
基于多特征融合的股票走势预测研究
2022-03-26 07:35刘月娟
云南民族大学学报(自然科学版) 2022年2期
刘月娟,王 武
(云南民族大学 数学与计算机科学学院,云南 昆明 650500)
随着现代科技的不断发展和人工智能时代的进步,越来越多的机器学习算法,比如逻辑回归[1]、支持向量机[2]、决策树[3]等以及深度学习中的一些经典网络模型已经被广泛应用于股票预测等金融领域的研究.近年来,深度学习已经发展成为一门热门技术[4],并且在各大领域都有所突破,如文本分析、时间序列预测、计算机视觉[5]、股价预测[6~8]等等.此外,研究发现,在对股票数据进行预测时,深度学习模型往往比传统的机器学习模型更能取得较好的预测效果[9].
循环神经网络(recurrent neural network,RNN)是一类以序列数据为输入,在序列的演进方向进行递归且所有节点(循环单元)按链式连接的递归神经网络,是一种常见的深度学习模型[10],其被广泛应用于股票预测模型,但其一直以来都存在着2个极其明显的技术缺陷,一是梯度爆炸,二是梯度消失.研究表明,RNN 在处理较长的时间序列数据时会忘记之前的状态信息,故引入了长短时记忆网络(LSTM),LSTM 是 RNN 的一种变体,在时间序列学习方面表现出良好的性能[11],LSTM既能保持事件的上下文信息,也能保持事件的时间行为.但是神经网络模型通常使用原始时间序列作为输入[12],这使得很难解释每个输入特征序列在预测中所起的作用,为了解决上述问题,我们提出了一个注意模型[13]来为每个输入金融特征序列分配不同的权重来替代原始时间序列,这些权重是预测,从而增加了模型的可解释性,注意机制的本质是训练一个模型选择性地学习输入,并将输出序列与其关联.近期研究发现,投资者的情感在股票市场投资中可能起着十分重要的作用.比如,Antweiler和Frank[14]通过对电子邮件的内容和道琼斯指数的实验发现电子邮件的内容有助于预测股市的变化,并证实了在线评论与股票交易量之间的相关性.此外,参考文献[15]也强调了情感在投资者决策中的重要作用.虽然有很多研究表明情感与股票价格之间存在很强的相关性,但是很少有研究将情感分析用于股票预测.
基于上述研究,为了提高股票预测的精度,本文构建了 BiLSTM+Attention模型来对股票次日的收盘价进行预测,输入特征除了历史交易数据外,还引入了情感分析特征和语义分析特征.其中,情感分析方面运用了 NLTK 内置的 Vader 情感分析器.首先创建一个情绪强度分析器(SIA)来分类新闻标题,然后使用 polarity_scores 方法来获得情绪分数.这个模型给出了4个分数:(i)负面情绪得分(ii)正面情绪得分(iii)中立得分(iv)句子的复合情感得分.本实验中将用复合情感得分这个分数来衡量评论的情绪.通过对比预测结果的拟合图[16]和评价指标值,来验证本文提出的模型在股票预测中的可行性和有效性.
1 相关理论
1.1 LSTM 的结构与原理介绍
因长短时记忆神经网络(LSTM)是一种特殊的RNN,它可以长时间存储信息,同时可以忘掉不必要的信息,解决了RNN长期依赖中梯度消失和梯度爆炸和梯度消失的问题,相比普通的RNN,LSTM 在针对较长的时间序列数据进行预测时更有优势.
LSTM主要由记忆细胞、输入门、输出门和遗忘门组成,3个门的激活函数均为Sigmoid[17],其关键就是细胞状态,细胞状态类似于传送带,直接在整个链上运行,只有一些少量的线性交互,信息在上面流传保持不变会很容易.
