
基于组合深度模型的现代汉语数量名短语识别
2022-03-16 11:19施寒瑜曲维光魏庭新周俊生顾彦慧
南京师大学报(自然科学版) 2022年1期
施寒瑜,曲维光,2,魏庭新,周俊生,顾彦慧
(1.南京师范大学计算机与电子信息学院/人工智能学院,江苏 南京 210023) (2.南京师范大学文学院,江苏 南京 210097) (3.南京师范大学国际文化教育学院,江苏 南京 210097)
数量短语是现代汉语中主要起计数作用的短语,包括统计数目多少或计算次序先后等. 数量短语作为现代汉语中常用的语法结构,一般用于修饰名词短语,并以“数词+量词+名词”的常规语序出现,然而在真实语境中,语言表达通常遵循经济原则,若名词中心语在上下文有提示,数量短语通常会以中心语省略的形式出现在日常语言中使用. 如“店家无奈,只好又给武松筛酒…武松前后共吃了十八碗. ”这种数量短语的特殊用法黎锦熙将其称之为“替代中心词”[1],即数量词修饰的中心语名词被省略,由前面的数量词替代,省略条件为中心语名词在上下文至少出现一次;并且该类数量短语在句法上可独立充当主语、宾语等句子成分.
近年来,有不少关于数量短语识别的研究工作. 以往大部分研究是基于知识库和规则的方法实现“数词+量词”短语识别. 白晓革等[2]将数量短语的构成模式细分为数词短语、数量短语、模糊数词短语、模糊数量短语、序数数量短语、范围数量短语、特殊符合量词短语和指量短语,并加以概念层次网络(hierarchical network of concepts,HNC)世界知识库以及数量短语3大词库对语料进行分析和提取,正确率和召回率达到90%. 张玲等[3]在探讨数量短语构成模型的基础上构建一个为数量短语识别提供词汇知识和短语结构知识的数据库,在1万字人民日报的新闻语料中正确率为90.9%,召回率为98.7%. 熊文等[4]在张玲等[2-3]的基础上又提出一种基于规则不依赖于分词的中文数量短语的识别,该方法在人民日报的未标注语料进行了识别,召回率达到98.7%,精度为90.9%. 以上研究都是针对“数词+量词”边界的识别. 然而仅仅识别数量短语在实际应用中是不够的,数量短语是名词中心语的修饰成分,识别数量短语只能实现HNC句类分析的前置处理. 本文将数量名短语作为一个整体进行识别,有利于数量信息的抽取,利于机器翻译、问答等相关工作的实现,同时有利于解决中文抽象语义表示(CAMR)模式中数量短语增补外部概念节点(名词性词汇语类缺省添加),补全数量短语省略的工作,有助于CAMR语义自动解析工作. 目前对于“数+量+名”短语的识别研究较少,且使用的是基于统计学习模型的识别方法. 方芳等[5]将数量名短语归纳为“基数词+量词+名词”“基数词+量词+修饰+名词”“序数词+量词+名词”“数词+名词”以及“指示代词+量词+名词”等5类,并基于规则库的方法在240万字的当代新闻小说语料上进行识别,调和平均值F1达到80%. 但该文只针对一种语序的数量名短语的识别,对于自然语言中出现的其他形式的数量名短语并未给出解决方案.
本文通过对语料的统计分析,发现数量名短语除了上述五类之外,还有3种情况:“名词+数词+量词(倒装)”“不定数词+(量词)+(修饰)+名词”和“数量名短语省略”这3种情况在自然语料中所占比例有17.44%. 因此为扩大识别数量名短语形式的规模,涵盖更全面的具有计数意义的短语,提升模型泛化性,本文将其均纳入研究范围,实现对如上8种类型数量名短语的边界识别.
