
Inf-ProA信息活动过程模型相似性度量方法
2022-03-10 00:46邹梦苑樊志强梁万路
计算机与现代化 2022年2期
邹梦苑,樊志强,2,徐 珞,刘 洁,梁万路
(1.华北计算技术研究所创新中心,北京 100083; 2.军事科学院,北京 100091; 3.中国电科智能科技研究院,北京 100005; 4.北京市信息技术研究所,北京 100036)
0 引 言
架构开发对于一个大型信息系统/体系来说意义重大,其开发过程往往涉及多个利益相关者、各种复杂的活动和多个开发阶段。一个完善的架构可以有效地满足用户的需求,并保持系统的强大生命力。大型信息系统/体系的架构开发需要科学的方法论支撑,目前国内外的主流架构方法有美国的DoDAF[1]、英国的MoDAF[2]、北约的NAF[3]、开放组织体提出的ToGAF[4],以及国内提出的信息主导的体系架构框架(简称“Inf-ProA框架”)[5]。随着全军顶层设计工作的开展和推进,很多单位使用Inf-ProA框架及其配套的工具开展了军事领域的架构设计工作,并逐步积累形成了一定数量的架构设计模型资产。在架构师进行模型设计时,存在着广泛的参考已有相似模型的需求。然而,现有的架构方法和工具还无法对有参考价值的相似模型进行度量和推荐。因此,本文研究一种基于架构模型特征的相似性有效度量方法,在未来的架构设计过程中十分必要。
信息活动过程模型是Inf-ProA框架的最核心的模型,因此,本文重点研究Inf-ProA信息活动过程模型相似性度量方法。
1 相关研究分析
目前还没有直接针对信息活动过程模型相似性度量的相关研究,考虑信息活动过程模型的设计要素(信息活动、信息流、信息界面等)和存储特征(XML格式存储),可以参考对统一建模语言(Unified Modeling Language, UML)模型相似性和可扩展标记语言(Extensible Markup Language, XML)文档相似性衡量的方法。近年来,有学者[6-8]提出了几种测量UML模型之间相似性的方法,WebDiff[9]和MADMatch[10]即是这些方法的例子。软件开发人员利用这些方法来度量UML模型的相似程度,甚至可以确定它们的共性和差异。它们允许开发人员处理与其相关的UML模型的特定部分。在合并所做的更改之前,需要测量并行创建的UML模型版本之间的相似性。从实证性研究[8-11]中可了解到,计算相似性仍然被认为是一个高度容易出错和耗时间的任务。同时,目前的相似性测量方法在精度和灵敏度方面通常达不到预期的效果[12-13]。因此,软件开发人员最终使用了不精确的相似度测量的方法来找出快速变化的信息系统的设计模型的相似度。Gonçales等[14]提出了UMLSim方法,这是一种测量UML模型之间相似性的混合方法。它通过使用多种标准来量化UML模型的相似性,包括语义、语法、结构和设计标准。虽然UML模型与IAV-1a(信息活动过程)模型间具有一定的相似性,但由于模型的定义和元模型仍存在较大的差异,故而UML模型相似性度量的方法并不能直接很好地运用于信息活动过程模型中。但是,UMLSim的多方面相似度量算子的构造和思想值得借鉴和学习。