
基于改进VGG网络的弱监督细粒度阿尔兹海默症分类方法
2022-02-26 06:58:52何小海卿粼波陈洪刚滕奇志
计算机应用 2022年1期
邓 爽,何小海,卿粼波,陈洪刚,滕奇志
(四川大学电子信息学院,成都 610065)
0 引言
据统计,在脑部疾病中,阿尔兹海默症(Alzheimer’s Disease,AD)患病率极高[1],到了晚期再发现没有任何方法可以治愈,只能依靠药物来延缓病情的恶化。根据预测,到2050 年,每85 人中就会有1 人受到AD 的影响[2]。临床上一般依靠专业的医生综合分析判断是否是AD 患者,这要求医生具有丰富的临床经验;培养一个专业的医生耗时很长而且诊断时也存在误诊的可能。基于此,目前依赖专业医生问诊的方法存在很多局限性,同时耗费的人力、物力、财力巨大;医院社会迫切地需要高效智能化的设备辅助医生诊断治疗。
如今,主流的智能化研究方法包括机器学习和深度学习。运用机器学习方法对AD 图像进行分析,这对网络特征提取模块的准确性要求较高,更有利于已知特征的数据分类。由于AD 脑部图像的特征并没有统一明确的标准,相比之下,拥有自动学习提取特征优势的深度学习方法在这一领域应用越来越广泛,比如卷积神经网络[3]和稀疏自编码器等。近年来,面对层出不穷的优秀分类网络,仅采用卷积神经网络进行分类的方法单一、不具竞争力。考虑到AD 患者脑部结构与正常人脑部结构的细微差别,需要一种高效的多模块结合的细粒度分类方法来识别AD 和正常(Normal Control,NC)人。
现在大批优秀的细粒度分类网络被大家所熟知,比如NTS-net(Navigator-Teacher-Scrutinizer network)细粒度分类网络,它是由Yang 等[4]提出的不需要边界框的自监督学习方法,能准确地识别图像的信息范围,提供精确的信息域,但会造成网络计算量过大,速率较慢,训练时间变长。比如Lam等[5]通过细粒度网络取得图像的边界框和候选框,接着利用长短时记忆(Long Short-Term Memory,LSTM)网络将边界框和候选框进行融合,这种需要利用其他的标注信息来获得标签的网络通过增加成本来提高识别率,也会造成网络运算量增大。所以,仅使用类别标签,不依靠外加其他标注信息的弱监督细粒度分类算法[6]逐步受到这一领域的重视。
目前,具有代表性的弱监督细粒度分类网络有以下几种类型:
类型一是端到端的训练,输入对象经过特征提取函数映射后,获得高阶特征向量再进行编码,以平移不变的方法对局部区域特征交互进行建模。首先提取尺度不变特征变换(Scale-Invariant Feature Transform,SIFT)等图像特征,再运用Fisher Vector、VLAD(Vector of Locally Aggregated Descriptors)、O2P(Online to Partner)等模型进行编码。该方法操作简单,但是对特征的提取不太精确。
类型二通过使用目标定位子网络协助主干网络,结合注意力机制获取局部细节信息,从而加强整个网络深入学习特征的能力。该方法不依靠局部标注信息,而采用注意力机制[7]、谱聚类[8]、空间转换[9]等分析出具有判别性的特征信息,再将特征信息送入相关网络结构,这将更有利于特征信息的提取。所以,类型二较优于类型一。
