
网联环境下基于精简车头时距特性的驾驶风格分类*
2022-03-20 14:42:20吕能超高谨谨王维锋王玉刚
交通信息与安全 2022年1期
吕能超 高谨谨 王维锋 王玉刚
(1.武汉理工大学智能交通系统研究中心 武汉 430063;2.河海大学土木与交通学院 南京 210098)
0 引 言
驾驶人风格存在差异,体现在驾驶操作的差异化。早在上世纪90年代,就有学者对驾驶风格开展了研究[1],并将驾驶风格定义为驾驶人在驾驶车辆过程中的驾驶行为习惯。驾驶风格与驾驶技能有所区别,驾驶技能是指驾驶人对车辆的控制能力和适应复杂交通状况的能力,而驾驶风格涉及个人选择驾驶的方式或多年来形成的驾驶习惯,体现在驾驶人对行驶速度的选择、超车阈值、车头时距,以及违反交通规则的倾向等[2]。驾驶风格对行车习惯有较大影响,因此在驾驶行为研究领域备受关注。
研究表明:不同风格驾驶人的跟车行为明显不同[3],为了便于研究驾驶风格及其行为特征,通常将驾驶人的驾驶风格分为激进型、普通型和保守型3类[4-6],也有的学者将其分为冒进型、比较冒进型、比较谨慎型和谨慎型4类[7],甚至还有的学者将其划分为5类[3]。目前,驾驶风格分类的研究一般可总结为主观的问卷调查和基于客观的驾驶数据分析建模等2类方法[8-9]。
主观问卷调查分类方法一般通过问卷的形式,对反映驾驶人主观感受和心理预期等方面的评价指标进行统计和量化分析,从而实现对驾驶人驾驶风格的分类[10-11]。如Taubman-Ben-Ari等[12]设计的多维度驾驶风格量表法(multimensional driving style inventory,MDSI),从多维度问卷数据量化分析中评估驾驶风格,对驾驶风格的结构进行界定并将其明确区分为4种风格;孙龙等[13]对MDSI中驾驶风格的影响因素进行了修订,增加了驾驶风格量表的信度和效度的评价指标。基于主观问卷的调查分类法方法简单,无需信息采集设备,但该方法的分类结果只能反映驾驶人对自我驾驶行为的评估,分类结果往往带有一定主观偏差,不能完全体现驾驶人实际驾驶行为特征[4];此外,该方法只能基于问卷进行事后分析,不能实时测量驾驶人风格。
为了弥补问卷调查方法的不足,Li等[14]采用1种基于客观数据的主观分类方法,这种方法主要是利用驾驶人自然驾驶的视频数据对驾驶风格进行分类。相比于问卷调查分类方法,该方法分类结果更符合驾驶人的实际驾驶行为特征。基于网联行车数据构建的驾驶风格分类模型能够更为客观、严谨地评价驾驶人的驾驶风格。该方法通常选择能够表征驾驶人的驾驶行为参数作为分类指标,如超速时间比例[5]、速度[6]、加速度[15]、车头时距、换道时距[16]、油门踏板开度[17]等,在分类方法方面,通过构建分层聚类和K-means聚类[7,18-19]等无监督机器学习方法、有监督机器学习的支持向量机模型方法[20]等实现驾驶风格的分类;此外,Li[21]对典型的机动状态之间的转换模式进行分析,采用随机森林算法对驾驶风格进行分类。结果表明:采用该方法可以显著提升驾驶风格的分类识别精度,有望在将来信息化程度高的车载环境中得到应用。
目前基于客观数据的驾驶风格分类方法,一般选用较多的参数,而且建模过程比较复杂;而目前的网联车辆仅能提供有限的感知参数,上述方法不能在现有网联数据采集条件下推广应用。为了降低数据采集的复杂程度和建模难度,本研究提出了1种基于精简客观行车数据的驾驶风格分类方法。由于驾驶人的一些特征与驾驶习惯相关,不同风格的驾驶人在操作车辆时,车辆的一些运行参数具有差异性,而车头时距指标能够直观地反应出不同驾驶人的驾驶习惯,即车头时距能够体现驾驶人的激进型程度[21];此外车头时距数据易于获取,通过常见的车载传感器即可获得。因此,本研究基于网联行车数据提取车头时距为研究指标,根据不同风格驾驶人的跟车特性提取每种驾驶风格典型的驾驶模式,利用模糊数学的思想对典型模式进行赋值,并提出驾驶风格分类的阈值。本研究提出的驾驶风格快速分类的方法,使用易获取、极精简的数据达到驾驶风格分类目的;与以往研究相比,在数据集质量要求、计算简便性等方面存在优势、便于实施;同时,对于制定个性化辅助驾驶策略、提高预警有效性方面具有重要意义[22]。
