
DVUGAN:基于STDCT的DDSP集成变分U-Net的语音增强
2022-04-11 10:43徐峰李平
信号处理 2022年3期
徐峰 李平
(华侨大学信息科学与工程学院,福建厦门 361021)
1 引言
现有的音频生成模型集中在直接使用时域一维信号序列,或频域中对应的傅里叶系数来合成音频样本。音频在不同频率下,周期具有不同的固定帧跳大小,生成模型必须准确地对齐不同帧之间的波形,以覆盖所有可能的相位。
对数梅尔(Log-scaled Mel,Log-Mel)谱图之间的均方误差(Mean-Square Error,MSE)只使用了振幅,可以用来量化帧间光谱包络之间的差异,但相位采用Griffin-Lim 算法[1]从振幅谱中估计而来,这种低精度的相位无法合成高保真的音频信号,研究[2-3]表明了相位对频谱图重建同步到时域波形的重要性。短时傅里叶变换(Short-Time Fourier Transform,STFT)是加窗波包的表现形式,基于傅里叶的模型[4]存在相位失配,且当傅里叶基频与音频不完全匹配时,存在频谱泄漏。部分研究试图直接或者间接估计相位谱,但效果不理想。最先进的研究在复值模型上取得了优异性能,如DCUNet[5]、DCCRN[6],但模型计算复杂度高,STFT的实虚部并不理想的强相关,且人工设计的复值处理层可能并不适合复值操作,限制了其发展。之后DCTCRN[7],在DCCRN的基础上提出以短时离散余弦变换(Short-Time Discrete Cosine Transform,STDCT)作为输入取代STFT,依靠实值神经网络估计包含隐式相位信息的掩模。该方法降低了模型计算复杂度且提升了性能。自回归波形模型WaveNet[8]、SampleRNN[9]、WaveRNN[10]采用一次生成单个波形样本的方式避免了上述问题。这些研究通常应用先验以产生具有波形包络而不是振荡的波形,缺乏物理和感知动机,表现低效或存在较大偏差,无法达到高保真的实际需求,如WaveGAN[11]等扩张卷积模型会直接产生混叠波形。且在训练过程中反馈偏差错误将恶化生成效果,使得生成样本和光谱特征等感知损失不兼容,会产生不符合的感知到自回归模型当中,进一步降低模型效率。
声码器和合成器采用振荡器生成音频,而不是预测波形或傅里叶系数,因此具有物理和感知动机,但模型分析参数需要手动调整。Jese Engel et al[1]集成了DDSP(The Differentiation Digital Signal Processing Library),专注于音频合成,能够在不损失神经网络表达能力的情况下利用强归纳偏置(Inductive Bias),无需大型自回归模型或对抗损失(Adversarial Loss)即可实现高保真音频生成。此外DDSP组件不限制生成模型的选择,且已证明DDSP组件能够显著提高音频领域的自动编码器性能。Eike J.Nustede et al.在经典的U-Net体系结构中采用变分概率瓶颈直接进行光谱重建,提出DVUNet[12],在包含已知和未知噪声类型以及混响的音频数据中对消融模型进行客观评价,证明了具有变分结构的U-Net体系优于经典U-Net网络,改善了脉冲噪声源的抑制。
本文在改进的DVUNet 的基础上与生成对抗网络(Generative Adversarial Networks,GAN)[13]相结合,提出生成对抗网络模型DVUGAN;采用STDCT作为输入特征,将变分自编码器(Variational Autoencoder,VAE)结构的U-Net 生成器与DDSP 组件结合,利用DDSP 的振荡器感知偏差的多尺度谱损失(Multi-Scale Spectral Loss)指导生成器训练,提升自编码器模型性能的同时保留神经网络和端到端训练的表达能力;设计了STDCT 判别器,另外添加了尺度不变信噪比(Scale Invariant-Singal to Noisy Ratio,SI-SNR)损失作为额外的判别器损失以平衡DVUGAN 生成对抗结构。实验证明,在主客观评价指标上DVUGAN 优于其他比较模型,证明了模型用于语音增强的优越性能。