类型二中,Fu 等[10]提出了循环自注意力卷积神经网络,采用相互加强的方法判别区域注意力和区域特征表示进行递归学习。但是,注意力区域只将重点关注部分剪裁放大,未考虑剩余区域的信息,这也将影响后续的特征关注。因此,Hu 等[11]提出的弱监督数据增强网络(Weakly Supervised Data Augmentation Network,WSDAN)备受重视,该网络在仅仅使用图像标签信息的条件下,通过弱监督注意力学习,运用注意力机制(包括注意力剪裁和注意力丢弃)引导数据增强,重点关注的特征区域将会更精细完善,并且加入中心损失函数和双线性注意力池化操作训练网络模型。
研究表明,更清晰的特征选取和更精细的注意力引导机制应用在细粒度分类上十分有必要,所以本文在利用增强图像数据的前提下,提出了基于改进VGG 的弱监督细粒度阿尔兹海默症分类方法,以此提高阿尔兹海默症的识别率。多次对比实验结果表明,所提方法具有较好的分类识别率。
1 WSDAN架构
WSDAN 模型[11]仅仅使用图片标签信息进行弱监督学习,不增加额外的辅助信息。该网络与传统分类网络的不同在于使用注意力图引导数据增强,同时引入中心损失函数避免生成的注意力图之间差别太大,并结合双线性注意力算法强化局部重要特征的学习,整个网络分为训练过程和测试过程两个部分。
在训练过程中,原始图像经过特征提取网络获得特征图,每一张特征图提取32 张注意力图;接着,运用注意力机制引导数据增强帮助获取更精准的细节特征,引导方式包括注意力裁剪和注意力丢弃;然后,将原始图像和经注意力引导增强后的图像共同作为网络输入参与训练;最后,特征图和注意力图通过双线性注意力池化算法运算得到特征矩阵,特征矩阵将作为线性分类层的输入,对应图1 中的(a)。
在测试过程中,总的分类概率由粗分类概率和细分类概率两部分组成;粗分类概率是原始图片经过训练好的模型得到特征图和注意力图,接着将特征图和注意力图采用双线性注意力池化(Bilinear Attention Pooling,BAP)算法点乘得出特征矩阵,特征矩阵直接进行池化、分类,对应图1(b)中的路线①;细分类概率是网络得到注意力图后,要对注意力图进行相加运算,求出注意力总和,再使用注意力总和引导数据增强实现注意力剪裁步骤,随后将剪裁后的结果和原始图片一起作为输入对象送入测试网络,最后特征图和注意力图点乘、池化、分类,得到细分类概率,对应图1(b)中的路线②。
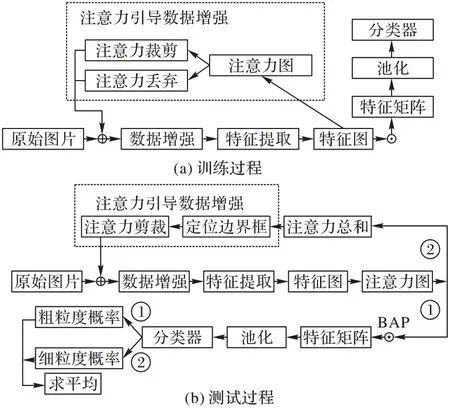
图1 WSDAN架构Fig.1 WSDAN architecture
1.1 注意力机制引导数据增强
原始图片载入弱监督注意力学习网络,从每张特征图中获取32 张注意力图,随机选取其中的一张注意力图Ak,对Ak按式(1)进行归一化处理[12],以避免奇异样本对整个数据的影响,随后采用注意力裁剪和注意力丢弃的方式使网络注意到图像局部区域,从而达到获取更多的细微特征的目的。
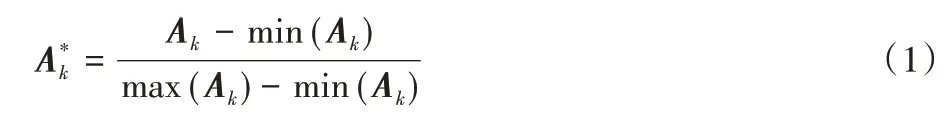