Zhang等[15]从理论上严格证明了2个XML文档间的距离可以通过计算它们的索引树间的距离来测定。张力生等[16]提出了基于路径特征的XML结构相似度量方法SSPF(Similarity based on Sequence, Position and Frequency)。该方法充分利用提取的DOM树路径信息,对树路径间序列和位置的相似度计算进行优化,并考虑了路径频率对相似度的影响。虽然IAV-1a模型也是以XML文档的形式存储,但并不能简单地将IAV-1a模型相似性度量归结为XML文档相似性度量。因为IAV-1a模型包含更多的设计要素在模型中,若转换为XML文档树的结构会丢失较多的信息,同时准确度也不高。
从实践研究中发现,IAV-1a模型的相似主要有以下的情况特征:
1)存在多个相同或相似的信息活动名称和信息流名称;
2)相似模型间存在子图或结构相同的部分;
3)存在相同的设计思路或设计趋势。
通过对这些相似特征进行科学合理的衡量便可得到IAV-1a模型的相似性度量方法。本文提出的方法主要从以下3个方面来量化IAV-1a模型的相似性:
1)内容相似性度量,即信息活动名称和信息流名称的相似性度量。
2)结构相似性度量,即判断是否包含子图或存在相同的结构,并以此作为模型的结构相似性。
3)设计趋势相似性度量,即通过考虑输入或输出信息流与结构的关系,对模型的设计趋势进行度量。
基于以上的学习和探索,本文提出一种可用于衡量Inf-ProA信息活动过程模型相似度的方法。
2 Inf-ProA信息活动过程模型介绍
IAV-1a模型是信息活动视角和信息架构的核心模型之一,用于对信息的加工处理过程进行描述,包括信息活动、信息流、信息界面等设计要素。
IAV-1a模型确定了支撑需求架构的信息活动流程,依据合理的信息加工处理需求来梳理和提取体系的信息活动。该模型把活动与过程合并成一个对象设计,活动由过程实现,过程是活动的集合,两者是一个整体。信息活动将输入的信息进行加工处理,并产生输出信息,活动之间通过信息流连接,信息流将一个信息活动的输出连接至另外一个信息活动的输入。IAV-1a采用如图1所示的信息活动过程模型进行描述,由信息活动(矩形)、输入界面(活动左侧倒T字)、输出界面(活动右侧倒T字)、信息流(有向线)和信息端(椭圆)组成。

图1 IAV-1a模型示例
IAV-1a模型采用层次化的过程模型对体系的信息活动过程进行描述。要进行信息架构设计,首先要把一个大的体系或系统分解成若干项信息活动,形成体系信息行为的整体架构,即构建活动模型。
3 信息活动过程模型相似性度量方法
3.1 模型要素及度量内容
IAV-1a模型主要包含以下几种架构设计要素:
1)信息活动:信息活动是该模型的核心建模元素,是指完成与信息处理相关的任务所执行的一项动作。信息活动的提取可依据业务流程中有信息输入输出的活动,将有相关信息输入输出的活动分别单独提取其信息活动,然后进行整体考虑合并,也可以参考信息活动生命周期模型中的活动类别定义信息活动,如信息采集活动、信息存储活动、信息发布活动等。信息活动的主要属性包括:活动名称、活动标识、活动说明。
2)输入界面:输入界面是信息活动接受其他活动作用的界面,可以是行为动作关系,也可以是技术接口关系等。