2 DVUGAN系统模型
2.1 STDCT输入特征
离散傅里叶变换(Discrete Fourier Transform,DFT)可不丢失信息将时域信号转换到频域,但DFT作为复值类型,计算复杂度高。因为STFT 为显示相位,若采用振幅谱或能量谱以及改进的Log-Mel谱图作为输入,只能增强振幅谱,丢失了相位信息。因此不少研究在增强振幅谱的同时使用带噪语音的相位重建语音信号,这个过程难以预测,且效果不够理想。若另外采用复值层直接或间接估计相位谱,要达到理想性能,需要强大的计算能力,无法满足普遍设备的实时需求。离散余弦变换(Discrete Cosine Transform,DCT)是无信息丢失且包含隐式相位的实值转换,可作为实值网络的输入特征,降低复杂计算,提升网络性能。已有研究证明了STDCT 作为输入的有效性,如模型[14-15]。本文将STDCT 引入DVUGAN,替代原有DVUNet 的Log-Mel 谱图输入,使相位信息被隐式学习。DCT表示如下:
离散余弦逆变换(Inverse Discrete Cosine Transform,IDCT)为:
其中f(n)是时域向量,N是向量的长度。DCT 和IDCT 都在时域中操作。从图1 可知STDCT 相比STFT保留更多细节信息。
2.2 DVUGAN模型结构
本文将改进的DVUNet 与GAN 相结合,提出VAE结构的U-Net生成对抗网络模型DVUGAN。其中变分U-Net 生成器的输入特征为带噪语音x的STDCT 特征X,假设VAE 基于所观测的数据X,使用一个Q分布去近似真实的先验分布P,Q(z|X)和先验P(z)都是高斯分布。现在希望得到生成模型P(Y|z),在z的 条件下生成Y,Y表示增强信号的STDCT。为了得到P(Y|z),首先最大化输入X的对数似然估计,将潜在变量z边缘化,表达如下:
可以得到:
其中θ,φ分别表示DVUGAN 生成器G(·)和VAEV(·) 参数。
代替式(5)第二项得到:
其中,KL 散度(KL-Divergence)被描述为两个概率分布Qφ(z|X)、Pθ(z)之间的差异程度最小化由模型编码器Q(z|X)计算的潜在空间编码向量z之间的距离,而解码器则在高斯先验P(z)假设下生成模型P(Y|z)。
在重建增强语音过程中,DVUGAN 采用信号逼近的方式估计理想余弦掩模(Ideal Cosine Mask,ICM)可定义为:
其中,St,f,Xt,f表示纯净语音s与带噪语音x在第t个时间帧、第f子带的STDCT谱图。
DCTCRN 已证明激活函数会影响掩模范围进而改变模型性能,且采用PReLU(·)[16]能取得最理想的性能,故本文DVUNet 同样采用PReLU(·)。DVUGAN 生成器Gθ(·)得到掩模后与Xt,f点乘生成增强语音Yt,fSTDCT 谱图,并按以下处理Yt,f以保证振幅不被裁剪,如下:
其中,负值非零斜率α根据数据在范围内随机取值,其被认为是超越人类分类水平的关键。当α取较小固定值时退化为LeakyReLU。
DVUGAN模型如图3所示。上半部分为变分UNet生成器,被描述为带噪语音信号x,经过STDCT变换后得到谱图X,概率分布为X,z~P(X,z),其中z为潜在空间编码向量;X经过生成器Gθ(·)生成的掩模ICM与自身点乘得到增强语音的STDCT谱Y,Y可经过短时离散余弦逆变换(Inverse Short-Time Discrete Cosine Transform,ISTDCT)变换得到增强语音序列信号y。下半部分为STDCT判别器,以平衡生成对抗结构,提升模型性能。
2.3 模型参数
