
权数对基于模型推断的影响分析
2022-03-25 03:06:00金勇进刘晓宇
统计与信息论坛 2022年3期
金勇进,刘晓宇
(中国人民大学 a.应用统计科学研究中心;b.统计学院;c.调查技术研究所,北京 100872)
一、引言
在实际抽样调查中,常需要对总体的一些参数进行推断,如总值、均值、比例等。对这些总体参数的推断途径主要分为两种:一种是传统基于抽样设计的推断,以入样概率为基础,根据从有限总体中进行的随机抽样对有限总体特征进行推断;另一种是基于模型的推断,假定有限总体是超总体模型的一次随机实现,通过估计超总体的模型参数来推断有限总体特征。
长久以来,基于设计和基于模型推断之间存在广泛的讨论。基于设计的推断仅在调查设计阶段要求对总体进行一些假设,例如依据中心极限定理,当样本量足够大时样本统计量服从正态分布等,这些假设通常比较宽松,在大样本情况下能够得到可靠的估计。基于模型的推断在单一抽样方法下,存在最优估计量理论并得到相对有效的目标量估计。事实上,两种途径各有利弊,基于设计的推断在存在非抽样误差或总体结构存在线性趋势等情况下,估计结果低效甚至无效;而基于模型的推断对模型的识别敏感、模型的错误识别可能会造成推断失效。对基于设计和基于模型推断,有比较优劣的研究,有探索关联的研究,也有模型辅助的估计[1],但鲜有文献涉及二者的结合,在充分考虑调查数据概率特征的基础上进行建模分析[2-3]。基于设计和基于模型推断的结合不仅缺乏理论研究,在实际应用中同样缺乏指导。导致这种情况的主要原因是,调查设计和数据分析通常是由不同的人来执行,数据分析人员能够掌握的现场调查信息受到限制,例如抽样框、抽样设计和原始数据的某些复杂特征可能被隐藏。同时,抽样设计相关的方法集中在基于设计的推断体系上,与许多主流应用统计常用的建模分析完全不同,会对习惯基于模型推断体系的数据分析人员造成混淆。
权数在基于设计推断中起着核心作用,它与入样概率相关,是样本推断总体的扩张系数用于衡量各样本单元的变量值在总体中的作用大小。将权数引入基于模型的推断,可以使得基于模型的分析结果反映样本的概率特征,具有总体代表性,实现两种推断体系优势的组合。本文创新性地将权数引入基于模型的推断,针对因果推断问题探究权数对模型推断效果的影响,将权数纳入模型拟合,构造处理效应的双重稳健估计;一方面从估计的角度讨论权数的功能,旨在获得更准确、稳健的估计结果;另一方面为实际应用提供参考,说明设计权数对于模型推断的重要性,强调在对调查数据分析时应充分考虑抽样设计的影响。
二、基于设计与基于模型的推断框架分析
(一)基于设计的推断思路
主流抽样教科书中介绍的估计方法均以随机化为基础,被称作基于设计的推断方法,也称作基于随机化的推断方法,例如HT估计、HH估计等。基于设计的推断只研究有限总体的特征,生成数据的模型虽然可能存在,但是不需要知道模型的具体形式,也不依赖于任何模型假设。

(1)

(2)
(3)
如果估计量的期望值等于真实值,则估计量是无偏的。如果偏差和方差都随着样本量的增加而趋近于0,则估计量是一致的。根据以上分析可知,通过设计权数将样本信息还原到总体,HT估计量具有无偏性和一致性。权数在基于设计的推断中发挥着重要作用。
(二)基于模型的推断思路