利用注意力图Ak引导原始图片实现注意力剪裁和注意力丢弃。这两类实现方式目标不同,注意力剪裁是将重点关注的特征区域剪裁下来,而注意力丢弃则是将当前特征区域抹去,使这块特征区域不再受关注。具体来说:
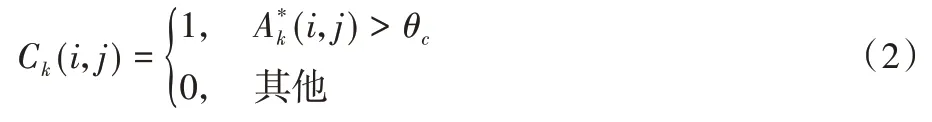
采用式(2)进行注意力裁剪,阈值θc取值范围为θc∈[0,1],(i,j)是归一化处理之后每个像素的值,Ck(i,j)是剪裁过程中需要标记的区域;当(i,j)大于阈值θc时,Ck(i,j)取1;当(i,j)小于等于θc时,Ck(i,j)取0,1 是需要剪裁区域,然后利用边界框覆盖剪裁区域并将重点关注的区域放大,即为裁剪图像。
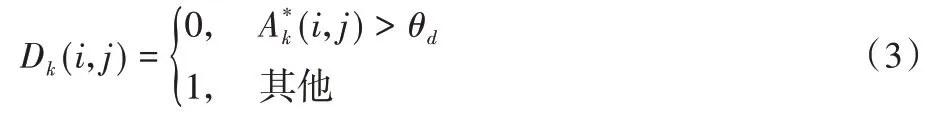
进行注意力丢弃时,使用式(3)运算,阈值θd取值范围为θd∈[0,1],Dk(i,j)是丢弃过程中需要标记的区域;当(i,j)大于θd时,Dk(i,j)取0;当(i,j)小于等于θd时,Dk(i,j)取1,取值为0 的特征区域为丢弃区域,将其消除以提高其他重点关注区域的识别率。
1.2 双线性注意力池化
将通过弱监督注意力过程学习得到的特征图F和注意力图Ak进行特征融合,运用BAP 算法[7]如式(4),将特征图和注意力图点乘生成部分特征图Fk,M表示注意力图的数量。

该BAP 算法能够加强局部重要特征区域的学习,减少不相关信息的干扰,提升网络模型的分类性能。

为了解决特征融合后维数过高的问题,按照式(5)进行池化降维操作,提取出部分特征fk,最后将部分特征图fk进行求和运算得到特征矩阵P,如式(6)。P由M个fk组成,Ak表示第k个注意力映射,F为提取的特征图。经过整个BAP过程后,将特征矩阵P接入中心损失函数再送入分类网络,求得每一个类别的预测概率。
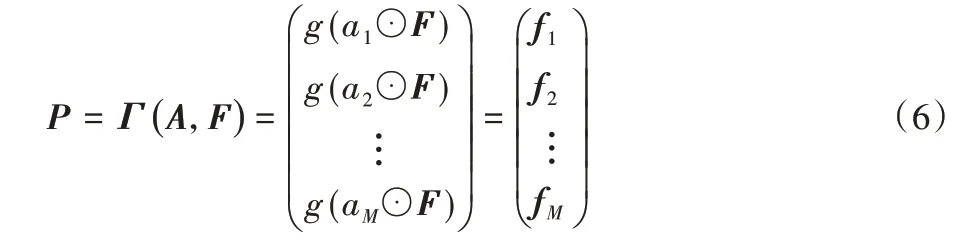
1.3 中心损失函数的设计
在使用细粒度网络进行图像分类时,目标对象之间的细微差异一般在于对象的局部区域,范围不会太大。中心损失函数[13]能有效地减小类内差异,增强同一类别间的相似性,同时保持类间距离。所以,中心损失函数的设计能够让每张特征图固定在每个部分的中心,这样生成的注意力图之间不会有较大的差异,其表达式如(7)所示:

其中:fk是经过BAP 降维后的特征图,ck表示第k个类别中心,M是mini-batch 的大小。在每一个批量训练时,样本特征中心距离的平方和越小越好,这等同于类内差异越小越好。模型训练时,ck不断地学习、修正,类似于梯度更新,是一个动态的学习更新过程,其计算式如式(8):

中心损失函数的引入减少了类内的差异,而不能有效增大类间的差异性,这为训练模型提供了更为精确的特征选择,使得模型的识别率更高,分类性能更好。
2 图像增强与网络结构改进
2.1 图像增强
由于AD 患者脑部区域和正常人脑部区域的差别很微小,因此,本文采用图像预处理技术对图片进行加强。在原始图片送入模型之前,将图片之间的局部差异放大,以提高AD 患者的分类识别率。