1 研究方法
1.1 驾驶风格分类建模思路
驾驶模式是驾驶人在某一时段内的连续操作状态的集合,反映了驾驶人操作状态变化的时变特征,不同风格的驾驶人的驾驶模式特征异质性显著;因此,可以通过提取驾驶人的典型驾驶模式来识别其驾驶风格。由于驾驶行为具有典型的时序特性,前后时序的驾驶行为之间的关联性和差异性具有重要的价值,因此采用时间窗分析驾驶人行为特性。根据文献[23],在驾驶过程中,一般时间窗为3 s的连续操作状态,就能很好地反应驾驶人的行为特性,代表驾驶人的驾驶习惯。太长的连续时间涉及的因素较复杂,因此,应在反映驾驶人意图的基础上尽可能选取较短的时间窗来分析其驾驶行为。研究在此基础上,引入车头时距(time headway,THW)指标,将连续时间窗的THW特征值表征为1个驾驶模式。为了更好地对驾驶风格进行识别,本研究分别选取3 s和5 s的时间窗对的THW特征值进行分析,通过对比发现,以5 s为时间窗提取出的不同驾驶风格的典型驾驶模式具有相似性,不能很好的区分其驾驶风格,因此,确定选取3 s的THW特征值为1个驾驶模式。
文献表明,将驾驶风格分为3种类型是最常用,也是最可用的分类方式[5-7]。本研究利用三分制量表法将44位驾驶人的驾驶风格标定为激进型、普通型和保守型3种类型。根据标定结果,通过计算提取每种驾驶风格中累计频率排名较高的前85%的驾驶模式作为该驾驶风格对应的典型模式;通过事先获取的大量带有风格标签的驾驶行为片段,提取能够代表驾驶风格的典型驾驶模型;利用模糊数学的方法,赋予不同驾驶风格的典型模式相应的分值。并基于自然驾驶采集的大量驾驶片段进行模型的建模和验证。
在样本数据选取时按照7∶3比例构造训练集和测试集,根据典型模式的分值对训练集驾驶人的驾驶风格进行量化,采用三分制量表法标定的驾驶风格结果,构建驾驶风格量化分类阈值准则,并对测试集的驾驶人的驾驶风格进行辨识。结合三分制量表法标定的结果评价所辨识的驾驶风格准确率。具体流程见图1。
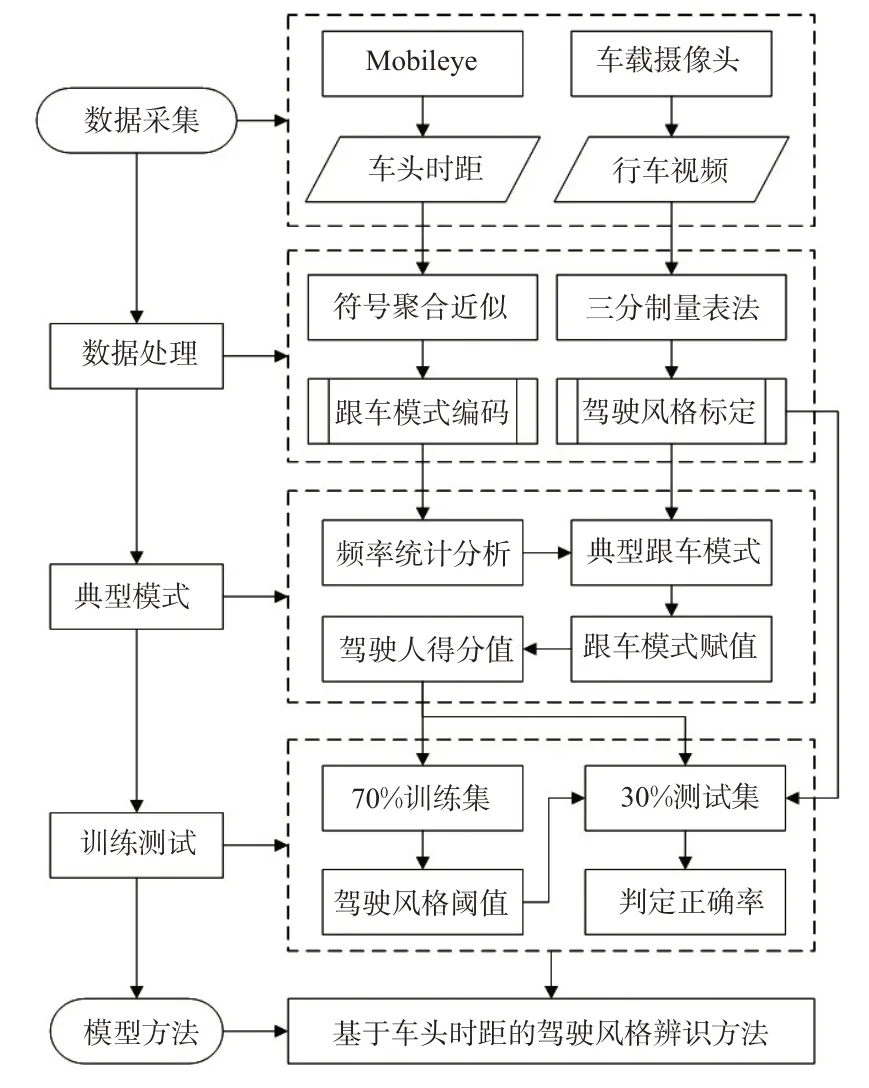
图1 基于网联数据的驾驶风格分类建模思路流程Fig.1 Procedure of driving style classification modeling based on connected data
1.2 样本数据驾驶风格标定方法
为了开展本研究所提出的驾驶风格分类方法建模和验证,要对每位参与实验的驾驶人进行评定和标记,以确定每位驾驶人的实际驾驶风格。根据以往驾驶行为相关研究经验[5,14],主观评价是稳定而又可行的评价方法;虽然该方法不能用于实时评价,但是在建模所需的样本标记阶段,是非常适用的方法。因此,本研究采用多名专家主观评价方法。考虑到驾驶风格分类方法的可行性和准确性,本研究选取三分制量表法对驾驶人的驾驶风格进行标定。
