
基于模糊集鲁棒概率不等式的风电斜坡估计方法
2022-03-18 06:14:24徐姣新
计算机应用与软件 2022年3期
徐姣新 杨 召
1(商丘学院 河南 商丘 476000)2(商丘工学院 河南 商丘 476000)
0 引 言
在向绿色和可持续发展社会过渡的过程中,风电在世界范围内得到了快速发展。然而,由于天气条件的原因,风力发电本质上是随机的。由于电力系统必须在瞬间平衡负荷,短期内电力输出的大幅度变化(称为风电斜坡事件[1])将给电力系统运行带来巨大挑战。根据方向,风电斜坡事件可以分为两类:向上斜坡和向下斜坡。向上斜坡事件通常由强低压空气系统、阵风、低空急流和雷暴引起。相反情形下,上述现象的逆转,便会发生向下的斜坡事件[2]。在向上斜坡事件中,系统调度员必须减少常规发电机的功率输出或减少一些风力发电;在向下斜坡事件中,调度员则需要备用容量的支持,或在备用容量不足时减少一些负荷[3]。所有这些斜坡事件都会增加系统运营成本和风险,因此,更好地检测和预测风电斜坡事件可以警告调度员,并帮助他们部署预防风险故障的主动策略。
风力发电斜坡事件的检测作为一项重要的技术,一直是众多学者研究的热点。文献[4]提出了一种基于澳大利亚风力发电预测工具(Wind power prediction tool,WPPT)风电场数据的两阶段方法来检测和分类大型风坡道。文献[5]提出了一种基于支持向量机(Support vector machine,SVM)的风力发电斜坡事件一步分类和多步分类模型。文献[6]提出了一种用于识别大时间序列风坡的最优检测技术,给出了一类带有斜坡定义的评分函数,并应用动态规划递归方法检测斜坡事件。文献[7]采用一种摆动门算法(Swinging door algorithm,SDA)从历史数据中识别斜坡事件,该方法只需定义一个参数,在计算效率和抗噪声方面具有显著优势。
基于斜坡检测技术的斜坡预测技术可以在几分钟或几小时之前提供警告信息,并帮助调度员提前安排系统操作。通常,风电斜坡事件的预测可分为两类:确定性预测和概率性预测。对于前者,文献[8]提出了一个基于数据挖掘算法的多变量时间序列模型来预测风电爬坡率。文献[9]提出了一种基于多数值天气预报(Numerical weather prediction,NWP)输入、统计处理和自适应算法的时间斜坡预测模型。
值得注意的是,上述研究依赖于确定性范式,而忽略了风坡事件的不确定性问题。采用概率方法提供风坡道的统计信息,可以帮助系统运营商做出更好的调度决策,以应对这些风险事件。部分研究提出利用大时间尺度信息建立概率风坡预测模型,或采用自回归对数模型,以基于多项式对数结构和分类分布同时估计不同阈值的斜坡事件概率。在应对斜坡坡度和相位预测误差问题时,可以使用短期斜坡预测模型,对风电功率进行概率密度估计,然后利用概率密度函数提供遇到斜坡事件的概率信息。
上述概率方法基于风电的经验分布进行统计分析。然而,一方面,校准一个精确的概率分布需要足够的历史数据,而这些数据可能不是可用的;另一方面,任何参数分布可能都不完全适合真实数据,导致统计分析对不确定数据分布的变化很敏感。克服上述困难的一种方法是采用分布鲁棒优化方法,该方法考虑了经验分布周围的一系列分布,其结果提供了对目标事件概率的保守估计,并且对概率分布中的扰动具有鲁棒性。
在分布鲁棒优化模型中,采用概率密度函数(Pro-bability density function,PDF)描述事件的不确定性,但PDF是不精确的,考虑将一系列候选PDF构成所谓的模糊集。根据已知信息,可以用两种方法构造模糊集。一种是使用力矩信息,另一种是采用经验分布和散度度量。本文从不确定性量化的角度研究了风电斜坡事件的概率预测[10],提出具有两个模糊集的鲁棒概率不等式来估计斜坡事件的概率。其中,第一个模糊集只需要点预测和预测误差的平均绝对偏差,并考虑预测误差分布的单峰性;第二个模糊集需要任意数量的风电历史数据。两种模型都是数据驱动的,得到可解的凸优化问题,通过离线求解器进行求解。
1 所提方法描述
1.1 不确定性量化模型
风力发电斜坡事件发生在与输电网相连的大型风电场中。现有文献以几种方式定义斜坡事件,在文献[1,12]中,是指风电场在多个时期内的巨大变化(如30分钟或1小时内达到20%的容量),或在短时期内的快速变化率。文献[1]中,多个时段的最大和最小风力之间的差异也被视为斜坡事件。
本文研究了文献[1]中定义的单周期爬坡的超短期预测问题:连续两个调度周期(通常为1小时)的风电变化超过一个阈值。假设未来两个连续时段的点风电预测可用,应用文献[10]中的方法,很容易识别风电输出的增量变化,从而以确定的方式检测斜坡事件。然而,点预测存在不精确性,可以为系统调度员提供保守或乐观的结果。具有置信水平信息的概率斜坡预测是理想的,如文献[11]中的条件区间预测方法。然而,由于一个斜坡事件包含两个不同时段的输出,这两个时段都是不确定的,因此很难从条件区间预测方法中提取风电动态。
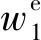