将患者和正常人的脑部图片差异放大的关键之处在于将图片之间信息差异放大,然而图片中大部分信息主要集中在低频部分,所以本文尽可能地利用图片低频信息进行特征提取,当然图像平滑[14]可以帮助实现这一目的。经典的图像平滑操作包括最小二乘多项式平滑、线性滤波、高斯滤波、双边滤波等。本文研究需要提取图像相关的有用信息,去除多余信息量,所以采用平滑线性滤波最为合适。
原始图像通过一个M×N的加权均值滤波器(M和N都为奇数值)[15],其滤波过程如式(9):
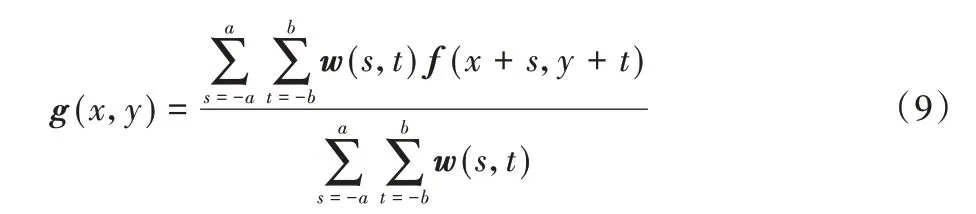
其中:f(x+s,y+t)是输入图像,x=[0,M-1],y=[0,N-1],以确保所有的像素点都进行了滤波处理;w(s,t)为加权系数,中心系数较大,周围系数小;本文采用3× 3 的滤波尺寸,这样每生成一个新的像素就会包含周围8 个原始像素的加权贡献,通过处理后的图像平滑缓和,帮助提高模型的分类识别率。
图2 展示了初始磁共振成像(Magnetic Resonance Imaging,MRI)图片经过平滑(SMOOTH)和锐化(SHARPEN)增强后的效果对比,能直观地看出SHARPEN 后的图像强化了图像的细节信息,同时也引入了更多的噪声,使特征提取变得复杂,对AD 图像而言反而添加了更多的干扰,造成分类性能变差。因此,本文选SMOOTH 方法用于增强图像局部信息。
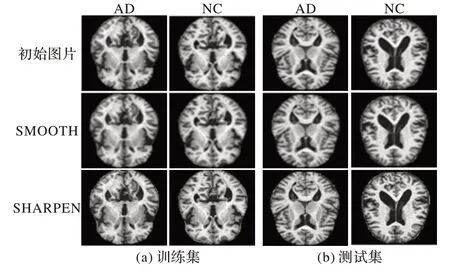
图2 脑部MRI初始图片与增强后对比Fig.2 Comparison of initial and enhanced MRI images of brain
2.2 网络结构改进
VGG(Visual Geometry Group)网络结构适用于图像分类,具有很多优势。首先,其网络结构简单,由5 层卷积层、3层全连接层和Softmax 层组成;采用3× 3 小卷积,在感受野相同时,迭代效率远远高于大的卷积核,减少参数量的同时提升网络的表达能力,并且它的成功应用[16]说明,在一定的范围内增加网络的深度能够提升模型的效果。
其次,由于每一层的通道数都在翻倍,最高达512 个通道,随着通道数的递增,将有利于提取出更多的有用信息,加之卷积池化操作对图像进行降维,减小了网络计算量,加快模型的训练。另外,测试过程中将3 层全连接层改为3 个卷积,这可以导入任意宽高的图像,不再受到限制。最后,根据已有研究的经验来看,VGG 网络在图像分类领域被广泛使用[17-19];因此,基础特征提取网络本文选择VGG 网络,由于AD 和NC 之间的差异较小,要求对特征进行更充分的提取,考虑到VGG19 在深度上的优势,所以在VGG19 网络进行加强改进。VGG19 网络结构如图3 所示,共有5 个卷积池化模块:Block1、Block2、Block3、Block4、Block5;每一个模块都由3× 3 的小卷积核和池化层构成,其详细网络参数如表1所示。
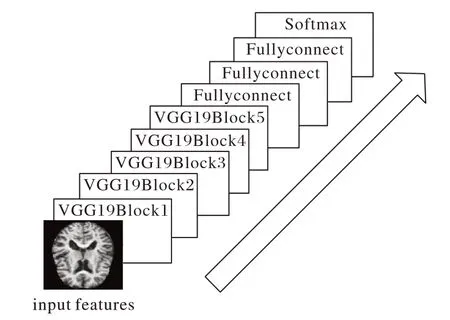
图3 VGG19网络结构Fig.3 Structure of VGG19 network
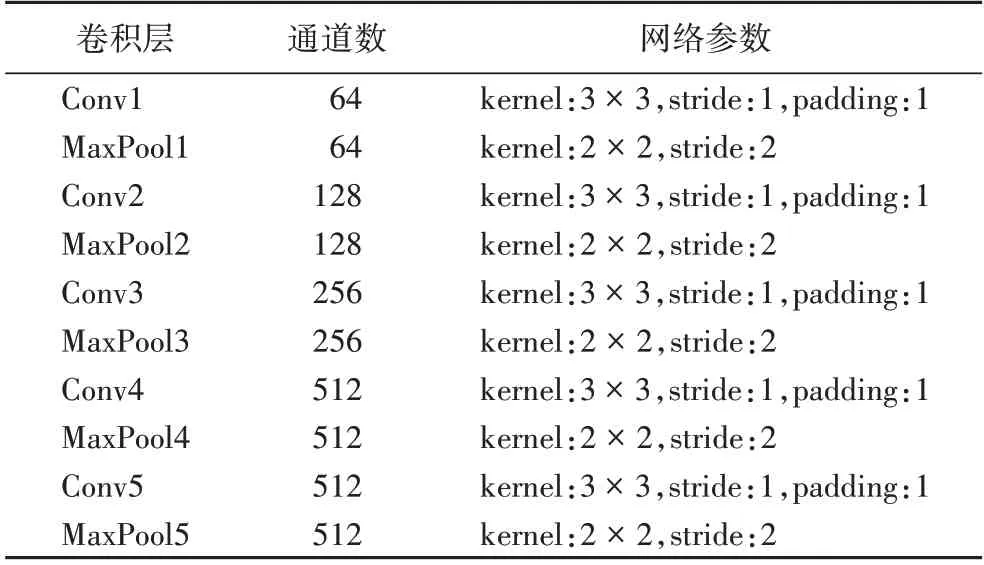
表1 VGG19网络参数Tab.1 VGG19 network parameters
