
上下文感知的树递归神经网络下隐式情感分析
2022-04-08 03:42陈秋嫦左恩光赵玉霞魏文钰
计算机工程与应用 2022年7期
陈秋嫦,赵 晖,左恩光,赵玉霞,2,魏文钰
1.新疆大学 信息科学与工程学院,乌鲁木齐 830046
2.商洛学院 数学与计算机应用学院,陕西 商洛 726000
情感分析一直是自然语言处理领域中的研究热点之一。由于情感分析可以通过构建模型进行计算,所以人们希望可以利用信息技术的方式来更好地理解他人的意见。情感分析从语言层面上分为显式情感分析和隐式情感分析,其中显式情感分析为隐式情感分析奠定了研究基础,而隐式情感表达充斥在日常生活的方方面面。特别地,微博等社交平台为隐式情感分析研究提供了一个新的机遇与挑战。
文献[1]提出,情感分析在本质上是人们对各个事物的主观评价和感受,使得人们倾向于使用具有客观性或事实性的句子来表达他们的情感倾向。文献[2]首先根据主客观将情感分为显式情感和隐式情感。文献[1]、[3-6]表示显式情感分析在浅层或者深层的网络模型中已经取得了很多成果。在文献[7]中隐式情感被定义为“一个语言片段(句子、从句或短语)以表达主观情感,但不包含显式情感词”。文献[8]对隐式情感分为4种类型:事实型、隐喻型、反问句式以及讽刺句式。文献[1]将客观事实型的隐式情感定义为蕴含了事实的情感并且通过阐述相关事实来呈现出相对客观的情感倾向。文献[7]对于事实型隐式情感的表达特点上进行了归纳:情感背景一致性、情感目标相关性、语义背景相关性以及表达结构相似性。文献[9]将隐喻归纳为不仅可以表示基于相似性的单个词的意义扩展,更多的涉及到从另一个角度对整个经验领域的再认识,也是目标和来源之间的关系。文献[10]认为反讽类型的隐式情感是一个有意识地使用词语或表达方式来表达与字面意义不同(通常相反)的修辞过程。文献[11]提出反问句式的隐式情感句子有3个基本特点:无疑而问、不需要回答、表示否定。这些修辞方式的运用虽然增加了语言表达的效果,但同时也为隐式情感的分析带来了挑战:由于隐式情感句中不包含显式情感词且表达词相对客观中立,意味着传统的显式情感分析模型(基于情感词典)不再有效;在语义表示和结构上也与显式情感具有某些差别;隐式情感更倾向于情感表达者的个人主观意识。
本文旨在提高隐式情感文本中上下文对目标句的作用,从而达到提高目标句隐式情感识别的准确率。通过分析事实型隐式情感的句子的特点,发现目标句情感倾向既受上下文背景情感倾向所影响,同时也受其目标语句自身句子结构所影响。由于中文隐式情感的语料中并不存在标注好的情感倾向词可以进行计算,而隐式情感句子的上下文中却存在影响情感倾向的信息,对目标句的情感分类结果造成相关性的影响。在语料库中发现存在一些目标句与上下文相关性较强的样例。
如表1所示,目标情感语句中具有相同的关键词“地铁站”,但是由于上下文语句对目标语句(即本文中需要进行情感判断的语句)的补充信息不同使得其情感倾向也不一样,实例证明上下文语义背景也是隐式情感的重要影响因素之一。文献[9]研究表明,如果一个句子有主语-动词或动词-直接宾语结构,它更有可能是一种隐喻表达,这一结论表明句法结构是句子表征的一个重要特征。在本文中需要考虑一个句子是否能够通过对一个事件或对一个产品的完整陈述来表达事实隐含的情感,这种陈述通常有一个完整的主语-动词-宾语结构。