在社会科学领域的研究中,常需要对调查数据进行建模分析,这种途径被称作基于模型的推断方法。该方法假定有限总体是来自一个无限超总体的样本,通过样本寻找一个生成总体的模型,并估计模型参数。与基于设计的“估计”相比,基于模型的方法侧重于“预测”,通过对目标变量Y的分布建模,预测总体中未入样单元,估计量的性质取决于模型假设,与抽样设计和样本选择无关。Royall在线性回归模型下对有限总体估计进行了研究,被认为是基于模型推断体系初步形成的标志[5]。
现以一个简单的超总体模型为例,分析基于模型估计量的性质。假定总体中的所有单元k=1,2,…,N服从如下模型:
μ=EM(yk),vM(yk)=σ2
(4)

(5)
(6)

(三)方法评述
基于设计与基于模型的推断是两类重要的抽样推断体系,二者各有特色。基于设计的推断更侧重“描述”,基于模型的推断更具有“分析性”,因此后者在经济学、社会学等领域的应用更为广泛。事实上,基于模型可以规避基于设计估计时存在的一些缺陷,具体包括以下几点:第一,方差估计问题。实际抽样设计通常较复杂,难以获得准确的πkl值,此时无法通过式(3)计算基于设计估计量的方差,需借助其他近似方法或重抽样方法,且在不放回抽样中可能出现Δkl<0的情况,致使式(3)的计算值为负,这有悖于方差的含义。而基于模型估计量的方差取决于yk,与包含概率无关,不受抽样设计的影响,不存在失效的风险。第二,样本量问题。基于设计的方法需要较大的样本量来保证估计量的渐近性质,若实际样本量无法达到要求,尤其是在对于总体估计时,估计精度将大打折扣。而基于模型的推断效果与样本量无关,当模型选择合适时,仅通过小样本就可以得到总体的优良估计。第三,估计量的稳健性问题。基于设计估计量的性质可能会受到其他因素的影响,例如总体结构中存在的线性趋势、周期波动和自相关问题、非抽样误差以及离群值等,而基于模型的方法可以依据对总体分布的认识,灵活设置超总体模型,进而避免这些因素的影响。
然而,基于模型推断总体的一大局限性在于,若选择了不恰当的超总体模型,可能会得到比基于设计方法更差的推断结果。且当样本的入样过程不具有无信息性时,总体单元是否入样与目标变量的取值有关,此时基于模型的推断结果存在选择性偏差。由于基于模型推断淡化了抽样设计,导致该方法对样本概率特征的反映并不是很敏感,那么,在模型确定的情况下,是否可以通过引入权数,改善基于模型的推断效果,组合两种推断途径的优势,既能保留对总体的代表性,又能得到精度高且效果稳定的估计结果,本文以因果推断问题为背景,对此展开讨论。
三、权数在因果推断中的使用
从观测数据中推断因果效应常借助倾向得分实现,目前大部分研究在实际推断时忽略了抽样设计的影响,少数学者尝试将权数纳入推断过程,但尚未形成统一结论[6-8]。在基于倾向得分对处理效应进行模型估计时,涉及倾向得分模型和预测模型两个模型,本部分在分析权数功能的基础上,讨论如何在估计过程中利用权数构造双稳健估计,并对其中涉及的一些问题进行思考,作为后续模拟研究的基础。
(一)基于倾向得分的因果推断法