3)输出界面:输出界面是信息活动作用于其他活动的界面,可以是行为动作关系,也可以是技术接口关系。
4)信息流:信息流用以链接信息活动,使一个信息活动的信息输出成为另一个信息活动的输入信息,两者之间的连接表示了活动间的信息流向,用有向线“→”表示,并用特殊标识或短语对其命名,进行唯一标识。信息流上的信息标示和名称给出了信息活动之间需要交换的信息,但并不需要说明如何实现信息交换。信息流和信息是多对多的关系,即一条信息流上可能传递多个信息,一个信息可能在多条信息流上传递。
基于IAV-1a模型主要包含的架构设计要素,本文提出的方法主要是对2个模型之间的内容相似性、结构相似性以及设计相似性3个方面进行衡量。内容相似性是指活动名称和信息流名称上的相似性,即用模型中相同内容所占总体元素内容数量的比例来反映内容上的相似性(详见3.3节);结构相似性是指模型中信息活动的输入输出流向结构之间的相似性(详见3.4节);设计相似性是指在设计模型的过程中,接近最终设计结果的相似模型,故考虑将输入输出关系与结构相结合的相似性作为模型的设计相似性,即基于模型的输入和输出界面,通过泛化的模型结构计算出的设计相似性结果(详见3.5节)。
3.2 模型相似性度量整体思路
本文基于信息活动模型的基本架构设计要素,采用一种创新的方法,通过多个方面来量化信息活动过程模型的相似性,包括内容和结构上相似性的衡量,以及考虑了接近模型最终设计结果上的设计相似性,使得到的相似性度量结果更具有合理性。信息活动过程模型相似度计算的算法流程如图2所示。

图2 IAV-1a模型相似性计算流程
其中内容相似性部分主要指通过对模型信息活动名称和信息流名称提取,比较相同内容元素所占总体内容数量的比例,以此作为对模型内容相似性的度量;结构相似性部分主要是通过对模型间子图或结构相同部分的计算,得出模型结构上的相似性[17];设计相似性部分是通过考虑输入或输出信息流与结构的关系,将模型的有向图结构转化为关联图和泛化图[18]进而得到模型的设计相似性。最后,通过对3个方面相似性的综合便可以结算出模型间总体的相似性。
设输入的2个待衡量信息活动过程模型A和B。通过这个过程进行对输入的模型MA与MB间相似性的计算。本文提出的Inf-ProA信息活动过程模型相似性度量过程的步骤描述如下:
步骤1 内容相似性。旨在计算2个输入模型MA与MB之间的内容相似性,得出内容相似矩阵,如图3所示。其中a(行)和b(列)分别为MA与MB模型元素即信息活动的数量。为此,需要对比模型中的主要内容要素,包括信息活动、信息流。由于信息活动输入、输出接口不包含内容信息,故不考虑。
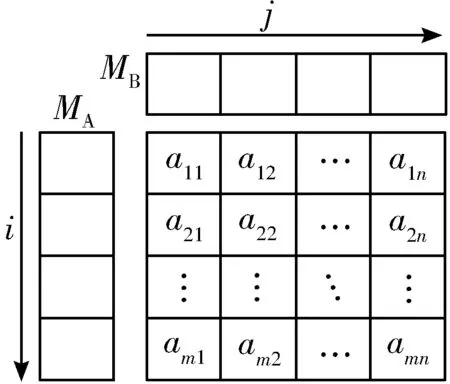
图3 相似矩阵
步骤2 结构相似性。这一步试图发现模型MA与MB之间的结构是否相似。判断依据主要是模型的图结构是否同构,关于子图同构的定义见定义1。
定义1 子图同构。假设有2个图H=(VH,EH)和图G=(V,E)子图同构,即从H到G存在着一个函数f:VH→V并且(u,v)∈EH使得(f(u),f(v))∈E同样成立,f叫做子图同构的一个映射。