三分制量表法是1种基于客观驾驶数据的主观分类方法。相比于其他主观分类方法,该方法由3位专家分别对驾驶人的驾驶风格进行分类,降低了评价的主观性,是1种常用且有效的方法。这种方法是通过3位专家观看驾驶人在驾驶过程中的驾驶行为表现,即超车、换道、跟车等能够反映驾驶人驾驶风格的驾驶行为等,对每位驾驶人分别进行评分(1分为保守型;2分为普通型;3分为激进型),即每位驾驶人可以得到3个分值。每位驾驶人的最终得分取决于3位专家评分结果是否一致。基于三分制主观评价的驾驶风格辨识遵循如下处理准则:①如果3位专家评分结果一致,那么该分值对应的驾驶风格类型即为该驾驶人的驾驶风格;②如果其中2位专家的评分结果相同,且与第3位专家的评分值相差小于或等于1,那么以相同评分的2位专家评分结果为准;③如果其中2位专家的评分结果相同,而评分值与第3位专家评分值相差大于1,则重新进行评分;若3位专家评分结果各不相同,也需要重新进行评分。
具体评分规则如下。
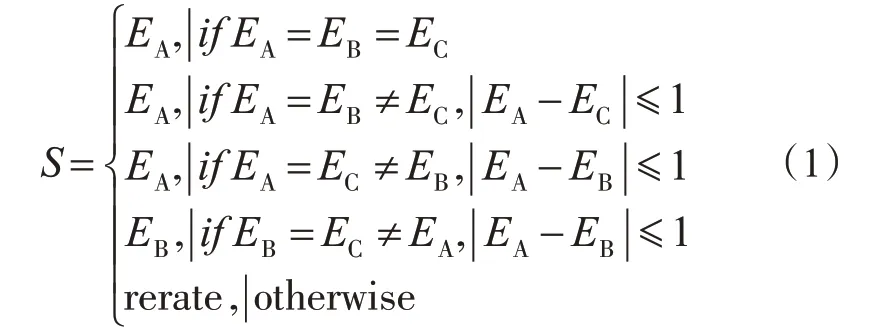
式中:S为驾驶人风格得分值;EA为专家A评分值;EB为专家B评值;EC为专家C评分值。
三分制量表法提供了1种准确、稳定的驾驶风格辨识方法,但其操作过程繁琐,且需要大量的视频数据资料支撑,不能实现驾驶风格的实时识别;然而,对于驾驶风格标注阶段非常适用。本研究用此方法对驾驶人自然驾驶实验过程中的驾驶风格进行分类,并对行车片段进行标签标注,为后续驾驶风格的阈值划分和验证提供依据。
1.3 基于车头时距的典型驾驶模式提取
驾驶人在驾驶过程中受交通流、周围环境以及前方引导车的影响,从而采取不同的操作。车头时距是驾驶行为的直观体现。本研究定义连续3 s的车头时距特征值为1个驾驶模式,提取不同驾驶风格中出现累计频率较高的驾驶模式作为该驾驶风格的典型驾驶模式。提取方法及流程见图2。
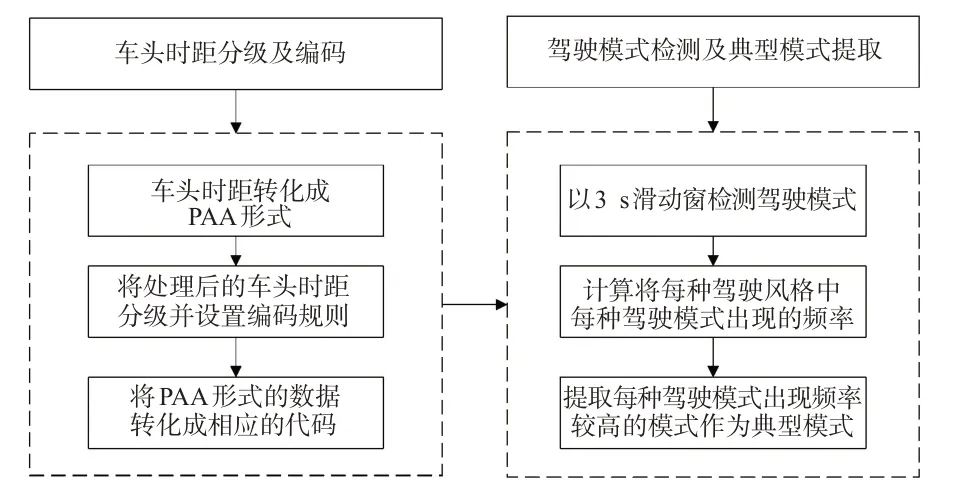
图2 基于车头时距的典型驾驶模式提取方法Fig.2 The method of typical driving patterns based on THW
1.3.1 车头时距分级及编码
对于时间序列数据,为了方便计算,需要对所提取的特征进行合理的简化,以降低复杂度和信息量。本文采用符号聚合近似(symbolic aggregate approximation,SAX)方法将数据转化为简化的代码。SAX算法由Lin等[23]提出,它可以将输入时间序列转换成字符串,既能够对原始数据进行简化降维,也保留了原始时间序列的大体形状。SAX包括2个步骤:①将原始数据转化成分段聚合近似(piecewise aggregate approximation,PAA)表示形式,即将一定时间长度的车头时距进行平均值计算,以均值代表该时间段内的数据;②根据聚类点的位置将聚类数据转换成字符串。
分段聚合近似是将n维时间序列C=c1,c2,…,c n转换为w维的向量C=c1,c2,…,c w的过程,其中,第i个按照式(2)计算。
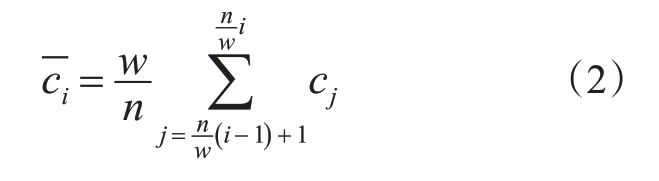
将n维原始的时间序列向量降维到w维,将原始时间序列向量划分为w个片段,是第i个片段的均值。其中,为压缩率,必须保证为整数。
将PAA形式的车头时距数据转化成字符串时需要依据车头时距的分级和编码规则来完成;因此,需要设置车头时距分级及编码规则。根据所有驾驶人的车头时距数据的分布情况,将其按从小到大的范围划分为不同的等级,并设置相应的编码。根据前期Lyu等[24]研究中行车状态下的车头时距分布规律,本研究根据车头时距分布情况将其划分为8个等级,并依次将其代码设置为1~8。具体划分情况见表1。

表1 车头时距等级划分情况Tab.1 Classification of THWclass
转化成PAA形式的时间序列根据车头时距编码设置规则,将PAA系数映射到相应的符号,即将降维之后的THW值映射到对应的等级中,从而将时间窗行车数据转化为对应的编码代码。