图1 风电斜坡事件描述
设w=┌w2,w2┐T为随机变量的向量,f(w)为其概率密度函数(PDF),向上斜坡事件的概率可以表示为:
Pr{w∈W}
(1)
式中:Pr┌·┐代表事件发生的概率,且:
(2)
式中:C表示风电场的容量;RU表示向上斜坡阈值。将最后一个约束替换为w1-w2≥RD即可以类似的方式设置向下斜坡事件的概率,其中RD表示向下斜坡阈值。
评估式(1)中的概率需要用到w的PDF,一般假设w服从高斯分布,并通过曲线拟合方法估计均值和方差。然而,这样的参数分布可能无法反映风电的真实分布情况。为了克服PDF获取困难的问题,本文提出考虑一类不确定的PDF,并将其限制在一个模糊集S内,目的是找出最不利的结果,从而得到以下分布的鲁棒不确定性量化问题:

(3)
这一问题对应一个概率不等式,可以转化为函数优化问题求解。Pr[·]定义了从PDFf(w)到实数的映射,决策变量是f(w),是实值函数。换句话说,对于每一个w∈W,f(w)是一个决策变量,决策变量的数目是无限的,可行域是S。如果w服从S中包含的任何分布,则斜坡事件的实际概率应不大于式(3)的最优值。这种保守的估计可以在PDF扰动的情况下保持足够的安全裕度,因此在电力系统运行中是可以接受的。
1.2 基于矩的方法
如果所有Borel集B∈B(Rk)的tkf(B-m/t)在t>0时不递减,则w∈Rk的概率分布f(w)∈S是中心为m的单峰分布。
(4)
基于矩的模糊集S1考虑了所有具有相同平均值m和平均绝对偏差σ的偏微分方程,此外,要求PDFf(w)单峰。
将S1代入式(3),得到的不确定度量化问题可以重新表述为以下形式[12]:
inf 1-λ+σTη
(5)
式中:s=[-1,1]T,λ、θ、η和π为辅助变量。
然而,可以发现约束条件式(9)实际上是凸的。通过引入几个辅助变量y、t1、t2,可以将它重新定义为线性不等式和二阶锥:
(10)
最后,将基于矩模糊集S1的概率不等式(3)转化为二阶锥规划,即可以进行有效的求解。
1.3 基于散度的方法
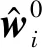
然而,f0通常是不准确的,所以本文使用一个模糊集,其中包含所有与经验分布f0足够接近的偏微分方程。为了量化两个偏微分方程之间的距离,本文采用Wasserstein度量,定义为:

对于两个离散分布,Wasserstein度量表示为:

使用Wasserstein距离度量,模糊集可以构造为:
S2={f(w)|DW(f,f0)≤dw}
(11)
式中:dw是确定模糊集大小的常数。当dw>0时,模糊集中存在无穷多个偏微分方程;当dw接近0时,模糊集收敛到经验分布f0。根据文献[13],dw表达式为:
dw=-log(α*)/N
(12)
f∈S2的置信水平至少为1-α*。显然,当N增大时,dw减小,这意味着数据越多,经验分布f0越准确。
Kullback-Leibler(KL)散度是另一个著名的概率分布距离度量。对于这两种度量方法,模糊集中的距离阈值在实际应用中都是一个关键参数。对于Wassertein度量,dw可以通过式(12)选择,而对于KL散度,这样的参数选择有点困难。此外,基于Wassertein度量的模糊集可以提供令人满意的样本外性能保证。所以本文选择Wasserstein度量进行研究。
将S2代入式(3),得到的概率不等式可以重新表示为以下形式:
(13)

