
基于AlphaPose优化模型的老人跌倒行为检测算法
2022-02-26 06:58:48马敬奇陈敏翼
计算机应用 2022年1期
马敬奇,雷 欢,陈敏翼
(1.广东省现代控制技术重点实验室(广东省科学院智能制造研究所),广州 510070;2.广东省科学技术情报研究所,广州 510070)
0 引言
截至2020 年我国60 岁以上(含60 岁)的老年人口突破2.3 亿,是世界老年人口最多的国家[1],中国疾病监测系统的数据显示,跌倒已经成为我国65 岁以上老年人因伤致死的首位原因[2]。医学调查表明,在跌倒后如果得到及时救治,可降低80%的死亡风险,显著提高老年人的存活率,因此,快速检测跌倒事件的发生有重大意义[3]。
目前,常见的跌倒检测方法主要有3 种:1)基于环境设备的检测方法。根据人体跌倒时形成的环境噪声进行检测,如感知物体压力和声音的变化检测跌倒[4],误报率较高,极少被采纳使用。2)基于穿戴式传感器的检测方法。利用加速度计和陀螺仪检测跌倒[5],长时间配戴传感器影响人的生活舒适度,会增加老年人机体负担,从事复杂活动时误报率较高。3)基于视觉识别的检测方法[6]。可分为两类:一类是传统机器视觉方法,提取有效的跌倒特征,对硬件要求低,但易受背景、光线变化等环境因素的影响,鲁棒性差;一类是人工智能方法,将相机图像数据用于卷积神经网络(Convolutional Neural Network,CNN)的训练和推理,虽然识别精度高,但高效的性能往往伴随着高昂的硬件成本,极大地限制了落地应用。近年来移动终端和小型嵌入式设备也具备了令人青睐的算力,且价格低廉,为人工智能算法的迁移部署提供了可能性。
文献[7]中以人体三维姿态数据为特征输入卷积神经网络,训练得到跌倒检测模型,具备了较高的准确率,但平均识别时间为0.178 s,实时性较低。文献[8]中提出一种嵌入式机器学习算法,使用滑动窗口提取图像特征,在计算机端利用支持向量机(Support Vector Machine,SVM)对特征进行分类,精度较高,但受低功耗嵌入式设备有限内存和并行计算的限制,该方法无法移植到低成本的嵌入式控制器中。文献[9]采用带注意力机制的轻量化结构搭建深度卷积网络提取人体关节点坐标,利用帧间关节点的变化追踪行人和检测跌倒行为,在Jetson TX2(硬件成本约为Jetson Nano 的4 倍)嵌入式平台帧率达到16.74 frame/s。文献[10]利用文献[11]中的深度学习算法获取人体的骨架图数据,通过计算人体质心点的下降速度、跌倒后颈部关节点的纵坐标值是否大于阈值,以及肩部和腰部关节点的相对位置关系来判断跌倒是否发生,在自制数据集上达到92.8%的平均检测精度。文献[12]中提出了一种光学匿名图像传感系统,利用卷积神经网络和自动编码器进行特征提取和分类,检测老人异常行为,一定程度保护了老年人的隐私。文献[13]中利用二维图像数据,通过帧差法、卡尔曼滤波等提取有效的图像背景作为KNN(K-Nearest Neighbors)分类器的输入,实现了96%的精确率,易受可变环境因素影响,预处理阶段工作量大。文献[14]中利用YOLO(You Only Look Once)v3 检测人体目标得到人体区域矩形框,将跌倒过程中的人体运动特征与CNN提取的深度特征融合,进行人体跌倒检测判别,其环境适应性和跌倒检测准确率都高于传统的人体跌倒检测方法。文献[15]中利用二维图像数据计算光流信息,并送入VGG(Visual Geometry Group)对光流信息进行特征提取和分类,检测跌倒现象。文献[16]中将CNN 卷积层和全连接层提取的特征信息送入长短期记忆(Long Short-Term Memory,LSTM)网络中,训练提取人体空间动作的时序相关性,识别人体行为,LSTM 需要对数据进行动态存储和更新,实时性受限。
