
面向多面体模型的静态控制块识别扩展方法
2022-03-18 05:01:06夏文博胡伟方郭浩然
计算机应用与软件 2022年3期
夏文博 胡伟方 郭浩然
1(郑州大学信息工程学院 河南 郑州 450000)2(北京空间信息中继传输技术研究中心 北京 100094)
0 引 言
近年来,随着以深度学习算法为代表的人工智能技术不断应用于各个领域,大量计算密集型程序对计算性能的要求逐步增高。为了利用程序中存在的并行性与数据局部性,确保程序快速执行,降低设备功耗,通用CPU提供了多级缓存、多核、SIMD部件,甚至GPU等专用的计算加速器也用于提升程序的执行效率[1]。更加复杂的并行层次及存储器层次结构给编译优化带来了新的挑战。
计算密集型程序中往往存在着大量的循环,例如在图像处理程序中,计算核心耗时一般在图像矩阵的运算,对这些运算进行处理时,需要多层循环来表示运算操作。将循环进行适当的变换,并且映射到不同目标平台以充分发掘程序中的并行性和数据局部性则需要编译优化的支持[2]。目前,大多数工业级编译器虽然支持基本循环变换、向量化、自动并行代码生成等功能,但是一旦涉及需要多种复杂转换才能确保优化所需的数据局部性及并行性的情况,常规编译优化过程是难以分析并进行处理的,这严重限制了编译器对程序性能的优化能力。
多面体模型[3]是一种集成了静态控制块分析、依赖分析、循环调度变换于一体的数学表示方法。多面体模型比传统抽象语法树(Abstract Syntax Tree,AST)表示更准确地描述了程序静态信息与动态特性。作为一种数学模型,多面体模型可以更抽象地描述循环嵌套,更加精确地计算语句实例之间的依赖关系。同时,多面体模型表示可以自然地表示多种循环变换方法,例如循环交换、循环倾斜等。利用多种循环变换方法,有利于发掘程序中的向量化机会,生成SIMD[4]代码,也可以利用循环分块等变换,帮助生成面向GPU体系结构的SIMT(单指令多线程)代码[5]。随着GPU、AI芯片等多种全新体系结构的出现,多面体编译优化已成为一种越来越流行的技术。
对程序应用多面体优化时,首先需要找到可以被转换成多面体表示的相关代码段,称为静态控制块(Static Control Parts,SCoP),并为它们创建一个多面体模型描述。然而,SCoP的构成必须非常规范,实际程序中往往具有许多限制循环嵌套被识别为SCoP的非规则因素。在通过对SPEC2006[6]测试基准的测试中发现许多测试用例程序中的相关循环代码段存在诸多限制SCoP识别的问题。例如图1中的代码,在进行SCoP检测的过程中,由于大多数编译器的别名分析相对保守,编译器无法证明循环嵌套中所有数组访问不会造成重叠,会将其识别为存在别名问题,多面体识别算法会判定该循环为非SCoP。

图1 带有可能别名的循环结构
为了扩展多面体编译的实用性,目前已经有一些学者对限制静态控制块识别的若干非规则因素进行了研究。Benabderrahmane等[7]利用任意边界建模循环结构,解决了while循环的多面体建模处理。Strout等[8]研究了稀疏矩阵的多面体编译优化技术,并基于运行时重排序转换技术,扩展了非仿射数组下标在多面体模型中的应用。另外也有开发人员选择使用一些工具来缓解多面体建模不充分的问题,例如:SCoP的解析器Clan[9],要求开发人员手工标记每个SCoP来手动帮助编译器识别更多的SCoP,但是这种做法也给程序开发人员带来了许多额外的负担,需要进行大量的人工分析来确定SCoP的位置及范围。
本文首先使用SPEC2006测试集进行多面体建模测试,分析并总结出实际应用程序中阻碍SCoP识别的主要因素。针对多面体建模的多种主要限制因素,基于LLVM编译框架提出了两种提升多面体建模能力的解决方案:(1) 针对多面体模型的SCoP识别限制中的复杂循环格式问题,在编译流程中添加循环规范化遍历,对待分析的循环进行规范化处理,消除部分不规范因素的影响。(2) 针对造成多面体建模失败最多的非仿射数组访问模式与循环边界的问题,利用LLVM的静态程序分析信息,提出了一种定值替换的方法来解决该问题。
1 SCoP识别限制分析
为了分析程序中限制SCoP识别的因素,对SPEC2006基准测试中的C语言程序进行了SCoP检测测试与评估。在LLVM的多面体建模模块中的SCoP识别功能函数中加入诊断信息输出语句,统计导致SCoP识别失败的原因,分析得出的主要原因如下:
(1) 非仿射的数组访问表达式。在多面体模型中,要求所有的数组访问表达式或条件表达式都必须是输入参数或归纳变量的仿射表达式,否则SCoP的识别算法不会将该代码所在的区域视为SCoP,从而阻碍了多面体模型对其进行优化。举例如图2所示。

