
基于深度强化学习与自学习的多无人机近距空战机动策略生成算法
2022-03-23 07:27孔维仁周德云赵艺阳杨婉莎
控制理论与应用 2022年2期
孔维仁 ,周德云 ,赵艺阳 ,杨婉莎
(1.西北工业大学电子信息学院,陕西西安 710129;2.悉尼大学计算机学院,悉尼2006)
1 引言
随着无人机技术在军事领域的发展,无人战斗机在战场上的作用越来越重要[1].然而,单架无人机所能完成的作战任务受到了很大约束.为了适应更加复杂军事任务的需要,多无人机智能化空战机动决策逐渐成为军事领域的研究热点.鉴于空战机动在战争发展进程中的重要地位,2020年8月,DARPA公布了名为AlphaDogfight Trail计划的最后一场比赛,且由苍鹭系统公司大比分获胜[2].该项目主要研究空战机动智能算法,以及如何将研究成果扩展至未来空战.该项目对于实现智能化作战和人机混合的智能作战系统具有重要意义.
自19世纪60年代以来,学者对无人机自主空战机动决策进行了大量的研究,并取得了一些显著的研究成果[3].本文把这些成果大致分为两类:基于对策论的方法与基于人工智能的方法.
在基于对策论的方法中,包括矩阵对策法[4-6]、影响图法[7-9]、微分对策法[10-12]等.这些方法在一定程度上为空战决策提供了有效的解决方案,但也有较大的局限.例如矩阵对策法得到的策略偏保守,且随着模型的精度增高,计算量会急剧上升;影响图法将空战建立为一个影响图,影响图可以反应出空战双方状态与决策的影响关系,如文献[8]给出了一对一空战机动决策问题的影响图,该图可以将空战这个动态连续的序贯决策问题转换为一个多阶段决策问题,并使用滚动时域控制等方法进行求解,然而对于可变规模多对多空战各无人机的状态变化对局部态势和全局态势的影响是很难评价的,所以影响图的建模是非常困难的;对于微分对策法,首先该算法需要精确的数学模型,计算量大,且该算法只能解决单纯的追逃问题,然而空战态势瞬息万变,随时可能改变攻防关系,需要多个模型进行交替切换,若将该方法运用到多对多空战机动决策问题上,所需的模型的种类和切换次数将会成指数型增加.
在基于人工智能的方法中,包括专家系统法[13-15]、人工神经网络法[16-18]、深度强化学习法[19-24]等.这些方法可以一定程度解决基于对策论方法中依赖精确模型、实时性等问题,但也有较大的局限.例如专家系统法依赖专家构建知识库,知识的更新难以满足实时性要求.人工神经网络法需要大量的空战样本,且需要大量的人工标注.深度强化学习方法解决无人机机动决策问题是当前研究的热点,文献[19]将空战机动决策问题转化为马尔可夫决策过程,并使用深度Q网络算法求解出了单机空战机动策略;文献[20]在文献[19]的基础上引入了逆强化学习算法来估计更准确的回报函数;文献[21-23]将空战机动决策问题转化为马尔可夫博弈,使用多智能强化学习结合最大最小博弈、自学习、机动预测等方法来获得均衡的机动策略.深度强化学习法虽一定程度上满足智能化空战机动决策的要求,但与理想效果还相差较远,主要体现在:
1) 使用强化学习框架主要解决一对一空战机动决策[19-24].
2) 给定了对手的运动规律或机动策略,使学习得到的空战策略只针对固定机动策略[19-20,24].
3) 假定敌我双方的运动状态是完全已知且准确的[19,21-24].
针对上述强化学习方法的技术难点,本文以多无人机近距空战为研究对象,探讨多无人机在近距空战中的智能化空战机动决策生成方法,基于强化学习框架设计一种适用于无人机规模可变的多无人机机动决策策略生成算法-参数分享的深度Q网络算法(parameter sharing-deepQnetwork,PS-DQN).参数分享是指各个Agent共用一个Q值网络参数,通过设计Agent的状态空间来使Agent协作完成任务.
本文选择使用参数分享的深度Q网络算法的主要原因有两点:1) 对于多无人机近距空战机动决策问题,认为各无人机是同构的,即各无人机的性能参数均相同,故具备多个Agent公用一个Q值网络的条件;2) 由于多无人机空战的特点,无人机初始数量不固定,而且在空战过程中也会出现损失,Agent的数量是动态变化的,由于Agent个数动态的不确定性,导致分布式多智能体强化学习不适合此场景,参数分享深度Q网络算法由于只存在一个Q值网络,故天然适用于此场景.
随后,通过设计Agent的状态空间,使Agent提取附近友方与敌方无人机的态势特征,从而使多无人机拥有进行合作空战所需的必要信息;该状态空间可以部分解决难点3,只需在一定范围内给出双方准确的运动状态;同时,为解决难点2,本文使用虚拟自我对局(fictitious self-play)使在不给定敌方机动决策的情况下迭代的增强空战机动策略的智能水平,并收敛到纳什均衡策略.
2 多无人机近距空战问题描述与建模
2.1 多无人机近距空战描述
多无人机近距空战的目的是通过编队内无人机的协作在保证己方编队损失最小的情况下,尽快歼灭敌方无人机编队.本文将多无人机近距空战建模为一个混合马尔可夫博弈(mixed Markov game),将每一个无人机作为博弈中的一个Agent.将空战编队双方分为红方(己方)和蓝方(敌方)分别采用集合R和B表示.为了方便对多无人机近距空战建模与生成机动决策,本文提出以下假设.
假设1在编队内部,每架无人机可以与一定范围内的无人机进行无延时通信.
假设2每架无人机可以探测到一定范围内的敌方无人机的准确位置.
假设3所有无人机均在同一高度机动飞行[23-25].
本文红蓝双方战机采用文献[25]中开发的一种模拟无人机的动力学方程,在惯性系下构建无人机的运动模型.每架无人机的运动状态由位置(x,y)、速度v、航迹偏角ψ、滚转角φ与滚转角变化率定义为