VGG19 网络特征提取部分如图4 所示,其中,Block1 包含2 组64 通道,3× 3 的卷积层;Block2 包含2 组128 通道,3×3 的卷积层;Block3 包含4 组256 通道,3× 3 的卷积层;Block4包括4 组512 通道,3× 3 的卷积层;Block5 也包含4 组512 通道,3× 3 的卷积层。本文期望在低层卷积层中提取相对精细的卷积特征,选取Block2 模块进行改进增强,最后在Block2 模块中进行池化前再增加3 组128 通道,3× 3 的卷积层,如图5 所示,以获取更高级,更精密的特征。
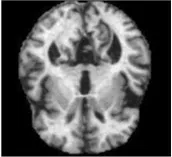
图4 VGG19网络的特征提取部分Fig.4 Feature extraction part of VGG19 network

图5 改进的VGG19网络的特征提取部分Fig.5 Feature extraction part of improved VGG19 network
将原VGG19 网络提取的脑部特征与改进后的VGG19 网络提取的脑部区域特征通过Grad_CAM[20]和Grad_CAM++[21]进行可视化,对比效果如图6 所示。
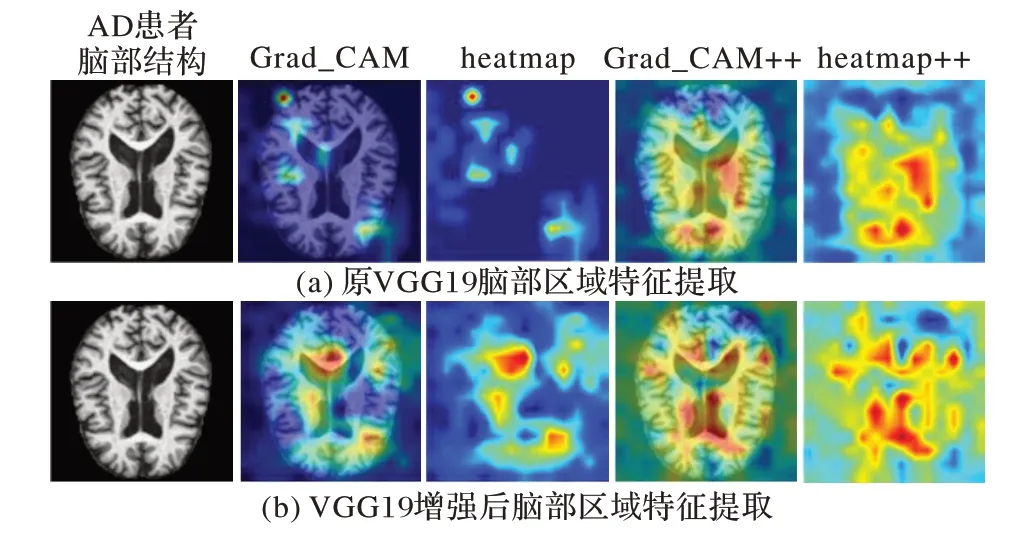
图6 特征网络可视化对比Fig.6 Visualization comparison of feature networks
从图6 可以看出,对于同一张AD 患者脑部结构图,从Grad_CAM、heatmap、Grad_CAM++和heatmap++四种形式能够表明:经过改进增强后的网络提取的特征范围明显更大、更精细,包含的有效信息更多。
3 实验与结果分析
3.1 数据集
本文使用的数据来自华盛顿大学阿尔兹海默病的成像数据OASIS(Open Access Sesies of Imaging Studies)[22]。此数据集包含18~96 岁的416 名被试者,其中AD 被试者100 人,NC 被试者316 人。实验中,本文选取AD 被试者和NC 被试者各100 个。所有数据都经过去除面部特征、校正和配准等处理。训练集包含AD 1 600 张,NC 1 600 张,测试集包含AD 320 张,NC 320 张,共计3 840 张图片。图7 展示了数据集中测试集AD 和NC 的图片,如果观察者不是相关领域的专业人士,很难判断出这两种图片的类别。
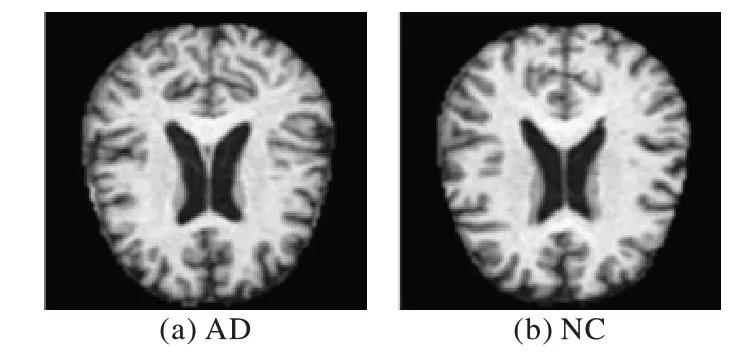
图7 测试集中的图片Fig.7 Images in test set
3.2 实验环境和内容
模型训练使用GPU 为Nvidia GTX1080Ti,显存11 GB,CPU 为Inter Core i5 7500,显存11 GB,使用CUDA 11.0,操作系统为Ubuntu 16.04,深度学习框架使用Pytorch-1.7.0。