因此,为在低功耗、低成本硬件平台快速、准确检测老人跌倒的异常行为,本文提出了一种基于AlphaPose 优化模型的异常行为检测算法。该算法对行人目标检测模型和姿态估计模型进行加速优化,通过优化的姿态估计模型快速获取人体姿态关节点图像坐标,结合人体跌倒过程瞬时姿态变化特征和跌倒状态短时持续不变的特征来判断跌倒现象的发生,并将算法移植到嵌入式开发板,与主要的基于人体姿态的跌倒检测算法进行了对比分析,实验结果验证了所提方法的有效性。
1 AlphaPose人体姿态估计
人体姿态关节点检测方法主要有两种:自顶向下和自底向上。1)自顶向下方法以AlphaPose[17]为代表,是一种分阶段的检测模型,首先进行目标检测,识别出图像中的人体目标,并标记各个人体区域矩形框,排除非人物体的干扰;再对各个人体区域进行关节点检测。此种方法具有极高的准确率。2)自底向上方法以OpenPose[11]为代表,是一种端到端的检测模型,首选检测图像中所有的人体关节点,再通过关节点之间的关联关系区分关节点属于哪个人体。这种方法运算较快,但容易引入非人物体的干扰,检测精度较低。表1 为主流人体姿态检测模型在COCO 数据集上的性能对比[17],可见在主要的精度指标上AlphaPose 均优于对比算法,AP@表示IOU(Intersection Over Union)为某一设定值时的准确率。为保证跌倒算法的可靠性,本文算法在AlphaPose 高精度的基础上,进行人体姿态模型推理加速和跌倒算法的设计工作。
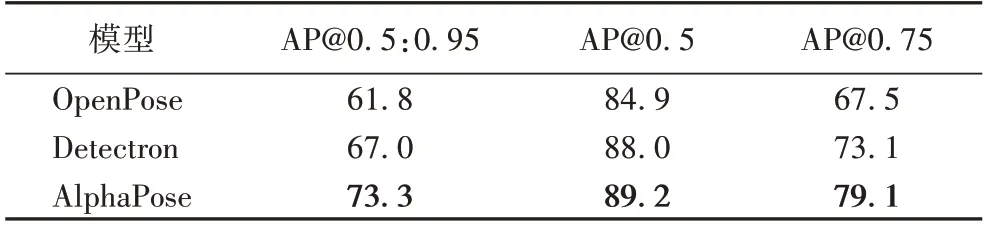
表1 主流人体姿态检测模型的性能对比 单位:%Tab.1 Performance comparison of mainstream human pose detection models unit:%
2 人体跌倒检测方法
本文算法主要的相关工作包括:1)对姿态估计模型进行运算加速优化,加快人体目标检测和姿态关节点推理,为算法的嵌入式平台移植应用提供低延迟、高吞吐率的部署推理;2)利用人体姿态关节点图像坐标数据,建立人体跌倒判定算法,结合人体跌倒过程瞬时姿态变化特征和跌倒状态短时持续不变的特征,判断跌倒现象的发生。
2.1 姿态估计模型推理加速优化
AlphaPose 是一种分阶段的姿态估计模型,因此推理加速工作主要分为对目标检测模型的优化和对姿态关节点检测模型的优化。在人体目标检测模型推理加速之后,对人体目标图像进行了序列化,以提高目标检测模型与姿态关节点检测模型之间的数据交换效率。
2.1.1 人体目标检测模型的优化
原AlphaPose 人体目标检测采用了YOLOv3[18],近年来YOLOv4 出现,在检测精度和检测速度方面都明显超越了YOLOv3,且能应对更复杂的检测环境(例如复杂光线、遮挡),达到了目标检测领域的新水准。本文的人体目标检测模型优化以YOLOv4 系列中的轻量化模型YOLOv4-tiny-416(参数量24.3 MB)为优化目标,在检测精度和检测速度之间得到平衡,具体的优化方法如图1。

