
基于多影像中心磁共振成像数据的半监督膝盖异常分类
2022-02-26 06:58:54张师天谢海滨
计算机应用 2022年1期
吴 洁,张师天,谢海滨,杨 光*
(1.华东师范大学物理与电子科学学院,上海 200241;2.上海市磁共振重点实验室(华东师范大学),上海 200062;3.爱丁堡大学物理与天文学院,爱丁堡EH8 9YL,英国)
0 引言
近几年,深度学习在医学图像领域的应用处于蓬勃发展阶段[1-2]。在磁共振成像(Magnetic Resonance Imaging,MRI)相关的疾病分类[3]、病灶检测[4]与组织分割[5]任务中,深度学习展现出自身强大的能力。这些研究通过实验表明,准确且具体的专业标记对于模型训练起到了重要作用。一些计算机视觉的研究也表明,使用网络层数深与通道数宽的网络用于训练模型可以提升模型性能[6-8]。但是,深而宽的网络意味着网络具有更多的参数,需要利用更多的数据去训练网络。如果采用监督学习方法,则需要放射学专家与临床医生花费大量时间与精力对所有磁共振数据进行一一标记。
为了能在有限的有标签数据集上利用大模型,迁移学习[9]是一种不错的选择,其工作机制是在具有大量有标签的数据集上预训得到一个模型,然后将该模型作为小数据集的初始模型。比如,Bien 等[10]在磁共振膝盖诊断任务中迁移了在大量自然图像组成的ImageNet 数据集[11]上预训练得到的AlexNet 网络。但是训练数据量如此庞大的数据集不仅需要大量计算机资源,还要求模型必须兼容两个不相关的数据集。磁共振图像是三维的灰阶图像,而ImageNet 数据集由二维的彩色图像组成,如果在磁共振图像上利用ImageNet 预训练的模型,可能会面临三维信息丢失与颜色信息冗余的潜在问题。
半监督学习[12]则是另一种可以缓解有标签数据有限问题的方法,它的核心是通过无标签数据来约束模型。一致性约束是实现半监督学习的一个有效算法,它要求同一样本经过多次噪声扰动或网络dropout 等约束后,模型必须给出一致的输出结果。比如Laine 等[13]提出可以利用高斯噪声与dropout 作为约束;Miyato 等[14]提出可以从样本自身角度出发得到对抗噪声,以此来代替随机噪声对样本进行扰动。也有半监督学习研究提出,模型对无标签数据的预测概率也可以作为无标签数据的伪目标。比如Tarvainen 等[15]提出利用指数移动平均(Exponential Moving Average,EMA)法可以得到更好的预测结果,然后将该结果作为无标签数据的伪目标;Xie 等[16]提出了用强度较弱的扩增变换数据后,把模型对弱扩增无标签数据的预测结果作为无标签数据的伪目标。
近期已经有一些研究开始将半监督学习应用于医学图像领域[17-19]。在这些研究中,有标签与无标签样本都来自同一个来源。但是对磁共振数据而言,很难从一个影像中心获取到足够多的有、无标签数据。为获取到足够多的磁共振数据,也面临着图像来源复杂的问题,比如来自不同的机构、生产厂家、成像协议与操作技师。另一方面,一个好的模型应该在不同来源的数据中有好的表现,因此在训练过程中让网络接触到多影像中心数据,可以使最终的模型更具鲁棒性。
基于上述问题,本文采用了两个不同来源的公开膝盖磁共振数 据——MRNet 数据集[10]与OAI(OsteoArthritis Initiative)数据集[20](https://nda.nih.gov/oai/)来开展半监督学习的研究。MRNet 数据集提供了每个样本膝盖是否异常的标签,因此作为有标签数据参与训练;而OAI 数据集没有提供膝盖异常与否的标签,因此作为无标签数据参与训练。在本文的半监督任务中,MRNet 数据集也作为无标签数据的一部分,将有标签数据作为无标签数据的一部分也是半监督学习研究工作的普遍做法。