在自然语言处理中将此类短语结构化识别问题归于序列标注问题,相类似的有词性标注、命名实体识别等任务. 近几年,序列标注问题通过神经网络的训练方法表现出很好的性能. Collobert等[6]首次实现将CNN模型与CRF结合应用于命名实体识别任务,在CoNLL2003的语料集上取得较好效果. 随后,Huang等[7]采用一个人工设计语义特征的BLSTM-CRF模型在CoNLL2003语料上将F1值提升到88.83%. Chiu和Nichols[8]将CNN和LSTM结合,在CoNLL2003语料上将命名实体识别任务F1值提升至91.62%.
虽然神经网络在命名实体识别上取得优异的效果,但将这些模型迁移到现代汉语数量名短语的识别领域中还存在若干问题. 相比命名实体识别,数量名短语识别有以下几个难点:(1)数量名词短语有过多的干扰项,如年月日、度量衡等这些非数量名短语的专有数量短语;(2)现代汉语中数词千变万化,量词的种类繁多,数量名短语的组合方式多样;(3)数词或量词或名词的省略现象在现代汉语的使用中尤为常见,这导致识别过程中边界模糊问题成为难点.
本文通过深度学习方法,减弱对人工特征设计和专家知识的依赖,实现数量名短语的识别. 本文利用中文抽象语义表示(CAMR)的语义表示体系[9]精确辨别数量名短语的左右边界,解决手工标注时往往遇到边界模糊的问题. 本文语料采用中文抽象语义表示[10](CAMR)语料,在该语料上识别效果F1值达到85.07%.
1 深度学习模型
1.1 模型整体框架
本文BERT-Lattice LSTM-CRF模型一共有3部分组成,如图1所示:

图1 BERT-Lattice LSTM-CRF 模型框架Fig.1 BERT-Lattice LSTM-CRF model
(1)BERT预训练模块:采用BERT模型进行预训练,对输入序列中的每个字符生成字符级特征表示,弥补数据集较少情况下,特征学习不充分的现象;
(2)Lattice LSTM特征获取模块:采用Lattice LSTM模块进行特征表示,该模块融合正确分词的软特征. 模块将BERT模型的输出和名词向量融合,解决因分词错误而导致的错误传递现象并进一步丰富特征表示;
(3)CRF解码模块:采用线性CRF模块,该模块将Lattice LSTM模型的输出的特征表示解码,获取一个最优的标注序列.
1.2 BERT预训练
在自然语言处理领域中为了更好地表示文本的特征,解决一词多义问题,通常使用ELMo(Embedding from Language model)[11],一种基于语境的深度词表示模型. 而2018年由Devlin等[12]提出BERT(Bidirectional Encoder Representation and Transformers)模型在ELMo模型基础上改进,通过超大数据、巨大模型、和极大的计算开销训练而成,并在11个自然语言处理任务中取得优异结果.
BERT模型的子结构是Transformer[13]双向编码器,它摒弃了RNN的循环网络结构,把Transformer编码器当作模型的主题结构,利用自注意力机制对句子建模. 本文将语料输入BERT模型预处理,可以充分学习语料的字符之间、词语之间以及句子与句子之间关系特征,为输入语料的每个字符生成基于当前语境上下文的动态字符级嵌入向量,解决传统词嵌入方法将不同语境中的同一单词映射到相同语义空间的问题,提升字符级嵌入向量的文本特征表示能力.
