
目标检测中语义约束检查算法的研究与实现
2022-04-08 03:42杨佳云么一诺柳秀梅于明鹤赵志滨
计算机工程与应用 2022年7期
杨佳云,么一诺,于 鲲,柳秀梅,于明鹤,赵志滨
1.东北大学 计算机科学与工程学院,沈阳 110000
2.东北大学 软件学院,沈阳 110000
近几年,随着卷积神经网络的快速发展,基于卷积神经网络的目标检测算法越来越成熟。基本的目标检测算法是在图像中识别每个目标的所属类别和位置信息,缺少对于目标所应满足的应用语义的检查。例如在生产安全监控视频中,目标检测不仅要识别出安全防护装备,还要检测这些安全防护装备是否被规范穿戴。
本文提出了一种目标检测中语义约束检查算法,基本思想是:形式化描述应用对于目标的语义约束,然后与实际的目标检测结果进行一致性判定,从而在目标检测的过程中同步实现语义约束检查。附加语义约束检查的目标检测算法具有非常广泛的应用,如标准工装检查、消防和安防设备检查等等。本文的主要贡献有:
(1)分析了目标检测中的语义约束类别,并据此提出语义约束的描述模型,其中包括单类别下目标的数量约束和多个目标之间的相对位置约束。
(2)基于基本的目标检测算法,提出了目标的数量计算方法和多个目标的空间相对位置计算方法;进一步,提出了目标检测结果与语义约束的一致性判定方法,实现了语义约束检查。
(3)以电力施工的防护装备检查任务为例,将目标检测中语义约束检查算法在真实数据集上进行验证,通过检查安全帽、安全带和绝缘手套是否规范佩戴这一应用实例验证算法的有效性。
1 相关工作
在计算机视觉领域内,目标检测是一个基础的视觉识别任务。基本的目标检测算法是从给定图像中检测出每个目标的类别信息和位置信息[1]。近几年,基于卷积神经网络的目标检测算法愈加成熟[2]。
文献[3-5]提出的R-CNN系列是深度学习应用到目标检测的开山之作,改进后的Faster R-CNN虽然检测准确率明显上升,但检测速度仍然达不到实时的需求。文献[6]提出的SSD目标检测算法检测速度可以达到实时,但对于小目标的检测效果略差。
从2016年开始,文献等[7-9]陆续推出了YOLO系列的端到端目标检测算法。因为具有实时的检测速度和愈来愈高的准确率,YOLO系列算法备受欢迎。YOLOv1由于输出层为全连接层,在检测时,模型只支持与训练图像相同的输入分辨率,且检测准确率比之前的R-CNN和SSD都要低。YOLOv2在YOLOv1的基础上将输出层改为卷积层,同时引入了Faster R-CNN中anchor box[10]的思想,改进了网络结构的设计,使模型更加容易学习。YOLOv3在YOLOv1和YOLOv2的基础上调整了网络结构,搭建并训练出了最新的Darknet-53模型。使用多尺度预测的方法提高了对小目标物体的检测精度;同时,将softmax分类器改为logistic分类器[11]改善了目标重叠的检测效果,检测精度大幅提高。