本文提出了用于磁共振的半监督学习(Magnetic Resonance Semi-Supervised Learning,MRSSL)方法,用于从多影像中心磁共振数据中训练出膝盖异常分类的模型。MRSSL以一致性约束为基础,要求模型对同一样本给出一致的预测概率。并且也提出了对应的仅利用有标签数据的完全监督学习(Magnetic Resonance Supervised Learning,MRSL)方法,将其作为MRSSL 的对比对象。在网络搭建方面,本文借鉴了M2D CNN(Multichannel 2D Convolutional Neural Network)[21]与残差网络ResNet(Residual Network)[6-7]这两个网络。在训练过程中,利用了数据扩增来提供模型所需的归纳偏置[22],并且该偏置不小于MRNet 数据集与OAI 数据集之间的差异。受RangAugment[23]启 发,也提出 了磁共 振扩增(Magnetic Resonance Augmentation,MRAugment)作为本文的扩增策略,用于缓解在扩增参数上的调参压力。然后,选出MRSL 与MRSSL 中各自的代表模型进行对比,采用的评价指标有接受者操作特性曲线下面积(Area Under Receiver Operating Characteristic Curve,AUC),准确率(accuracy),敏感性(sensitivity),特异性(specificity)和敏感性与特异性的几何平均值(Geometric mean between sensitivity and specificity,Gmean),其中AUC 是模型选择的重要依据。实验结果表明,在具有相同有标签样本的前提下,MRSSL 训练出的模型比MRSL 模型在性能与模型泛化能力上表现更好,在AUC、准确率、特异性与G-mean 上面都有明显的提升。最后,将MRSSL与其他半监督学习方法在多个指标上进行了比较,实验结果表明MRSSL在膝盖异常分类任务中取得了最好的模型性能。
1 数据介绍
1.1 MRNet数据集及其拆分
MRNet 数据集是斯坦福大学医学中心对外公开的膝盖磁共振数据集。所有磁共振样本都是在3.0 T 或者1.5 T 磁场强度的GE 扫描仪上采集到的,每个样本都有3 个解剖方位的磁共振图像,矢状位、冠状位和横断位图像分别使用了T2 加权序列、T1 加权序列和质子密度加权序列。MRNet 数据集的类别主要分为两大类:膝盖正常与膝盖异常。所有磁共振数据的宽高都统一为256× 256 大小。
斯坦福大学医学中心对外提供了1 130 个样本作为训练集,120 个样本作为验证集,但是没有公开测试集中的120 个样本。根据MRNet 数据集中提供的标记信息,膝盖类别又可以细分成5 类:膝盖正常、前交叉韧带撕裂、半月板撕裂、既有前交叉韧带也有半月板撕裂,以及其他膝盖异常问题。本文从5 个类别的数据中各选出了24 个样本,总共120 个样本作为本文的验证集。余下的1 010 个样本(其中膝盖正常的数据有193 个,膝盖异常的数据有817 个)作为本文的训练集。而MRNet 数据集原始的验证集被作为本文的测试集。MRNet 数据集原本的数据划分与本文所用的数据拆分详情请见表1。由于MRNet 数据集没有对外公开测试集,所以把MRNet 数据集的验证集作为本文实验中的测试集。

表1 MRNet数据集的原始训练集、验证集与本文实验中训练集、验证集的膝盖情况分布Tab.1 Distribution of original training set and validation set of MRNet dataset and training set and validation set used in the paper
1.2 OAI数据集及其预处理
OAI 数据集是一个对观察群体长达10 年的多中心研究,是美国国家健康研究所(National Institutes of Health,NIH)支持开展的研究项目。所有的磁共振图像都是用3.0 T 磁场强度的西门子扫描仪采集得到的。该数据集由4 796 个样本组成,根据本文需要,从中选取了满足要求的4 692 个样本。选取标准是样本必须需要同时具有矢状位T2 加权序列、冠状位T1 加权序列以及横断位T2 加权序列的右膝盖图像。可以发现,OAI 数据集不仅在扫描仪器厂商使用上与MRNet 数据集不一样,而且提供的横断位数据所采用的扫描序列与MRNet 的也不一样,这也反映了多影像中心磁共振数据往往会存在很大差异这一现实问题。此外,OAI 数据集中没有提供膝盖异常的标签,所以它是本文半监督学习研究中的无标签数据。