遗忘门将细胞状态中的信息选择性的遗忘,其决定了上一时刻的单元状态Ct-1有多少保留到当前时刻Ct,输入门将新的信息选择性的记录到细胞状态中,其决定了当前时刻网络的输入Xt有多少保存到单元状态Ct,输出门控制单元状态Ct有多少输出到LSTM的当前输出值ht,这3个门的目的都是用来保护和控制细胞状态,LSTM的网络结构展开图见图1,结构图中Xt表示t时刻的输入,ht表示t时刻细胞的状态值,

图1 LSTM 网络结构展开图
下面是LSTM的计算公式:
输入门:
it=δ(Wi*[ht-1,Xt]+bi),
(1)
(2)
输入门用来控制当前输入新生成的信息Ct中有多少信息可以加入到当前时刻发细胞状态Ct中,tanh层用来产生当前时刻新的信息,δ层用来控制有多少新信息可以传递给细胞状态.
遗忘门:
ft=δ(Wf*[ht-1,Xt]+bf),
(3)
遗忘门决定上一时刻细胞状态Ct-1中的多少信息可以传递到当前时刻Ct中.
(4)
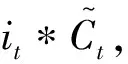
输出门:
Ot=δ(Wo*[ht-1,Xt]+bo).
(5)
ht=Ot*tanh(Ct).
(6)
基于更新的细胞状态,输出隐藏状态ht.式中,Wi、Wc、Wf、Wo分别为输入门、更新门、遗忘门和输出门的权值矩阵,bi、bf、bc、bo分别为输入门、更新门、遗忘门和输出门的偏置.
双向LSTM(BiLSTM)是LSTM的一种变体,在近年来的NLP任务中,由于能够更好地理解上下文,其效果优于单向LSTM[18].Bi-LSTM是由前向LSTM与后向LSTM组合而成,按顺序分别从左端和右端开始运行正向LSTM和反向LSTM[19].BiLSTM不仅可以保存过去的信息,而且可以捕捉未来的信息,BiLSTM的网络结构展开图见图2,
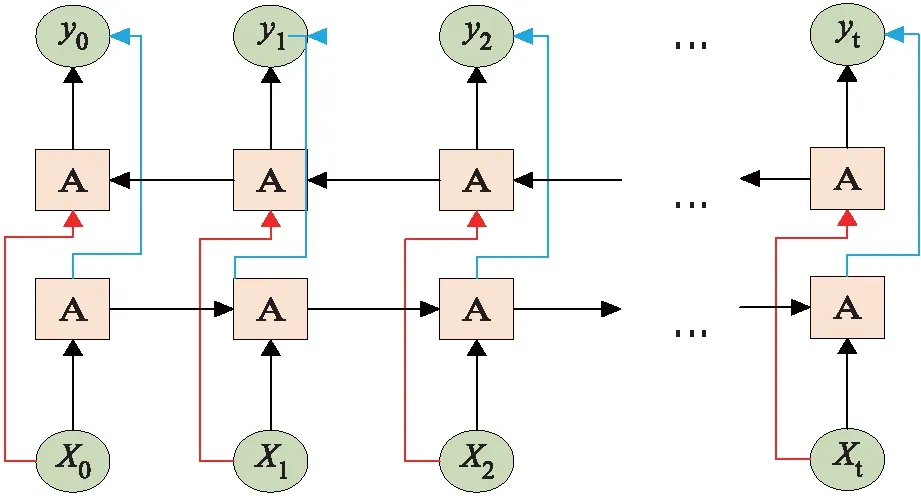
图2 BiLSTM网络结构展开图
1.2 注意力机制
最近几年,注意力模型在深度学习各个领域被广泛使用,无论是图像处理、语音识别还是自然语言处理的各种不同类型的任务中,常常都需要引入注意力模型机制,其是深度学习技术中最值得关注与深入了解的核心技术之一.本质上,注意力模型的核心目标就是从众多的信息中选择出对当前任务目标更为关键的信息.
