
教室监控下学生异常行为检测系统
2022-04-08 03:42谭暑秋汤国放涂媛雅张建勋葛盼杰
计算机工程与应用 2022年7期
谭暑秋,汤国放,涂媛雅,张建勋,葛盼杰
1.重庆理工大学 计算机科学与工程学院,重庆 400054
2.中国矿业大学 计算机科学与工程学院,江苏 徐州 221116
近年来随着高校招生扩招,以班级为单位的学生数量不断上涨,大学授课老师管理课堂、教学授课工作日益繁重。并且随着智慧化校园的普及,通过深度学习检测学生在教室中的异常行为是提高课堂效率的重要措施之一。
随着计算机视觉的日益发展,基于计算机视觉的异常行为检测可以采用两个方面的思路来实现。传统方法基于图像像素的灰度值,通过人为设计的特征模版在原图滑动并匹配像素点是否一致,从而达到检测识别的效果。传统的特征提取算法有SIFT(scale-invariant feature transform)[1]和ORB(oriented fast and rotated brief)[2],传统的分类有支持向量机(SVM)[3]或Adaboost[4]等实现分类。当检测物体的像素分布不变时可以得到快速且准确的检测识别效果,但当同一类物体在图像中呈现不同的状态时,仅依靠人为设定的特征模板难以获得较好的检测识别效果。近些年,随着计算机GPU计算能力的显著提升和世界各地的研究员对深度学习的研究,卷积神经网络以提取大量特征的优势开始成为检测识别技术的主流。此类技术分为双步检测和单步检测,前者采用的策略是先通过一个卷积网络生成特征候选区,再将生成的特征送入检测分类的网络从而实现识别检测功能,相关算法有R-CNN系列[4-6];后者将目标检测问题简化成单步的回归问题,直接通过图像获得anchor锚框从而省去了候选区生成网络,常见算法如YOLO(you only look once)系列[7-10]及SSD(single shot multibox detector)[11]等。
鉴于此,本文设计了一套基于计算机视觉的学生异常行为识别系统,即将教室监控所拍摄的学生学习状态传给计算机,利用基于YOLO v3的目标检测技术实现学生的定位与分类,再将有异常状态标签的学生位置信息封装保存用于发送预警信号。
1 系统概述
本文所设计的学生异常行为检测系统主要由视频采集、图像识别、信息响应3个模块组成,首先通过教室监控摄像头采集学生上课视频并将视频信息实时输入到计算机进行预处理,再将预处理后的关键帧输入到改进后的YOLO卷积网络中进行识别检测,封装统计网络输出的位置、类别和时间信息为API接口供其他系统实时调用。学生异常行为检测系统流程图如图1所示。
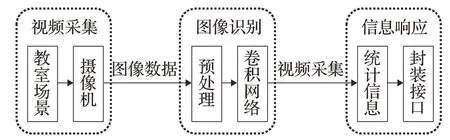
图1 教室监控下异常行为识别系统Fig.1 Abnormal behavior recognition system under classroom monitoring
视频采集模块是在教室场景下通过摄像机采集视频,对视频进行关键帧处理后,将关键帧图像数据送送入图像识别模块;图像识别模块的功能是对图像进行数据增强预处理后再通过YOLO v3进行异常行为检测;信息响应模块的功能是将异常信息进行数理统计,计算图像中异常行为人数、类别、所占比例等信息,并将这些信息封装成类,方便其他模块或模块调用。
2 YOLO v3网络
