
考虑双参照点和Choquet积分的新型研发机构绩效评估方法及应用
2022-03-15 08:47朱建军
运筹与管理 2022年2期
姜 琳, 朱建军
(1.南京航空航天大学 经济与管理学院,江苏 南京 211106; 2.盐城师范学院 信息工程学院,江苏 盐城 224000)
0 引言
新型研发机构随着新一轮科技革命应运而生,在孵化源头科技、促进成果转化上独具优势,瞄准了产业创新转化、集聚资源,显示出强劲的创新活力。新型研发机构是未来新的经济增长点,代表国家创新的重大使命,是保持创新领先优势、支撑引领战略性新兴产业发展的新业态[1],国家很多文件如《“十三五”国家科技创新规划》、《国家创新驱动发展战略纲要》、《2018年政府工作报告》、《深化科技体制改革实施方案》、《关于促进新型研发机构发展的指导意见》都明确新型研发机构的发展要求和绩效评估要求[2]。
新型研发机构的研究受到广泛关注,经查询知网,2019年发表论文109篇,2020年发表论文179篇,内容涵盖功能定位、产学研合作模式、产业化、财政金融、竞争力、运行机制等,但是绩效研究并不丰富。孟溦从资源依赖和社会影响力双重视角分阶段(建设期-成长期-成熟期)进行绩效评估[1];郭百涛从研发条件、创新活动、创新效益以及人力资源4个维度设计绩效评估模型[2];周恩德运用层次回归分析法研究发现经费支出与绩效显著正相关,研发人员投入影响不显著,企业型机构绩效高于事业单位型[3];杨博文从科研投入、产出质量、成果转化、原创价值、实际贡献、人才集聚六个方面构建绩效评估体系[4];陈红喜用德尔菲法以研发基础与活动-体制机制创新建设-技术与成果转化-孵化企业-集聚高端人才-社会效益构建了新型研发机构评估体系[5]。目前的绩效研究运用了层次分析法和德尔菲法,研究视角停留在宏观层面,缺少以方法、数据为基准的实证分析。新型研发机构具有投资主体多元化、运行机制市场化、管理制度现代化、用人机制灵活化等特点,其绩效评估存在以下难点:一是绩效评估指标不够全面,没有反映新型研发机构的所有特征;二是指标权重不易确定,指标间存在关联;三是实际案例评估数据较少,不易获取,评估数据存在不确定性;四是评估专家存在主观偏好,预期不一致,是不完全理性决策。
本文考虑新型研发机构的特征,构建涵盖创新全过程的“基础-氛围-层次-成果”四个维度的绩效评估指标体系;用区间灰数[6]表征不确定的评估值;基于累积前景理论[7]设置同行和期望参照点,基于灰靶理论[6]以参照点为靶心来测度决策者的满意度,以解决不同专家的偏好和预期不一致的不完全理性决策问题,基于Choquet积分[8]、K-可加模糊测度[9]、指标集合平均边际贡献Banzhaf值[10]解决指标关联问题,最终实现新型研发机构的绩效评估、排序及结果分析。
1 基于区间灰数和双参照点的新型研发机构绩效测度方法
1.1 新型研发机构绩效评估指标的确定
本文考虑新型研发机构具有与市场结合度高、规模大、重品牌、层次高、灵活度高等特点,从创新基础、创新氛围、创新层次、创新成果四个维度构建新型研发机构二级评估指标体系。这样设置指标既考虑科技研发的投入、产出的全过程和全方位,突出强调市场导向和科技层次的重要性,增加社会效益和人才效益。
