
基于循环生成对抗网络的机器翻译方法研究
2022-03-16 11:19周湘贞
南京师大学报(自然科学版) 2022年1期
夏 珺,周湘贞,隋 栋
(1.黔南民族师范学院外国语学院,贵州 都匀 558000) (2.马来西亚国立大学信息科学与技术学院,马来西亚 雪兰莪 43600) (3.北京建筑大学电气与信息工程学院,北京 102406)
语言作为一种高级符号系统,本身就非常复杂,并且语言是一个复杂网络的观点已经被人们广泛地接受. 然而,智能语言处理[1-4]作为一种语言学习任务,通常是需要从一段未被预处理的语音中获得一系列可能的语音标签,并将语音信号转换为单词和子词单元,并将处理后的语音单元转换为我们需要的输出以实现语音识别和语言翻译的效果.
2001年,人们发现语言中连接单词的图与其他复杂网络具有相同的统计特征. 在这之后,不同语言单元组成的语言网络及其在不同语言中的关系受到了学者们的关注. 2012年,微软研究人员将前馈深度神经网络(FFDNN)应用于大词汇连续语音任务的声学建模,使用DNN而不是GMM-HMM. 该混合高斯模型可以提供更好的观测概率,引发了一波混合神经网络和隐马尔可夫混合建模[5-6]. 复杂网络的构成要素主要是网络节点和节点间边,而如何确定语言网络的节点和边呢?学者们提出了不同的构建语言网络的方法,主要包括可以根据同义词表确定原始词与其同义词之间的网络连接;可以根据词汇表进行语义连接;根据词在句子中的共现情况,可以构建语言的共现网络;通过标注依存句法的语料库,可以得到语言网络连接.
在声学建模过程中,DNN-HMM[7]通常使用左右相邻特征拼接在一起作为卷积神经网络的输入. 上下文窗口可以反映两帧之间的关系,这更符合实际情况. 为了获得更好的建模结果,输出在GMM-HMM中聚类或状态绑定后使用三音素(senone)来减少参数爆炸[8]的问题. 相邻音素中语音的每一个单词都相互影响. 当每个特征帧的长度之间有相关性时,必须考虑声学模型. 在以往的工作中发现,深层变压器是很难训练的,例如超过12层的变压器[9]. 这是由于优化网络模型的挑战:每一层的输出随着深度的增加而变化,导致不稳定的梯度,最终导致训练的收敛度不理想. 训练数据必须在卷积神经网络之间进行处理,即每一帧的标记数据、输入的特征序列和标记的特征序列必须具有相同的长度. 当使用大数据训练模型时,标记训练数据需要专业知识和大量的工作,而现有的模型需要在获取注释[10]时强制输入数据对齐和标记序列对齐. 强制对齐所使用的模型会有一定程度的精度偏差,导致标记错误. 对训练数据注释的依赖性和强制对齐问题限制了语音识别的进一步发展.
本文提出了一种将长期短期记忆网络和循环网络相结合的基于循环生成对抗网络的机器翻译方法. 首先,将LSTM顶层的Softmax向量输出连接到神经机器翻译模型上,并使用神经机器翻译解码方法减少了整个序列的损失,因此,我们可以在预测LSTM输出的预测概率中,正确地预测该序列的标签. 然后,将经过预处理的语音输入到特征提取模块并结合长时短时记忆网络循环提取语音特征;最后,将网络模型输出的语音与人工翻译的语音进行对比,并判别网络模型输出的语音特征与人工翻译的语音是否匹配,如果不匹配则继续优化生成网络. 实验结果表明,本文方法既关注了每个特征针的长度之间的相关性,减少了标记数据间的偏差,又解决了优化网络模型困难的问题. 本文设计的基于循环生成对抗网络的机器翻译网络模型,该模型主要有生成网络模型和对抗网络组成,并通过对抗网络优化生成网络的输出从而达到预期的结果.

图1 基于循环生成对抗网络的机器翻译网络Fig.1 Machine translation network based on cyclic generation countermeasure network
1 网络模型
为了解决处理语言中存在的网络模型优化困难、强制对其标记数据会出现精度偏差等问题,本文设计了基于循环生成对抗网络的机器翻译网络模型,网络模型如图1所示.
模型主要包括两大部分,分别为生成网络和判别网络. 生成网络是对未经过预处理的语音进行特征提取并翻译成需要的单词. 首先,模型主要利用了对抗网络的特点来优化生成网络,解决网络模型优化困难的问题;其次,在生成网络中使用了长期和短期记忆模块,缓解了由于强制标记数据而出现精度偏差问题;最后,模型经过优化训练保存生成网络的网络模型来处理自然语言. 判别网络则是通过判别生成网络的输出语音和人工翻译的语音是否相符,达到相符则输出“是”,否则输出“否”. 如果不符合则反馈给生成网络以优化生成网络,直到生成网络输出的语音与人工翻译的语音达到一定的相符度就会自动保存生成网络.
1.1 神经机器翻译模块
到目前为止,Dewangan等[11]和Shterionov等[12]提出了各种NMT框架. 其中,基于自我注意的框架(称为变压器)实现了最先进的翻译性能.
变压器遵循编码器-解码器架构,其中编码器将源句子X转换为一组上下文向量C.解码器从上下文向量C中生成目标句子Y.给定一个并行的句子对数据集D={(X,Y)},其中X为源句子,Y为目标句子,损失函数可以定义为:

(1)
1.2 长期短期记忆模块
长期短期记忆模块,又称LSTM,是一种改进的时间递归神经网络,可以有效地处理时间序列中的长期依赖问题,该模块在语音识别上有着强大的优越性[13-16].