在科学研究中,经常需要识别不同处理对于结果变量的影响,即进行因果推断。研究因果关系的黄金法则是随机化试验。然而在实际研究中,无论是出于执行成本和执行难度,还是道德和伦理的限制,无法实施随机化试验,而借助观测数据开展的因果推断研究得以发展。在实际中,个体一旦处于某种状态,将无法回到原始状态,更无法得到其处于其他状态下的结果,也就是说,研究者永远无法同时观测到一个特定个体的两个潜在结果,处理组的个体只能看到处理后的状态,对照组的个体只能看到未处理的状态。但是,如果能够知道潜在结果,或者是对潜在结果进行一些合理的假设,便可估计处理效应,这是利用观测数据进行因果推断所依据的主要思想。在基于观测数据的因果推断研究中,如何控制混杂变量造成的偏差至关重要。混杂变量会同时影响个体是否接受处理和结果变量,若不加以控制,将无法确定结果变量的差异是来自不同处理还是混杂变量。
倾向得分理论最早由美国统计学家Rosenbaum和Rubin提出[9],是控制潜在混杂对推断造成的影响的常用方法。倾向得分法是指在控制了协变量后,观测样本中的单元被分配至处理组的概率。假设每个样本单元的观测值为{yi,ti,xi;i∈s},其中y为待研究变量,t为示性变量,ti=1时表示第i个观测样本单元被分配至处理组,ti=0时表示第i个观测样本单元被分配至对照组,x为混杂因素,定义倾向得分为ei=P(ti=1|x,y;γ,γ0),其中γ、γ0是未知参数,分别表示真实模型中x、y的系数。倾向得分法的假设如下:
(1)∀i∈s,满足P(ti=1|x,y;γ)=P(ti=1|x;γ,γ0)
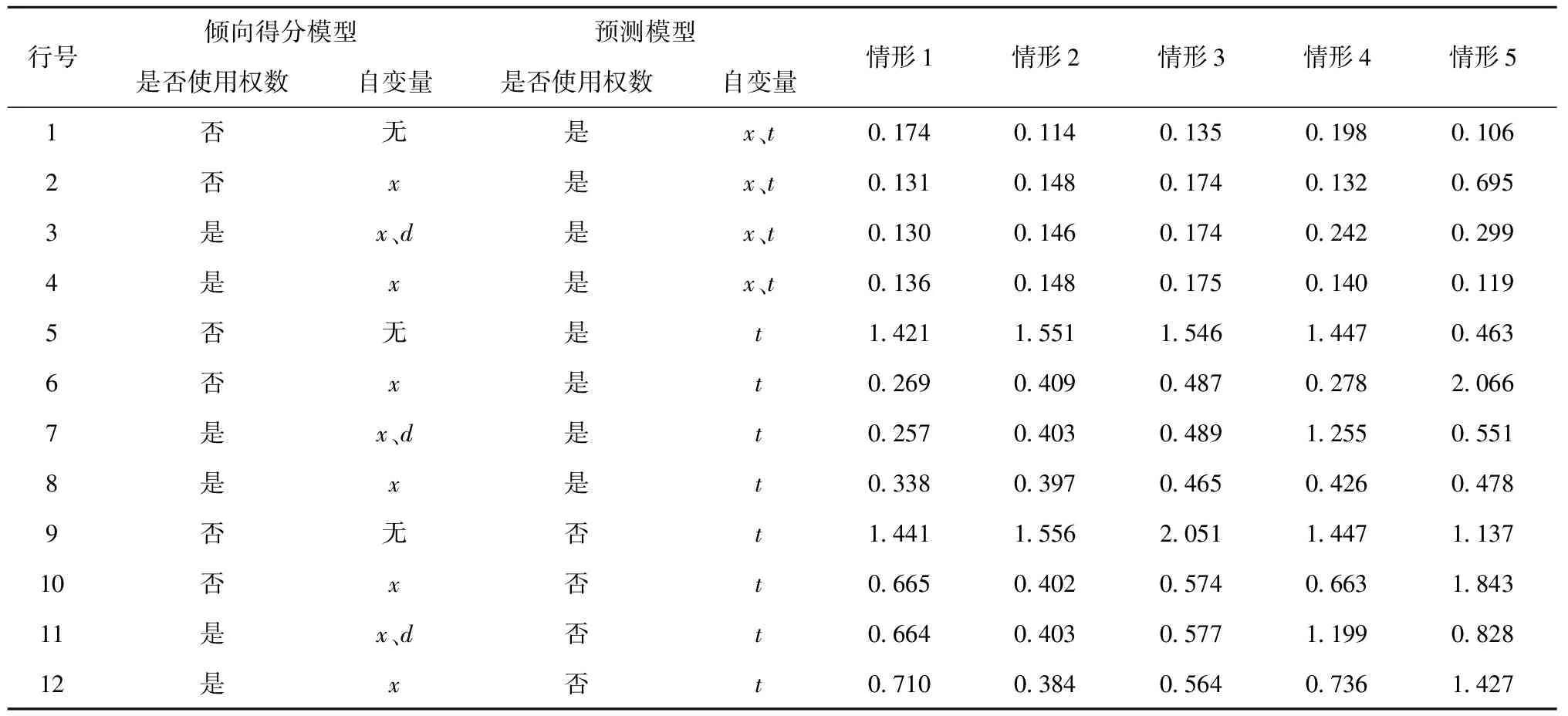
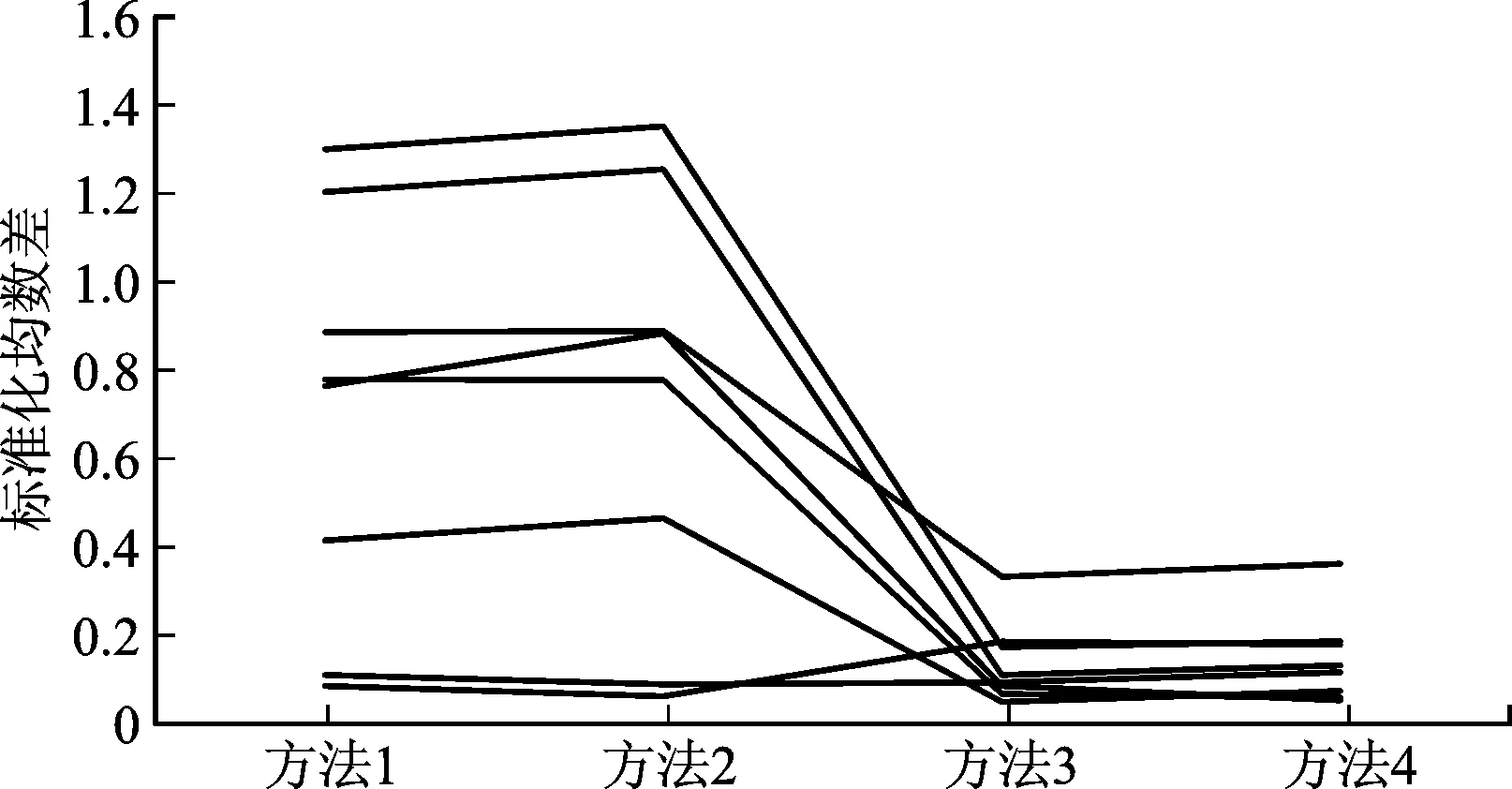
(2)∀i∈s,0 (3)∀i∈s,P(ti=1|x;γ)=P(ti=1|xi;γ) Rubin对倾向得分的性质进行了研究,结果表明,通过倾向得分不仅有效控制了混杂因素,使得处理组与对照组的待研究变量具有可比性,还能实现协变量的充分降维,得到的处理效应估计具有无偏性[9]。倾向得分可与传统方法如匹配、分层、回归等相结合,在此基础上Hirano等提出了利用倾向得分进行逆概率加权的方法估计因果效应[10]。 假设样本量为n,对于每个样本单元i∈s;ti为示性变量,ti=1时表示单元i被分配至处理组,ti=0时表示单元i被分配至对照组;xi为混杂因素,f(x|t=1)表示处理组的混杂变量分布,f(x|t=0)表示对照组的混杂变量分布;y0i表示对照组的潜在结果变量,y1i表示处理组的潜在结果变量,二者只有一个可以观测到。 因果推断要求处理的分配是随机的,此时处理组和对照组的混杂变量分布相同,即f(x|t=1)和f(x|t=0)相同。而实际上,二者并不相同。为实现随机化的要求和样本对总体的代表性,需对两分布构造一个权数w(x),使得f(x|t=1)=w(x)f(x|t=0,s=1),根据贝叶斯公式有: (7) 其中1/f(s=1|t=0,x)为样本的设计权数,f(t=1|x)/[1-f(t=1|x)]为从处理组出发估计的风险比。若随机样本与总体的处理分配不同,即f(t=1|x)≠f(t=1|x,s=1),那么w(x)将无法使处理组和对照组的混杂达到平衡,仅基于样本处理的分布f(t=1|x,s=1)对总体处理的分布f(t=1|x)进行推断,可能无法准确刻画总体的分布特征。因此在估计f(t=1|x)时,需充分考虑样本与总体的关系,发挥权数的作用。 