文献[12]提出的recurrent tree communication model(RTCM)虽然解决了短语级树型情感一致性的问题,但并没有对拥有篇章级上下文的目标句的情感进行准确地分类出结果。因此,本文提出一种新的具有上下文感知注意力机制的树形递归神经网络(CA-TRNN)的结构。对于解决篇章级上下文信息丢失的问题,具体而言,模型分别对目标句以及其上下文生成不同的表示,而上下文的表示也必须与目标句子的进行注意力机制的训练,从而使得它们更有价值。针对上述文献的不足,本文主要工作如下:

表1 隐式情感句子样例Table 1 Samples of implicit sentiment sentences
(1)针对隐式情感依赖其句子表达的语义结构信息,本文利用vanilla tree LSTM对目标情感语句表示初始化,每个节点使用递归神经网络重复地与它的邻居交换信息。这种多通道信息交换可以使每个节点通过丰富的通信模式获得更多的句子级目标句的语义信息。此外,时间步数不随树的高度而缩放。通过多跳步的树形递归神经网络对目标句进行单独的语义编码。
(2)设计了一个注意机制编码网络来绘制目标句和上下文之间的隐藏特征和语义特征之间的交互信息。目的是将得到的目标语句表示引入一个对上下文感知的注意力,使得上下文表示围绕着目标句表示展开训练。
(3)将得到的上下文和目标语句语义信息进行并行融合,最终得到目标句的语义表征能更加充分考虑上下文和目标语句之间的联系,克服中文隐式情感分类难的情况。
1 相关工作
1.1 树形神经网络
文献[13]和文献[14]最早将卷积神经网络模型应用于文本表示中,虽然这是一种比较有效的句子表示方法,但该模型无法对具有结构信息的句子(如短语结构,依存结构等)进行建模,因而在此基础上,文献[15]提出了树形卷积神经网络(tree-based convolutional neural network,TBCNN),该模型将句子以依存树(dependency tree)或者短语结构树(constituency tree)进行表示。文献[16]于2015年提出了Tree-LSTM模型,将序列的LSTM模型扩展到树结构上,即可以通过LSTM的遗忘门机制,跳过(遗忘)整棵对结果影响不大的子树,而不仅仅是一些可能没有语言学意义的子序列。由于有了树结构的帮助,传统的Tree-LSTM就更容易对长距离节点之间的语义搭配关系进行学习,但是,它们不能将信息从组成节点传递给其子节点。因此,文献[17]为双向树LSTMs提供了一种解决方案,即使用单独的自上而下LSTM的方式来增强树LSTM。不仅如此,在图神经网络的最新进展上,如文献[18]和[19]提出的图卷积神经网络(graph convolutional neural network,GCN)及在图递归神经网络(graph recursive neural network,GRN)模型,文献[20-22]提供了在图模型基础上建立丰富的节点通信模式的模型研究,这种多通道信息交换可以使每个节点通过丰富的通信模式获得更多的篇章级上下文信息。文献[23]为了在二叉树上提取到双向信息,提出了从树根节点向下传播到叶节点上的全局性的双向树LSTM的概念。文献[24]提出了双向依存树的LSTM模型,融合了序列化信息和依赖树的结构信息。与以上工作相比,本文的工作是将该模型迁移至中文隐式情感文本分类问题上,在树形递归神经网络的基础上加入了围绕目标句的注意力机制,在中文隐式情感分析中表现了良好的性能,使得树形递归神经网络拥有上下文感知的能力。