图2 非仿射表达式
此外,SCoP中所有循环迭代的上下限也必须是输入参数或归纳变量的仿射表达式。
(2) 别名。当编译器对循环的分析结果无法证明两个内存访问的基地址是否不相交时,特别是当指针与参数值相关而不是全局变量或堆栈分配的内存空间地址时,编译器的别名分析就会保守地将其识别为指针别名,导致对该内存访问所在的程序段的多面体建模失败。
(3) 函数调用。在多面体模型中,调度变换需要首先分析并尝试消除程序中存在的依赖关系。然而,在具有外部函数调用或间接函数调用的循环中,依赖关系将变得非常复杂。基于多面体模型的依赖关系分析方法也不能给出程序中精确的数据依赖关系。所以,在SCoP的检测过程中,往往会排除包含函数调用的相关代码段。
(4) 非规范化的归纳变量。在多面体模型对循环嵌套的抽象表示中,循环嵌套中某个语句的迭代域会被表示成多维仿射空间中的有界凸多面体,该多面体中每个整数点都代表该语句的一个执行实例。这使得在多面体建模过程中,对循环中的归纳变量具有一定的限制:在循环每次迭代中,迭代变量递增或递减幅度要求为1。编译器在多面体模型建模之前,应尽量将循环中的归纳变量等进行规范化处理。
(5) 复杂的控制流。在多面体模型中,优化需要得到代码段中的循环的各个信息,如果程序代码段中出现了比较复杂的终止符(例如:switch、goto等)或者具有复杂形式的控制流(通过while和for或者if结构无法表示),多面体模型将难以对程序的静态信息与动态特性进行建模,不能识别为SCoP。
2 基于LLVM静态分析的识别优化
LLVM[10]是一组用于构建编译器的工具和库。它围绕一种和语言以及平台无关的中间表示(LLVM-IR)构建,提供了先进的程序分析、优化和目标代码生成等模块功能。除了支持x86-32、x86-64和ARM等后端,还有针对大多数GPU加速器甚至硬件描述的目标代码生成。LLVM支持目前大部分常用的编程语言的静态和即时编译。LLVM模块化的结构、有良好可读性的IR和一系列有用的工具,便于开发人员进行基于LLVM的编译模块开发。基于LLVM的多面体工具的静态控制块检测实现流程如图3所示。

