
跨信道注意力权重最大区域掩盖的正则化方法
2022-03-15 03:02贾晓芬王景泰郭永存赵佰亭
西安交通大学学报 2022年3期
卷积神经网络(CNN)凭借着其丰富的表达能力以及对复杂参数的处理能力在图像去噪
、分类
和超分辨率重建
等领域得到爆发式发展。研究发现,CNN拟合情况跟训练集数目近似呈现对数比例关系。在训练样本不足时,由于CNN模型中有大量参数,在训练时会错把一些无法泛化的详细、繁杂的特征当作分类特征,从而出现过拟合现象
。ResNet
、VggNet
、WRNNet
、MobileNet
、MoblieNetV3
、EfficientnetV2
、DenisNet-SE
等在训练时都会有不同程度的过拟合现象出现。
对于外界的声音,比如说我太狠了等等。我不在乎这些说法,我承认确实我很狠,但我没有原则性的错误,所以我不在意他们的说法。
在实际应用中,样本获取困难,多为小样本情况。常采用数据集增强(翻转、随机裁剪等)、模型集成、早停、正则化
等方法来解决过拟合现象。其中,数据集增强对过拟合缓解有一定的限度,模型集成会使训练时间倍增,早停会使训练模型的准确率降低。正则化方法中
正则化
、批归一化(BN)
、Dropout
等的应用较为普遍。
、BN正则化方法对缓解过拟合有一定限度,缓解过拟合效果小。Dropout虽然效果很好,但是存在很大的随机性和流动性,不普遍适用于现有的模型和数据集。
为了提高Dropout的普适性,学者们基于Dropout机制提出了DropPath
、CorrDrop
、DropFilterR
、DropBlock
、AttentionDrop
和TargetDrop
等改进方法。DropPath采用随机丢弃其中一些支路的策略,仅适用于Block支路较多的模型。DropBlock将随机丢弃特征单元的方案改进为自适应丢弃特征区域的策略,但随机丢弃的特点同样容易造成过拟合或欠拟合。CorrDrop和AttentionDrop的丢弃策略较为极端,均是屏蔽掉具有较明显特征的单元或具有特征不够明显的特征的区域。TargetDrop的注意力提取方法含有降维、升维操作,效率较低且会影响预测准确性,该方法仅以最大特征判别单元来确定掩盖特征判别区域,存在特征区域注意力权重代表性较弱的问题。
为了解决这些问题和增强模型训练的拟合度,本文提出跨信道注意力权重最大区域掩盖的正则化方法(MARDrop),使用一维卷积对不同通道中跨信道交互信息处理,无需降维。同时,根据注意力权重最大的特征判别单元附近注意力权重变化情况来确定注意力权重最大区域并掩盖。MARDrop降低了注意力机制的计算复杂度,提取的注意力权重也更加符合理想的分类依据,使掩盖掉的区域更加符合网络模型依据的分类特征。
1 前期工作
Dropout
通过忽略部分特征检测器的方式减少特征检测器间的相互作用,减小对局部特征的依赖性,从而减少过拟合。但是,Dropout的随机丢失以及仅对全连接层有效的特点限制了其效果。TargetDrop
是根据Dropout原理提出的正则化方法,使用类似SENet
的注意力提取机制。经注意力机制筛选后,选出部分注意力权重最大的单元作为特征判别单元,并以这些单元为中心掩盖周围区域。TargetDrop的注意力机制工作流程如图1所示。
以ResNet18为基础模型,在CIFAR-10和CIFAR-100数据集上测试MARDrop的分类错误率,并与各种改进型的Dropout正则化方法,如DropBlock、AttentionDrop、TargetDrop进行对比分析,结果见表1。