由于基本的目标检测算法检测信息的局限性,一些学者在传统目标检测算法的基础上增加了对图像的语境分析[12]。图像中的语境分析一般是从全局和局部两个层次考虑。全局语境是从图像整体出发考虑图像的统计信息;局部语境是利用目标周围的区域检测其他的目标或像素,分为目标级交互和像素级交互[13]。
文献[14]针对传统目标检测方法中语义关系漂移和位置建模偏差的问题,总结语境信息基本类型和应用方法。从图像空间约束、视频时空约束和语义语境约束三个方面建立目标之间的语义和位置先验模型,改善目标检测的效果。文献[15]将语义约束与视觉定位算法相结合提出了一种基于语义约束的特征点定位算法,该算法可以剔除大量的误匹配特征点,有效减少定位匹配阶段提取特征点的区域和特征点的个数,提高特征提取的效率。文献[16]提出了一种语义规则和模板相结合的安全帽佩戴图像描述生成方法,根据预定义规则结合语句模板生成描述语句,有效完成了安全帽佩戴描述生成的任务。
基于以上相关工作,本文以YOLOv3目标检测模型为基础提出了一种目标检测中语义约束检查算法。该算法不仅可以检测图像中单类别下目标的数量,还可以检测出多个目标的空间位置信息,实现从图像中提取更加丰富的内容,具有重要的现实意义。
2 语义约束检查算法
语义约束检查的目标是根据用户指定的约束对目标检测结果进行一致性检查,其中的约束包括单类别下目标的数量约束和多个目标的空间位置约束。为此,本文算法需要:提出一种语义约束描述模型;获得带有语义信息的目标检测结果,包括检出目标的数量和空间位置关系;带有语义信息的目标检测结果与语义约束进行一致性检查。本章对这三方面工作进行详细介绍。
2.1 语义约束的模型定义
目标检测任务输入是一幅静态图像,其中包含的目标也是静态的。目标检测中的语义约束可描述为式(1)的形式:

其中,L表示用户定义的目标类别的集合,F表示目标实例应满足的语义约束条件的集合。L和F来自于应用需求,由用户定义。静态目标的语义约束有单类别目标的数量约束和多个目标之间的空间位置约束。
(1)单类别目标的数量约束
单类别目标的数量是指属于同一类别的目标的个数,用 |N(L i)|( ∀L i∈L)表示,那么类别L i下的实例可以表示为O L i( ∀L i∈L)。所以,单类别下目标实例的数量约束如式(2)所示:

(2)多目标之间的位置约束
多目标之间的空间位置约束是指多个目标实例的中心点在空间中的相对位置关系,由中心点的坐标决定。任意多个目标之间的相对空间位置均可通过多组双目标之间的空间位置关系来描述。因此,只需要定义两个目标实例的空间位置关系即可,如式(3)所示:
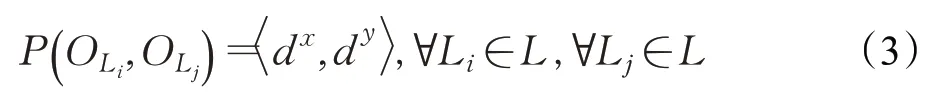
其中,d x表示O L i与O L j的水平方向上的空间位置关系。设d x表示O L i与O L j的水平距离,当d x>0,表示O L i中心在水平方向上沿正向移动d x个单位距离到达O L j中心;反之,表示O L i中心在水平方向上沿反向移动d x个单位距离到达O L j中心。同理,d y表示O L i与O L j的垂直方向的空间位置关系。设d y表示O L i与O L j的垂直距离,当d y>0,表示O L i中心在垂直方向上沿正向移动d y个单位距离到达O L j中心;反之,表示O L i中心在垂直方向上沿反向移动d y个单位距离到达O L j中心。
所以,多个目标实例之间的位置约束可以描述为式(4)的形式:
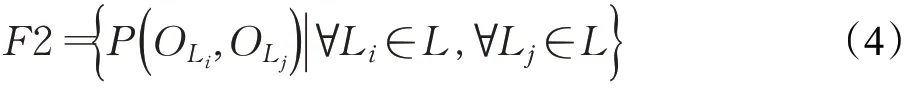
2.2 带有语义信息的目标检测
目标检测是图像分析的基础,基本的目标检测算法是从图像中逐个识别出目标的所属类别和位置信息。其中,位置信息由目标的中心坐标(x,y)和目标的宽度w、高度h表示,目标所属类别为给定标签中置信度最高的标签。
然而,仅提取单个目标的类别信息和位置信息往往不足以满足实际检测的需要。很多应用中的目标检测任务常常带有语义约束,典型的包括单类别目标的数量约束和多个目标之间的空间位置约束。为此,本文在基本的目标检测的基础上,提出带有目标数量和目标相对空间位置的语义信息检测方法。
单类别目标的数量信息可以通过统计目标所属类别标签获得,只有属于同一类别的目标才进行累加计算目标数量。类别L i所包含的目标实例数量̂(OL i)的计算式可以表示为公式(5):
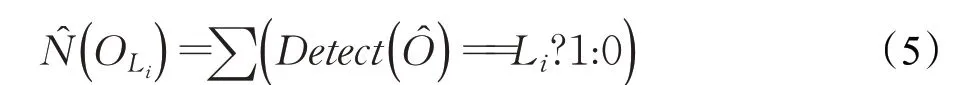
其中,Detect()为基本目标检测函数对检出目标实例的分类结果。当判定目标实例属于某一类别时,该类别数量加1,反之,则加0。
两个目标的相对空间位置是通过计算两个目标的中心坐标位置关系获得的。两个目标中心横坐标差值的绝对值表示目标间水平方向上的距离,差值的正负表示目标间水平方向上的相对方位信息;同理,两个目标中心纵坐标差值的绝对值表示目标间竖直方向上的距离,差值的正负表示目标间竖直方向上的相对方位信息。因此,目标之间的位置关系计算式如式(6)所示,形象化描述如图1所示。
