
基于支持向量机的短文本分类方法
2022-03-10 01:23赵延平
计算机与现代化 2022年2期
赵延平,王 芳,夏 杨
(北京交通大学信息中心,北京 100044)
0 引 言
随着互联网的兴起,越来越多的商家关心用户对其产品的咨询和评论,从而进行用户满意度分析、倾向性分析和用户关联性分析,以便给商家提供更良好的决策支持。分析用户的咨询针对的是哪类产品或哪方面问题,是一种文本分类方法。在电信领域中,用户的咨询都在160字以内,称为短文本。本文针对这些短文本进行主题分类,对子串和子序列特征进行度量,利用SVM分类器实现分类。
1 相关工作
常见短文本分类有2种方法。一是利用搜索引擎扩展短文本[1],这种分类方法仅仅扩展了文本,但对无效信息和噪声处理不佳,且消耗时间长,并且分类效果对搜索引擎依赖较大。二是在短文本特征的基础上,利用知识库,发现词之间的语义关系[2],如维基百科,利用语义特征进行分类;还有一种分类方式是利用短文本隐藏的主题作为额外特征集,与原始特征一并用于训练和分类[3]。这2种方式都是在人工干预的情况下扩展特征,然后进行相似度计算,虽然也可以取得不错的效果,但获取有效特征比较困难。本文摆脱这种外部依赖,针对特定领域,提出利用Web模式序列挖掘PLWAP算法[4-5]得到频繁子串和子序列特征从而进行分类,经实验,得到了良好的效果。
2 Web模式序列挖掘算法PLWAP
WAP算法对项目的前缀树进行挖掘,PLWAP算法基于WAP算法[5],对某个项目的后缀树进行挖掘。PLWAP-Tree算法描述如下:
算法:PLWAP-Tree
输入:Web访问序列数据库WASD;
支持度阈值λ(0<λ≤1);
频繁事件集L。
输出:PLWAP-Tree
方法:
1)扫描原始数据,得到频繁项目FE集合
2)再次扫描FE中每个event
If current tree node has children
if event is one of the child:
the count of current node=count +1
else:
insert into tree as a new node
the count of new node =1
position code=rightmost child node position code +′0′
endif
else:
insert into tree as a new node;
the count of new node=1
position code=parent node position code +′1′
endif
之后对PLWAP-tree进行挖掘,输出所有满足最小支持度阈值的频繁模式。
本文采用这种方法得到所有频繁子串和子序列。
3 咨询短文本分类方法
3.1 研究背景及意义
本文数据集来源于某移动公司客服平台的真实数据,该平台每天实时接收用户通过手机/Web对运营商所提供的各种业务的实时咨询,并对问题进行自动回复。本文收集了4个月的数据,有百万条级别的文本。把所有文本分为4类,分别是介绍、开通、使用、取消。介绍类是用户对业务的了解;开通类是用户针对如何开通或开通过程中的咨询;使用类是指用户开通后,在使用过程中的咨询,另外,优惠类咨询和比较类咨询本文都统一归为使用类;取消类是针对如何取消或取消过程中的咨询。以下以彩铃业务咨询语句为例,其中的实验数据集描述如表1所示。