从提要的著录情况来看,明代文学整体呈递减趋势,从前文的文学分期也可看出,四库馆臣对明代文学持倒退衰敝的态度。反观开国洪武期间的文坛,短短三十余年,就有“59位作家的65部作品被收入”。[7]四库馆臣褒扬洪武期间的文学平正典雅,称其“一扫元季纤秾之习,而开明初舂容之派”。[2]479而对于晚明文坛的代表——公安、竟陵两派,《四库》则将其贬为“交煽伪体,幺弦侧调,无复正声”。[2]820可以说,馆臣对于明代文学的整体把握,不仅与史实不符,与当今的学界观点也是相悖的。
我国经济的快速发展大力推动了基础设施建设,大跨度桥梁建设项目呈现出逐年增加的趋势,其中,大部分基础形式采用桩基础,而且桩径与桩长也在不断增加。大直径超长桩基础拥有整体刚度大、承载能力强、变形小、沉降稳定快、抗震性能好等优势,逐渐得到了建筑施工界的普遍认可与应用研究。目前,我国大多数超长桩基成孔采用的设备是反循环设备,而本项目选用大功率旋挖钻进行成桩,成桩效果较好。通过对成桩倾斜度控制技术进行分析,对我国今后项目施工具有非常重要的借鉴作用。
=Sigmoid(
ReLU(
))
(1)
定义 3 若f为G的正常边染色,且对任意u,v均满足d(u)=d(v)=d,均有C(u)≠C(v),则称f为关于G的所有d度点可区别边染色。
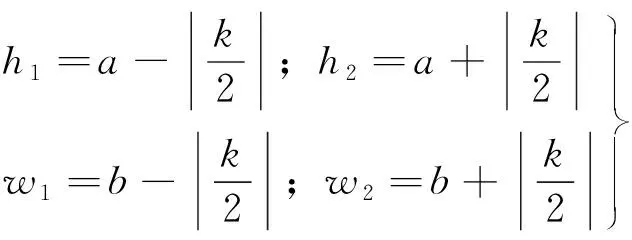
(2)
式中:
、
为特征单元中最大特征点的坐标值;
为超参数,代表掩盖的正方形区域的边长,
<
,
<
;
、
和
、
分别代表掩盖的正方形区域在
和
两个方向的顶点坐标值。
TargetDrop按照这一方法,选取出全部最大特征点并逐个掩盖掉周围的
×
区域,但掩盖掉的区域并没有包含特征最明显的区域,从而引起某些重要特征的过度训练,使分类过于依赖这些特征,进而导致过拟合现象。同时,TargetDrop使用全连接层进行降维和升维,此操作会影响通道注意力权重的预测,且在捕获通道之间依赖时也是低效的。
2 掩盖注意力权重最大区域的正则化
为了解决TargetDrop中出现的问题,本文提出了MARDrop,结构见图2。MARDrop包括特征判别单元的提取、最大特征判别区域的选择、掩盖和还原共3部分。第1部分负责注意力权重的提取、注意力图谱的构建、注意力权重的排序以及
个权重最大特征单元的筛选;第2部分负责分析
个权重最大特征单元周围区域的注意力权重变化情况,选择最大特征判别区域;第3部分是对选出的最大特征判别区域的掩盖以及非最大特征判别区域对应原特征图的还原。

2.1 特征判别单元的提取
MARDrop使用计算量更小、特征提取更准确的跨通道注意力机制对特征图
进行特征提取,得到注意力权重图谱
,然后从中筛选出部分注意力权重大的作为特征判别单元,筛选后得到注意力二值图
。

MARDrop的提取特征判别单元结构见图3。提取过程为:首先,对特征图
进行全局平均池化操作,得到一维卷积输入层
;然后,求出
的跨信道交互范围
,然后对输入层
进行一维卷积处理,求出注意力权值
;使用Sigmoid函数激活
,得到严格单调的注意力权重图谱
(介于0~1之间);最后,按照
中的注意力权重大小,选出
个重要特征通道(
为掩盖比例
与总通道数
的乘积),并将其注意力权重置为1,其余全部置为0。
求出各区域注意力权重后,选出最大特征判别区域的注意力权重
,筛选公式为

(3)
通过使用每个通道及
个邻近信道捕获跨通道交互信息(
个邻近通道对应一个通道的注意力的预测),提取更准确的注意力权重。跨通道信息交互作用的覆盖范围
与通道数
成正比,通过自适应函数确定,计算式为