图1 人体目标检测模型的优化Fig.1 Optimization of human target detection model
YOLOv4 网络模型输出维度初始化,其中网络层'030_convolutional'=[c,h//32,w//32],'037_convolutional'=[c,h//16,w//16],其中:c表示输入图像通道数,h表示输入图像,w表示输入图像宽,//表示整除操作;在维度初始化后的行人目标检测模型中创建onnx 网络节点,并移除dummy 网络层中的route 和yolo 节点;对维度初始化后的行人目标检测模型中的输入层进行判别,若输入层为“convolutional”,则加载卷积权重参数,若输入层为“upsample”,则加载上采样参数;创建维度初始化后的行人目标检测模型计算图,并加载模型转换优化器,经过转换,获得优化后的目标检测模型YOLOv4-tiny-trt-416,模型参数量32.7 MB。
2.1.2 人体目标图像序列化
得到人体目标检测结果之后,将检测结果转化为2 维的tensor 数据结构,Td=[[x1,y1,w1,h1,sc1],[x2,y2,w2,h2,sc2],…,[xi,yi,wi,hi,sci]],其中[xi,yi,wi,hi,sci]表示第i个人体的结构化数据,x表示预测框左上角的图像横坐标,y表示预测框左上角的图像纵坐标,w表示预测框的宽,h表示预测框的高,sc表示判定为人体的置信度。
原始图像Im变换为浮点32 位的tensor 类型数据Im_t,且对Im_t进行归一化操作,如式(1):

其中:Im_t[0]为Im的R 通道数据,Im_t[1]为Im的G 通道数据,Im_t[2]为Im的B 通道数据。
根据Td,从原始图像中截取出人体区域图像,并按照sc从高到低排列,得到序列化的图像列表,实现人体图像的序列化,提高目标检测模型与人体关节点检测模型之间的数据交互效率。
2.1.3 姿态关节点检测模型的优化
原AlphaPose 姿态关节点检测采用的是以Fast_Reset50为基础网络,模型参数量为238.9 MB,优化方法如图2 所示。

图2 关节点检测模型优化Fig.2 Optimization of joint point detection model
姿态关节点检测模型输入dummy 网络层维度初始化,dummy 网络层输入维度设置为tensor类型(1,3,Wdummy,Hdummy),其中:1 表示batchsize为1;3 表示图像通道数;Wdummy、Hdummy表示网络层输入图像归一化尺度,本文Wdummy=160、Hdummy=224。为维度初始化的姿态关节点检测模型中创建onnx 网络节点,并对维度初始化的姿态关节点检测模型的输入输出网络层定制设计,输入层设定为“input1”,输出层设定为“output1”。创建目标检测模型计算图,设定计算图输入维度为(1,3,Wd,Hd),其中:1 表示batchsize为1;3 表示图像通道数;Wd、Hd表示网络层输入图像归一化尺度,本文Wd=160、Hd=224,并加载模型转换优化器,生成姿态关节点检测优化模型Pose-trt,模型参数量229.8 MB。
2.2 人体跌倒判定算法
生活中的跌倒过程一般为:行走(站立)→跌倒过程→跌倒状态,且跌倒过程往往发生得非常突然急促,一瞬间即可完成,由于跌倒过程存在时间短,该过程的跌倒特征并不容易获取。而跌倒状态一般会保持一段时间,尤其是老年人发生跌倒之后会持续更长时间的跌倒状态,其跌倒特征更容易获取。因此在跌倒过程中,跌倒状态的可靠快速检测更具有实际意义。
