
基于词向量的多维度正则化SVM社交网络抑郁倾向检测方法
2022-03-18 06:17贾宝龙杜依宁
计算机应用与软件 2022年3期
王 垚 贾宝龙 杜依宁 张 晗 陈 响
(北京世相科技文化有限公司 北京 100102)
0 引 言
微博是一种开放化的互联网社交服务,人们可以通过微博分享自己的心情、经历或故事。微博提供的评论、超级话题等功能,使人们能快速找到志同道合的朋友。海量的微博文本中蕴含着大量的情感。微博的文本内容成为抑郁倾向检测的主要数据来源之一。
国内外对于社交媒体文本内容的情感分析方法主要包括统计学方法和机器学习方法。统计学方法通过统计高频词,构建情感词典来分析文本内容的情感倾向。高一虹等[1]基于数据统计来分析抑郁症患者在现实生活中和社交媒体上的表现,发现抑郁症患者在社交媒体上发微博的频率更高,微博的文本内容中的负向情感更明显。林晔[2]对当时引起巨大轰动的“走饭”和“醒醒我们回家了”两个微博账号进行了统计分析,发现在实施自杀前,抑郁患者会反复、频繁地表达自己的抑郁、痛苦和自杀意图,纠结于生死之间。虽然基于统计的方法能够一定程度上分析出微博用户的情感,但是忽略了用户信息,并且过分依赖分词的好坏,因此不能准确地评价用户的抑郁倾向。
基于机器学习的方法是通过将微博文本、博主简介和博主标签等特征抽象为向量,构建分类器进行训练。施志伟等[3]通过问卷调查得到有抑郁倾向的用户,获取他们的微博文本数据,使用支持向量机模型进行有监督学习,准确率达到82.35%。但是其训练数据单一,只考虑了微博文本的内容,没有考虑发博人的性别、情感等因素。为了考虑更多的有效信息,Peng等[7]增加了发博人简介、发博人行为等特征,对比了传统支持向量机、朴素贝叶斯、决策树和K-近邻等算法后,提出一种多元支持向量机模型,准确率达到了83.5%,明显高于其他几种分类算法,但由于数据量较少,模型的泛化能力不足。Hao等[8]提出了一种基于两种分类器的检测方法,首先训练朴素贝叶斯分类器,并生成一个抑郁患者的常用词词典,然后使用线性分类器加入更多的特征,得到了准确率较高的分类器。方振宇[9]提出了基于Word2vec词向量的神经网络分类模型,将用户情绪向量与微博内容向量进行拼接作为用户特征向量,准确率达到了86.5%,但是忽略了用户的个人属性信息。为了解决上述存在的问题,本文在使用微博文本作为样本特征的基础上,将用户的情感、性别和发博频率融入到SVM的目标函数中,提出了一种基于词向量的多维度正则化SVM的社交网络抑郁倾向检测方法,并通过多组对比实验验证了该方法的有效性。
1 相关工作
1.1 抑郁症
抑郁症[11]是一种心理障碍或情感障碍,是最常见的精神疾病之一,主要表现为兴趣减退、认知功能受损和情绪紊乱。据统计,抑郁症患者的终身患病率为13.2%[12],大约有25%的女性患过抑郁症,大约有10%的男性患过抑郁症[13]。由于基层医疗机构对抑郁症的认识不充分,仍存在着普遍的一高两低现象,即高患病率、低诊断率、低治愈率。
1.2 数据的收集