在OAI 数据集预处理方面,本文利用了基于直方图的灰度值标准化算法[24],以确保OAI 数据集中的图像具有可对比的灰度值表示,将磁共振图像的灰度值都统一到了0~255,去除一些比较异常的灰度值。图像读取方面采用了SimpleITK(v1.2)[25-26],预处理方面利用了scikit-image library(v0.16)[27]。
2 方法介绍
2.1 MRSL与MRSSL及其训练目标
MRSL 采用了完全监督的学习方式,输入网络的数据只包含有标签数据,如图1 虚线框内区域所示,具有金标准YL的有标签数据XL经过数据扩增α后得到,然后被喂入网络中训练(网络细节见2.2 节),网络给出对应的预测概率值,训练目标则是描述金标准与预测概率间的差异的二值交叉熵损失函数:
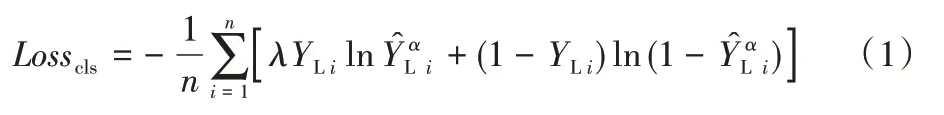
其中:n是训练集中有标签样本的总数,在本文中是1 010;λ是处理类别不平衡数据集时常用的系数。本文中膝盖正常样本与膝盖异常样本数目不平衡,所以用λ来起到均衡作用:将其作用于膝盖异常的样本前,λ的值等于训练集中膝盖正常的样本总数与膝盖异常的样本总数之比[28],结合表1可知该比值约为0.236(193/817)。注意MRSL 训练目标中仅包含分类损失函数。
MRSSL 既利用了有标签数据进行分类任务(图1 虚线框内区域),也利用了无标签数据进行一致性约束(图1 虚线框外区域)。从图1 可见,MRSSL 在处理有标签数据时与MRSL是一样的,主要差别体现在MRSSL 对于无标签数据采用了一致性约束。在一致性约束部分,无标签数据会分别经过两次扩增,一次是程度较强的扩增(用大写A表示),一次是程度较弱的扩增(用小写a表示)。需要注意的地方有两点:一是这里的较强与较弱扩增是指扩增A的强度要比扩增a的变换程度更强,实验用到的扩增策略细节展示在表2 中;二是同大多数半监督研究一样,为了充分利用所有数据,有标签数据同时也作为无标签数据的一部分。经历弱扩增a和强扩增A的无标签数据和经历同样扩增的被用作无标签数据的有标签数据经由网络输出的预测概率分别是,一致性损失函数即是描述与之间的差异以及之间的差异的均方误差函数:
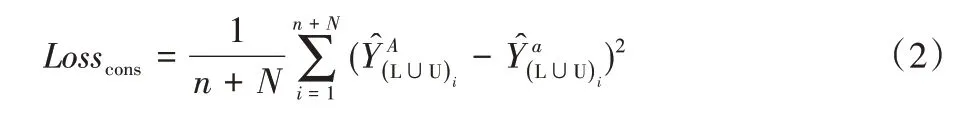
其中:n+N是指有标签与无标签样本的总数,本文中一共有5 702(其中1 010 个样本来自MRNet 数据集,4 692 个样本来自OAI 数据集);L ∪U 指有标签与无标签样本组成的集合。
MRSSL 的总训练目标Losstotal中包含了两大部分:

其中:Losscls是式(1)定义的分类损失函数,Losscons是式(2)定义的无监督的一致性损失函数。这里的一致性约束权重系数ω用于控制一致性部分在训练过程的贡献程度,初期随着训练迭代次数t线性增加至其最大值ωmax,然后维持不变。
图1 中虚线箭头表示着梯度反向传播的方向。在这一过程中,弱扩增后的无标签数据经过模型输出的概率被看作是强扩增分支的伪目标,即认为该伪目标在梯度下降优化过程中不应该被主动调整,同金标准一样不参与到求导中。强扩增图像的模型输出概率看作需要调节的,在优化时通过梯度下降调节。之所以这样做,是因为相对于强扩增变换后的图像,弱扩增变换后的图像相对于原图的差距更小,模型更容易准确预测结果,因而以弱扩增后输出的概率作为伪目标显得更为合理。
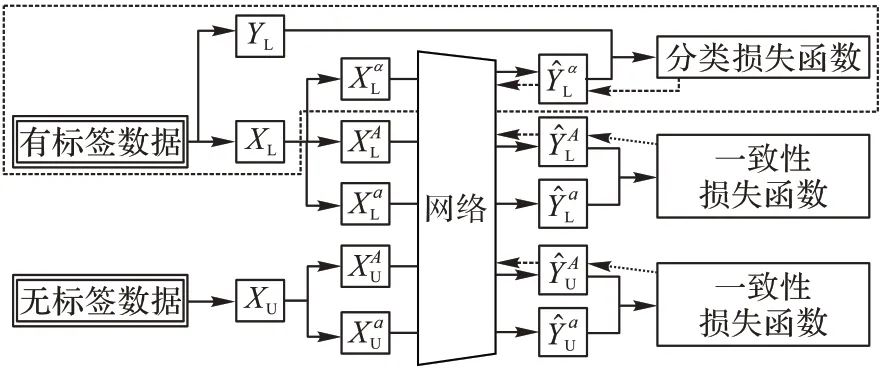
图1 MRSL与MRSSL的结构Fig.1 Structure of MRSL and MRSSL