步骤3 设计相似性。通过文本内容和架构模型结构对比后,为了达到更准确相似度,需要对正在设计模型的设计趋势进行量化。这一步主要是将模型转化为有向图的泛化图和关联图后进行对比,从而确定模型MA与MB之间的设计相似性。
定义2 泛化图与关联图。有向图G=(V,E)可以表示面向对象系统的类图,顶点集(V)对应于系统中的所有类集合,边集(E)对应于这些类之间关系的集合,比如有向边(p,q)∈E表示类p与q的关联关系方向是从p到q。模型的输入输出关系(包括泛化、关联、组合)都可以表示成有向图,图4是一个简单的有向图示例。
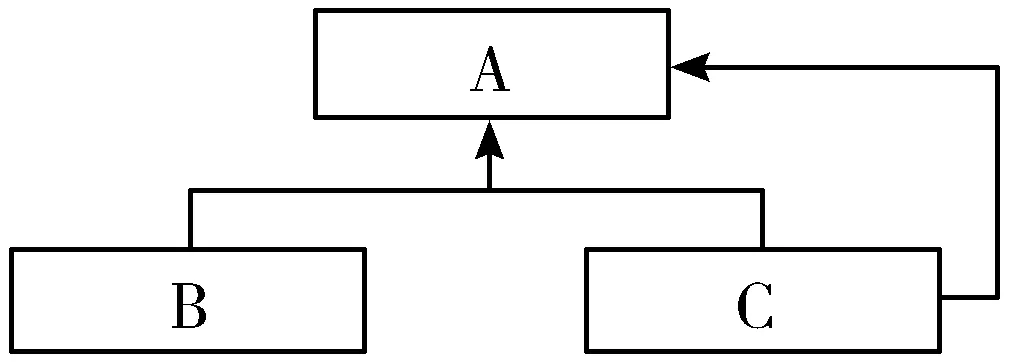
图4 有向图图示例
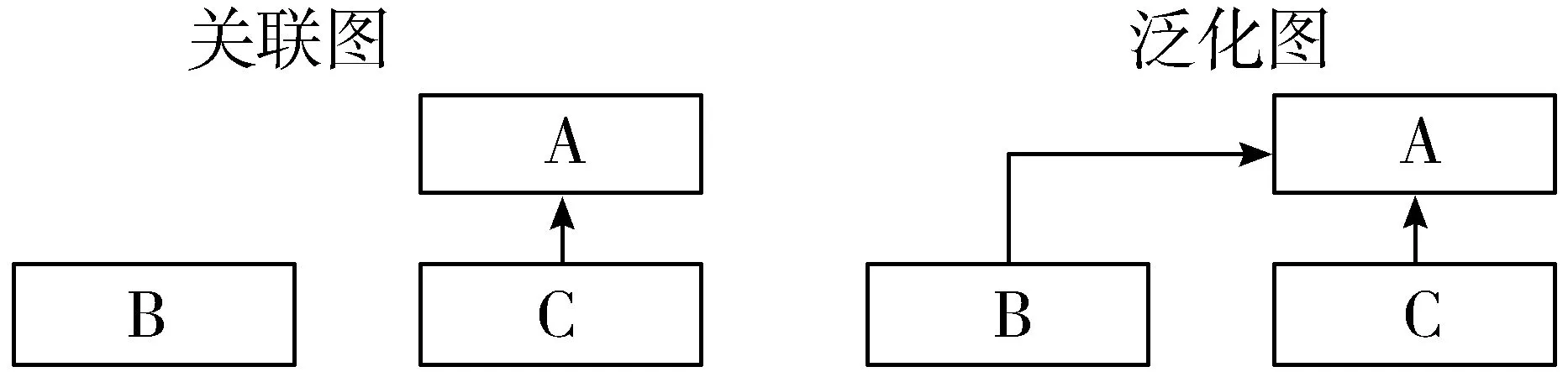
图5 有向图的关联图和泛化图表示
步骤4 总体相似性。这一步负责汇集内容、结构和设计的相似性,以便可以计算出模型间总体的相似性。每一步相似计算的算子输出一个相似度矩阵。它输入了在原始步骤中产生的矩阵和权重。这一步完成后则生成了一个m×n的最终相似度矩阵,m(行)和n(列)分别是模型MA与模型MB元素的数量。该矩阵的元素由aij表示,它对应于MA的一个i元素和MB的另一个j元素之间的相似性值。计算最后一个amn元素时,相似矩阵则完整。
以下更详细地描述这4个步骤所采用的方法。
3.3 内容相似性
信息活动过程元模型规范阐明了信息活动过程模型语法的定义。基本上,信息活动过程模型有一个具体的和抽象的语法。每个模型的元模型规范定义了它们各自的抽象语法。信息活动过程模型的具体语法是指信息活动的构造、信息流的传递和表示方式。在内容相似性的对比中,只对比内容的相似性,不关注元模型的比较。具体内容上的构造和表示是指诸如信息活动、信息流等元素。因此,内容相似性是基于这些内容之间的不同进行的衡量。
公式(1)展示了内容运算符如何计算各项之间属性的相似性值。该方程式计算术语是否是同义词。如果这些术语是同义词,那么它们是完全相似的,若为其他表明并不相似。例如,对2个输入模型MA与MB之间信息活动和信息流的比较,公式(1)的结果为1,表明这些项是100%相似。这是因为这些术语与字典上的同义词有关。图3显示了内容相似度矩阵上的这个结果。此外,这种相似性表明,这2个模型元素在意义上都是相等的,即它们具有相同的目的。但是,这个运算符不计算这2个类是否对它们的邻域等价,这可能会影响这2个模型的上下文相似性。为此,对结构相似性的评估也很重要,特别是,模型的结构围绕着这2个元素。为此,下一节提供了一个结构运算符来评估围绕这些模型的结构的相似性。

(1)
3.4 结构相似性
3.3节仅限于计算模型内容的相似之处,即信息活动或信息流在内容上是否相同。但是,若其具有相同的名称,而上下文不同时,就无法考虑它们的相似度值,也不能评估它们关于模型结构的差异。解决这个问题的方法是评估结构上的相似性。但是,它们在如何评估图的结构方面并不收敛。在本文提到的相似性度量的方法中,结构相似性是为了评估子图同构的直接影响。