为了和基本模型做对比,本文使用的网络的特征提取部分采用VGG19,并将fc6、fc7、fc8 三个全连接层去掉。首先,在送入网络之前,对数据的空间域进行增强,然后将数据裁剪 为224× 224,batchsize 大小设置为16,初始学 习率为0.001,epoch 为100,使用随机梯度下降(Stochastic Gradient Descent,SGD)优化器,动量为0.9,gamma 值为0.9,权重衰减为0.005,每隔2 次迭代调整一次学习率。
整个训练过程通过注意力引导数据增强结合双线性注意力池化算法得到线性分类层的输入,其关键步骤分为两步:
步骤1 首先,将训练的图片,通过增强后的VGG19 网络进行特征提取,得到特征图;然后,经过注意力学习网络将每一张特征图生成32 张注意力图,对应原图目标中32 个不同的部位;最后,经过注意力引导数据增强,在生成的32 张注意力图中,随机选择其中的一张进行注意力剪裁和注意力删除,从而突出图像重点关注区域。
步骤2 在得到特征图和注意力图后,采用双线性注意力池化的方式,将特征图和每个通道的注意力图按元素点乘,相乘之后的结果再进行池化降维和拼接操作获得最后的特征矩阵,作为线性分类层的输入。
测试过程也分为两个部分:
步骤1 将测试图片输入到训练好的模型中得到每个类别的粗分类概率和32 张注意力图。
步骤2 将步骤1 中得到的32 张注意力图像素取平均值,根据平均值画出截取框,将截取框上采样还原后再放入训练好的模型中,得到“基于注意力”的各个类别的细分类概率。
最后将上述两步的粗分类概率值和细分类概率值取平均后作为分类结果。
3.3 结果分析
3.3.1 评价指标
为了评估该模型AD 分类的性能如何,本文将采用准确性(accuracy)、敏感性(sensitivity)和特异性(specificity)作为分类网络的评价指标[23]。
准确性(accuracy)反映了训练网络准确分类AD 和NC 的数量,准确性越大,表明正确分类AD 和NC 的数量就越多,其表达式如式(10)所示:
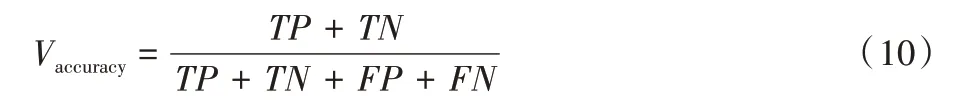
其中:TP、TN、FP和FN分别代表真阳性、真阴性、假阳性和假阴性。
敏感性(sensitivity)代表了模型准确分类AD 患者的数量,敏感性(sensitivity)越大,诊断对的AD 病例就越多,其计算式如式(11)所示:

特异性(specificity)说明了训练网络正确分类正常人的数量,特异性(specificity)越大,正常人诊断为AD 患者的就越少,计算式如式(12)所示:

3.3.2 不同网络的三大评价指标
为了表明本文所采用的细粒度分类网络比传统的分类网络更有效,首先,将数据集送入传统经典分类网络VGG19和ResNet101,对三大指标进行比较。
传统经典网络三大指标如表2 所示,由于VGG19 网络提取了更充分的特征,分类效果明显优于ResNet101,所以对于特征提取网络,本文研究考虑采用VGG19 作为基础特征网络。

表2 传统的分类网络性能对比 单位:%Tab.2 Performance comparison of traditional classification networks unit:%
本文采用WSDAN 作为基础网络模型,特征提取网络有多种选择,比较结果如表3 所示。