其中(ut,u˙φ)为无人机的切向与法向控制量.
2.2 多无人机近距空战建模
2.2.1 状态空间设计
本文提出的PS-DQN算法使Agent共用Q值网络,则应保证每个Agent的状态向量维度相同;同时Agent的状态不仅需要反映出自身无人机的运动状态,而且还需反映出友方无人机与敌方无人机的信息.这样才可以保证多个Agent共用Q值网络且可以学习出协同策略.按照上述设计思路,将Agent的状态空间S分为3个部分:当前空战态势信息Sc,上一步空战态势信息Sp与上一步无人机动作ap

其中:|R|,|B|分别表示现存的我方与敌方无人机数量.由于与的设计思路相同,现以为例描述其设计思路.为可以使用固定维度的向量来描述友方无人机信息,首先,本文根据无人机的速度方向,将无人机所处的平面平均分为6个区域,如图1所示.本机相对于任意无人机的方位关系均可以归纳为双方划分的6个区域内,即共有36种方位关系.然后,为每一种方位关系设计一个4维向量用于表示友方无人机的位置信息
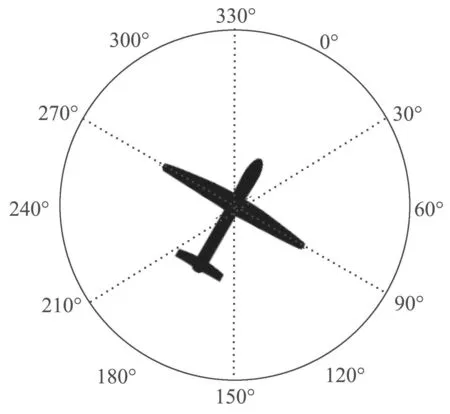
图1 无人机空间划分Fig.1 UAV space division

其中:c表示在区域内的友方无人机个数,dsum表示归一化距离总和,dmax表示归一化距离最大值,dmin表示归一化距离最小值.归一化距离dnorm为
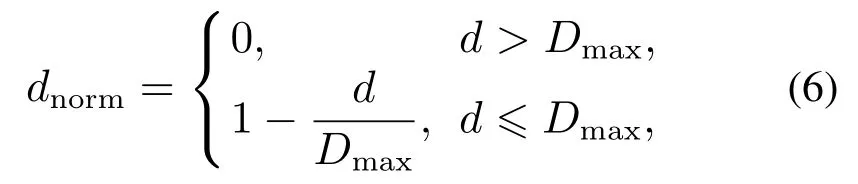
其中:d为双机距离,Dmax为最大通信(攻击)距离.友方态势信息共有144维,同理敌方态势信息共有144维.所以,当前状态信息Sc共有295维.上一步态势信息Sp储存上一时刻的空战态势信息,故与Sc结构相同;上一步无人机动作ap为独热编码(one-hot),储存该无人机上一时刻的动作,无人机的动作空间在第2.2.2节中定义.
本文考虑到,S维度过高且与稀疏程度较高,故采用自编码器(autoencoder)对S进行降维,具体方法将在第3.1节中阐述.
2.2.2 动作空间设计
在多无人机近距空战中,无人机动作空间是连续的,分别为无人机的切向控制量ut和法向控制量u˙φ.为了满足DQN算法框架,本文将无人机动作空间离散化,按照美国国家航空航天局(NASA)学者设计的基本机动动作库[26]并结合假设3设计了5种机动动作,分别为匀速直飞、最大加速直飞、最大减速直飞、最大过载左转与最大过载右转.5个机动动作与控制量的映射关系如表1所示.其中:的最大值与最小值,的最大值.

表1 机动动作库Table 1 Maneuver library
2.2.3 奖励函数设计
强化学习算法框架利用Agent与环境交互获得奖赏信息,根据最大奖赏原则选择动作,得到最优策略.奖励函数为强化学习Agent提供了有用的反馈,对策略学习结果有显著影响[27].本文将奖励函数定义为

其中:Rr为真实奖励函数,Rg为全局奖励函数,Rl为局部奖励函数,ne为第ne个训练周期(episode).真实奖励函数Rr是描述空战的最终结果,它真正表明了多无人机近距空战的目标.然而Rr是一个非常稀疏的奖励函数,这样的奖励函数学习到有效的空战机动策略是非常困难的[28],因此,本文通过设计Rg与Rl对真实奖励函数进行了奖励塑造(reward shaping).λ(t)是一个随着训练周期的增加而逐渐减小的因子,它的目的在于在强化学习训练初期按照Rg与Rl的指导快速的学到有效的空战机动策略,同时在强化学习训练后期按照Rr的指导使无人机完成真正的空战目标.λ(ne)的表达式为