使用的数据来自新浪微博,选择352位有明显抑郁倾向的博主的35 962条微博文本作为正数据,323位非抑郁症患者博主的72 697条微博文本作为负数据。筛选后得到28 654条微博文本的正数据,58 569条微博文本的负数据。经过3位心理学系的硕士研究生进行交叉检验,仅有10位用户存在争议,说明数据的可信度较高。
1.3 数据的清洗
微博内容数据形式多样,包含大量“脏”数据,所以需要对数据进行清洗,通过人工观察或统计发现主要有以下形式的“脏”数据:(1) 非文本信息(图片和视频等);(2) 广告数据以及非原创数据(文本中包括投票、打榜、影响力和人气演员等);(3) 部分干扰字符(@xxx,#xxx超话#等);(4) 长度小于7个字的微博文本;(5) 不规范表达方式(emoji表情、颜文字等)。
清洗前和清洗后的数据如表1所示。

表1 数据展示
2 抑郁倾向检测方法
本文提出的抑郁倾向检测方法主要包括两部分,分别为构建用户向量、构建多维度正则化SVM,如图1所示。
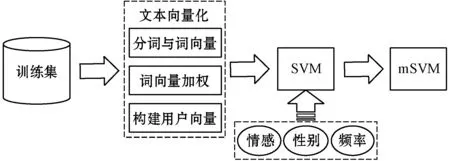
图1 多维度正则化SVM检测模型
首先,微博文本的向量化主要包括:(1) 对微博文本的分词;(2) 获取每个词语的腾讯词向量;(3) 将词向量进行特征加权计算句向量;(4) 根据句向量构建用户向量。然后,进行多维度正则化SVM的有监督学习。
2.1 构建用户向量
2.1.1分词与词向量
腾讯词向量是腾讯AI实验室在2018年开源的一个大规模、高质量的中文词向量数据集。该数据集在多个方面较现有公开数据集均有改善。在覆盖率上,该数据集包含了超过800万的中文词汇,覆盖了更多的短语,包含了近两年的网络用语。在准确性上,该训练算法使用的是腾讯自研的Directional Skip-Gram(DSG)算法[14],它改进了被广泛使用的如Word2vec词向量模型中的词向量训练算法Skip-Gram(SG)[15],在文本窗口中词对共现关系的基础上,加入了词对的相对位置的考量,以此提高词向量语义表示的准确性。所以用它来作为微博内容分词后每个词的词向量[18]是合理有效的。
由于微博文本包含大量网络用语,而百度分词比较善于针对网络文本进行分词,同时也能通过构建自定义词典提高特殊词汇的分词效果,所以,首先利用百度分词API进行分词,然后获得对应的腾讯词向量。对于腾讯词向量库中不存在的抑郁词,则选择腾讯词向量库中与其最相近的词作为替代。对于不在抑郁词典中且腾讯词向量未收录的词语,将其赋值为0向量,便于之后的计算。
2.1.2构建微博文本向量
首先使用TF-IDF[19]进行特征加权。特征权重Wij的计算式为:
Wij=TFij·IDFij
(1)
式中:TFij表示特征词ωi在文本dj中出现的次数,IDFij表示特征词ωi的逆文档频率。为了能够一定程度上增强抑郁词权重,IDFij通过大规模的微博文本数据集计算。
为了提升抑郁词对于整条微博文本的影响,赋予抑郁词相对较大的权重值,赋予非抑郁词权重1。即加权后的词向量表示为:
Vi=TVi·Wij·Wd
(2)
式中:TVi表示该词的腾讯词向量,Wij表示该词的TF-IDF值,Wd表示该词的抑郁词权重。