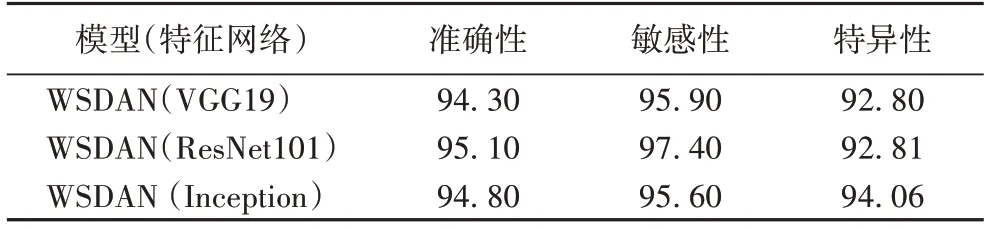
表3 使用不同特征提取网络的WSDAN基础网络模型 单位:%Tab.3 WSDAN basic network models with different feature extraction networks unit:%
由表3 可以发现,相较于表2 仅采用传统经典的分类训练网络来说,使用细粒度网络区分类内差异较小的图像具有一定优势。
将经过增强的图像导入上述3 个网络模型进行训练分类(导入增强图像的网络称为WSDAN_d),结果如表4所示。
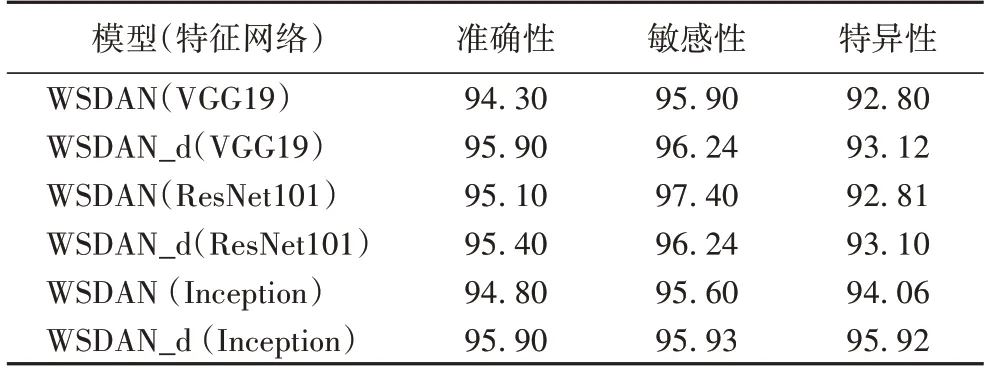
表4 增强图像后模型的训练结果与基础网络模型结果的对比 单位:%Tab.4 Comparison of training results of models with enhanced images and results of basic network models unit:%
由表4 能够看出,经过空间域增强图像后,在以上3 个模型中均有明显的提升。深入分析发现,特征网络VGG19 准确性提升了1.6 个百分点,ResNet101 的准确性提升了0.3 个百分点,Inception 特征网络提升了1.1 个百分点;敏感性对比中,VGG19 提升了0.34 个百分点,ResNet101 降低了1.16 个百分点,Inception 增加了0.33 个百分点;特异性比较中,三种特征提取方式均有所提升;但是综合前人经验、网络适用性、以及特征提取的精细程度和对比结果可知,VGG19 加深了网络结构,能更加充分地提取特征,因此选取VGG19 网络进行特征提取。
接下来的训练模型中,特征提取网络采用改进的VGG19网络,数据集首先采用未经增强的原始图像,结果如表5所示。

表5 使用改进的VGG19网络的模型与使用基础VGG19网络的模型对比 单位:%Tab.5 Comparison of model with improved VGG19 network and model with basic VGG19 network unit:%
以上对比结果中显示,改进后的网络在准确性和特异性上明显优于基础网络,尤其是特异性方面,相较于基础网络提高了2.82 个百分点,说明将正常人误诊为AD 患者的概率极小。
对VGG19 网络Block2 模块进行改进时,每增加一组128通道、3× 3 卷积层都进行对比,其结果如表6 所示。结果表明,增加3 组128 通道、3× 3 卷积层取得的效果最好。
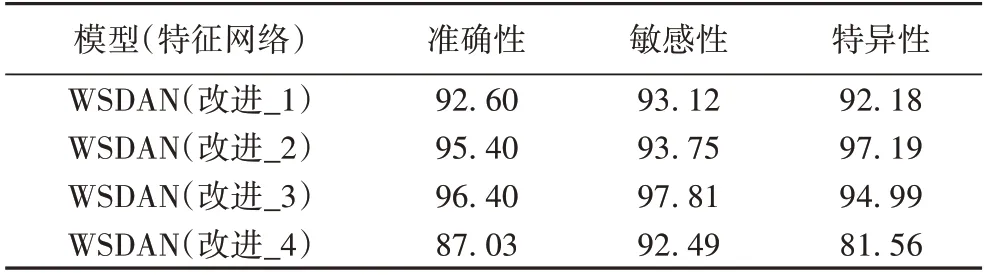
表6 增加不同的卷积层对比 单位:%Tab.6 Comparison of adding different convolutional layers unit:%
接着,在改进的VGG19 网络的基础上,同时结合空间域增强图像,效果如表7 所示。

表7 增强图像结合改进网络的模型与基础网络模型的对比单位:%Tab.7 Comparison of model with enhanced images combining improved network and basic network model unit:%