本文采用YOLO v3网络框架进行图像识别功能,YOLO网络为单步目标检测网络,去除了候选区网络,将检测任务转换成端到端的回归任务,降低了网络的参数量,提升网络性能并实现了实时检测的功能。YOLO v3网络由特征提取网络和多尺度预测网络组成,前者是轻量级深度学习框架Darknet-53,用于提取不同深度的数据特征,后者融合前者提取到的特征,并对特征进行预测,最终得到预测类别和检测框的坐标。
由图2可知,YOLO v3的主干网络Darknet-53采用了较深的网络结构提取较丰富的语义特征,并在网络中增加大量的残差网络层解决网络深度增加产生的网络退化现象。虽然残差网络可以降低参数运算量,但是较为庞大的网络结构仍然会影响单阶段检测网络的实时性,为此YOLO v3的作者提出了另一个版本的网络YOLO v3 Tiny,该网络的主干网络删除了一部分冗余的网络层,并将原本的3个预测层降低到2个,在精度下降的同时,检测速度大幅度提高,YOLO v3 Tiny与同类型网络在COCO公开数据集上的性能如表1所示。
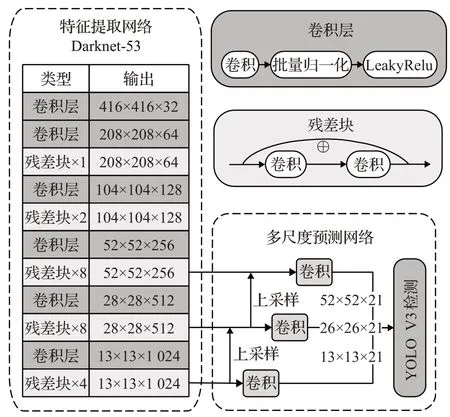
图2 YOLO v3网络结构图Fig.2 Network structure diagram of YOLO v3
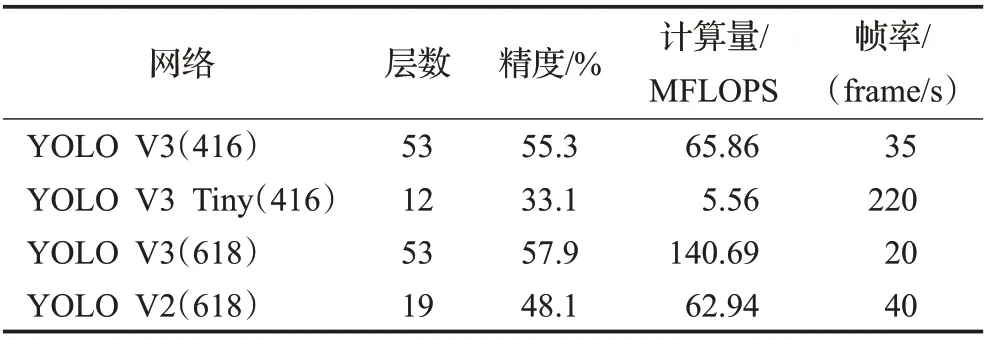
表1 YOLO不同版本网络对比Table 1 Network comparison of different versions of YOLO
3 针对教室监控的学生异常行为的YOLO v3的改进
3.1 图像预处理
数据增强是图像预处理的常用方法之一,它可以在一定程度上扩充样本、防止过拟合、提高模型鲁棒性。本文采用了改进后的random erasing(随机擦除法)[12]数据增强方法,模拟图像中的目标被遮挡的情形,增加数据集的数量,提高网络的泛化能力,使得网络仅通过学习局部特征即可完成目标的检测和识别。该算法过程如下:
(1)设置擦除概率P,若擦出概率大于P,则随机选择图像中的一块矩形区域I e,并填充制定像素值或随机像素值。
(2)设置随机矩形区域I e的相关参数。随机矩形区域面积,其中S表示图像的面积,其值为图像的水平像素个数与垂直像素的个数的乘积,s l、s h表示认为设定擦除面积的阈值,通过随机擦除矩形区域面积Se可以得到随机擦除矩形的高和宽:
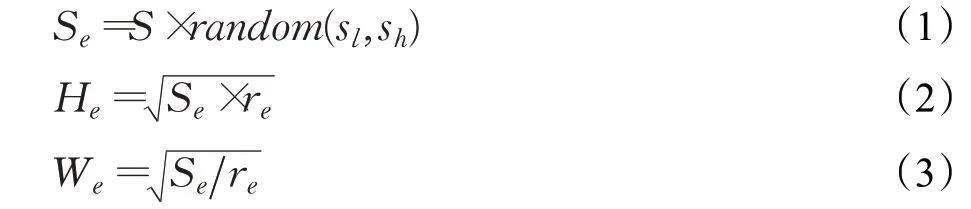
其中r e表示擦除矩形的高宽比,可以通过手工设定或在一定范围内生成随机值。
(3)在图像中随机选择一个点Pe=(x e,ye),xe,y e的限制条件:
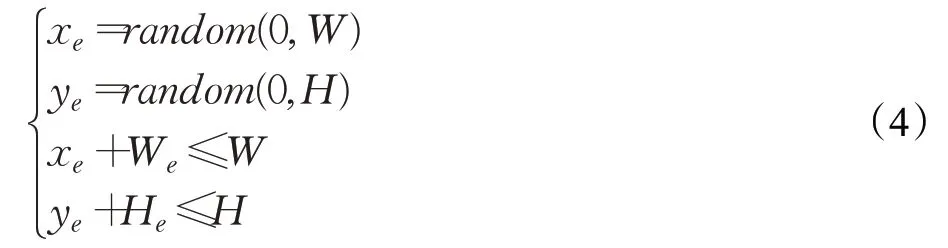
本文算法的应用场景为教室,检测目标为学生,属于多目标、小目标检测范畴,原算法中的全局随机方法不能保证每次的擦除区域能覆盖到目标物体,未能被有效擦除的数据不能起到模拟遮挡的作用,增加了数据集的冗余程度。因此本文在此基础上对随机擦除法进行改进,提出了基于数据标签的随机擦除法,修正P e的横纵坐标x e、y e的限定范围,具体如下:
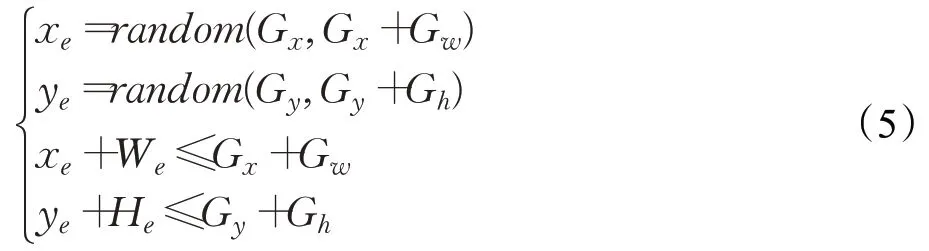
其中G x、G y、G w和Gh分别表示真实标签检测框左上顶点的坐标值和长宽值。