本实验中在BiLSTM模型基础上引入注意力机制(attention),输入序列是描述金融市场历史信息的原始特征时间序列,使用了苹果从2010-01-04日到2018-12-31日的开盘价(open)、最高价(high)、最低价(low)、调整后的收盘价(adj close)和成交量(volume)数据.注意力机制可以自适应地选择最相关的输入特征,并对相应的原始特征序列赋予更高的权重.然后我们将注意力模型的输出作为BiLSTM深度学习模型的输入来预测金融市场.即利用先前的信息和关注权重来预测下一个交易日的收盘价[20].
1.3 Word2vec模型
Word2vec是一种流行的序列嵌入方法,它将自然语言转换为分布式向量表示[21],它可以在多维空间中捕获上下文的词到词的关系,并作为预测模型的初步步骤得到广泛应用语义和信息检索任务.Word2vec依赖Skip-gram或连续词袋(CBOW)来建立神经词嵌入[22].本文主要是基于Skip-gram方法进行文本数据进行词向量处理,因为它可以在大型数据集上产生更加准确的结果.首先将数据进行预处理,切分训练集与测试集,其次进行分词处理,然后对每个句子的所有向量取均值来生成一个句子的vector,计算出词向量,最终用于训练BiLSTM+Attention模型,Word2vec的2种训练模式见图3.
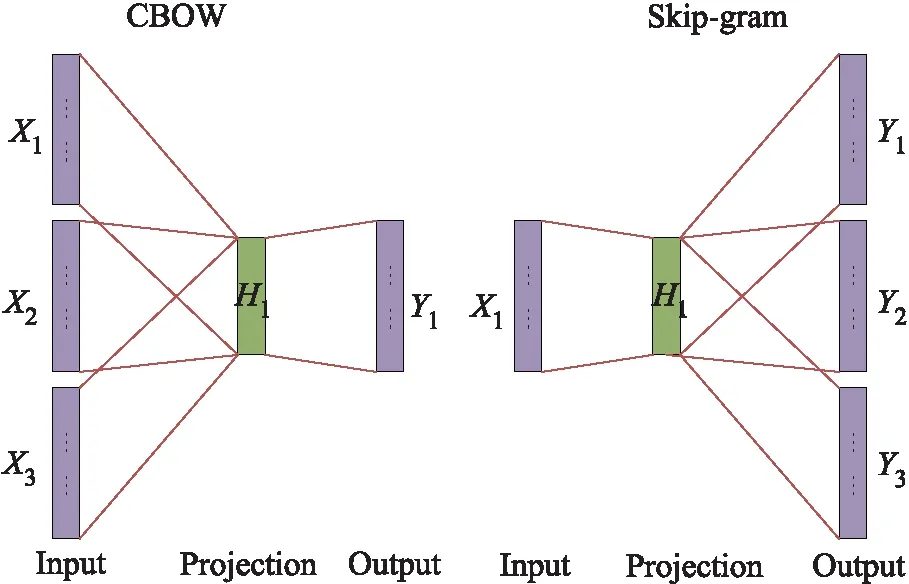
图3 Word2vec模型
2 股票预测模型框架设计
文中用到的股票预测网络模型是在BiLSTM模块的基础上进行搭建的.其中的BiLSTM模块使用了单层的BiLSTM神经网络结构学习数据中的时序特征,有200个隐藏神经元,输出层采用linear激活函数来输出最终的结果,并选用Adam优化器做优化.其实验是在Python3.6.5上配合一系列的依赖库完成的.表1列出了BiLSTM模型结构用到的主要软件.基于多特征融合和BiLSTM+Attention的股票预测网络模型框架见图4,其中在语义特征提取部分,我们进行了m维语义特征提取,经过不断的实验验证发现,当m取1时,模型预测效果最好.