根据以上分析可知,在基于调查数据进行因果推断时,权数的使用包括两步:一是在对f(t=1|x)进行估计时纳入权数;二是无论基于设计还是基于模型推断,应在处理效应的估计中考虑权数。 1.回归模型中的权数 众所周知,标准线性回归是典型的基于模型推断的方法,一般采用普通最小二乘法(OLS)或极大似然法进行拟合。对于OLS法,在进行拟合时需要假定残差的方差恒定,当残差不满足方差齐性时,将单元i残差的方差表示为σ2/ui,其中ui是一个已知常数,那么可以通过加权最小二乘法(WLS)得到更好的推论,即回归模型中样本单元i与ui成比例进行加权。WLS同样是基于模型的推断方法。若要在基于模型的推断中结合基于设计的推断,加权方法则会出现完全不同的形式。在基于设计的推断中,设计权数di是根据抽样方案确定的,代表样本在总体中的相对重要程度。此时,在模型推断中考虑抽样的随机性,应根据权数di进行加权最小二乘法的估计,将包含概率的倒数加入最小二乘方程。由于每个样本i代表总体的1/πi个单元,所以它在回归中的权数与1/πi成正比。两种加权方式都是合理的,但它们的思路完全不同,对y的分布的建模导致利用ui加权,随机抽样导致利用1/πi加权。 对于极大似然法,假设超总体模型的形式为g(E[Y|X=x])=g(μ)=η=x′β,方差v[Y|X=x]=σ2V(μ),示性变量Ii表示单元是否入样,若单元i入样,则Ii为1,否则为0,那么参数估计通过求解如下的得分方程得到: (8) 当考虑抽样设计时,极大似然法演变为伪极大似然法,得分方程变为: (9) 根据大数定律和中心极限定理,若正确地指定了超总体模型,伪极大似然法得到的参数估计值具有渐近正态性和一致性。接下来考虑更加复杂的情形,针对基于倾向得分的因果推断,利用权数构造双稳健估计。 2.双稳健估计中的权数 双稳健估计采用两种关系模型估计待估参数,即使其中一个模型被错误指定,所得的估计量仍具有一致性。通过倾向得分可以保证处理分配机制的可忽略性,通过预测模型可以进行参数估计。如何利用权数构造两个估计模型,实现处理效应的双稳健估计,是本部分讨论的重点。 (1)倾向得分的估计 倾向得分模型常采用通过Logistic或者Probit回归拟合,属于概率估计模型,处理作为因变量,其他混杂因素作为自变量。为了实现对背景变量的平衡、减少选择性偏差和控制估计量的方差,倾向得分模型应包含与处理和结果变量均相关的变量,通过控制这些变量排除它们对结果变量的影响,使结果变量的差异仅来自不同处理。若纳入与处理有关而与结果变量无关的变量,无法控制估计量的方差;若纳入与处理无关但与结果变量相关的变量,无法排除混杂的影响,消除选择性偏差[11]。 根据调查数据进行因果分析,需同时考察样本选择机制和处理分配机制,识别影响样本选择的变量,以及这些变量与倾向得分模型中的协变量的包含关系。倾向得分模型涉及处理分配机制。假设变量z影响样本选择机制,倾向得分模型根据协变量x建立,ei=f(t=1|xi),总体治疗组的平均处理效应ATT的估计为: (10) 对于式(10)的前半部分,根据贝叶斯公式计算可得: =E(y1|t=1) (11) 对于式(10)的后半部分,根据贝叶斯公式以及倾向得分的性质,即对协变量x取条件后t与y0独立,分子为: dy0dxdz (12) 分母的计算类似,可得 (13) 欲使式(13)是E(y0|t=1)的一致估计,需要f(y0,x,s|t)=f(y0,x|t)f(s|t)成立。