一些半监督方法会将伪目标进行一定程度的“硬化”,即将预测的概率向着更高的自信度调整,例如将概率最大值直接作为标签[29]。但是,在现实生活中有些磁共振图像上会存在一些伪影导致图像质量不佳,放射科专家或临床医生很难给出绝对的异常或正常(1 或0)判断,比如本文所使用的两个数据集都没有排除有伪影的数据,对于模型而言,使用预测概率作为伪目标可以允许模型对信息不足的图像给出非确定性的判断,比起在特定阈值下给出的二值化标签(1或0)显得更合理。
2.2 网络框架结构
本文采取了端到端的学习方式,联结特征提取与类别判断两个过程,即图像输入网络后网络直接给出相应的预测概率。网络图像输入方式上借鉴了M2D CNN,网络结构上采用了ResNet。
在图像输入方面,M2D CNN 将磁共振图像层厚方向的图像置于通道维度,然后使用二维卷积进行特征提取,二维卷积相较于三维卷积具有更少的参数,对计算机资源需求量更少,并且训练也更加容易。此外,也有一些磁共振相关研究采用其他方式利用了二维卷积,比如文献[10]将磁共振图像当作二维图像输入网络,将层厚方向看作是不相关的,但该方法在每次迭代训练中只能学习单个样本,使得模型训练的稳定性较差,而M2D CNN 采用的方式可以较为灵活地控制每次训练迭代中的样本数量,这也是本文选用M2D CNN方法作为网络输入的主要原因。
关于网络主体部分,由图2 可以看出,3 个方位的磁共振图像分别经过一个具有22 个卷积层的前激活残差网络[7],在较深的网络中,一些位于前若干层的训练参数和训练目标之间距离较远,训练时的随机因素被放大,使得这些层训练困难,而残差网络通过引入跨层连接,缩短了这些层和训练目标的距离,使得所有层都容易获得有效的训练。然后网络从每个方位的磁共振图像中分别提取了256 个特征,注意3 个方位经过的残差网络是共享参数的。残差网络主要包含了一个7× 7 的卷积层和3 个残差组,每个残差组由3 个残差块构成。在每两个残差组之间有1 个dropout 层,并且dropout的概率是0.1。之后,将从3 个方位的磁共振图像中提取特征并进行合并,得到1 个768 长的特征向量,然后通过1 个全连接层产生1 个logit,再经过sigmoid 激活层输出最终的预测概率。
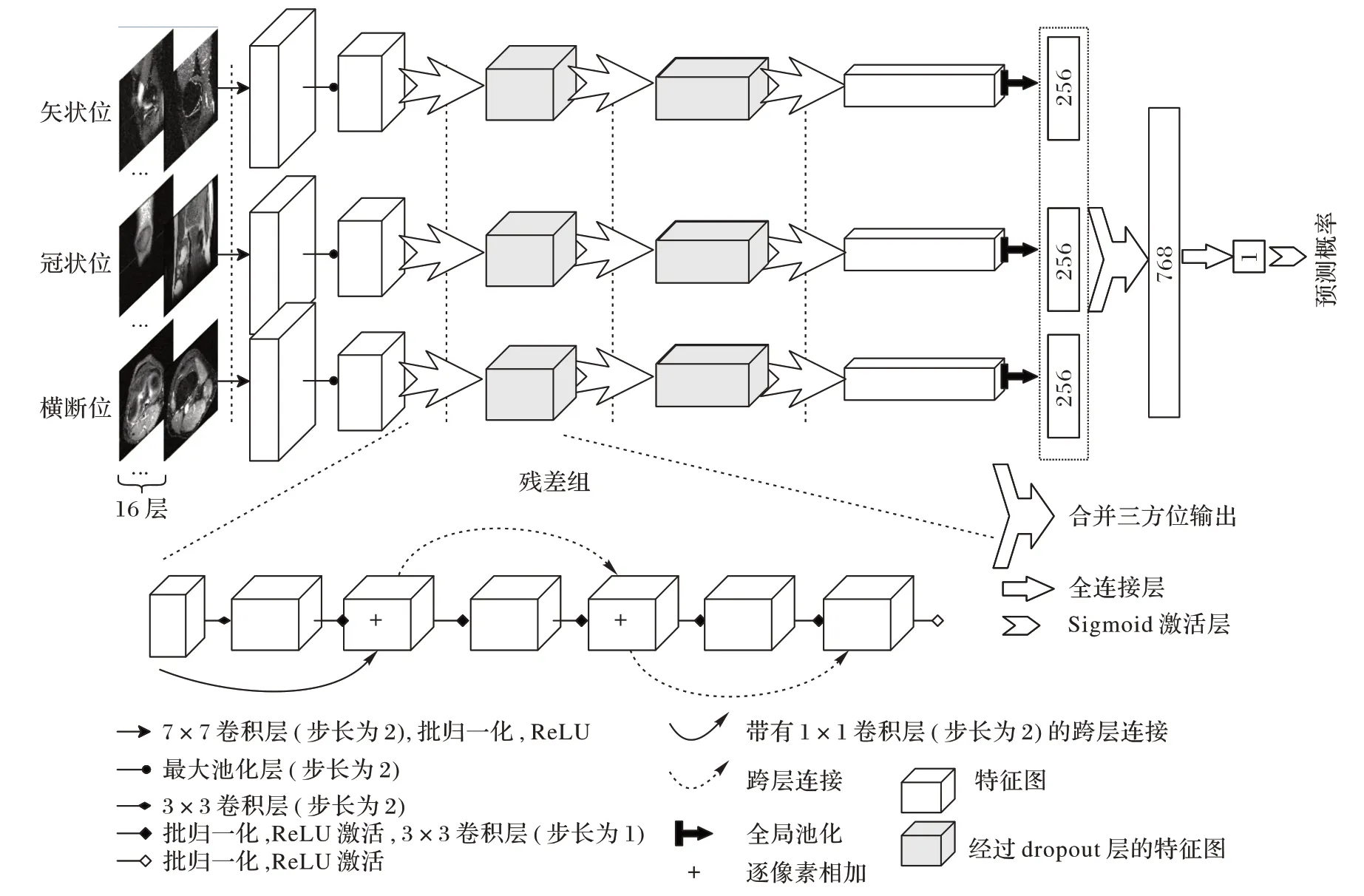
图2 网络框架结构Fig.2 Architecture of network
2.3 数据扩增方法
受RandAugment[23]的启发,本文设计了一种分等级的扩增参数调节策略MRAugment。扩增的方式主要分为两大类,一个是颜色变化(亮度与对比度),另一个是仿射变化(水平翻转、缩放、旋转和平移)。把这些变换进行组合,形成了如表2 所示的5 种变换组合。这5 种变换组合依据扩增强度可以分为5 个等级。本文提出的扩增策略将这些变换看成一个整体统一进行调节,从而大大缩短了在数据扩增上花费的调节时间。
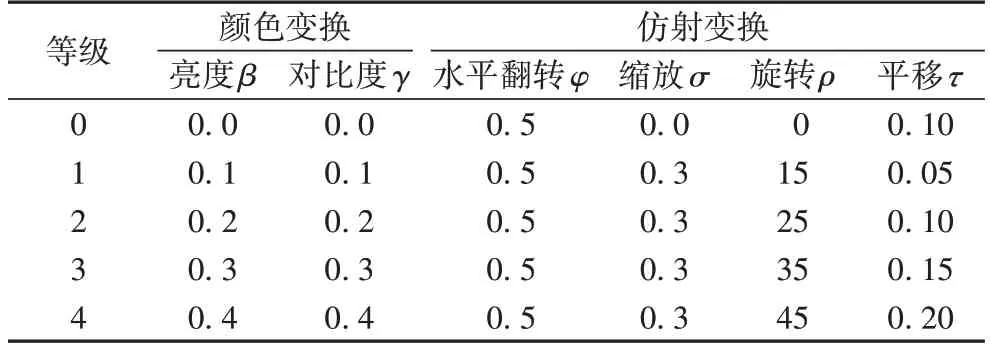
表2 MRAugment的5种扩增等级Tab.2 Five augmentation levels of MRAugment
所有变换对应的数值都是随机生成的,水平翻转变换的值(记为φ)代表翻转概率,其他变换的值代表着一个均匀分布的上下限。亮度值(记为β)与对比度值(记为γ)对图像X的变化表示为:

其中:b~Uniform(-β,β),c~Uniform(-γ,γ)。
仿射变换可以用仿射变换矩阵进行描述,缩放大小记为σ,旋转角度记为ρ,平移量记为τ。多种仿射变换组合的变换矩阵可以写成:

其中:Ms是缩放变换矩阵,Mr是旋转变化矩阵,Mt是平移变换矩阵,它们的矩阵形式如下所示:
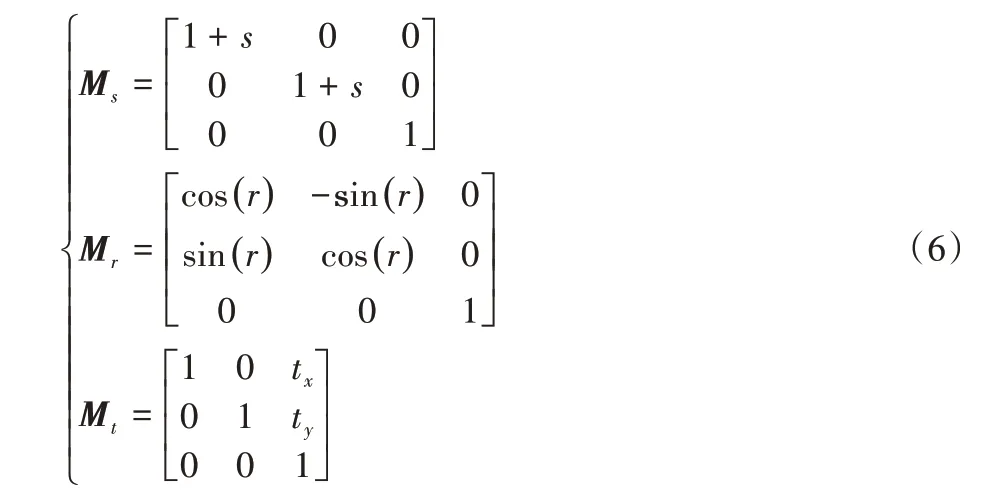
其中 :s~Uniform(-σ,σ),r~Uniform(-ρ,ρ),tx~Uniform(-τ,τ),ty~Uniform(-τ,τ)。
