
电子公文全文检索系统的设计及实现
2022-02-25 14:45:22张红玲
微型电脑应用 2022年2期
张红玲
(陕西警官职业学院, 法律系, 陕西, 西安 710021)
0 引言
1 知识本体
本体即事物的主体或自身,事物的来源或根源。在信息科学领域对“本体”存在着不同的定义,根据Neches等[10]的说法,本体是“给出构成某一领域词汇的基本关系和术语,并利用构成的规定对词汇外延规则的定义”。随着计算机、智能领域的发展,Fensel[11]将本体定义为“一个特定领域重要概念的共享的形式化描述”,体现了Ontology的4个含义:概念化、明确化、形式化、共享化。概念化:对客观事件某些现象建立抽象化的模型,该模型独立于具体环境状态。明确化:所有概念和关联关系都有精确定义。形式化:采用计算机可读的精确数学描述。共享化:Ontology中表征的知识是该领域公认的概念集。
在对本体进行具体表征时,则需要采用某种描述语言进行特征表述。目前应用较多的描述语言包括Ontolingua、Loom等,但要将本体概念应用于计算机网络应用程序,则需要考虑到标准化问题,即采用一个标准化语言表征本体,可省略各种描述语言描述本体间的转化问题。由于XML已经是Web上数据交换的标准语言,因此,目前开发的SHOE、XOL、OML等都是基于XML语言的描述语言。
2 基于本体的全文检索引擎
Lucene作为一类高性能、可伸缩的信息搜索库,本身只关注文本的索引和搜索[12]。Lucene提供了简单的函数调用接口进行数据的访问和管理,将嵌入在各种应用中进行全文索引/检索功能。在Lucene的输入输出结构类似于数据库的表、记录和字段,因此传统的应用文件、数据库等都可连接到Lucene的API接口,因此,Lucene本质是一个支持全文索引的数据库系统。
2.1 Lucene系统结构
Lucene系统结构基于面向对象的设计思想,首先定义一个与平台无关的索引文件格式,将系统核心部件设计为抽象类,将与平台相关的文件封装为类,通过面向对象的编程处理,形成一个低耦合、高效率的二次开发检索引擎系统[13]。图1为Lucene体系结构示意图,整个系统由基础结构封装、索引核心、对外接口构成,直接索引作为系统的核心,将检索产生的索引文件构成索引库。基础结构封装主要对不同类别的数据文件处理成类,对外接口实现不同数据类型的传输。