然而,由于变量z影响样本选择机制,(y0,x)与s的独立性难以保证,而在倾向得分模型中引入权数获得f(t=1|x)的一致估计,在一定程度上能弥补由此造成的推断误差[6]。引入的方式可分为两种:一种是将权数作为协变量拟合模型;另一种是保留权数的原始含义,采用伪极大似然法进行估计。具体效果如何,将在模拟部分予以讨论。 (2)处理效应的估计 (14) (15) 利用权数构造双稳健估计,理论上能得到性质优良的估计结果。然而,实际情况更为复杂,具体应用效果如何需要从以下几个方面进行考察:第一,权数与因果推断的结合涉及样本选择机制和处理分配机制,影响二者的变量包含关系如何,是重叠还是独立,均有可能影响推断效果,实际中完整找到这两类变量并判断其关系并不容易,通过权数构造的双稳健估计能否在不同情况下保持优良性质有待研究。第二,由于无法得知真实模型,若倾向得分模型没有包含与样本选择机制有关的变量,或错误指定了模型形式时,设计权数的加入是否能弥补由此造成的误差值得探讨。第三,受资料的限制,研究中往往需要将两个不同调查的数据集进行融合分析,此时具有相同抽样权数的受访者不具有相同特征,利用权数构造双稳健估计的方法是否适用有待研究。下文的模拟研究将依据以上三点设计不同情形,对所提出方法的准确性和稳定性进行探究。 结合第三部分的分析,本部分通过设置不同情形模拟实际应用,探究前文所述方法的准确性和稳定性。 模拟样本的生成方式如下:假设总体共有10 000个单元,根据x划分为5层,每层2 000个;一维协变量x~N(0.25j-0.75,1),j=1,2,3,4,5,一维协变量z~N(0.5,0.5);潜在结果y0、y1服从正态分布,根据x生成y0~N(1+x,0.5),y1~N(y0+0.2+0.1x,0.5);t为是否接受处理的示性变量。样本由分层抽样得到,每层抽取的样本量分别为100、150、200、250、300。 为比较不同情况下权数对倾向得分法推断结果的影响,分别用符号s和符号t代表样本选择机制和处理分配机制,在以下五个不同s与t的关系下进行模拟。情形1,s与t均与x相关,这是较理想的情况,在控制x后,s与t的影响均得到控制,理论推断效果好;情形2,s与x无关,t与x有关,与情形1相同,理论推断效果好;情形3,s与z有关,t与x有关,此时倾向得分模型没有包含与样本选择机制有关的变量z,用以研究权数对由此造成误差的弥补情况;情形4,在已知t的情况下,s与x有关,t与x有关,人为将控制组的权数扩大1.8倍,处理组不变,使得两组中权数相同的单元特征及其在总体中的相对重要程度均不同,此情形用以研究来自不同调查的样本;情形5,s与t均与x相关,但形式不同,假设s与x呈线性关系,t与x呈非线性关系,此情形用以研究倾向得分模型识别错误时的估计效果。以上情形的具体生成形式见表1。 表1 样本选择机制和处理分配机制的生成 模拟部分根据利用权数构造的双稳健估计对ATE进行推断。