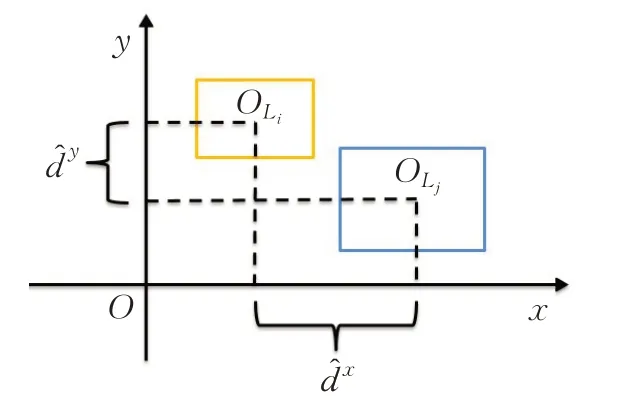
图1 目标间位置信息Fig.1 Location information between objects
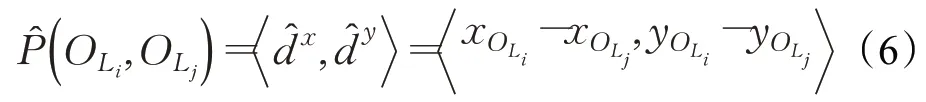
算法1带有语义信息的目标检测算法SemDetect
输入:Image
1. Inpu(tImage)
2. {}=detec(tImage)
3.for̂in{̂}:4.//Count the number of single category objects
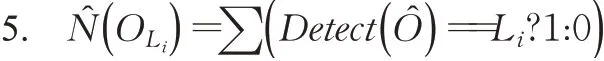
6.forO L iin{̂}:
7.forO L jin{̂}:
8.//Calculate location information between objects
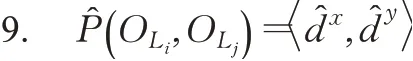
2.3 模板匹配
为了检查目标是否符合语义约束条件,需将带有语义信息的目标检测结果与用户设定的约束条件进行一致性检查。由于本文定义了单类别目标的数量约束和多个目标之间的位置约束两种约束条件,所以根据这两种约束设计两条匹配规则:一是目标数量匹配规则;二是目标间相对位置匹配规则。
(1)目标数量匹配
将带有语义的目标检测结果中同一类别的目标数量与约束条件设定的该类别目标数量进行一致性检查,如式(7)所示:
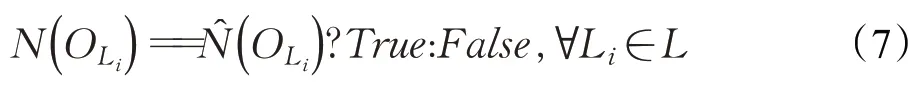
(2)目标间空间相对位置匹配
将指定目标间的位置关系与约束条件设定的位置关系进行一致性检查,检查目标间的距离是否在最大约束距离允许的范围之内。如式(8)所示:
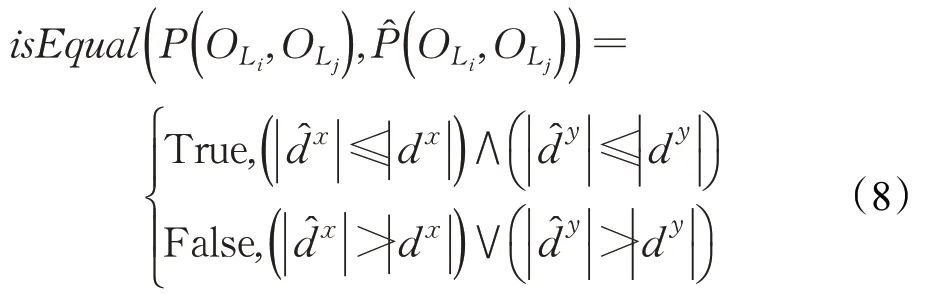
总体上,当所有检测结果及其语义均符合用户指定的语义约束时,才认为目标检测结果满足语义约束。
算法2目标检测中语义约束检查算法

3 实验设计与结果分析
3.1 实验方法
本文实验将使用所提出的目标检测中语义约束检查算法,判定安监视频中电力工人是否严格按照安全生产规范要求穿戴施工防护装备。
按照电力公司的安全生产规范要求定义约束条件,工人必须佩戴安全帽、安全带和绝缘手套。同时,安全帽必须佩戴在头顶,安全带必须穿戴在身上,绝缘手套必须戴在手上。上述规范描述如表1所示。
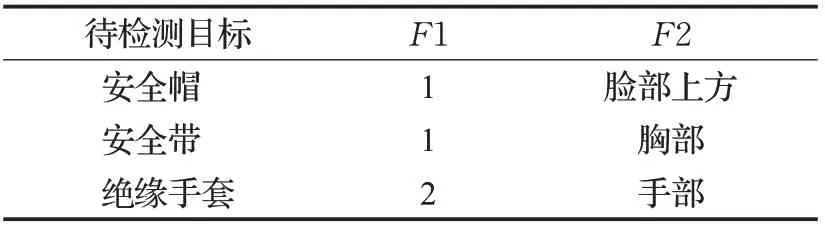
