基于地铁列车监控数据的牵引变流器滤网堵塞故障预警研究
2022-04-11 10:46梁师嵩
城市轨道交通研究 2022年3期
梁师嵩
(中车南京浦镇车辆有限公司, 210031, 南京∥高级工程师)
0 引言
地铁列车牵引系统的冷却装置故障关系到列车的运行安全。列车牵引系统的冷却装置风机滤网若发生脏堵,将对牵引系统的正常运行产生重要影响[1]。列车牵引部件(如变流器、变压器等)的滤网若未及时清洗、除尘,容易降低列车运行可靠性,造成安全隐患[2]。因此,如何建立准确、有效的滤网脏堵预警模型,用以指导滤网脏堵的预测维修,是亟需解决的问题。
为保证列车牵引变流器的工作可靠性,应确定合理的滤网维修方式与维修周期。目前,对于滤网的运用维修仍以计划预防修为主,并结合换件修、集中修,以确保滤网的维护质量。但经验表明,列车运行的外界环境变化对计划修的影响非常大,对一级修的影响尤为显著[1]。因此,列车的运用维修应结合外部运行环境,适当缩短或延长各部件的维修周期,以避免因不及时维修造成的系统可靠性隐患或频繁维修增加的额外维修成本。为此,利用数据挖掘技术,在列车现有数据上构建系统预测模型,以推动由计划修到状态修、再到预测修的进程,是近年的发展热点;利用预测维修理论,能够有效降低维修成本、缩短维修周期,且能够更有针对性地进行维修处理[3-4]。
根据故障清单的样本条件,可将列车牵引变流器滤网部件的故障预测方法分为两类:一是依靠异常检测的方法[5-6]。该类方法完全基于健康状态历史数据进行预测模型的正常域标定,如文献[3]构建了油冷却器的油温、温升、温差等加权特征指标,并通过无脏堵健康数据确定指标正常边界。与性能退化模型相比,基于阈值参数判别的检测方法的性能相对更依赖历史数据集的大小,故异常识别结果受阈值参数取值变化的影响较大。二是利用历史故障数据拟合性能指标的退化轨迹,该类方法需建立在足够的故障试验数据基础上。文献[1]基于不同脏堵程度的模拟数据标定风机电流值,采用设定多级电机电流控制门限的方式,以进一步减少故障误判;文献[7]利用多任务深度学习技术,拟合出变流器性能退化的曲线,实现脏堵程度的量化。
事实上,列车的外界环境多变(如受沙尘天气等影响),且滤网脏堵程度量化指标的定义依赖主观经验,缺乏确切的定义标准,因此,如何基于现阶段的列车牵引系统实时采集数据来实现滤网脏堵预警,仍需进一步探讨。
本文在不增加传感设备的前提下,利用列车历史数据,采用聚类方法进行滤网脏堵的异常检测,并对脏堵程度完成了量化。首先,根据变流器滤网的计划修清洗记录对列车采集的历史数据标签进行处理,并利用随机森林模型进行特征权重分析,以筛选出模型特征;其次,利用孤立森林模型构建牵引变流器滤网脏堵预警模型,并对模型的参数进行设定。本文所构建的孤立森林模型的模型分数能够直接反映变流器滤网的脏堵程度,可用于滤网脏堵的维修决策。
1 牵引变流器冷却系统原理分析
列车牵引变流器主要包括逆变整流模块、热交换器、风机等部件,其散热的原理是:冷却水在流经热交换器依靠风机换风降温后,再次回流至冷却水管路,完成循环降温。显然,相同的外界环境条件下,如果变流器滤网发生严重脏堵,必然导致定功率、或风机的有效换风面积减小,进而可能引发柜体温度上升、柜体内外温差增大等问题。
在建立预警模型时,一方面需要考虑外部环境变化、滤网清洗标准控制等差异,低信噪比数据并不利于复杂回归模型的拟合效果;另一方面,还要认识到故障数据标签不足的现状。本文利用冷却水进口和出口的温度差、压力差等特征向量,构建孤立森林模型,以确定滤网脏堵的正常域边界。
2 牵引变流器滤网脏堵预警模型的建立
2.1 样本分析与筛选
如表1所示,模型的输入数据至少应包括冷却风机状态、列车参考速度、环境温度、冷却水进出口温度、冷却水进出口压力等方面。