创新基础包括硬件设施、人才占股、优势学科、运行管理。机构重视设施的规划与建设,激发创新活力,深化学科应用改革,注重信息共享和开放协作。
创新氛围包括目标认同、角色清晰、信任合作、跨界融合。机构增加人才的归属感和信心,促进沟通,提高人才创新主动性,从而应对不确定的动态环境[11]。
创新层次包括市场需求、行业影响、技术突破、国际领先。机构精准问需市场,提升行业影响和技术突破,整合资源获得竞争优势,标杆先进,力争领先[12]。
创新成果包括经济效益、社会效益、科技效益、人才效益。习近平总书记在“科技三会”上提出“加强科技供给,服务经济社会发展主战场”;科技部《关于促进新型研发机构发展的指导意见》中将“科学研究、技术创新和研发服务”作为新型研发机构的核心任务;人才的可持续发展依赖于机构的集聚、吸引和培养[13]。
1.2 基于区间灰数和双参照点的新型研发机构绩效评估值表征
新型研发机构绩效评估委托第三方平台,采取临时指定、专人负责、单线联系的方式邀请专家,评估数据属于小样本,不确定性较大。灰色系统理论就是研究少数据、贫信息的不确定性问题[6],因此本文用区间灰数来表征初始评估数据。
区间灰数⊗∈[aL,aU],aL表示下界,aU表示上界,只知道取值范围而不知道确切的信息值。评估后形成m个新型研发机构、n个指标的初始评估数据矩阵A。
Kahneman和Tversky在前景理论中提出决策者的决策依据不是指标结果的绝对量,而是指标结果与参照点的差值[7]。邓聚龙教授提出的灰靶理论是以一组参照序列作为靶心,将各个序列原始数据与参照序列构成灰靶,各序列与靶心的距离称为靶心距,距离靶心越近效果越优[6]。
本文设计两个参照点:同行参照点和期望参照点。新型研发机构要提升行业影响力,占据较大市场份额,必须走在同行前列,通过与同行的发展水平比较可以评判机构的发展优势和劣势。新型研发机构投资主体多元,面临收益和损失时存在不同偏好,投入越多则期望值越高,通过与期望水平比较可以看出当前投入状态下决策者对新型研发机构绩效的满意程度。
定义1称Zq=(Zq1,Zq2,…,Zqn)为参照点序列,q表示参照点,n表示评估指标。
当q=1时,Z1为同行参照序列,指某一区域内新型研发机构同行评估值的平均值,高于同行参照序列,竞争优势明显;低于同行参照序列,则处于劣势。
当q=2时,Z2为期望参照序列,指新型研发机构不同投资主体期望值的平均值,高于期望参照序列,决策者满意度高;低于期望参照序列,决策者不太满意。
新型研发机构的同行评估值和期望评估值均具有不确定性,用区间灰数表征,因分布信息未知,本文考虑核和区间灰数的长度来计算区间灰数之间的距离[14]。

(1)
定义l(⊗)为该区间灰数的长度
l(⊗)=|aU-aL|
(2)
定义d(⊗1,⊗2)为两个区间灰数的距离
(3)

(4)
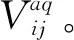
(5)