1) 真实奖励函数设计.
根据多无人机近距空战的目的,设计真实奖励函数Rr:
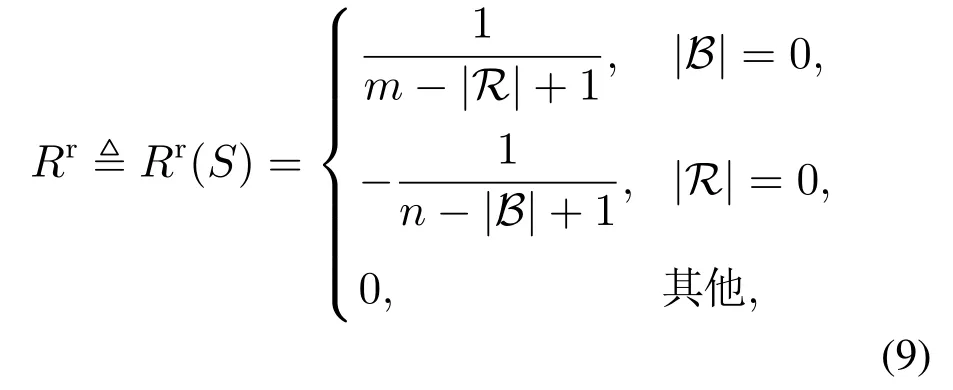
其中Rr表示当多无人机空战结束后,若我方无人机获胜,则根据我方的损失程度得到一个正的奖励值;反之,根据我方的损失程度得到一个负的奖励值.当多无人机空战正在进行,则奖励值一直为0.
2) 全局奖励函数设计.
全局奖励函数Rg反映了多无人机空战全局的战损信息,对于整个编队无人机接收到的奖励值都是相同的,其形式为

从Rg中可以看出,在多无人机空战时,我方无人机损失越少,敌方无人机损失越大,则奖励值越大,反之越小.并且当多无人机空战结束后,Rg等于Rr.
3) 局部奖励函数设计.
局部奖励函数Rl反映了多无人机空战中各无人机的局部战场信息,本文参考文献[25]中定义的局部态势,且不考虑格斗导弹的前向攻击能力.我方无人机取得优势需要满足3个条件:
1) 双机距离d小于等于Dmax.
2) 我方无人机视界角在指定视界范围内,本文设置为30°.
3) 我方无人机的天线偏转角在指定天线偏转角范围内,本文设置为30°.
根据上述空战局部态势优势满足条件,设计局部奖励函数Rl:

其中:|B|head为图1中无人机头部区域中敌方无人机个数,|B|tail为图1中无人机尾部区域中敌方无人机个数.从Rl中可以看出,当无人机在局部态势中处于优势,Rl越大,反之,Rl越小.
3 多无人机近距空战机动决策生成算法设计
3.1 状态空间自编码器设计
多无人机近距空战机动决策生成算法的第1步是收集数据来训练自动编码器(autocoder).在第2.2.1节中,作者设计了多无人机空战的状态空间.然而,状态空间的维度过高,这将会使训练强化学习Agent昂贵且耗时[29].
自动编码器是一种基于人工神经网络(artificial neural network,ANN)的特征表达网络,用于将高维数据压缩成小的潜在表示(latent)[30].本文设计为3层神经网络结构,包括编码器和解码器两部分,其中,编码器完成从输入信号到输出表征的映射转换,解码器实现输出表征逆向映射回输入空间,获取重构输入.根据第2.2.1节可知,编码器的输入输出维度为144;本文选取Sigmoid函数作为激活函数.自动编码器的训练过程即为最小化重构误差函数JAE的过程,其表达式为

其中:p为输入样本的个数;λ为L2正则化系数,用于减少权重的大小来防止过拟合;JAE中的第1项为误差项平方和均值,第2项为正则化项.
3.2 参数分享深度Q网络算法(PS-DQN)
3.2.1 算法描述
为使无人机编队生成合理的近距空战机动策略,本节提出参数分享的深度Q网络算法(PS-DQN)用于求解混合马尔可夫博弈模型,得到合理的多无人机近距空战机动策略.
PS-DQN算法整体框架图如图2所示,该算法整体框架共包含2个部分:Q网络训练部分与多无人机空战仿真部分.多无人机空战仿真部分用于仿真多无人机空战场景;Q网络训练部分是PS-DQN算法的核心部分,它由两个Q值网络和一个经验回放记忆池(experience replay memory)组成.从图2可以看出,我方无人机均使用同一个Q值网络进行机动策略的获取与更新,我方所有无人机共享Q值网络的参数.
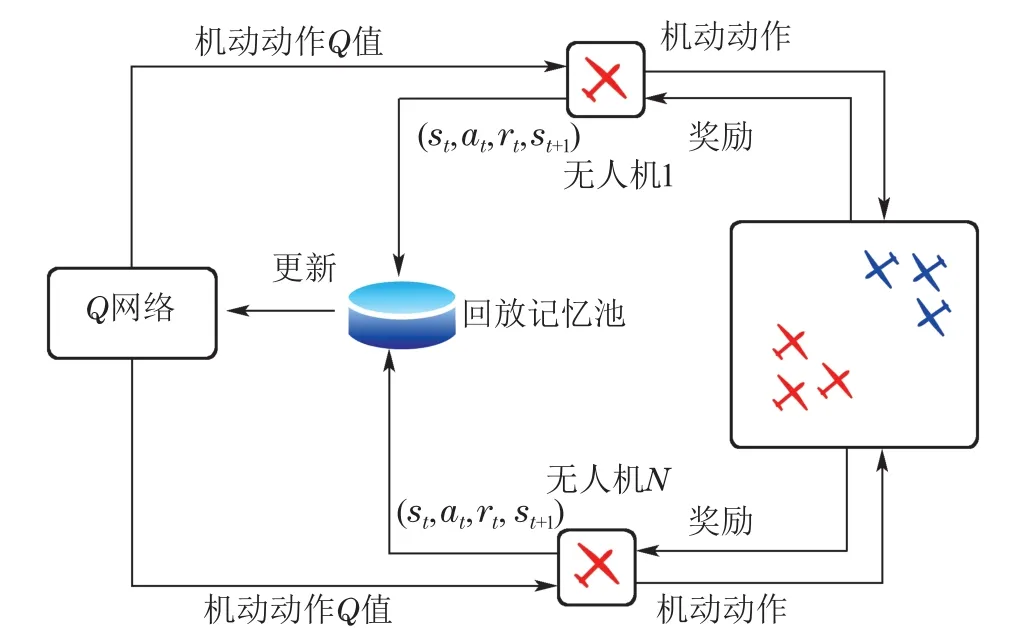
图2 PS-DQN算法整体框架图Fig.2 PS-DQN algorithm diagram
3.2.2 PS-DQN原理与算法步骤
强化学习是一个反复迭代的过程,每一次迭代要解决两个问题:给定一个策略求取Q值函数,根据Q值函数来更新策略.在环境中的Agent的目的是最大化长期未来奖励,为得到每个状态下执行每个动作后所得到长期未来奖励,定义状态-动作值函数Qπ(s,a)