人体姿态估计模型推理加速优化之后,能够快速准确地获取人体的主要关节点图像位置数据,得到的18 个姿态关节点如图3(a)所示。利用人体姿态关节点数据,建立人体跌倒判定算法,结合跌倒过程瞬时姿态变化特征和跌倒状态短时持续不变的特征,检测跌倒事件。具体包括:1)瞬时跌倒特征,人体跌倒瞬间头部关节点线速度与胯部关节线速度之间的数学关系。2)跌倒状态特征,计算人体中垂线与图像X轴之间夹角(分为躯干上半部中垂线与图像X轴之间夹角θu和躯干下半部中垂线与图像X轴之间夹角θd)的变化来判断跌倒现象的发生。跌倒特征分析如图3(b)、(c)所示,瞬时跌倒特征的思想来源是人在跌倒初期的某个过程,一般是脚踝位置的位移不明显,人体躯干围绕脚踝向某一方向跌倒,类似人体躯干以脚踝为圆心转动,那么离圆心越远的点线速度越大。跌倒状态特征利用的是人体自然站立平衡性的特点,当人体躯干与水平面夹角超过某一角度时,具有极大的跌倒可能性。跌倒检测算法流程如图4 所示。
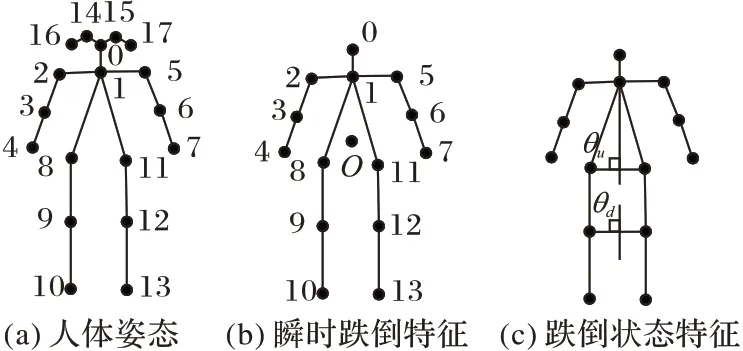
图3 人体姿态图与跌倒特征Fig.3 Human pose map and fall characteristics

图4 人体跌倒判定算法流程Fig.4 Flowchart of human fall determination algorithm
2.2.1 瞬时跌倒特征的计算
步骤1 计算人体头部关节点0 的线速度V0,计算人体胸部重心O的线速度VO,人体胸部重心位置由人体关节点1、8、11 图像坐标计算得出。计算人体脚踝线速度V10-13,V10-13是人体关节点11 和13 的平均线速度。以上线速度是由连续M帧图像、每次间隔N帧图像所计算出的平均线速度。
步骤2 如果V0、VO、V10-13满足式(2),则初步判定为疑似跌倒。

其中:χ为设定阈值,α,β分别是速度V10-13的下限、上限值。
2.2.2 跌倒状态特征的计算
在跌倒以后,一般会保持跌倒状态一段时间后,才开始发生姿态变化,比如手撑地、坐起、躬身弯腰爬起等,因此需要时间阈值的过滤。根据人体站立平衡的特点,当人体躯干上半部中垂线与水平面夹角满足某一条件时人体就会失去平衡,发生跌倒,但并不一定满足,例如弯腰捡东西、系鞋带等动作。因此,结合步骤2,检测人体躯干下半部中垂线与水平线夹角的变化,同样加上时间阈值的过滤,判定人体跌倒情况。
步骤1 计算人体上半身中垂线与水平线夹角θu,如果θu<ε1,且在时间阈值T1 时长内保持θu<ε1,则判定为跌倒;否则到步骤2。
步骤2 计算人体下半身中垂线与水平线夹角θd,如果θd<ε1,且在时间阈值T2 时长内保持θd<ε1,则判定为跌倒;否则判定行人未发生跌倒。
3 实验结果与分析
实验所用硬件环境为NVIDIA Jetson Nano 嵌入式开发板,4 核64 位ARM CPU,128 核集成NVIDIA GPU,4 GB LPDDR4 存储器,外观尺寸80 mm×100 mm。软件环境为64位Ubuntu18.04LTS,依赖的主要工具包括opencv4.1.1、torch1.6.0、torchvision0.7.0、tensorRT7.1.3。