子图同构算法是解决图相关问题经常要用到的一种方法,也是本文中分区过滤策略的一种基础算法。Ullmann算法[19]是最早提出解决子图同构问题的算法,其处理过程相对简单,主要利用枚举的方式找到被匹配图在查询图中的匹配子图。该算法的思想虽然简单,但是其时间复杂度却与图的顶点数的指数成正比。公认比较好的子图同构算法还有VF2算法[20]。VF2算法既可以做图同构匹配也可以做子图同构匹配。该算法的高效之处在于有许多剪枝策略,提高了算法的效率。假定s为搜索过程中的一个中间状态顶点,M(s)表示中间状态s代表的部分匹配,M1(s)代表搜索到该中间状态顶点时图g1中的顶点,M2(s)代表搜索到该中间状态顶点时图g2中的顶点,以下算法给出求2个图g1、g2是否子图同构的关键代码。算法具体描述如下:
Matching(s)
输入:中间状态s,初始状态s0,M(s0)=φ
输出:匹配成功的映射顶点集M(s)
Begin
1.If |M(s)|=|Vg2| then
2.returnM(s)
3.else
4.compute the set Cand(s) of the pairs candidate for inclusion inM(s);
5.for each pairs in Cand(s) do
6.if the feasibility rules succeed for the inclusion of pairs inM(s) then
7.compute the states′ obtained by adding pairs toM(s);
8.Matching(s′);
9.for eachgin Ip such thatM[g] is not initialized do
10.M[g]←false;
End
3.5 设计相似性
设计相似性是一个较为抽象的概念,但可以理解为架构师在设计模型时的参考设计相似性。若2个模型的设计相似性越大,则在设计时的参考价值越大。故而在衡量设计相似性时不能只局限于内容和结构的对比。首先可以采用引起两图结构差异的最小编辑数,即图编辑距离[21],作为图趋势量化的具体标准。利用编辑距离来衡量2棵树之间的相似度,其基本思想是将2棵树之间的距离定义为利用编辑操作实现一棵树到另一棵树转换所需要的代价,其之间的距离越小,相似度越大,反之亦然。但是这样的衡量方式在设计参考的场景下,对比的结果将不准确。如图6所示,基于输入输出关系可知在设计(C)时,(A)的设计参考相似性比(B)更大,即(A)更接近(C)要设计的最终结果。但是就编辑距离和单计算结构相似性会出现(B)对(C)的参考性最大。

(A) (B) (C)
由图6可知,图编辑距离和单进行结构相似性度量的方法并不适用于这种情况,甚至会产生误判。所以本文采用拆分为泛化图和关联图的方法(以下分别简称g图和a图),计算图邻接矩阵的相似度,以此来衡量模型间的设计相似性。
首先将图6的模型图按照a图和g图拆分开来,如图7所示。

图7 拆分开的图
然后分别计算出它们的邻接矩阵,得到泛化矩阵和关联矩阵。之后将这个矩阵代入到公式(2)中(其中A和B分别为有向图A和B的邻接矩阵,Z0为元素都为1的NA×NB矩阵),分别迭代计算后,获得2个片段的a/g图相对于待比较模型(即有向图C)的a/g图的相似度。之后分别将每个片段的2个相似度矩阵进行相加,并且进行归一化,可以得到最终的相似度矩阵。