先计算前景值再进行规范处理,新型研发机构绩效评估值函数特征明显,保留了指标值是否中靶的信息,且使前景值落在统一的阈值[-1,1],前景值在[0,1]之间,中靶;前景值在[-1,0]之间,脱靶。在本文中,对比同行参照序列,中靶表示新型研发机构绩效优于同行,脱靶表示劣于同行;对比期望参照序列,中靶表示决策者感到满意,脱靶表示决策者感到不满意。
2 基于K-可加模糊测度和平均边际贡献Banzhaf值的指标集权重测度方法
评估指标权重的确定方法有层次分析法[2]、德尔菲法[5]、熵权法[15],定性方法能兼顾评估专家的经验,但具有主观性;定量方法能综合考虑数据的变化特征。针对指标间关联、指标权重可加性遭到破坏、加权平均方法失效的情况,Sugeno和Marical提出模糊测度可度量事物之间的任何关联[8],Sugeno和Grabisch用K-可加模糊测度对指标权重进行建模,准确度高,计算量小[9]。Marichal定义平均边际贡献Banzhaf值为一种特殊的模糊测度,它不仅反映单个指标对整体评估值的贡献度,而且反映单个指标或指标集对整体评估值的整体平均贡献[10]。本文采用K-可加模糊测度和平均边际贡献Banzhaf值的指标集权重测度方法。
第一步,请专家确定指标间两两直接关联矩阵A([aij]n*n)。关联度用0-1的数值表示,0表示两个指标间没有直接关联,1表示一个指标可以确定另一个指标。
第二步,通过布尔变换和海明距离确定参数K。指标间两两直接关联矩阵An*n作布尔变换,从而得到指标间的布尔综合关联矩阵Bn*n=A1+A2+…+An和K-可加布尔综合关联矩阵Cn*n=A1+A2+…+AK,用海明距离σ[9]计算矩阵B和C之间的距离,当σ(B,C)达到阈值∈(本文∈取0),此时得到K值。根据K-可加模糊测度的定义,当指标集的指标个数大于K时,其默比乌斯变换M(E)=∑E⊂X(-1)|XE|μ(X)=0,此时指标间关联为0,这样减轻计算工作量的同时结果依然准确[9]。
i=1,2,…,n;j=1,2,…,n
(6)
第三步,基于Banzhaf值优化求解指标集权重。
定义3设P(X)为指标集X={x1,x2,…,xn}的幂集,μ为定义在P(X)上的指标集权重,F是X的任意一个子集,XF表示X和F的差集,E是XF的任意一个子集,|X|和|F|分别为X和F的势,∀F∈P(X),其广义Banzhaf值为[10]
(7)
当F中只有一个元素xi时,公式(7)归约为Banzhaf函数[10]:
(8)
根据Banzhaf值的定义和性质,选用Banzhaf值方差最小作为优化目标,表示单个指标或指标集合对绩效评估的整体平均贡献差距最小,显示每个指标存在的意义,既均衡平均贡献,又考虑指标集的关联效应。
基于平均边际贡献Banzhaf值和K-可加模糊测度构建指标集权重优化模型M-1:
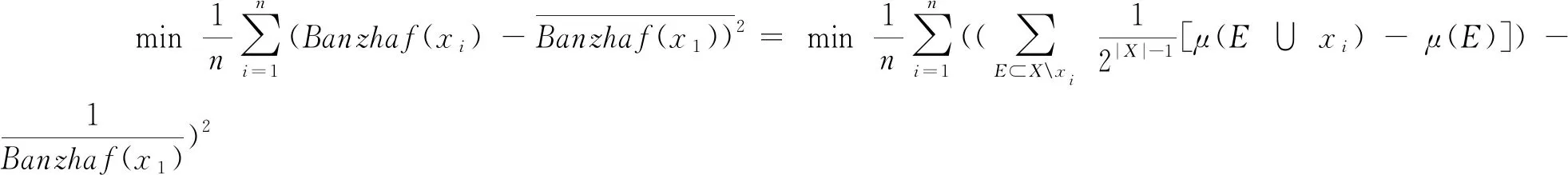
(M-1)
约束条件的含义:(1)指标集为全部指标时,权重为1;(2)指标集权重值在0-1之间;(3)指标集的指标越多,权重越大;(4)当指标集的指标个数大于参数K时,不考虑指标间关联;(5)当指标间没有关联,指标集权重为指标权重之和,满足可加性;(6)当指标间存在关联,关联性用专家确定的两两直接关联矩阵A中的数据。