实验数据为从公开数据集le2i fall dataset[19]选取104 段人体跌倒视频,每段包含完整的跌倒过程(从站立姿态→跌倒状态),视频分辨率为320×240,场景包括家庭、办公室、茶水间3 种。家庭环境为客厅场景,包括沙发、餐桌、楼梯、座椅、台灯等饰品,包含多种光照条件。办公室场景内包括桌子、椅子,光照较为正常且分布均衡。茶水间场景内包括沙发、桌子、茶具等,光线较为正常且分布均衡。每段视频包含的人数为1 人,共7 人参与视频的采集,包括1 名女士6 名男士,包含多种跌倒姿态,且包括行走、弯腰、坐姿干扰姿态。
将当前主要的基于人体姿态的跌倒检测算法YOLOv3+Pose、YOLOv4+Pose、YOLOv5+Pose、trt_pose、NanoDet-m+Pose与本文算法进行对比,为确保在嵌入式平台上的运算效率最优,YOLO 系列的模型具体为YOLOv3-spp-416、YOLOv4-tiny-416、YOLOv5s,实验分别从模型轻量化优化、定量分析和定性分析3 个方面进行对比。
3.1 模型轻量化优化对比
3.1.1 目标检测模型对比
由表2 可知,YOLOv4-tiny-trt-416 的检测帧率达到30.3 frame/s,是原始YOLOv4-tiny-416 的2.83 倍,而平均准确率保持一致,均优于其他对比方法。YOLOv4-tiny-trt-416的平均准确率和检测帧率均明显优于NanoDet-m,NanoDet-m也具备一定的实时性。YOLOv5s 的平均准确率与YOLOv4-tiny-trt-416 相差约1.42%,但其检测帧率明显低于YOLOv4-tiny-trt-416,难以达到实时性的要求。YOLOv3-spp-416 的平均准确率优于YOLOv4-tiny-trt-416,但其检测帧率仅为4.15 frame/s,无法满足实时性的需求。因此从检测精度和检测速度综合考虑,在各对比算法中YOLOv4-tiny-trt-416 是最优的目标检测方法,适用于低功耗嵌入式开发板。
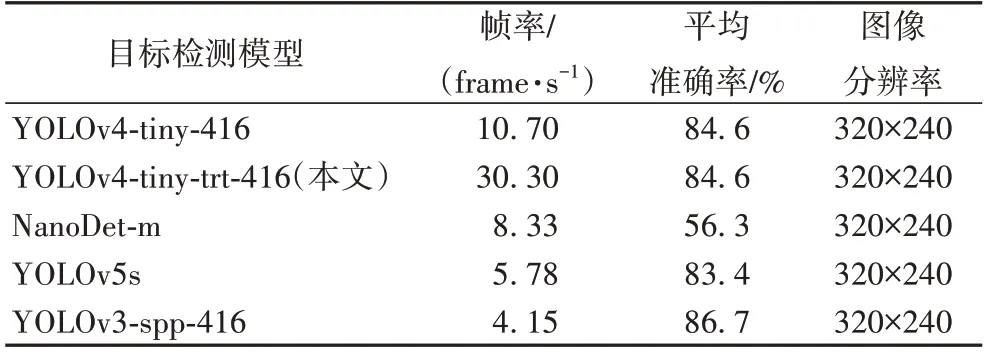
表2 目标检测模型的性能对比Tab.2 Performance comparison of target detection models
3.1.2 姿态检测模型对比
由表3 可知,Pose-trt 模型检测帧率是原始Pose 的1.7倍,帧率达到了12.5 frame/s,同时保持相同的准确率,具有一定的实时性。Pose-trt 的检测帧率和平均准确率均优于OpenPose,OpenPose 平均准确率高于trt_pose,检测帧率约降低为trt_pose 的1/2,但trt_pose 输入的图像分辨率为224×224。因此,在对比姿态估计模型中Pose-trt 最优。

表3 姿态检测模型的性能对比Tab.3 Performance comparison of pose detection models
3.2 定量分析
为验证本文算法的时效性和准确性,将本文算法与YOLOv3-spp-416+Pose、YOLOv4-tiny-416+Pose、trt_pose、YOLOv5s+Pose、NanoDet-m+Pose 等算法进行对比,评价标准主要包括检测帧率、检测准确率,并统计测试视频的漏检数、误检数,还分析了瞬时跌倒特征和跌倒状态特征对跌倒事件检测的有效性。准确率为P=Tc/Ta,其中Tc是跌倒测试视频中检测为跌倒的视频个数,Ta为跌倒测试视频总数,漏检为跌倒测试视频中未能检测到跌倒的视频数,误检为跌倒测试视频中将非跌倒行为检测为跌倒的视频数。