表1 安全生产规范的约束条件Table1 Constraints of safety production standard
用YOLOv3模型检测图片中的安全帽和脸部、安全带和胸部、绝缘手套和手部。统计检测出的安全帽、安全带和绝缘手套的数量,并根据脸部位置检查安全帽位置;根据胸部位置检查安全带位置;根据手部位置检查手套位置。最后,对目标检测结果与语义约束进行一致性判定。所有检查均合格判定该工人的穿戴符合公司的标准,若有一条不符合则判定该工人的穿戴不合格。
本文采用某电力公司采集的施工防护设备佩戴视频作为实验数据集。数据集中包含仅戴安全帽、仅戴安全带、仅戴绝缘手套的图片,戴其中两种设备的图片和3种设备均佩戴的图片,2分钟左右的视频,共计4 050帧图片。根据统一的标注规则进行标注,将视频的80%作为训练集,20%作为测试集进行实验。
本文实验所使用的操作系统为Ubuntu16.04 LTS,开发语言为C++,硬件为GeForce GTX 1060 6 GB。
3.2 实验结果与分析
本文提出的方法主要解决的是一个二分类的问题。对于二分类问题的评价,通常使用准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1-Score作为评价指标来评价分类算法的整体性能。其中,准确率表示是否规范穿戴的检出准确率;精确率表示规范穿戴的精确率;召回率表示规范穿戴的召回率;F1-Score表示规范穿戴的精确率和召回率的加权平均。
表2记录的是在不同阈值设定下检测安全帽是否规范佩戴的实验结果;表3记录在不同阈值设定下检测安全带是否规范穿戴的实验结果;表4记录在不同阈值设定下检测绝缘手套是否规范穿戴的实验结果;表5为最优阈值设定下整体约束检查的效果评价。
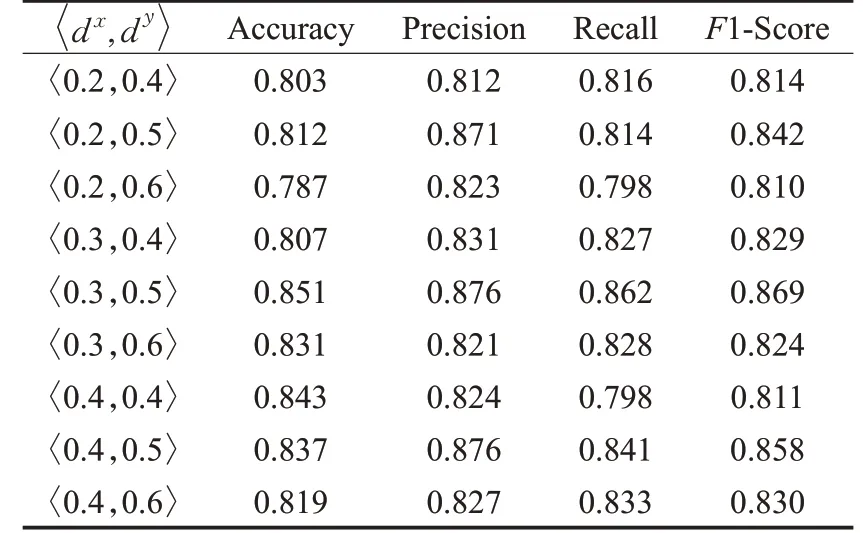
表2 不同阈值设定下的安全帽佩戴检测实验结果Table 2 Testing results of helmet wearing under different threshold settings
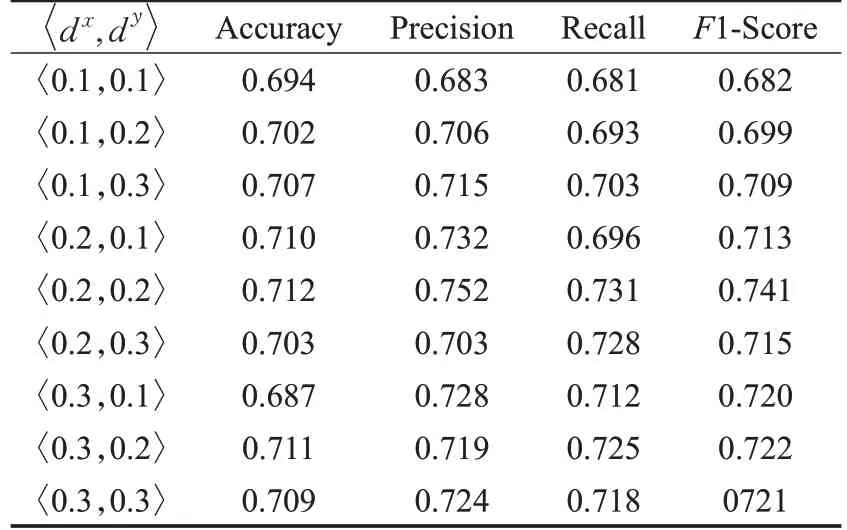
表3 不同阈值设定下的安全带佩戴检测实验结果Table 3 Testing results of safetybelt wearing under different threshold settings
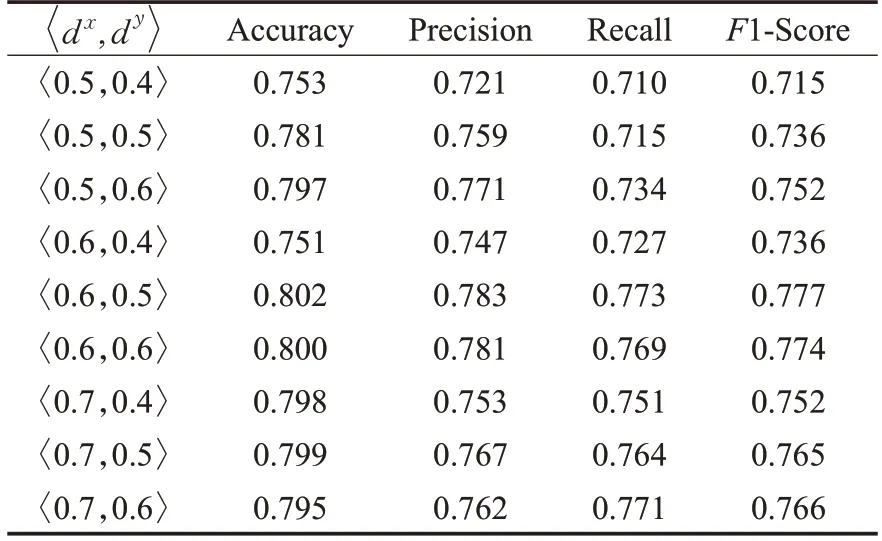