改进的方法缩小了随机点Pe的选取范围,缩短了Pe点横纵坐标的计算时间,每次生成的擦除区域都能覆盖到目标物体,即生成的所有数据均能模拟物体被遮挡的情况,在同等数量的数据集下,改进后的方法使得训练后的网络具有更强的泛化能力。
(4)为擦除区域赋固定值或随机值,并输出处理后图像数据,达到模拟图像中物体被遮挡的效果。
Random erasing算法的参数数值如表2所示,其中图像面积S在改进后的方法中为检测框的面积,在原方法中为输入图像的面积,即416×416;随机矩形区域的面试S e由公式(1)可得;擦除面积的上下阈值由表2中的s l、s h可得;随机擦除矩形的高宽比由表2中的r e可得,本文采用表2的参数模拟对比实验。

表2 Random erasing实验参数值Table 2 Parameter values of random erasing experiment
观察图3可以发现:A组随机擦除法第三行,B组随机擦除法第三行等数据未能有效地将擦除区域覆盖到目标框内,A、B两组改进后的方法所生成的数据均能较合理地模拟目标被遮挡的情况,降低数据的冗余性并提升数据的有效性。

图3 随机擦除算法实验对比图Fig.3 Experimental comparison of random erasure
通过表3可知:数据经过原始的随机擦除算法处理后送入网络,模型的精准度可以得到提升,使用本文的算法进行预处理后的数据能够使模型的精准度进一步提升,证明改进后的随机擦除预处理算法能够提升网络的泛化能力,强化网络对局部特征的学习能力。
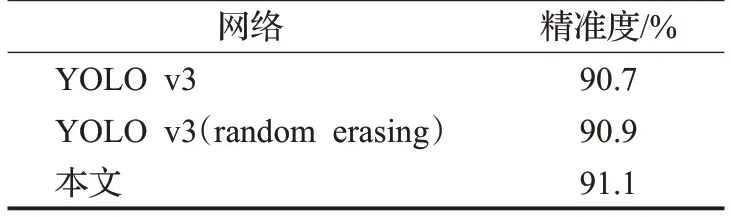
表3 随机擦除算法精准度对比Table 3 Accuracy comparison of random erasing algorithm
3.2 YOLO v3网络改进
深度卷积网络存在的普遍特性是随着网络层数的递增,特征图的大小逐渐减少,而特征图的纬度逐渐递增。由卷积参数量计算公式(6)可知:增加浅层网络数量相较于增加深层网络数量的参数量更少,因为浅层网络特征图的维度往往远小于深层网络特征图的维度。
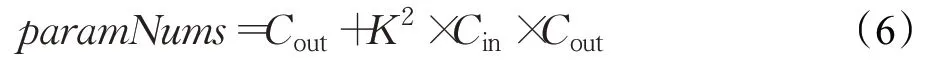
式中,K表示卷积核的大小,Cin和Cout分别是输入通道和输出通道的数量。
由感受野理论大小计算公式(7)可知:感受野的变化趋势是随着网络的深度和卷积核的大小以及步长的大小增大而增大的。
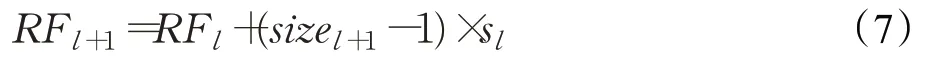
式中,RF l表示特征在第l层的感受野(region filed),sizel表示卷积核在l层的大小,s l表示卷积在第l层的步长(stride)。
然而每层感受野中元素对特征的贡献并不是相同的,如图4所示,输入的图像矩阵INPUT的大小为5×5,卷积核的大小为3×3,步长为1,两次卷积输出的图像矩阵大小为3×3和1×1。对比INPUT[1][1]和INPUT[3][3]对输出特征图的影响可以发现:INPUT[1][1]仅可以通过OUTPUT1[1][1]影响OUTPUT2[1][1],而INPUT[3][3]可以通过OUTPUT1的所有特征点影响OUTPUT2[1][1]。因此可以得出结论:输入中越靠近感受野中心的元素对特征的贡献越大,由于目标检测的目标物体不是均存在于图像的几何中心,所以通过扩充浅层网络,使网络不容易忽略图片边缘或呈像小的物体。
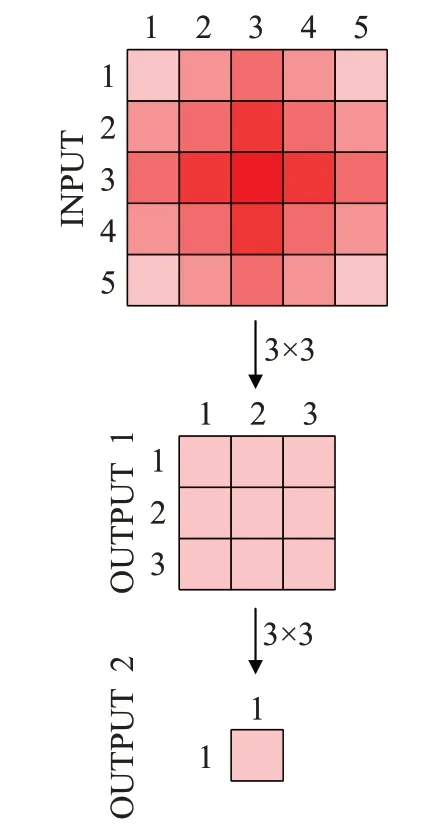