各对比算法的性能如表4 所示。从表4 中可以看出,本文算法的检测帧率和准确率均明显高于其他对比算法,帧率达到8.83 frame/s,具有较好的实时性,误检测和漏检测数最少,准确率超过91%,一定程度上能够满足实际落地应用的需要。YOLOv5s+Pose 准确率与本文算法较为接近,YOLOv5s 在目标检测方面具有较明显的优势,是目前最优秀的目标检测模型之一,但其在Jetson Nano 上的检测速度较慢,无法满足实时性的需要。其他对比算法虽然也有较高的准确率,但同样受限于检测帧率,无法满足时效性。trt_pose采用自底向上的方式检测人体姿态关节点,其检测效果并不理想,在对比算法中trt_pose 的准确率最低,但其检测帧率高于YOLOv3-spp-416+Pose、YOLOv5s+Pose、NanoDet-m+Pose。从表4 中也可以看出,跌倒状态特征生效次数明显多于瞬时跌倒特征生效次数,跌倒状态特征能够更有效检测跌倒现象的发生,具有更好的实用性。

表4 使用跌倒测试视频进行的算法性能定量分析Tab.4 Algorithm performance quantitative analysis by using fall test videos
3.3 定性分析
跌倒检测方法的定性分析主要围绕不同跌倒姿态、不同着装、不同场景、不同光照条件进行,所选测试视频符合这样的测试条件,同时为了验证摄像头拍摄角度、测试人员体型、测试人员身高变化对算法的影响,分析时所选择的视频包含了不同测试人员从不同方向进行跌倒,包括了蜷伏、仰俯、侧卧、趴倒等多种跌倒姿态。分析过程选取le2i fall dataset 中家庭、办公室、茶水间场景的9 个测试视频,截取的测试效果图像如图5 所示;另外还针对le2i fall dataset 中的5 类漏检测情况进行了原因分析,截取的测试效果图像如图6 所示,分析的重点聚焦在跌倒状态的检测。
如图5 所示,在le2i fall dataset 中选取9 个测试视频,每个视频中的测试人员的跌倒方向均不相同,图像中带“◇”标记的表示未能有效检测跌倒,其他图像中能够检测人体姿态且成功检测出跌倒现象;姿态关节点连接线的粗细程度表明关节点的置信度,线越粗置信度越高。①、②、③为茶水间场景,光照条件较好且光线分布均匀,①为侧卧跌倒姿态,②为仰俯跌倒姿态,③为趴倒跌倒姿态。本文算法均能成功检测到跌倒现象,且能较完整地检测人体关键点,与真实姿态较为接近。以①为例说明:YOLOv3-spp-416+Pose 成功检测到跌倒,但对人体上半身的姿态估计较差(圆圈处),关节点之间的连线连接混乱,在②中也出现类似情况,③中关节点置信度较低。YOLOv4-tiny-416+Pose 成功检测到跌倒,但存在姿态错误估计现象(如箭头所示),真实图像此处并不存在右臂,在②、③中能够较好地检测到跌倒。YOLOv5s+Pose 成功检测到跌倒,但对人体上半身的姿态估计较差(圆圈处),关节点之间的连线连接混乱,另外对右腿部的姿态检测不准确(如箭头所示),在②、③中也出现类似情况(如箭头所示)。trt_pose 虽然能成功检测跌倒现象,但对人体关键点的估计并不理想,躯干上部关键点检测较为混乱,无法检测到腿部的关键点,且估计的关节点位置与真实的关节点位置存在偏差,在②、③中也出现类似情况,且存在较多的关键点缺失。NanoDet-m+Pose 成功检测到跌倒,但对腿部关节点的检测效果并不好,右腿姿态与真实姿态存在明显偏差(如箭头所示),在②、③中能够较好地检测到跌倒,但在②中出现了误检(如箭头所示)。