其中:π为Agent的策略函数,它可以为随机性或者确定性函数.γ为折扣系数,取值区间为[0,1].对于多无人机近距空战场景,在式(14)中,s和a的取值空间已分别在第2.2.1节与第2.2.2节给出.得到状态-动作值函数Qπ(s,a)后,得到相应的贪婪策略π(s)

深度Q网络是基于深度学习与强化学习思想而提出的机器学习方法[31-32].使用神经网络(Q网络)对Q值函数进行近似表达.本文采用全连接神经网络对Q值函数进行拟合.Q网络的输入层接受由第2.2.1节设计出的特征状态或自动编码器压缩后的特征状态(在第4.1节进行对比实验),与当前时刻无人机的动作,输出层输出对应的Q值.PS-DQN算法的损失函数可表示为
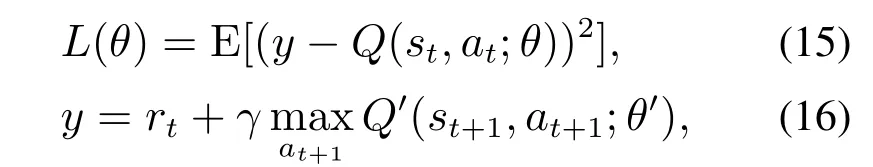
其中:Q(st,at;θ)为估值Q网络,θ为估值Q网络的参数;Q′(st,at;θ′)为目标Q网络,θ′为目标Q网络的参数.PS-DQN算法步骤在算法1中给出.
算法1PS-DQN算法.


3.3 神经网络虚拟自我对局
3.3.1 算法描述
由于将多无人机近距空战机动决策问题建模为马尔可夫博弈问题,若将敌方无人机编队建模为交互环境的一部分,会造成第3.2节提出的强化学习算法训练过程不稳定[33];若设定敌方无人机编队为基于规则的机动策略,则无法保证得到的空战策略收敛到纳什均衡策略[34].
为获得多无人机近距空战机动决策问题的纳什均衡策略,本文引入神经网络虚拟自我对局(neural fictitious self-play,NFSP)方法作为策略生成的主框架[35].虚拟自我对局(fictitious self-play,FSP)是一种被证明在二人零和博弈中可以收敛到纳什均衡的机器学习算法.在FSP的学习过程中,两个玩家通过相互博弈不断优化各自的博弈策略,最终得到纳什均衡策略.对于多无人机近距空战机动决策问题,敌我双方使用相同的策略更新方法,故以我方无人机编队为例,给出NFSP算法框架图如图3所示.
3.3.2 NFSP算法原理与算法步骤
从图3中可以看出,敌我无人机编队均拥有两套空战策略:对于对手的最优反应策略B以及自己的平均策略Π,且使用神经网络来拟合最优策略以及平均策略.无人机编队的行动策略σ是通过对最优反应策略与平均策略按照η的概率选取,即