由式(1)可知,TargetDrop利用全连接层的先降维后升维方法提取注意力权重,降维时会降低特征图各信道之间的信息依赖,破坏原有空间结构,引起升维过程中注意力提取效率低且注意力权重提取不准确的问题。为此,本文提出一维卷积提取注意力机制。使用注意力机制适当捕获跨信道交互信息,无需降维,不会破坏原有的空间结构。注意力权重则通过结合前一层获取的其他特征信息来确定。一维卷积提取注意力机制的过程如下。
出现HIV耐药,表示该感染者体内病毒可能耐药,同时需要密切结合临床情况,充分考虑HIV感染者的依从性,对药物的耐受性及药物的代谢吸收等因素进行综合评判。改变抗病毒治疗方案需要在有经验的医师指导下才能进行。HIV耐药结果阴性,表示该份样品未检出耐药性,但不能确定该感染者不存在耐药情况。

(4)
式中:
(
)表示关于通道
的自适应函数;|·|
表示向上取最近的奇数值操作;考虑到总通道数
不小于2、
不小于1,所以将
、
分别设置为2、1。
这符合自然规律,故乡总是留不住漂亮的孩子。可至少我、胡来、胡去,我们三个没有一点要走的意思。我们喜欢出海,但是前辈们再不让我们跟着出海。在电视机普及以后,他们就说:要出海,没出息。至于什么是有出息,他们还没想太明白。爷爷说:他们呀,总是觉得小孩子背井离乡,老头子衣锦还乡就叫有出息。成天看着太平洋,还觉得自己眼界不够宽;什么鱼都认识,还觉得自己见识不够多。
③通过响应面试验设计统计分析得到可靠性较高的二次响应面回归模型,并预测最佳工艺参数:对于固态发酵551H,发酵时间27 h,固态培养基组成/固液比值2.125,发酵温度25℃,接种量10%;对于固态发酵552H,发酵时间48 h,固态培养基组成/固液比值1.5,发酵温度30℃,接种量3%,验证试验证明该参数可行。
确定一维卷积中局部跨信道交互范围
后,使用一维卷积提取每个单元对应的注意力数据,得到
。然后,使用Sigmoid函数得到连续、光滑的严格单调注意力权重图谱
。计算过程为
=C1D(
,
)
(5)
=Sigmoid(
)
(6)
2
1
2 特征单元的筛选 根据注意力权重和丢弃比率
,在注意力图谱中选出前
个最重要特征通道。以第
个的注意力权重为筛选标准(1表示被选中,0表示未选中),将得到的相应值放入注意力二值图
中。计算过程为
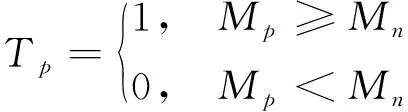
(7)
式中
、
分别为
、
中的第
个元素。
TargetDrop通过选取特征单元中的最大特征点,并以其为中心掩盖周围的
×
区域,实现掩盖区域选择,选择过程为
2.2 最大特征判别区域的选择
以所占权重最大的特征单元为中心,从中心向四周延伸时,注意力权重以不同变化率随之减小。TargetDrop使用式(2)方法,只依据特征判别单元来选择征判别区域,未对周围单元权重进行考究,并且如果所选特征单元代表性不足,则选择的特征判别区域很可能不存在代表性。
为此,本文提出根据权重变化以及注意力权重特征图来确定最大特征判别区域的方法,具体过程见图4。根据特征判别单元图
中各特征单元的位置,求出这些点在特征图
上的位置坐标,以该坐标(
,
)为中心,计算给定边长为
的正方形区域的注意力权重,以及该区域外向上、下、左、右平移后区域的注意力权重之和,比较中心区域与平移后的区域注意力权重,选出注意力权重最大区域即最大特征判别区域。
为初始的
×
区域对应的权重之和,
、
、
、
分别为
×
区域外向上、下、左、右平移后区域的注意力权重之和,计算公式为

(8)

(9)

(10)

(11)