表1 BiLSTM模型软件环境
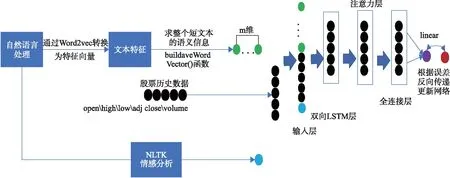
图4 股票预测模型总体设计框图
3 实验与结果分析
3.1 实验数据
3.1.1 数据来源
本文的数据集包括2部分:股票历史交易数据和金融新闻标题数据.股票历史交易数据是利用python自带的Tushare财经接口包下载的,从中选取了影响股票价格波动的5个主要技术指标[23]:最高价(high)、最低价(low)、开盘价(open)、成交量(volume)和调整后的收盘价(adj close),金融新闻标题信息来源于Reddit(社交新闻站点),选用的数据集为苹果(AAPL.us).
其中苹果(AAPL.us)选用的股票历史交易数据和新闻标题日期为2010-01-04至2018-12-31,爬取到的有关苹果的金融新闻标题内容共2357条.
3.1.2 数据预处理
针对股票历史交易数据,由于获取到的原始数据集存在乱序、异常值和缺失值等情况,所以要先对数据集进行数据清洗和排序等操作,最终获得一个完整且排序准确的数据集.由于不同的指标数量级之间存在着巨大的差异,为了消除这种差异,本文使用Min-Max 归一化方法,将数据的值压缩到0到1之间,它是将观测值减去该组观测值中的最小值,再除以该组观测值中的最大值与该组观测值中的最小值的差值得到的,公式如下:
(7)
针对金融新闻标题文本,需要对一些标点符号、特定术语缩写等字符串进行处理;然后在百度提供的停用词表基础上对文本进行去停用词处理[24].
3.1.3 时间步数设置
本文为了更好的对比训练结果,将实验数据集划分为训练集合测试集2部分,将2010-01-04至2016-07-29的数据集作为训练集,2016-08-01至2018-12-31的数据集作为测试集.在本文提出的股票预测模型中,为了达到好的训练效果,设置了不同的时间步长,其股票预测效果图分别如下图5所示,实验表明,模型预测结果的准确性与时间步长的设置有很大的关系.