图4 感受野大小与卷积层数的关系图Fig.4 Relationship between size of receptive field and number of convolution layers
文献[14]在道路检测方面提出了基于Darknet30的网络结构,采用1、2、2、2、2、2次的残差块重复结构,参数量减少47%,降低了运算复杂度,提升了检测速度;文献[15]在机器人抓取网络中将Darknet-53改进为Darknet-43,使网络对不同的角度、尺度或新物体的泛化性得到提高;有研究在单目标物体检测方面对Darknet-53进行裁剪,另根据数据集的特性对网络结构进行调整,使得改进后的YOLO v3模型的检测精度和速度都有提升。考虑到实际因素:本文以教室为应用场景,以学员为目标物体,必然存在学员存在于图像中的边缘位置和呈像为小目标的问题;因此本文提出了参数量少、运算复杂度低和对小目标检测性能较好的Darknet-47。
Darknet-47由6个单独的卷积层和5种类型的残差块组成,6个单独的卷积层的作用是降低特征图大小,增加特征图维度,提取更深层次的语义信息;5种类型的残差块数量分别是2、4、4、6、4,具体结构如表4所示,前两种类型的残差块数量由1、2个扩充到2、4个,使网络可以提取到图像边缘目标和小目标的特征。第3、4种残差块的数量由8、8个减少到4、6个,考虑到第4种的残差块输出的特征参与另外两个尺度特征的融合,因此保留了较多的残差块。
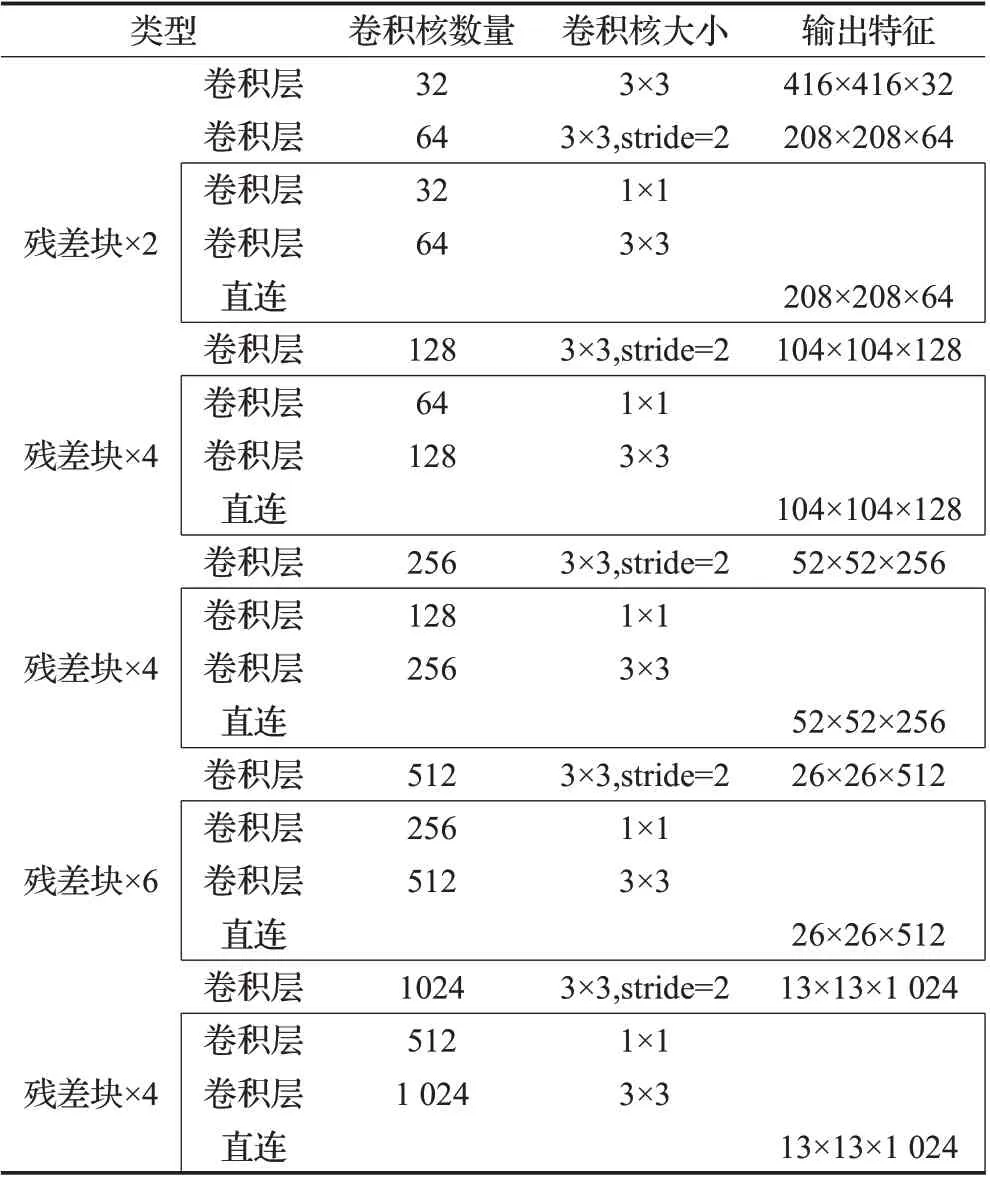
表4 改进的YOLO v3网络结构Table 4 Improved YOLO v3 network structure
改进后YOLO v3采用新的特征提取网络Darknet-47,如图5所示,输入数据为416×416,经过一系列的卷积、上采样、融合操作输出3个维度的特征图。A卷积层采用3×3×32的卷积核对原图进行卷积,步长为1,作用是增加特征图通道数、提取浅层的语义信息,其他卷积层均采用大小为3×3,步长为2,通道数为输入特征图的通道数的2倍,作用是降低特征图大小、增加特征图通道数、提取抽象的语义信息;残差层将输出特征图与输入特征图进行连接操作,在一定程度上可以解决网络退化问题;上采样层的作用是提升特征图大小,提供多尺度特征图融合的条件;融合层将多个特征在通道方向上相加,作用是使特征图包含深、浅多层语义信息。检测层输出三类特征图,其大小分别为52×52×21、26×26×21、13×13×21,其中通道数均为21,计算过程如公式(8)所示,本文实验设置2种检测类别(class),分别是玩手机和睡觉,网络预测检测框的横纵坐标值、长宽和置信度共5个参数,每个尺度的检测层均输出3个预测框。深层网络的感受野大,语义信息表征能力强,特征图的分辨率低,几何信息的表征能力弱,浅层网络的感受野比较小,几何细节信息表征能力强,虽然分辨率高,语义信息表征能力弱,多尺度融合,能够丰富预测检测框的多尺度特征图,提高精度。
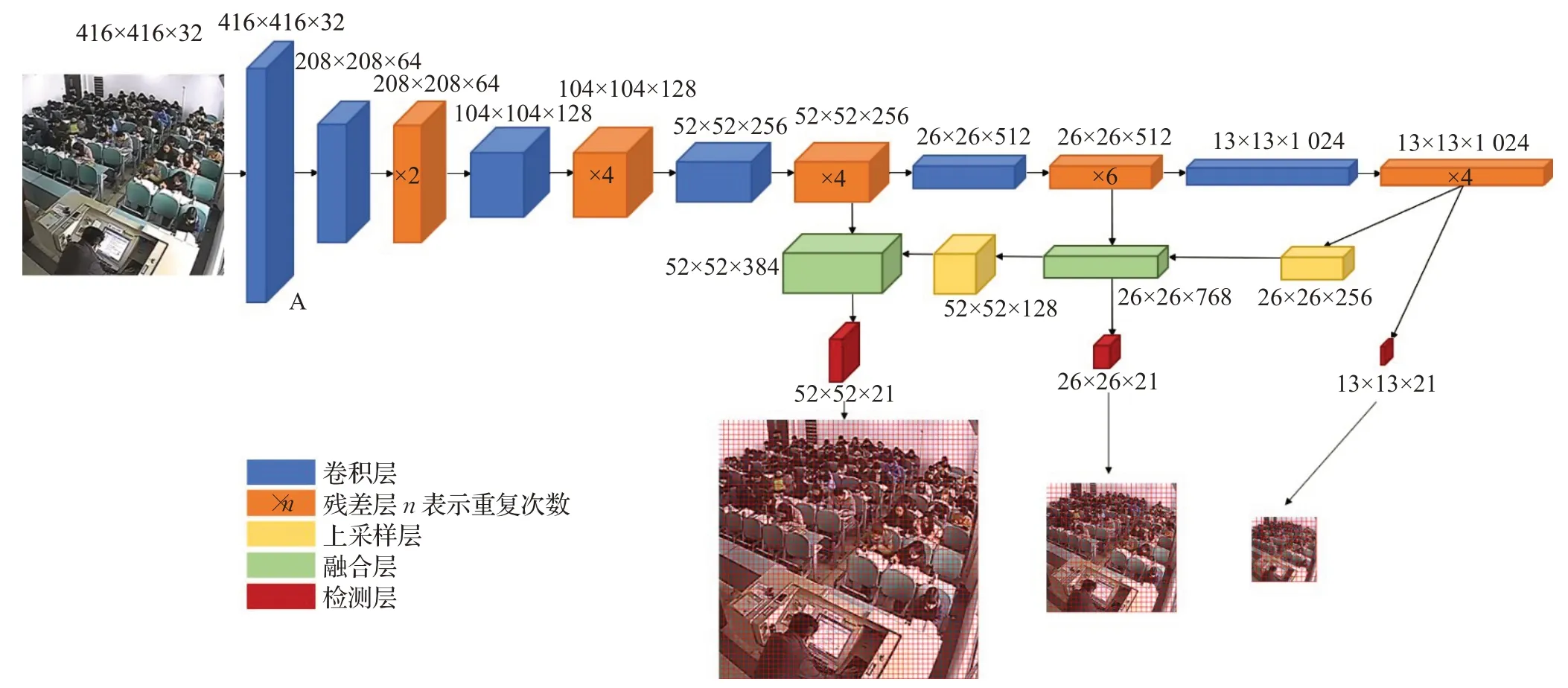
图5 改进的YOLO v3网络结构图Fig.5 Network structure of improved YOLO v3
检测层通道数计算公式:

