
基于RCBAM 和SSD 的特征融合低照度环境目标检测算法研究
2022-03-21 10:59常亮白傑黄李波
北京理工大学学报 2022年3期
常亮,白傑,黄李波
(1. 同济大学 汽车学院,上海 200082;2. 中国科学院 微小卫星创新研究院,上海 201210)
近年来,随着计算机视觉与智能驾驶技术的快速发展,一系列基于卷积神经网络的感知算法被提出[1−3],极大提高了智能驾驶汽车的感知性能. 由于光学相机易受到天气与光照等影响,在面对一些雨雾等恶劣天气、低光照以及远处小目标检测的场景时,仅依靠图像的感知系统会存在大量的漏检和误检;而毫米波雷达在恶劣天气和光照条件下仍能保持稳定的测距测速性能[4]. 因此,目前基于毫米波雷达与传感器融合的深度学习方案也得到了众多研究并取得一系列的技术成果[5−8]. NOBIS 等[5]提出的CRF-Net 通过融合摄像机数据和稀疏雷达数据在网络的投影增强了当前二维目标检测网络,并证明了融合网络的检测比纯图像网络表现更好. 针对夜间检测场景,KOWOL 等[6]提出了YOdar 网络将处理相机和雷达数据的两种神经网络输出以一种不确定性感知方式组合在一起,提高了夜晚目标检测性能.
注意力机制在2015 年被提出,在自然语言处理中取得了出色的表现,被逐渐引入到图像处理中[9].注意力机制是一种对资源的分配机制,按照对象的重要性将原本平均分配的计算资源重新分配,这种分配机制可以用于深度卷积网络中对权重进行重新分配. 受到启发,本文提出雷达注意力机制模型,并构建雷达与相机特征级融合网络,对恶劣场景目标检测问题的进行研究.
1 SSD 神经网络模型
单次多核探测器(single shot multiBox detector,SSD) 网络[1]作为具有代表性的单阶段目标检测网络,结构如图1 所示. SSD 网络的基本思想是通过主干的卷积神经网络提取图像特征得到特征图,并在特征图的每个像素点上设置先验框,通过卷积的方式得到先验框调整参数,获得最终的检测结果.
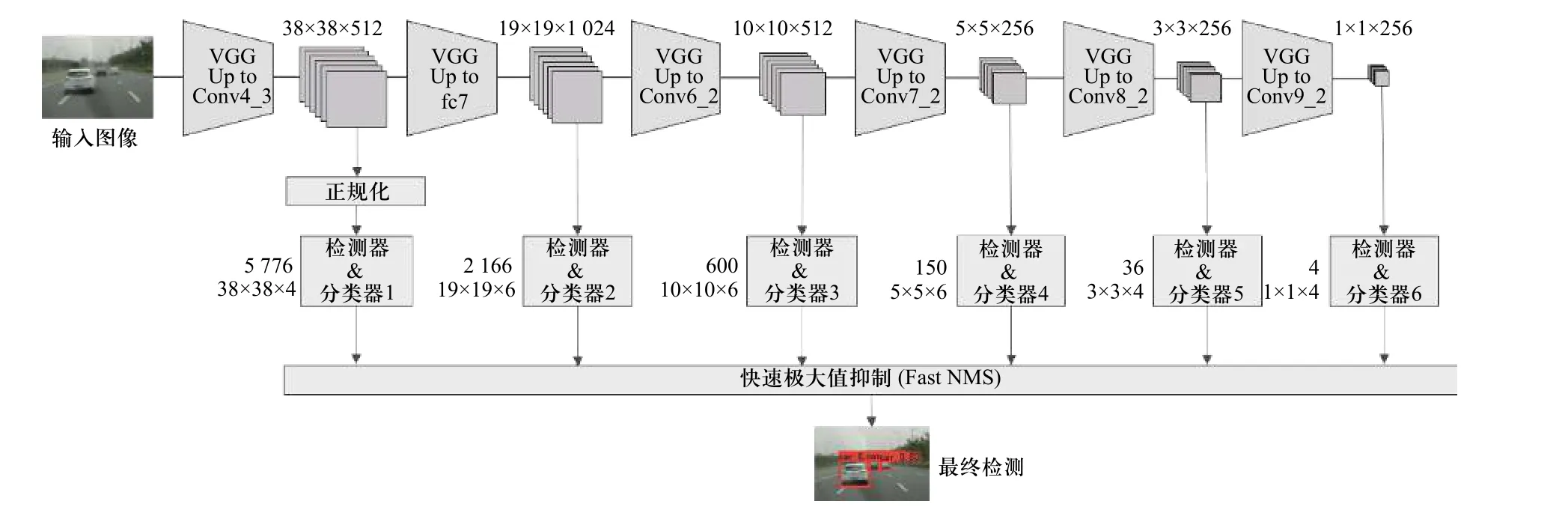
图1 SSD 卷积网络架构图Fig. 1 SSD convolutional network architecture diagram
2 注意力机制