(12)
式中
=[
,
,…,
(1,)
;…,
(,)
]。
2
1
1 注意力权重的提取 对卷积层、ReLU层处理后的特征图
进行全局平均池化处理,将特征图
之间的空间信息以及空间联系聚合到相应通道输入层
中。计算公式为
纳米药物的应用十分广泛,如制备智能化药剂,即通过机体反馈来的微环境,设计相应的具有靶向性的纳米药物,达到特异性治疗、延缓释药等效果,用于肿瘤、糖尿病和血管疾病等疾病的治疗[3]。其次,还可以应用于疾病诊断和某些疾病的辅助性治疗,如在影像学方面的应用。当前,纳米药物在中药新制剂方面的应用也十分广泛[4]。
=max{
,
,
,
,
}
(13)
对应的区域就是注意力权重最大区域,即最大特征判别区域。
2.3 掩盖和还原
确定出最大特征判别区域
后,需要将其掩盖,并还原全部未掩盖区域,得到特征图
。掩盖及还原过程见图5,图中最大特征判别区域
中黑色为掩盖区域,代表着最大特征判别区域,该区域元素置为0,其他红色区域为未掩盖区域,该区域元素置为1。将
中每个元素与原特征图
中对应元素相乘,得到特征图
。

3 实验结果与分析
3.1 实验设置
使用Python语言,在Pytorch环境开展相关实验。参数设置为:batchsize为256,优化器使用动量为0.9的SGD,初始学习率为0.1,在总时数比为0.4、0.6、0.8时衰减2e
倍。
掩盖比率是选取的掩盖特征所占总判别特征的比例,与模型对图像分类依据所占比例相关,与掩盖尺寸无关。实验固定掩盖尺寸为5×5像素,在基础模型MoblieNetV3
上分别加入掩盖比率为0.05、0.1、0.15、0.2和0.25的MARDrop,对比其在数据集CIFAR-10上的分类准确度,结果见图6。可以看出:掩盖比率从0.05增大到0.25时,分类精度呈先增大后减小的趋势;掩盖比率为0.15时,分类精度为87.25%;掩盖比率为0.2时,分类精度达到最大,为87.27%。掩盖比率取0.15和0.2时效果相差很小,但掩盖比率小可以减少MAPDrop的数据处理量,提高分类效率。因此,后续实验中取掩盖比率为0.15。
MARDrop根据特征单元周围注意力权重的分布情况,选择出最大特征判别区域并进行掩盖,需要先确定掩盖比率和掩盖尺寸,得到MARDrop的模型结构后,再开展对比实验。
3.2 确定掩盖比率
本次论坛上,专家们对清华附小主题教学的新发展给予了充分肯定。北京教科院基础教育课程教材发展研究中心王凯副主任认为主题教学试图让学生实现从“在场”到“入场”的转变,在真实体验中实际获得,提出了工具作为脚手架和通道的重要意义。北京师范大学胡定荣教授认为语文学科无边界,主题教学用课程观引领了学科教学和教师专业发展。北京教育学院刘加霞院长认为主题教学更加关注学生的体验与获得,采用了“分学科、综合用”这一最有效的学习方式来真正实现学习方式的变革。
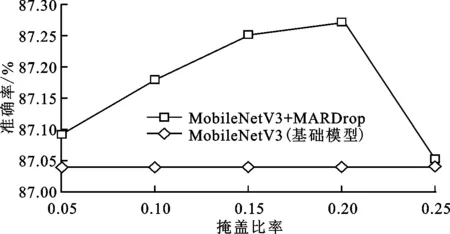
3.3 确定掩盖尺寸
掩盖尺寸是指特征判别区域尺寸,与图像被检测物体尺寸以及卷积提取的特征元素有关,与掩盖比例无关。
固定掩盖比例为0.15,在MoblieNetV3上分别使用掩盖尺寸为3×3、5×5、7×7和9×9像素的MARDrop,对比其在数据集CIFAR-10上的分类准确率,结果见图7。可以看出,随着掩盖尺寸的变化,分类准确率先升高后降低,在掩盖尺寸为5×5像素时准确率达到最高,为87.25%。后续实验中,MARDrop模块的掩盖比率和掩盖尺寸分别设置为0.15、5×5像素。