改进后的网络深度、参数量、计算量相较于Darknet-53有大幅下降:网络层数减少6层,参数量减少了约3.3×106个,FLOPS减少了约7.23,二者性能对比如表5所示,mAP、RIoU、FPS分别上升了0.5、5个百分点和3 frame/s。

表5 改进的YOLO v3网络与原网络性能对比Table 5 Performance comparison between improved YOLO v3 network and original network
3.3 引入GIoU
图6中有预测框X、真实框Y和交集框Z,根据这种方法引入IoU(intersection over union)定义作为目标检测中的常用指标,可以直观反映出预测框与真实框的相似度,如公式所示:
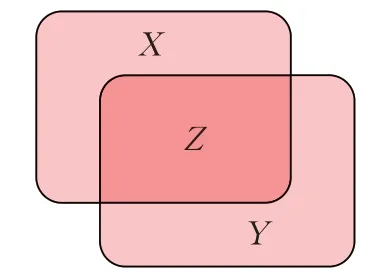
图6 预测、真实和交集框的关系图Fig.6 Diagram of forecast,reality and intersection box

传统的IoU指标方法在一些特殊情况下衡量预测框与真实框的相似度时会存在一些问题,无法正确判断出预测框与真实框的相似值。
GIoU[13]的设计初衷就是解决传统IoU方法所存在的问题。如图7所示对于任意的两个X、Y框,首先找到一个能够包住它们的最小方框C,然后计算C/(A⋃B)的面积与C的面积的比值,再用X、Y的IoU值减去这个比值得到GIoU。GIoU与IoU均是度量函数,相比之下,GIoU对尺度变化并不敏感,可以规避尺度差异所造成的定位不准确问题。GIoU的度量标准不仅仅是重叠交集部分,它通过引入非重叠部分计算大大提高其度量结果的准确度。
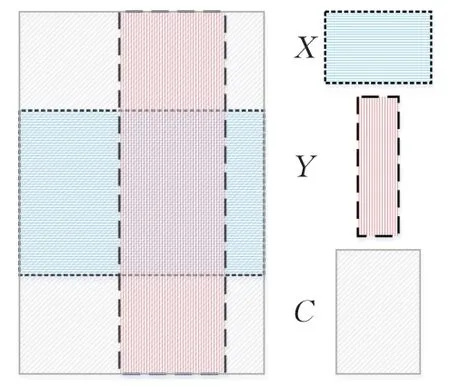
图7 GIoU关系图Fig.7 GIoU relationship diagram
GIoU的计算公式如下:
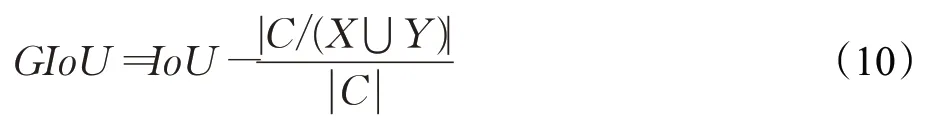
其中,X为预测框的面积,Y为真实框的面积,Z则为包含了预测框X与真实框Y的最小矩形的面积。IoU的计算方式发生了变化且IoU是YOLO v3损失函数的一部分,网络新的损失函数结构如下:
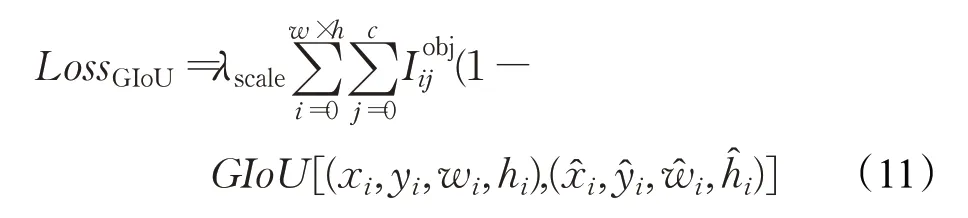
式中,λscale为预测目标大小的权重,系数权重的值与检测目标的大小呈反比。w×h为预测特征图的尺寸值,c为单位尺寸内的锚点数,表示特征图中此处存在检测目标。GIoU的详细计算方法如公式(10)所示,所计算的是预测值边框信息(x i,y i,w i,h i)与实际边框信息之间的广义交并比,与传统YOLO算法采用的均方误差(MSE)方法相比,GIoU更能反映预测检测框的检测效果的准确度。
LossCls的计算公式为:
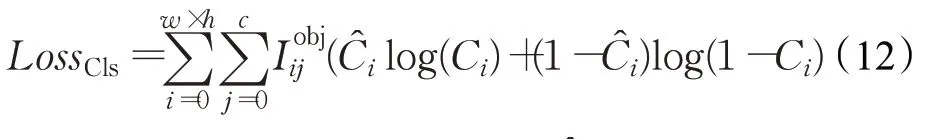
式中,Ci代表目标类别预测值,代表目标类别标签值。
置信损失不只包括有目标时的置信损失,也包括无检测目标的置信损失,因为这是确定目标位置的首要信息。LossConf的计算公式为:
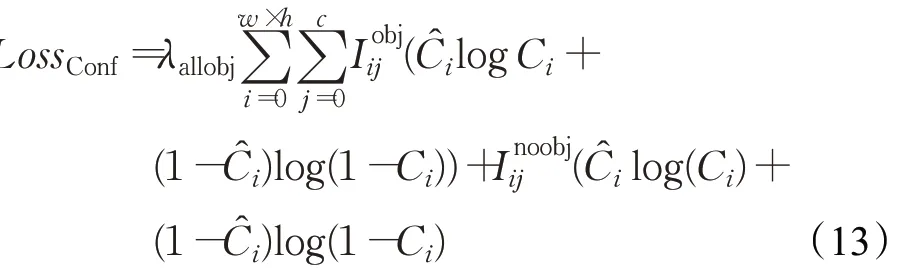
式中,λallobj为所有预测格点的系数,在此之后的因子代表的是交叉熵损失。λallobj的公式如下:

λallobj是反映预测整体结构与标签之间差异的指标,本文中∂=1,γ=2,即用L2距离。