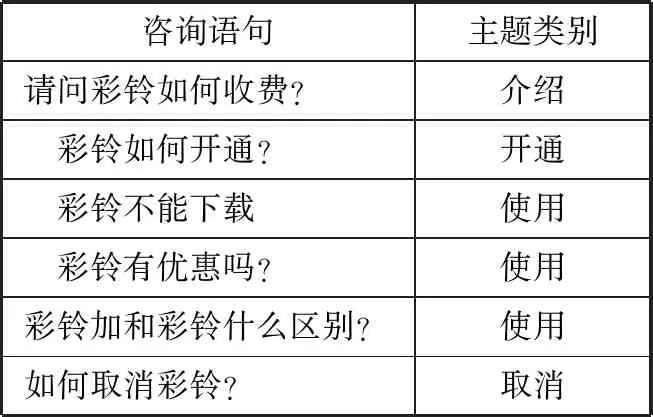
表1 实验数据集描述
本文的目标是分析每一条无结构化的用户咨询文本,得到结构化信息用于支持企业进一步地对不同业务的统计分析。它分为4子任务:1)识别用户发送信息的情绪倾向;2)分析表达情绪所针对的业务[6];3)分析信息的主题;4)对用户发送信息形成摘要。例如对于表1中的第一条咨询语句,系统所抽取的信息如下:
情绪倾向:“非负情绪”
相关业务:“彩铃”
相关主题:“介绍”
文本摘要:“彩铃如何收费”
本文主要完成第三个子任务。
3.2 分类特征
通过观察每类特征,发现每种类别经常会出现一些词或串,如开通类经常会出现“开通”“如何开通”“怎样开通”,取消类经常会出现“取消”“如何取消”“怎么取消”,使用类经常会出现“怎么用不了”“怎么不能下载”“为什么……却……不”等,类似地,其他主题也会有相应的模式。这种模式分别是文本的字串和子序列,直观上这2种特征是很有用的分类特征。
由于针对汉语的依存语法分析准确率和时间效率尚不高,所以本文未对句子进行依存语法的分析,因而,本文主要使用第一种特征,即句法特征。它可以分为2类:子串(在语句中连续出现)和子序列(在语句中按顺序出现):
1)子串:在一个字符串中连续出现的元素形成的串称为子串。针对语句有不分词和分词2种情形:
①N-gram:一个N-gram(N=1, 2, 3)是一条语句中连续出现的N个字形成的字串。
②公共频繁词语串(frequent common word substring):将语句进行分词,频繁出现的一个或连续多个词语形成的串。例如语句“我的手机7610,请问网络怎样才能使用?怎样才能开通网络?”,若其子串“怎样才能开通”在其他语句也经常出现,则称该子串为公共频繁词语串。
2)公共频繁子序列(frequent common subsequence):对语句分词后,频繁出现的且保持顺序的一个或多词语构成的子序列。对语句分词是为了在得到意义明确的频繁子序列时,避免生成单字组成的子序列。例如语句“开通移动网络收费吗?”,经过分词处理:“开通 移动 网络 收费 吗?”,可能计算得到的频繁子序列是:“开通……收费……”。
3.3 特征抽取
如何确定支持度阈值是个关键问题,当给定支持度阈值较小时,可能会带来大量的冗余特征的问题,当给定支持度阈值较大时,得到的特征对分类没有帮助,因而,本文要进行特征选择。最常用的特征度量方法有信息增益(Information Gain, IG)、卡方统计量(CHI)、互信息(Mutual Information, MI)、词频(Document Frequency, DF)等。文献[7]选取高指示性特征用于分类。文献[8-11]利用互信息进行特征选择,然后获取主题词,再把这些词扩充到短文本的特征中进行分类。文献[12-14]建立规则库作为特征进行分类。文献[15-17]针对中文文本分类中的特征方法进行了对比。在实际应用中,本文采用了信息增益、互信息、卡方统计这3种特征选择方法并进行对比。但限于篇幅,本文仅介绍信息增益的定义:
假设文本D有m种类别C1,C2,…,Cm,P(Ci)表示未给定任何特征时类别Ci出现的概率,P(Ci|f)表示给定特征f时类别Ci出现的概率,则一个特征f的信息增益是在给定特征f下文本的熵与未给定任何特征时文本的熵的增益,形式化如下:
Gain(f)=Entropy(D)-Entropy(D|f)