除了范数约束式(17),目标函数式(13)和约束式(14)-式(16)都是线性的。然而,可以发现当p=1或p=∞时,式(17)为线性约束,当p=2时,式(17)为二阶锥约束。本文选择p=∞,q=1,且式(17)表示为以下线性形式:
2τn≤γ,∀n=1,…,N
(18)
2 算例分析
这里将本文模型与高斯混合模型(Gaussian mixture model,GMM)进行比较,并用华北地区风电场的实际数据进行检验,所用数据集为2006年1月1日至2015年12月31日的小时点预测和观测输出。为了检验200 MW斜坡事件的可能性,选择两个连续的小时,其中风电预测分别在[495 MW,505 MW]和[695 MW,705 MW]之间。从数据集中恢复1 083个数据对,在算例分析时,只估计了向上斜坡事件的概率,向下斜坡可以用同样的方法处理。在MATLAB R2018a中用YALMIP编制了线性程序和二阶圆锥程序,并用CPLEX 12.8进行了求解。
为了便于比较,采用GMM进行斜坡概率估计。GMM是多种高斯分布的混合体,可以描述服从任意分布的不确定性。本文GMM分布中包含了三种高斯分布,其中,基于GMM的模型、基于矩的模型和基于散度的模型计算得到的风电斜坡概率分别称为GMM-WRP、Moment-WRP和Div-WRP,根据历史数据观测到的风力发电斜坡概率表示为O-WRP。表1和图2比较了不同斜坡阈值RU的结果。可以观察到GMM-WRP和Div-WRP与O-WRP非常接近,而Moment-WRP总是大于它们。这是因为基于GMM的模型和基于散度的模型充分利用了历史数据的离散性,而基于矩的模型只考虑了两个分布参数,忽略了更多有用的信息。然而,考虑到预测误差的单峰性,当RU>280 MW时,Moment-WRP随斜坡阈值RU的增大而迅速减小,与GMM-WRP和Div-WRP相当。表1中,当RU=300 MW和400 MW时,GMM-WRP小于O-WRP,而Div-WRP总是大于O-WRP。这表明,与基于GMM的模型相比,本文提出的基于散度的模型可以提供更保守、更可靠的估计,以保证电力系统的安全运行。此外,表1列出了用给定阈值估计斜坡概率的平均计算时间,可以发现,基于GMM的模型比所提出的数据驱动模型花费的时间要长得多,这是因为其计算包括两个步骤:参数估计和基于蒙特卡罗的概率计算。