文献[16]将GIoU引入YOLO v3网络,在PASCAL VOC 2007测试集上达到83.7%的mAP值,在COCO测试集上比YOLO v3算法在mAP上提升2.27个百分点;文献[17]基于GIoU计算方法,与YOLO v3算法目标函数结合,在安全帽佩戴数据集测试结果表明,相比于YOLO v3算法,改进YOLO v3的mAP-50分别提高了2.05个百分点。由上述实验结论和GIoU的衡量指标可知在YOLO v3网络框架中引入GIoU算法能够优化网络的损失函数,提高目标检测的精准度。
4 信息响应
本文对将教室监控下的记录学生行为的录像作为改进后的YOLO v3网络的输入端,输出端连接响应软件,实时统计监控中出现异常行为的学生数量和异常行为的类别,并将统计后的信息封装成API供其他软件调用。
通过改进后的YOLO v3网络能够实时、可视化地显示监控中产生异常行为的对象,但不具有统计异常行为人数和异常行为类别的功能。
本文通过增加YOLO v3网络的代码,使检测模型每完成一次迭代不仅都能够输出异常行为类型而且输出异常行为人数等信息,响应软件处理此类信息并展现给软件使用者。
本文基于C++、Qt框架编写软件,使用MVC与单例设计模式能够较好地服务于软件使用者,MVC设计模式将数据模块(model)和视图模块(view)分离开,使用控制模块(controller)在二者之间传递信息,单例模式保证程序在运行过程中只能创建单个进程,防止多个检测网络同时对一个源数据进行检测,并且加入了互斥锁,检测过程中输入数据禁止被修改,提高了程序的健壮性。
软件界面如图8所示,左侧是一个矩形显示模块,用于响应采集、处理并显示视频帧。右侧为三个功能模块,由上至下依此为导入模块、预警模块和导出模块,导入模块的功能是用户选择数据采集模式并将视频数据按每帧输送到检测网络,并将检测结果显示到左侧控件上,预警设置模块的功能是设置触发预警的异常人数,人数超过一定阈值则会触发警报,通知连接API的其他端设备;导出功能模块到本地的功能是用户选择将输出结果以视频的形式或文本形式导出到当前环境中,底部的控件为以文本形式呈现当前视频帧的检测结果。
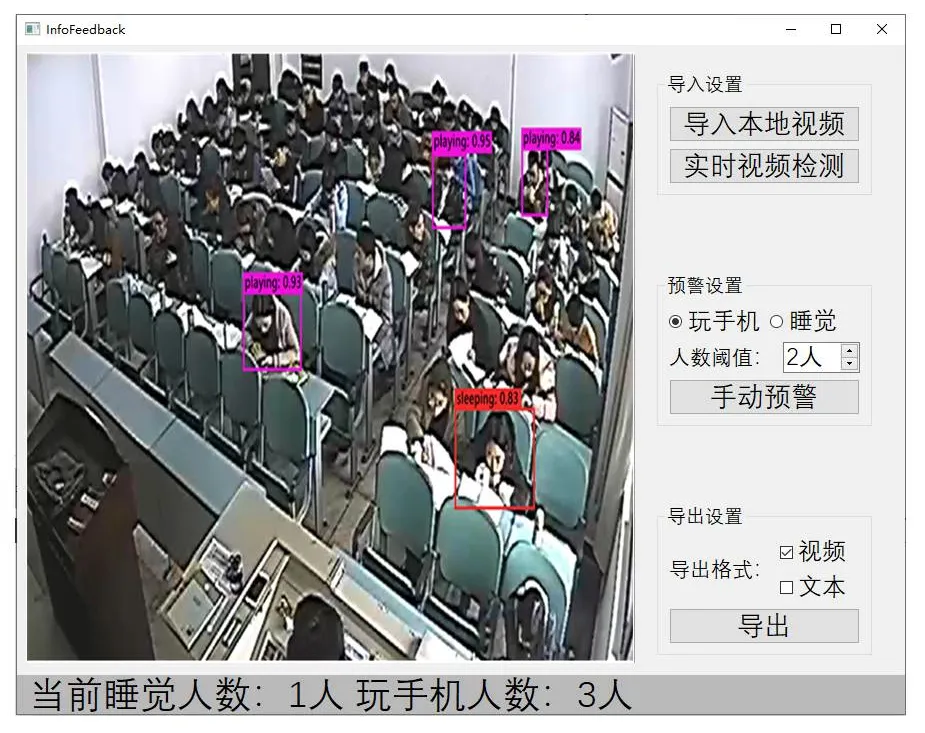
图8 信息响应软件界面Fig.8 Information response software interface
可视化的UI界面相较于Python IDE控制台的字符显示更直观。按钮封装实现功能的复杂代码,降低了搭建环境的成本,提高了软件的易用性,使得对计算机知识薄弱的用户能够操作软件从而实现检测的功能。
5 实验结果与分析
下面介绍本文实验的相关软硬件环境及训练细节。
(1)硬件环境:处理器为Intel®Core™i7-8750H CPU@2.20 GHz,8 GB DDR4内存,显卡为NVIIA GeForce GTX1050Ti 4 GB独立显卡。
(2)软件环境:ubuntu18.04操作系统,python3.8.5,A9.2,toch1.6.0,opencv-python4.4.0等相关工具包。
5.1 数据集
本次实验的数据集取材于重庆理工大学第三教学楼6个教室的监控视频,每个教室大约30到50个学生。使用光流法对视频进行关键帧提取,采用LabelImg软件对关键帧进行标注,设置异常行为的标签为:睡觉(sleeping)和玩手机(playing),通过改进的random erasing数据增强方法对样本进行扩充,最终选取3 270张图像作为实验数据,其中2 289张图像用于训练数据集,其余981张用于测试数据集。