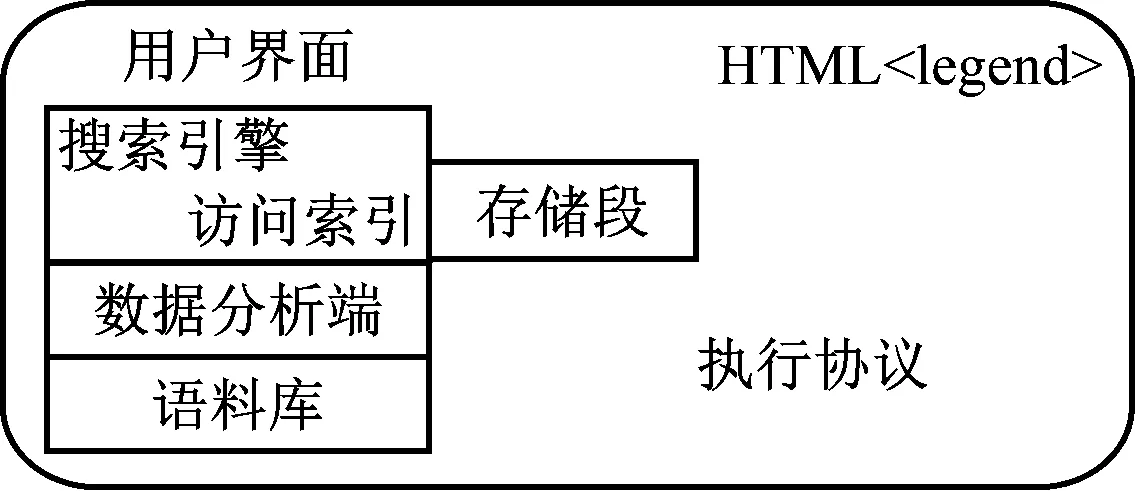
图1 Lucene体系结构
Lucene以JAR文件形式发布组件包,其中包括7个类包,3个核心类包,具体为:①org. Apache.lucene.analysis类包用于分词类,由Analyzer扩展类实现,参照Lucene的StandardAnalyzer类编辑分词分类器类;②org. Apache.lucene.index类包为系统提供数据库对接接口,常见索引、更新引擎;③org. Apache.lucene.search提供检索接口,可根据需求输入条件,获得查询结果集。
2.2 基于本体的检索模型
为保证全局信息检索系统查全率和查准率,提出基于本体的Lucene语义检索系统模型,如图2所示。
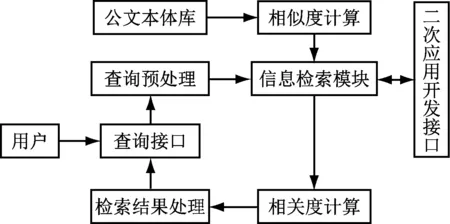
图2 基于本体的Lucene语义检索系统
系统首先构建相关领域的电子政务公文本体库,用户由查询接口输入需要的查询内容,由查询预处理模块对输入内容处理,转化为标准化的内容并提交给信息检索模块。信息检索模块根据相似度法则确定超过设定相似度临界值的相似概念集,并利用邻域本体通过Jena推理进行概念检索,由相关度来确定计算结果与用户查询内容间的相关性排序,将排序结果在应用界面中展现。
2.3 系统流程
系统实现对text、pdf、Word、Excel等多种格式的数字化公文检索,针对政府部门的实际需求和应用规则,将整个全文检索系统划分为3个模块,图3给出了系统流程图。
建筑企业要想在复杂残酷的市场竞争中生存发展,首先要提高企业自身的综合素质。综合素质的提高对建筑企业能否在市场中立足至关重要。综合素质的高低是一个企业的面貌体现,是能否在市场竞争中占据主导地位的体现。如建筑企业综合素质较低,就无法对市场需求与走向进行理性分析与研究,导致逐渐被市场所淘汰或者摒弃。所以,建筑企业应该加强工程施工管理模式的创新,只有创新的理念才是提升企业综合素质的基础与保障。