然而,众所周知,有些度量(比如CHI)对于低频词的度量不够准确。另外,笔者发现在给定领域下,用户咨询中频繁出现的子序列或子串具有较强的语义,并体现一定的情感。为了抽取这些特征,提出使用基于半监督的方法进行特征选择(见图1),可以分为如下2个步骤:

图1 基于半监督的特征选择
1)通过频繁挖掘算法获取频繁子串和子序列,形成候选特征集。
2)在有标记的文本上计算IG/MI/CHI,选择其取值高的特征,得到有效的特征集。
一些典型的特征如表2所示。

表2 典型特征举例
这种特征选择方法有效地使用了大量未标记文本中的信息,避免训练语料不足导致的被忽略的低频度特征,保证选择满足一定频度的特征。
3.4 部分冗余特征的处理
使用频繁子串特征和频繁子序列特征带来的一个问题就是可能会带来冗余,因为对于任意频繁子序列f1,其任意子序列仍是频繁的;同理,对于任意特征频繁子串f2,其任意子串仍是频繁子串。尽管使用特征选择算法已经挑选了对文本分类区分能力强的特征,可能已经消除了一些冗余。对此,本文通过使用极大匹配来分析该部分冗余特征的作用:
极大匹配是指从文本转化为向量表示时,只使用极大的特征,形式化如下:
句子s可用k个特征f1,f2,…,fk表示,则∀i,j≤k,i≠j,fi不是fj的子串或子序列。
例如句子“八月份的优惠是充三百送一百五的未赠送也未发短信,告知我什么时候送?”在文本匹配特征时,如果已经匹配到一个特征“未赠送”,之后又匹配到一个子序列特征“充…送…未赠送”,则只匹配当前极大特征,即“充…送…未赠送”。即文本转换为特征向量时,所有特征是极大的,它们之间没有包含关系。
4 实 验
4.1 实验结果
本文以150000条短信作为实验语料,其中每条短信都包含词性标注信息和业务分类信息。人工选取10000条作为训练语料,5000条作为封闭测试语料,其他为开放测试语料。本文使用了2种已有的开源算法:分词算法使用中科院计算所的分词软件ICTCLAS;频繁子序列挖掘算法使用由C.I. Ezeife等提出的基于WAP树的序列挖掘算法。
本文使用了广泛应用于文本分类的SVM分类器[18-19](C.-J. Lin开发的libsvm[20])。实验步骤如下:
1)预处理:去除停用词(例如“我”“和”“与”等),将每条用户文本分割为句子。
2)对于已标记文本,生成1-gram、2-gram、3-gram。
3)根据未标记文本及已标记文本进行分词,之后计算频繁子序列和频繁子串,其中最小支持度阈值设为20/10000。
4)对于步骤2和步骤3得到的所有特征,计算IG,进行特征选择。
5)将语句转化为特征的向量表示:向量中的每一维对应一个特征,当语句具有一个特征时,向量对应的值为1,否则为0。
6)训练SVM分类器。
上述实验中,频繁子序列和频繁子串的支持度阈值可以通过十字交叉验证来确定。本文在同一组训练语料上进行了3组对比实验:使用十折交叉验证进行极大匹配和非极大匹配时的性能对比(表3);仅使用子串特征与增加子序列特征后的性能对比(表4);使用IG、MI、CHI这3种度量时分类器的性能对比(表5)。由于实验中每个类别所占比例不同,实验中各主题类别的召回率和总体准确率(召回率)。性能指标定义如下:
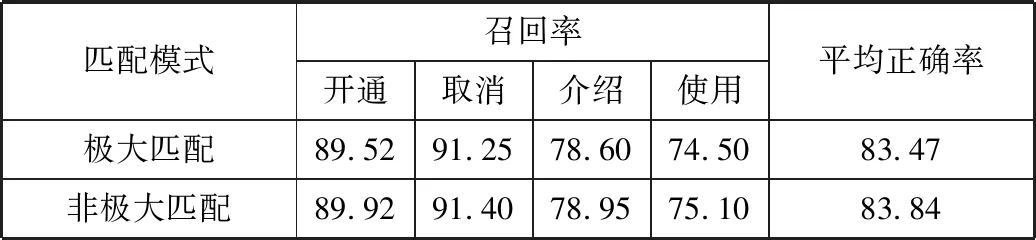
表3 十折交叉上2种匹配模式召回率和正确率/%
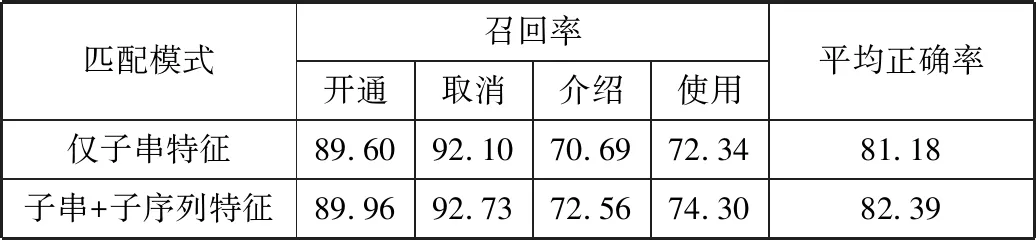
