
色弱群体对社会归属感满足调查研究
2022-03-04 12:51高兴
科教导刊·电子版 2022年2期
高 兴
(上海星河湾双语学校 上海 200000)
1 研究方法
逻辑回归模型。
(1)变量。
选取对社会归属感是否满足(Belonging)作为因变量,性别(Sex)、年龄(AgeC)、出生地(Born)、现阶段长期居住地(Live)以及职业(Job)作为主要的自变量。其中,本文针对年龄进行中心化处理,即将年龄减去数据集中的中位数;出生地与现阶段长期居住地均分为城镇与乡村;职业则根据现行分类分为学生,各类专业和技术人员,国家机关、党群组织、企事业单位的负责人,办事人员和有关人员,商业工作人员,服务性工作人员,农林牧渔劳动,生产工作、运输工作和部分体力劳动者,以及不便分类的其他劳动者。
(2)模型。
在上一节中,本文将因变量定义为一个服从伯努利分布(Bernoulli distribution)的哑变量(Dummy variable),因此我们使用逻辑回归模型:

其中Belongingi表示一个色弱者对社会归属感是否满足的变量;i表示一个色弱者对社会归属感是否满足的可能性;fi为逻辑链接函数(Logit link function),为;X为模型矩阵,包括上述定义的自变量(Sex、AgeC、iBorn、Live与Job),以及 为模型矩阵对应的系数向量。
(3)访谈法。
为了进一步探究影响色弱群体对社会归属感满足与否的原因,本文对问卷调查过程中自愿受访的色弱者进行访谈。本文将针对以下几点对受访者进行提问:对社会归属感是否满足及其原因,以及提升其社会归属感的可能措施。
2 结果
2.1 逻辑回归模型结果
利用调查问卷中收集的数据对系数进行最大似然估计(Maximum likelihood estimate,MLE),并将其转化为比值比(Odds ratio),如表1所示。

表1:基准比值(Baseline odds)和比值比的最大似然估计与的置信区间
数据结果分析表明,年龄与现阶段长期居住地显著影响一个色弱者对社会归属感是否满足。在保持其它因素不变的情况下,年龄增长一岁会使一个色弱者对社会归属感满足的可能性增加 3.3%(其 90%置信区间为 [0.6%,6.1%]);与长期居住于城镇的色弱者相比,现阶段长期居住于乡村的色弱者更可能对社会归属感不满足(对社会归属感满足的可能性降低96.6%,其90%置信区间为[39.2%,99.8%])。
考虑到在数据收集过程中,职业的分类过多导致变量过多,可能导致过拟合(Overfitting)的问题并影响其它变量,因此本文尝试在模型矩阵中去除职业(Job)变量进行分析,其结果如表2所示。
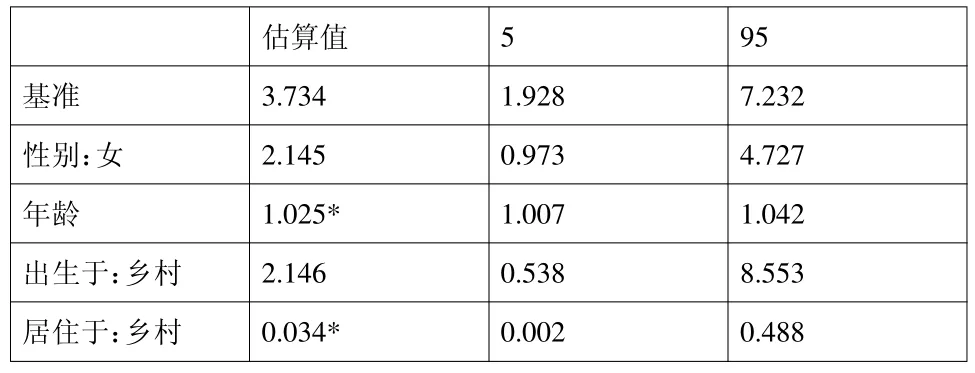
表2:基准比值(Baseline odds)和比值比的最大似然估计与的置信区间
数据结果分析表明,年龄与现阶段长期居住地显著影响一个色弱者对社会归属感是否满足。在保持其它因素不变的情况下,年龄增长一岁会使一个色弱者对社会归属感满足的可能性增加;与长期居住于城镇的色弱者相比,现阶段长期居住于乡村的色弱者更可能对社会归属感不满足。这一结果与第一个模型的结果是一致的。
因此,本文根据数据发现,对于色弱者而言,年龄越大,对社会归属感越满足;长期居住于乡村的色弱者比长期居住于城镇的色弱者对社会归属感更不满足。
2.2 访谈结果
与同龄人相比,年轻的色弱者可能会感受到格格不入,读书、就业不便等等,甚至在虚拟世界中的体验都受到了影响。而对于年龄更大的色弱者,在他们的青、壮年时期,他们并未因为色弱而受到太多的影响——这很可能是因为在当时,我国并未建立健全完善的体检机制,他们在专业选择或就业上并未受到阻碍,并且在当时,人们的穿衣风格基本朴素,社会娱乐活动匮乏,因此很难感受到不同。
2.3 城镇与乡村
长久居住于城镇的色弱者能享受到更完善的基础设施,因此在日常生活中并未有过多的不便。但由于只有极少数的居住于乡村的色弱者愿意提供联系方式,本文无法很好地总结为什么长期居住于乡村的色弱者比长期居住于城镇的色弱者对社会归属感更不满足,因而猜测长久居住于乡村的色弱者对社会归属感更不满足的主要原因是乡村的基础设施建设偏弱。
长久居住于乡村的人们主要以种植业为生计,而色弱无疑影响了一些种植业项目,比如观赏花卉、具有一定颜色的蔬菜水果等等,这极有可能导致他们出售的产品质量下降,从而影响收入。长此以往,恶性循环,他们对社会归属感或者会更不满足。而这样的认知差异存在在色弱者群体中,更不用说一些不了解色弱的其他人了。
3 改进措施
国家与学校应当加强对于色弱的科普,让每一个人了解色弱,从而减少对色弱群体的歧视;国家可以做适当的色弱普查,需要将一些交通路牌等的颜色变得更有区分度;大力发展科技,利用计算机技术,放大色差,以便于色弱患者辨认;国家在对于安排调配人民职业的时候,应当更充分考虑色弱的影响;对于色弱群体增加一些心理课程,来弥补色弱所造成的对于微表情的限制;国家可以召集各个街道小区,设立专门为色弱建造沟通交流的地点,成立互帮互助小组。
4 结论
在数据收集过程中可能存在不足,虽然是通过随机抽样调查的方式收集数据,但是数据类别存在着不平衡的现象。一个是因变量的类别不平衡,在机器学习的领域,这一问题可以通过重采样法解决,但本文考虑到这是一个社会科学的数据,利用算法强行平衡会使结果失去现实意义,因此未有采纳。此外,自变量的类别也存在着不平衡,而由于样本容量不大,不平衡导致的问题会被放大,在今后的研究中,可以通过扩大样本容量的方式降低这一影响。
猜你喜欢
中学生数理化·七年级数学人教版(2022年9期)2022-10-24
内江师范学院学报(2022年4期)2022-04-27
湖北师范大学学报(自然科学版)(2021年3期)2021-09-08
数学物理学报(2021年1期)2021-03-29
海峡姐妹(2019年5期)2019-06-18
今日农业(2019年10期)2019-01-04
中学生百科·大语文(2018年9期)2018-11-30
铁道通信信号(2018年9期)2018-11-10
公民与法治(2016年23期)2016-05-17
发明与创新(2015年13期)2015-02-27