2.1.3构建用户向量
根据2.1.2节得到的加权词向量,通过对应维度求均值的方式计算整条微博文本的向量表示,该向量表示为:
cd=(xd1,xd2,…,xdt)
(3)
式中:xd1表示当前文本中所有词向量第1维的均值。因为腾讯词向量的纬度是200,所以由此得出的文本向量也是200维,进而可得到用户的矩阵表示为:
(4)
式中:n表示用户的微博总条数。最后,通过将矩阵Mi按行求均值得到用户的向量。
2.2 多维度正则化
支持向量机[20]是一种优秀的机器学习分类模型,在面对非线性以及高维度分类问题上,效果比其他二分类方法更好,因为SVM能够接受高维特征空间和稀疏特征向量,所以在文本分类上有很好的效果。面对微博文本分类这个非线性问题,直接利用线性化的SVM是无法分类的,所以将决策函数的限制条件进行一定的放松,使它对于一些异常或极端样本点有一定容错空间,SVM模型表示为:
yi·[(WT·xi)+b]≥1-ξi1≤i≤N,ξ≥0
(5)

(6)

由于文本在经过前期词向量信息累加的处理后,所得到的数据的维数已经较高,所以还需要进行变换,这也是SVM的一个优势,它通过构造可以将已有数据x映射到高维空间H的映射函数,即φ(xi)。因为此类映射的维度理论上是可以无限维的,无法显式求出,所以SVM引入核函数[21]来实现不需要知道映射向量就可以实现分类的目的。核函数形式如下:
k(xi,xj)=φ(xi)Tφ(xj)
(7)
这里通过高斯核函数实现同等映射:
(8)
通过将式(6)转化为对偶问题的方式,利用KKT条件,构造拉格朗日函数,求得最终的分类函数如下:
(9)
式中:αj是拉格朗日乘子;x表示待分类文本。
经过前期相关研究工作,发现有抑郁倾向的用户存在以下明显特征:(1) 发微博频率明显高于正常用户;(2) 有明显消极情感;(3) 女性人数明显高于男性用户,比例大致为3 ∶1。因此将用户发微博频率、用户文本情感和性别特征加入到目标函数中,使SVM学习到的超平面更加准确,因此在原本的目标函数上增加一项由发微博频率、情感和性别组成的正则项,表示为:
ωi=ωe·ei+ωs·si+ωf·fi
(10)
式中:ei表示用户的负向情感概率;si表示用户的性别分数;fi表示用户的发微博频率分数。因此,改进后的目标函数为:
(11)
式中:W表示ωi的影响力权重。
3 实 验
3.1 实验设计及评价标准
实验包括以下四种算法:(1) 使用腾讯词向量训练SVM;(2) 使用腾讯词向量训练mSVM;(3) 用TF-IDF加权词向量训练mSVM;(4) 使用TF-IDF和抑郁词加权词向量训练mSVM。为了便于描述,算法1用SVM表示,算法2用mSVM表示,算法3用mSVM-T表示,算法4用mSVM-TW表示。
在四种算法上进行3组对比实验,分别为:(1) 随着迭代次数准确率的变化趋势;(2) 随着迭代次数召回率的变化趋势;(3) 随着迭代次数F1值的变化趋势。准确率、召回率和F1值的计算公式如下:
(12)
(13)
(14)
(15)