1.2 上下文感知模型
在传统方法上,文献[25]以及文献[26]都提出过传统的机器学习的方法,主要集中在提取一组词汇等特征的单词来对上下文进行训练。文献[27]发现可以使用一个主题相关的评论集来扩展了一些伪上下文,但由于评论集是有限的,扩展的上下文仍然是有限的且不可靠的。为了克服这一问题,提出了一个无监督的三元框架来扩展网络中更多的伪上下文,来进行搭配从而提高识别。同样的,文献[28-29]在研究中也发现收集与文本相关的上下文信息有必要的,并且也验证了使用传统分类器在收集上下文信息时候是失败的。文献[30]通过分析在Twitter上包含来自目标句其额外上下文信息,能够在检测这种复杂现象时获得比纯目标句特征更高的准确性。近年来,神经网络方法由于不需要人工构造特征就能够对语义信息丰富的低维词向量进行编码而受到越来越多的关注。文献[31]融合的是不同的语境背景下提取出来的上下文信息,作为一个预训练模型取得了不错的性能。与此同时,文献[7]针对隐式情感文本阐明了上下文情感对目标句情感具有密切的关联关系。文献[32]提出TD-LSTM扩展LSTM,分别使用两个单向LSTM对目标词的左上下文和右上下文进行建模。文献[33]提出了一个针对目标情绪分类任务的注意编码网络,它使用基于注意的编码器在上下文和目标之间进行建模。与以上工作相比,为了将文献[32]和[33]的工作更好地体现在中文隐式情感分析的文本上,利用注意力编码网络提取出具有特定目标相关性的上下文信息表示,本文利用其模型[32-33]的基础上,提出了t-TRNN(context-TDLSTM based TRNN)、a-TRNN(context-AEN based TRNN)将其作为对比实验与本文所提模型作为对比。由于序列化模型容易导致梯度爆炸或消失,文献[34]提出了LSTM来解决这一问题,并且在此基础上本文使用了变形的LSTM(BiLSTM)来作为上下文感知的基础模型。
2 本文模型
本文使用的上下文感知神经网络包括树形递归神经网络(CA-TRNN),基于注意力的编码网络(BiLSTM+attention)以及特征融合的表示学习机制,模型结构如图1所示。模型结构对目标句通过树形递归神经进行目标句表示的提取,并且对篇章级的上下文通过双向长短时记忆网络生成出对应目标句的上下文表示,将提取到的目标句表示对上下文表示进行注意力机制学习,最后进行并行的两级表示融合。
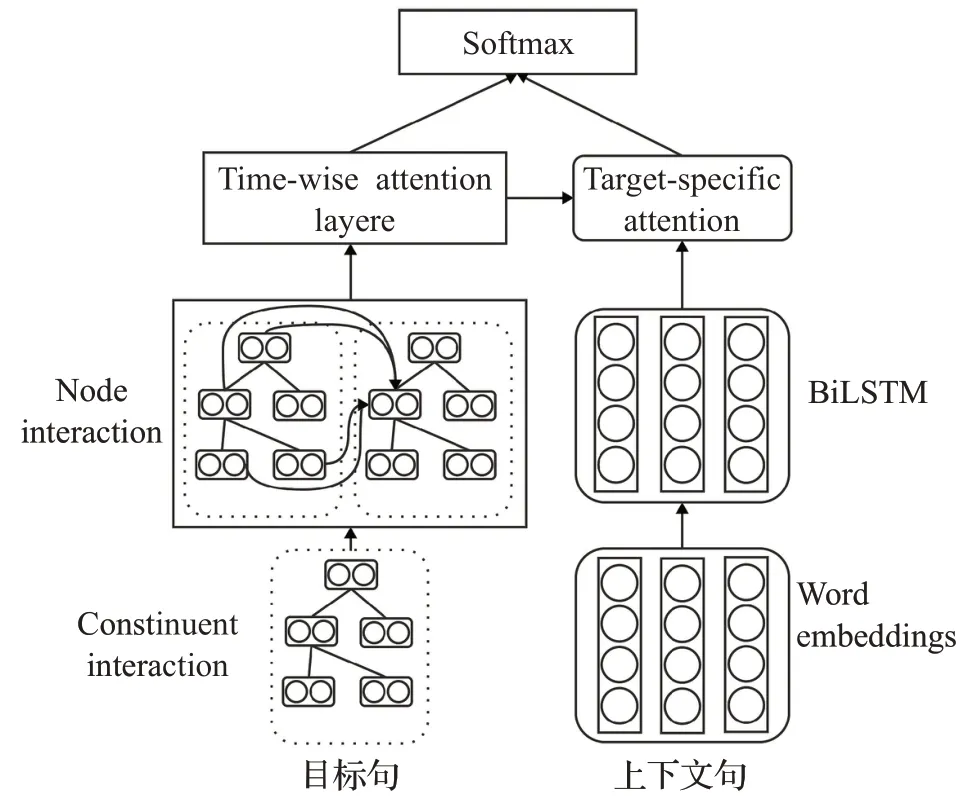
图1 上下文感知的树形递归神经网络模型结构Fig.1 Model structure of CA-TRNN
2.1 输入层
基于本文模型需要将不同的文本分别输入到树形递归神经网络和BiLSTM中,且两个子模型的结构不一致,模型对输入层需要不同的预处理。基于树结构的神经网络模型需要对句子进行短语结构分析,得到短语结构树,如图2所示。本文使用Stanford parser工具包建造短语结构树。节点中的数字代表该目标句的所对应的隐式情感倾向类型,图2中的“我租的房子走到地铁站也就5分钟”是需要进行短语结构树分析的目标句,且该句子的分类标签为贬义,即隐式情感倾向为2的句子。对于上下文部分:定义上下文句子个数为m且每个句子中分词长度为n,则上下文表示为s c={w11,w21,…,其中表示句子第j个上下文中第i个词语。所有上下文表示构成一个词向量表示矩阵matrix c∈ℝdw×||V,其中dw表示词向量矩阵, ||V表示词向量矩阵内词语的个数,词向量矩阵通过通用语料预训练得到。