本文用LINGO软件优化求解15个指标集权重μj。该方法与最小二乘法、专家访谈法比较优点明显:一是考虑指标间关联;二是模型结构清晰,目标易于理解,每一个指标都有评估意义;三是计算量小,只需提供指标间的直接关联矩阵就可求解权重,且不考虑K值以后的指标间关联;四是形式简单,存在最优解。
3 基于Choquet积分的新型研发机构综合绩效评估值的确定
Choquet积分具有单调性、幂等性、有界性等性质,常被用来作为指标集权重的集结算子。Choquet在1954年系统研究了非可加测度,Sugeno在此基础上提出了模糊测度,以讨论具有关联性的整体模糊评价[8]。考虑指标间关联的方法更具有一般性,而不考虑指标关联的方法是考虑指标关联的特例。
定义4设P(X)为指标集X={x1,x2,…,xn}的幂集,μ为定义在P(X)上的指标集权重,f是定义在X上的函数,本文基于Choquet积分的新型研发机构绩效评估值为:
(9)
n表示指标个数,Yj和μj分别有2n-1个。Yji表示在某个指标集下的绩效评估值,μj是与之一一对应的指标集权重。E表示指标集,XE表示除E以外的指标集。不同参照点下基于Choquet积分的新型研发机构绩效评估值Cqi由Yji和μj加权得到,q=1时,得到同行参照点下的综合绩效评估值C1i;q=2时,得到期望参照点下的综合绩效评估值C2i。
设同行参照点和期望参照点权重分别为ω和1-ω,加权计算得到第i个新型研发机构的综合绩效评估值Si。
Si=ω*C1i+(1-ω)*C2ii=1,2,…,m
(10)
Si越大,新型研发机构的绩效越优,据此进行新型研发机构的绩效评估和排序。综上,考虑双参照点和Choquet积分的新型研发机构绩效评估方法的决策步骤如下:
步骤1确定绩效评估指标,获取基于区间灰数的初始评估值,设计同行-期望双参照点,以参照点值为靶心计算前景值,并用最大值法进行规范处理;
步骤2根据专家提供的指标间两两直接关联矩阵、K-可加模糊测度以及Banzhaf值构建优化模型M-1求解指标集权重。
步骤3将规范化后的前景值和指标集权重代入Choquet积分公式,结合参照点权重,集成得到新型研发机构的综合绩效评估值,并进行排序和比较分析。
4 算例及方法比较
4.1 背景介绍
S区新型研发机构科技园成立于2015年,5年内共建70余家新型研发机构,与35所海内外知名高校、科研机构开展合作,吸引了90余位高端人才,走出了一条平台化发展、爆发式增长、开创式引领的创新路径。2019年底,我国爆发了新冠肺炎疫情,S区新型研发机构用“智慧”践行他们的使命担当。笔者走访了其中4家生物医药方面的新型研发机构,情况见表1。
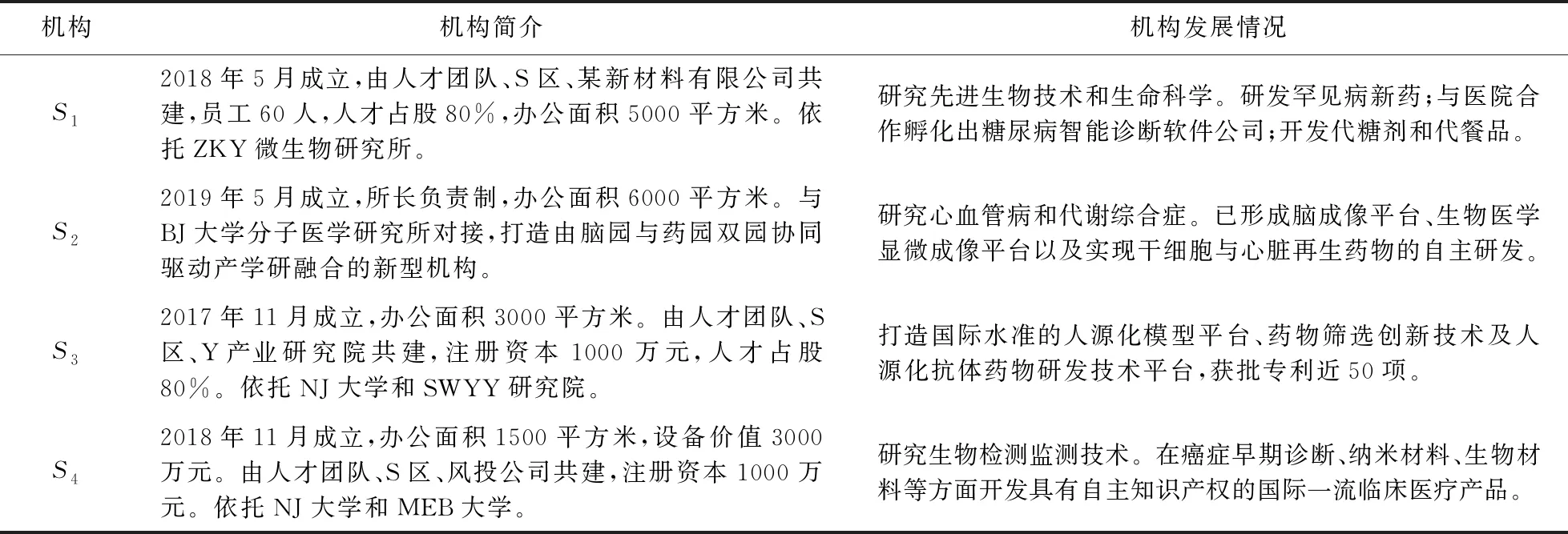
表1 4个新型研发机构的机构简介和发展情况
4.2 4个新型研发机构的绩效评估值计算及分析
第一步:评价指标下的评价数据来源及处理。
参加评估的评委由15名专家组成,主要为科技发展、机构改革、学科建设、人事管理、重大项目的负责人以及博士、教授、同行专家代表等。15名评委分别依据评估指标进行百分制评分,同行参照序列是同行绩效评估数据的平均值,期望参照序列是5个投资主体代表给出的期望值的平均值,相关数据见表2。