在MRSL 实验中,只涉及有标签样本的扩增,用α=0 表示有标签数据经过了MRAugment 扩增等级0 的对应的变换。在MRSSL 实验中,用(α,A,a)=(1,1,0)等级组合表示有标签数据、强扩增的无标签数据与弱扩增的无标签数据分别采用了等级为1 的MRAugment 变换,等级为1 的MRAugment 变换和等级为0 的MRAugment 变换。
2.4 模型训练细节
在网络的搭建方面,本文使用了PyTorch[30]作为框架。在MRSL 与MRSSL 上的一些参数设置是共享的:扩增后的图像的宽高将会被中心裁剪成224× 224,厚度方向随机选取连续的16 层(MRNet 数据集中图像最小的层数为17 层)。优化方式上使用了带动量的随机梯度下降方法,动量值设置为0.9。权重衰减系数为5E-4。整个训练过程一共训练迭代了12 600 次,在前200 次迭代中采用了warmup 来控制学习率线性增长到0.1,之后再利用余弦衰减策略让学习率从0.1下降到1E-5。在MRSL 中,有标签数据的batch size 是24,MRSSL 中有标签数据与无标签数据的batch size 也都设置为24。
半监督实验与监督实验设置的区别在于,前者需要调节MRSSL 损失函数中一致性约束损失的权重因子(式(3)中的ω)。在训练最开始的3 780 次迭代中,权重因子ω会从0 线性增长到10,并在往后的迭代中继续保持该值。值得注意的是,之所以采用渐进式变化的方式而不是维持权重因子从始至终是一个常数,是因为一开始模型还没有充分学习有标签数据中的标签信息,此时无标签数据产生的伪目标可信度很低,如果此时让模型过于关注一致性约束,会造成模型训练方向混乱,很难有好的分类表现。随着训练迭代次数增加,模型的分类准确度提升,无标签数据的伪目标和有标签数据的真目标更加一致,此时增加一致性约束的权重,可以让模型有效吸收更多来自无标签数据的信息,而不至于让两个训练目标南辕北辙。
2.5 模型选择与评价
验证集在模型选择中担当着重要的角色。在监督实验中,有标签数据分别在4 个等级的MRAugment 变换(表3 的MRSL 部分)下进行网络训练;在半监督实验中,有标签数据与无标签数据在MRAugment 等级组合变换(表3 的MRSSL部分)下得到扩增的有标签数据、强扩增的无标签数据与弱扩增的无标签数据。然后,基于7 个不同的变换组合分别进行了网络训练。在每次训练迭代过程中,验证集的分类损失值最低的模型将被选出来。由于模型训练过程中存在着随机性,本文对每种情形都进行9 次重复实验。在MRSL 中,验证集AUC 平均值最高的MRAugment 等级将被选出,作为MRSL 最适合的扩增等级;同样地,在MRSSL 中,验证集AUC平均值最高的MRAugment 等级组合将被选出,作为MRSSL最适合的扩增等级组合。
设置好参数后,测试集将会被用来评价MRSL 与MRSSL这两种方法对应的模型在分类性能方面的表现优劣;验证集与测试集之间的差距将用于评价两者模型的泛化能力。评价指标有接受者操作特性曲线下面积(AUC)、准确率acc、敏感性sen、特异性spe与G-mean,后4 个指标的形式如下:

其中:TP、TN、FN与FP分别是指膝盖异常的样本被模型正确预测为异常的个数,膝盖正常的样本被模型正确预测为正常的个数,膝盖异常的样本被模型错误预测为正常的个数与膝盖正常的样本被模型错误预测为异常的个数。其中在准确率、敏感性与特异性的计算中,概率转化为二值输出的阈值是0.5,这一阈值也是文献[10]所使用的,本文将与之保持一致。G-mean 是敏感性与特异性的几何平均值,是结合两者对模型进行综合评价的指标。
3 实验结果
3.1 扩增对模型的影响
在2.5 节模型选择与评价部分已经提及本文在监督与半监督实验中开展了多个扩增强度等级与等级组合下的实验(扩增调节实验中一致性约束权重因子最大值统一设置为10),实验结果展示在表3 中。对比表3 展示的MRSL 与MRSSL 的所有实验的测试集AUC 的平均值与中位数,可以发现,MRSSL 在测试集上的AUC 平均值与AUC 中位数都明显高于MRSL,由此可以看出,MRSSL 训练出的模型在膝盖异常分类性能上面比MRSL 更胜一筹。