5.2 训练细节
网络模型训练时,样本总共迭代了50 000次,其中动量设置为0.92,批量大小设置为8,初始学习率设置为0.001,权重衰减系数为0.000 15。
5.3 改进前后的算法性能对比
本文采用平均检测精度(mAP)、召回率(recall)、交并比(IoU)和平均检测速度(FPS)作为检测模型的评价指标。表6显示了本文方法与传统的YOLO v3在重庆理工大学监控视频数据集上的检测效果。其中YOLO v3(random erasing)采用了改进后的random erasing方法对数据集进行数据增强,YOLO v3(random erasing and GIoU)在前者基础上引入GIoU并重新定义损失函数,本文(Darknet-47)在前者基础上更改骨干网络为Darknet-47。
衡量指标mAP、召回率、交并比和平均检测速度的计算公式如下:
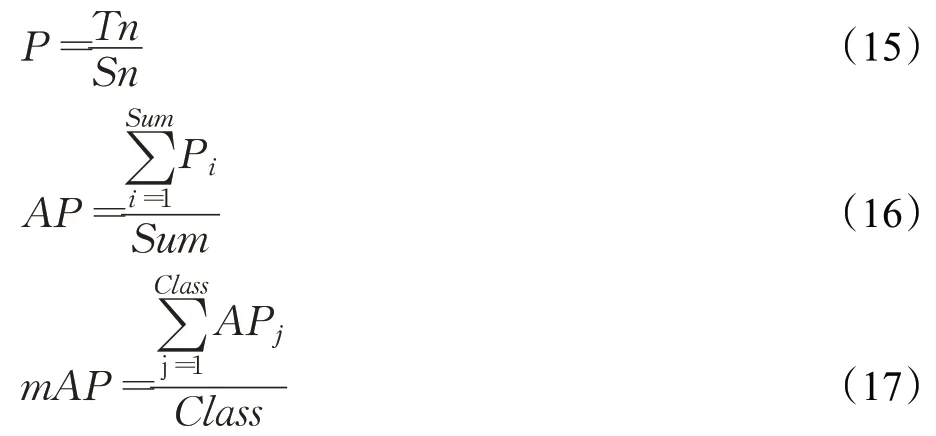
其中,Tn表示预测正确的图片数量,Sn表示标签为当前类别的图片总数,Sum表示测试集中图片总数,Class表示检测类别数。

式中,TP表示真阳性样本数量,FN表示假阴性样本数量,recall表示样本中有多少正例被预测正确了。

式中,X表示预测框,Y表示真实框,X⋂Y表示二者交集面积,X⋃Y表示二者并集面积,IoU表示二者交集与并集的比值。

式中,fNum表示模型处理视频总帧数,T表示处理视频所用时间,FPS表示模型单位时间内可以处理的视频帧的数量。
训练过程loss曲线如图9所示,训练在迭代到45 000次后loss值趋于稳定,最终下降到0.52左右。
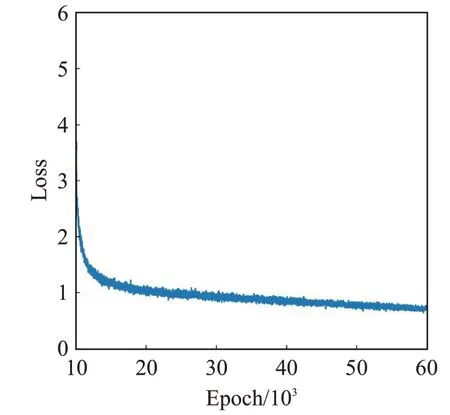
图9 训练过程loss曲线Fig.9 Loss curve during training
由表6可知,与骨干网络为Darknet-53的YOLO v3算法相比,改进后网络的精准度、交并比、召回率以及运算速度均有提升,分别提升了4.2、5.3、4.8个百分点和8 frame/s,证明骨干网络为Darknet-47的YOLO v3更具有可靠性。
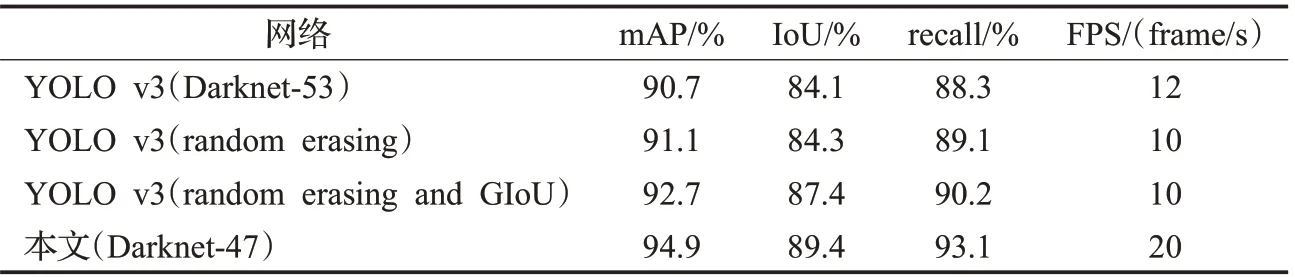
表6 改进前后的算法性能对比Table 6 Performance comparison of improved algorithm
如图10所示,由上至下分别是原图、YOLO v3输出结果、改进后的YOLO v3输出结果。对比输出图像可知:YOLO v3输出结果相较于改进后的YOLO v3输出结果出现多次漏检,图(a)组出现2次漏检,对应教室5、6两排,图(b)组出现2次漏检,对应教室1、4两排,4个漏检目标距离均摄像头较远,在图像上呈现形式为小目标,部分目标对象前方有书桌遮挡。因此,可以证明改进后的random erasing算法能够模拟检测目标被遮挡的情况,提高网络的泛化能力,使得网络仅通过学习局部特征即可完成目标的检测和识别。Darknet-47可以更好地提取图像边缘目标和小目标的特征,降低检测网络输出结果出现漏检的概率。

图10 改进前后的算法效果对比Fig.10 Comparison of algorithm effect before and after improvement