在基于深度学习的图像处理任务中,注意力机制可以划分为通道注意力机制和空间注意力机制,如图2 所示. 通道注意力机制主要反映了特征层在各个通道维度上的关系. 对于一个输入为(C,W,H)的特征层,其中C为通道数、W为特征层宽度、H为特征层高度,经过池化后会形成一个(C,1,1)的张量. 池化后的结果会送入到多层感知机中得到最大池化向量和均值池化向量,最终二者相加,得到输出的通道注意力模块. 通道注意力模块反映了算法对于图像特征层各个通道的重视程度,注意力模块的权值越大,投入的注意力也越大. 通道注意力机制的公式如下:
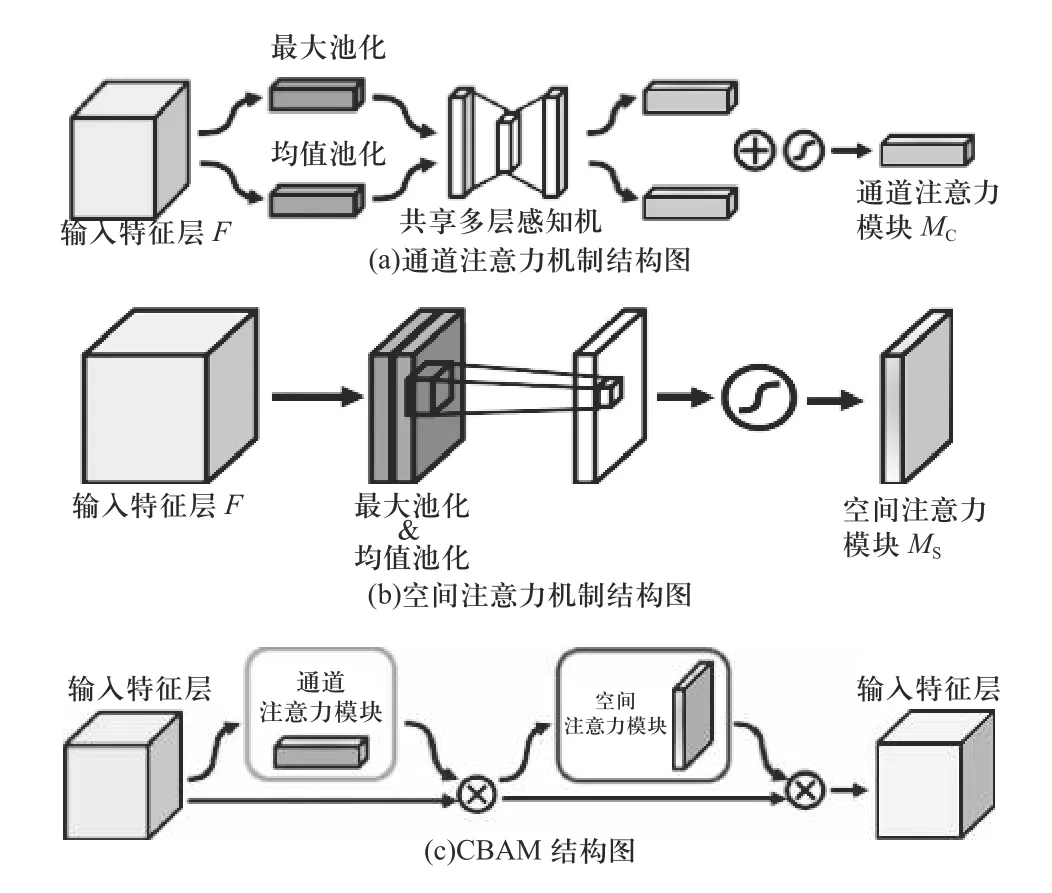
图2 图像注意力机制结构图Fig. 2 Image attention mechanism structure diagram
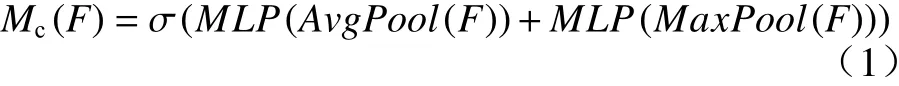
式中:F为输入特征层;Mc(F)为通道注意力机制的模块输出;σ(·)为激活函数;MLP(·)为多层感知机中进行的矩阵运算;AvgPool(·) 和MaxPool(·) 分别代表均值池化和最大池化计算.
通道注意力机制是对图像中更具代表性的特征施以更多的注意力,而空间注意力是寻找特征层中需要施加注意力的位置. 空间注意力机制的思想在于,卷积后得到的特征层的数值越大,该位置出现目标的可能性越大,因此需要施加更大的权重. 对于一个输入为(C,W,H)的特征层,经过过最大和均值池化的两个矩阵将堆叠在一起,形成一个(2,W,H),经过一次卷积后形成(1,W,H)的空间注意力模块. 空间注意力机制的公式如下:
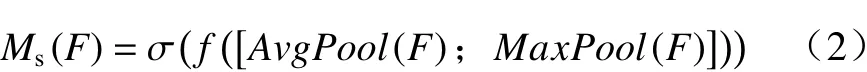
式中:F为输入特征层;Ms(F)为空间注意力机制的模块输出;σ(·)为激活函数;f(·)为卷积层中进行的矩阵运算.
随后WOO 等[10]提出了通道注意力机制和空间注意力机制结合的(convolutional block attention module,CBAM)机制,在实际的目标检测任务中获得了更高的检测效果.
3 相机与雷达特征级融合网络模型
在没有先验信息的前提下,图像注意力模块的权重由特征层卷积、池化、全连接等过程计算得出,也就是特征成参数值越大,权重越大. 在通道注意力机制中,以每个通道上单层特征的最大值作为该代表;而在空间注意机制中,以每个通道上单层特征的最大值作为该代表. 由于毫米波雷达信息具有较好的定位能力和鲁棒性,可以作为图像处理的先验信息. 将图像CBAM 模块中融入雷达特征,构建雷达信息注意力机制模块RCBAM,并在此基础上构建了雷达与图像特征级融合网络. RCBAM 模块可以为图像提供目标的先验信息和候选区域,可以提高目标定位和分类的准确率.
3.1 雷达注意力机制模块RCBAM