图5 le2i fall dataset 上不同算法的测试效果对比Fig.5 Test effect comparison of different algorithms on le2i fall dataset
④、⑤、⑥为家庭场景,光照较弱且光线分布不均,④为仰卧跌倒姿态,⑤为侧卧跌倒姿态,⑥为趴倒跌倒姿态,本文算法均能成功检测到跌倒现象,且能较好地检测人体关键点,但出现了局部关节点检测不准的现象(如箭头所示,④右臂处、⑤姿态与真实偏移、⑥右腿脚踝处)。以④为例说明:YOLOv3-spp-416+Pose 成功检测到跌倒,但对人体姿态估计较差(圆圈处),存在检测混乱和缺失现象,在⑤、⑥中也出现类似情况。
YOLOv4-tiny-416+Pose 成功检测到跌倒,姿态检测较为完整,在⑤中出现躯干上部检测不准的现象(圆圈处),⑥中的右腿脚踝处与左腿脚踝存在错误连接(如箭头所示)。YOLOv5s+Pose 成功检测到跌倒,但人体姿态关节点的置信度较低。trt_pose 无法检测跌倒现象,对人体姿态估计不完整,存在较多的关键点缺失。NanoDet-m+Pose 成功检测到跌倒,姿态检测效果较好,但在⑤中无法检测到人体目标,⑥中存在错误连接和关节点置信度低的现象(如箭头所示)。
⑦、⑧、⑨为办公室场景,光照条件良好且光线分布均匀,⑦为蜷伏跌倒姿态、⑧为侧卧跌倒姿态、⑨为仰俯跌倒姿态,本文算法均能成功检测到跌倒现象,且能较好地检测人体关键点,⑨测试人员右腿部超出图像边界,但仍然能够准确估计人体姿态。以⑦为例说明:YOLOv3-spp-416+Pose成功检测到跌倒,但对人体姿态估计较差,存在关节点漏检和置信度较低现象,在⑧、⑨中也出现类似情况,⑨在图像边缘处关节点估计置信度较低(如箭头所示)。YOLOv4-tiny-416+Pose 成功检测到跌倒,姿态检测较为完整。YOLOv5s+Pose 成功检测到跌倒,但人体姿态关节点的置信度较低,存在关节点漏检现象,在⑧、⑨中也出现类似情况(如箭头所示)。trt_pose 检测效果较差,对人体姿态估计不完整,存在较多的关键点缺失。NanoDet-m+Pose 虽能成功检测到跌倒,但姿态检测存在误检及关节点置信度较低的问题,在⑦中左腿脚踝存在误检,⑨中躯干部分出现了误检,且关节点置信度较低。
在测试时出现了漏检,可归结为5 类情况,选取具有代表性的5 个案例进行分析,如图6 所示,其中圆圈表示检测到跌倒。①人体区域接近图像边缘,测试人员为蜷伏跌倒状态,双臂和腿部被自身遮挡,所呈现的人体图像变形较为严重,加之头部图像部分缺失,不利于人体特征的提取与判别,因此本文算法、YOLOv3-spp-416+Pose、YOLOv4-tiny-416+Pose、YOLOv5s+Pose 都不能检测到人体目标,无法进行人体姿态检测。NanoDet-m+Pose 虽然能够检测到人体目标,但人体关节点置信度较低,所检测的姿态与真实姿态不一致,且出现了误检(如箭头所示)。trt_pose 仅能检测到左肩部关节点,缺失较多,为无效检测。②场景光线分布不均匀,测试人员侧卧跌倒姿态,人体头部、双臂局部自身遮挡,人体所在区域光线暗淡,人体区域梯度特征不明显,且人体腿部被桌椅遮挡,人体目标不易检测,对比算法均无法正常检测到人体目标。