5.4 改进前后的算法性能对比
本文将FastR-CNN、FasterR-CNN、SSD300、SSD512、YOLO、YOLO v2、YOLO v3和改进后的YOLO v3在同样的数据集下进行训练与测试,并选取平均检测精度(mAP)和平均检测速度(FPS)作为评测指标。表7展示了FastR-CNN、FasterR-CNN、SSD300、SSD512、YOLO、YOLO v2、YOLO v3与改进后的YOLO v3算法对比的实验结果。
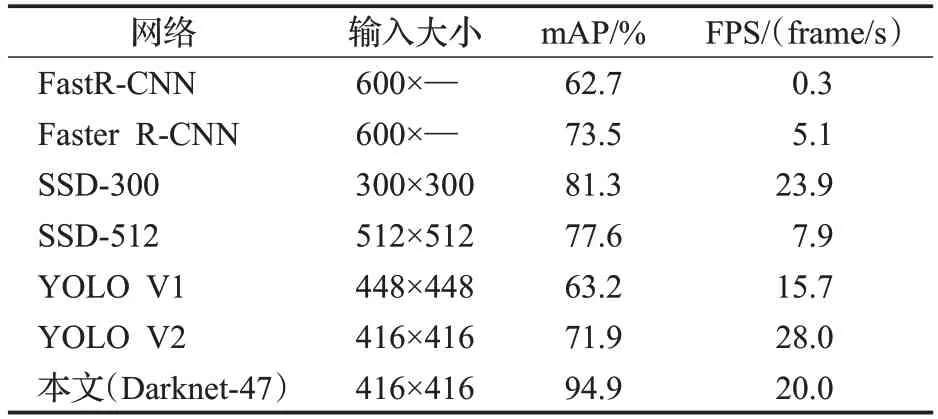
表7 改进后的算法与其他算法性能对比Table 7 Performance comparison between improved algorithm and other algorithms
由表7可知,其他算法模型在目标检测上的准确率均在60%至80%区间,YOLO v2在缩减模型、降低精准率的情况下,运算速度达到每秒28帧。改进后的YOLO v3算法模型在预处理阶段对数据进行随机擦拭算法(random erasing),模拟图像数据被遮挡的情况,提高了检测网络对局部特征的学习能力和模型的泛化能力,降低了目标由于被遮挡而产生的漏检概率;在准确率方面由于网络加入GIoU损失函数,模型在检测时,预测框能更准确地拟合真实标签框,平均精准率达到94.9%;在实时性方面,由于本文算法采用的骨干网络为Darknet-47,在参数量和FLOPS均有大幅降低,使得算法模型在速度上有大幅提升,在GPU为1050Ti的平台上能够达到每秒20帧,鉴于监控摄像机每秒采集帧数为20~25帧,基本满足对于教室的复杂场景实时检测的需求。
6 结束语
课堂中异常学生过多往往无法使教师集中注意力授课,针对此类问题,本文对YOLO v3深度卷积网络进行改进。首先增加改进的随机擦除算法(random erasing)模拟课堂学生被遮挡的情况,降低了检测的漏检率;然后修改YOLO v3骨干网络Darknet-53,扩充浅层网络层数,减少深层网络层数,提高网络对图像边缘学生、小目标学生的检测的平均精度,减少了参数量和计算量,使得网络的检测速度有大幅度提升;最后将改进后的YOLO v3算法应用于教室监控下异常学生的检测并与原始YOLO v3算法进行定性对比实验,同时运用改进后的YOLO v3算法先后与FastR-CNN、FasterRCNN、SSD300、SSD512、YOLO、YOLO v2、YOLO v3等流行的目标检测算法进行定量的对比实验。实验结果表明,本文改进后的YOLO v3算法能够有效降低图像数据的边缘目标、小目标的漏检率,在精准率和速度上均有大幅提升,本文实验所得平均精准度为91.7%,检测速率达到每秒20.2帧。
本文改进的算法虽然在检测速度与精度上已经有了很大提升,但仍然可以在K-means算法、数据集等方面继续探索,以进一步提升算法的实时性与实用性。
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
作文小学中年级(2020年6期)2020-07-24
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
当代陕西(2019年10期)2019-06-03
北京航空航天大学学报(2018年1期)2018-04-20