在本文DVUGAN 网络中,将输入统一重采样为16 kHz,汉明窗为512(32 ms),步长为160(10 ms)。训练目标定义为ICM 掩模。优化器采用Adam,epoch设置为500,初始学习率为0.001,采用早停法学习最理想的模型,若迭代次数大于300时候,依旧未达到最优模型,学习率每100 epochs 衰减0.5。输入STDCT 为512 维非对称实值向量。生成器编码器卷积层通道为[8,16,32,64,128,128,256],卷积核大小为(5,2),卷积步长为(2,1);解码层参数为[128,128,64,32,16,8,1];瓶颈大小设为256,是具有256个均值和方差参数的对角高斯分布。批处理大小为64。对于STDCT 判别器卷积层通道数为[8,16,32,64,128],其他参数和生成器编码器层一致。
2.4 目标函数
A.Multi-Scale Spectral Loss
DDSP 已被证明能够提升音频领域的自动编码器性能,且不限制生成器模型。本文将该组件集成在DUVGAN 网络中,引入DDSP 中的Multi-Scale Spectral Loss,利用振荡器感知偏差,优化模型性能。定义如下:
其中,Ai和分别为给定快速傅里叶变换数据量大小(Fast Fourier Transform Size,FFT Size)i的条件下,相对应的纯净语音序列信号s和增强序列信号y的振幅谱,计算两者之间L1 范数与对数L1 范数之和。β为权重系数。总重建损失定义为所有频谱损失之和:
B.SI-SNR Loss
本文将SI-SNR[17]作为判别器优化目标之一,用于优化判别器性能,以平衡DVUGAN的生成对抗架构,保证生成器和判别器共同优化而不失衡,表示如下:
其中,s,y分别表示纯净语音序列信号和生成增强语音序列信号,<·>表示点积操作。
C.Adversarial Loss
STDCT 判别器关于X、Y以及ground-truths的STDCT谱S之间的生成对抗博弈可以描述如下:
(1) 施做注浆锚杆:由于普通自进式中空注浆锚杆在TBM掘进过程中会对刀盘形成严重损坏,因此掌子面注浆采用Φ32玻璃纤维自进式中空注浆锚杆,通过刀孔或人孔向掌子面施做。锚杆长度根据刀盘内空间和锚杆具体施做位置确定,一般为2.0 m~3.0 m,间排距取1.0 m~1.5 m。
其中,Pdata(·)表示ground-truth 数据集分布,θG和θD分别表示生成器和判别器参数。
D.All Loss
根据以上目标函数,在平衡对抗网络且优化性能的目的下,总损失如下:
其中,λ,ω,γ分别为权重系数。
3 实验与结果分析
3.1 评价指标
评价指标描述表如表1所示。

表1 评价指标描述表Tab.1 Evaluation index description table
3.2 Deep Noise Suppression(DNS)数据集评估结果与分析
本文在ICASSP2021 DNS 挑战数据集[22]上训练DVUGAN 模型。从DNS RIR 数据集中随机选取不同房间的脉冲响应信号,用于在不同信噪比条件下与纯净语音和噪声卷积,合成混响语音,其中纯净语音和噪声随机选择,SNR 取[-6,-3,0,3,6,9]。在开发测试集Synthetic without Reverb/Synthetic with Reverb 下评估模型性能。将DVUGAN 和最近提交的部分模型进行对比,用PESQ、STOI和SI-SDR指标评估模型性能。
从表2 可以知道,模型DVUGAN 优于DVUNet,表明GAN 结构的引入进一步提升了U-Net 这类编解码结构性能。模型在混响环境下增强效果依然最佳,且相比不含混响噪声条件下的所有指标只有较小的降幅,表明引入变分结构使得模型具有一定的鲁棒性。SI-SDR 在三个指标中,相比其他模型提升最明显,这是因为DVUGAN 将SI-SNR 作为优化目标函数参与模型训练。相比DCTCRN-T,在STDCT 作为输入特征条件下,Multi-Scale Spectral Loss 和对抗结构的引入,加持了本文语音增强的表现性能。本文模型只在STOI指标下表现次于TRUNe(tFP32),这可能和其递归结构有关。