通过观察图5可以发现,当时间步长为5时,由于考虑到的时间步长较短,预测结果有一定误差.
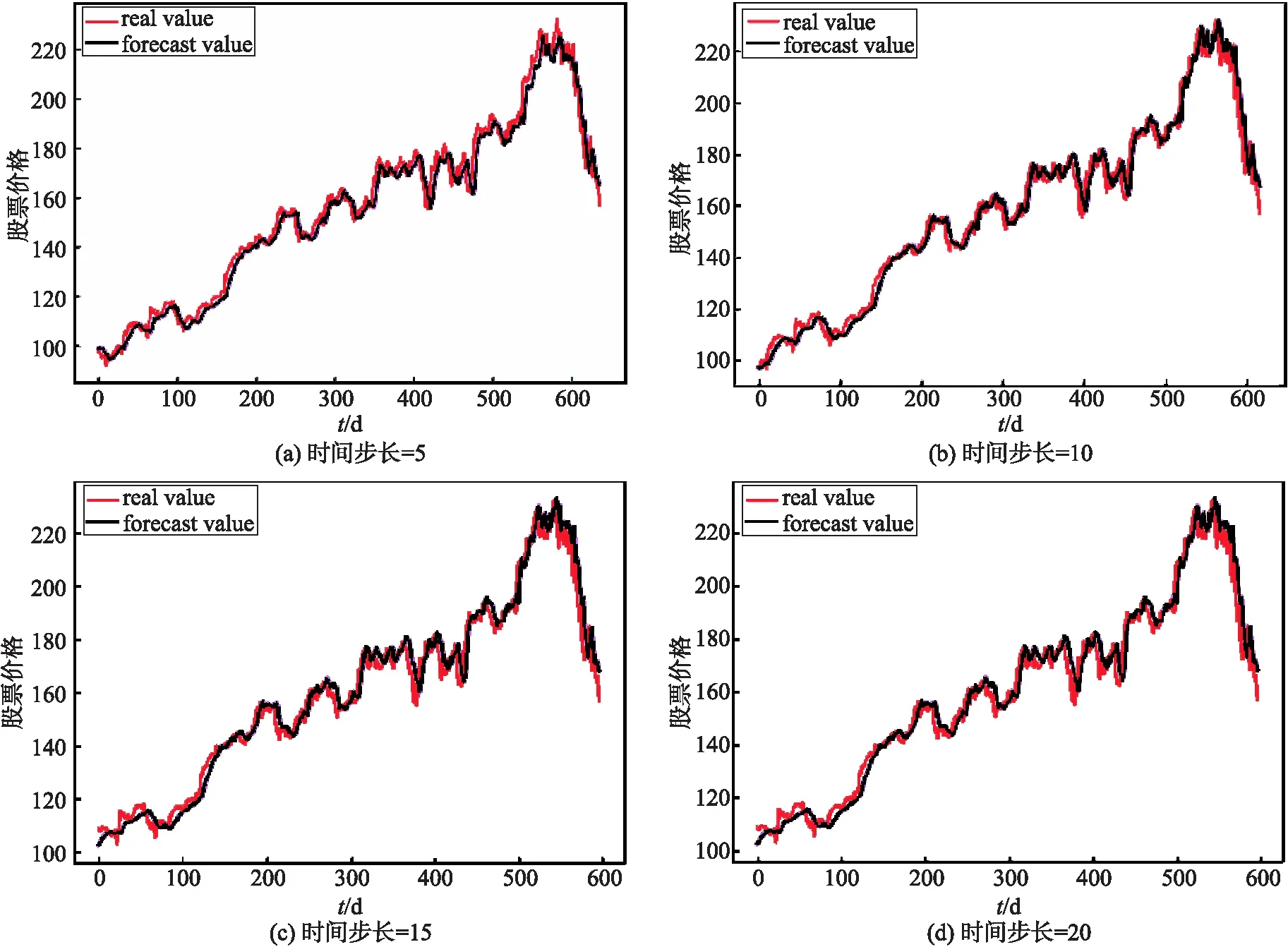
图5 不同时间步长下模型预测效果图
当时间步长设置较长时,如图5(d),(e)和(f),当时间步长分别为20,25,30时,考虑的时间范围相对较大,容易忽略掉短时间内金融新闻等因素造成的影响,预测结果误差较大,准确性偏低.可以发现,当步长设置为10时,预测结果准确性最高,所以本文将时间步长设置为10,即用前10天的7个属性的数据特征作为神经单元的输入层,第11天的收盘价作为标签进行模型训练.
3.2 实验结果
模型预测结果如图6、7、8、9、10所示,红色曲线代表股票的预测收盘价格,紫色曲线代表股票真实的收盘价格,横坐标代表时间,纵坐标代表反标准化后的股票价格.
图6表示用BiLSTM网络对股票收盘价进行预测,其中模型输入为股票历史数据,即最高价(high)、最低价(low)、开盘价(open)、成交量(volume)和调整后的收盘价(adj close),共5个输入特征.
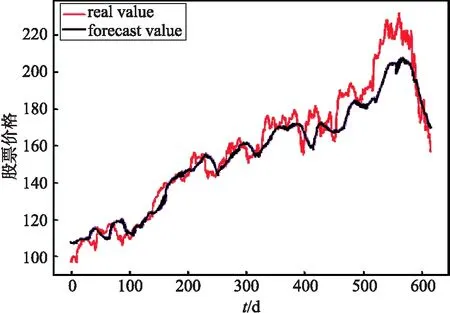
图6 BiLSTM
图7表示用BiLSTM网络对股票收盘价进行预测,其中模型输入为股票历史数据和使用NLTK内置的Vader情感分析器对金融新闻标题文本数据进行情感分析提取出的情感特征,即最高价(high)、最低价(low)、开盘价(open)、成交量(volume)和调整后的收盘价(adj close)和文本情感特征,共6个输入特征.