表1 滤网脏堵预警模型的输入数据类型
为降低外部环境、列车运行状态等因素对模型的干扰,本文将列车以大于50 km/h的速度运行时的数据作为历史数据集,并设定数据样本筛选的条件为:① 列车参考速度大于50 km/h;② 冷却风机为运行状态(即状态信号为“1”);③ 冷却器出水口、入水口的压力无明显异常(基于设定参考阈值);④ 冷却器出水口、入水口的温度无明显异常(基于设定参考阈值)。
2.2 特征构建与特征选择
将随机森林分类器的分类准确率作为可分性判据进行特征的重要性度量,这是机器学习中经典的特征评价策略[8]。因此,为明确特征变量对于区分滤网脏堵与洁净状态的贡献度大小,应确定构建模型使用的输入特征。本文利用随机森林分类模型来量化特征变量的重要性。
2.2.1 数据准备
每次进行滤网清洗维护时,滤网在脏堵程度、清洗标准均不可避免地存在一定的差异性[9],但滤网物理脏堵程度的主观量化值差异性水平并不会对分类的准确性产生根本性影响,因此,本文认为清洗前1 d采集的数据可以作为滤网脏堵的故障数据,清洗维修后次日采集的数据可以作为滤网的健康数据。根据该原则,本文随机选取了2次滤网清洗过程,记录清洗前1 d和清洗后1 d的数据,依次对数据进行筛选和标签处理。
2.2.2 特征生成
所构建的数据特征包括原始物理特征、再生物理特征的统计特征。其中:原始物理特征参数包括柜体温度、环境温度、进水口温度、出水口温度、进水口压力、出水口压力和列车参考速度;再生物理特征参数包括柜体温度和环境温度的差值、进水口温度和出水口温度的差值、进水口压力和出水口压力的差值。再生物理特征指基于原始物理特征形成的数学特征,包括最大值、中位值、平均值、差分值等。
2.2.3 特征筛选
上述数据经标签处理、特征提取后得到特征变量数据。本文针对双路冷却水构成的冷却系统(存在进口1、进口2和出口1、出口2),利用随机森林分类模型进行强分类能力特征变量筛选,得到特征变量的权重分布如图1所示。由图1可知:区分滤网脏堵与清洁的主要特征变量重要性按照从大到小排序,前6位分别为:柜体温度和环境温度差值的中位值、柜体温度和环境温度差值的平均值、冷却水进口1压力和出口1压力差值的平均值、冷却水进口2压力和出口2压力差值的平均值、冷却水进口1温度和环境温度差值的平均值、冷却水进口2温度和环境温度差值的平均值。因此,本文将选定这6个特征变量作为模型特征。

图1 滤网脏堵预警模型特征变量的权重分布Fig.1 Weight distribution of characteristic variables of filter fouling early warning model
本文选择某列车的A、B两节车厢作为研究对象进行对比分析。如图2所示,以测试当日作为时间参照,A车在测试日的前1 d未进行滤网清洗,B车在测试日的前1 d进行了滤网清洗。从测试当日柜体温度和环境温度差值的变化曲线可以看出:A车的温度差值明显大于B车的温度差值。

图2 滤网清洗(B车)和滤网未清洗(A车)的 车辆柜体温度和环境温度差值的对比
如图3所示,另选某个检测日,在该检测日前累计7 d内A、B车均未进行过清洗,此时A、B车在检测当日柜体温度和环境温度的差值变化曲线非常接近。这说明柜体温度和环境温度的差值是关联滤网清洗与否的直接、关键的变量,这与本文特征筛选得到的结论相符。

图3 累计7 d未进行滤网清洗的车辆柜体温度和 环境温度差值的对比
2.3 模型的建立与训练
由于故障标签的数据量不足,应结合所构建的特征建立孤立森林的异常检测模型,用以作为滤网脏堵预警模型。本文结合列车的实际维修清洗记录,默认仅有极少数日期发生过滤网严重脏堵的情况,即异常点占总样本量比例极小。根据该原则,选定2020年3月、4月列车白天的运行数据作为训练样本,在综合实际检修记录数据的基础上确定模型孤立异常点的比例值。
滤网脏堵预警模型的整体输入为当前时刻的列车参考速度、柜体温度、环境温度、冷却水进出口温度、冷却水进出口压力等数据;模型的整体输出为当前时刻滤网脏堵的模型分数,其取值范围为0~100,数值上等于异常样本数占总样本数的比例。因此,该分值越高,则表面滤网的脏堵情况越严重。图4为滤网脏堵预警模型的计算流程。