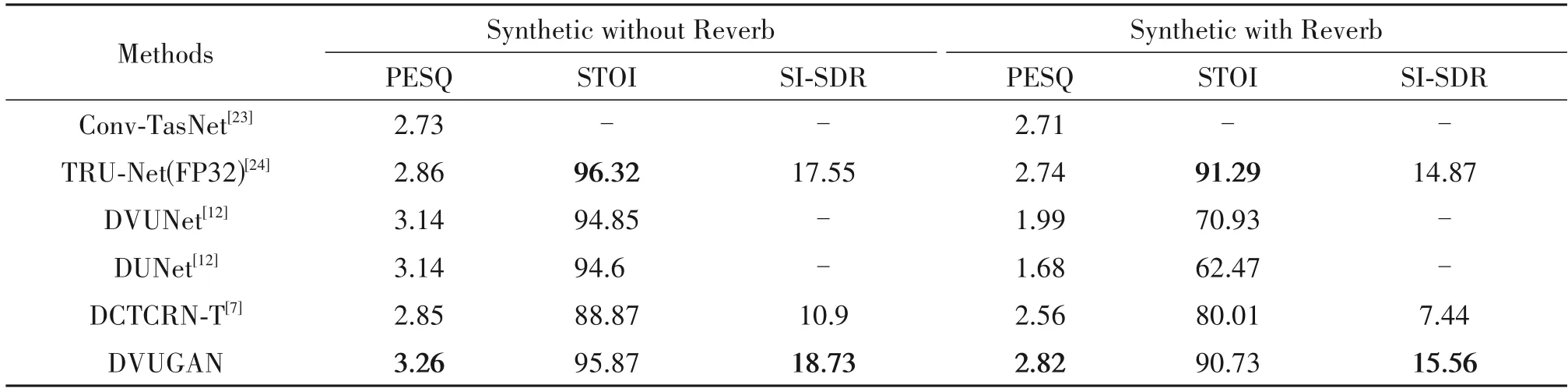
表2 DNS开发数据集下客观评价结果Tab.2 Objective evaluation results under the DNS development data set
3.3 Voice Bank+DEMAND 数据集评估结果与分析
根据表3,DVUGAN 只能取得和PHASEN 相当的性能,这与PHASEN 采用双流通道TSB,额外利用显示相位丰富的信息提升模型重建语音质量和可懂度,还有模型大小有关。像SEGAN直接预测干净语音的一维序列波形,丢弃相位信息将造成增强信号的退化,所以其表现最差。DVUGAN 采用STDCT输入特征,隐式学习相位信息,额外集成DDSP的Multi-Scale Spectral Loss 组件优化了编解码结构的生成器性能,至此模型DVUGAN 已表现优于Metric-GAN、STFT-TCN。模型性能较TDCGAN-L1和DCCRGAN-C相对更优,因为变分结构的瓶颈层和SI-SNR Loss保证了模型的鲁棒性和减少增强信号失真。

表3 Voice Bank+DEMAND 数据集下评价结果Tab.3 Objective evaluation results under the Voice Bank+DEMAND development data set
从图4 中可以看到DVUGAN 和PHASEN 在带有混响噪声背景下的语音增强性能,两者差别和表3 评价指标表现基本一致。因为Voice Bank 纯净噪声并不干净,依旧带有少量噪声,根据红框内容,与纯净STDCT 相比,可以看到DVUGAN 消除了人声前后的部分噪声,表现出比PHASEN 更强的增强能力,但这与ground-truth 的Clean 语音STDCT 并不一致,因此降低了DVUGAN 的部分指标,其实这是有益的部分。根据黑框内容,可以观察到DVUGAN相比PHASEN 能够生成更高感知质量的增强信号,这得益于模型集成了DDSP 的振荡器感知损失Multi-Scale Spectral Loss和采用STDCT作为输入特征,反映了DVUGAN 能够很好的学习隐式相位,从另一个角度看,表明了该实值网络能够达到复值网络或操作的同水平的能力,避免提升模型复杂度。
4 结论
本文设计具有变分编码结构的对抗网络模型DVUGAN。采用STDCT 作为输入特征,将相位隐式表达,无需复值网络或额外添加相位操作,即可利用相位信息用于提升模型性能,降低模型复杂度;采用包含概率瓶颈的变分U-Net,增加未知数据分布的先验知识,提高模型鲁棒性;集成了提升音频自动编码器性能的DDSP 组件,用Multi-Scale Spectral Loss 这种振荡器感知偏差损失指示训练,以保证增强语音的感知质量;额外利用SI-SNR Loss指导STDCT 判别器,以平衡DVUGAN 生成对抗结构。DVUGAN 在变换域语音增强相比基线和对比模型,表现最优。之后的研究会完善网络结构,并扩展到广义语音增强的等效领域中。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
电子技术与软件工程(2022年6期)2022-07-07
计算机研究与发展(2022年3期)2022-03-09
锻压装备与制造技术(2021年5期)2021-11-13
科学技术创新(2021年5期)2021-03-17
杭州电子科技大学学报(自然科学版)(2021年1期)2021-03-17
防爆电机(2020年4期)2020-12-14
——编码器
演艺科技(2020年7期)2020-08-13
雷达学报(2018年5期)2018-12-05
汽车维护与修理(2018年9期)2018-10-31