表4 不同阈值设定下的绝缘手套佩戴检测实验结果Table 4 Testing results of insulating gloves wearing under different threshold settings
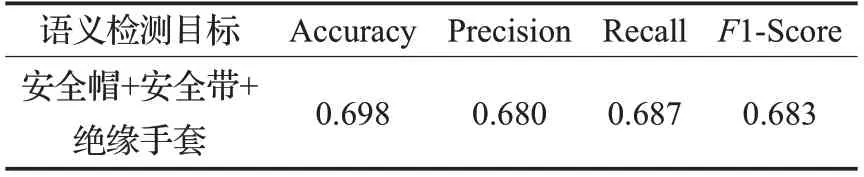
表5 整体约束检查实验结果Table 5 Testing results of overall constraint check
在进行整体约束检查时,检查规则为当所有目标均符合约束条件时才认为合格。那么,整体目标检测效果与每个目标的检测效果息息相关。因此,表5中呈现的检测指标不高。
图2为目标检测中语义约束检查算法检查规范佩戴施工防护设备实验的检测效果图。其中,图(a)表示单独检测安全帽佩戴情况;图(b)表示单独检测安全带佩戴情况;图(c)表示单独检测绝缘手套佩戴情况;图(d)表示整体约束检测。

图2 实验检测效果Fig.2 Experimental detection results
本文提出的目标检测中语义约束检查算法检测一帧图片的耗时为130 ms左右,帧率为每秒8帧。同时,为了提高检测准确率,设置当连续3帧图片均不合格时才认定其佩戴不规范。实验证明该算法能够有效完成约束条件检查的任务。
4 结束语
针对基本目标检测算法仅识别目标类别信息和位置信息的问题,本文提出了一种目标检测中语义约束检查算法。该算法定义了一种语义约束模型,提出了带有语义信息的目标检测算法,将该目标检测算法提取出的单类别目标数量信息和多个目标之间的位置信息与语义约束模型进行一致性匹配,从而检查目标是否符合约束条件。实验表明本文算法在电力施工防护装备检查任务中表现出了良好的检查效果。
随着图像分析技术的成熟,监控系统朝着智能化的方向发展将是必然趋势。本文提出的算法仍然需要深入研究的内容:
(1)除了本文提到的两个约束条件之外,还可以从其他维度对目标进行更细致的描述,比如颜色、大小等,从而提高检测准确率;
(2)除了本文使用的检查目标检测结果与语义约束是否一致的模板匹配函数之外,可探寻更加准确有效的匹配函数检查目标是否满足约束条件。
猜你喜欢
机电安全(2022年4期)2022-08-27
电机与控制应用(2022年4期)2022-06-27
少儿画王(3-6岁)(2020年4期)2020-09-13
课外生活·趣知识(2019年4期)2019-09-10
今古传奇·故事版(2017年5期)2017-04-08
北京航空航天大学学报(2016年6期)2016-11-16
微型计算机(2009年4期)2009-12-23
安全与健康(2006年2期)2006-04-21