3.4 优越性验证
由表5可以看出,银行类型(bank)、营业收入(turnover)和关系年限(rela_len)三个变量显著,且回归权重均为负,这表明:(1)小微企业从国有商业银行处获得贷款的利率溢价较低;(2)小微企业的经营规模越大,其获得贷款的利率溢价较低;(3)银企关系时间越长,小微企业越有可能获得较低水平的贷款利率溢价,这与关系型贷款的研究结论一致。但三个信任变量并未对小微企业贷款利率产生显著影响,表明高程度的银行信任并不能帮助小微企业获得更低的贷款利率。综上,假说2不成立。

由表1可知,加入Dropout正则化比原基础模型错误率更高,说明训练过程中过拟合更加严重,或者出现欠拟合现象。使用DropBlock、AttentionDrop、TargetDrop时的分类精度均比Dropout有所提升,MARDrop在两个数据集上分类错误率均最小。相对于基础模型,加入MARDrop后在CIFAR-10上分类错误率降低了9.96%,在CIFAR-100上错误率降低了5.83%。相比于2020年提出的TargetDrop
,MARDrop在CIFAR-10和CIFAR-100上分类错误率分别降低了3.63%和1.03%。
3.5 泛化性验证
3.5.1 不同模型上的泛化性验证 在ResNet20、VGG16、WRN28-10、MoblieNetV3S、MoblieNetV3L、EfficientnetV2和DenisNet-SE共7个网络模型上,分别加MARDrop、Dropout、TargetDrop正则化方法,并在CIFAR-10数据集上测试分类准确率,结果见表2。其中,EfficientnetV2和DenisNet-SE两个模型的参数比较复杂,使用了原文中的参数,其他5个模型均采用3.1小节设置的参数。

由表2可知,加入Dropout后,VGG16、WRN2810错误率不降反升,ResNet20的错误率有所下降。加入TargetDrop后,7个网络模型的分类错误率均有所下降。MARDrop在7个网络模型均获得了最低的分类错误率。对于VGG16,加入MARDrop后在CIFAR-10上分类错误比基础模型降低了10.05%,比使用TargetDrop错误率降低了5.77%。在2021年提出的最新模型DenisNet-SE
上,加入MARDrop后比基础模型的分类错误率降低了5.78%。
3.5.2 不同图像尺寸数据集上的泛化性验证 从ImageNet数据集中选前9类制作成ImageNet_C9数据集(训练集和测试集按照数据量7∶3的比例划分),分别在MoblieNetV3S、MoblieNetV3L上使用MARDrop正则化方法对ImageNet_C9数据集进行分类实验,MARDrop参数设置以及实验结果见表3。