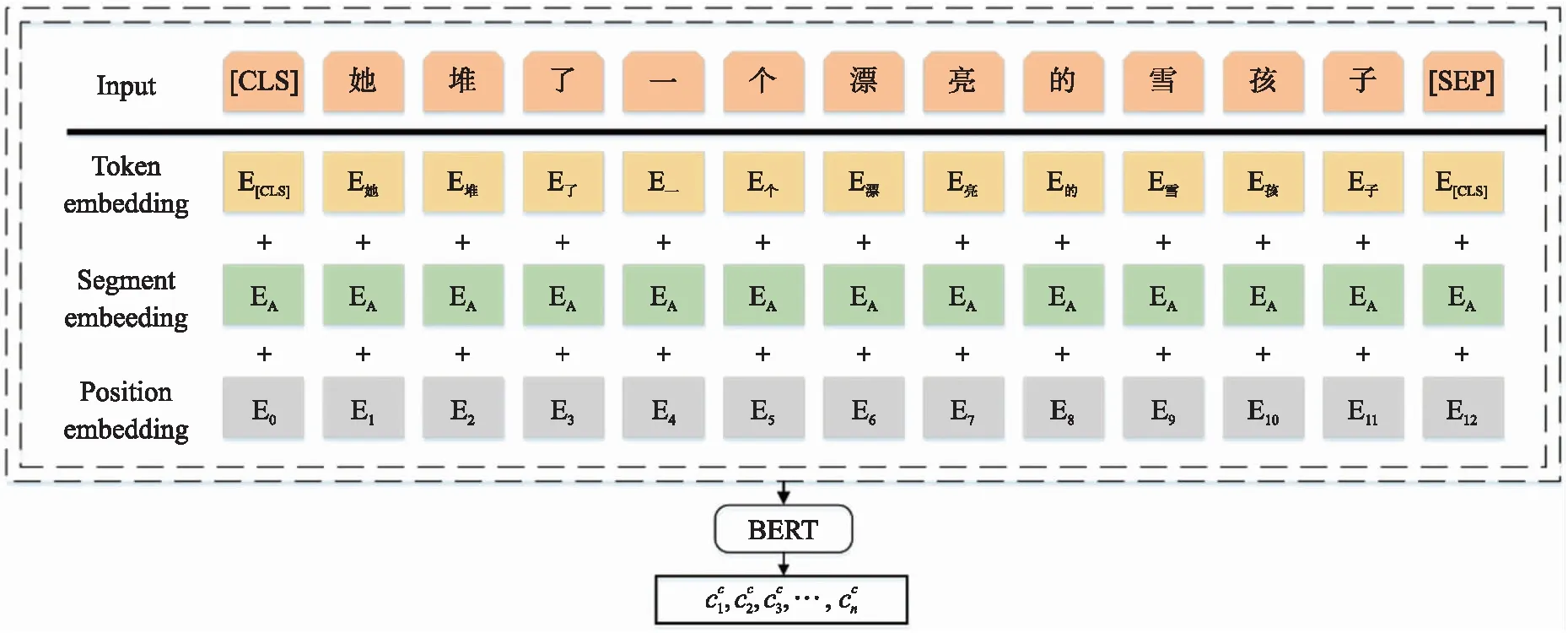
图2 BERT预处理字符向量Fig.2 Pre-trained character vectors by BERT
如图2所示,为获取语料预训练的字符级嵌入向量,将原始语料处理成token嵌入,segment嵌入,position嵌入3部分输入. BERT层通过联合调节内部的双向Transformer编码器,利用自注意力机制学习上下文中其余字符对当前字符的贡献程度,从而增强上下文语义信息的获取. 最终,编码生成基于当前语境上下文的字符级嵌入向量.
本文将AMR语料输入BERT模型,预训练生成融合上下文信息的字符级嵌入向量,并将该字符级嵌入向量输入Lattice LSTM模型,通过Lattice LSTM模型生成含有词语信息的字符级特征表示.