本研究样本数据车头时距的采集频率为10 Hz,数据量较大,需对原始数据进行欠采样处理。因此,以1 s为时间长度进行符号聚合近似处理,即以1 s的车头时距平均值来表示这1 s内的车头时距。以其中任意1名驾驶人30 s内的车头时距数据为例,分段聚合近似结果见图3。图中右侧的数字表示各等级范围,根据车头时距所属范围确定其编码。
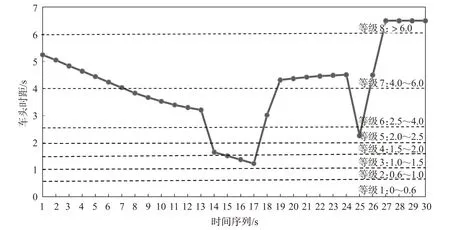
图3 车头时距分级及编码Fig.3 Grading and coding of THW
1.3.2 驾驶模式提取
本研究定义连续3 s的车头时距对应等级的字符串为1个驾驶模式。由于驾驶过程是1个连续的过程,因此采用滑动时间窗法来检测驾驶人的驾驶模式。见图3,每3 s产生1个驾驶模式,选择3 s的滑动时间窗口来检测驾驶人的驾驶模式,如123,234,345,…,等。时间段分别产生1个驾驶模式。由于车头时距被划分为8个等级,每3 s为1个驾驶模式,因此共产生83=512种驾驶模式。见图4,每个矩形框包围的连续3个代码为1个驾驶模式,从第13 s起驾驶模式依次为:643,433,333。
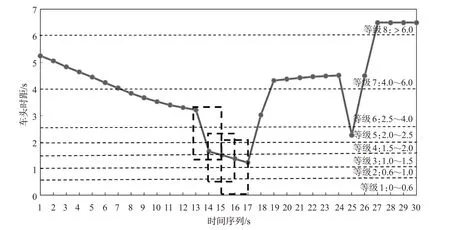
图4 驾驶模式提取及编码过程Fig.4 The process of car driving patterns extracting and coding
考虑到有效样本筛选的原则,充分考虑驾驶人本身意图的跟车数据,剔除由于其他车辆的行为而产生的THW突变等情况;通过分析,认为以下情形中THW不代表驾驶人本身的跟车意图,将剔除以下数据:①连续3 s内的THW均大于6 s,即产生888这种驾驶模式时,此时车辆处于自由巡航状态;②连续2 s内的THW发生突变,即产生881,811,882,822或产生188,118,288,228等这几种驾驶模式时,前者可能是该车辆被其他车辆切入,后者可能是由于前车换道驶离。
1.3.3 驾驶风格典型模式选取
假设认为,不同驾驶风格有其典型的高频驾驶模式,提取这些典型的高频驾驶模式是关键。典型模式选取时,结合三分制量表法划分的驾驶风格结果,将每种风格驾驶人相同代码的驾驶模式自然聚集成一组;统计每种驾驶风格中不同类型的驾驶模式的发生频率,提取每种驾驶风格典型高频的驾驶模式。
此外,不同驾驶风格存在典型驾驶模式可能存在类似的现象,即同一种驾驶模式在不同驾驶风格中均出现,这就使得同一种驾驶模式成为不同驾驶风格的典型模式,出现这一现象的原因可能是某些驾驶模式是所有驾驶人普遍采用的驾驶模式,不具有驾驶风格的区别性。为了解决这一问题,设置典型模式提取规则:①一般情况下,提取每种驾驶风格中出现频率较高的前85%分位的驾驶模式为典型驾驶模式;②若不同驾驶风格中累计排名较高的前85%分位驾驶模式中出现相同的驾驶模式,则对比该模式在不同驾驶风格中的出现的累计频率,认为该模式属于累计频率较高的驾驶风格的典型模式。
通过分析不同驾驶风格的驾驶模式,以提取其对应的典型驾驶模式,主要思路及步骤如下。
步骤1。根据三分制量表法的主观评价分类结果,对驾驶人风格进行分类,并将相同驾驶风格的行车片段构成1个子数据集,提取其THW特征值。
水肥一体化技术是将灌溉与施肥融为一体的农业新技术。在国家大力发展现代农业的新形势下,河北华雨农业科技有限公司发挥自身在灌溉装备和新型微生物肥料行业多年形成的独特优势,在水肥一体化技术领域推出新成果,为优质高效绿色环保型现代农业注入新的活力。
步骤2。采用滑动时间窗法检测每类驾驶风格驾驶人的驾驶模式,将每种驾驶风格产生的相同的代码自动划分为1组,即每种驾驶风格中包含的每种驾驶模式划分为1组。
步骤3。统计每种驾驶风格中每种驾驶模式出现的累计频率,并提取每种驾驶风格中出现累计频率较高的前85%分位的驾驶模式作为典型驾驶模式。