表7 结果表明,增强的图像结合改进网络模型与基础模型相比,准确性提升了2.1 个百分点,敏感性提升了1.91 个百分点,特异性提升了2.19 个百分点,提升效果较为明显。
综上所述,本文采用的网络在阿尔兹海默症分类研究上无论是从分类准确率、正确分类AD 患者还是正确分类正常人来说,都是具有一定提升效果的。最后,在使用相同数据集的条件下结合不同分类网络的三大指标比较结果如表8所示。
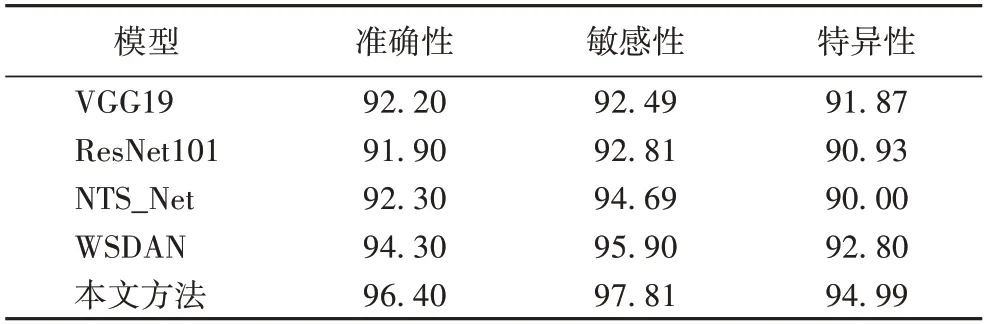
表8 不同分类网络的指标对比 单位:%Tab.8 Comparison of indicators of different classification networks unit:%
从表8 中可知,本文的方法在该数据集上表现良好,敏感性高于WSDAN 有1.91 个百分点,高于NTS_Net 网络有3.12 个百分点,高于ResNet101 有5 个百分点,高于VGG19有5.32 个百分点;准确性比WSDAN 提高了2.1 个百分点,比NTS_Net 提高了3.1 个百分点,比ResNet101 提高了4.5 个百分点,比VGG19 提高了4.2 个百分点;特异性比WSDAN 提高了2.19 个百分点,比NTS_Net 提高了4.99 个百分点,比ResNet101 提高了4.06 个百分点,比VGG19 提高了3.12 个百分点,表明本文方法有较好的分类准确率和良好的泛化能力。
4 结语
为了更有效地对阿尔兹海默症核磁共振图像进行分类,本文提出了一种基于改进增强的弱监督细粒度分类方法。首先,通过弱监督注意力学习网络得到注意力图,并且利用注意力引导数据增强,将原图和增强后的数据都作为输入数据进行训练;然后,结合双线性注意力池化算法将特征图和注意力图点乘得到各个部分的特征图,采用卷积或者池化处理这些部分的特征图;最后,将特征图结合得到特征矩阵,作为线性分类层的输入。本文的方法在OASIS 数据集表现良好,取得了96.40%的分类准确率,优于目前热门的细粒度AD 分类。然而本文研究只是在数据和特征提取部分做了改进增强,没有涉及网络传播中的修改,在下一步工作中可以继续探索所提模型,使得本文网络结构更加完善。
猜你喜欢
计算机工程与应用(2023年22期)2023-11-27 05:35:46
科学技术与工程(2023年3期)2023-03-15 10:34:12
红外技术(2022年11期)2022-11-25 03:20:40
软件导刊(2022年3期)2022-03-25 04:45:04
高技术通讯(2021年1期)2021-03-29 02:29:24
计算机技术与发展(2019年1期)2019-01-21 00:56:38
电子制作(2018年19期)2018-11-14 02:37:08
电脑与电信(2018年11期)2018-02-16 05:41:32
自动化学报(2017年11期)2017-04-04 02:52:58
信息安全研究(2016年3期)2016-12-01 06:06:41