对于倾向得分模型的拟合采用Logistic回归进行,为研究权数在倾向得分法中的效果,考虑如下四种方式:模型1,不进行倾向得分建模,直接比较两组结果变量的差异;模型2,根据协变量x拟合模型,不考虑权数的影响;模型3,将权数作为协变量,根据协变量x和权数d拟合模型;模型4,将权数作为样本单元相对重要程度的度量,可看作将样本单元做d倍的复制,根据协变量x拟合模型。此外,倾向得分模型仅涉及x项,不涉及x2项。预测模型采用线性形式,分别采用不考虑权数的极大似然法和考虑权数的伪极大似然法,拟合y~t以及y~(t、x)的关系。 模拟过程共进行1 000次重复试验,评价方法采用协变量的平衡性、估计值的均方误差根和真实参数的覆盖率。 通过倾向得分可平衡处理组和对照组的协变量,因此,对协变量的平衡性检验可以评价倾向得分模型的效果,不同情况下协变量的标准化均数差(SMD)的数值见表2。 表2 协变量平衡检查结果 由表2可见,倾向得分法有利于协变量的平衡;若倾向得分模型中未考虑权数,在一些情况下会使协变量的差异更大,甚至劣于不进行倾向得分建模(见情形5);若在倾向得分模型中将权数作为协变量使用,协变量得到了一定程度的平衡,但在样本选择机制和处理分配机制较复杂时效果一般(见情形3~5);若在倾向得分模型中将权数作为样本单元相对重要程度的度量,与其他方法相比,协变量的平衡性最好且效果稳定。 均方误差根可以综合评价方法的准确性,出于篇幅考虑仅展示部分结果,具体数值见表3。 表3 估计量的均方误差根 对比表3不同行的数据可知,总体而言,当预测模型不考虑权数时,估计值的均方误差根增大,推断效果变差(对比1~4行与9~12行)。比较不同预测模型自变量对估计的影响,当自变量是x、t时,估计值的均方误差根较小,推断效果更优(对比1~4行与5~8行),其原因是x、t可以更好地刻画待研究变量y的特征。当合理指定了预测模型且加入权数时(对应1~4行),不同倾向得分模型对均方误差根的影响不大,虽然不采用倾向得分模型的估计均方误差根不大(见1行),但其对协变量的平衡效果差,不符合因果推断的要求,此外,加入权数的倾向得分模型表现更稳定且相对更优(见4行);当预测模型的指定有所偏离但加入权数时(对应5~8行),采用加入权数的倾向得分模型进行估计,得到的估计标准误最小,推断效果最好且表现稳定(见8行)。 表4是估计量95%置信区间对真实参数覆盖率的部分结果,由于预测模型不使用权数的方法得到的预测准确度低且稳定性差,相关数据未予展示。 由表4可知,当倾向得分模型和预测模型均使用权数时,95%置信区间对真实参数的覆盖率最高,且在不同的样本选择机制和处理分配机制下表现稳定。 表4 真实参数覆盖率 模拟研究对前文的理论分析展开了进一步验证,分别将权数纳入倾向得分模型和预测模型,构造ATE的双稳健估计。通过设置不同情形研究估计量的性质,相关结论如下:第一,无论影响样本选择机制的变量与影响处理分配机制的变量是相互重叠还是彼此独立,利用权数构造的双稳健估计量均具有高的精确度;第二,当倾向得分模型在变量和形式指定上有所偏误时,设计权数的加入能够弥补由此造成的误差,提高推断效果;第三,对于不同来源的数据集,在数据融合后所述方法仍然适用且估计量性质稳定。 总体而言,在采用倾向得分法进行调查数据的因果推断时,应充分考虑调查设计对样本的影响,分别在倾向得分和处理效应的估计中加入权数,且保留权数的原本含义,体现样本对总体还原。