表4 子串特征及增加子序列特征后召回率和正确率/%

表5 3种度量开放测试召回率和正确率/%


4.2 结果分析
从表3可以看出,极大匹配和非极大匹配的性能几乎相当,可见使用子序列特征所造成的部分冗余特征对分类器性能的影响可以忽略。表4显示了仅使用子串特征和引入子序列特征后的性能情况,可以看出仅使用子串特征可以达到较高的性能,引入频繁子序列后性能略有提高。文献[8]中对文本分类中的各种度量特征的方法进行了对比,他们的实验表明IG和CHI的性能最高。表5显示了本文使用3种度量训练的分类器的分类结果,可以看出三者性能差异较小,其中使用IG的性能略高。
从实验结果可以看出,分类器整体的分类能力比较好,开通、取消类特征较明显,所以召回率比较高。但介绍、使用类有相互混淆的特征,所以二者召回率相对较低。另外,IG值高的频繁子序列或频繁子串,表示它们在某一个类别中频繁出现,同时可以发现其体现很强的语义,它可以进一步支持构造业务本体以及用户问题的摘要提取,一些实例如表6所示。

表6 高IG的特征及蕴含的语义
4.3 讨论
本文总结了一些分类错误的句子,难于分类的主要有如下几类:
1)短文本:导致文本的“特征稀疏”,因而分类器很容易错误分类。例如:
①“开GPRS”(特征“开”,正确分类:开通,实验结果:介绍)
②“查密码”(特征“无”,正确分类:使用,实验结果:其他)
2)对比:句子通过对比来陈述事实,但因特征不明显,归类错误。
例如下面2条咨询正确分类为使用,实验结果为其他:
①“刚才我拨打一个电话,讲了55秒的时间,为何变成1.08分钟?”
②“您好?我的手机扣了四十块钱的月租,我三月份开通的新号码,月租本来是十九块钱吗!”
3)其它原因,比如文本中包含错别字、表述不清楚、缺乏标点符号等。
另外,还有一些可以进一步改进的问题,对不同子句中的特征建立一种条件或顺序上的关联模型,从而研究文本中几个子句的关系,才能更准确地判断分类,也可以更容易生成文本的摘要。
例如“本来有开通电脑飞信,今天用不了,说未开通此项业务,这种情况不是第一次”。关联一些特征“用不了”“未开通”以及“不是第一次”才能判断出其类别。
5 结束语
本文尝试对短文本进行分类,使用了子序列和子串2种句法特征,并通过半监督的思想进行频繁子序列/子串的特征选择,有效地利用了未标记文本的信息。同时,讨论了频繁子串/子序列带来的特征冗余问题,实验表明使用这些特征可以达到较好的分类效果。
然而,在短文本分类过程中,还有如下问题需要进一步研究:如何抽取更有效的句法特征[21-22];对于不同类别数据的不平衡性,研究针对非平衡数据的分类问题;如何利用句子中评价语的依赖关系以及引入语义资源来提高分类的准确性。
猜你喜欢
福州大学学报(自然科学版)(2022年1期)2022-01-21
河南科学(2021年3期)2021-05-06
计算机系统应用(2021年2期)2021-02-23
新世纪智能(语文备考)(2020年4期)2020-07-25
电子技术与软件工程(2019年18期)2019-11-18
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年3期)2017-05-24
电子制作(2017年23期)2017-02-02
航天返回与遥感(2014年5期)2014-07-31
小学生·多元智能大王(2014年6期)2014-07-09