1.3 Lattice LSTM模块
LSTM(Long Short-Term Memory)长短时记忆网络[14]是RNN(Recurrent Neural Network)的一种. 该模型涉及四种类型的向量,即输入向量,输出隐藏向量,单元向量和门向量. 在基于字符级的LSTM模型中,每个字符cj用字符输入向量来表示:
(1)

(2)
(3)
(4)
(5)
(6)
(7)
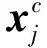
(8)
(9)
(10)
(11)
(12)



图3 Lattice LSTM 字符和词的融合模型Fig.3 Lattice LSTM model with Character and word information fusion

(13)
(14)
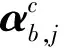
(15)
(16)
1.4 CRF模块
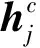
(17)
式中,矩阵A是转移矩阵,例如Aij表示由标签i转移到j的概率,y0,yn则是预测句子起始和结束的标注,因此A是一个大小为m+2的方阵.所以在原语句S的条件下产生标注序列y的概率为:
(18)

在训练过程中标注序列的似然函数:
(19)
其中,Yx表示所有可能的标注集合,包括不符合BIOES[17]标注规则的标注序列.通过式(19)得到有效合理的输出序列.预测时,由式(20)输出整体概率最大的一组序列:
(20)
1.5 训练参数
训练过程中,使用具有批量大小10和动量0.9的小批量随机梯度下降(SGD)执行参数优化. 我们选择学习率为0.015. 同时,通过实验发现在LSTM的输入和输出部分增加Dropout可以减轻模型过拟合的问题,Dropout[18]值选取了0.5.
我们探索了其他更复杂的优化算法,如AdaDelta[19],Adam[20]或RMSProp[21],但它们都没有在我们的动量和梯度削减中改进SGD.
2 实验结果
2.1 语料介绍
本文采用的语料是小学1-6年级语文教材(人教版)的抽象语义表示(AMR)语料[10],共8 587个中文句子,其中数量名短语总计有6 142个. 本文将语料以7∶1的比例分为训练集7 587句,数量名短语 5 320个;测试集1 000句,数量名短语822个. 数量名短语分成如下8种类型:(1)基数词+量词+名词;(2)基数词+量词+修饰+名词;(3)序数词+量词+名词;(4)数词+名词;(5)指示代词+量词+名词;(6)名词+数词+量词(倒装);(7)不定数词+(量词)+(修饰)+名词;(8)数量名短语省略. 如表1所示:

表1 数量名短语形式短语分类Table 1 Categories of quantity noun phrases
在语料处理方面,为了能够清楚地表示语料中待识别的数量名短语,本文采用序列化标注任务中常用的BIOES[16]标注方式. 数量名短语的左边界标记为B-NUM,右边界标记为E-NUM,中间文本标记为 I-NUM,该方式能更清楚的划分数量名短语的左右边界. 本文为了消除分词错误造成的错误传递问题,在处理语料时以中文字符为单位进行标记. 该方法减少因中文分词歧义而造成边界模糊的问题,使得数量名短语左右边界更为精确便于深度学习模型的训练和测试.
2.2 实验结果及分析
本文通过对比实验的结果来分析各个模块在模型中起到的作用,实验结果如表2,3所示. 其中,BLSTM-CRF,CRF,Lattice LSTM-CRF三种模型均采用基于Baidu Encyclopedia预训练的字向量;BERT-CRF,BERT-BLSTM-CRF,BERT-Lattice LSTM-CRF 3种模型中BERT模型采用BERT-Base,Chinese字符级预训练模型.
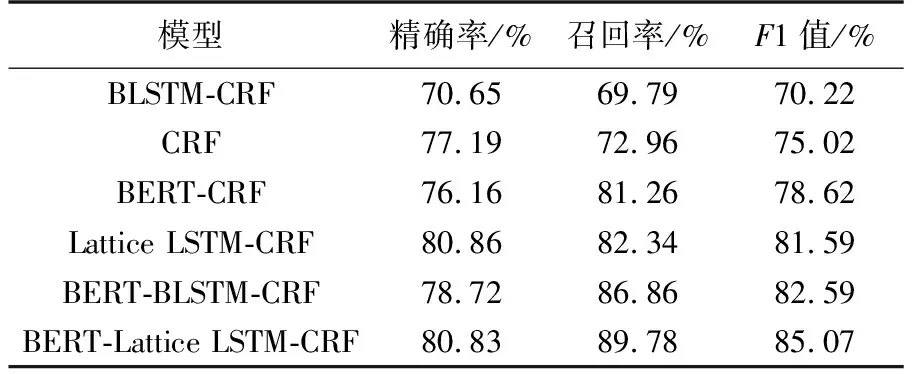
表3 模型精确率、召回率、F1值Table 3 Precision,recall and F1 results

表2 模型结果对比Table 2 Comparison of model results
本文的基线模型采用传统的机器学习方法CRF模型. 传统的机器学习方法在规则性较强的识别任务上可取得较好效果. 本文研究的数量名短语大部分左边界由具体的数词组成,数词的表达方式又明显有别于汉语其他词类,加之量词基本是一个封闭集合,所以CRF模型能够充分利用相邻标签关系实现边界识别. CRF模型在本文数量名短语边界识别任务中F1值达到75.02%.