由表3可知,使用MARDrop后,MoblieNetV3L错误率降低了14.67%。使用MobileNetV3S模型实验时掩盖比例调整为0.10,加入MARDrop后分类错误率降低了96.90%。
VE-1和世锐的推出,推动广汽本田产品阵营更加多元化,更助力广汽本田电动化战略迈出坚实的一步。VE-1基于Honda成熟紧凑型SUV平台开发,搭载永磁同步电机及53.6千瓦时三元锂电池包,工况续航里程为340公里,等速续航里程为430公里。世锐搭载1.5升阿特金森循环发动机和国内首创G-MC无级变速机电耦合系统组成的插电式混动系统,配合12千瓦时电池组,可实现纯电驱动、增程及混合动力多种驱动模式。
临床上应加大对样本采集及送检环节的监督与管理力度,并且应制定出规范、科学的管理制度标准;在采样前,应该充分做好相关的准备工作,尽可能地避免人为操作意外的出现;注意样本采集的最佳时间,以防感染外源性细菌而影响检验质量;样本采集完毕后,应在规定时间内送试验室进行检验,根据样本类型的不同而采用不同的处理方法;一般试验室温度最好控制在19~26℃之间,湿度维持在40%~60%之间,从而确保临床免疫检验结果的精准性;注重检验方法的合理选择,尽量应用较常见的试剂,确保检验方法具有较高的重复性、特异性及敏感性,并且无交叉反应。[3]
3.6 灵活性验证
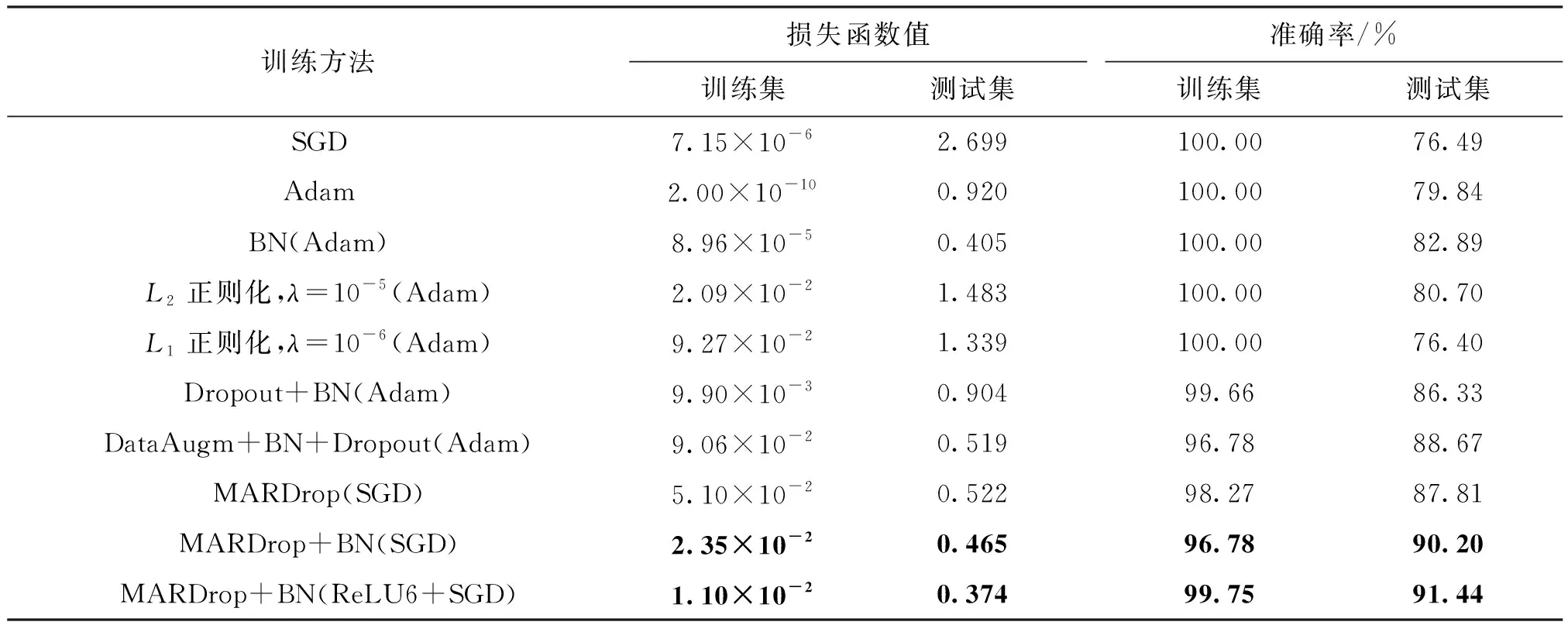
以文献[25]中搭建的Model2为基础模型,在CIFAR-10数据集上测试MARDrop的优越性及其和不同优化器或者正则化方法相结合的灵活性,每组实验的参数设置相同,测试结果见表4。表中,SGD和Adam是Model2基础模型的测试结果。
由表4可知,相对于基础模型,使用正则化方法后,测试集与训练集的损失函数值明显减小,训练准确率与测试准确率差值减小。采用正则化方法组合的优化方案后,训练集准确率小于100%,且测试集准确率远大于原模型准确率,说明优化后模型的拟合程度高于原模型拟合程度。从分类精度的角度分析,使用优化器Adam的基础模型效果较好。在此基础模型上加入不同正则化方法后,除了加入
正则化后分类精度降低外,其余均有所提升。使用优化器SGD的基础模型效果较差,比使用Adam时的分类精度低了4.20%。为了更好地显示MARDrop的优势,在使用SGD的基础模型上分别引入MARDrop、MARDrop+BN、MARDrop+BN+ReLU6,开展3个实验。可以看出,相对于仅使用SGD时的分类精度76.49%,3个实验的分类精度分别提高到了87.81%、90.20%和91.44%,提升率分别为14.79%、17.92%和19.55%。
4 结 论
为了解决现有正则化方法对过拟合现象处理效果不足的缺点,本文提出使用跨通道的注意力机制提取注意力权重,根据注意力权重选择特征单元并通过比较附近区域权重大小选择出注意力权重最大区域,最后将该区域掩盖并还原为特征图的正则化方法。为了证明该方法的有效性,本文将MARDrop方法用于不同CNN分类模型,在CIFAR-10、CIFAR-100数据集进行图像分类测试。测试结论如下。
(1)确定掩盖比率和掩盖尺寸的实验结果表明,可以通过调节MARDrop的掩盖比率和掩盖尺寸使拟合情况达到最优。
(2)MARDrop与不同Drop机制正则化方法对比,错误率均最低。相比于对过拟合处理最好的TargetDrop,使用MARDrop在CIFAR-10、CIFAR-100上分类错误率分别降低了3.63%、1.03%。证明了该方法相对于同类方法的优越性。
(3)DenisNet-SE等7种模型经MARDrop优化后在CAFIR-10上的分类错误率均有所降低。使用MoblieNetV3在图像尺寸不同的ImageNet-C9数据集上分类错误率相对于基础模型分别降低了14.67%和96.90%。这两组实验证明了MARDrop方法的泛化性。
(4)使用包含MARDrop的多种正则化方法优化后,模型在CAFIR-10上的拟合程度远高于使用其他正则化方法优化的模型,其中使用MARDrop+BN(ReLU6+SGD)方法优化后在CIFAR-10上的分类准确率比原模型提高了19.55%,证明了MARDrop方法的灵活性。
:
[1]吕永标, 赵建伟, 曹飞龙. 基于复合卷积神经网络的图像去噪算法 [J]. 模式识别与人工智能, 2017, 30(2): 97-105.
LÜ Yongbiao, ZHAO Jianwei, CAO Feilong. Image denoising algorithm based on composite convolutional neural network [J]. Pattern Recognition and Artificial Intelligence, 2017, 30(2): 97-105.
[2]SONG Jia, GAO Shaohua, ZHU Yunqiang, et al. A survey of remote sensing image classification based on CNNs [J]. Big Earth Data, 2019, 3(3): 232-254.
[3]宋长明, 王赟. 融合低秩和稀疏表示的图像超分辨率重建算法 [J]. 西安交通大学学报, 2018, 52(7): 18-24.
SONG Changming, WANG Yun. Super resolution reconstruction algorithm combined low rank with sparse representation [J]. Journal of Xi’an Jiaotong University, 2018, 52(7): 18-24.