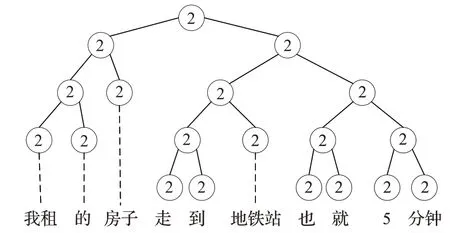
图2 短语结构树实例Fig.2 Sample of constituent tree
2.2 树形递归神经网络
以文献[22]的策略为例,TRNN的结构如图3所示。特别地,对于节点j,上一步的隐藏状态可分为self-toself channel的最新隐藏层状态、自下而上通道的最新的隐藏层状态和自上而下通道的最后隐藏状态,其中代表节点j在t-1的时间时刻的父亲节点parent的隐藏层状态,计算如(1)~(3)所示:

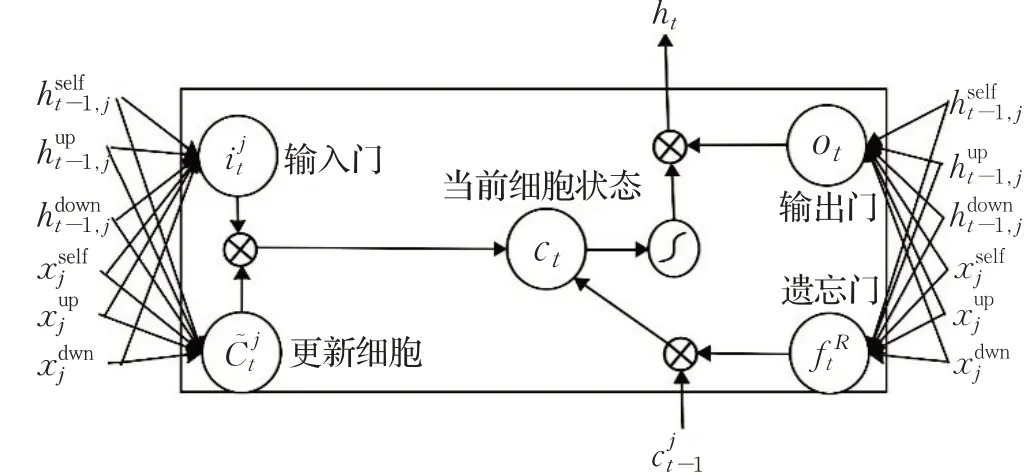
图3 树型递归神经网络模型原理图Fig.3 Schematic diagram of CA-TRNN model
根据3个信息通道的输入和最后隐藏层的状态来计算门和状态值。输入门i t,j和遗忘门f t,j的定义如下,计算公式如(4)和(5)所示:
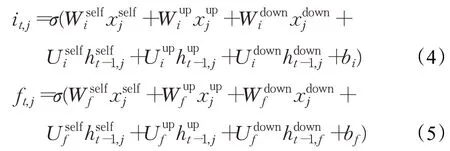
更新的细胞状态被定义,计算公式如(6)所示:
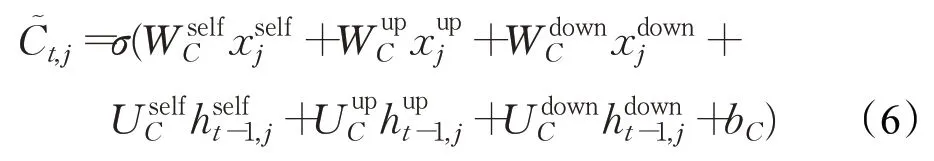
当前的细胞状态ct,j计算方法为(7):
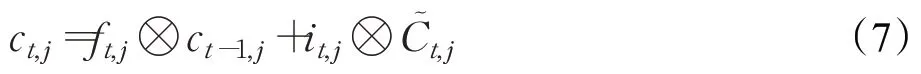
输出门o t,j被定义为公式(8):
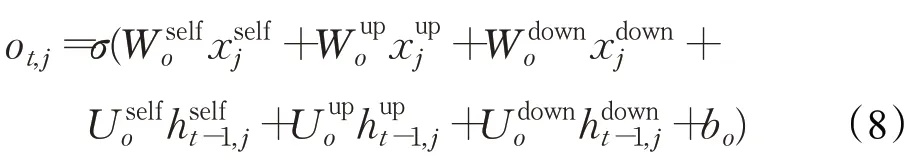
最后的隐藏层h t,j是通过计算当前细胞状态ct,j和输出门ot,j,计算方法如公式(9)所示:

2.3 基于时间序列的注意力机制
由于TRNN中是按时间序列学习语义上抽象级别的特征表示,对于与当前节点相关的叶子节点或者比当前节点更高的父节点以及其祖父节点,可能需要更多的重复步骤来学习节点之间的交互。因此,文献[12]的模型采用了一种自适应递归机制,通过注意力结构来学习动态节点,计算公式如(10)所示:
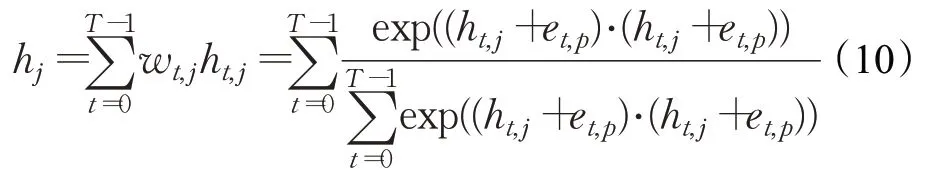
其中,et,p是第t时刻的位置编码,根据文献[35]定义,计算公式如(11)和(12):
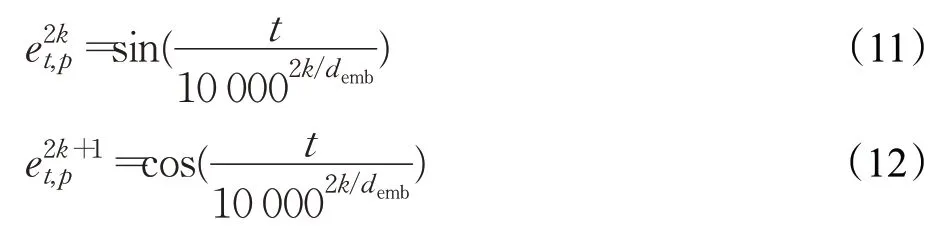
其中,代表的是第q个维的位置编码表示,而dembdemb则是表示的维度值。
2.4 上下文感知模型
在本文中,将除了目标句的上下文句子送入Bi-LSTM中,Bi-LSTM对上下文句子进进行双向编码。利用LSTM对于长句子的编码上的特点,即可以产生长期依赖信息,解决对于长句子的信息缺失问题。
LSTM单元包含3个额外的控件:输入门、遗忘门和输出门。这些门自适应地记住输入向量,遗忘以前的历史并生成输出向量。LSTM单元计算如公式(13)~(18)所示:
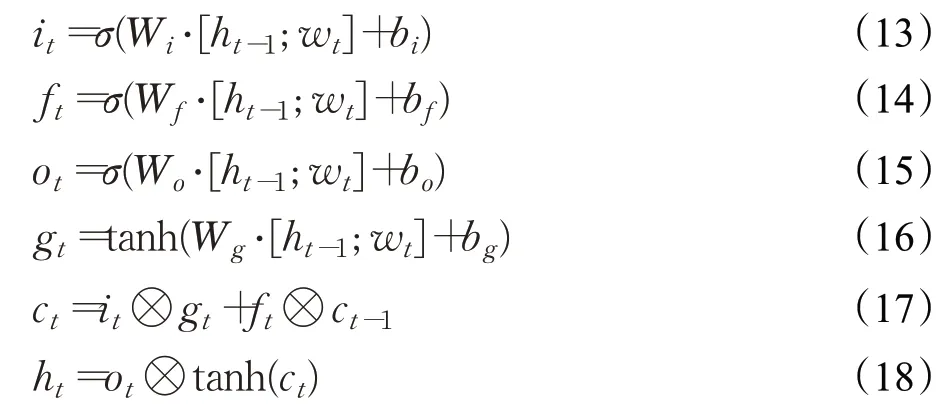
其中,⊗代表的是元素相乘,σ代表的是sigmoid函数,而Wi,W f,Wo,b i,b f,b o则是输入门、遗忘门以及输出门的参数。