根据2.5 节所介绍的模型选择方法,表3 中的加粗字体表示了MRSL 与MRSSL 所选取的最佳扩增等级与等级组合所对应的结果。对于MRSL,等级2(α=2)的MRAugment 是最为合适的扩增强度;对于MRSSL,MRAugment 等级组合(α,A,a)=(1,3,0)是最为合适的。值得注意的是,在MRSSL中,有标签数据所对应的扩增强度等级是a=1,这比MRSL中选出的有标签数据的扩增程度a=2 要小。这是因为在MRSL 的网络训练过程中,数据扩增带来的约束在模型性能上占据着主要的影响地位,而在MRSSL 的网络训练中不仅有数据扩增的约束,还添加了一致性约束,所以MRSSL 受到的约束需要综合扩增约束与一致性约束。考虑到数据扩增的一种解释(也是原始解释)是增加数据量,从这种意义上使用了更多数据的一致性约束和扩增约束有一定的互相替代关系。因此,使用MRSL 时最合适的有标签数据扩增强度等级对于使用MRSSL 时的有标签数据而言,并不一定意味着也是最合适的。
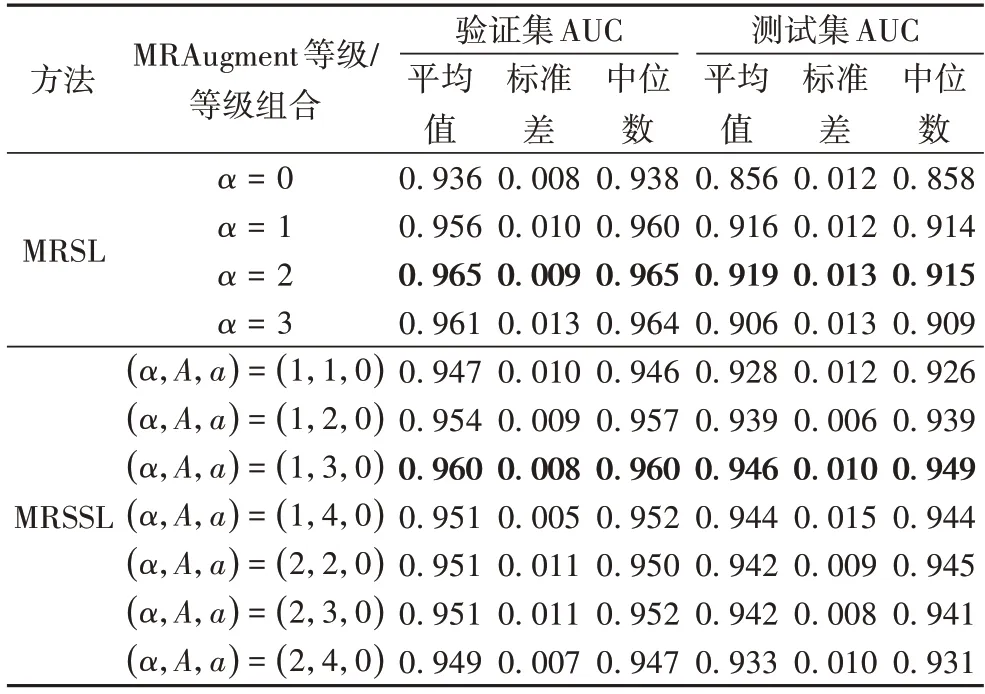
表3 MRSL与MRSSL分别在不同MRAugment扩增等级与等级组合下的AUC的统计情况Tab.3 AUC statistics of MRSL with different MRAugment augmentation levels and MRSSL with different MRAugment level combinations
本文探究了验证集AUC 与测试集AUC 在MRSL 与MRSSL 中分别随着扩增程度增加的变化情况。各自的结果展示在图3 中,图3(a)是MRSL 中对应的变化图,图3(b)是MRSSL 中对应的变化图,其中横轴表示数据扩增的强度等级,纵轴表示AUC 的大小,实线代表验证集AUC,虚线代表测试集AUC,线条周围的误差线代表着9 次重复实验得到的标准差。
从图3 中能明显看到,扩增对于MRSL 与MRSSL 都起到了一定作用。在图3(a)中,α=0 至α=2 时,本文的验证集与测试集的AUC 随着扩增增强而变大,MRSL 模型性能得到了提高;与此同时,验证集与测试集的AUC 间的差距也在缩小,这意味着模型的泛化性能得到了一定提高。当然过强的扩增也会导致模型退化,如α=3 时,验证集与测试集的AUC开始出现下降。
同样在MRSSL 中也能得到类似的结论。如图3(b)所示,在保持有标签数据的扩增α强度与无标签数据的弱扩增a强度不变的情况下,分别对应的是α=1 和a=0,验证集与测试集的AUC 随着无标签数据的强扩增A强度的增大(A=1 至A=3)而增长,但A=4 时AUC 开始出现下降。最后对比图3(a)与图3(b)中验证集与测试集AUC 之间的差距,可以发现MRSSL 对应的验证集AUC 与测试集AUC 的差距明显小于MRSL 的,MRSSL 的模型在测试集上具有更好的模型泛化能力。

图3 MRSL与MRSSL在不同MRAugment扩增等级与等级组合下的AUC变化Fig.3 AUC changes of MRSL with different MRAugment augmentation levels and MRSSL with different MRAugment level combinations
3.2 一致性权重对模型的影响
在2.4 节模型细节介绍中提到一致性权重ω在前3 780次迭代中线性增长到一个定值ωmax,本节将探索ωmax对MRSSL 的模型性能的影响。本文对比了当ωmax=0(该情形对应于MRSL 的实验中有标签数据扩增强度等级为α=1 的情形)、ωmax=5、ωmax=10 与ωmax=20 时,验证集AUC 与测试集AUC 的变化。ωmax=5、ωmax=10 与ωmax=20 这三个实验对应于扩增等级组合为(α,A,a)=(1,3,0)下的MRSSL 实验,结果如图4。
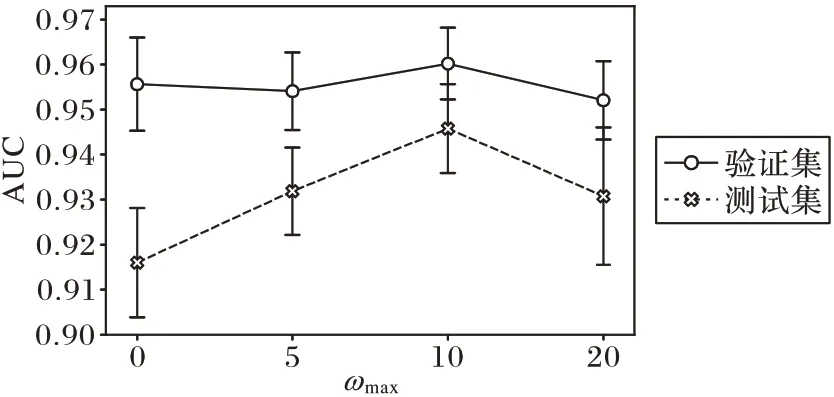