(2)
最终就可以得到(A)的设计参考相似性比(B)更大,即(A)更接近(C)要设计的最终结果。
4 实验与结果分析
为了验证本文所提模型相似性度量方法的有效性,采用C++语言进行编程实现。实验用的PC机配置为CPU 2.1 GHz,16 GB机带RAM,Windows10操作系统。
实验数据主要来自某项目中某军多个指挥所的36套信息架构设计模型。该数据主要描述了不同指挥所和作战部位的信息架构,数据丰富且由于某些作战部位功能相同而具有相似的架构模型。故而,从中选取不同特征的相似模型用于对本文方法的实验与验证。选取其中信息活动过程模型内容相似度不高但结构相似度高的模型数据为组1、内容相似度与结构相似度都较高的模型数据为组2、内容相似度较高但结构不同的数据为组3,以及设计参考相似性较高的数据为组4。最后,任意选取2组较难采用人工量化相似度的模型数据分别为组5和组6作为测试数据,每组数据分别有20个IAV-1a模型。
4.1 相似度比较
好的相似度计算方法应该是属于同一类别文档之间的相似度尽可能大,同时也能在一定程度上反映出同类型文档间的细微差别的。为了验证本文所提相似度计算方法在度量模型相似性计算的效果,与文献[16]的XML文档比较法的SSPF进行对比,相似度计算结果如表1所列,同时也将人工的衡量方法作为对比。表1中组1至组5分别对应选取的不同特征类别的数据组。其中,每个类别下的相似度为该类别中所有文档的相似度平均值。
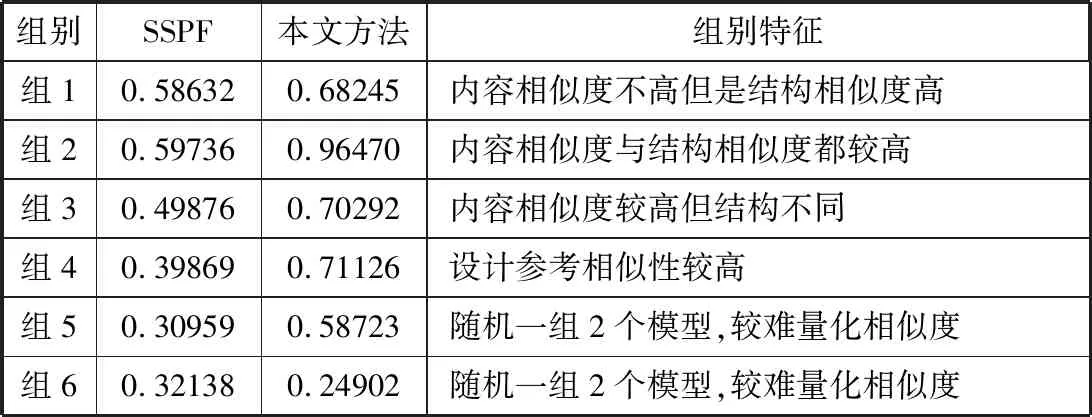
表1 相似度计算结果比较
从表1中可以看出,对组1至组4这几个类别,采用衡量XML文档结构的SSPF算法所得的相似度计算结果均不是很高,虽然也能反映出相似的差别,但是不太明显。而本文提出的方法则可以辨别出相似度的大小,即相似的方面越多相似值越大。同时,从组5和组6数据可以看出,SSPF算法对于无明显相似结构特征的数据则无法起到有效的相似度衡量,但本文的方法则可以显示出模型的相似差异大小。XML文档的比较方法更多地关注于结构和内容,存在相同或相似的路径结构则可衡量出相似性。由于本文提出的方法是基于信息活动过程模型的特征进行3个方面的衡量,因此使得相似度计算度计算结果更加真实地反映出实际的相似性。
4.2 结果分析
在相似度计算的基础上,通过定量精度、召回率和F型度量值来评估该工具的精度[22]。公式(3)的结果在0和1之间变化,越接近1的值表示结果越精确,越接近0的值越不精确。在本文中,精度(公式(3))定义为正确分配为相似的类数除以应等效的所有类的集。实验结果如表2所示。

表2 所得结果的精度、召回率和F度量指标比较
特别说明的是,精确度的计算(公式(3))是预测结果为正(TP),即正确结果和假阳性结果。召回率(公式(4))表示是否获得了所有可能的正确答案。为此,它考虑真实的正结果(TP),即正确匹配的数量和正确指出为错误结果的预测结果为负(FN)。最后,本文还评估了比较工具的F-度量值(公式(5))。F-度量值是精确度和召回率之间的谐波平均值。为此,在这个方程中考虑了精确度和召回率的值。
(3)
(4)
(5)