2.5 目标特定的注意力机制
得到上下文表示以及目标语句的表示之后,为了让上下文表示更够更好的与目标语句的表示关联,本文采用注意力机制的方式,将目标句表示ht对上下文表示h c做一个注意力计算,得到一个与目标句相关的上下文表示h tsc,计算公式如下(19)所示:

2.6 输出层
模型分别通过不同的网络模型对上下文学习最终得到两个不同的表示,并将它们连接成最终的综合表示͂,然后使用全连接层将连接向量投影到C个目标的空间中。计算公式如下(20)~(22)所示:
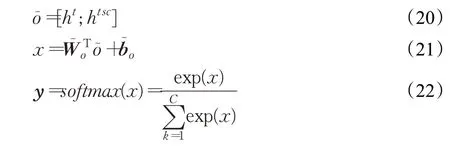
其中,y∈RC是预测的隐式情感极性分布,͂∈RC以及∈RC都是模型可学习而得的参数。
3 实验结果分析
3.1 数据集
实验所用数据集是全国社会媒体处理大会(SMP2019)公开,由山西大学提供的数据集主要是来源于产品论坛、微博、旅游网站等平台的数据。本文主要的工作是对中文的隐式情感句进行评测,数据集中包含显式情感词的文本已经通过大规模情感词典进行过滤处理。处理后的数据集中将隐式情感句进行了部分标注,分为褒义隐式情感句、贬义隐式情感句和中性情感句三类。数据以切分句子的文档形式发布,其中包含有句子的完整上下文信息,数据集的详细数据如表2所示。
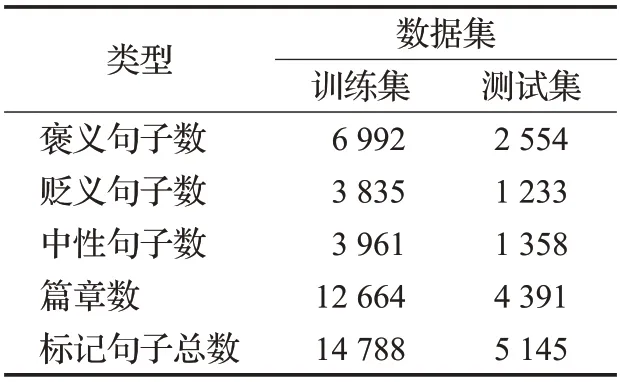
表2 数据集详细数据Table 2 Dataset details data
3.2 对比模型
为了更好地理解模型带来的准确性提升,以及对本文提出模型的方案有更好的理解,采用2组实验、6种模型作为对比,其中包括上下文不同长度表示的对比以及树形递归网络模型对于隐式情感的提升的对比实验。
3.2.1 LSTM
该模型是将完整的上下文以及目标句组成篇章级的文本输入至LSTM中进行建模,是一个传统的神经网络文本分类器。
3.2.2 TRNN
该模型是一种基于树结构的递归神经网络,通过将不同长度的上下文输入至模型的结果作为比较,分类结果可用来判断该模型对上下文信息提取到的特征是否准确,并以此来验证上下文信息是否有助于提高树形递归神经网络。
3.2.3 TD-LSTM
文献[36]的模型为了考虑目标信息,对一般的LSTM模型做了一些修改,在参照实验中引入了目标相关LSTM(TD-LSTM)。其基本思想是对目标字符串前后的上下文进行建模来扩展LSTM,使两个方向的上下文都可以作为情感分类的特征表示。文献[36]认为,捕获这些目标相关的上下文信息可以提高目标相关情感分类的准确性。模型通过使用两个LSTM网络分别对左上下文和右上下文中的关键词进行建模,扩展了LSTM。为了预测关键词的情感倾向,将左、右文本相关表示串联起来。
3.2.4 AEN
文献[33]提出的模型目的就是希望获取到目标句中的关键字相关的特征作为上下文表示。模型将给定的上下文和关键词分别转换为“[CLS]+上下文+[SEP]”和“[CLS]+关键词+[SEP]”之后,送入Bert进行预训练得到字向量。文献[35]所提出的多头注意multi-head attention(MHA)和逐点注意point-wise(PW)卷积变换模型分别对关键词和上下文进行intra-MHA(self-attention)以及PCT(point-wise convolution transformation)来计算关键词相关的特征信息。