图3 SCoP识别流程
2.1 复杂循环格式的优化
LLVM-IR是LLVM编译器的中间表示语言[11]。将源程序降级到LLVM-IR之后,源程序的复杂性就会显著降低,并且生成的LLVM-IR没有高级语言中的循环表示,只有跳转语句和goto语句。源程序中的数组或仿射表达式也转换为指针运算和三地址格式的操作。在这种表示中,源程序中的所有必要信息都会通过LLVM提供的内部分析Pass重新计算。所以,在LLVM-IR中,可以使用循环检测或支配树信息等简单分析来验证待分析程序段是否只包含结构化控制流,也可以使用更复杂的分析来检查别名或提供关于函数调用副作用的信息。这里本文选择运行一组LLVM规范化Pass,进一步规范化代码,解决程序中不规范的循环格式。具体实现如图4所示。
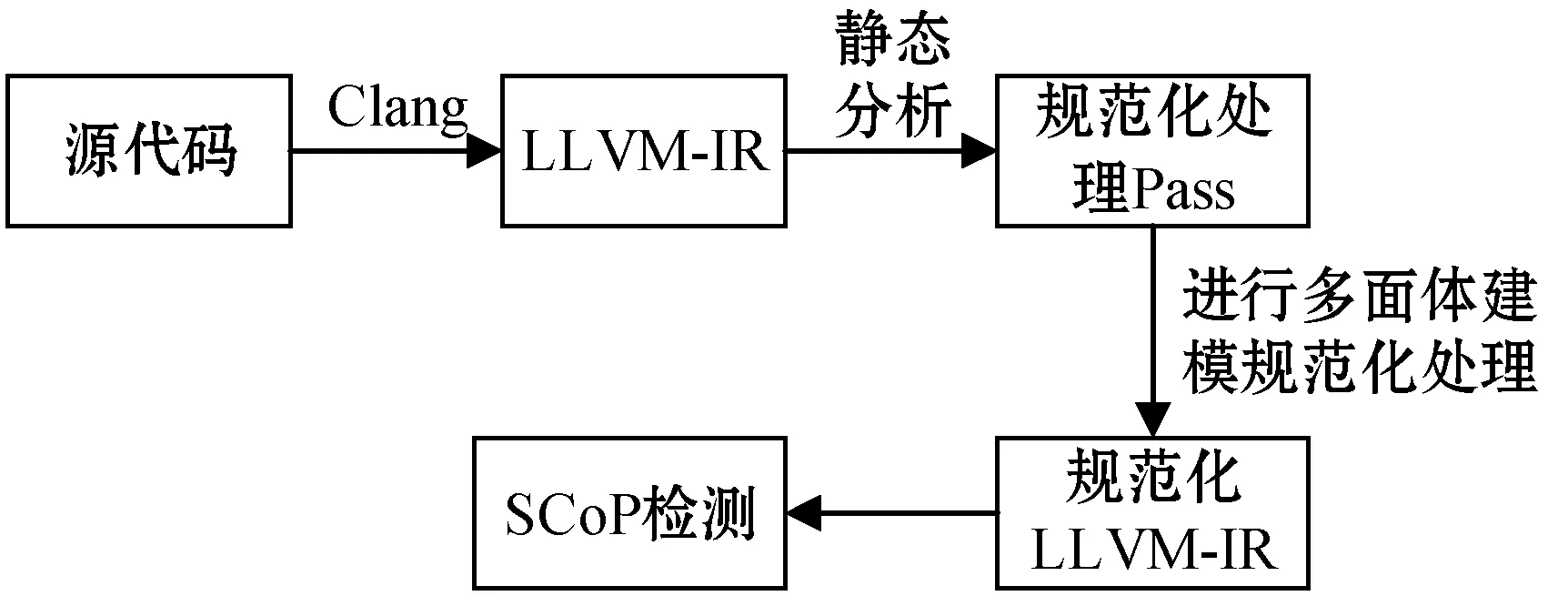
图4 不规范循环格式处理流程
LLVM编译框架具有非常完备的程序变换和规范化Pass集。其中包括基本别名分析、内存到寄存器的提升、库调用的简化、指令简化、尾部调用消除、循环简化、闭环SSA表单计算和归纳变量规范化。表1中给出了一些限制SCoP识别的非规范因素相应的解决方案,将这些方案加入到规范化Pass中,用以解决多面体的建模的一些限制。

表1 不同限制因素解决方案
2.2 非仿射问题的优化
如图5所示,多面体模型不支持维数是未知的数组。一种常用的做法是对数组进行降维。使用一维数组并“手动”执行索引算法来实现n维数组。这样就可以在一维数组上创建仿射下标,使用静态分析可以推断出该一维数组是二维数组的映射访问。但是,目前LLVM编译器中并没有相关的转换实现。另外,这样的转换也会导致代码的复杂度增加,可能会导致静态分析失败,对后续的分析造成影响。所以,非仿射表达式的主要问题是:虽然表达式的值是固定不变的,但是其表达式是非仿射的,并将其判定为不满足多面体模型建模条件。

图5 非仿射表达式
本文基于LLVM分析Pass得到的循环分析结果,对非仿射的表达式进行结果判断,通过保持恒定的参数值来消除上述形式的非仿射表达式对多面体建模的影响。具体所用的分析如下:
(1) 静态单一赋值(SSA):SSA表示的抽象视图是一种声明性语言[12],通过插入额外的标量变量,使每个定义都是唯一的。标量变量的赋值可以是表达式的结果,也可以是位于目标基本块中控制流节点的phi节点的结果。例如,图6中所示的程序代码通过添加新的变量名和在控制流节点处合并值的phi节点,将其转换为SSA。