1.4 基于模糊隶属度的驾驶模式赋值
为了区分不同驾驶风格,需将不同驾驶风格驾驶人的跟车特性量化,对不同驾驶风格中典型的驾驶模式进行赋值。实现分类的方法有多种,如聚类、模式识别、模糊隶属度等方法。模糊数学是研究现实世界中许多界限不分明甚至是很模糊问题的数学工具,本研究采用模糊隶属度思想研究不同驾驶风格的典型模式的分值设置。模糊隶属度的首要问题就是确定隶属度函数,半梯形分布或梯形分布是比较常用的隶属度函数。根据本研究典型模式频率数据分布的特点,采用半梯形分布方法确定典型模式的隶属函数。
由本研究中定义的典型模式可知,每种风格出现某种典型模式的频率越高,说明这种典型模式越能够体现该驾驶风格的驾驶模式;因此可知,典型驾驶模式的频次对应的隶属度函数属于偏大型隶属度函数,函数形式见式(3)。
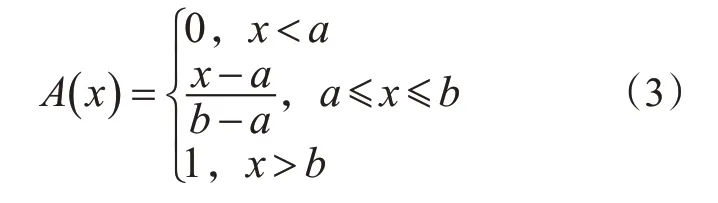
为了定量描述驾驶人的驾驶行为,根据驾驶人行车数据中出现典型对应的分值以及所占行车时间百分比对驾驶人进行分值计算,分值具体定义为,驾驶人行车片段中出现各典型模式所占总驾驶时间的百分比与该典型模式对应分值乘积的累计值[25]。计算公式为

式中:S为驾驶人驾驶风格的得分值;Pi为驾驶人行车数据中出现典型模式i的时间占总驾驶时间的百分比;Si为典型驾驶模式i对应的分值。
2 自然驾驶实验及数据集
2.1 被试驾驶人
样本量的选取是获得足够实验数据的关键,样本量过小会降低结果的可信度,过大则会导致资源的浪费。本研究参考文献[26]基于预期方差、目标置信度和误差幅度计算所需样本量。计算公式为
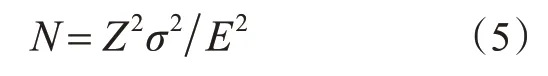
式中:N为样本量;Z为标准正态分布统计量;σ为标准偏差;E为最大误差。
通常,选择10%的显著性水平来反映未知参数的90%置信水平。当置信水平为90%时,Z=1.25;σ取值为0.25~0.5,E=10%。因此,计算所需最小样本量取值范围为10~39。因此,本研究共招募44名被试驾驶人(女性=19;男性=25),被试年龄在22~55岁之间(mean=32.8,SD=8.2),驾驶人驾龄在2~18年之间(mean=6.9),平均驾驶里程为11万km,范围在400~4×105km之间,样本的性别、年龄和驾驶经验的分布符合中国一般驾驶人群的分布情况。
2.2 实验设备及路段
本研究的建模数据来自自然驾驶网联行车数据,实验基于自主开发的实车实验平台开展。如图5所示,实验平台基于广汽传祺GA3集成,主要装载了高级驾驶辅助系统Mobileye M630、前向激光雷达Ibeo LUX4、车载惯性导航系统OXTS RT2500、前视摄像头等。其中Mobileye用于采集前方最多8个目标的位置信息以及本车相对车道线位置信息,Mobileye的预警功能在部分实验过程中处于关闭状态;CAN总线用于采集驾驶人操作和部分车辆运动姿态信息,如油门踏板、制动踏板、转向盘转角和车速等;惯导系统用来采集车辆运动姿态和位置信息,如加速度、角速度和经纬度;激光雷达隐藏安装在车头,用于采集前方目标相对于本车的位置和相对速度,作为冗余信息采集传感器;前视摄像头用来采集车辆行车视频。除视频外,所有数据均采用CAN总线设备采集,实现了时间的同步;最终通过采集软件处理后,采用频率为10 Hz。

图5 实验平台Fig.5 Experimental platform
本次实验给出驾驶员起点和终点,实验路段包括4个部分,见图6,路段1和路段3为城市快速路,路段2为高速公路,路段4为城市道路。整个实验过程中驾驶人无需佩戴任何实验仪器,只需按照日常的习惯从起点驶向终点,在保证安全的前提下,发挥每位驾驶人各自的操作习惯和驾驶风格。