式中:TP表示真例判断为正样本;FP表示假例判断为正样本;FN表示假例判断为负样本;TN表示真例判断为负样本。
3.2 实验结果与分析
为了能够更准确地反映四种算法的准确率、召回率和F1值随着迭代次数的变化情况,在当前迭代次数下的准确率、召回率和F1值均为独立训练10次取均值。四种算法的准确率随迭代次数的变化趋势如图2所示。
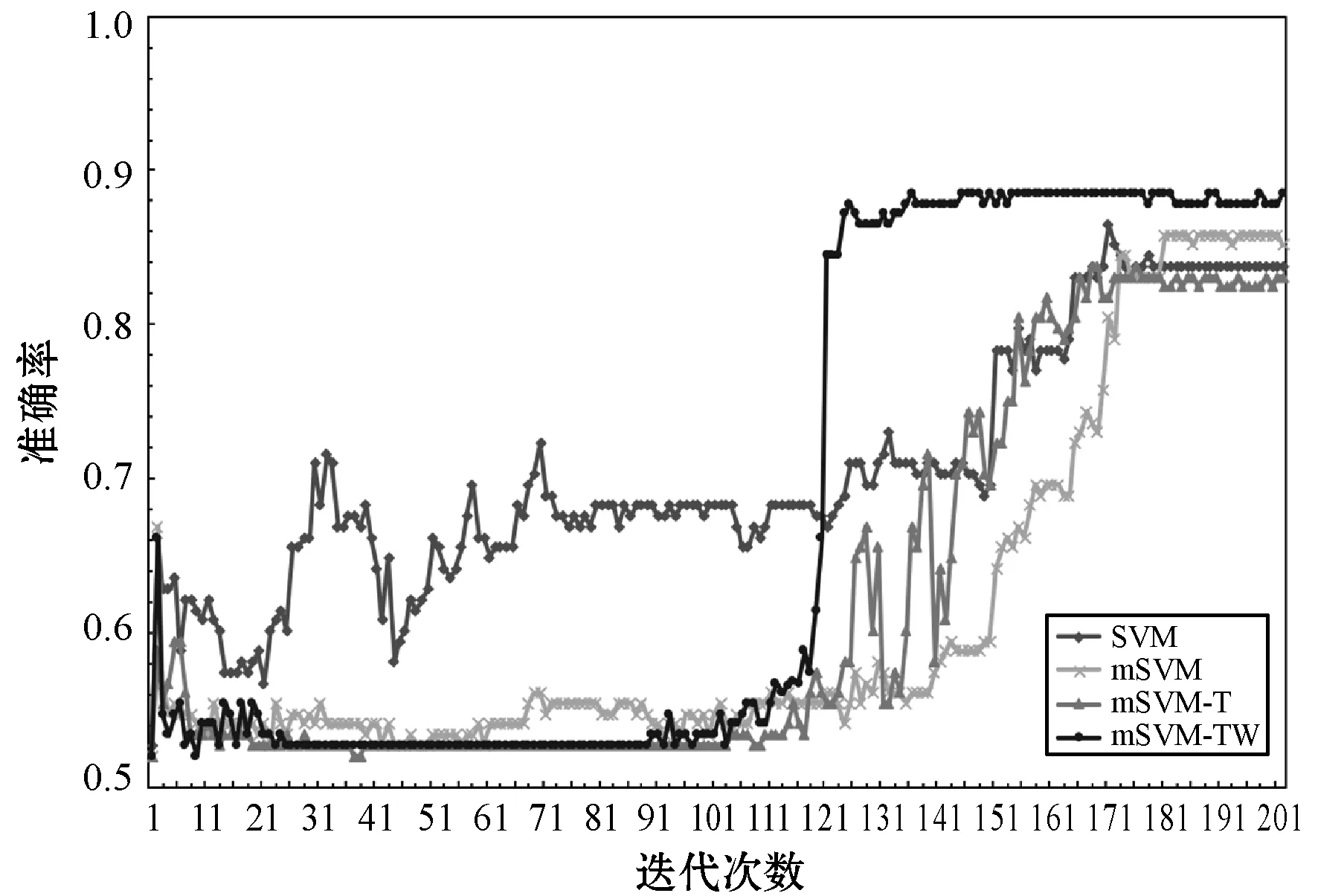
图2 准确率变化趋势图
由图2可看出,mSVM-TW在140次迭代后收敛,达到最优值0.89±0.05。SVM和mSVM-T在170次迭代后收敛,分别达到0.83±0.05和0.82±0.05,mSVM在180次迭代后收敛,达到0.85±0.05。在收敛速度和最优值上,mSVM-TW均明显优于其他三种算法,主要原因有两点,一是输入向量通过TF-IDF和抑郁词加权,改变了原始数据分布,使得数据的分布对于当前的任务更加清晰,因此更容易被分类;二是通过情感、性别和发博频率使得目标函数的损失变得更小,因此收敛速度更快。
召回率随迭代次数的变化趋势如图3所示,从收敛速度和最优值,mSVM-TW也明显优于其他三种算法。mSVM-TW的最优召回率达到0.86±0.05。在迭代次数较低时,召回率异常偏高,甚至达到1.0。这是由于当迭代次数较低时,分类器处于欠拟合状态,此时分类器将所有样本判断为正样本,因此召回率会异常高。随着迭代次数的增加,处于分类超平面较近的真负或假正样本逐渐增多,因此召回率逐渐下降,并趋于稳定。

图3 召回率变化趋势图
F1值随迭代次数的变化趋势如图4所示,从收敛速度和最优值来看,mSVM-TW也明显优于其他三种算法,最优F1值达到0.89±0.05。

图4 F1值变化趋势图
综合上述实验结果,mSVM-TW在各评价指标上均有较大提升,说明通过词向量加权和多种特征的正则化能够有效提升传统SVM在抑郁倾向检测任务上的分类性能。
4 结 语
本文提出的基于词向量的多维度正则化SVM方法,由于在传统SVM的损失函数中融入情感、性别和发微博频率,所以在SVM的监督学习过程中,能够根据用户的多种特征约束损失函数,使得学习到的分类超平面更加准确,泛化能力更强。因此,对于那些文本特征不够明显的用户也能较好地分类。
由于微博内容的形式具有多样性,除了文本,还有图片、视频、音频等,所以只考虑微博的文本内容会丢失用户的大量有效信息。因此,下一步考虑加入用户更多的有效信息,构建多模态的抑郁倾向检测模型,进一步增强模型的性能。
猜你喜欢
作文大王·低年级(2022年3期)2022-03-19
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
校园英语·月末(2021年13期)2021-03-15
健康体检与管理(2021年10期)2021-01-03
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
小学生作文·小学低年级适用(2018年12期)2018-04-11
校园英语·下旬(2016年2期)2016-03-18