3.2.5 t-TRNN
该模型通过使用两个不同的模型分别对上下文以及目标情感语句进行建模,上下文文本对TDLSTM进行建模得到上下文表示,而目标语句则对TRNN进行建模得到目标句的表示,最后得到的两个表示以及关键词的表示进行并行融合学习。
3.2.6 a-TRNN
该模型通过使用两个不同的模型分别对上下文以及目标情感语句进行建模,上下文文本对AEN进行建模得到上下文表示,而目标语句则对TRNN进行建模得到目标句的表示,最后得到的两个表示以及关键词的表示进行并行融合学习。
3.2.7 CA-TRNN
该模型通过使用两个不同的模型分别对上下文以及目标情感语句进行建模,上下文文本通过BiLSTM进行建模得到上下文表示,而目标情感语句则通过TRNN进行建模得到目标句的表示,并且将得到的目标句表示通过上下文得到注意力表示,得到一个对目标句感知的上下文表示,最后两个表示进行softmax得到分类结果。
3.3 实验结果和分析
实验一验证树形递归神经网络对隐式情感分类中的有效性,并考察不同长度的上下文对目标句的作用对分类结果的影响。一般来说,上下文越多,其蕴含的语境特征就越丰富,但这并不绝对呈正相关关系。本文对微博中文隐式情感语料的上下文进行选择,将上下文长度设置为目标句的前后两句(C-2),目标句的全部上下文(C-all)以及仅有目标句(C-no)进行测试。通过对验证集上的结果进行调参,最终所采用的超参数如表3所示。
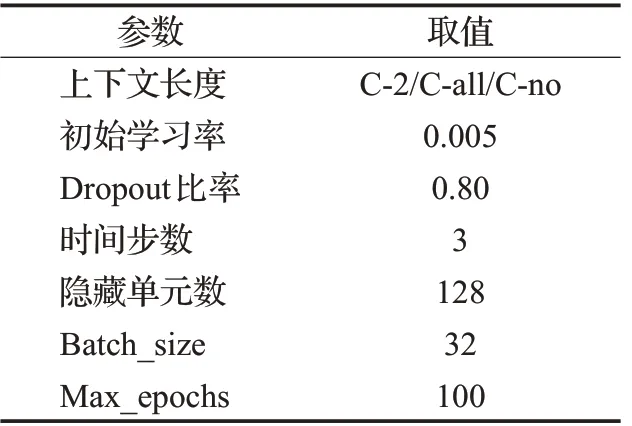
表3 树形递归网络实验超参设置Table 3 Hyper parameters setting of TRNN experiment
在TRNN结构中,通过在验证集上进行实验发现模型的时间步数对精度影响微弱,因此将模型的隐藏层设置为3。在分类任务中,隐藏层节点数通常取128~512之间,这里取128作为参数。最小样本数设为32,每个样本大小随着上下文长度的不同而不同。模型的优化采用在分类任务中效果较好的“Adam”算法。采用Dropout方法来降低过拟合,通过随机减少部分神经元的个数,降低过拟合程度,使得模型的泛化能力最优。
从表4可以看出,加入上下文对中文隐式情感的分类任务是具有有效性的,尤其是拥有前后两句上下文的目标句在树形递归神经网络中,提升了0.42个百分点。同时,通过实验也发现,当模型将完整的篇章级上下文输入到模型的时候,对比于TRNN中未使用上下文的模型而言,反而降低了1.78个百分点。实验结果表明篇章级的上下文在树形递归神经网络中不能准确地提取到其上下文的信息。

表4 树形递归网络对微博中文隐式情感分类结果ACC值Table 4 ACC of Chinese implicit sentiment classification based on TRNN
实验二基线模型和本文的方法的实验结果见表5。利用目标句相关的所有上下文,通过对比不同的实验模型在相同的数据集上的表现,有三方面的结论。
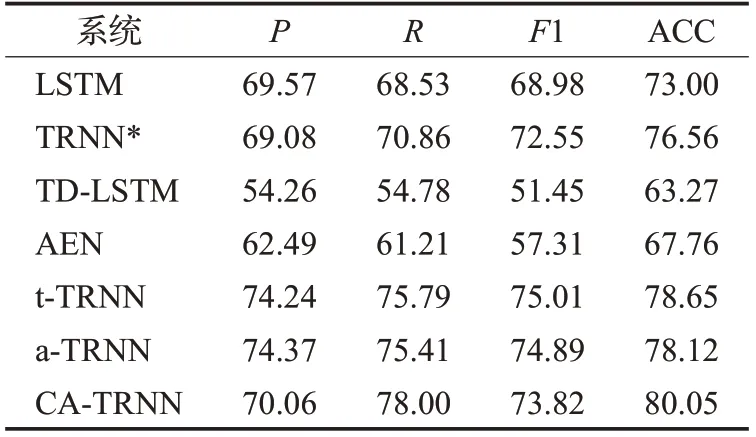
表5 对比实验下的实验结果(*为基线模型)Table 5 Experimental results of comparative experiments(*is baseline) %