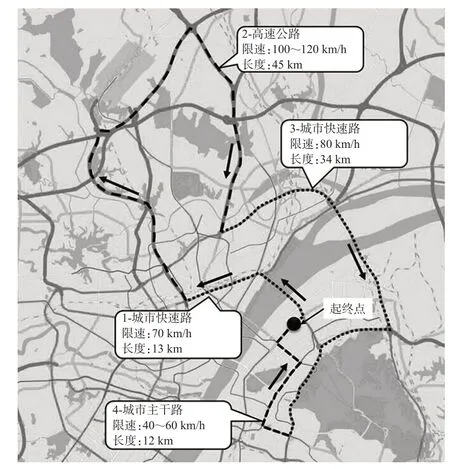
图6 实验路线Fig.6 Experimental routes
2.3 网联实验数据
通过自然驾驶实车实验获取到88人次、每人次105 km的实车实验数据,共计约10 000 km。实验过程中采集的数据包括驾驶员基本信息、速度(v,km/h)、纵向加速度(a x,m/s2)、车头时距(THW,s)、碰撞时间(time-to-collision,TTC,s)和车头间距(Distance Headway,dhw,m)等,获取的所有数据类型见表2。
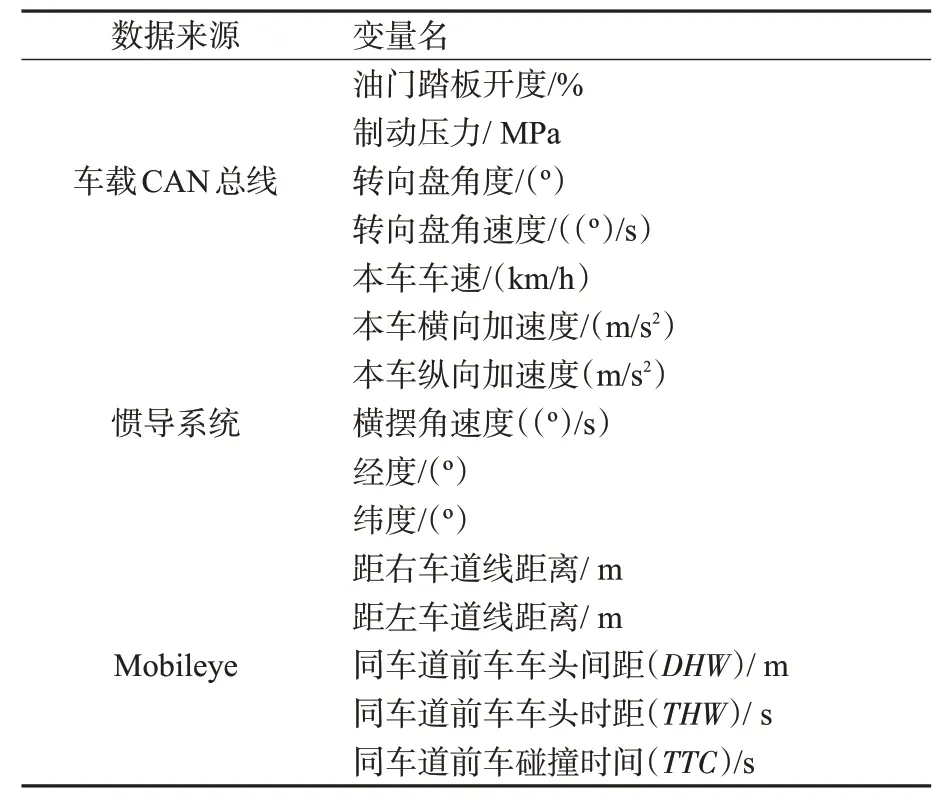
表2 自然驾驶平台采集的原始数据Tab.2 Raw data from a natural flight platform
本研究仅使用Mobileye采集的THW及前视摄像头采集的行车视频数据来研究驾驶风格。由于传感器检测范围限制或者前方没有目标,Mobileye输出的数据并不是直接输出车头时距指标,需要进行进一步处理,同时车载传感器采集的原始数据不可避免的存在漏帧、不连续、跳变等缺陷,需对原始数据进行清洗与预处理以保证数据质量。因此,本文使用三次样条插值对丢失帧进行补充,并基于Savitzky-Golay滤波器过滤噪声、修正跳变,最终获得准确的车头时距数据。
通过对行驶工况界定,提取有效行车片段。有效片段选取时充分考虑样本中能够代表本车驾驶人意图的跟车数据。由于实验路段中高速公路路段车流量较小,车辆基本处于自由巡航状态,无法提取到有效的车头时距数据;城市道路车流量较大,车辆经常处于交通拥堵状态,车头时距过小,难以有效区分不同风格驾驶员操作的差异性。因此,最终选取路段1和路段3总长度为47 km的城市快速路作为研究对象。将城市快速路的行车数据按照30 s为1个时间窗进行划分,每个时间窗内的行车数据作为一段有效行车片段,最终共获取到约2 640段有效行车片段。其中,30名驾驶人数据用于建模(占总数据集68.2%),14名驾驶人数据用于验证(占总数据集31.8%)。
3 建模过程及结果验证
3.1 模型训练
1)三分制量表法划分驾驶风格。选择3位驾驶经验丰富且深入了解不同驾驶风格特征的驾驶人作为驾驶风格主观评价专家,3位专家通过观看44位驾驶人的行车视频数据,根据被试驾驶人在行车过程中的跟车、超车、换道等能体现驾驶风格的驾驶行为,并采用三分制量表法分别对44位驾驶人依次进行打分从而对其驾驶风格进行标定。在驾驶风格标定过程中,初次打分时,不同专家之间出现意见分歧,其中39位驾驶人的风格标定结果一致,5位驾驶人的驾驶风格不能确定;随后,3位专家对这5位驾驶员重新进行标定;最终,将这5位驾驶员确定为3位属于普通型,2位属于保守型。三分制量表法的驾驶风格分类结果见表3。

表3 驾驶风格标定结果Tab.3 The result of driving style calibration
2)不同驾驶风格的模式赋值。根据不同驾驶风格驾驶人的行为特性分别赋予不同驾驶风格的典型模式初始分值。分值可以设置为-1,0,1,也可以设置为其他值,主要用来区别不同类型风格。初始值设置见表4。

表4 典型驾驶模式初始分值Tab.4 Typical initial values of the following patterns
首先,基于自然驾驶建立行车数据集,对行车数据集进行有效性筛选及分段;然后,根据三分制量表法得到每位驾驶人的驾驶风格,进而对每个行车片段进行驾驶风格标注;最后,提取3种驾驶风格的行车片段中的典型驾驶模式,并对其按照出现频次百分比进行分值赋值。基于每种典型模式所占的时间百分比,利用式(4)计算每种典型模式的隶属度及对应分值,提取的每种驾驶风格的典型模式见表5。