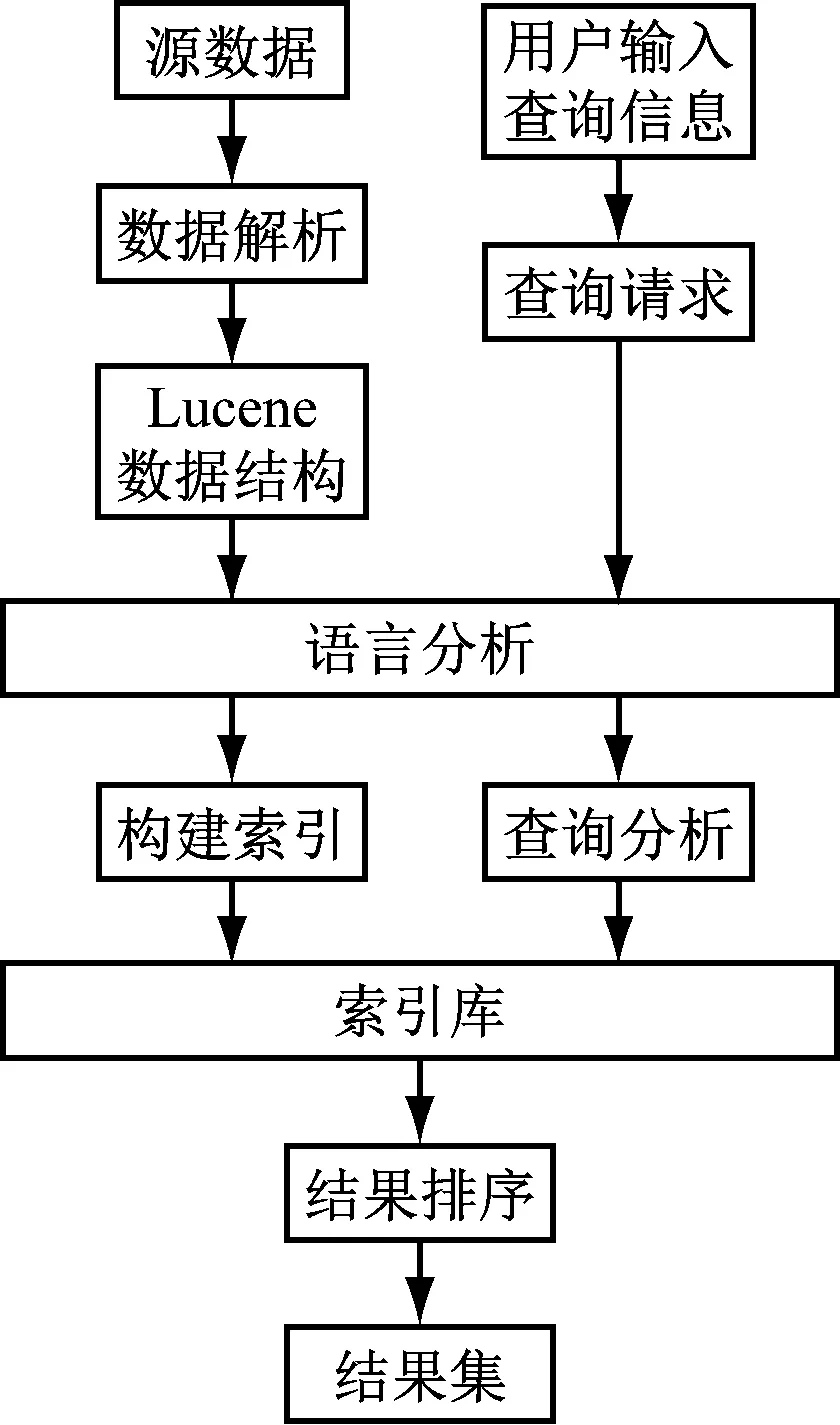
图3 本体的Lucene全文检索系统流程
整个系统分为公文抽取模块、索引模块、搜索模块。公文抽取模块利用建立的本体数据源进行数据抽取,索引模块对存储到Lucene终端公文文本进行倒排索引,搜索模块提供数据查询,由Lucene索引功能按照相关程度显示搜索结果。
2.3.1 公文抽取模块
部门接受到不同类型的数字化公文时,以Lucene为数据库来抽取文本数据。若数据为Word、Excel格式文本,采用POI技术抽取文件信息,若为pdf格式文本,采用PdfBox抽取文本。将文件中的文本信息以字段的形式保存在Lucene数据库中,同时将数字文档中的文件名、标题、发文单位等信息以字段的形式保存在Lucene中。
2.3.2 索引模块
不同格式的文件中的文件信息抽取文本后,由索引模块转化为固定格式,便于对内容进行索引和存储。这是系统支持各种格式文件的根本所在。采用Lucene选择一个合适的分词器,将文档内容与单词的形式进行划分,建立索引过程的具体步骤:将不同数据源作为Document类型对象;对数据对象分析,文本先由Analyzer分析,将分词后的内容交给IndexWriter建立索引;按照Lucene的索引格式写入索引文件。
2.3.3 搜索模块
公文文件索引完成后,系统即可为用户提供搜索服务。搜索模块提供搜索界面,接收到检索请求后,访问Lucene索引数据库,按照相关度对检索记录集进行排序,并返回给用户搜索结果。
Lucene支持B/S方式对系统内容进行全文检索,其中包括对公文正文、批阅文件内容的全文检索,全文检索无需设定关键词,能够对字、词、数字、数据的检索[14]。为便于用户检索,Lucene同时支持简单检索和高级检索两类,通过点击公文标题、主题词等相关信息常用项得到相应数据,也可通过And、OR逻辑组合检索。
当用户在图4中提出搜索请求时,如“党务”,由search.jsp页面的