(1)通过观察实验结果得到验证,将传统序列化模型(LSTM)和树形递归网络(TRNN)的精确度作对比,实验发现没有添加上下文信息的树形递归网络(TRNN+C-no)比LSTM高7.05个百分点,进一步验证了树形递归模型在隐式情感分析任务的有效性。即使对于放入了与目标句的全部上下文的TRNN*也表现的比LSTM效果更好,提高了3.56个百分点。该实验对比证明树形递归神经网络能够更准确地捕抓到中文隐式情感中的语义信息。
(2)本文对比了隐式情感分析数据集在文献[36]提出的TD-LSTM,以及文献[33]提出的AEN模型的结果,分别得到63.27%和67.76%的精确度,比传统的序列化模型分别降低了9.73个以及5.24个百分点的精确度。结果说明对目标句进行上下文关联并不能有效地提高模型的精确度。
(3)从表5结果可以看出,本文提出的3种方法(t-TRNN、a-TRNN以及CA-TRNN)在中文隐式情感领域的数据集上都取得不错的情感分类效果,其中t-TRNN以及a-TRNN分别比LSTM高5.65个以及5.12个百分点,并且CA-TRNN比传统序列化模型LSTM高7.05个百分点,初步验证并行输入对于模型的有效性。其次,通过对比t-TRNN与TD-LSTM的结果以及a-TRNN与AEN的结果,也可以发现t-TRNN比TD-LSTM高15.38个百分点,同样,a-TRNN比AEN高10.36个百分点,即对目标句及上下文并行输入的效果更佳。进一步观察发现,CA-TRNN比t-TRNN以及a-TRNN高1.4个以及1.93个百分点,可知结合目标特定上下文的注意力机制在上下文感知模型的有效性,弥补长距离树形递归结构的不足,从而取得更好的分类效果。
为了进一步验证本文提出的实验的有效性,用混淆矩阵对CA-TRNN、t-TRNN以及a-TRNN模型的分类结果及其分类样例进行说明。
如图4纵向表示文本的实际类别,横向表示模型预测文本的类别,在3种模型的混淆矩阵中,CA-TRNN在三分类的结果中表现优秀,优于t-TRNN,而对于贬义情感分类结果中,a-TRNN表现的比CA-TRNN高0.1个百分点。进一步对表6进行观察,表6对比了3种模型对于隐式情感文本分类的差异结果,针对无情感倾向的文本而言,CA-TRNN能够更好地对其进行分类,而另外两个模型(t-TRNN、a-TRNN)在对于上下文信息捕获的结果中,表现并不是很高。在样例中,第二个目标句在t-TRNN以及a-TRNN中被误导,目标句特征与目标特定的上下文注意力特征融合中,并没有更好地平衡两个特征之间的权重,使得目标特定的上下文信息被加重。实验结果也表明本文模型在一定程度上可以提升隐式情感文本的分类结果。
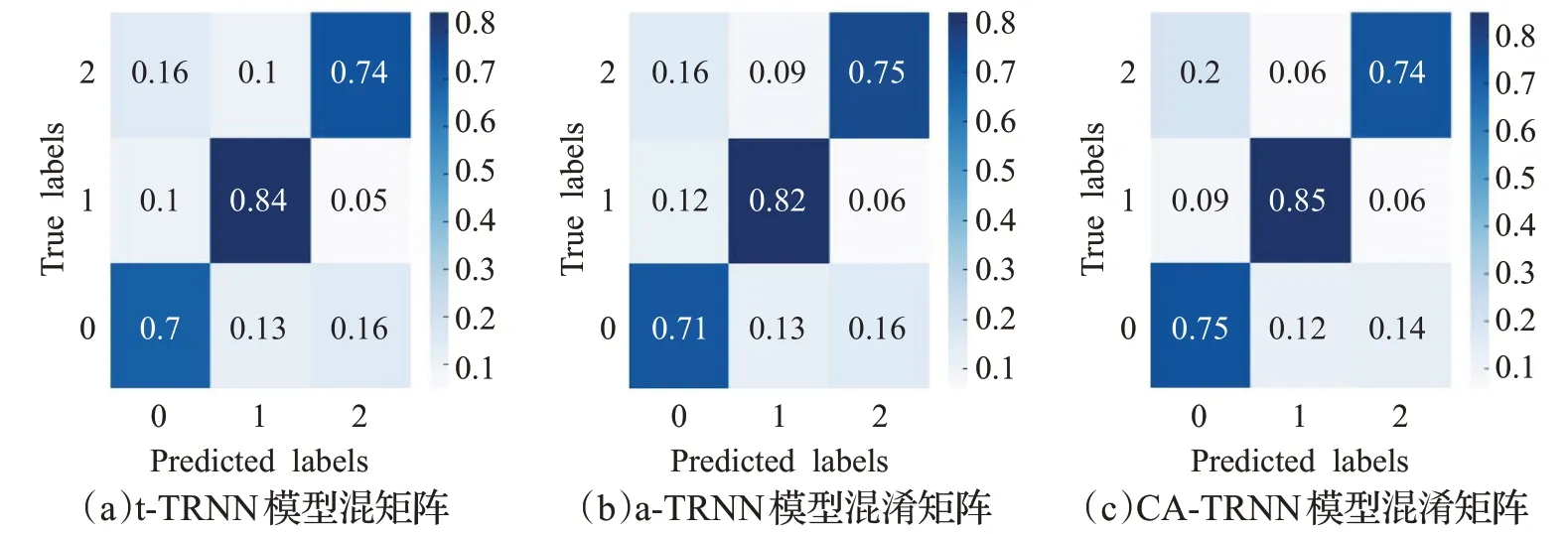
图4 3种模型的混淆矩阵对比Fig.4 Comparison of confusion matrix of three models

表6 模型预测样例Fig.6 Samples of implicit sentiment sentences
3.4 训练时间分析
为了验证不同模型在相同条件下的时间性能,本文在相同的CPU、GPU和网络框架下完成实验对比,同时,该部分的实验基于使用相同上下文条件下进行对比,即使用该目标句所具有的所有上下文信息。表6给出在不同的网络模型下对SMP2019数据集上完成10次epoch下的平均训练时间的对比结果。