表2 4个新型研发构不同指标下的初始评估值及参照点值
根据上表分析:(1)初始评估值和参照序列数据均以区间灰数表征,评估值之间差距不大;(2)不同指标下的评估值是不一样的,区间灰数的长度也不一样。
对以上4个新型研发机构根据式(1)~(5)计算,分别得到基于同行参照点和期望参照点下的规范前景值,见表3和表4。
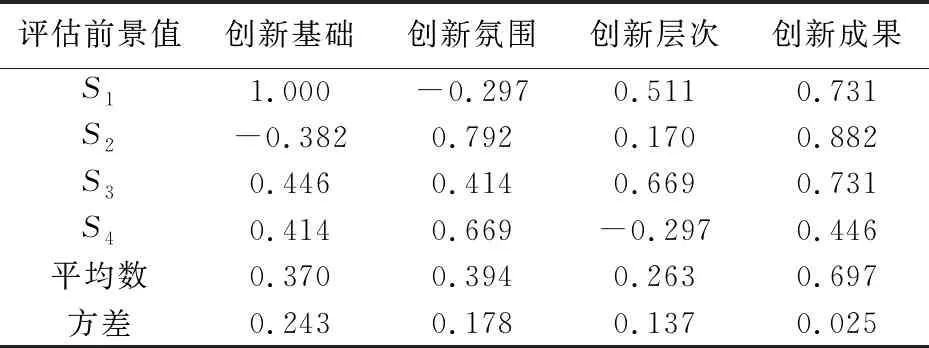
表3 4个新型研发机构基于同行参照点的规范前景值

表4 4个新型研发机构基于期望参照点的规范前景值
根据上表分析:(1)S1、S3、S4的创新基础比同行好;(2)S1的创新氛围较差,S2、S3、S4优于同行;(3)S1和S3的创新层次优于同行,S2和S4仍很欠缺;(4)4个机构的创新成果均达到同行水平;(5)创新基础差距最大,创新成果差距最小;(6)从脱靶情况看,S1要提升创新氛围,S2要提升创新基础,S4要提升创新层次。
根据上表分析:(1)S1、S3、S4的创新基础达到期望;(2)S1要改善创新氛围;(3)S1和S3的创新层次达到期望,S2和S4未达期望;(4)只有S2达到创新成果的期望;(5)创新氛围差距最大,创新成果差距最小;(6)从脱靶情况看,S1要提升创新氛围,S2要提升创新基础和层次,S3要提升创新成果,S4要提升创新层次和成果。
第二步,依据指标间的直接关联矩阵和式(6)计算K值。
专家确定指标间两两关联矩阵

创新基础与创新氛围、创新氛围与创新成果之间存在补充关联。将A转换为布尔综合关联矩阵

和K-可加布尔综合关联矩阵
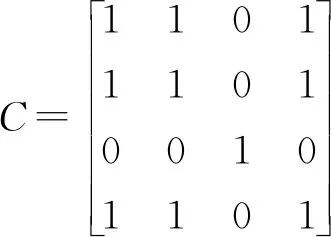
计算φ(B,C)的值,见表5。海明距离φ(B,C)随着K值的增大而增大,当K≥2时,矩阵B和C的贴近度恒为1,取K=2。当K≥2时,指标间关联为0。

表5 不同K值对应的海明距离φ(B,C)的值
第三步,数据代入M-1模型,用LINGO软件优化求解指标集权重μj,见表6。

表6 基于M-1模型优化求解得到的指标集权重
根据上表分析:(1)指标集权重并不完全符合可加性原则,比如μ9({x2,x4})>μ2({x2})+μ4({x4});(2)指标越多,指标集权重越大,符合单调性,比如μ11>μ5;(3)指标集权重μj与指标间两两关联矩阵A有关。
第四步,将表3、表4和表6的数据代入式(9)和(10),得到不同ω下基于Choquet积分的新型研发机构的综合绩效评估值Si和排序情况,见表7。

表7 不同参照点权重ω下新型研发机构的综合绩效评估值及排序
根据上表分析:(1)S2和S3全部中靶,S1和S4出现脱靶;(2)4个机构差距不大,ω越大方差越小;(3)绩效评估值随着ω的增大而增大,说明4个机构高出同行平均水平,却不一定达到期望的发展水平;(4)不同ω下排序一样,为3≻2≻1≻4。
4.3 不同方法下的4个新型研发机构的绩效值及比较分析