图4 MRSSL中AUC与一致性权重系数最大值的关系Fig.4 Relationship between AUC and maximum value of consistency weight coefficient in MRSSL
对比ωmax=0 与其他三种情形,它们的验证集AUC 处于差不多的高度,但是ωmax=0 的测试集AUC 明显比其他三种情形对应的测试集AUC 低,该结果也再次表明一致性约束损失函数作为训练目标的一部分可以对模型性能起到促进作用。
另一方面,相对于其他数值,一致性权重系数最大值为10 时的模型表现更好。主要体现在两个方面:一是模型的测试集AUC 明显高于其他三种情形;二是验证集与测试集AUC 间的差距也小于其他三种情况。由此可以看出,一致性权重最大值的大小对于模型训练也起到了较大的影响,在进行半监督学习任务中也需要仔细调节该参数的大小并分析该参数对模型的影响。
3.3 确定参数下选取模型的对比
通过上述实验结果,本文确定了在MRSL 中最适合的扩增变换是α=2,在MRSSL 中最适合的扩增变换组合是(α,A,a)=(1,3,0),并且MRSSL 合适的一致性权重系数最大值为10。在确定好两者各自的最适合参数后,接下来从MRSL 和MRSSL 各自的9 组重复实验中,分别选取出各自具有代表性的模型。选择标准是9 组实验中验证集AUC 是中位数所对应的模型。然后给出两个代表模型的AUC,以及在概率阈值为0.5 的条件下的准确率、敏感性、特异性与G-mean 这5 个评价指标的数值,并从这5 个指标出发,对两者的代表模型进行对比。同时本文也给出了AUC 的95%DeLong 置信区间,准确率、敏感性与特异性的95% Wilson Score 置信区间。
表4 中可以看到,MRSSL 的模型在AUC、准确率、特异性和G-mean 指标上明显好于MRSL,分别提升了0.043、0.025、0.160 与0.085。在模型特异性上,MRSSL 的模型对膝盖正常的样本精确预测为正常的能力明显优于MRSL;但是在敏感性上,MRSL 比MRSSL 高0.009,此时需要使用G-mean 指标来综合敏感性与特异性这两个指标去评价模型。由表4可以看出,MRSSL 的G-mean 数值是高于MRSL 的,同时相对于其他四个指标的差异,敏感性的差异也相对不明显。总的来说,MRSSL 在多个评价指标上的表现是超过MRSL 的。

表4 MRSL与MRSSL各自选取的代表模型在5个指标上的结果对比Tab.4 Result comparison between the selected models of MRSL and MRSSL on 5 evaluation indicators
3.4 半监督学习方法的对比
本文也将提出的半监督学习方法与其他半监督学习方法进行了对比。首先对比了最早将一致性约束方法引入半监督学习的PI Model[13],它要求一致性约束的两条分支采用同样程度的微扰——高斯噪声,也就是由一个样本得到两个经过同样程度扰动的样本,然后要求模型对两者给出一致的预测结果。其次也选取了同样在无标签数据上分别使用强弱扩增进行一致性约束的UDA(Unsupervised Data Augmentation)[16]与FixMatch[29]方法进行比较。这两种方法与本文方法不同之处在于,UDA 要求弱扩增一侧的输出logit经过温度锐化,使得最终的输出概率往更高的自信度上进行调整,比如模型对弱扩增的样本给出的logit 值为1.1,那么经过sigmoid 激活层后,模型原本会给出0.75 的输出概率,但使用了温度锐化(参照文献[16]中的温度值设为0.7)后,再经过sigmoid 层后输出概率便是0.83。而FixMatch 要求弱扩增一侧的输出概率在给定区间以外时,则将该输出概率直接转为二值化伪标签(0 或1)。9 次重复实验的结果展示在表5 中。

表5 不同方法的结果对比Tab.5 Result comparison of different methods