据此方法得到的协变量平衡性最好,估计量的均方误差根更小,估计量更准确且表现稳定。 本文采用2017年CGSS(China General Social Survey)调查数据,进行处理效应的估计。CGSS调查始于2003年,是中国最早的全国性、综合性、连续性学术调查项目,全面收集了社会、社区、家庭、个人多个层次的数据,由中国人民大学调查与数据中心组织实施。调查的目标总体范围涵盖了全国31个省、自治区、直辖市(不含港澳台)的所有城市、农村家庭户,并通过分层三阶段抽样的方式获取了全国层面的代表性样本。 经济学中的人力资本理论将劳动者收入差异主要归结为劳动者人力资本的不同,教育水平是影响人力资本的重要因素。教育可以提高人的知识和技能,进而提高生产能力,增加个人收入,进一步使得个人工资和薪金结构发生变化,理论上来看,受教育程度与个人年收入之间存在因果关系[12],这也潜在影响了人口流动[13]。因此,实证部分对个人年收入和是否接受高等教育之间的因果关系进行研究。 选取来自CGSS调查的2 000个样本,个人年收入作为待研究变量,估计总体的平均处理效应(ATE),涉及的其他变量有性别、年龄、城乡划分、受教育程度、父亲受教育程度、母亲受教育程度、婚姻状况、政治面貌和民族等。样本中个人年收入的均值为996 930.5元,接受过高等教育的个人年收入均值为1 106 653元,未接受过高等教育的个人年收入均值为933 178.6元。倾向得分采用Logistic模型拟合。由于实证部分的目的并非研究个人年收入与其他变量的关系,因此为了对自变量的选择和模型形式的指定进行探讨,假定预测模型为线性形式,模型中仅包含协变量的一次项。 现估计教育造成的收入差异,受教育程度按照是否接受过高等教育划分处理组和对照组,其他变量作为协变量,分别采用四种估计方法检查协变量的平衡情况:方法1,不采用倾向得分模型且预测模型不加入权数,直接计算两组协变量的差异;方法2,不采用倾向得分模型但预测模型加入权数;方法3,采用不加入权数的倾向得分模型和加入权数的预测模型;方法4,采用加入权数的倾向得分模型和加入权数的预测模型。8个协变量平衡情况的具体结果见图1,8条折线分别代表8个变量对应的标准化均数差数值变化情况。 图1 协变量的平衡情况 由图1可以看到,整体来看采用方法4估计时处理组和对照组的协变量差异最小。四种方法下得到ATE的估计值及p值分别为46 219.286(p>0.5)、45 700.433(p>0.1)、37 023.474(p<0.001)、36 638.211(p<0.001)。可以看到,第一,不采用倾向得分模型会忽略其他因素对收入的影响,造成估计量被高估且不具有显著性,此时在预测模型建模时加入权数有利于改善估计效果。第二,在预测模型加入权数的情况下,倾向得分模型是否加入权数对估计的影响不大,估计量均具有高度显著性,但加入权数的倾向得分模型对协变量的平衡效果更好,因此有理由认为由该方法得到的结果可信度更高。第三,综合考虑协变量的平衡性和估计量的显著程度,本例表明应同时在倾向得分模型和预测模型中引入权数。采用不同方法进行因果推断会得到不同的结果,未平衡混杂变量或未合理使用权数均会造成估计值的偏离,在实际研究中应充分考虑抽样设计对样本造成的影响,将权数引入推断的各个过程。 基于设计和基于模型的推断各有优劣。