图6 SSA转换
循环phi节点定义递归表达式:循环phi节点的第一个参数定义初始值,第二个参数使用自引用定义递归。例如:
a=loop_1-phi(0,a+1)
b=loop_1-phi(0,2×a)
a在第一次迭代时定义为0,并且对所有其他迭代使用自引用表达式a+1;b在第一次迭代中定义初始值0,接着是对于所有后续迭代引用另一个loop-phi节点2×a的表达式。
循环close-phi节点用来计算loop-phi节点在循环中定义的最后一个值:它们对应于部分递归函数的min运算符。例如:
c=loop_1-cloase-phi(b,a>10)
c被定义为当a变为大于10时第一次迭代的b的值:在示例中,c的值可以被静态地计算为22。
(2) 标量演化分析(SCEV):从上述SSA表示的抽象开始,通过识别循环phi节点、循环闭合phi节点和派生的标量声明来分析标量变量演化函数。循环phi节点由初始值和包含自引用的表达式来声明,当自引用与当前循环中的标量值或不变表达式一起出现在加法表达式中时,SCEV表示具有线性或仿射演化的递归函数。循环close-phi节点被声明为一个由表达式计算的最后一个值,该表达式可能在循环中发生变化,然后SCEV表示一个部分递归函数。所有其他标量声明都可以表示为从其他递归和部分递归函数的声明派生的SCEV。SCEV分析将为上述运行示例提供以下表达式:
a={0,+,1}_1
b={0,+,2}_1
c=22
a的SCEV分析其初值为0,每次迭代值线性递增加1。类似地,b的初值为0,每次迭代递增加2。由于c的计算是在循环外,它的值并不随循环的迭代而变化,所以,在这里可以通过SCEV的静态分析得到表达式c的值为常量22。
(3) 迭代次数的分析:提供一个表示循环执行的次数的SCEV分析。迭代的次数被计算为闭合phi节点(close-phi)的SCEV,或者SCEV的最后一个值,从0开始,在循环的每次迭代中增加1。在运行的示例中,迭代数可以在退出循环时计算为a的值,并可以静态地计算为11。
通过上述的分析可知,可以通过LLVM编译器中的循环分析Pass得到程序中循环嵌套的中表达式的静态分析值,再从中筛选出循环中重复出现的,可被定值为常量的参数值。然后,将其插入到非仿射参数或者表达式中,通过替换定值让表达式保持恒定,并创建一个新的定值循环版本。最后将调度代码插入到相应的循环检查基本块中,以在运行时确定实际参数值是否存在符合要求的版本。如果不符合,则使用原始版本。这样可以将一些原本不能看成仿射的,但是循环上下界都是常数值的非仿射表达式表示成为仿射的,从而对更多的循环进行多面体优化。其具体实现如图7所示。

图7 定值版本循环生成流程
多面体模型代码检测阶段,对循环代码进行分析时,如果发现循环中存在非仿射表达式,调整其判断策略:将其进行标识为待分析的仿射表达式;再判断是否存在专用的循环版本,如果存在则识别为SCoP,进行多面体优化,如果不存在,则判定为非SCoP,让其按照原来的方案进行处理。实现流程如图8所示。

图8 基于静态分析的非仿射表达式处理流程
3 实验与分析
3.1 测试指标与实验平台
在多面体优化过程中,SCoP的识别是优化的基础。本文进行了如下两个方面的测试:SCoP识别数目的优化测试和优化后的程序运行加速比测试。
(1) SCoP识别数量测试:测试优化前和优化后,识别出来的符合多面体建模条件的静态控制块的平均数目,通过对比得出优化的效果,验证本文提出的非规范因素消除方法的有效性。
(2) 程序运行加速比测试:首先进行不引入多面体优化的基准测试;之后分别测试初始多面体优化工具和经过本文优化后的多面体优化工具测试结果。通过对比两次测试相对于基准测试的加速比,来分析SCoP识别数目对多面体优化的影响。
测试平台采用处理器为Intel(R) Xeon(R) CPU E5- 2682 v4 @ 2.50 GHz,128 GB内存,操作系统为CentOS7;编译器版本为LLVM- 8.0.0。
3.2 测试内容
为了对比测试优化方案在实际应用中对SCoP检测能力的优化效果,实验采用SPEC2006测试集来进行测试。分别在LLVM中的多面体工具和经过本文中设计的优化后的LLVM多面体工具上进行测试,得出识别到的SCoP数目的平均值。
LLVM编译器可以使用OPT工具来手动实施对LLVM-IR的单独优化,使用-polly-detect选项来直接测试识别出的SCoP,其中-polly选项代表引入多面体优化。针对优化后的版本,本文添加编译选项-polly-canonicalize,利用LLVM标准化Pass来规范多面体检测代码,非仿射表达式的处理则使用-polly-opt-nonaff选项进行控制。
3.3 实验结果及分析
3.3.1识别率分析
为了更确切地表示基于LLVM的静态分析对消除多面体建模中SCoP识别的优化能力,实验依然采用SPEC2006的C语言测试用例。实验结果如图9所示,其中黑色部分表示优化前识别出的SCoP数量,8个测试用例共识别出296个SCoP。白色表示经过本文方法优化后识别出的SCoP数目,8个测试用例共426个SCoP,平均识别数目增加了1.4倍。除mcf的识别出的循环个数没有发生改变外,其余测试用例符合SCoP条件的循环个数都得到了提高。并且sjeng测试用例静态控制块数目提升最为明显,提升了约4.3倍。实验结果表明,基于LLVM的静态分析优化以及规范化方法能够有效提升SCoP的识别率。