图3 PS-NFSP算法整体框架图Fig.3 PS-NFSP algorithm diagram

η ∈(0,1)称为预测参数(anticipatory parameter).每当无人机编队依据其行动策略采取动作并获得空战环境的反馈后,将记忆片段
对于通过模仿学习算法得到平均策略的目标是保持一个过去迭代轮的最优反应策略的平均混合策略组:
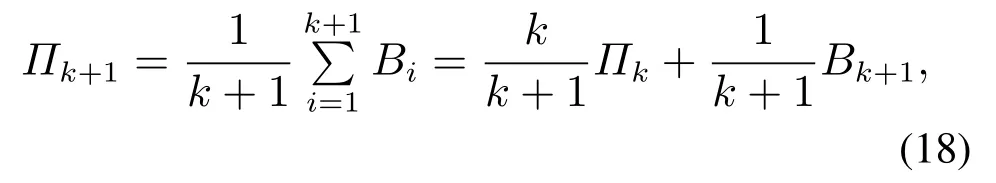
Πk和Bk+1分别表示上一轮(第k轮)迭代的平均策略与当前轮(第k+1轮)迭代的最优反应策略.通过上式看出当前轮的平均策略可以通过所有轮的最优反应策略进行均匀采样进行获得.这也是模仿学习记忆池只储存最优反应策略采样记忆片段的原因.
由于模仿学习记忆池是通过所有轮的最优反应策略采样进行增量更新的,为了构建一个最优反应的平均策略的无偏估计,需要从每一轮的最优反应策略中抽样相同数量的片段.故使用蓄水池抽样[36](reservoir sampling)的方式随机的从模仿学习记忆池中采样训练数据进行模仿学习.模仿学习算法本质为监督学习算法,是使用神经网络对平均策略函数进行拟合的过程.模仿学习算法步骤在算法2中给出.
算法2模仿学习算法.
Input:平均策略网络Π(S,a;θΠ),学习速率α,模仿学习记忆池DSL,batch规模Nbatch.
1) 在DSL中进行蓄水池采样Nbatch大小的batch:
2) 构造误差函数-logΠ(S,a;θΠ),并对θΠ使用mini-batch梯度下降法进行更新,学习速率为α.
根据上述NFSP算法原理,在算法3给出NFSP算法步骤.
算法3NFSP算法.

4 仿真实验与分析
4.1 空战仿真平台搭建
本文空战仿真平台采用Python 3编程语言,基于OpenAI团队开发的gym强化学习环境开发包进行开发[37],该仿真平台能够在一定的空域内仿真多无人机近距空战.对于每架无人机,平台采用式(1)的微分方程组来解算每架无人机的运动状态,同时仿真平台收集所有无人机的运动状态计算在第2.2.1节中提出的状态向量,并分发给每架无人机,作为该无人机当前的空战状态.
本仿真平台中,假设红蓝编队处于同一高度水平,无人机的空域范围设置在5 km以内,假定各架无人机机动能力相同,且最小速度为100 m/s;最大速度为300 m/s;最大通信距离为5 km;最大探测距离为2 km,滚转角变化率为40(°)/s.每个仿真步长代表0.15 s且最大仿真时间为20 s.由于本空战仿真平台没有对近距格斗导弹进行建模与仿真,故本平台对于击落的判别方式为满足第2.2.3节给出的稳定跟踪条件且持续3个仿真步长.
4.2 自编码器latent维度选择实验
4.2.1 实验设计
在第3.1节中,提出了使用状态空间自编码器来降低状态空间维度,以加快空战策略学习速率.本节将选取不同latent维度:8,16,32和64维,用来考察不同latent维度对原始状态的表示精度,并选取合理的latent维度.
在本实验中,双方无人机使用随机策略,通过对不同规模空战仿真进行随机采样,得到40000组空战状态.其中,30000组空战状态作为训练集,剩余10000组空战状态作为测试集.空战规模有:1v1,2v2,4v4,4v2这4种.使用pytorch对自编码器进行实现,采用Adam优化算法[38]进行训练,学习速率α为0.01,β1为0.9,β2为0.999.迭代次数选为30000,batch大小为64,在采样的时候对数据进行打乱,用于消除batch内数据之间的相关性.
4.2.2 实验结果与讨论
算法训练过程中的损失变化图如图4所示,横坐标为训练步数,纵坐标为自编码器每次训练的损失,可以看出随着训练步数的增加,训练损失逐渐下降最终收敛趋近于稳定,说明自编码器训练收敛.通过观察不同latent维度收敛到的训练误差可以发现,当latent维度为32与64时,收敛后的训练误差在误差范围内是相同的.说明latent为32维时,latent就足以表示144维的原始空战状态.