式中:(u0,v0)表示图像坐标系的投影中心O1在像素坐标系的偏移量;dx,dy分别表示单个像素点在图像坐标系中x和y轴单位长度. 传感器的参数可以通过相机标定以及联合标定得到[11−12]. 通过投影变换,可以将毫米波雷达点投射到图像中,如图4 所示.

图3 相机与雷达联合标定Fig. 3 Joint camera and radar calibration

图4 雷达点云投射图Fig. 4 Radar point cloud projection map
然后构建雷达特征图. 先生成一个和图像大小相同的空白特征图,即尺寸w×h的单通道灰度图,每个像素点初始值为0. 根据雷达点云在图像中的位置,以单个雷达投影点为中心构建矩形感兴趣区域ROI,即目标在图像的潜在位置. ROI 中的像素点值设为1.ROI 的大小与目标距离有关并与距离的倒数成线性关系,可以得到ROI 的面积公式为

式中:S为ROI 的面积;d为目标的距离; α 和 β分别为斜率和截距. 可以通过最大化ROI 与目标真实框之间的IOU 进行学习参数 α 和 β,同时获得的ROI 也能更接近物体真实的边界框,公式如下:

公式中:SROI表示雷达点产生的ROI 的面积;Sgt为样本中物体真实标记框的面积. 在获得雷达特征图后可以构建雷达的注意力机制模块RCBAM 如图5 所示.