[4]ZHANG Xiangyu, LI Jianqing, CAI Zhipeng, et al. Over-fitting suppression training strategies for deep learning-based atrial fibrillation detection [J]. Medical & Biological Engineering & Computing, 2021, 59(1): 165-173.
[5]任义丽, 罗路. 卷积神经网络过拟合问题研究 [J]. 信息系统工程, 2019(5): 140, 142.
REN Yili, LUO Lu. Research on over-fitting of convolutional neural networks [J]. China CIO News, 2019(5): 140, 142.
[6]谢璐阳, 夏兆君, 朱少华, 等. 基于卷积神经网络的图像识别过拟合问题分析与研究 [J]. 软件工程, 2019, 22(10): 27-29, 26.
XIE Luyang, XIA Zhaojun, ZHU Shaohua, et al. Analysis and research of overfitting of image recognition based on convolutional neural networks [J]. Software Engineering, 2019, 22(10): 27-29, 26.
[7]HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition [C]∥Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE, 2016: 770-778.
[8]SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale visual recognition [C/OL]∥Proceedings of the International Conference on Learning Representations. London, UK: ICLR, 2015 [2021-05-01]. https: ∥arxiv.org/pdf/1409. 1556.pdf.
[9]ZAGORUYKO S, KOMODAKIS N. Wide residual networks [C]∥Proceedings of the 2016 British Machine Vision Conference (BMVC). Guildford, UK: BMVA Press, 2016: 1-15.
[10]HOWARD A G, ZHU Menglong, CHEN Bo, et al. MobileNets: efficient convolutional neural networks for mobile vision applications [EB/OL]. [2021-05-01]. https: ∥arxiv.org/abs/1704.04861.
[11]KAVYASHREE P S P, EL-SHARKAWY M. Compressed MobileNet V3: a light weight variant for resource-constrained platforms [C]∥Proceedings of the 2021 IEEE 11th Annual Computing and Communication Workshop and Conference (CCWC). Piscataway, NJ, USA: IEEE, 2021: 0104-0107.
[12]TAN Mingxing, LE Q V. EfficientNetV2: smaller models and faster training [C]∥Proceedings of the 38th International Conference on Machine Learning. Princeton, NJ, USA: IMLS, 2021: 10096-10106.
[13]YANG Mingming, MA Tinghuai, TIAN Qing, et al. Aggregated squeeze-and-excitation transformations for densely connected convolutional networks [J/OL]. The Visual Computer, 2021 [2021-05-01]. https: ∥doi.org/10.1007/s00371-021-02144-z.
[14]WANG Haojun, LONG Haixia, WANG Ailan, et al. Deep learning and regularization algorithms for malicious code classification [J]. IEEE Access, 2021, 9: 91512-91523.
[15]LIU Ziqi. XU Yanbin, DONG Feng.
-