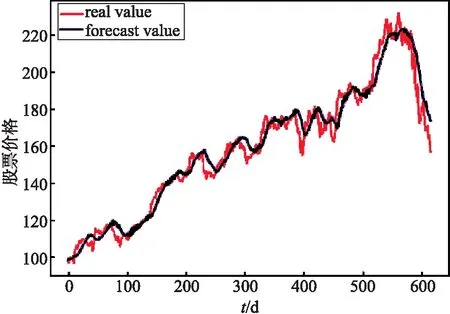
图7 BiLSTM+情感特征
图8表示用BiLSTM+Attention网络对股票收盘价进行预测,其中模型输入为股票历史数据,即最高价(high)、最低价(low)、开盘价(open)、成交量(volume)和调整后的收盘价(adj close),共5个输入特征.

图8 ATT-BiLSTM
图9表示用BiLSTM+Attention网络对股票收盘价进行预测,其中模型输入为股票历史数据和使用NLTK内置的Vader情感分析器对金融新闻标题文本数据进行情感分析提取出的情感特征,即最高价(high)、最低价(low)、开盘价(open)、成交量(volume)和调整后的收盘价(adj close)和文本情感特征,共6个输入特征.
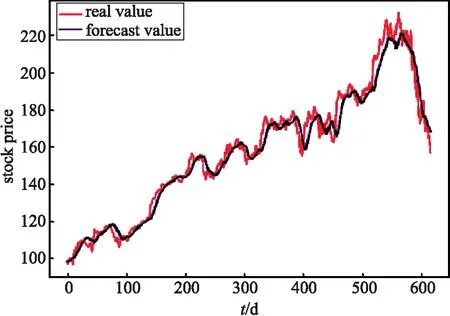
图9 ATT-BiLSTM+情感特征
图10表示用BiLSTM+Attention网络对股票收盘价进行预测,其中模型输入为股票历史数据和使用NLTK内置的 Vader 情感分析器对金融新闻标题文本数据进行情感分析提取出的情感特征以及运用Word2vec模型最终提取出文本的语义特征,,即最高价(high)、最低价(low)、开盘价(open)、成交量(volume)和调整后的收盘价(adj close)、文本情感特征和文本语义特征,共7个输入特征.
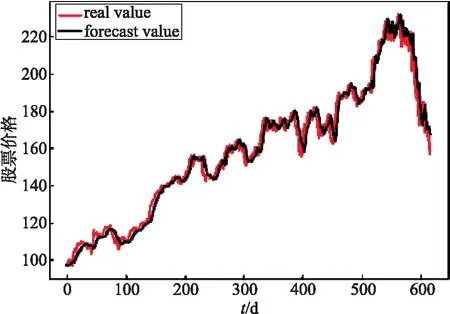
图10 ATT-BiLSTM+情感特征+语义特征
通过对图6~10 的实验结果观察对比可以发现单一的BiLSTM网络对股票价格的预测最不敏感,图10是文中新提出的网络模型,可以发现预测效果较其他相比预测误差是最小的,可以较为准确的预测到股票的价格波动趋势.因此,通过对比试验结果验证了文中提出的网络模型的有效性和可行性.
3.3 评价指标
文中提出的网络模型最终目标是预测股票未来的收盘价,选用了均方根误差(RMSE)、平均绝对误差(MAE)和R2作为模型的评价指标,计算公式如下:
(8)
(9)
(10)
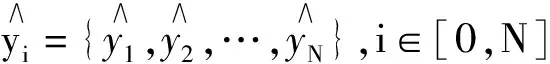
各个模型的评价指标结果对比如表2.
由表2可以看出,7个属性作为输入特征进行训练时,预测结果的准确率最高,也就是我们本文提出的模型,RMSE和MAE 都低于前4种模型,RMSE 和 MAE 越低,说明预测值和真实值越接近,同时可以看出,R2值较于前4个模型更接近于1,R2的值越接近1,说明回归直线对观测值的拟合效果越好,并且可以发现,加入新闻文本的模型预测效果比只用历史交易数据作为输入特征的模型预测效果更好.因此可以得出结论,BiLSTM+Attention模型在股票价格预测上有很大的参考价值,并且加入新闻文本数据提取相关特征,可以使预测效果更加准确,文中提出的网络模型可以为投资者和研究人员提供一定的参考.