图5 雷达注意力机制模块结构图Fig. 5 Structure diagram of radar attention mechanism module
3.2 特征融合网络构建
在毫米波雷达特征网络中,首先对原始雷达特征网络图分两次进行3×3 卷积和一次最大池化,并将该层特征与图像同维度进行融合形成RCBAM 模块,这是由于在图像进行前两次卷积和池化操作后,图像中依旧包含着较多的低层次语义信息,与雷达特征图的融合更为简单. 同时此后对整个网络反复进行3 个维度上不同层次的RCBAM 融合,保证了网络不会因层次的加深而丢失注意力信息.
初始的SSD 网络为了兼顾大小目标的检测,设置了6 个尺寸分别为 38×38、19×19、10×10、5×5、3×3、1×1 的有效层,从而在一定程度上减小了图像预测框的回归损失,但也导致了模型运算速度的降低. 在引入 RCBAM 模块后,本文的特征级融合网络将仅输出38×38、19×19、10×10 三个尺度的有效特征层,在雷达 RCBAM 模块的定位下,输出预测框的的回归损失并不会降低,同时也能够最大程度上提高网络的运行效率,提升网络的实时性.
此外,雷达注意力机制模块所提供的权值对图像检测只是一个建议值,在和图像注意力模块融合的过程中,融合网络的权值由神经网络训练得出最优权值. 因此在雷达发生误检时,能够通过权值的调整抵抗噪声;在雷达发生漏检时,则该位置权值为0,在与SSD 主干网络融合时也不会影响网络的检测,因此融合网络更强的鲁棒性.图6 是特征级融合网络结构图.

图6 特征级融合网络结构图Fig. 6 Feature level fusion network structure diagram
4 特征级融合网络模型的训练与测试
4.1 实验环境
nuScenes 数据集[13]是2019 年推出的包含了1 000个驾驶场景的大型自动驾驶场景公开数据集. 该数据集包含了毫米波雷达、相机、激光雷达和惯性导航等多种传感器数据,而本实验仅利用相机和毫米波雷达的样本数据完成融合网络的训练与测试. 模型训练的软硬件环境如表1 所示.