图4 自编码器训练损失变化图Fig.4 Autoencoder training loss diagram
现使用测试集中的任意空战状态输入到训练完成的latent维度为32的自编码器中,得到的编码平均误差为0.031,与训练集的误差相似,说明未出现过拟合现象.以某一空战状态为例,原始空战状态与通过自编码器解码的空战状态对比图如图5所示.
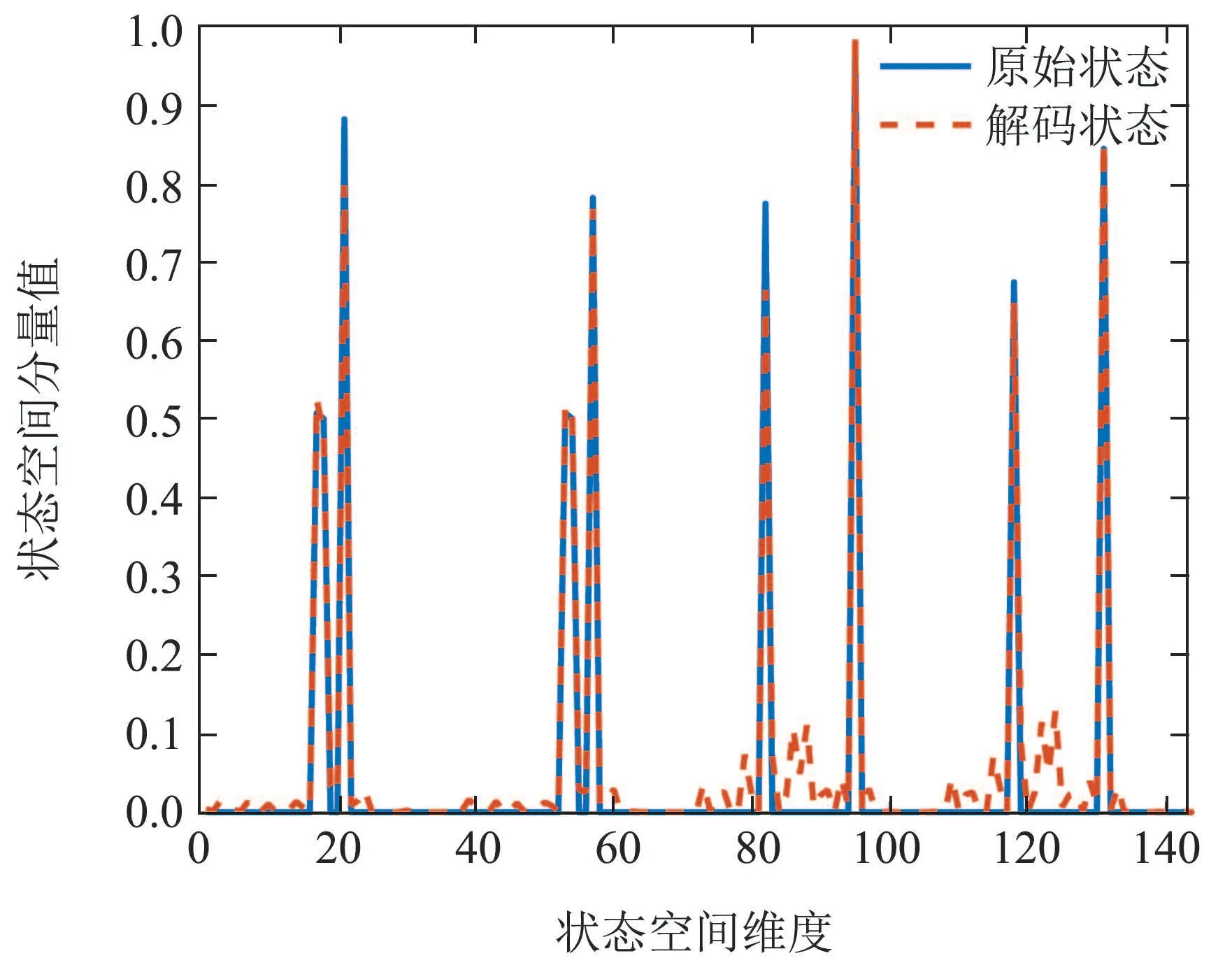
图5 原始状态与自编码器解码状态对比图Fig.5 The diagram comparising original state and autoencoder decoding state
从图5中发现,原始空战状态有稀疏的特性,且自编码器解码的空战状态可以很好的的反映出原始空战状态不为0的分量,平均误差在0.1以内,足以满足空战机动策略生成算法所需要的精度.
4.3 策略生成算法训练实验
4.3.1 实验设计
本节对提出的空战机动策略生成算法的训练过程进行实验,研究引入自编码器与神经网络虚拟自我对局对PS-DQN算法训练效果的影响.故本节设计3个训练算法进行对比:
算法1假定敌方无人机编队为贪婪策略,引入自编码器的PS-DQN算法.
算法2引入神经网络虚拟自我对局,不引入自编码器的PS-DQN算法.
算法3同时引入神经网络虚拟自我对局与自编码器的PS-DQN算法.
本节将从两个方面分析PS-DQN算法的训练效果,首先通过对比3个算法策略的可利用性(exploitability)[39]来研究策略是否收敛到纳什均衡策略,用以判断引入NFSP是否可以改善策略的可利用性,然后对比算法2-3的平均策略网络训练的收敛情况,用以判断引入自编码器是否可以加快策略收敛的速度.策略可利用性是用来衡量当前双方策略是否达到纳什均衡的指标,计算方法为
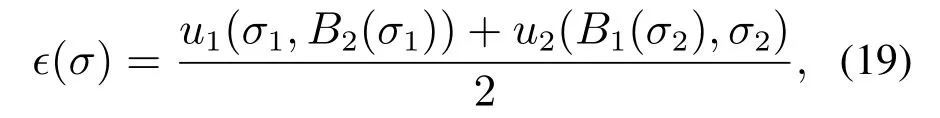
u1(σ1,B2(σ1))为我方采用当前策略σ1,对方使用针对我方当前策略的最优反应策略B2(σ1)所得到的真实奖励(式(9)所示).从上式可以看出,若双方策略达到纳什均衡,ϵ(σ)值为0;相反,若双方背离纳什均衡策略,则ϵ(σ)越大.故策略的可利用性是衡量双方策略是否达到纳什均衡的指标.
整体仿真实验参数设置:采用4v2的空战规模,初始无人机运动状态随机;仿真步数设置为 200000;强化学习与模仿学习记忆池规模为 100000;预测参数η为0.1;网络训练开始时的步数为1000;单次episode最大步数为150.PS-DQN算法参数设置:采用4层全连接网络作为Q网络,使用Dueling网络结构[40],2层隐藏层节点个数分别为128,64;Q网络学习速率为0.001;折扣系数γ为0.95;探索概率ϵ为动态衰减因子,初始为1.0,终止为0.001;目标网络更新周期为1000.模仿学习算法参数设置:模仿网络采用4层全连接网络,两层隐藏层节点个数分别为60,30,输出层为softmax层;网络学习速率为0.001.
4.3.2 实验结果与讨论
平均策略网络训练过程中的损失变化图如图6所示,由于算法1只有Q网络,故图中只有算法2-3的平均策略网络损失变化图.在图中,横坐标为训练步数,纵坐标为平均策略网络每次训练的损失,可以看出随着训练步数的增加,训练损失逐渐下降最终收敛趋近于稳定,说明平均策略网络收敛.对比算法2与算法3的收敛曲线,可以发现算法3相比于算法2有更快的收敛速率,说明引入自编码器可以改善空战机动策略的学习效率.