基于设计的推断理论完善,但它仅根据一次抽样结果进行推断,受到样本量、非抽样误差和总体分布等因素的影响,估计效率较低;基于模型的推断则能根据实际情况选用不同模型,更充分地利用各类辅助信息,提高估计效率,但对于模型识别较敏感。实际抽样调查多采用复杂抽样,基于模型的推断在复杂样本中具有更重要的现实价值,它能更好地利用先验信息和辅助信息,解决如小样本推断、小域估计、误差分析和缺失值处理等实际问题,因此具有更广泛的应用前景。 本研究从因果推断入手,尝试将基于设计与基于模型推断结合,通过引入权数提高基于模型推断的准确度和稳定性,提出了利用权数构造双稳健估计的方法。结合理论分析与模拟研究,指出应将设计权数同时加入倾向得分模型和预测模型中,具体优势体现在以下几点:第一,在该方法下协变量的平衡性最好;第二,通过该方法估计的处理效应均方误差根最小,准确度最高;第三,该方法效果稳定,即使倾向得分模型在变量和形式指定上有所偏误,该方法仍能得到准确度高的估计结果。实证部分将所述方法应用于收入的推断中,对不同方法的估计效果进行了分析,这为其他社会科学领域进行因果关系研究提供了参考价值,具有较大的现实意义。值得一提的是,对于不同来源的数据集,在数据融合后所述方法仍然可行且推断效果好,由此拓展了各类调查数据的使用范围,使得一些科学研究成为可能。事实上,不仅是因果推断,凡是基于调查数据的问题研究,研究者都应对抽样设计的影响予以重视,尝试将权数纳入分析。 两种推断途径的结合有利于发挥各自的优点,既能实现样本对总体还原,又能综合各方面的信息提高估计效率,灵活解决各种推断问题,还能提高估计的稳健性。本文的讨论仅以因果推断为切入点,作为此类研究的一个范例,对于如何在其他具体问题中将基于设计和基于模型相结合,达到更好的估计效果,还存在广泛的探讨空间。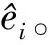
(二)权数的功能

(三)权数的使用
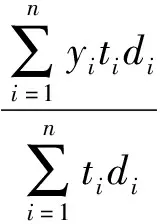
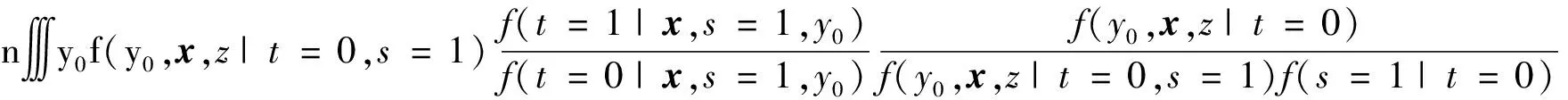

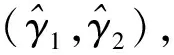

四、模拟研究
(一)数据生成与模型设置

(二)模拟与结果分析


(三)总结评价
五、实证分析
六、讨论
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
今日农业(2020年23期)2020-12-15 03:48:26
统计与信息论坛(2020年5期)2020-06-03 06:57:04
证券市场周刊(2019年25期)2019-08-16 01:27:48
证券市场周刊(2019年26期)2019-07-20 10:00:48
中国外汇(2019年6期)2019-07-13 05:44:06
统计与决策(2018年23期)2018-12-21 07:14:20
中学生数理化·高一版(2017年2期)2017-04-25 13:22:36
现代营销·学苑版(2016年12期)2017-01-23 13:00:14
电测与仪表(2015年6期)2015-04-09 12:00:50