③测试人员身着黑色衣物,为侧卧跌倒姿态,双腿粘连在一起,且脚踝图像缺失,身体轮廓特征较少,本文算法、YOLOv3-spp-416+Pose、YOLOv4-tiny-416+Pose、YOLOv5s+Pose 均无法连续检测到人体目标,不能进行稳定的跌倒检测。trt_pose 能检测到人体膝关节以上的主要关节点,但与真实姿态相差较明显且姿态关节点位置出现偏移,为无效检测。NanoDet-m+Pose 无法检测到人体目标,姿态检测失败。④测试人员为侧卧跌倒姿态,身着红色上衣和黑色裤子,头部和双臂被自身遮挡,腿部被桌子遮挡,人体图像特征不明显,且人员跌倒位置的背景为红色,与人员上身衣物较为相似,图像对比度低,不利于人体目标的检测,对比算法均无法正常检测人体目标。⑤测试人员为趴倒跌倒状态,腿部被自身遮挡,由于相机拍摄高度较低,图像中的人体区域出现明显的“近大远小”畸形,较难进行人体目标检测,YOLOv3-spp-416+Pose 仅能在视频的部分帧检测到人体,并不能稳定持续检测,且检测出的人体姿态与真实姿态差别较大,可靠程度较低,而其他对比算法无法正常检测人体目标。

图6 不同算法漏检测情况对比Fig.6 Missed detection comparison of different algorithms
4 结语
为进一步推进跌倒检测系统的落地应用,提高老年人群体在居家生活、独自活动等情况下的行为安全,本文提出了一种基于AlphaPose 优化模型的异常行为检测算法。该算法通过对人体检测模型和人体姿态检测模型的优化加速,并利用人体姿态数据构建跌倒检测算法,能够快速迁移部署在低成本、低功耗的嵌入式开发板。实验结果表明,该算法具有较高的实时性和准确率,能够在线快速检测到老人跌倒行为的发生,具备一定的落地应用价值。
经过实验对比分析可知,本文所提跌倒检测算法的缺点有:①在光线分布不均匀的情况下检测效果不理想;②监控相机高度较低,导致所拍摄图像中人体跌倒后出现较明显的图像畸形,算法无法有效检测跌倒;③当人体跌倒方向与图像Y轴平行,跌倒位置与图像X轴中点较为接近,且人体跌倒时头部图像坐标大于脚踝图像坐标,此时的跌倒姿态与正常站立时的姿态非常接近,无法进行跌倒判别。为了改进算法的准确性,将开展下一阶段的研究工作:
1)研究光照自适应补偿算法,融合到跌倒检测系统中,增加系统的抗光照变化能力。
2)研究多相机联合检测方法,尝试用多个相机从多个角度进行跌倒检测,在一定程度上解决局部遮挡现象。
3)因目前尚无公开的专门针对老人异常行为公开的数据集,测试数据集缺少老年人异常行为视频数据,拟通过与广州市黄埔区养老院开展技术合作,逐渐收集老年人异常行为数据,增加更多的其他人体行为和测试场景进行跌倒实验,进一步发现算法的问题和不足。
猜你喜欢
科学技术创新(2021年19期)2021-07-16 10:07:04
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
沈阳航空航天大学学报(2020年6期)2021-01-27 02:11:30
学生天地(2020年3期)2020-08-25 09:04:16
汽车观察(2018年9期)2018-10-23 05:46:40
中国自行车(2018年8期)2018-09-26 06:53:44
中国交通信息化(2018年5期)2018-08-21 03:37:40
军营文化天地(2017年6期)2017-06-28 11:30:19