在CRF模型基础上,本文加入BERT模型,利用BERT自身Transformer模块,通过自注意力机制使得CRF获取具有文本上下文信息的字符级特征表示,丰富CRF模型的特征获取. 实验证明,在加入预训练模型后,BERT-CRF模型F1值为78.62%,比基线CRF模型的F1值高出了3.60%,BERT-CRF模型的召回率也明显优于CRF模型.
BLSTM-CRF深度学习模型效果远不如统计学习CRF模型,原因在于该模型训练数量名短语此类左边界相对封闭,右边界开放的短语结构时,从右往左读取的右边界信息的无规律性,导致右边界识别效果不佳;同时BLSTM-CRF模型受到训练数据集较少的约束而不能充分表示每个字符在文本中的特征信息,从而导致识别效果远不如统计学习CRF模型. 为弥补小数据集带来的缺陷,本文融合预训练模型BERT,实验表明经过预训练处理后识别效果有显著提升. 相较BERT-CRF模型,BERT-BLSTM-CRF模型中的双向LSTM模块能将BERT预训练获得的上下文字符向量训练出更符合上下文的特征表示,并将F1值提升3.97%. 由此可见深度学习方法在数量名短语边界识别的任务中能发挥其优势. 相比仅使用字符信息的BLSTM模型,本文认为结合了正确切分的名词信息的Lattice LSTM模型更适合处理中文语料. 实验结果表明,Lattice LSTM-CRF比BLSTM-CRF模型的F1值提升11.37%. Lattice LSTM能够融入正确分词软特征,丰富字符向量的上下文特征,并且能够减少模型因分词错误而造成的错误传递问题,从而提升模型效果. 本文最优模型BERT-Lattice LSTM-CRF将BERT预训练、Lattice LSTM字词融合模型以及线性CRF模型相结合,将数量名短语的边界识别的F1值提升至85.07%.
BERT-Lattice LSTM-CRF模型在本文AMR小学语料1000句测试集的822个数量名短语中,按照数量名短语不同类别,统计不同类别数量名短语的识别效果,如表4所示.

表4 不同类别数量名短语精确率、召回率及F1值Table 4 Precision,recall and F1 results of different quantity noun phrases categories
在数量名短语中,“基数词+量词+名词”是数量名短语中短语形式最为常规的一类,也是最为常见的一类,在测试集中占24.82%,其识别效果F1值为93.21%. “基数词+量词+名词”“基数词+量词+修饰+名词”“指示代词+量词+名词”和“不定数词+(量词)+(修饰)+名词”这四种类别在现代汉语中出现频率较高,因而深度学习模型能够充分这四种类别的短语特征,取得相对较好的识别效果. “数词+名词”类别的F1值为76.84%,在所有数量名短语中识别效果较差,原因在于中文常见“数+名+数+名”短语的词语,如“一文一武”“千言万语”等词语识别成“一文”“一武”“千言”和“万语”等非数量名短语从而导致该类数量名短语识别的精确率和F1值偏低. “名词+数词+量词(倒装)”类别的F1值为72.73%,在数量名短语识别中识别结果最低,其主要问题在于该类型数量名短语在训练语料中出现频率低,模型无法充分学习该类数量名短语的特征. 在以往数量短语识别中,仅仅识别未缺省的数量名短语,无识别“省略数量名短语”的相关工作. 本文将“数量名短语省略”类别纳入识别范畴,填补该类短语识别工作的空白,模型取得较优越效果,F1值达到84.51%. 同时,该结果对于后期“省略数量名短语”的补全工作具有先导意义.