表1 不同模型估计的斜坡概率
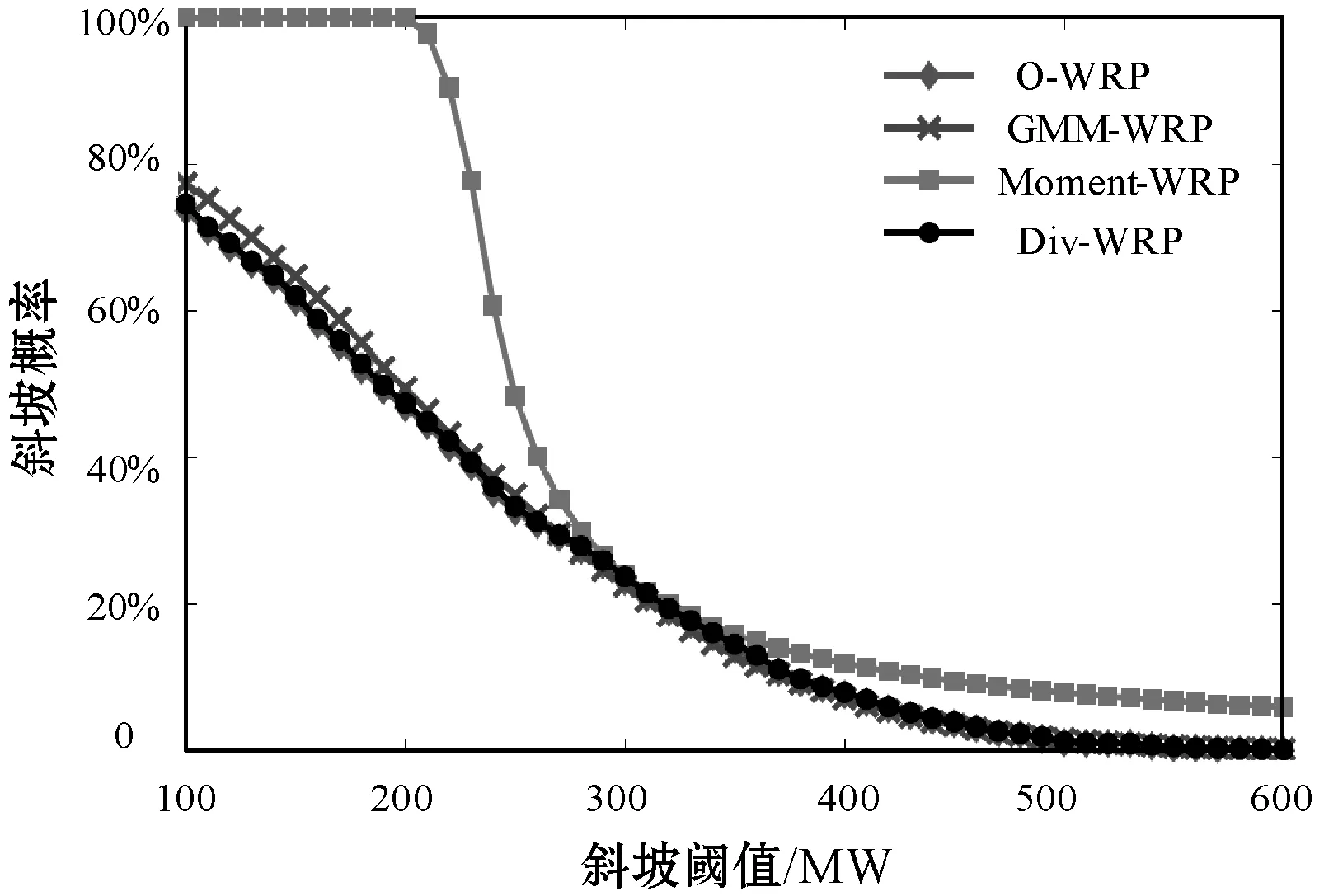
图2 不同模型计算的斜坡概率
在数据驱动方法中,历史样本数是影响估计结果的一个关键因素。为了研究其影响,本文首先使用文献[14]中的场景生成方法,基于上述1 083个数据对生成10 000个风电场景。随后,从10 000个场景中随机选取一组具有给定元素数的样本,测试三个模型的性能,此过程重复100次。RU=300 MW的结果如图3所示。随着抽样数据的增加,三种模型的波动率均减小,说明样本数对概率估计的稳定性有显著影响,而且矩模型的波动率明显小于GMM模型和散度模型的波动率,因为其使用的历史数据信息最少,所以几乎不受样本数变化的影响。

(a) 基于GMM的模型
表2给出了不同RU值和采样数据NS情况下估计斜坡概率的统计信息。采样数据越多时,斜坡概率的标准差和其限值之间的差异会显著减小。当NS≤200时,GMM-WRP和Div-WRP比Moment-WRP更敏感,因为这两个模型中使用的色散信息必须基于一定数量的样本,而矩模型对中等数据的敏感度较低。当NS≥400时,GMM-WRP和Div-WRP在估计精度上要明显优于Moment-WRP。然而,GMM-WRP估计可以是乐观的,也可以是悲观的,而Div-WRP总是保守的,这可以从RU=300 MW和400 MW时的平均值观察到。