表1 实验环境硬件、软件配置参数Tab. 1 Experimental environment hardware and software configuration parameters
4.2 实验结果
模型的评价指标为mAP(mean average percision)和FPS(file per second),其中mAP 能够准的反映出检测算法在所有类别目标检测上的综合性能,FPS 表示每秒处理图像的数量,反映了算法数据处理速度的快慢. 为了验证模型效果,训练了不同网络结构进行对照,各算法的检测结果如表2 所示.
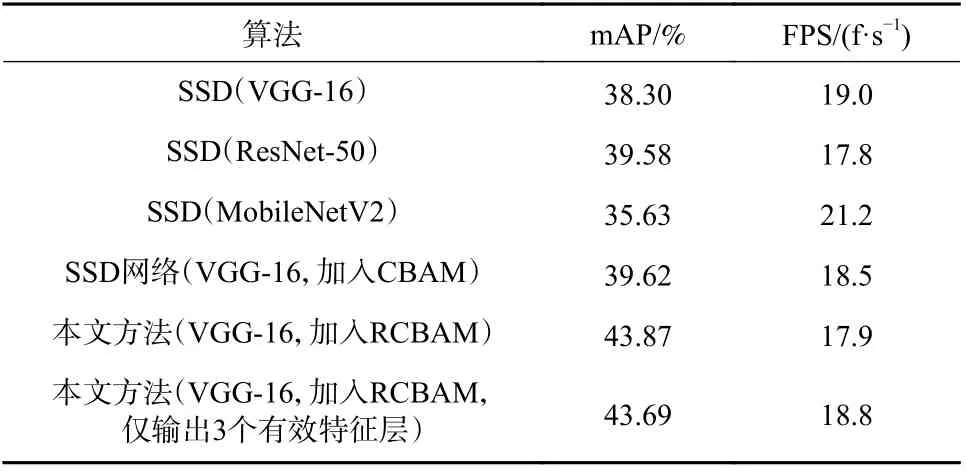
表2 不同网络模型检测结果Tab. 2 Detection results of different network models
从表2 可得:采用传统 VGG -16 作为骨架的SSD 目标检测网络的mAP 值仅为38.30%,FPS 为19.0,而采取了更为复杂的ResNet-50 作为网络主干后,mAP 值有所提升,但 FPS 却有明显的下降. 采用轻量化MobileNetV2 作为 SSD 网络的主干网络可以显著的提升检测效率,但精度也大幅下降. 而在SSD网络的基础上引入注意力机制模块 CBAM 可以在小幅降低FPS 的前提下升网络的检测精度. 所以仅仅在图像检测层面对网络结构进行优化,对于检测效果的提升十分有限. 而本文提出的基于 RCBAM 的特征级融合网络能够在 SSD (VGG-16)网络的基础上将mAP 值提升 5.57%,而少量牺牲FPS. nuScenes数据集的部分测试结果如图7 所示.
图7 中选择了一些常见的交通场景,包括了车辆、行人密集场景以及夜间行驶场景. 从检测结果中可以看出,SSD 目标网络虽然能够检测出场景中大部分的目标. 但是在面对远处小目标和夜晚低光照的目标时,SSD 网络会出现明显漏检的情况,同时检测框的回归误差也较大. 引入RCBAM 模块后,整个融合网络增加了雷达点云的先验信息,从而可以提高目标候选区域的权值,使得之前被遗漏的目标能够被重新检测,提高目标的检测能力. 为了验证模型在困难场景的检测能力,采集不同场景的数据进行了验证,部分结果如图8 所示.

图7 不同模型在nuSences 数据集的部分测试结果Fig. 7 Partial test results of different models on nuSences dataset

图8 实测实验中的部分测试结果Fig. 8 Partial test results of actual experiments
从图8 中可以看出,仅依据图像信息的SSD 网络在面对阴雨、雾霾以及低光照的复杂场景时,其目标检测能力会显著下降出现大量漏检. 而引入了RCBAM 模块的特征融合网络可以很好的改善此问题. 由于雷达信息不易受天气和光照的影响,因此在基于图像的SSD 网络中增加的RCBAM 模块的特征融合网络可以显著提高目标检测的鲁棒性和抗干扰能力.
5 结 论
针对图像在小目标以及恶劣天气和光照场景中目标检测能力下降的问题,提出的基于RCBAM 模块和SSD 模型的特征融合网络算法. RCBAM 模块可以为检测算法提供目标的先验信息和目标候选区域权重. 在nuSences 数据集测试中,基于RCBAM 模块的融合网络的mAP 比初始SSD 网络提高了5.57%;在实际采集的恶劣场景中,基于RCBAM 模块融合网络对大雨、夜晚低光照、低能见度场景和远处小目标的检测性能有了明显的改进,可以为目标检测网络的设计提供一定的指导意义.
猜你喜欢
军民两用技术与产品(2022年5期)2022-06-28
小雪花·成长指南(2022年1期)2022-04-09
科普童话·百科探秘(2020年5期)2020-09-14
初中生世界·九年级(2018年12期)2018-12-22
小学生导刊(高年级)(2016年11期)2016-11-14
第二课堂(课外活动版)(2016年2期)2016-10-21
读者(2015年9期)2015-05-04
初中生世界·八年级(2014年2期)2014-03-15
意林(2011年10期)2011-05-14
小哥白尼·军事科学画报(2009年4期)2009-05-11