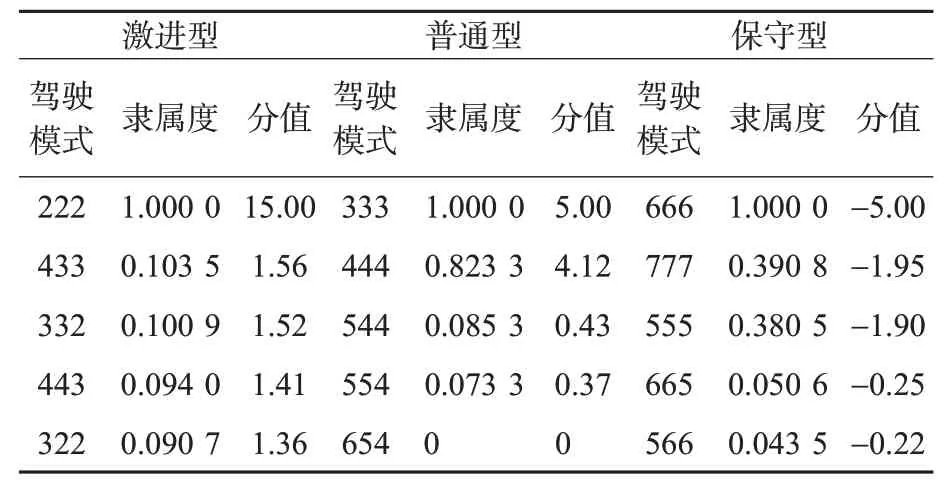
表5 部分典型的驾驶模式隶属度及对应分值Tab.5 A part of the membership and the corresponding values of typical car following patterns
从上述提取的不同驾驶风格的典型模式可以看出:①激进型驾驶人排名靠前的驾驶模式为222,433,332,443,322,可以看出激进型驾驶人倾向于与前车保持较小的车头时距,且有将车头时距由大到小调整的意愿;②普通型驾驶人排名靠前的驾驶模式为333,444,544,554,654,其车头时距保持在比较适中的位置;③保守型驾驶人排名靠前的驾驶模式为666,777,555,665,556,可以看出保守型驾驶人倾向于与前车保持较大的车头时距,且有将车头时距由小到大调整的意愿;④激进型驾驶人在驾驶过程中紧紧跟随前车,随着前车速度的变化不断调整运行状态;而保守型驾驶人则为自己预留更加充裕的时间来应对前车速度的变化,这一结果符合不同驾驶风格驾驶人的心理特性。
3)不同驾驶风格的阈值设定。驾驶风格阈值设置时,根据实验得到的44组有效样本,选择约70%的样本,即30名驾驶人作为驾驶风格分类的建模数据集。随机选取样本时遵循分层抽样的原则,按照比例随机选择激进型、普通型、保守型驾驶人分别为4,15,11名。利用式(4)计算得出训练集驾驶人的平均分值、分值标准差、分值极大值和分支极小值见表6。
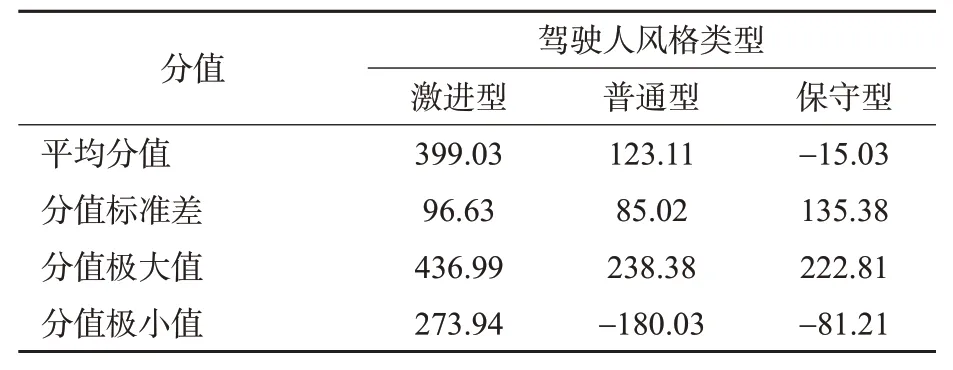
表6 训练集驾驶人得分情况Tab.6 Training set the driver of the score
具体分值分布情况见图7。由图7中建模数据集驾驶人得分情况可知,普通型和保守型驾驶人分值有交叉重叠部分。这种情况符合客观规律,本身因个体差异会存在少数不同类型驾驶人评分分值重合情况;但是激进型和保守型驾驶人之间分值没有重叠。设置阈值的目的是区分不同的驾驶风格,准确地说,就是找出2个临界值作为不同驾驶风格的分界线,其中1条线尽可能将普通型与保守型分开,是与保守型、普通型的各个样本分值距离之和最小的值,另1条线尽可能将激进型与普通型分开,即与激进型、普通型的各个样本分值距离之和最小的值。通过计算得出与保守型和普通型各样本分值距离之和最小的值为64.67,与普通型和激进型样本分值距离之和的最小的值为181.20,如图7中的虚线所示。因此,将各驾驶风格阈值是设置为:S<64.67为保守型,64.67≤S<181.20普通型,S≥181.20为激进型驾驶人。
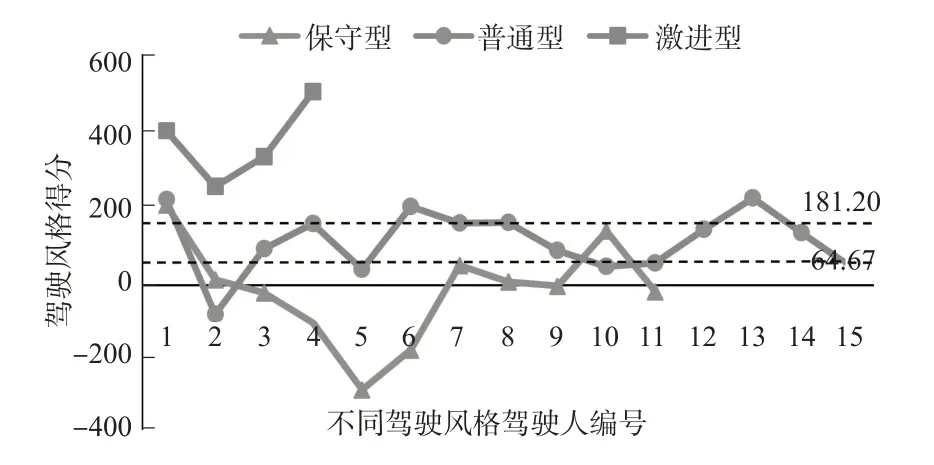
图7 训练集驾驶人分值分布情况Fig.7 Drivers'scoring of training set
3.2 模型测试及验证
为了测试与验证本研究所提出的基于精简车头时距特征驾驶风格分类方法的识别效果,本研究利用样本集中其余14名驾驶人的实验数据作为模型的测试集。利用上述同样方法对测试集的驾驶人数据进行分析,计算出14名驾驶人的分值,并根据以上模型中设定的各驾驶风格阈值对测试集驾驶人的驾驶风格进行识别。测试集驾驶人得分情况及识别结果见表7。