图9 动态优化前后静态控制块数量对比图
3.3.2加速比分析
本文采用多面体模型编译测试集PolyBench作为加速比测试的测试用例来测试SCoP识别数目对多面体优化效果的提升效果。PolyBench[13]是一个具有30个数值计算的基准测试套件,包含了线性代数计算、模板计算、图像处理和数据挖掘的计算内核。在计算加速比时,先使用经过LLVM编译器最优选项-O3优化后,获取的程序运行时间作为基准时间,通过使用和不使用本文中的SCoP识别优化方法,分别测试程序运行的时间,通过与基准时间相比较计算出各自的加速比。
测试结果如图10所示,其中黑色部分表示在没有进行SCoP识别优化情况下取得的加速比,白色部分表示在对SCoP识别方法进行改进后的情况下所取得的加速比。经过优化后,测试用例中的3 mm运行速度最高相对于优化前提升了2.3倍。大部分情况下,加速比有了相应的提升,说明基于循环格式规范化和定值替换的方法可以避开多面体建模的一些限制,提升SCoP的识别率,发掘更多的多面体优化机会以获得性能提升。然而,也有一些测试用例出现了加速效果降低的现象,例如:mvt、symm。这种情况的出现,主要是因为新增加的一些循环代码区域本身存在一些依赖或者其他原因,造成并行化优化失败。这样就会出现优化带来的收益,不能抵消多面体建模或者SCoP识别带来的时间消耗的情况,从而导致程序运行速度变慢。也有另外一种原因是SCoP识别数目增加后,并行处理这些静态控制单元,需要更加频繁地进行线程开启和同步,造成了线程开销增加的问题,抵消了程序并行运行带来的收益。要解决这个问题,需要后续对SCoP的处理算法进行改进。

图10 多面体优化加速对比
4 结 语
本文针对多面体建模有诸多限制的问题,对阻碍程序代码中实现多面体模型建立的因素进行了全面分析。对不规则的循环代码,在规范化处理Pass中整合了解决方案,对进行多面体建模识别的区域进行了规范化处理,解决了复杂的循环结构的简化和处理。针对限制多面体建模占比最多的非仿射表达式的问题,基于LLVM的静态分析中的标量演化,进行了预分析优化,将循环中不确定的变量参数,进行了定值化处理,生成了定值版本的循环,从而对非仿射问题进行了扩展。最后经过实验验证,本文所做的方法优化,可以有效提升SCoP的识别数量,增强了多面体模型的优化效果。
猜你喜欢
数学大王·低年级(2022年3期)2022-03-17 21:51:44
课外生活·趣知识(2021年8期)2021-08-24 02:25:39
数学物理学报(2020年2期)2020-06-02 11:29:10
安顺学院学报(2020年1期)2020-04-05 10:57:20
铁道通信信号(2020年7期)2020-02-06 09:04:50
现代计算机(2019年6期)2019-04-08 00:46:50
东华大学学报(自然科学版)(2018年1期)2018-06-29 03:35:26
金色年华(2016年11期)2016-02-28 01:42:38
组合机床与自动化加工技术(2014年10期)2014-03-01 02:22:05
商(2012年11期)2012-07-09 19:07:55