其中,TP表示样本为正,预测结果为正;FP表示样本为负,预测结果为正;FN表示样本为正,预测结果为负。
图8和图9分别描述了通过Kiviat图表生成的当前对比获得的结果。图中的每个轴对应于一种比较场景中2个输入模型MA和MB之间的比较。此外,3种不同的线型分别代表定量变量,短划线代表精确度、圆点短划线代表召回率,实线代表F-度量值。

图8 采取本文方法得到的结果

图9 采取XML比较法得到的结果
总体而言,实验结果表明,所提出方法的精度在所有场景中均达到至少60%。第2组数据中的精度值也是最大的,其中精确度、召回率和F-度量值达到了100%。这表明所提出的方法的精确度在不同的场景下达到了相当好的结果。存在的问题是,对于内容、结构或设计参考方面,若模型在其中一个方面显示出相似性,则容易被判断为相似,虽然无法通过本文的方法直接显示出不同方面的相似性,但是在架构师设计的过程中,判断相似的指标并无侧重,故而也可使用该方法找出任何一个方面的相似,对后续架构师的设计也有一定的参考意义。
5 结束语
随着架构设计工作的日益增多与推进,在架构师进行模型设计时,存在着广泛地参考已有相似模型的需求。然而,现有的架构方法和工具还无法对有参考价值的相似模型进行度量和推荐。因此,本文针对Inf-ProA框架的核心模型——信息活动过程模型,提出了一种混合的方法和多标准的相似度量的方法。它由内容、结构和设计相似性算符组成。本文实验结果表明,该方法在不同的评估场景中表现良好,使用多次迭代法可以提高模型之间相似性的精确度和召回率。这个方法提高了架构设计过程的高效性和架构设计模型数据的利用率。对于架构师来说,一种混合的方法是至关重要的,因为它考虑了多重指标和多个方面进行相似性的判断,这使得相似性更加精确,比较过程更适应所使用的模型类型。
架构设计师在开展架构设计时,可通过本文的度量方法对接近最终设计成果的相似IAV-1a模型进行推荐,从而达到对已有架构设计模型利用的目的,并从整体上提升架构设计的效率,以更高效的方式形成高质量的架构成果。
最后,本文采用已有的IAV-1a模型进行案例研究,通过5种评估场景将本文提出的方法与文献[16]提出的基于XML文档比较的SPFF方法进行了对比。实验结果验证了该方法的有效性,并且其精确度、召回率和F-度量值指标都优于其他的方法。
今后,笔者将继续提高相似度衡量的精确度,对不同方面的相似度衡量进行对比,得出“最相似”的结果,并进行更多相关案例的研究及更详细的分析。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
上海文化(文化研究)(2022年3期)2022-06-28
现代电子技术(2021年10期)2021-05-20
河北画报(2020年8期)2020-10-27
军事运筹与系统工程(2020年1期)2020-09-11
五邑大学学报(自然科学版)(2019年3期)2019-09-06
江西教育B(2019年2期)2019-04-12
中国诗歌(2018年6期)2018-11-14
军事运筹与系统工程(2018年1期)2018-11-10
环球市场信息导报(2017年1期)2017-04-08