方法A本文的方法,用区间灰数表征评估值,考虑指标关联,考虑同行-期望双参照点,基于Choquet方法计算综合绩效评估值。
方法B用区间灰数表征评估值,不考虑指标关联,考虑同行-期望双参照点,基于加权算术平均法计算综合绩效评估值。
方法C用区间灰数表征评估值,不考虑指标关联,考虑同行参照点,基于加权算术平均法计算综合绩效评估值。
方法D用区间灰数表征评估值,不考虑指标关联,考虑期望参照点,基于加权算术平均法计算综合绩效评估值。
方法E文献[16]提出基于Topsis的区间灰数逼近理想解决策方法,用区间灰数表征评估值,不考虑指标关联,考虑最大值和最小值参照点,基于加权算术平均和Topsis方法计算综合绩效评估值。
方法F文献[9]提出基于Marichal熵优化求解指标集权重的方法,用实数表征评估值,考虑指标关联,不考虑参照点,基于Choquet方法计算综合绩效评估值。
以上方法中,不考虑指标关联时指标权重取(0.2,0.2,0.3,0.3),考虑2个参照点时参照点权重取0.5。不同方法下新型研发机构的综合绩效评估结果见表8。

表8 不同方法下的新型研发机构综合绩效评估结果
根据表8得出:(1)A、B、C、D、E使用了区间灰数表征,F为实数表征;方法不同,绩效评估值不同,排序也不同;(2)A、B、E考虑了2个参照点,C、D考虑了1个参照点,F没有考虑参照点;考虑参照点更加贴近现实,同行参照点帮助了解新型研发机构在同行发展中的位置,期望参照点更加符合新型研发机构的投资主体多元性和组合方式灵活性,充分反映决策者的满意度;(3)A、B、C、D运用了前景理论,B、D出现脱靶,脱靶表示绩效需要改进;(4)A、F考虑了指标关联,排序为3≻2≻1≻4;B、C、E不考虑指标关联,排序为3≻1≻2≻4,指标关联考虑与否影响机构排序。有研究表明,大多数指标间存在关联,本文中主观的指标间两两直接关联矩阵和客观的Banzhaf值优化模型,既考虑指标间关联,兼具主客观,且计算量不大,更具合理性、现实性和通用性。
5 结论
本文提出一种基于双参照点和Choquet积分的新型研发机构绩效评估方法,该方法降低了决策者的压力,通过K值减少了计算量,通过Banzhaf值和K-可加模糊测度使指标集权重优化模型有解的可能性大大增加,提高了参照点和Choquet积分理论解决指标关联绩效问题的可行性,有利于促进绩效评估理论与实际问题的融合,也有利于促进新型研发机构的发展。下一步的研究可聚焦于考虑多参照点、指标间关联概率分布特征以及动态分阶段评估等的新型研发机构绩效评估方法。
猜你喜欢
数学物理学报(2022年3期)2022-05-25
数学物理学报(2022年2期)2022-04-26
华中师范大学学报(自然科学版)(2021年2期)2021-04-10
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
经济与管理(2020年4期)2020-12-28
山东工业技术(2018年20期)2018-11-26
物流科技(2017年10期)2017-11-22
理论观察(2016年10期)2016-12-07
西部学刊(2014年1期)2014-02-14