表5 JLM数量名短语精确率、召回率和F1值Table 5 Precision,recall and F1 results of JLM quantity nonn phrase
以往工作仅仅针对“基数词+量词+名词”“基数词+量词+修饰+名词”“序数词+量词+名词”“数词+名词”和“指示代词+量词+名词”这五种数量名短语识别(以符号JLM表示). 本文模型针对这五类数量名短语的识别效果远超方芳[5]等80%的调和平均值,如表5所示,F1值达到86.15%. 本文在JLM数量名短语的基础上将“名词+数词+量词(倒装)”“不定数词+(量词)+(修饰)+名词”和“数量名短语省略”三种数量名短语纳入识别范围,并实现F1值85.07%的识别效果.
综上,本文工作扩大数量名短语的识别范畴,填补“省略数量名短语”识别工作的空白,并通过BERT-Lattice LSTM-CRF组合深度模型实现目前最优的数量名短语识别效果.
3 结论
本文针对现代汉语数量名短语识别任务,通过BERT预训练模型获得具有上下文信息的字符向量表示,并通过Lattice LSTM网络将字和词的信息融合,丰富字符级网络的词语信息,减少分词错误造成的错误传递,最后通过CRF全局约束完成数量名短语识别工作,在AMR小学语料中取得较好性能. 主要结论如下:
(1)在现代汉语数量名短语识别任务中,人工特征和知识库对于结果的影响很大,但构建合适的人工特征需要大量的特征提取实验,导致了系统的成本提升、泛化能力下降. 本文采用的深度学习方法可以自动获取数量名短语的结构特征,大大降低人工获取特征的工作量并提升模型泛化能力.
(2)本文在JLM数量名短语的基础上扩大识别范畴,并采用深度学习模型,构建BERT-Lattice LSTM-CRF组合模型,在不使用任何人工特征的情况下,实现数量名短语边界识别F1值达到85.07%.
(3)实验表明,BERT模型预训练字符向量的加入,使得模型实现对于含有不常用数词和量词这类数量名短语更有效地识别;通过Lattice LSTM网络把正确分词的信息融入字符向量的表示,减少因分词错误导致的边界偏移问题;最后采用线性CRF算法提升对含有多修饰词、边界模糊的现代汉语数量名短语的识别能力.
综上,本文研究基于组合神经网络的数量名短语识别方法. 通过BERT预训练模块学习文本字符级上下文特征表示,利用Lattice LSTM字词融合思想,结合线性CRF全局约束完成识别任务. 在下一步的研究中,我们将进一步扩大语料规模,使得模型学习更多更丰富的特征信息以取得更好效果. 随后,我们在识别数量名短语的基础上,解决中文抽象语义表示(CAMR)模式中数量短语增补外部概念节点(名词性词汇语类缺省添加),补全数量短语省略的工作并尝试将补全的省略数量名短语用于CAMR语义自动解析等工作中.
猜你喜欢
电脑报(2021年41期)2021-11-04
作文周刊·小学二年级版(2021年28期)2021-01-04
小天使·一年级语数英综合(2020年3期)2020-12-16
电脑知识与技术(2019年29期)2019-12-16
电脑爱好者(2019年8期)2019-10-30
小学阅读指南·低年级版(2016年3期)2016-05-27
农机使用与维修(2014年10期)2014-10-23
对联(2011年24期)2011-09-19
对联(2011年22期)2011-09-19
学苑创造·B版(2009年12期)2009-01-15