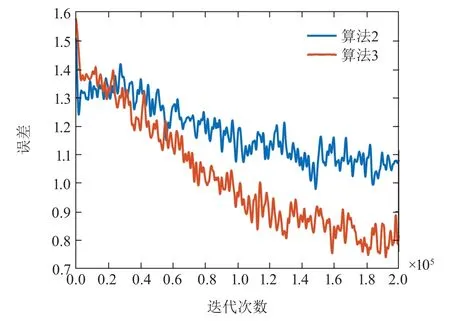
图6 平均策略网络训练损失变化图Fig.6 Average policy network training loss diagram
3个算法平均策略可利用性的变化过程如图7所示.训练初期,3个算法的平均策略可利用性在0附近震荡,这是由于在训练初期最优反应策略网络与平均策略网络无法提供准确的策略,使双方均无法进行有效的攻防,双方均无战损;训练中期,3个算法的平均策略可利用性均上升,这是由于平均策略网络平均的最优反应策略过少,而导致平均策略网络无法反应出真实的平均策略,然而这时最优反应策略对平均策略有较好的针对性,故此时的策略可利用性逐渐增加;训练后期,算法2-3的策略可利用性逐渐减小,且收敛到0附近,这说明双方的平均策略逐步趋近于纳什均衡策略,算法1的策略可利用性依然增大,这是由于敌方策略为贪婪策略,导致我方策略收敛至针对贪婪策略的最优策略,然而该策略是与纳什均衡策略相背离的,故策略可利用性依然增大.同时通过对比算法2-3的策略可利用性变化曲线可以发现,算法3的策略可利用性峰值与收敛速度均好于算法2,这说明引入自编码器确实有益于策略的学习效率.
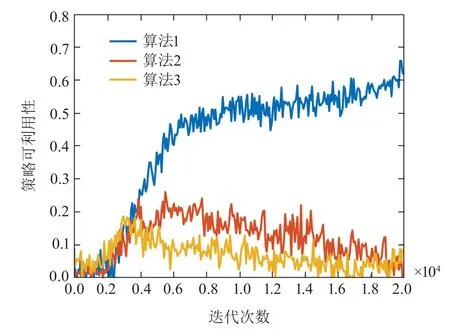
图7 平均策略可利用性变化图Fig.7 Exploitability of average policy diagram
4.4 机动策略合理性与迁移性实验
4.4.1 实验设计
本节对使用算法3得到的多无人机近距空战机动策略的合理性与迁移性进行实验,对于策略有效性,本节首先使用两个双机编队在近距空战空域内对抗一个双机编队,且双方为迎头的均衡态势,如图8(a).该空战规模与策略生成算法训练实验相同.该实验将给出该空战想定下的整体无人机机动过程,用于分析空战机动策略是否合理,是否符合基本的空战原则[41].随后,验证空战规模为1v1,2v2,4v2,4v4下的多无人机近距空战机动策略的合理性,即机动策略的迁移性实验.此外,由于1v1空战的基础性与特殊性,本实验也将给出1v1空战的整体无人机机动过程,用以直观的分析空战机动策略的迁移性.
4.4.2 实验结果与讨论
4v2空战机动过程如图8所示,空战初始红方有两个双机编队呈平行态势,蓝方有一个双机编队,双方为迎头的均衡态势.在空战进行0 s至4 s之间,双方战机均选择正面接敌,进入1 km2内的空域内进行缠斗(图8(a)).空战进行4 s至8 s之间,红方1,2,3号无人机进行大过载右转试图稳定跟踪蓝方编队的尾部,以锁定并构成攻击条件,同时红方4号无人机进行加速直飞用于诱敌与后续包夹,此时蓝方编队合力追击红方4号无人机,意在锁定红方4号无人机(图8(b)).空战进行8 s至12 s之间,红方红方1,2,3号无人机成功锁定蓝方2号无人机并满足攻击条件,进而歼灭蓝色2号无人机,红方4号无人机进行大机动左转试图摆脱蓝方1号无人机的追踪,蓝方1号无人机由于目标的大机动导致脱锁(图8(c)).空战进行12 s至20 s之间,由于红方态势占绝对优势,故蓝方1号无人机实施连续的S形机动试图脱离红方无人机编队的追击,红方编队各无人机从多个角度追击蓝方无人机并最终成功击落(图8(d)).