图4 滤网脏堵预警模型的计算流程Fig.4 Calculation process of filter fouling early warning model
如图4所示,滤网脏堵预警模型的训练流程为:
1) 数据处理模块。筛选满足上文所述条件的列车数据,目的是通过数据清洗规则排除非运行状态的干扰噪声。
2) 特征工程模块。针对处理后的数据,生成柜体温度和环境温度差值的中位值、柜体温度和环境温度差值的平均值、冷却水进口1压力和出口1压力差值的平均值、冷却水进口2压力和出口2压力差值的平均值、冷却水进口1温度和环境温度差值的平均值、冷却水进口2温度和环境温度差值的平均值。
3) 模型训练模块。以上述6个特征变量作为孤立森林算法的输入,在训练集上进行网格搜索,并结合经验,对孤立森林模型超参数作进一步的优化。
4) 模型分数模块。计算检测当日异常数据的比例,并将异常样本比例作为滤网脏堵的预警模型分数结果输出,将结果进行记录,如表2所示。
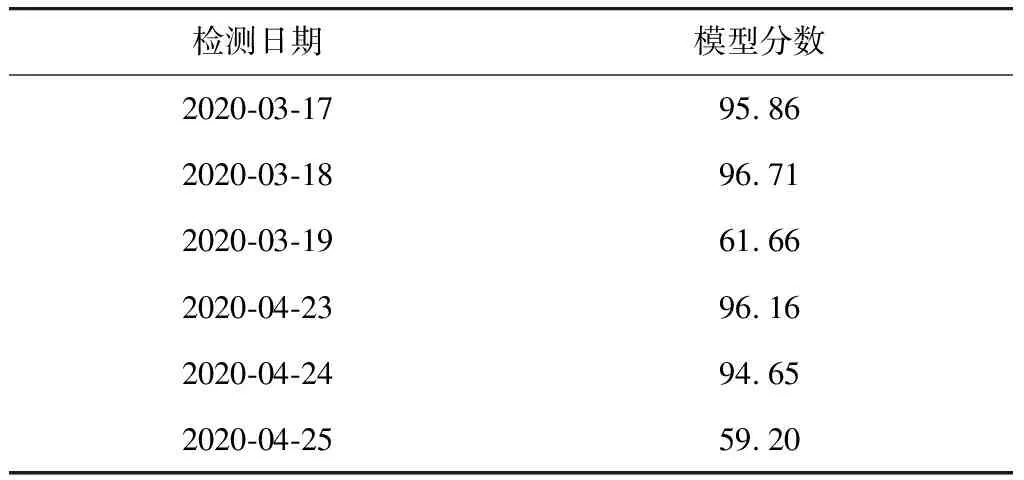
表2 训练数据集中清洗日期前后的模型分数对比
根据检修记录,2020年的3月18日和4月24日列车在完成载客任务回库后,在夜间进行了滤网清洗。表2的实际检修结果显示,滤网在3月18日、4月24日白天处于脏堵状态。
表2数据表明,3月18日(清洗前)的模型分数明显高于3月19日(清洗后)的模型分数,4月24日(清洗前)的模型分数同样高于4月25日(清洗后)的模型分数。这说明所建立模型的输出分值能够真实地反映滤网的清洁状态。
2.4 模型预测结果分析
本文选定某3列车(T1、T2、T3)2020年的5月17日至5月22日的历史数据,用以验证滤网脏堵预警模型的准确性。预警模型在测试数据上的模型分数如表3所示,其中:T1的滤网清洗时间为5月18日夜间和5月20日夜间;T2的滤网清洗时间为5月17日夜间和5月19日夜间;T3的滤网清洗时间为5月17日夜间、5月19日夜间和5月21日夜间。
由表3可以看出:
1) 以T1为例,滤网清洗当日(清洗前)所得的滤网脏堵预警模型分数显著高于次日(清洗后)的模型分数,这表明本文建立的孤立森立模型分数能够反映滤网脏堵程度的状态变化,即脏堵越严重,模型分数越高;

表3 滤网脏堵预警模型在测试集上的模型分数
2) 以T2、T3为例,清洗前、后模型分数差值幅度差异的原因可能在于清洗前的滤网脏堵程度受当日环境因素影响,或清洗前滤网有效流通面积存在差距,但这些差异并不影响脏堵程度模型分数符合预期规律;
3) 对T3在5月21日滤网清洗维护后脏堵评分的情况进行原始物理特征观测,发现目标对象在滤网清洗后1 d内列车参考速度偏小,该原因或导致冷却牵引变流系统的散热效果变差。
综上所述,本文所建立的滤网脏堵预警模型,其在测试数据集上的模型分数变化能够表征滤网清洗的数据变化规律,可有效地反映滤网的脏堵程度。
3 结语
本文针对列车牵引变流器冷却系统的滤网脏堵问题,提出了基于机器学习的变流器滤网脏堵预警模型,用以指导滤网的预测维修决策。
1) 基于特征工程与特征权重分析手段,确定采用柜体温度和环境温度差值的中位值、柜体温度和环境温度差值的平均值、冷却水进口1和出口1压差的平均值、冷却水进口2和出口2压力差的平均值、冷却水进口1和出口1环境温差的平均值、冷却水进口2和出口2环境温差的平均值等6个变量作为判别滤网脏堵的强分类能力特征变量。采用这些特征变量进行预警分析,在提升模型效果的同时也降低了滤网脏堵异常预警模型的复杂度。
2) 本文建立了基于孤立森林的滤网脏堵预警模型,该模型能够在历史数据集上较好地反应当前列车牵引变流器的滤网脏堵状态,并能有效识别滤网清洗前后的故障状态。
3) 目前影响滤网脏堵预警模型所输出的脏堵程度量化指标准确性的因素包括训练集数据量的限制、外界环境变化的不可控性、计划清洗作业规范性的主观影响等。如何提高输出指标的准确性,是未来进一步研究的方向之一。
猜你喜欢
钢铁钒钛(2022年4期)2022-09-19
广东造船(2022年3期)2022-07-09
科学与生活(2021年4期)2021-11-10
家居廊(2019年11期)2019-09-10
高中时代(2017年7期)2018-02-24
南方农业·下旬(2017年8期)2017-10-23
优雅(2017年10期)2017-10-16
神州·上旬刊(2017年3期)2017-06-27
科技与创新(2015年3期)2015-03-31
科技与创新(2015年3期)2015-03-31