造问题,问题数量可以任意扩充.CNN /Daily Mail[11]数据集数据来源于美国新闻网和每日邮报网,网站中近100万条新闻数据被转换为<文章(c),问题(q),答案(a)>的三元组形式.BookTest也是完型填空式数据集,它是从书中连续抽取21个句子分别作为文章和问题.

表1 完型填空式数据集
3.2 多项选择式数据集
多项选择是从候选答案集中选定正确答案.2013年MCTest数据集出现.该数据集问题选项基本来自作为原文的童话故事.由于MCTest 数据集无法满足更复杂的机器阅读理解模型,学术界又开放RACE数据集和CBT数据集,二者的数据分别来源于中国学生的英语考试题和古登堡项目提供的书籍,答案需要模型联系上下文进行推理.

表2 多项选择式数据集
3.3 片段抽取式数据集
片段抽取式数据集的答案更加复杂,包括单一实体和文章片段.SQuAD[6]数据集是该类数据集的典型代表﹐数据来自维基百科.2016年Maluuba研究院提出 NewsQA数据集,该数据集数据来源于CNN新闻,其中包含12万问答对,均基于人类自然语言编写.

表3 片段抽取式数据集
3.4 答案生成式数据集
答案生成类任务是从文章中抽取或生成答案,具有代表性的数据集是MS MARCO数据集[7].该数据集答案无法直接在文章中获取,需要模型进行推理.2017年百度公司提出了首个机器阅读理解领域的答案生成类中文数据集 DuReader.

表4 答案生成式数据集
4 评价指标
评价指标是衡量机器阅读理解模型性能的可靠依据.一般情况下,完形填空类和多项选择类机器阅读理解任务通过准确率进行评价;片段抽取类机器阅读理解任务使用EM(精确匹配)和F1值(模糊匹配)进行评价;答案生成类机器阅读理解任务使用ROUGE-L和BLEU值进行评价.
4.1 EM
EM算法是在概率模型中寻找参数最大似然估计或最大后验估计的算法,其中概率模型依赖无法观测的隐性变量.该算法经过两个步骤迭代进行计算:第一步计算期望,利用对隐藏变量的现有估计值,计算最大似然估计值;第二步最大化,通过迭代寻找似然函数最大化时对应参数,迭代过程计算如公式(13).
(13)
4.2 F1值
F1值是先计算模型的召回率Recall、准确率Precision,计算方法如公式(14)、公式(15),最后调和平均,因此即便预测答案和参考答案不完全匹配也能得分.F1值计算方法如公式(16).
(14)
(15)
(16)
4.3 ROUGE-L
ROUGE将系统生成的自动摘要与人工生成的标准摘要相对比,通过统计二者之间重叠基本单元的数目来评价摘要质量,计算方法如公式(17).
(17)
ROUGE-L是机器阅读理解比赛的主要评价指标,计算方法如公式(18)~(20).其中LCS(X,Y)是X和Y的最长公共子序列长度,m、n分别表示参考答案长度和预测答案长度,Rlcs、Plcs分别表示召回率和准确率,最后Flcs即ROUGE-L.
(18)
(19)
(20)
4.4 BLEU值
BLEU值最初作为机器翻译效果评价指标,应用到机器阅读理解任务后,用于衡量预测答案与标准答案的相似性.它的取值范围在0~1之间,模型分数越接近1,质量就越高.BLEU值计算方法如公式(21)、公式(22).公式中lr为机器译文长度,lc为最短参考译文长度,Pn为n-gram准确率.
(21)
(22)
5 机器阅读理解应用
机器阅读理解是让机器读懂文本、理解文本语义﹑挖掘或推理文本关键信息,帮助人类从海量信息得到所需信息,解决问题.机器阅读理解主要应用场景是搜索引擎、智能问答、智能教育和辅助决策.
5.1 搜索引擎
传统搜索引擎只能返回与用户搜索相关的文档,而使用机器阅读理解的搜索引擎能精确定位文档中问题的正确答案,使用户体验得到改进.如使用百度搜索引擎查询“中国的首都是哪里”,它会直接返回正确答案“北京市”.机器阅读理解能将查询最相关的搜索片段进行展示,查询关键词也会重点标出,使用这种搜索引擎能给用户提供更多信息和更好体验.
未来搜索引擎发展趋势有多媒体搜索和情景搜索.多媒体搜索引擎查询方式多样化,包括文本、图片、音频和视频等.情景搜索引擎能自动了解用户所处环境,并能根据“此时此地此人”建立模型,理解用户信息需求.
5.2 智能问答
问答系统是可以自动回答用户问题的系统.机器阅读理解在智能问答方面的代表性应用场景是客服机器人和社区问答.
聊天机器人是加入人工智能算法后,有近似人脑学习能力的程序,能批量处理相对需要大脑思考的工作,主要用于客服咨询.在客户服务中,利用机器阅读理解技术能提高服务效率和接待数量,也能提高接待转化率和游客留联率.
传统的社区问答答案包含大量信息噪音,而结合机器阅读理解的社区问答可以过滤网络社区的信息噪音,能快速而准确地得到用户需要的答案.
5.3 智能教育
训练机器阅读理解的过程是计算机学习语言的过程,而已经训练完成的机器阅读理解模型能帮助人学习.机器阅读理解在教育领域的典型应用是作文自动批阅.
经过训练的自动批阅模型能理解作文语句,检查作文的语言正确性和语意连贯性,能给予学生帮助,纠正作文语法错误并归纳易错点,可帮助学生提高作文水平.模型添加语音合成和语音识别技术,就能锻炼学生听写读的能力.模型添加机器视觉技术,就能直接识别书写内容,让学生获得及时反馈,提高学生书写能力.
5.4 辅助决策
将机器阅读理解引入医疗、法律和金融等专业性较强领域,可以帮助用户更好地决策,并有效解决问题.
在医疗卫生领域,机器阅读理解模型能对病历文本进行语义分析,提取病人生理指标和用药历史等信息,以便在病历库寻找相似病历,总结出数种可行治疗方案供医生参考.在法律领域,智能审判可以利用机器阅读理解模型并根据现行法律决定是否支持指定案例的诉求,利用机器阅读理解模型可智能判决确定判决适用条款.在金融领域,股价预测模型利用机器阅读理解技术加深对政策的理解和对新闻舆论的情感分析,提高模型预测准确率.
6 结语
理解能力是机器和计算机走向认知智能的关键枢纽.机器阅读理解是利用人工智能技术,使计算机具有理解人类自然语言的能力,这些技术主要包括机器读懂并理解文本以及准确搜索问题答案等.本文通过概述机器阅读理解任务构成要素和发展情况,介绍注意力机制、预训练模型和记忆网络这三大关键技术及相关机器阅读理解模型,然后归纳机器阅读理解领域的公开数据集和评价指标,最终对机器阅读理解技术的应用场景提出新思路.
猜你喜欢
环球时报(2022-07-13)2022-07-13
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
环球时报(2022-03-14)2022-03-14
电影(2018年8期)2018-09-21
第二课堂(课外活动版)(2016年2期)2016-10-21
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
中学英语之友·高一版(2008年10期)2008-12-11