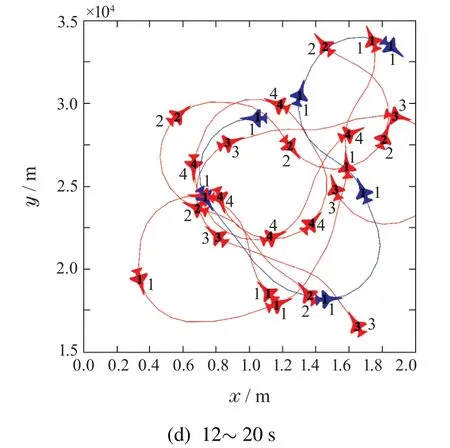
图8 4v2空战机动过程图Fig.8 Maneuver process diagram of 4v2 air combat
从4v2空战整体过程可以看出,双方的机动动作是可以被直观解读的,这说明得到的空战机动策略是合理的.
1v1空战机动过程如图9所示,空战初始红蓝双方为迎头的均衡态势,双方无人机在4 s后形成互相“咬尾”的缠斗模式,一直往复下去.这在1v1空战实战中是非常常见的,只是由于模型的简化,没有势能的损耗而导致的高度下降.从1v1空战整体过程可以看出,双方的机动动作是可以被直观解读的,说明空战机动策略迁移至1v1空战场景也是有效的.
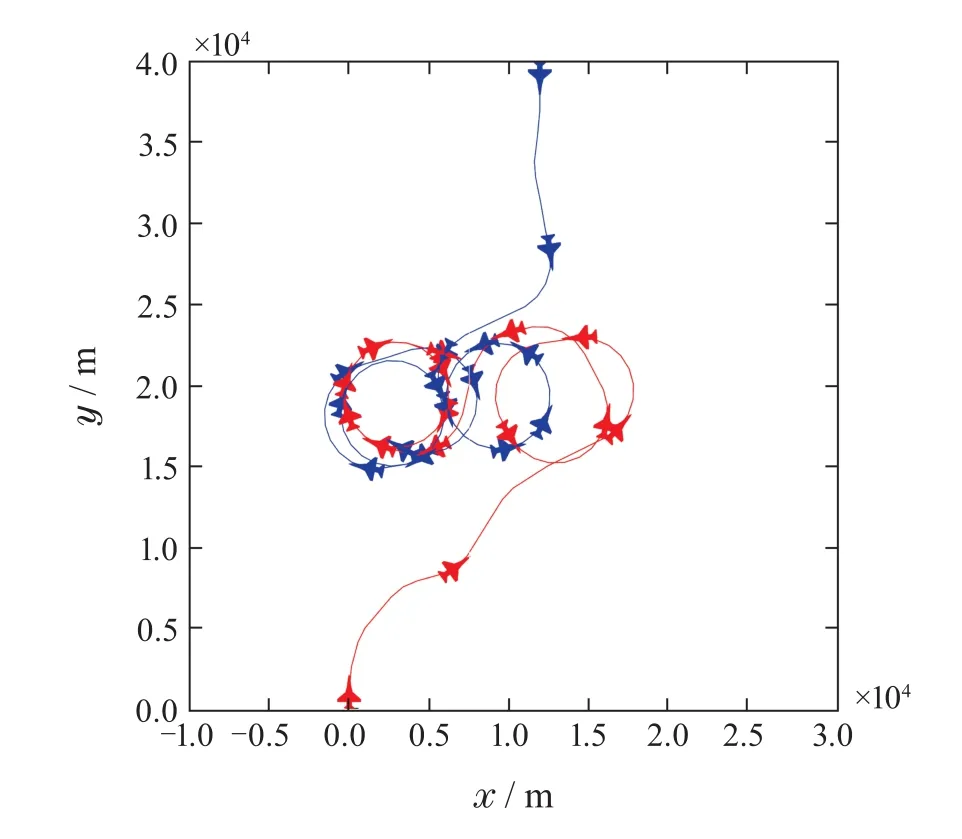
图9 1v1空战机动过程图Fig.9 Maneuver process diagram of 1v1 air combat
随后对空战规模为1v1,2v2,4v2,4v4下的多无人机近距空战分别进行了1000次的对抗仿真,初始空战态势随机,得到以红方视角的空战结果如表2所示.
从表2中可以看出,对于双方无人机个数相同的空战仿真结果是对称的,说明双方的平均策略拥有达到了均衡的必要条件,且均可以有效的歼灭对手.这说明得到的策略迁移到不同空战规模均是有效且合理的.对于4v2的空战规模,红方4机无人机编队明显优势于蓝方的双机编队,这与实际空战相符.

表2 不同空战规模下的多无人机近距空战结果Table 2 Air combat results under different air combat scales
5 结论
本文采用深度强化学习与自学习相结合的技术,提出了一种解决多无人机近距空战机动决策问题的算法.该算法允许所有编队中的无人机共用一个Q网络来使算法满足在不同无人机编队规模下具有良好的迁移性.同时,引入了自编码器与神经网络虚拟自我对局机制,使算法可以高效率的学习到达纳什均衡的无人机空战机动策略.
目前本文通过空战仿真实验验证了算法的可行性,下一步的工作将加入高度影响将仿真环境从二维拓展到三维,并考虑雷达和武器情况做现代空战的研究,使算法适应更加复杂的战场环境.
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
小哥白尼(军事科学)(2022年1期)2022-04-26
科学技术创新(2021年5期)2021-03-17
装备制造技术(2020年3期)2020-12-25
——编码器
演艺科技(2020年7期)2020-08-13
当代陕西(2019年12期)2019-07-12
汉语世界(The World of Chinese)(2019年1期)2019-03-18
军营文化天地(2017年6期)2017-06-28
探测与控制学报(2015年4期)2015-12-15
百科探秘·航空航天(2015年10期)2015-11-07