在表5 中也添加了数据扩增等级为α=2 时的MRSL 结果,还有仅使用高斯噪声MRSL 结果作为4 种半监督学习方法的对比基准。可以发现,使用数据扩增的MRSL 方法的模型性能优于仅使用高斯噪声的MRSL 方法。这是因为数据扩增相较于高斯噪声能够从原样本中衍生出更加多样化的数据,所以在膝盖磁共振异常分类中对模型的性能提升更能起到促进作用。
对比半监督学习方法与监督学习方法,可以发现:在磁共振膝盖异常分类任务中,半监督方法PI Model 的模型性能不仅与仅加高斯噪声的MRSL 的模型性能相当,且明显低于使用数据扩增的MRSL 的模型性能。但是使用了数据扩增的FixMatch、UDA 和MRSSL 半监督学习方法既获得了比上述两种情形的MRSL 更高的AUC,也在5 个评价指标上获得比PI Model 更高的数值。这说明在一致性约束中,简单高斯噪声是不足以提供模型所需的归纳偏置,从而导致最终模型性能不能得到有效提升,而数据扩增的使用可以带来明显的性能增益,这也反映了数据扩增在多影像中心磁共振数据与半监督学习的结合应用中的重要性。
此外,FixMatch、UDA 与MRSSL 这三个半监督学习方法总体上都优于MRSL 方法。在使用同样的有标签数据时,这些使用了另一影像中心无标签磁共振数据与数据扩增的半监督学习方法可以在不进行额外专家标记的情况下有效提高模型的分类性能,从而大大缓解了数据标记与专家知识需求上的压力。
对比FixMatch、UDA 与MRSSL 三者,FixMatch 的特异性平均值是最高,G-mean 平均值次高,但在其他3 个指标上的表现都不如UDA 和MRSSL,并且MRSSL 对应的G-mean 平均值值高于FixMatch。对比UDA 与MRSSL,可以发现MRSSL在5 个指标上都是处于较高的水平。由以上分析可知,在这三种半监督学习方法中,FixMatch 对模型预测输出进行了最强的“硬化”,UDA 方法次之,本文提出的MRSSL 方法则是维持原始输出。本文在2.1 节提到当遇到图像质量不佳的磁共振图像时,医生仅依据患者的图像也很难给出确定性的膝盖异常判断结果。此时,对预测值进行“硬化”容易引起错误标签传播的问题,最终导致模型性能下降。而MRSSL 的设计中考虑到了这一情况并允许模型对这些数据给出非确定性的判断,所以相较于FixMatch 与UDA,MRSSL 在磁共振膝盖异常分类任务中获得了更好的表现。
4 结语
为了缓解数据标记压力与单一影像中心数据有限的问题,提出了利用多影像中心有标签与无标签磁共振数据的半监督学习方法MRSSL。将MRSSL 与对应的监督学习方法MRSL 进行了对比,发现MRSSL 在模型性能与泛化能力上明显超过MRSL,实验结果说明,无标签数据加上合适的数据扩增有助于模型获得必要的归纳偏置以及提取出更有辨别力的特征。最后对比了MRSSL 与其他半监督学习方法,发现采用了数据扩增以及具有更强数据包容性的MRSSL 取得了最好的膝盖异常分类性能。
为了进一步提高MRSSL 的模型鲁棒性,在未来的研究中,将继续研究如何将MRSSL 应用到更加现实、复杂的磁共振多影像中心问题上,比如有标签数据中的样本也是多影像中心的等。同时,本研究主要聚焦于膝盖异常诊断任务,在未来的工作中将会把本文的方法应用于其他身体部位或组织的磁共振成像任务中,进一步验证MRSSL 方法的有效性。
猜你喜欢
公民与法治(2022年5期)2022-07-29 00:47:28
教学考试(高考物理)(2021年5期)2021-11-08 10:31:22
中老年保健(2021年5期)2021-08-24 07:08:44
中国临床医学影像杂志(2021年6期)2021-08-14 02:22:00
中医眼耳鼻喉杂志(2021年1期)2021-07-22 07:38:14
中国生殖健康(2020年6期)2020-02-01 06:29:06
基层中医药(2018年10期)2018-12-06 09:27:12
中国生殖健康(2018年6期)2018-11-06 07:09:42
中国自行车(2018年6期)2018-07-23 03:17:18
阅读(快乐英语中年级)(2016年12期)2016-05-30 10:48:04