将识别结果与三分制量表法划分的结果进行比较,验证识别结果的准确率,见图8中混淆矩阵。横坐标为本研究所提方法的辨识结果,纵坐标三分制量表法的分类结果,即实际驾驶风格,横纵坐标中的数字1,2,3分别表示保守型、普通型和激进型。由混淆矩阵可知,利用本研究提出的驾驶风格分类方法对14名驾驶人进行识别,具体识别结果为:保守型、普通型、激进型驾驶人人数分别为7,5,2名;与真实结果相比,本文所提方法误将2名普通型驾驶人识别成保守型驾驶人,总体来看,驾驶风格识别准确率为85.7%。其中,驾驶风格被识别错误的2名驾驶人在专家打分时也出现了不同的意见,由表7可知,采用三分制量表法进行驾驶风格划分时,2名专家认为是普通型,1名专家认为是保守型,最终标定为普通型,因此,这2名驾驶人的驾驶风格不明显,介于保守型与普通型之间。此外,模型训练集与验证样本量较小,导致不同驾驶风格阈值设置时存在偏差,因此也会导致驾驶风格识别错误的情况。如果增加样本数量有望进一步减小随机误差对识别精度的影响。
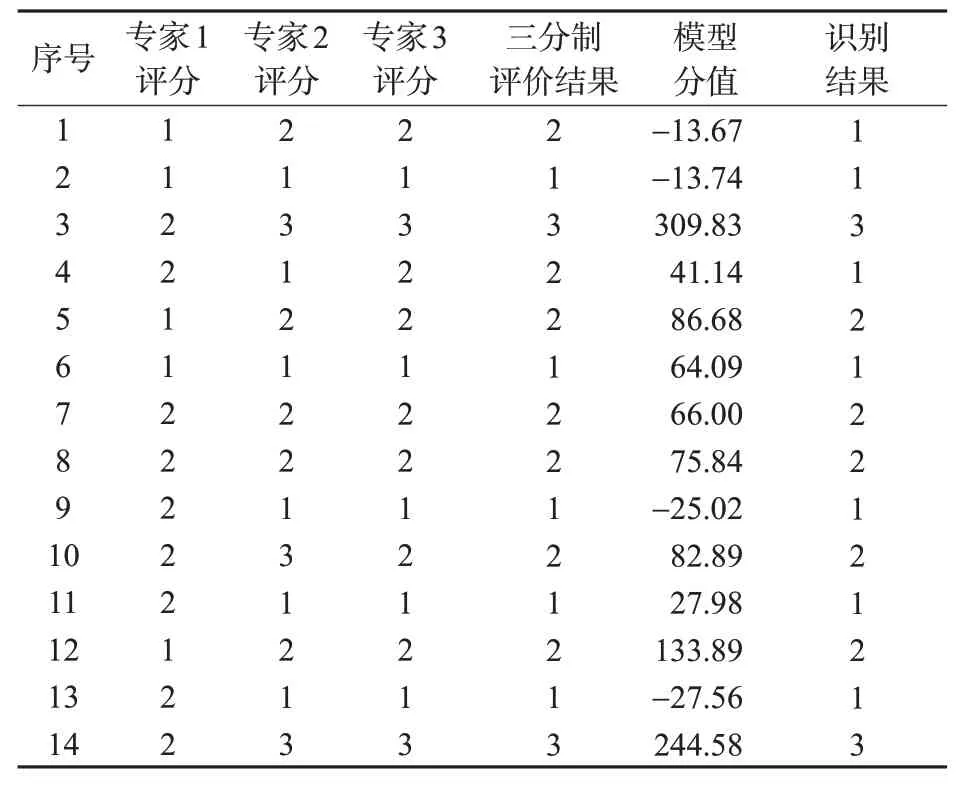
表7 测试集驾驶人得分情况Tab.7 Drivers'scoring of test set
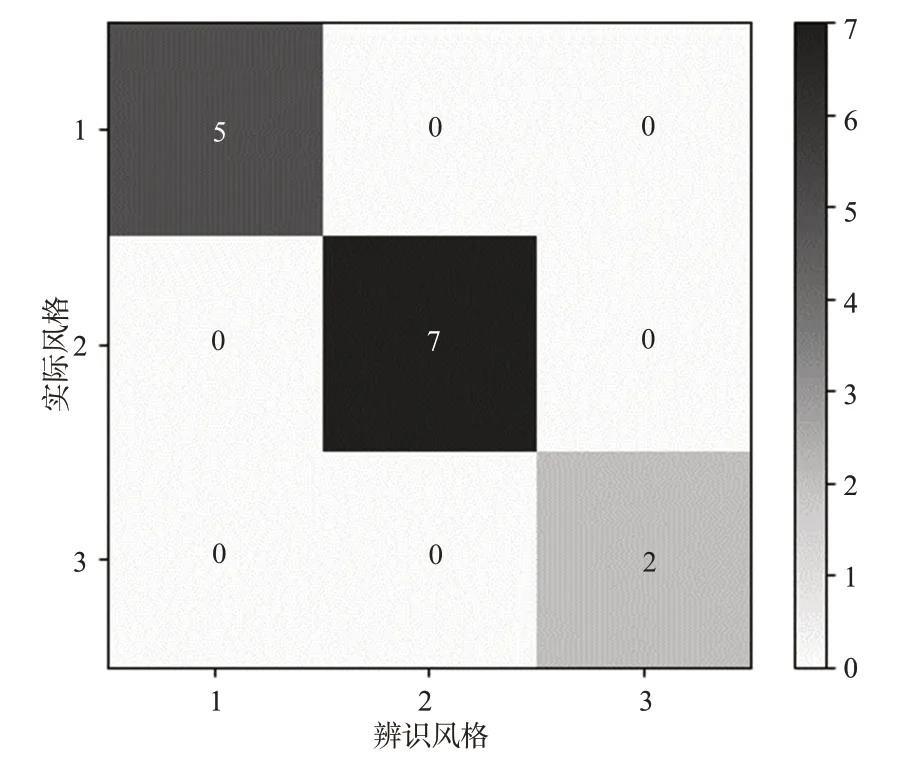
图8 驾驶风格识别结果Fig.8 The result of driving style recognition.
4 结束语
本研究提出了1种基于车头时距特性来辨识驾驶风格的方法,仅利用精简的车头时距指标,在车联网环境下具有可实施性。采用三分制量表法辨识驾驶人驾驶风格,将驾驶人的驾驶风格分为保守型、普通型和激进型3种,将驾驶人的驾驶操作过程进行量化,采用模糊隶属度方法构建了驾驶人驾驶风格的分类阈值准则,得到不同驾驶风格的阈值,通过对测试集进行验证,发现12名驾驶人的驾驶风格被正确识别,2名驾驶人的驾驶风格被错误识别,识别的准确率为85.7%。主要结论及贡献如下。
1)激进型驾驶人更倾向于近距离跟车,且有将车头时距向小调整的倾向;相反地,保守型驾驶人更倾向于远距离跟车,且有将车头时距向大调整的倾向。这一结论与之前研究中不同风格驾驶人的驾驶习惯相符合[27]。可见,本研究所提取的不同风格下典型驾驶模式能够很好地反映不同风格驾驶人的驾驶行为特征。
2)本研究创新性地提出了驾驶风格分类的阈值,并结合实例得出各驾驶风格阈值分别为:S<64.67为保守型,64.67≤S<181.20为普通型,S≥181.20为激进型驾驶人。
3)通过极精简的单一指标-车头时距来实现驾驶风格的识别。基于本研究提出的方法可以构建一套实时、易用、有效的驾驶风格识别方法,将分类结果反馈给驾驶人和车载系统,以实现个性化预警或个性化自动驾驶,使得辅助驾驶及自动驾驶更加符合个性化要求。
本研究在训练集样本选取时,采用分层抽样的方法。由于总样本量不大,分层抽样时存在每层的抽样比例不均衡、有偏差的现象;抽样的结果可能会影响阈值设置结果,进而对驾驶风格的识别结果产生一定影响。如果样本量够大,能够消除训练集抽样不均衡现象,使得不同驾驶风格的典型驾驶模式及阈值设置更具有科学性和可信性。
猜你喜欢
人类工效学(2021年5期)2022-01-15 05:06:30
煤气与热力(2021年5期)2021-07-22 09:02:14
中国民间疗法(2021年1期)2021-04-20 02:30:40
广东医科大学学报(2020年6期)2020-02-06 06:01:14
军事文摘(2020年24期)2020-02-06 05:56:58
绥化学院学报(2019年10期)2019-10-12 01:08:12
心理科学进展(2018年8期)2018-02-21 18:32:04
中国老区建设(2016年4期)2017-01-15 13:53:45
心理科学进展(2015年5期)2015-02-26 07:07:54
中国卫生标准管理(2015年14期)2015-01-27 02:24:27