从表7结果可以看出TRNN对于具有完整上下文信息的训练时间代价是非常高的,这主要是因为TRNN网络训练的时候需要对树型结构的数据进行计算,而对于具有较长上下文信息的文本而言,所生成的短语结构树的深度也是可观的,其计算量在无论使用CPU条件下,还是GPU条件下都是本文所提方法(CA-TRNN)的2倍多。此外,本文所提的t-TRNN、a-TRNN以及CA-TRNN都低于TRNN*网络模型,既可说明使用注意力机制的神经网络可以接收句子的平行化输入,也可以有效降低模型的训练时间。
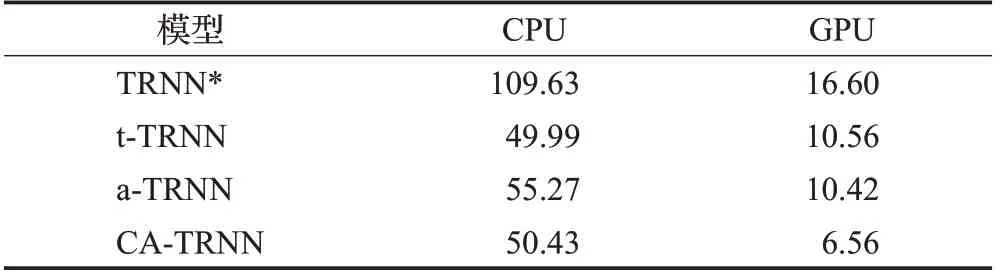
表7 不同模型完成10次迭代的平均训练时间Table 7 Average runtime of ten training epochs min
为了进一步说明不同模型在训练过程中模型收敛速度效果,本文抽取了100个epoch的loss值作为比较。
通过比较图5中不同模型的loss值可以看出,TRNN*的损失变化波动较大,收敛趋势较t-TRNN、a-TRNN以及CA-TRNN慢,这是因为TRNN*中使用了完整的上下文信息以及目标句信息,使得初始化的短语结构树较高,在TRNN*进行递归学习的过程中容易造成精度损失以及梯度爆炸,导致TRNN*结果相对较差,而将目标句以及上下文并行输入的时候,实验效果明显趋于缓和,且模型收敛速度较好,既可缩短模型的训练时间,保证时间代价减小,也能确保模型能够充分提取隐式情感文本中有意义的特征信息。
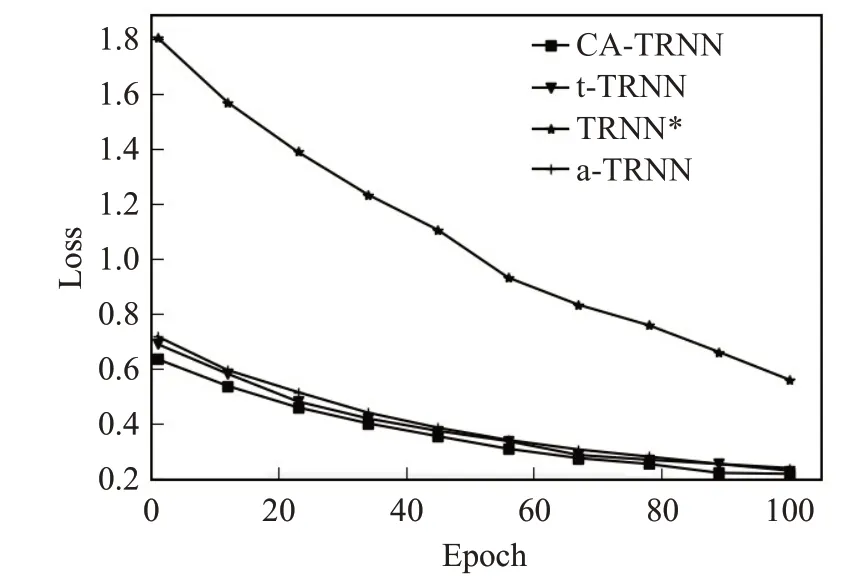
图5 利用上下文信息进行训练的模型的loss值对比Fig.5 Comparison of loss in training models using context information
4 结语
在中文隐式情感分类任务中,本文提出了基于注意力编码网络来提取目标句对上下文相关的表示,并生成目标句的语义表示进行融合表示,以此改善由于目标句拥有过长的上下文所导致的准确率下降的问题。本文对有无进行上下文信息表示的提取融合进行了探索和比较,发现CA-TRNN具有较好的准确性,也通过TRNN与LSTM比较发现,句子中的短语提供了更高的预测效果。实验和分析证明了该模型的有效性和准确性。同时通过实验也发现,单纯的TD-LSTM模型比LSTM的模型的精确度要低9.73个百分点。因此推测由于本文提取的是文本中的相关方面级词(TF-IDF),该词并未提高模型的准确度。经过观察,得知大多数提取到的词并不是目标句中具有情感倾向的方面级词语,而方面级词相关性也是一个重要的分类依据,往后的工作将致力于提取与目标句相关的方面级词以提高现有模型的精确度。
猜你喜欢
食品科学与人类健康(英文)(2022年2期)2022-11-28
机械工业标准化与质量(2022年6期)2022-08-12
现代电力(2022年2期)2022-05-23
河北果树(2022年1期)2022-02-16
河北果树(2021年4期)2021-12-02
烟台果树(2021年2期)2021-07-21
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
小型微型计算机系统(2020年5期)2020-05-14
电子制作(2019年19期)2019-11-23
电子制作(2019年24期)2019-02-23