图2 长期短期记忆网络Fig.2 Long term short term memory network
最后将隐藏层与传统的前馈网络作为输出层进行连接.输出层中的每个节点yi对应于下一时刻的未归一化对数概率,然后通过softmax函数对输出值y进行归一化.其公式如下:
(2)
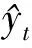
2 实验
2.1 数据集
本文使用了来自不同服务类型和规模网站的4个大规模的真实口令集. 并且这4种口令集的语言和文化背景也有一定的差别,它们的服务类型分别为程序员论坛、游戏、社交网站和互联网门户,它们分别来自中国和美国包括中文和英语两种类型的语言,并且每种口令集的口令总数也不同. 这4种口令集的详情如表1所示.

表1 口令集Table 1 Password set
如表1所示,我们的口令集分别是本文中的语音库是CSDN口令集、Rockyou口令集、Tianya口令集和Yahoo口令集. 其中,口音集均分为训练集和测试集,训练集和测试集有语音紧凑的句子和语音上不同的句子,并且训练集和测试集的数据结构不一致.
2.2 实验结果
我们分别在上文中提到的口令集中做了对比实验,分别将CSDN口令集、Rockyou口令集、Tianya口令集和Yahoo口令集中的测试集口令输入DNN-HMM、LSTM-CTC和本文模型中得到的单词错误率如表2 和图3所示:
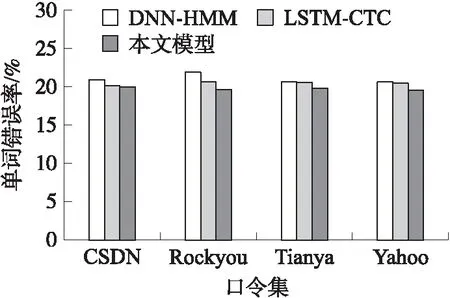
图3 不同口令集上的错误率对比Fig.3 Comparison of error rates on different password sets

表2 在4个数据集上的实验结果Table 2 Experimental results on four data sets
如表2所示,本文模型在口令集中均取到了最优的结果. 其中,与DNN-HMM模型和LSTM-CTC模型相比本文模型在Yahoo的口令集中的单词错误率将至19.5%,分别比DNN-HMM模型、LSTM-CTC模型的错误率降低了5%和4.5%,结果达到了最优.
如图3所示,根据直方图可以更清楚直接地看出我们的方法与其他两种方法(DNN-HMMLSTM-CTC)相比,在CSDN口令集、Rockyou口令集、Tianya口令集和Yahoo口令集中均取到了最优的结果,其中在Rockyou口令集中我们的方法与DNN-HMM的方法相比,我们的方法的单词错误率明显低于DNN-HMM方法的单词错误率. 因此我们的方法更适合用于机器翻译.

表3 部分识别错误示例Table 3 Examples of partial identification errors
虽然本文设计的网络模型已经取得了比较优秀的结果,但是本文模型还存在一些不足,表3展示了本文模型在测试结果中经常出错的例子.
如表3所示,可以看出一些读音相同的字经常会被错误识别. 针对以上问题我们还需继续实验,继续研究读音相同的字的识别方法,这也是一个值得挑战的困难,我们未来将从分析语境方面入手.
2.3 隐藏层中神经元消融的影响分析
隐藏层中存在大量的神经元,适当的隐藏层层数有利于对语音特征的提取,但是过多的设计隐藏层会对网络模型带来巨大的计算开销,所以合理设计隐藏层的层数非常重要. 因此,本文对隐藏层的层数做了消融实验,实验结果如表4所示.
表4显示,隐藏层数对语音识别系统的准确性有很大的影响. 当隐藏层数增加时,网络的识别能力就会增加,但当隐藏层继续增加时,识别效果就会回归. 随着层数的增加,训练时间也会变长,从而导致系统效率的降低. 因此,通过将隐藏层设置为4层,可以得到最佳的结果.
隐藏层中存在大量的神经元,适当的神经元个数有利于对语音特征的提取,但是过多的神经元个数会对网络模型带来巨大的计算开销,所以合理设计隐藏层中的神经元个数非常重要. 因此,本文对隐藏层的神经元的个数做了消融实验,实验结果如表5所示.

表5 隐藏层神经元个数对网络模型的影响Table 5 Influence of number of hidden layer neurons on network model

表4 隐藏层层数对网络模型的影响Table 4 Influence of hidden layers on network model
为了研究每层神经元数量对识别结果的影响,本文选择了不同数量的神经元:120、240、480、600、1 024. 对比表3的结果表明,神经单元的数量太少,网络的拟合能力不足. 从而导致系统的音素的错误率过高. 然而,当隐藏层数的数量继续增加时,音素错误率逐渐降低,但是神经元数量增加,会导致系统效率下降,训练所需时间的增加. 所以,在长期短期记忆模块中,每层的单位数被设置为480个.
3 结论
本文设计了一种基于循环生成对抗网络的机器翻译网络模型,使用生成网络处理自然语言,并通过判别网络优化生成网络,两个网络相互作用最终得到一个比较理想的机器翻译网络模型,我们也分别在CSDN口令集、Rockyou口令集、Tianya口令集和Yahoo口令集等口令集中做了大量的对比实验,实验结果表明,在每个口令集中我们的结果均达到了最优.
猜你喜欢
电子产品世界(2021年8期)2021-01-16
动漫界·幼教365(小班)(2019年10期)2019-10-28
儿童故事画报(2019年3期)2019-04-01
新课程·上旬(2019年1期)2019-03-18
中国计算机报(2019年49期)2019-02-07
中国新闻周刊(2017年36期)2017-10-21
作文周刊·小学一年级版(2017年30期)2017-09-03
教师·中(2017年3期)2017-04-20
创新时代(2016年8期)2016-10-21
试题与研究·教学论坛(2016年27期)2016-08-11