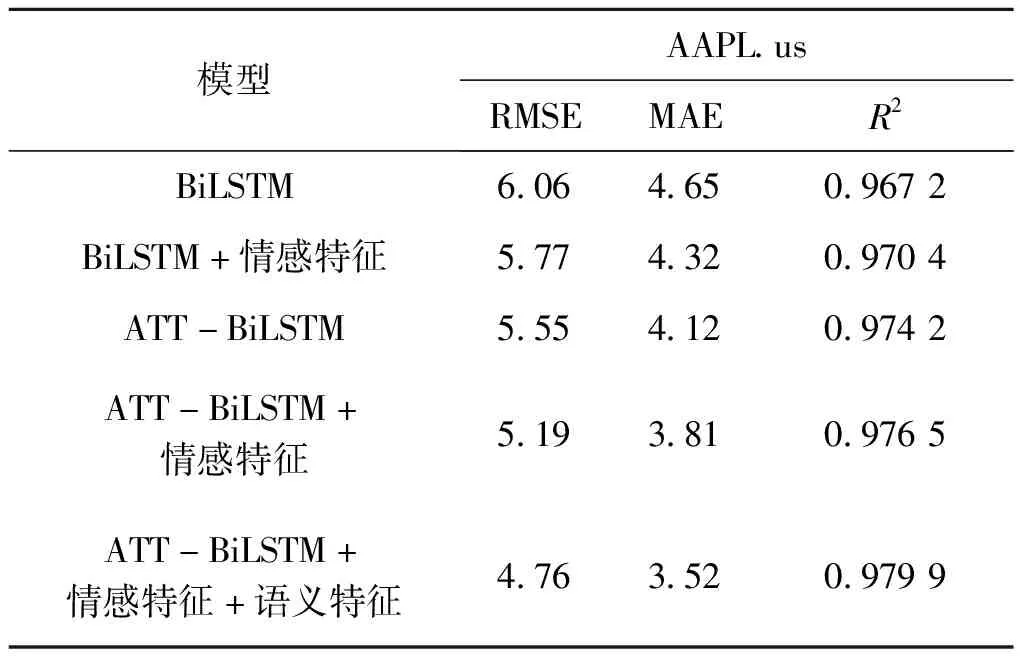
表2 网络模型的预测评价指标对比
4 结语
为了更好地对股票走势进行预测,在特征输入部分考虑到股民的情绪也会对影响到股市的波动,文中Vader情感分析器对文本数据进行情感分析得到情感分数,进行得出股民的情感特征,将情感特征与运用Word2vec模型提取出的文本特征以及股票交易数据特征进行融合,最终使用BiLSTM+Attention模型进行股价预测,通过与只使用股票交易数据作为输入特征进行股价预测的 BiLSTM和BiLSTM+Attention模型,使用了股票交易数据以及金融新闻标题的情感特征共同作为输入特征进行股价预测的BiLSTM和BiLSTM+Attention模型的对比实验可以看出预测效果得到了一定的提升,表明了本文模型的可行性和有效性.
未来的研究中可以增大股票的相关技术指标数据量和影响股票市场波动的文本信息量,将深度学习和机器学习方法结合建立股票预测模型,进一步提升模型的预测效果.
猜你喜欢
无线互联科技(2020年12期)2020-09-03
科学大观园(2019年10期)2019-09-10
中国经济周刊(2019年9期)2019-05-24
学校教育研究(2018年9期)2018-05-14
——中国制药企业十佳品牌
西部大开发(2017年5期)2017-07-05
股市动态分析(2016年23期)2016-12-27
股市动态分析(2016年22期)2016-12-27
股市动态分析(2016年7期)2016-09-29
股市动态分析(2016年4期)2016-09-29
喜剧世界(2016年9期)2016-08-24