表2 不同NS和RU值下斜坡概率的统计信息
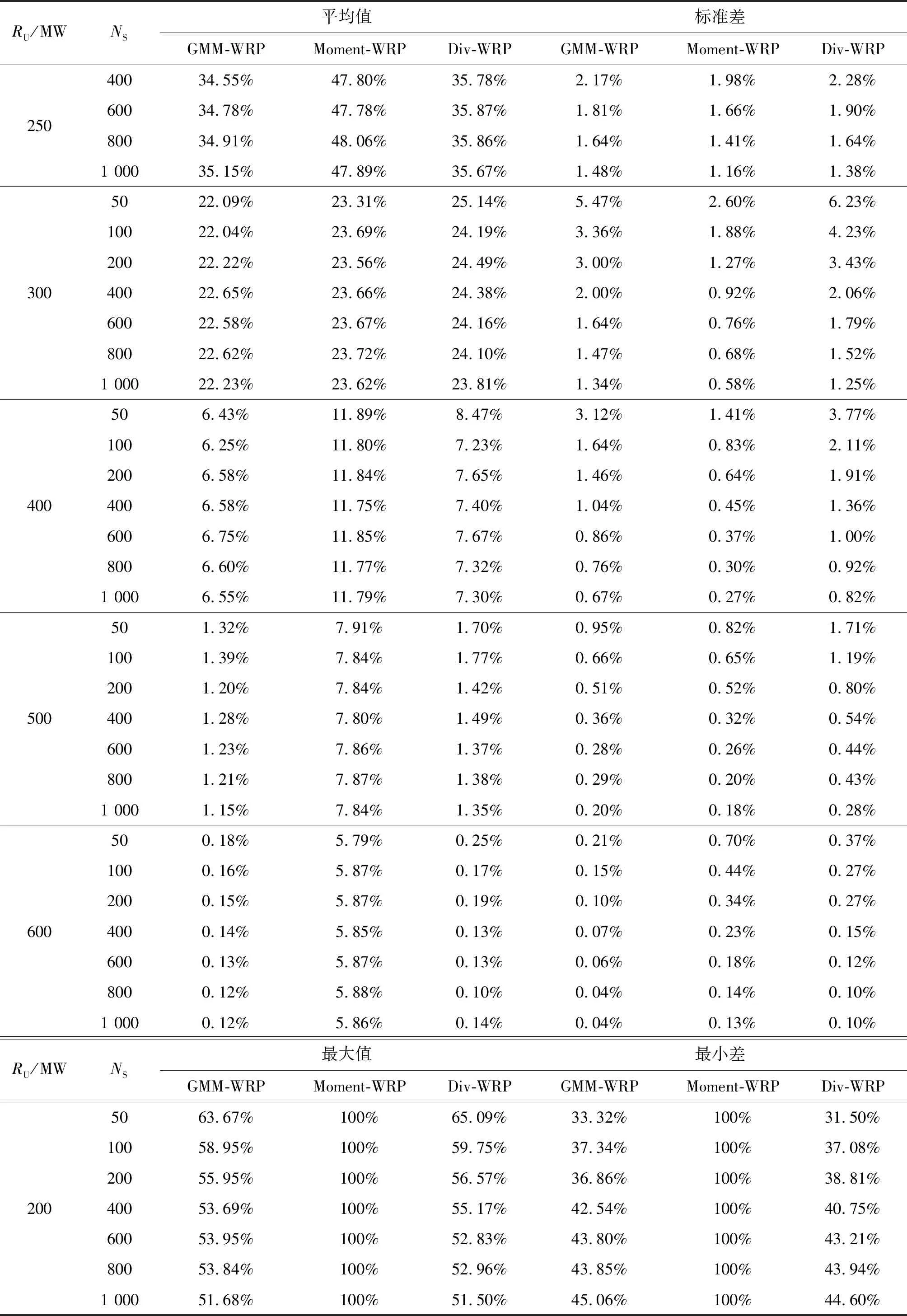
续表2

续表2
综上所述,对于系统调度员来讲,当只有有限的历史数据时,建议使用基于矩的模型。即使在完全没有数据的情况下,如果对平均值和平均绝对偏差提供适当的猜测,也可以应用该模型。相反,在数据量较大的情况下,由于散度模型可以有更精确的估计结果,且具有分布鲁棒性保证,因此可以使用散度模型来限制斜坡事件的概率上限。
3 结 语
本文提出了一种基于数据驱动概率的不等式模型,在给定斜坡阈值下,用于估计发生风电斜坡事件的概率上限。利用风电时间信息和风电出力的单峰性构造了模糊集,在构造基于散度的模糊集时,使用了Wasserstein标准度量两种概率分布之间的差异。在此基础上建立了不确定量化模型,其优势在于不需依赖不确定因素的精确分布,并且使用了计算上可处理的凸优化。最后,表3中给出了本文讨论模型的性能比较和总体评价,作为应用选择的参考。

表3 不同模型的性能
猜你喜欢
数学年刊A辑(中文版)(2022年1期)2022-08-20 08:50:04
数学大世界(2021年4期)2021-03-30 00:44:24
数学物理学报(2019年6期)2020-01-13 06:08:08
当代陕西(2019年6期)2019-04-17 05:03:50
数学物理学报(2018年3期)2018-07-17 06:15:30
天津诗人(2017年2期)2017-11-29 01:24:12
山西大同大学学报(自然科学版)(2016年2期)2016-12-12 03:19:12
华中师范大学学报(自然科学版)(2016年1期)2016-11-30 03:42:14
佳木斯大学学报(自然科学版)(2014年4期)2014-07-09 01:59:58
有色金属设计(2014年4期)2014-03-11 19:43:11