spatial adaptive regularization method for electrical tomography [C]∥Proceedings of the 2019 Chinese Control Conference (CCC). Piscataway, NJ, USA: IEEE, 2019: 3346-3351.
[16]ABBASI A N, HE Mingyi. Convolutional neural network with PCA and batch normalization for hyperspectral image classification [C]∥Proceedings of the 2019 IEEE International Geoscience and Remote Sensing Symposium. Piscataway, NJ, USA: IEEE, 2019: 959-962.
[17]SRIVASTAVA N, HINTON G, KRIZHEVSKY A, et al. Dropout: a simple way to prevent neural networks from overfitting [J]. The Journal of Machine Learning Research, 2014, 15(1): 1929-1958.
[18]ZOPH B, VASUDEVAN V, SHLENS J, et al. Learning transferable architectures for scalable image recognition [C]∥Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2018: 8697-8710.
[19]ZENG Yuyuan, DAI Tao, XIA Shutao. Corrdrop: correlation based dropout for convolutional neural networks [C]∥Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Piscataway, NJ, USA: IEEE, 2020: 3742-3746.
[20]PAN Hengyue, NIU Xin, LI Rongchun, et al. DropFilterR: a novel regularization method for learning convolutional neural networks [J]. Neural Processing Letters, 2020, 51(2): 1285-1298.
[21]GHIASI G, LIN T Y, LE Q V. DropBlock: a regularization method for convolutional networks [C]∥Proceedings of the 32nd International Conference on Neural Information Processing Systems. Vancouver, Canada: NIPS, 2018: 10750-10760.
[22]OUYANG Zhihao, FENG Yan, HE Zihao, et al. Attentiondrop for convolutional neural networks [C]∥Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME). Piscataway, NJ, USA: IEEE, 2019: 1342-1347.
[23]ZHU Hui, ZHAO Xiaofang. TargetDrop: a targeted regularization method for convolutional neural networks [EB/OL]. [2021-05-01]. https: ∥arxiv.org/abs/2010.10716.
[24]HU Jie, SHEN Li, SUN Gang. Squeeze-and-excitation networks [C]∥Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2018: 7132-7141.
[25]MARIN I, KUZMANIC SKELIN A, GRUJIC T, et al. Empirical evaluation of the effect of optimization and regularization techniques on the generalization performance of deep convolutional neural network [J]. Applied Sciences, 2020, 10(21): 7817.
猜你喜欢
延边大学学报(自然科学版)(2022年1期)2022-06-13
心理学报(2022年5期)2022-05-16
华南师范大学学报(自然科学版)(2021年5期)2021-11-09
当代陕西(2020年17期)2020-10-28
新课程·上旬(2019年1期)2019-03-18
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
上海师范大学学报·自然科学版(2018年3期)2018-05-14
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
教师·中(2017年3期)2017-04-20
